Top 5 Extensões Gratuitas do Chrome para Web Scraping
Uma extensão de web scraper do Chrome permite que você colete dados como texto, tabelas, links, imagens e listas diretamente do seu navegador. Muitas extensões oferecem fluxos de trabalho sem código, detecção de campos impulsionada por IA, scraping agendado, exportações para Google Sheets e monitoramento de alterações de página.
Compare as extensões populares de web scraper do Chrome por suas capacidades principais, opções de exportação, facilidade de uso e recursos de monitoramento:
Comparação rápida das melhores extensões de scraper do Chrome
Provedor | Avaliação na Chrome Web Store | Exportações |
|---|---|---|
WebScraper.io | 4,1 de 1K avaliações | CSV, XLSX, CouchDB |
Thunderbit | 4,2 de 167 avaliações | CSV, Excel, Google Sheets, Notion, Airtable |
Data Miner | 3,9 de 701 avaliações | CSV, Excel, Google Sheets |
Simplescraper | 4,4 de 363 avaliações | CSV, JSON, Google Sheets, API |
Browse IA | 3,9 de 45 avaliações | CSV, Google Sheets, integrações |
Melhores extensões de web scraper gratuitas do Chrome
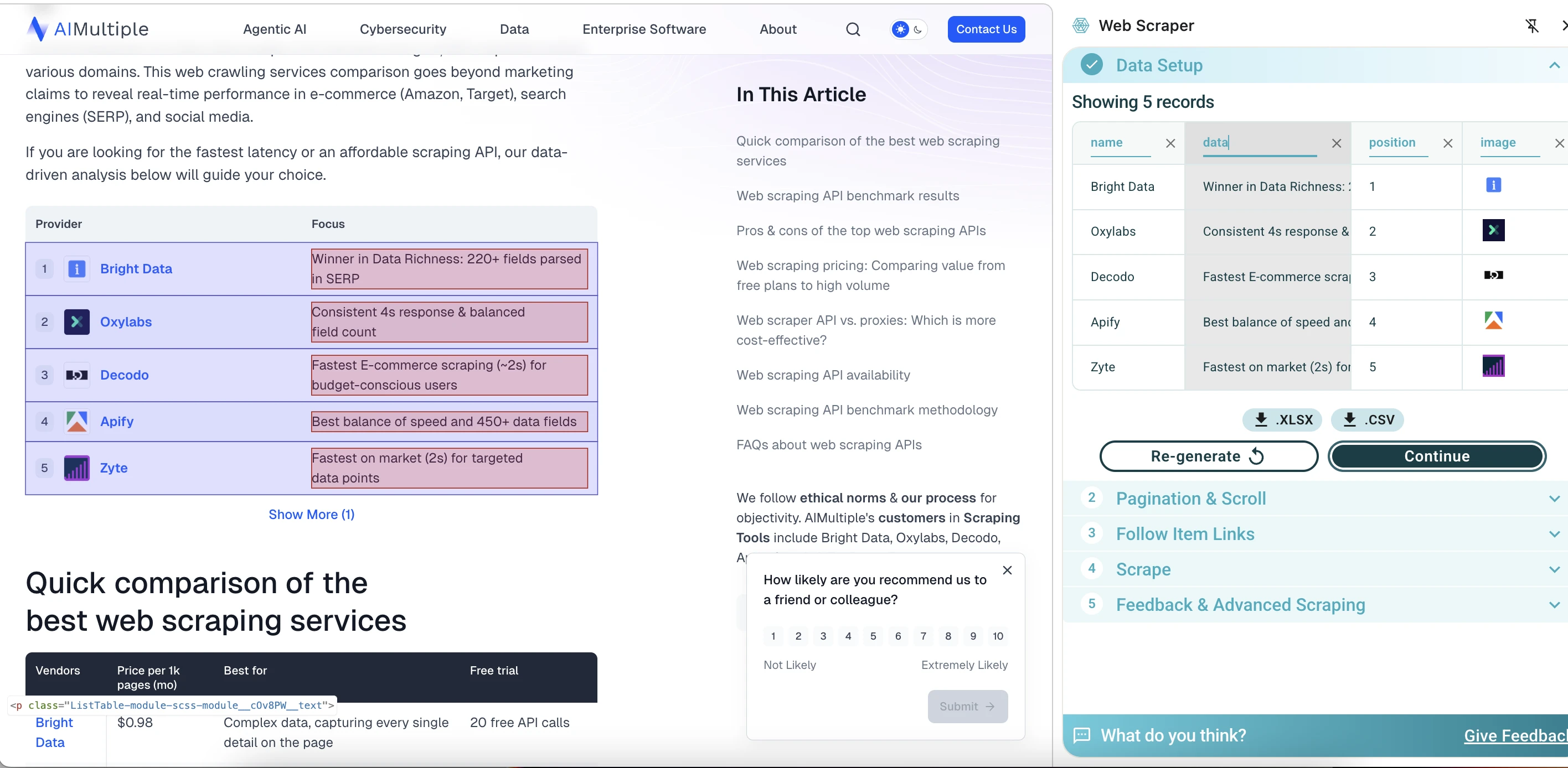
O WebScraper.io identificou rapidamente o primeiro elemento na página e exibiu uma prévia de 5 registros, extraindo campos como nome do provedor, descrição, posição, URL da imagem e URL da página de origem. Um detalhe útil é que os nomes das colunas são editáveis. Isso torna a saída mais fácil de limpar antes de exportar, em vez de corrigir tudo depois em uma planilha.
