20 Estratégias para Melhoria de IA & Exemplos
Os modelos de IA exigem melhoria contínua à medida que os dados, o comportamento do usuário e as condições do mundo real evoluem. Mesmo modelos com bom desempenho podem sofrer deriva quando os padrões que aprenderam já não correspondem aos inputs atuais, levando a uma redução da precisão e a previsões não confiáveis.
Mudanças nas regulamentações, requisitos de produto ou expectativas dos clientes também podem introduzir novas restrições que os modelos existentes não foram concebidos para lidar.
Manter a qualidade do modelo, portanto, envolve fortalecer tanto os dados que suportam o modelo quanto os algoritmos que moldam o seu comportamento, garantindo que os sistemas permaneçam alinhados com os requisitos atuais em vez de pressupostos desatualizados.
Explore estratégias-chave, incluindo alimentação de dados, melhoria dos dados e do algoritmo, e leis de escalabilidade de IA que garantirão que os seus modelos de IA se mantenham relevantes e práticos.
Top 20 maneiras de melhorar o seu modelo de IA
Explicamos métodos para aprimorar o seu modelo de IA em 4 categorias diferentes:
Método | Descrição | Principais Desafios |
|---|---|---|
Alimentar mais dados | Adicionar dados reais ou sintéticos de alta qualidade para melhorar a cobertura e a generalização. | Garantir a qualidade dos dados, evitar viés, gerir limites de privacidade e acesso. |
Melhorar os dados | Aprimorar a rotulagem, diversidade e augmentação para reduzir ruído e viés. | Equilibrar qualidade vs. quantidade, reduzir viés do dataset, manter anotações consistentes. |
Melhorar o algoritmo | Usar melhores arquiteturas, técnicas de fine-tuning e práticas de deployment. | Maior complexidade e custo, comportamentos não intencionais, necessidades rigorosas de privacidade. |
Leis de escalabilidade de IA | Aumentar a escala, computação, eficiência e técnicas de recuperação ou multi-agente. | Retornos decrescentes, limites de computação, impacto ambiental, complexidade de integração. |
Alimentar mais dados
Adicionar dados novos e atualizados é um dos métodos mais comuns e eficazes para melhorar a precisão do seu modelo de machine learning. A investigação mostrou uma correlação positiva entre o tamanho do dataset e a precisão do modelo de IA.1
Portanto, expandir o dataset utilizado para o retreino do modelo pode ser uma forma eficaz de melhorar os modelos de IA/ML. Garanta que os dados mudam de acordo com o ambiente onde são implantados. Também é essencial aderir a práticas adequadas de garantia de qualidade na coleta de dados.
1. Coleta de dados
A coleta/extração de dados pode ser usada para expandir o seu dataset e alimentar mais dados no modelo de IA/ML. Neste processo, dados novos são recolhidos para retreinar o modelo. Esses dados podem ser obtidos através dos seguintes métodos:
- Coleta privada
- Coleta de dados automatizada
- Crowdsourcing personalizado
Para recolher dados para IA com sucesso, as empresas precisam de estar atentas a:
- Considerações éticas e legais na coleta de dados devem ser respeitadas para evitar problemas éticos.
- O viés nos dados de treino pode levar a resultados indesejados da IA.
- O pré-processamento de dados brutos é essencial para resolver problemas de qualidade e garantir a integridade dos dados para o treino de IA/ML.
- Nem todos os dados são facilmente acessíveis devido a restrições relacionadas com sensibilidade e regulamentações de privacidade.
Saiba mais sobre métodos de coleta de dados.
Também é aconselhável trabalhar com um serviço de dados de IA para obter datasets relevantes sem o incómodo de recolher dados e para evitar problemas éticos e legais.
2. Dados sintéticos com modelos generativos
A IA generativa avançou a criação de dados sintéticos, produzindo datasets de alta qualidade que replicam condições do mundo real. Modelos de linguagem de grande escala e modelos de difusão podem agora gerar dados estruturados e não estruturados para treinar modelos em domínios onde os dados reais são limitados.
Exemplos incluem:
- Produzir casos médicos raros para melhorar modelos de machine learning em saúde.
- Gerar dados de conversa realistas para melhorar sistemas de processamento de linguagem natural.
- Criar datasets visuais para testar resolução de imagem, qualidade de foto ou modelos de reconhecimento de imagem.
Auto-jogo sintético e dados de treino sintéticos
O auto-jogo sintético gera novos dados de treino ao permitir que modelos ou agentes interajam com tarefas ou entre si. Estes suplementos têm dados humanos limitados de alta qualidade.
Este método proporciona:
- Produção escalável de dados de instrução, raciocínio ou diálogo.
