Los mejores más de 50 agentes de IA de código abierto listados
Todos han estado construyendo agentes de IA, así que después de probar prácticamente con populares agentes de codificación de IA, creadores de agentes de IA y herramientas de uso de benchmarks para evaluar sus capacidades en el mundo real, hemos elaborado una lista seleccionada de los mejores más de 50 agentes de IA de código abierto. Haga clic en los encabezados de categoría para saltar directamente a nuestras principales selecciones:
Desarrollo de agentes e infraestructura
- Frameworks de agentes (Crea tu propio)
- Herramientas de automatización y orquestación de flujos de trabajo
Aplicaciones de agentes de dominio específico
- Agentes de automatización y navegación web
- Herramientas de codificación y desarrollo
- Herramientas de ciberseguridad
- Creadores de contenido de video con IA
- Asistentes financieros
- Asistentes de salud
- Agentes de investigación
- Asistentes de análisis de datos
- Asistentes personales
¿Cómo pensar en los agentes de IA?
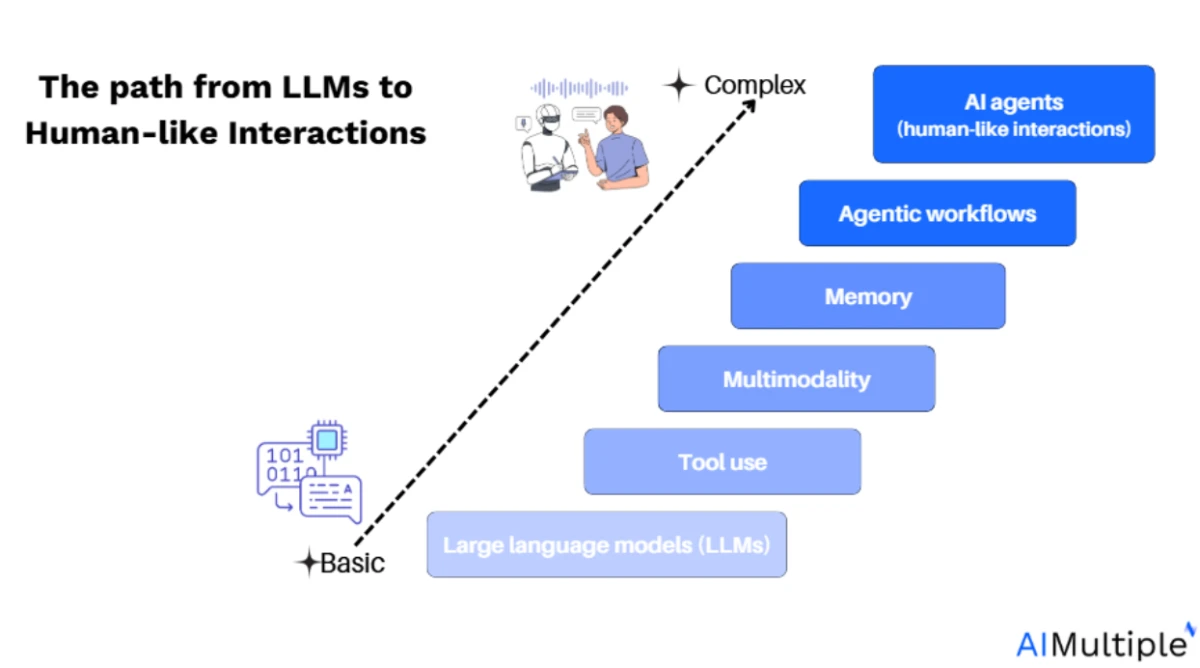
Un agente de IA es un sistema componible que combina planificación, memoria, uso de herramientas y ejecución iterativa. Forma un bucle estructurado alrededor de un LLM que puede tomar decisiones, realizar acciones y adaptarse a nueva información.
He aquí cómo pensar en ellos:
- Autonomía y flujos de trabajo: Los agentes de IA van desde la automatización básica de tareas basada en flujos de trabajo predefinidos hasta sistemas totalmente autónomos capaces de descomponer objetivos, usar memoria e interactuar con herramientas. El principal desafío técnico radica en mantener el contexto a través de los pasos y coordinar operaciones de varias etapas.