No entanto, ele não conseguiu carregar ou configurar o restante da página para um scraping maior. Para extração simples de tabelas, ele funcionou bem, oferecendo velocidade, uma interface visual e exportação fácil de dados. Neste teste, foi mais limitado ao fazer scraping de toda a página.
O fluxo de trabalho de extração rápida é simples o suficiente para tabelas simples, enquanto o fluxo de trabalho avançado de sitemap dá aos usuários mais controle. No entanto, o modo avançado requer uma compreensão de conceitos como URLs de início, seletores, múltiplos elementos, árvores de seletores pai-filho e atrasos de scraping.
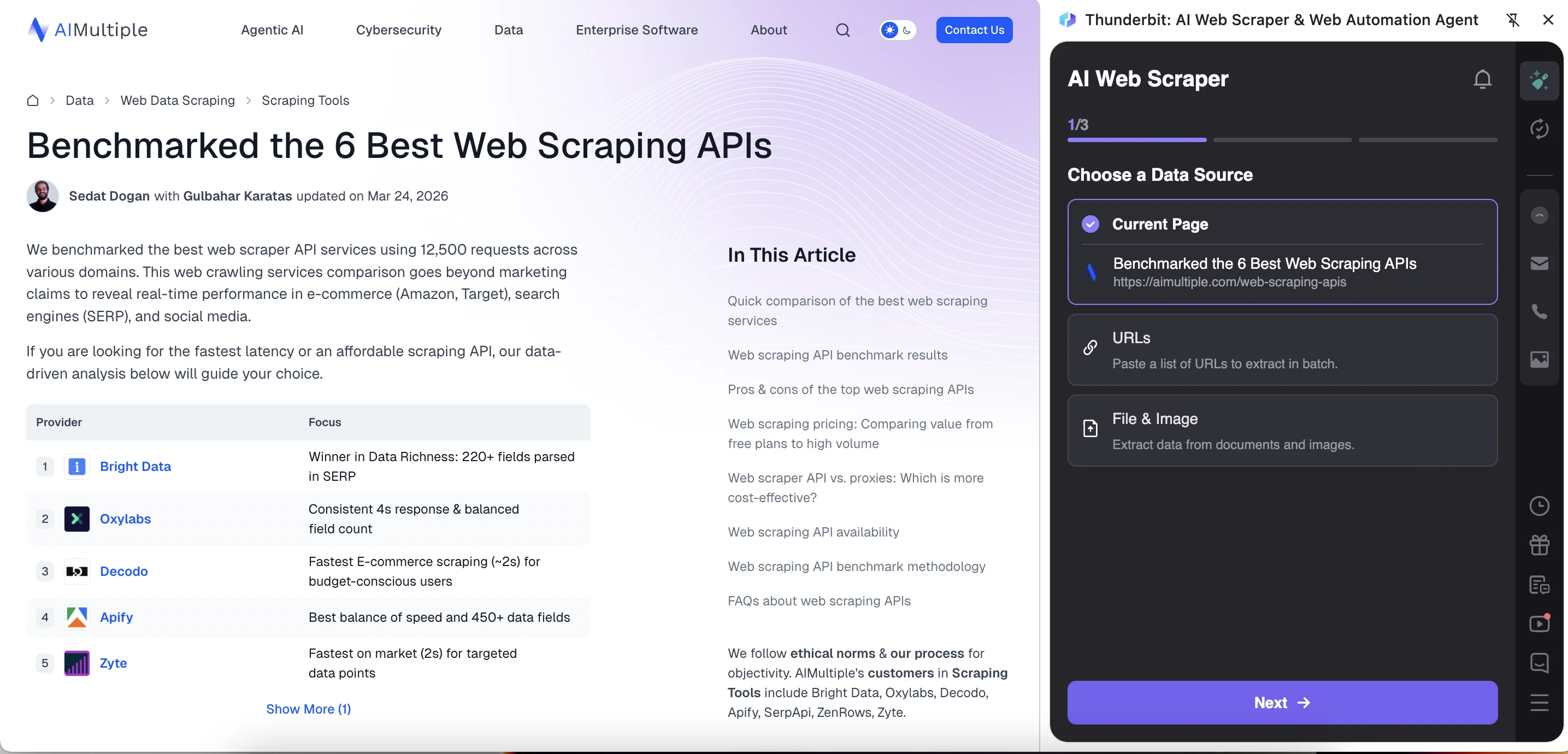