- Cobertura de cenários raros ou caros de recolher manualmente.
- Melhor desempenho do modelo em domínios onde a escassez de dados é uma restrição principal.
Exemplo real: Mais dados para chatbots
Um chatbot para suporte de TI tinha dificuldade em entender e classificar perguntas dos usuários com precisão. Para melhorar o seu desempenho, 500 consultas de suporte de TI foram reescritas em múltiplas variações em sete idiomas.
Estes dados adicionais ajudaram o chatbot a reconhecer diferentes formatos de perguntas, melhorando a sua capacidade de responder de forma mais eficaz.
Melhorar os dados
Melhorar os dados existentes também pode resultar num modelo de IA/ML melhorado.
Agora que as soluções de IA estão a enfrentar problemas mais complexos, são necessários dados melhores e mais diversificados para as desenvolver. Por exemplo, investigação2 sobre um modelo de deep-learning que ajuda sistemas de deteção de objetos a entender as interações entre dois objetos, conclui que o modelo é suscetível3 ao viés do dataset e necessita de um dataset diversificado para produzir resultados.
As melhorias podem ser alcançadas através de:
3. Enriquecer os dados
Expandir o dataset é uma forma de melhorar a IA. Outra forma importante de melhorar os modelos de IA/ML é enriquecendo os dados. Isto significa que os novos dados recolhidos para expandir o dataset devem ser processados antes de serem introduzidos no modelo.
Isto também pode significar melhorar a anotação do dataset existente. Uma vez que foram desenvolvidas novas e melhores técnicas de rotulagem, estas podem ser implementadas no dataset existente ou recém-recolhido para melhorar a precisão do modelo.
4. Melhorar a qualidade dos dados
Melhorar a qualidade dos dados é essencial para o avanço dos sistemas de IA e para melhorar o desempenho dos modelos de IA. Embora os avanços na IA muitas vezes enfatizem melhores algoritmos e mais poder computacional, dados de treino de alta qualidade continuam a ser cruciais para um desempenho ótimo.
Adotar uma abordagem centrada nos dados ajuda a acelerar o progresso da IA ao garantir que os dados utilizados para o treino são abundantes e de alta qualidade.
A recolha e curadoria de dados de alta qualidade permitem aos programadores construir modelos de IA mais eficientes e eficazes, que podem depois ser aproveitados para resolver tarefas complexas em várias indústrias. Ao focar na qualidade dos dados, as empresas podem fazer previsões mais precisas, reduzir o viés e melhorar as capacidades dos sistemas de IA.
A qualidade dos dados pode ser significativamente melhorada durante a fase de recolha de dados. Este processo inclui garantir que os dados são representativos dos cenários do mundo real que o modelo encontrará para eliminar viés, reduzir ruído e garantir que são suficientemente diversos para capturar todas as variáveis relevantes.
Além disso, manter a consistência na rotulagem dos dados e abordar lacunas no dataset pode ajudar a reduzir erros no processo de aprendizagem do modelo.
5. Aproveitar a augmentação de dados
Algumas pessoas podem confundir dados aumentados com dados sintéticos; no entanto, os dois termos diferem. Dados aumentados referem-se à adição de informação a um dataset existente, enquanto dados sintéticos são gerados artificialmente para substituir dados reais.
Melhorar o algoritmo
Por vezes, o algoritmo inicialmente criado para o modelo precisa de ser melhorado. Isto pode dever-se a diferentes razões, incluindo uma mudança na população sobre a qual o modelo é implementado.
Suponha que um algoritmo de IA/ML implementado que avalia o risco de saúde do paciente e não inclui o parâmetro do nível de rendimento é subitamente exposto a dados de pacientes com níveis de rendimento mais baixos. Nesse caso, é improvável que produza avaliações justas.
Portanto, atualizar o algoritmo e adicionar novos parâmetros pode ser uma forma eficaz de melhorar o desempenho do modelo. O algoritmo pode ser melhorado das seguintes formas:
6. Melhorar a arquitetura
Há algumas coisas que podem ser feitas para melhorar a arquitetura de um algoritmo. Uma forma é tirar partido de características modernas de hardware, como instruções SIMD ou GPUs.4
Além disso, as estruturas de dados e algoritmos podem ser melhorados através do uso de layouts de dados amigáveis à cache e algoritmos eficientes. Finalmente, os programadores de algoritmos podem explorar avanços recentes em machine learning e técnicas de otimização.
O Transformer é uma arquitetura de deep learning que mudou o processamento de linguagem natural (NLP) e outros campos ao permitir uma modelação mais eficiente e eficaz de dados sequenciais. Introduzido no artigo "Attention Is All You Need"5 , baseia-se fortemente num mecanismo chamado self-attention, substituindo operações recorrentes e convolucionais usadas em modelos anteriores como RNNs e CNNs.