- Contexto y control: El verdadero desafío en los agentes de IA es asegurar que el LLM tenga el contexto adecuado en cada paso. Esto incluye gestionar el contenido que se introduce en el LLM y asegurar que el agente ejecute tareas relevantes basadas en un contexto actualizado.
- Integración de herramientas: Construir agentes efectivos requiere una integración perfecta con herramientas externas, APIs y fuentes de datos. Los frameworks como LangChain pueden ayudar a integrar estos recursos externos, pero el control sobre el flujo de trabajo es esencial para adaptar el comportamiento del agente a nuevas entradas.
- Beneficios de los frameworks de agentes: Todos los sistemas agénticos, ya sean flujos de trabajo simples o agentes autónomos complejos, pueden beneficiarse de las características principales proporcionadas por los frameworks agénticos. Estas características pueden construirse desde cero o aprovecharse de una plataforma de código abierto existente, dependiendo de sus necesidades.
Nuevos estándares
- Protocolo de Contexto de Modelo (MCP): El estándar de la industria sobre cómo los agentes hablan con fuentes de datos externas. LangGraph integra MCP para permitir que los agentes “conecten y usen” bases de datos y herramientas locales sin envoltorios personalizados.
- Stripe Protocolo de Comercio Agéntico (ACP): Este es el primer estándar industrial en vivo que permite a los agentes de IA manejar pagos, inventario y envíos de forma segura. Permite el “Checkout Agéntico”, donde el agente puede completar una compra para el usuario dentro de una interfaz de chat.
¿Qué es exactamente un agente de IA?
No existe una definición consensuada de lo que constituye un “agente de IA”.
- La IA tradicional define a los agentes como sistemas que interactúan con su entorno.
- La encuesta de Simon Willison a profesionales presenta una variedad de definiciones de trabajo de participantes de la industria.2
- Anthropic’s definición describe principios de diseño para construir agentes de IA efectivos y alineados.3
- Las principales empresas de consultoría enfatizan el papel de los agentes en la automatización de flujos de trabajo empresariales y la toma de decisiones.4 .
Muchas de ellas incluyen explícitamente flujos de trabajo y autonomía de lugar al final de un espectro.
Estamos de acuerdo con estos puntos de vista, por lo tanto, no proporcionamos una definición estricta. En su lugar, enumeramos los factores que hacen que un sistema de IA sea considerado más agéntico:
- Entorno y objetivos:
- Los sistemas de IA en entornos complejos, como aquellos con múltiples tareas y cambios inesperados, son agénticos.
- Los sistemas de IA que siguen objetivos sin ser instruidos son agénticos.
- Interfaz de usuario y supervisión: Los sistemas de IA que pueden aprender lenguajes naturales y los sistemas que necesitan menos supervisión del usuario son agénticos.
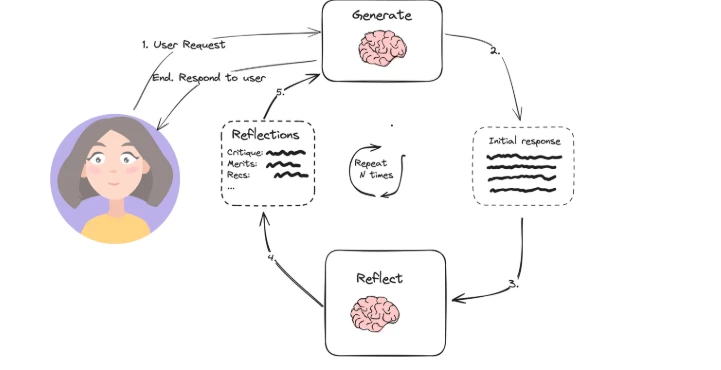
- Diseño del sistema: Los sistemas que utilizan patrones de diseño como el uso de herramientas (por ejemplo, búsqueda web, programación) o planificación (por ejemplo, reflexión, desglose de subobjetivos) son agénticos.