O Thunderbit tem uma interface mais guiada e orientada para IA. Ele começa pedindo ao usuário para escolher uma fonte de dados: Página Atual, URLs ou Arquivo & Imagem. O Thunderbit extraiu mais tipos de informações da página do artigo do que o WebScraper.io. No entanto, a saída não foi perfeitamente estruturada porque campos de artigo repetidos apareciam ao lado de cada linha de provedor.
O Thunderbit cria ou permite que você crie um modelo com campos predefinidos. A ferramenta criou automaticamente um modelo para o artigo e sugeriu campos como título do artigo, URL, autor, data de publicação e conteúdo. O modelo também é editável, para que os usuários possam remover campos irrelevantes, adicionar novos ou usar “IA Improve Fields” para refinar a configuração de extração antes de executar o scraper.
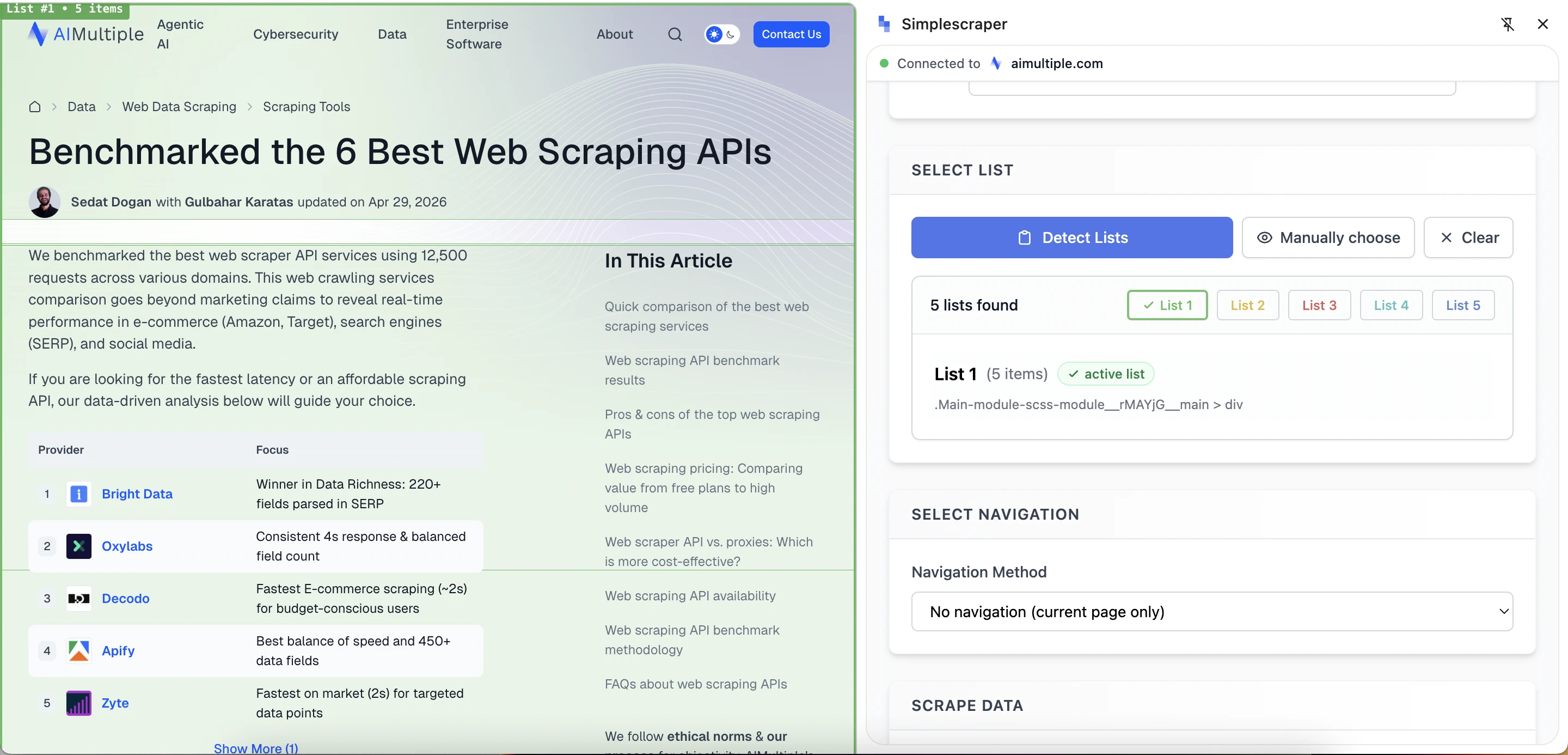
O Simplescraper parece mais moderno e amigável ao usuário do que o WebScraper.io e o Data Miner. A ferramenta oferece dois modos de scraping:
- Scrape lists: Para dados repetidos, como produtos, artigos, resultados de pesquisa ou linhas de tabela.
- Scrape details: Para campos específicos de uma única página.
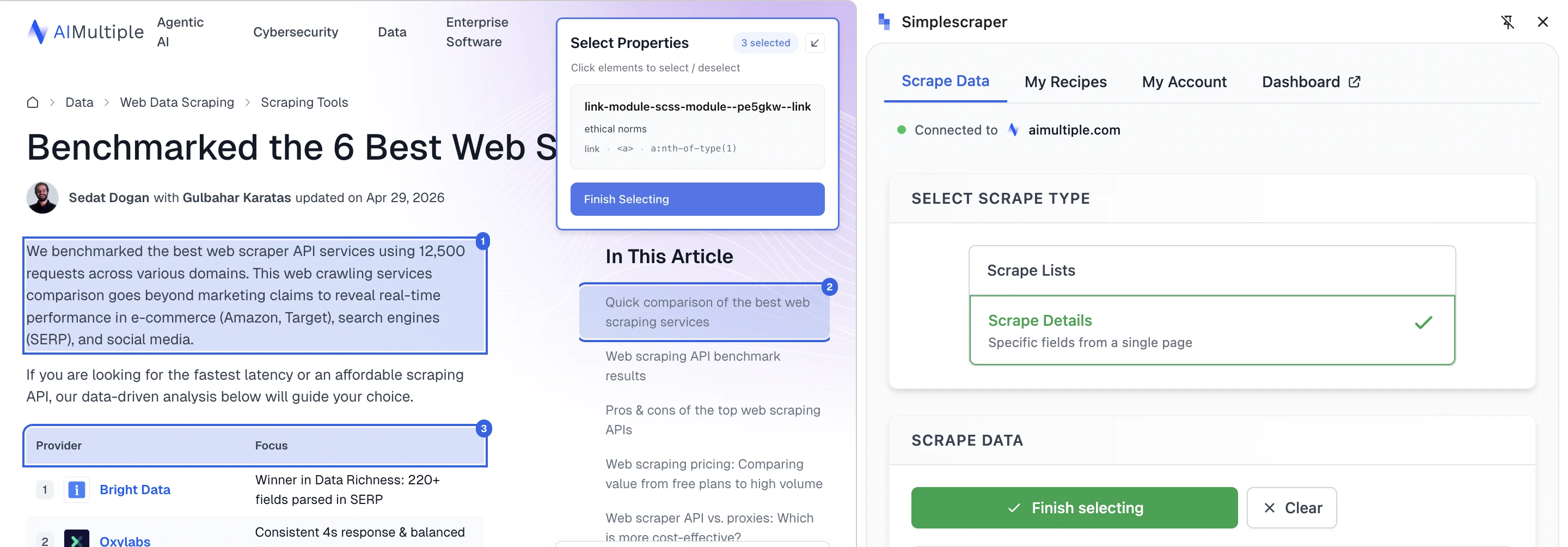
O recurso de detecção de lista analisa a página em busca de listas potenciais, destaca cada uma e as rotula. O Simplescraper também fornece uma opção de seleção manual, permitindo que os usuários cliquem diretamente nos elementos da página.