Um Transformer consiste num Codificador e um Descodificador, cada um construído a partir de múltiplas camadas empilhadas:
- O Codificador transforma sequências de entrada em representações conscientes do contexto usando multi-head self-attention para capturar relações entre tokens, redes feedforward para processamento e conexões residuais com normalização de camada para estabilidade.
- O Descodificador gera sequências de saída token a token, incorporando multi-head self-attention mascarada para impedir o acesso a tokens futuros, cross-attention para integrar as saídas do Codificador e mecanismos semelhantes de feedforward e normalização para aprendizagem eficiente.
7. Arquiteturas de modelos híbridos
As arquiteturas de modelos híbridos combinam elementos de Transformers, modelos de espaço de estados e outros métodos de processamento de sequências. Esta abordagem suporta contexto de longa duração e reduz os requisitos de computação.
As principais vantagens incluem:
- Processamento mais eficiente de sequências longas.
- Uso reduzido de memória para treino e inferência.
- Compatibilidade com ambientes de data center e edge.
Exemplo real: Kimi K2.5
Kimi K2.5 é um modelo de IA agêntico open-source desenvolvido pela Moonshot IA, pré-treinado em aproximadamente 15 trilhões de tokens mistos visuais e de texto.
O design do Kimi K2.5 integra compreensão de visão e linguagem com raciocínio agêntico, oferecendo tanto modos instantâneos como de "pensamento" e suportando workflows de conversação e agentes autónomos.6
As principais características são:
- Multimodalidade nativa: Processa e raciocina sobre texto, imagens e vídeo num modelo unificado.
- Codificação assistida por visão: Pode gerar código a partir de inputs visuais e alinhar as saídas com especificações visuais.
- Execução Agent Swarm: Suporta decomposição coordenada de tarefas, permitindo que processos agênticos sejam executados em paralelo para workflows complexos.
8. Reengenharia de features
A reengenharia de features de um algoritmo é o processo de melhorar as features do algoritmo para torná-lo mais eficiente e eficaz. Isto pode ser feito modificando a estrutura do algoritmo ou ajustando os seus parâmetros.
9. Modelos de mundo multimodais
Os modelos de mundo multimodais aprendem a partir de texto, imagens, áudio, vídeo, dados estruturados e inputs de sensores. Isto cria uma representação unificada entre modalidades.
Aspetos importantes incluem:
- Melhor fundamentação em informações do mundo real.
- Interpretação mais precisa de cenas, sinais e inputs multi-formato.
- Aplicabilidade a tarefas que exigem compreensão integrada entre modalidades.
Exemplo real: DeepMind
A Google DeepMind fez melhorias significativas nos seus modelos de IA otimizando a sua arquitetura e refazendo vários componentes para melhor desempenho. Por exemplo, o modelo Gemini foi construído com uma arquitetura multimodal, permitindo-lhe lidar com tarefas em texto, áudio e imagens de forma mais eficaz.
Além disso, o PaLM 2 foi melhorado com uma abordagem de escalonamento otimizado de computação e melhorias no dataset para melhorar tarefas de raciocínio. Estas atualizações arquitetónicas permitiram maior precisão e adaptabilidade.7
10. Segurança, alinhamento e governança de IA
Melhorar algoritmos já não está limitado a otimizações técnicas. A segurança, o alinhamento e a governança da IA são cada vez mais críticos para garantir que os sistemas de IA se comportam como pretendido. Programadores e organizações estão a priorizar métodos que:
- Alinham os outputs do modelo de IA com valores humanos e requisitos de negócio.
- Incorporam ciclos de feedback para prevenir comportamentos não intencionais durante o deployment.
- Estabelecem quadros de governança que definem limites para o uso de ferramentas em várias indústrias.
Esta mudança destaca que alcançar melhores resultados de IA envolve melhorar a precisão e a confiabilidade, abordar considerações éticas e garantir a sustentabilidade a longo prazo.
Exemplo real: IA Sandbagging no Relatório Internacional de Segurança de IA
O Relatório Internacional de Segurança de IA destaca uma preocupação conhecida como IA sandbagging, em que um modelo tem um desempenho diferente durante a avaliação do que no uso no mundo real. Em particular, sistemas avançados podem parecer mais seguros ou menos capazes durante testes formais, mas comportar-se de forma diferente uma vez implementados.