Para una explicación más detallada, anteriormente enumeramos estos factores y discutimos cómo definen los sistemas de IA agénticos.
¿Son estos agentes completamente autónomos?
Todavía no. La mayoría de los agentes de IA de código abierto mejoran la autonomía del LLM al permitir el uso de herramientas, la toma de decisiones y la resolución de problemas, pero aún requieren entradas estructuradas y un humano en el bucle.
Ejemplos como Devon y PR-Agent siguen lógica predefinida o flujos de trabajo de RL en lugar de demostrar un comportamiento agéntico completo. Otros agentes de IA aún carecen de capacidades de (Aprendizaje Autónomo + Generalización).
Cuándo (y cuándo no) usar agentes de IA
No todas las aplicaciones de LLM requieren complejidad agéntica. Muchos casos de uso se benefician mejor con generación aumentada por recuperación (RAG) ligera.
Los sistemas agénticos introducen sobrecarga arquitectónica: gestión de memoria, orquestación de herramientas, manejo de errores y bucles de control que aumentan la latencia y el costo. Por ejemplo, en nuestros benchmarks, observamos que las tasas de éxito de los agentes de IA disminuyeron después de 35 minutos de interacción humana.
Para mitigar estos riesgos, es esencial probar los sistemas agénticos en entornos controlados e implementar barreras de protección sólidas antes del despliegue.
Los agentes son más valiosos cuando los pasos no se pueden predecir o codificar fácilmente. Son particularmente adecuados para situaciones en las que:
- Las tareas son dinámicas y de múltiples pasos, con lógica de ramificación o subobjetivos poco claros.
- El uso de herramientas es condicional o adaptativo, lo que requiere que el sistema elija qué herramienta invocar según la entrada o el estado anterior.
- Se requiere memoria a largo plazo o contexto, a través de sesiones o etapas de ejecución.
- La ejecución debe responder a la retroalimentación del entorno, como resultados de API, salidas de búsqueda o acciones fallidas.
- Se necesita colaboración con un humano en el bucle, donde la autonomía y la supervisión deben combinarse (por ejemplo, copilotos de IA).
Por otro lado, los flujos de trabajo o las llamadas sin estado a LLM son preferibles cuando:
- La lógica de la tarea es estática o predecible, como el llenado de formularios o la transformación de contenido.
- La baja latencia es crítica, como en interacciones orientadas al usuario.
- Minimizar el costo es esencial, especialmente evitando llamadas recursivas a LLM y una orquestación compleja.
Leer más
Aquí están nuestros últimos benchmarks sobre infraestructura comúnmente utilizada por sistemas agénticos:
- Navegadores remotos: Cómo la infraestructura de navegadores permite a los agentes interactuar con la web de forma segura.
- Benchmark de MCP para navegadores: Los mejores servidores MCP para uso de herramientas y acceso web.
Ejemplos de agentes de IA de código abierto
Algunas herramientas descritas como “agentes de IA” no son realmente tan agénticas; estos sistemas (por ejemplo, Devon PR-agent) son en gran medida flujos de trabajo de IA basados en RL, con LLMs organizados a través de rutas de código predefinidas.
1. Frameworks de agentes (Crea tu propio)
Bibliotecas modulares y SDKs para que los desarrolladores construyan agentes con control sobre la lógica, memoria, herramientas y orquestación.
✳️ Algunos agentes como SmolAgents y Agno encajan tanto en las categorías de frameworks de agentes como en automatización de flujos de trabajo.
Frameworks generales de agentes
Frameworks que se centran en construir agentes, ofreciendo herramientas flexibles y personalizables para orquestar flujos de trabajo, configuraciones de múltiples agentes y casos de uso de propósito general.
- LangGraph – Orquestación de flujos de trabajo basada en grafos de LLM – LangGraph es software propietario, pero proporciona una biblioteca de código abierto para el desarrollo de agentes. Ideal para pipelines de RAG, memoria del agente/ manejo de estado, y configuraciones de múltiples agentes.