Recursos de navegação como próxima página, rolagem infinita ou carregar mais exigem uma conta paga. Para usuários testando a extensão gratuita, o Simplescraper é principalmente útil para fazer scraping da página atual. A saída é útil, embora alguns campos detectados possam ser pouco claros devido a nomes de colunas abreviados ou conteúdo misturado. A detecção automática de lista identifica estruturas repetidas, mas os usuários podem precisar selecionar a lista correta e refinar os campos.
Recurso de detecção automática de lista:
Detecção manual de campos específicos da página:
A extensão de extração de dados do Browse IA tem dois recursos principais: ela pode extrair dados de uma página da web e monitorar alterações nela ao longo do tempo. A ferramenta oferece as seguintes capacidades:
Capture list extrai dados organizados selecionando itens repetidos em uma página, como linhas de tabela ou cartões de lista, e os transforma em uma tabela ou planilha baixável.
Capture text monitora texto ou imagens específicos selecionando os elementos que você deseja rastrear. O Browse IA verificará automaticamente esses elementos toda vez que for executado. Você pode escolher o número de linhas para extrair, como 10 ou 100, ou qualquer outra quantidade preferida. O sistema então solicitará que você selecione um tipo de paginação, o que é útil para navegar em listas que abrangem várias páginas ou exigem opções como “Mostrar Mais”.
Capture screenshot fornece opções para tirar capturas de tela visuais. Você pode capturar uma área selecionada, toda a página ou a parte visível da sua tela. Após capturar uma captura de tela ou selecionar um elemento da página, o Browse IA permite que você configure um cronograma de monitoramento e regras de alerta de alteração. Por exemplo, você pode definir o limite de sensibilidade para uma pequena alteração (1%), o que significa que você pode ser notificado mesmo quando uma pequena parte da captura de tela capturada mudar.
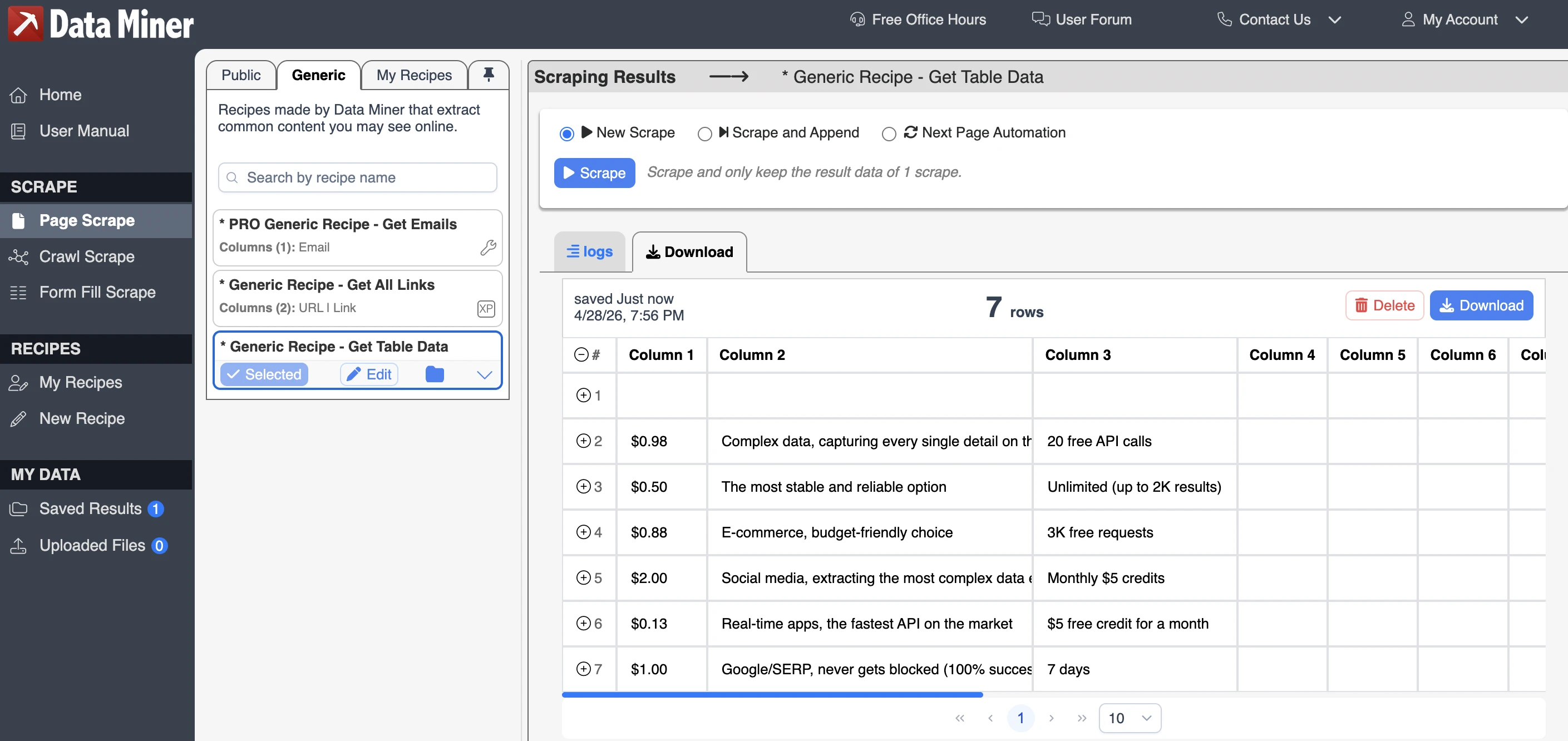
Data Miner
O Data Miner exige que os usuários se cadastrem ou façam login antes de usar a extensão. O plano gratuito inclui 500 scrapings de página por mês, acesso a scripts específicos de site existentes, scraping de várias páginas e exportações para arquivos CSV ou XLS.
