Meilleurs outils de surveillance des performances de base de données: Comparaison des 5 meilleures plateformes
Les problèmes de base de données provoquent des pannes d'applications : un pic de mémoire fait planter votre serveur et une requête lente entraîne un délai d'attente des demandes des utilisateurs.
Nous avons analysé six plateformes de surveillance de bases de données et avons effectué des tests approfondis sur trois d'entre elles avec MySQL et MongoDB en les installant à partir de zéro, en exécutant des charges de travail identiques et en documentant chaque étape de la configuration et de l'expérience de surveillance. Les résultats montrent des différences significatives en termes de complexité de configuration, de capacités d'analyse des requêtes et de précision des métriques :
Résultats du benchmark de surveillance de la base de données
Nous avons testé SolarWinds, New Relic et Datadog avec de vraies charges de travail de base de données sur MySQL et MongoDB. Les trois plateformes ont reçu des mises à jour importantes depuis les tests. Consultez les sections individuelles des vendeurs pour les dernières fonctionnalités, notamment la détection de régression des requêtes de Datadog, l'application de surveillance de base de données de Dynatrace et les mises à jour d'indépendance de la plateforme de Percona PMM
- Expérience de configuration : SolarWinds a terminé l'intégration en 5 à 8 minutes avec détection automatique. New Relic et Datadog étaient plus lents et nécessitaient une configuration manuelle.
- Profilage des requêtes : Seul SolarWinds fournit une analyse au niveau des requêtes qui identifie les requêtes lentes, les index manquants et les opérations gourmandes en ressources.
- Précision des métriques : SolarWinds a suivi les opérations avec une précision de 100 %. New Relic a sous-compté de manière significative les opérations dans les deux tests et a manqué complètement un pic de mémoire.
- Consommation de ressources : Les trois agents sont restés légers.
Pour des benchmarks spécifiques aux bases de données avec des étapes d'installation détaillées, des données de consommation de ressources et des comparaisons de tableaux de bord :
- Surveillance MySQL : Processus de configuration, profilage des requêtes, précision des métriques avec une charge de travail d'importation de 26 Go
- MongoDB Monitoring : Fonctionnalités NoSQL, qualité du tableau de bord avec insertions de documents
Couverture des bases de données sur site
Tous les fournisseurs prennent en charge ces bases de données : MySQL, PostgreSQL, MongoDB, MariaDB, Redis.
Prise en charge des bases de données cloud
Comparer les outils de surveillance de base de données :
Les notes sont recueillies à partir de sites Web d'avis B2B.
Ce que fait réellement la surveillance de base de données
La surveillance de base de données suit les performances, la sécurité et la disponibilité en temps réel. L'objectif : détecter les problèmes avant que les utilisateurs ne les remarquent.
Ce qui est surveillé :
- Utilisation des ressources (CPU, mémoire, disque I/O)
- Durées et modèles d'exécution des requêtes
- Nombre de connexions et disponibilité
- Taux et types d'erreurs
- Événements de sécurité et anomalies d'accès
Meilleures plateformes de surveillance des performances de base de données
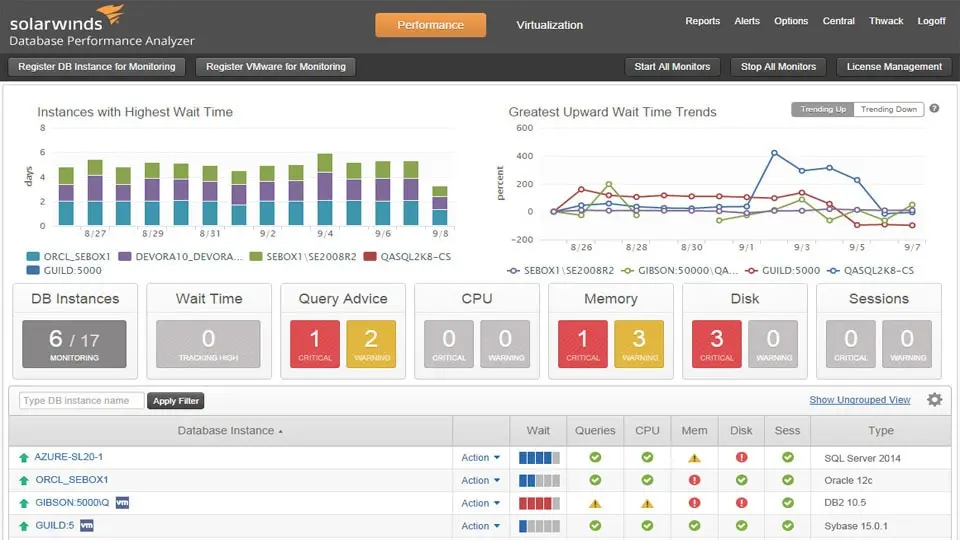
SolarWinds Database Performance Analyzer
SolarWinds Database Performance Analyzer se concentre sur l'analyse du temps d'attente au lieu de simplement suivre les métriques de base. Lorsque votre base de données ralentit, elle montre exactement quelles requêtes attendent et pourquoi, qu'il s'agisse d'I/O disque, de verrous ou de contraintes CPU.