- AutoGen – Colaboración asíncrona de múltiples agentes – Diseñado para coordinar agentes que usan herramientas a través de APIs similares a chat. Ideal para automatizar flujos de trabajo complejos, especialmente en generación autónoma de código.
- CrewAI – Framework multiagente sin código/de bajo código – Una de las herramientas más fáciles para comenzar, ofreciendo plantillas de agentes listas para usar (por ejemplo, agente de preparación de reuniones).
Frameworks de agentes especializados
Frameworks con un enfoque especializado en tipos específicos de comportamientos o integraciones de agentes.
- Camel – Simulación de agentes basada en roles – Optimizado para agentes colaborativos de juegos de rol utilizando razonamiento estructurado. Ideal para automatización de flujos de trabajo y generación de datos sintéticos.
- Mastra – Desarrollo de agentes integrado en el frontend – Basado en JavaScript, ideal para incrustar agentes en aplicaciones orientadas al usuario.
- PydanticAI – Control mínimo de agentes con seguridad de tipos – Proporciona validación estricta y rutas lógicas transparentes con Pydantic.
- Cybersecurity IA (CAI) – Framework de agentes de ciberseguridad impulsado por IA – Proporciona pruebas de penetración, descubrimiento de vulnerabilidades y red teaming con capacidades de humano en el bucle, aprovechando modelos de lenguaje grandes e integraciones con herramientas como Nmap.
- Atomic Agents – Constructor de agentes personalizados granular basado en esquemas – Construido para estructura de agente granular y lógica componible.
- SmolAgents – SDK de agente ligero para desarrolladores – Abstracción mínima, enruta la lógica a través de Python en lugar de JSON.
Runtimes de agentes (Agentes autónomos preconstruidos)
Agentes preconstruidos y autocontenidos que puede ejecutar inmediatamente (como una aplicación). Normalmente soportan la ejecución autónoma de tareas a partir de objetivos en lenguaje natural.
Totalmente autónomos:
- Auto-GPT – Descomposición de objetivos y ejecución autónoma – Descompone objetivos en subtareas y los completa utilizando herramientas, memoria y razonamiento. Ofrece agentes preconstruidos y una interfaz de bajo código.
- AIlice – Ejecución local de tareas de propósito general – Ejecuta tareas complejas en el dispositivo, admite herramientas locales y manipulación de archivos. Su objetivo es crear un asistente de IA, similar a JARVIS, basado en el LLM de código abierto.
- Manus IA – Operaciones aisladas de propósito general. Ejecuta herramientas y flujos de trabajo en un entorno aislado seguro, capaz de manejar operaciones de múltiples dominios y múltiples pasos de forma autónoma. Fue adquirido por Meta, integrándose al ecosistema de “Inteligencia Ambiental Personal” de Meta.5
Parcialmente autónomos:
- BabyAGI – Ejecutor de bucle de tareas iterativo – Crea, prioriza y ejecuta listas de tareas en un bucle de retroalimentación. Ideal para experimentos de generación de tareas.
Basados en navegador/interfaz:
- AgentGPT – Agente autónomo desplegado en el navegador – Permite a los usuarios crear y ejecutar agentes de tareas a través de una interfaz web. Ligero, ideal para experimentación.
- OpenManus – Agente persistente de navegador – Diseñado para flujos de trabajo que abarcan sesiones en entornos de navegador. Utiliza herramientas como Playwright para automatizar interacciones web. Bueno para usar en pipelines de automatización existentes. La configuración es rápida con Conda.
2. Automatización y orquestación de flujos de trabajo
Herramientas que automatizan flujos de trabajo e integran múltiples plataformas o servicios, a menudo con la capacidad de integrar agentes de IA.
Agentes generales de automatización e integración de flujos de trabajo
Plataformas que conectan APIs, desencadenan eventos y automatizan tareas, facilitando la construcción e integración de flujos de trabajo en diferentes sistemas.