O Data Miner usa um sistema de scraping baseado em receita. Uma receita é um modelo de extração de dados predefinido que diz à extensão quais partes de uma página da web extrair. Em vez de selecionar manualmente cada campo a cada vez, os usuários podem executar uma receita existente, criar a sua própria ou usar uma receita pública compartilhada por outros usuários.
A saída não foi perfeitamente estruturada para obter dados de tabelas. Ele perdeu a coluna vendor-name, usou nomes de colunas genéricos como “Column 1” e “Column 2”. Os valores raspados foram na maioria precisos, mas o resultado exigiu limpeza manual antes de poder ser usado como um conjunto de dados limpo.
Perguntas frequentes
Uma extensão de web scraper do Chrome extrai dados de páginas da web e exporta dados raspados como um arquivo CSV ou XLSX em um formato estruturado. Você pode selecionar texto, tabelas, links, imagens ou listas e exportá-los. Muitas extensões não exigem codificação.
Não. A maioria das extensões de scraping do Chrome funciona sem codificação, oferecendo uma interface de clique e apontar. Instale a extensão, abra uma página da web, selecione os dados e exporte-os. Para páginas complexas, use seletores ou regras personalizadas.
Um web scraper do Chrome pode extrair nomes de produtos, preços, links, imagens, avaliações, tabelas, resultados de pesquisa, listagens de empresas, ofertas de emprego, títulos de artigos e entradas de diretório. Algumas ferramentas podem extrair dados de várias páginas ou listas de URLs.
Sim. Muitas extensões de scraper de dados podem processar páginas com botões de próxima página ou carregar mais, e listas de URLs. Você pode coletar dados de catálogos, resultados de pesquisa, diretórios ou tabelas em várias páginas. Um scraper de navegador é executado no seu navegador para scraping local.
Uma extensão de scraper do Chrome geralmente é executada dentro do seu navegador e é útil para scraping rápido, visual e local. Um web scraper cloud é executado em servidores remotos e é mais adequado para trabalhos agendados, raspagens maiores, automação e scraping quando seu computador está offline.
Cite esta pesquisa
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{karatas2026,
author = {Karatas, Gulbahar},
title = {{Top 5 Extensões Gratuitas do Chrome para Web Scraping}},
year = {2026},
month = apr,
howpublished = {\url{https://aimultiple.com/web-scraper-chrome-extension}},
note = {AIMultiple. Acessado em 30 Abril 2026}
}




Seja o primeiro a comentar
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.