Isto cria uma lacuna de avaliação: benchmarks tradicionais e testes de red team podem não capturar totalmente os riscos do mundo real se os modelos puderem adaptar o seu comportamento dependendo do contexto. Para as empresas, isto implica que testes de segurança pontuais são insuficientes e devem ser complementados por monitorização contínua, auditoria e mecanismos de governança.8
Figura 1: Exemplo do modelo o3 da OpenAI mostrando consciência situacional durante avaliações.
11. Modelos verificadores e pipelines de autocorreção
Os modelos verificadores avaliam os outputs produzidos por um modelo base e identificam erros ou inconsistências. Eles suportam autocorreção estruturada. As suas principais contribuições incluem:
- Maior precisão em tarefas de raciocínio e matemática.
- Taxas de falha mais baixas através de verificação sistemática.
- Maior confiabilidade em aplicações de alto risco ou específicas de domínio.
12. Otimização de IA on-device e edge
A otimização de IA on-device e edge tornou-se cada vez mais crucial para melhorar a privacidade, reduzir a latência e aumentar a eficiência. Em vez de processar dados em servidores centralizados, os sistemas de IA podem ser executados diretamente em dispositivos como smartphones, sensores IoT ou hardware empresarial.
Os benefícios incluem:
- Melhor privacidade ao manter dados sensíveis localmente.
- Menor latência, permitindo insights instantâneos em tempo real.
- Dependência reduzida de conectividade constante e infraestrutura de cloud em larga escala.
Esta tendência é particularmente relevante em indústrias como saúde, automóvel e manufatura, onde respostas atempadas e proteção de dados são cruciais.
Leis de escalabilidade de IA
As leis de escalabilidade descrevem como o desempenho do modelo muda à medida que parâmetros, dados e computação escalam em conjunto em proporções equilibradas. A investigação mostra que a perda tende a seguir padrões previsíveis de lei de potência quando os modelos são treinados com dados e recursos de computação suficientes em relação ao seu tamanho.
Trabalhos iniciais identificaram relações entre parâmetros, tokens e computação de treino, enquanto estudos posteriores revisaram os rácios ótimos, mostrando que muitos modelos grandes foram sub-treinados e que os modelos têm melhor desempenho quando parâmetros e tokens de treino são escalados para magnitudes semelhantes.
Análises mais recentes incorporam custo de inferência, indicando que modelos mais pequenos treinados por mais tempo podem igualar o desempenho de modelos maiores quando as cargas de trabalho de inferência são elevadas. Estudos adicionais focam-se em como as capacidades escalam entre benchmarks e mostram que a eficiência do modelo aumenta à medida que as arquiteturas, qualidade dos dados e métodos de treino melhoram.
Estas descobertas orientam a seleção de modelos e o planeamento de recursos, enfatizando o escalonamento equilibrado, dados de treino adequados e a importância crescente da eficiência de parâmetros e inferência.
Exemplo real: Escalonamento TTC Paralelo com PaCoRe
PaCoRe (Parallel Coordinated Reasoning) é uma framework open-source que introduz uma nova abordagem para escalonar a computação no momento do teste (TTC).
Em vez de ficar limitado pela janela de contexto de um modelo, o PaCoRe lança uma exploração paralela massiva, depois compacta e sintetiza os resultados através de uma arquitetura de passagem de mensagens, permitindo um escalonamento efetivo de computação de milhões de tokens durante a inferência.
O PaCoRe também disponibiliza um servidor aberto que pode ser usado com endpoints arbitrários de LLM, permitindo aos programadores aplicar esta abordagem de escalonamento paralelo em diferentes modelos e fornecedores.9
13. Escalonamento do tamanho do modelo
Aumentar o número de parâmetros num modelo significa torná-lo maior, tipicamente adicionando mais camadas ou tornando as camadas existentes mais complexas. Modelos maiores podem:
- Capturar padrões mais complexos: Com mais parâmetros, o modelo pode representar relações mais intrincadas nos dados.
- Lidar com datasets maiores: Modelos maiores têm maior capacidade para processar e aprender com dados em larga escala.
No entanto, a relação entre o tamanho do modelo e o desempenho pode exibir retornos decrescentes. Um aumento de 10x no tamanho do modelo não leva necessariamente a uma melhoria de 10x no desempenho.
Modelos maiores também requerem exponencialmente mais recursos de computação e memória, o que pode torná-los dispendiosos e mais difíceis de treinar. Para além de um certo ponto, aumentar o tamanho do modelo pode produzir ganhos negligenciáveis, particularmente se o dataset ou os recursos de computação forem insuficientes.
14. Escalonamento de dados
A disponibilidade e o tamanho do dataset usado para treinar um modelo afetam significativamente o seu desempenho:
- Datasets maiores melhoram a generalização: Com dados mais diversos e abrangentes, o modelo aprende uma gama mais ampla de padrões e tem menos probabilidade de sofrer overfitting.