- n8n – Automatización visual de flujos de trabajo e integración de APIs – Conecta aplicaciones, disparadores y flujos de datos mediante un editor de nodos. Combina la construcción visual sin código con JavaScript/Python personalizados y admite más de 400 integraciones. Puede autohospedarse, ejecutar flujos de trabajo de agentes de IA con LangChain. Ideal para personas técnicas.
- PlanExe – Herramienta de planificación de LLM a diagramas de Gantt/WBS – Planificador de IA similar a la investigación profunda de OpenAI. Convierte objetivos en lenguaje natural en líneas de tiempo estructuradas utilizando LlamaIndex.
- Agno ✳️ – Constructor de flujos de trabajo y agentes amigable para desarrolladores – Encaja tanto como una herramienta de automatización de flujos de trabajo (ayudando a automatizar tareas y flujos de trabajo) como un constructor de agentes.
- SmolAgents ✳️ – SDK de agente ligero para desarrolladores – SmolAgents es lo suficientemente flexible como para encajar tanto como un SDK de agente ligero (para frameworks de agentes) como una herramienta de flujo de trabajo (ya que se integra con modelos de Hugging Face).
- Windmill – Plataforma de desarrollo de código abierto y motor de flujos de trabajo – Convierte scripts en interfaces de usuario, APIs y trabajos cron; es compatible con Python, TypeScript, Go y otros lenguajes.
- Activepieces – Plataforma de automatización de código abierto – Constructor visual de flujos de trabajo autohospedado para automatizar tareas e integrar aplicaciones con mínima codificación. Es compatible con 280+ MCP servidores para ejecutar tareas distribuidas de IA y cadenas de agentes a escala.
- Huginn – Automatización web y gestión de agentes – Construye agentes para automatizar tareas basadas en la web y monitoreo.
- Node-RED – Desarrollo basado en flujos para IoT y datos en tiempo real – Integra servicios y automatiza tareas con un editor de flujos basado en navegador.
Orquestación de flujos de trabajo multiagente
Frameworks diseñados para coordinar agentes que interactúan a través de flujos de trabajo estructurados e integrar sistemas multiagente.
- HyperAgent – Orquestación de agentes para el ciclo de vida completo del software – Los agentes trabajan juntos para planificar, codificar y verificar tareas de ingeniería.
- Supercog – agentic – Orquestación modular con bloques de lógica reutilizables – Diseñado para una automatización escalable, estructurada y basada en equipos.
3. Automatización y navegación web
Los agentes navegan por sitios web de forma autónoma y realizan tareas de varios pasos, como el llenado de formularios, la extracción de datos y la automatización de la navegación web.
Agentes web autónomos y copilotos
Agentes autónomos de propósito general (capaces para la web):
- AgenticSeek – Agente de navegación web totalmente autónomo – Manus IA completamente local. Se especializa en extracción de datos y llenado de formularios, automatizando tareas basadas en la web.
- Agent-E – Agente de automatización de navegador consciente del DOM – Se enfoca en interactuar con páginas web analizando el DOM (Modelo de Objetos del Documento), ideal para hacer clic en botones y llenar formularios.
- AutoWebGLM – Agente web basado en LLM – Utiliza aprendizaje por refuerzo y simplificación de HTML para una mejor navegación en sitios web complejos.
Agentes de navegación web basados en visión (multimodales):
- Autogen extension WebSurfer – Agente web multimodal – Combina entrada de texto y visual (capturas de pantalla) para mejorar la interacción web.
- Skyvern – Agente de IA con visión por computadora – Automatiza flujos de trabajo utilizando LLMs y visión por computadora, manejando tanto elementos de texto como visuales.
- WebVoyager – Agente web con capacidad visual – Usa texto y capturas de pantalla para mejorar la navegación en sitios web con muchas imágenes.
Para más información sobre automatización y navegación web de código abierto, aquí hay una mirada estructurada a algunas de las principales herramientas y agentes:
Kits de herramientas de automatización y extracción web
LLM-powered web RPA and browser extensions
Extractores y rastreadores web de IA
Herramientas de búsqueda web de IA
4. Agentes de codificación y desarrollo
Agentes de IA diseñados para ayudar con tareas de codificación, proporcionando soporte en tiempo real a los desarrolladores a través de sugerencias de código, depuración y automatización de tareas.
Agentes de codificación basados en CLI
- Codex CLI – Herramienta de interacción multimodo (sugerir, editar, ejecutar) – Mejora los flujos de trabajo de los desarrolladores a través de la línea de comandos ofreciendo sugerencias y ediciones de código.
- OpenDevin – Asistente de codificación de IA de código abierto – Ayuda con tareas de programación, ofreciendo sugerencias de código para varios lenguajes. Nota: OpenDevin ha sido renombrado recientemente a OpenHands para reflejar su misión más amplia de “All Hands IA”.6
- Aider – Asistente de programación en pareja de IA – Integrado en su terminal para asistencia en codificación, compatible con autocompletado, depuración y automatización de tareas.
Editores de código con IA
- Neovim – Editor de código integrado con IA – Plugins impulsados por IA que proporcionan completado de código, refactorización.
- Visual Studio Code (VS Code) – Herramienta de completado de código y depuración impulsada por IA – Ofrece sugerencias de código y autocompletado a través de GitHub Copilot, integrado con entornos IDE para desarrolladores.
- Cursor – Editor de código integrado con IA – Construido con completado de código en tiempo real impulsado por IA.
Creadores de aplicaciones a partir de prompts (Vibe coding)
Alternativas de código abierto a v0 / lovable / Bolt:
- Dyad – Constructor de aplicaciones de IA de código abierto – Herramienta local primero, sin código, para construir aplicaciones impulsadas por IA con comandos en lenguaje natural.
- vx.dev – Constructor de aplicaciones de IA de código abierto – Una herramienta local primero, de bajo código, enfocada en transformar prompts en lenguaje natural en aplicaciones.
5. Agentes de ciberseguridad
Agentes de IA diseñados para mejorar las operaciones de ciberseguridad, incluyendo tareas como pruebas de penetración, descubrimiento de vulnerabilidades, red teaming y detección autónoma de amenazas.
- YAWNING TITAN – Simulación abstracta de ciberseguridad basada en grafos – Apoya el entrenamiento de agentes para operaciones cibernéticas autónomas con un enfoque en entornos basados en grafos.
- bumpgen – Agente de gestión de paquetes – Actualiza automáticamente paquetes npm (gestor de paquetes de Node.js).
- Agentes de ciberseguridad LLM – Tareas de ciberseguridad impulsadas por LLM – Construido sobre AutoGen. Utilizado en varias aplicaciones de investigación para demostrar automatización EDR con ChatGPT y CI/CD automatizado para ingeniería de detección.
6. Agentes de creación de contenido de video con IA
Agentes de IA que ayudan a generar, editar y mejorar contenido visual y multimedia, incluyendo arte, imágenes, y videos.
- Mochi – Generación de texto a video – Convierte prompts de texto en video, con un enfoque en la creación de videos de formato corto. Adecuado para generar rápidamente videos a partir de descripciones textuales.
- CogVideo – Generación de texto a video – Convierte prompts de texto en video con alta fidelidad, permitiendo la creación de imagen a video. Una herramienta más avanzada para la generación de video de alta calidad a partir de texto o imágenes.
- Allegro – Generación de texto a video – Convierte prompts de texto en video con un enfoque en la creación de contenido creativo. Esta herramienta enfatiza la síntesis creativa de video a partir de texto para producir narrativas visuales únicas.
- DALL·E (versiones de código abierto) – Generación de texto a video – Genera imágenes a partir de descripciones de texto, convirtiendo prompts escritos en contenido visual detallado y creativo.
7. Agentes financieros
Agentes de IA que ofrecen mejora automatizada del aprendizaje por refuerzo o análisis de datos financieros en tiempo real.
- FinRL – Aprendizaje por refuerzo automatizado para trading – Aprende y ejecuta estrategias de trading de forma autónoma basándose en datos de mercado, adaptándose a entornos financieros dinámicos.