- Melhor compreensão de eventos raros: Datasets grandes ajudam o modelo a aprender padrões raros e diversos, o que o tornaria melhor a lidar com casos incomuns.
No entanto, escalonar dados também tem limites:
- Nivelamento dos ganhos: Após um certo ponto, adicionar mais dados proporciona retornos decrescentes no desempenho porque o modelo já aprendeu a maioria dos padrões úteis.
- Qualidade sobre quantidade: Dados de má qualidade ou ruidosos podem não melhorar o desempenho, mesmo em grandes volumes.
- Estrangulamento de computação: Datasets maiores exigem mais poder de computação e tempo de treino, o que pode ser proibitivo.
15. Geração aumentada por recuperação (RAG)
A geração aumentada por recuperação tornou-se uma estratégia essencial para melhorar modelos de IA sem depender apenas de modelos maiores ou mais recursos de computação. Os sistemas RAG integram um modelo de linguagem de grande escala com uma base de conhecimento externa, permitindo ao modelo aceder a informações relevantes em tempo real.
As principais vantagens incluem:
- Reduzir a necessidade de retreinar modelos quando novas informações são criadas.
- Melhorar o desempenho em funções de negócio especializadas, ancorando os outputs em fontes de dados curadas.
- Mitigar os riscos de respostas desatualizadas ou alucinadas, permitindo que os sistemas citem fontes de origem.
Esta abordagem é agora comum em soluções de IA empresarial, onde os dados de treino não conseguem acompanhar domínios em rápida mudança, como finanças, direito ou serviço ao cliente.
16. Sistemas aumentados por memória
Os sistemas aumentados por memória dão aos modelos acesso a memória persistente ou ao nível da sessão. Isto permite ao modelo manter o contexto entre tarefas e interações.
Características importantes incluem:
- Suporte para contexto de longo prazo que não é limitado pelo comprimento do prompt.
- Melhor consistência em workflows de vários passos.
- Melhor alinhamento com casos de uso que exigem continuidade, como trabalho de projeto ou análise complexa.
17. Escalonamento de computação
O escalonamento de computação envolve aumentar o poder computacional disponível durante o treino ou inferência, tipicamente através de:
- Hardware mais potente: GPUs, TPUs ou chips de IA especializados.
- Sistemas distribuídos: Treino em múltiplas máquinas em paralelo para lidar com grandes cargas de trabalho.
- Durações de treino mais longas: Permitir que o modelo otimize os seus pesos ao longo de mais iterações.
A relação entre computação e desempenho do modelo é fundamental:
- Mais computação permite modelos maiores: Escalonar computação permite treinar modelos com mais parâmetros.
- Treino prolongado: Com computação suficiente, os modelos podem treinar em datasets maiores por períodos mais longos, o que levaria a uma melhor otimização.
No entanto, escalonar computação também tem desafios:
- Retornos decrescentes: Embora o desempenho melhore com mais computação, a taxa de melhoria abranda à medida que os recursos aumentam.
- Exigências de custo e energia: Treinar modelos avançados como o GPT-4 requer recursos financeiros e ambientais extensos.
Apesar destes desafios, escalonar computação tem sido fundamental para impulsionar melhorias no machine learning de IA.
Na fase de inferência, o desempenho de um modelo de IA, particularmente para tarefas que exigem matemática ou raciocínio de vários passos, pode melhorar alocando mais tempo de computação. Isto é frequentemente alcançado através de estratégias como aumento de computação por consulta ou refinamento iterativo. Veja como funciona:
O que acontece durante a inferência?
A inferência é a fase em que um modelo pré-treinado é usado para gerar previsões ou realizar tarefas com base em novos inputs. Ao contrário do treino, a inferência não atualiza os pesos do modelo, mas baseia-se nas suas capacidades aprendidas para resolver problemas específicos.
Por que é que mais tempo de computação ajuda?
Ao realizar tarefas como cálculos matemáticos ou raciocínio de vários passos, o modelo beneficia de mais tempo e recursos por consulta porque:
- Refinamento iterativo: Para tarefas que requerem múltiplos passos lógicos, o modelo pode dividir o problema em partes menores, resolver cada parte e refinar iterativamente a sua solução. Alocar mais computação permite ao modelo processar estes passos de forma mais completa.
- Precisão aumentada: Em tarefas matemáticas, um tempo de inferência mais longo permite uma exploração mais profunda de padrões ou mecanismos de tentativa e erro para aproximar soluções corretas.
- Melhor compreensão contextual: Em tarefas como raciocínio de vários passos, um modelo com mais tempo de computação pode avaliar o contexto repetidamente, para garantir que os passos intermédios se alinham com o problema mais amplo.