- OpenBB Terminal – Análisis de datos financieros – Proporciona información financiera autónoma para trading en tiempo real, permitiendo a los profesionales de la inversión tomar decisiones informadas.
8. Agentes de salud
Agentes de IA que ayudan en diagnósticos médicos, monitoreo de enfermedades y perspectivas de salud mediante el análisis de datos de pacientes e informes médicos.
- HIA (Health Insights Agent) – Análisis de informes médicos – Analiza informes médicos y proporciona información de salud.
- IA-HealthCare-Assistant – Diagnóstico y monitoreo de enfermedades – Diagnostica y monitorea enfermedades utilizando datos de pacientes.
9. Agentes de investigación
Agentes de IA que ayudan en la recopilación de datos, revisiones de literatura y pruebas de hipótesis, agilizando el proceso de investigación.
- ChemCrow – Agente autónomo de investigación química – Integra LLMs con herramientas de química para planificar y ejecutar tareas experimentales y computacionales complejas en análisis químico.
- GPT Researcher – Asistente de investigación general autónomo – Realiza búsquedas estructuradas en línea, analiza contenido y elabora informes de investigación detallados con una mínima intervención del usuario.
10. Agentes de análisis de datos
Agentes de IA que procesan, analizan e interpretan datos para proporcionar información procesable y apoyar la toma de decisiones.
Finanzas
- FinRobot – Agente de análisis de datos financieros – Automatiza la interpretación y presentación de informes de datos financieros utilizando modelos de lenguaje grandes.
Agentes de inteligencia de negocios y consultas
- Wren IA – Agente de perspectivas empresariales de texto a SQL – Convierte preguntas en lenguaje natural en consultas SQL para informes empresariales.
- Entaoai – Herramienta de ingeniería de datos asistida por GenAI – Proporciona una interfaz de chat para tareas de consulta y transformación de datos.
- Vanna IA – Agente de lenguaje natural a SQL – Genera consultas SQL basadas en prompts del usuario para explorar conjuntos de datos estructurados.
Agentes de redes sociales
- Twitter Personality Agent – Agente de análisis de redes sociales – Analiza el historial de tweets para inferir rasgos de comportamiento y personalidad.
11. Agentes de asistencia personal
Agentes de IA que ayudan con la gestión de tareas, programación y organización personal, mejorando la productividad y la gestión del tiempo.
- VacAIgent (agente preconstruido de CrewAI) – Asistente de planificación de viajes –Genera automáticamente itinerarios completos de viaje utilizando Streamlit y LLMs.
- Inbox Zero – Asistente de correo electrónico – prioriza, clasifica y resume mensajes utilizando procesamiento de lenguaje natural e integración con Gmail.
- Cal – Agente de programación de calendario – Automatiza la creación, reprogramación y resumen de reuniones mediante interacción basada en LLM.
Construcción de sistemas de agentes de IA
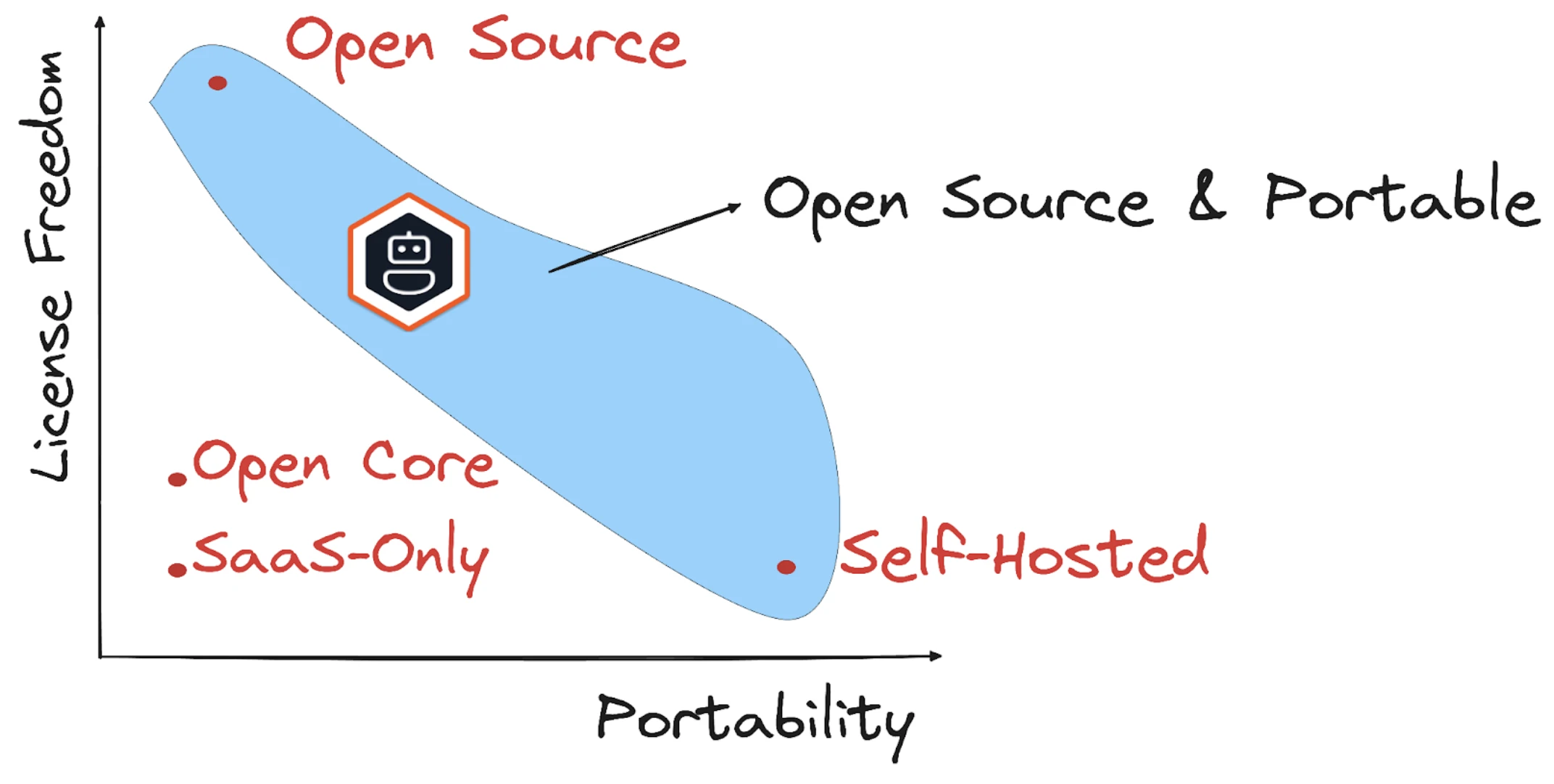
Muchos frameworks de IA están controlados por un solo proveedor o repositorios públicos, pero están estrictamente gobernados.
Estos proyectos a menudo cambian hacia modelos open core: el código base sigue siendo gratis, pero la orquestación multiagente, la observabilidad o el control detallado pueden estar limitados detrás de licencias comerciales. En algunos ecosistemas “abiertos”, el uso en producción a menudo requiere adoptar un backend cerrado.
Fuente7
Proyectos reales de agentes de IA
Desde nuestra experiencia, aquí hay algunos agentes de IA y sus aplicaciones:
- Editores de código con IA para desarrollo de API construyendo aplicaciones
- Ejecución de código a partir de capturas de pantalla para la generación de sitios web con IA
- Agentes de uso de computadora para pedir entregas, hacer una reserva en un restaurante o diseñar una habitación.
Otros proyectos independientes de agentes de IA:
Otros proyectos de agentes de IA por framework:
Lectura adicional
Cita esta investigación
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Los mejores más de 50 agentes de IA de código abierto listados}},
year = {2026},
month = may,
howpublished = {\url{https://aimultiple.com/open-source-ai-agents}},
note = {AIMultiple. Recuperado el 14 de Mayo de 2026}
}
Sé el primero en comentar
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.