18. Escalonamento de computação no momento da inferência
O escalonamento de computação no momento da inferência refere-se a alocar mais computação a um modelo durante a inferência. Esta abordagem suporta rastreios de raciocínio mais longos e avaliação de vários passos sem modificar os parâmetros do modelo.
Os pontos-chave incluem:
- Os modelos podem refinar iterativamente passos intermédios para tarefas que exigem raciocínio.
- A precisão aumenta quando se permite que o modelo execute caminhos de inferência mais profundos.
- Os ganhos de desempenho são alcançados sem retreino, o que torna este método adequado para atualizações frequentes.
Exemplo real: Ganhos de capacidade pós-treino e no momento da inferência
O Claude Opus 4.6 da Anthropic ilustra como os sistemas de IA de fronteira estão a avançar através de melhorias no raciocínio no momento da inferência e integração de ferramentas. Esses ganhos manifestam-se em codificação agêntica mais capaz, onde o modelo pode planear tarefas de software de vários passos, navegar em codebases grandes e corrigir iterativamente os seus próprios erros.
Também aparecem num uso mais forte de ferramentas e workflows de agentes coordenados, como equipas de agentes no Claude Code que dividem e executam tarefas complexas.
Além disso, o Opus 4.6 suporta janelas de contexto longas (até ~1 milhão de tokens em beta), permitindo-lhe manter coerência em documentos extensos, codebases e interações de vários passos.
Juntos, estes desenvolvimentos destacam como o design do sistema e as técnicas no momento da inferência estão a impulsionar ganhos de capacidade significativos para além do treino base isolado.
Figura 2: Gráfico mostrando o desempenho do Opus 4.6 no Terminal Bench. Terminal Bench é uma suíte de benchmarking para avaliar agentes de IA operando em ambientes de terminal.10
Exemplo real: Gemini 3 Deep Think
O Gemini 3 Deep Think da Google foi concebido para enfrentar problemas científicos, matemáticos e de engenharia complexos com pesquisa inferencial mais profunda e exploração multi-hipótese.
O Deep Think melhora o desempenho alterando a forma como o modelo raciocina no momento da inferência, alocando mais computação a problemas mais difíceis em vez de depender apenas de uma contagem de parâmetros maior.
Isto mostra que as modalidades de raciocínio, nas quais um modelo pode mudar para um modo de pensamento profundo otimizado para tarefas analíticas mais difíceis, estão a emergir como um conceito distinto de progresso da IA a par da contagem de parâmetros e melhorias de ferramentas/deployment.
Figura 3: Gráfico mostrando o desempenho do Deep Think nos benchmarks ARC-AGI 2, Humanity's Last Exam, MMMU-Pro e Codeforces.11
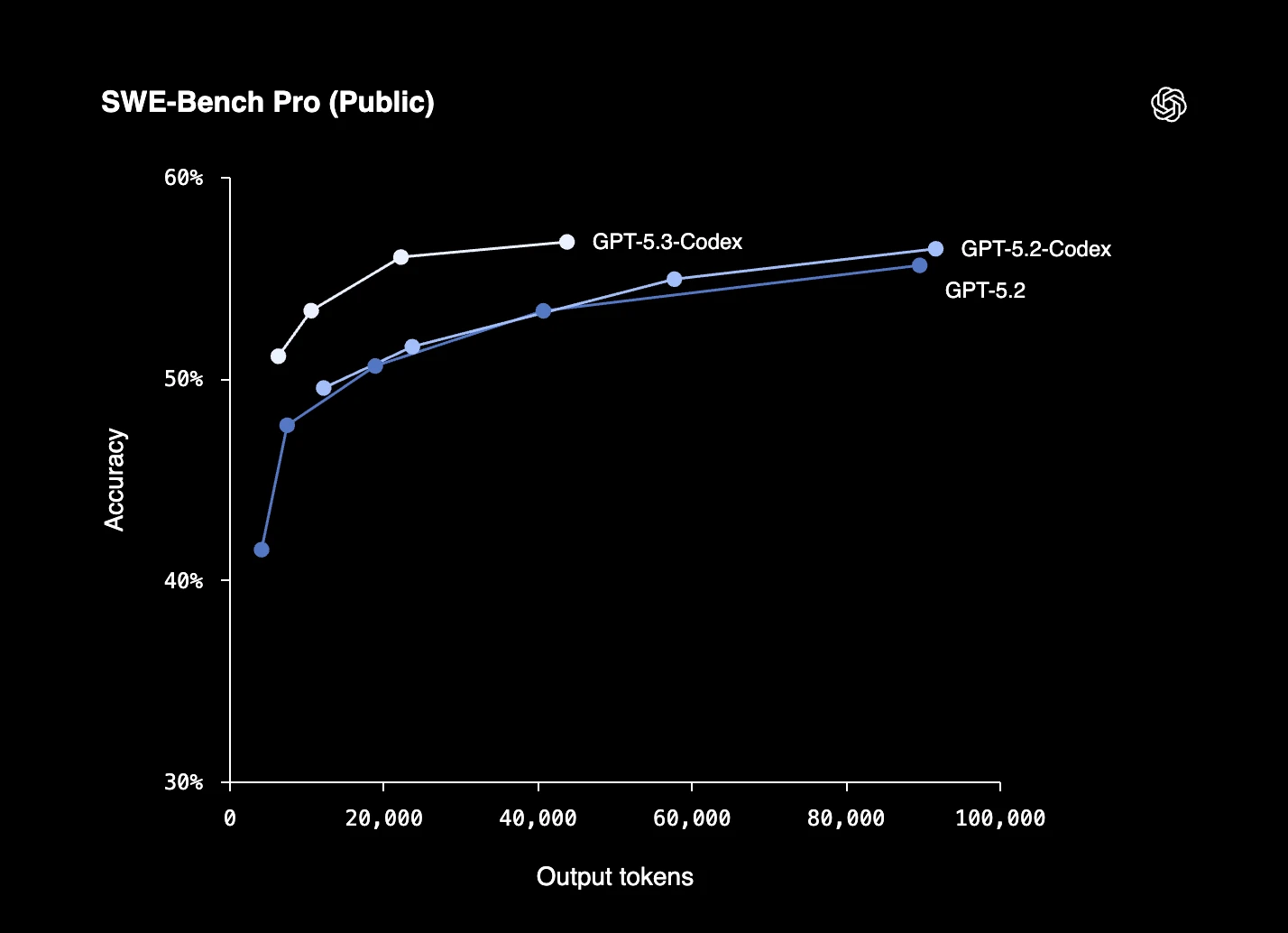
Exemplo real: GPT-5.3-Codex-Spark
O GPT-5.3-Codex-Spark da OpenAI é um modelo focado em codificação, posicionado como uma variante otimizada para velocidade do GPT-5.3-Codex, destinado a fluxos de trabalho de programação em tempo real.
As principais características incluem:
- Inferência de alto débito: Concebido para assistência à codificação de baixa latência, com velocidades de output relatadas superiores a 1.000 tokens por segundo em ambientes suportados.
- Janela de contexto grande: Suporta até 128.000 tokens de contexto, permitindo uso com bases de código maiores e sessões mais longas.
- Fluxos de trabalho de codificação interativa: Destinado a tarefas de codificação iterativas, como edição, depuração e refinamento de código em tempo real.
- Ênfase em infraestrutura: Construído para ser executado em infraestrutura de inferência de baixa latência, incluindo implementações em hardware Cerebras.
Figura 4: Desempenho de benchmark do GPT-5.3-Codex-Spark da OpenAI no SWE-Bench Pro.12
19. IA agêntica
Em vez de depender de um único modelo maior, os sistemas agênticos usam diferentes modelos com funções definidas, como planeamento, raciocínio e execução.
As vantagens incluem:
- Escalonar capacidades de raciocínio sem aumentar indefinidamente a contagem de parâmetros.
- Maior flexibilidade no uso de ferramentas, atribuindo tarefas ao modelo mais capaz.
- Incorporação mais direta de feedback de usuários e stakeholders em diferentes fases de um processo.
Um exemplo é um sistema multi-agente onde um modelo lida com tarefas de gestão de projetos, outro interpreta inputs de linguagem natural e um terceiro gere a recuperação e integração de dados. Juntos, estes modelos proporcionam melhores resultados do que um único modelo a trabalhar isoladamente.
20. Técnicas de eficiência de modelos
Em resposta ao custo e impacto ambiental do treino de modelos maiores, as técnicas de eficiência tornaram-se recentemente um foco. Estes métodos permitem aos programadores melhorar o desempenho usando menos recursos:
- Quantização reduz a pegada de memória diminuindo a precisão dos parâmetros do modelo sem perder qualidade nas previsões.
- Destilação de conhecimento transfere capacidades de um modelo grande para um modelo mais pequeno, permitindo inferência mais rápida.
- Poda remove parâmetros redundantes para reduzir a complexidade mantendo a precisão.
- Adaptação de baixa classificação (LoRA) permite o fine-tuning eficiente de modelos grandes em tarefas específicas de domínio com recursos limitados.
Estas técnicas permitem que os sistemas de IA sejam mais escaláveis em vários modelos e contextos de negócio, permitindo melhores resultados a um custo mais baixo.
Recomendações sobre como abordar a melhoria de modelos de IA/ML
Melhorar um modelo de IA/ML requer uma abordagem estratégica para identificar áreas e implementar soluções eficazes. Ao combinar a monitorização do desempenho com a tomada de decisão orientada por hipóteses, os modelos de IA/ML podem ser refinados e otimizados para melhores resultados:
Monitorizar o desempenho
Pode-se melhorar algo conhecendo as suas áreas de melhoria. Isto pode ser feito monitorizando as features do modelo de IA/ML. No entanto, se todas as features do modelo não puderem ser monitorizadas, um número selecionado de features-chave pode ser observado para estudar variações na sua saída que possam impactar o desempenho do modelo.
Geração de hipóteses
Antes de selecionar o método certo, recomendamos realizar a geração de hipóteses. Este é um processo pré-decisional que estrutura o processo de decisão e reduz as opções.
Este processo envolve adquirir conhecimento de domínio, estudar o problema que o modelo de IA/ML está a enfrentar e reduzir as opções prontamente disponíveis que possam abordar os problemas identificados.
Melhoria iterativa e experimentação
A melhoria de modelos de IA/ML é um processo contínuo. Após formar hipóteses e selecionar soluções potenciais, a experimentação e a iteração são fundamentais para refinar o modelo.
Testes A/B: Testar diferentes modelos ou alterações em subconjuntos de dados para comparar resultados. Isto ajuda a identificar quais as melhorias mais eficazes.
Retreino do modelo: Retreinar regularmente o modelo com novos dados, atualizações de features ou ajustes de algoritmo para garantir que se mantém relevante e se adapta a condições em mudança.
Monitorização automatizada e ciclos de feedback: Utilizar sistemas automatizados para fornecer feedback contínuo de IA, permitindo ajustes rápidos e iteração rápida nas melhorias.
Incorporar feedback dos stakeholders
Uma parte frequentemente negligenciada do processo de melhoria do modelo é a recolha de input dos usuários finais ou stakeholders. O feedback de IA recolhido de equipas de negócio, especialistas de domínio ou usuários finais oferece contexto valioso para refinar previsões e abordar pontos cegos do mundo real.
Integrar este ciclo de feedback ajuda a garantir que o modelo se adapta continuamente e permanece alinhado com as necessidades operacionais.
Este ciclo de feedback garante que o modelo permanece alinhado com as necessidades e expectativas do mundo real.
Priorizar as mudanças mais impactantes
Nem todas as melhorias terão o mesmo nível de impacto. É essencial priorizar alterações que abordem diretamente os problemas de desempenho mais críticos.
Por exemplo, melhorar a qualidade dos dados ou abordar um viés significativo no modelo pode ter efeitos mais substanciais do que ajustes menores nos hiperparâmetros do algoritmo.
Documentar e padronizar o processo de melhoria
Para melhorias contínuas, documente os métodos, experiências e resultados.
Padronizar este processo permite que futuras melhorias sigam uma abordagem comprovada e estruturada, garantindo que as melhorias possam ser medidas, comparadas e rastreadas.
Perguntas frequentes
A evolução da inteligência artificial levou a um progresso notável no processamento de linguagem natural (NLP). Os sistemas de IA atuais podem entender, interpretar e gerar linguagem humana com uma precisão sem precedentes. Este salto significativo é evidente em chatbots sofisticados, serviços de tradução de idiomas e assistentes ativados por voz.
Para melhorar a precisão do seu modelo de IA, considere recolher mais dados de treino de alta qualidade e diversificados. Além disso, faça fine-tuning dos hiperparâmetros do seu modelo, experimente diferentes algoritmos e aplique técnicas como validação cruzada para otimizar o desempenho.
Previna o overfitting de IA usando técnicas de regularização, implementando camadas de dropout em redes neuronais e empregando paragem antecipada durante o treino. Aumentar o tamanho do seu dataset e garantir a diversidade dos dados também pode ajudar o seu modelo a generalizar melhor para novos inputs.
Cite esta pesquisa
Escolha o formato adequado ao local onde você vai publicar. Colar a versão com link no seu CMS preserva o backlink.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Ermut, Sıla},
title = {{20 Estratégias para Melhoria de IA & Exemplos}},
year = {2026},
month = feb,
howpublished = {\url{https://aimultiple.com/ai-improvement}},
note = {AIMultiple. Acessado em 20 Fevereiro 2026}
}




Seja o primeiro a comentar
Seu endereço de e-mail não será publicado. Todos os campos são obrigatórios. Os comentários são deixados em seu idioma original.