Différences clés :
- Les lignes de base d'apprentissage automatique s'adaptent à vos modèles de base de données spécifiques
- L'analyse des requêtes fonctionne sur SQL Server, Oracle, MySQL, PostgreSQL et MongoDB dans une seule interface
- La détection d'anomalies historiques remonte à plusieurs mois pour comparer les problèmes actuels avec les incidents passés
- Les recommandations sont liées directement aux plans d'exécution de requêtes spécifiques
LogicMonitor
LogicMonitor utilise une architecture sans agent pour surveiller les bases de données dans des environnements IT hybrides. Au lieu d'installer un logiciel sur chaque serveur de base de données, un collecteur léger interroge les bases de données via des API et des protocoles standard.
Différences clés :
- Intelligence des événements : Intègre les métriques, les journaux, les traces et les tickets dans un flux corrélé unique avec corrélation inter-domaines, réduisant le bruit des alertes de 90 à 95 1
- Agents IA : Des agents IA de pointe conçus pour un usage spécifique gèrent tout le cycle de vie des incidents avec un dépannage conversationnel, une analyse de la cause racine utilisant des modèles de données corrélés et une correction automatisée
- Fonctionnalités spécifiques aux bases de données : Détecte automatiquement les anomalies dans les requêtes lentes, les pics de connexion et les goulots d'étranglement de ressources avec des résumés d'incidents en langage clair
- Plus de 3 000 intégrations d'outils : Connecte les outils d'observabilité, APM, sécurité et CMDB pour une réponse unifiée aux incidents
Percona Monitoring and Management (PMM)
Percona se concentre sur les bases de données open source, avec une expertise approfondie en MySQL, PostgreSQL et MongoDB. La plateforme fournit des outils d'analyse de requêtes et d'optimisation des performances sans les coûts de licence de logiciels d'entreprise.
Différences clés :
- Conseillers intégrés : Tous les conseillers de base de données et modèles d'alerte (précédemment classés en Basic, Standard, Premium) sont désormais inclus par défaut sans abonnement requis. Fonctionne complètement hors ligne sans dépendances Internet.
- Prise en charge de Valkey et Redis : Surveillance native de Valkey (alternative Redis haute performance) et de Redis avec dix tableaux de bord dédiés couvrant les performances, la détection de latence, les problèmes de réplication et le dépannage des goulots d'étranglement.
- PostgreSQL 18 : Prise en charge complète de PostgreSQL 18 Community Edition.
- Fonctionnalités Kubernetes d'entreprise : Prise en charge complète d'OpenShift 4.16 pour les déploiements Client et Serveur. Configuration centralisée de VMagent via des variables d'environnement qui applique automatiquement les paramètres à tous les clients connectés, optimisant l'utilisation du stockage partagé Kubernetes
Dynatrace
Dynatrace offre une observabilité alimentée par l'IA avec son moteur Davis IA, fournissant des informations du frontend à la base de données avec un focus sur l'expérience utilisateur.
Application de surveillance de base de données : Lancement d'une application dédiée de surveillance de base de données offrant une visibilité unifiée sur l'ensemble du parc de bases de données avec un score de santé proactif, une analyse au niveau des requêtes capturant les plans d'exécution réels et une intégration transparente reliant les performances de la base de données à la surveillance des applications pour une analyse plus rapide de la cause racine.
Fonctionnalités améliorées de Davis IA : Extension des capacités prédictives, causales et génératives de l'IA, notamment :
- Génération d'artefacts alimentée par l'IA pour les flux de travail de correction automatisée (par exemple, ajustements des ressources de déploiement Kubernetes)
- Résumés de problèmes en langage naturel avec des étapes de correction spécifiques
- Apprentissage intelligent de la base de connaissances à partir d'incidents historiques pour des opérations préventives
Observabilité métier : Dynatrace Intelligence positionné comme premier « OS agentique », combinant l'IA causale avec la topologie Smartscape pour des opérations autonomes. Le lac de données Grail fournit un contexte unifié à travers les bases de données, les modèles d'IA, les applications et l'infrastructure.
New Relic
New Relic traite les bases de données comme faisant partie de la surveillance des performances des applications plutôt que comme une infrastructure isolée. Leur approche relie les appels de base de données à des transactions spécifiques dans votre code.
Différences clés :
- Le traçage des transactions montre le chemin complet de la demande de l'utilisateur à travers les requêtes de base de données
- L'analyse des requêtes lentes inclut la ligne exacte de code d'application qui a déclenché chaque requête
- Opérations de tableau de bord pour les utilisateurs en lecture seule limitées à la vue seule
- Prise en charge de MySQL, PostgreSQL, MongoDB, Redis et Elasticsearch
- Suivi amélioré de la surveillance de base de données avec suivi de l'ID d'instance RDS pour Amazon RDS (meilleure corrélation entre PMM et la console AWS)
- Plusieurs annonces de fin de vie : règles de suppression d'événements d'infrastructure, règles de suppression d'interface utilisateur de surveillance IA, graphiques intégrés APM hérités
Datadog Database Monitoring
Datadog intègre les métriques de base de données avec toute votre pile d'applications. Vous voyez les performances de la base de données aux côtés des journaux, des traces et des métriques d'infrastructure dans le même tableau de bord.
Différences clés :
- Les échantillons de requêtes capturent automatiquement les plans d'exécution réels et expliquent les déclarations
- Les métriques au niveau de l'hôte corrèlent le CPU de la base de données avec l'utilisation des ressources au niveau du système
- Les traces APM relient les requêtes lentes à des demandes d'application spécifiques
- Fonctionne avec PostgreSQL, MySQL, SQL Server, Oracle et les bases de données cloud
- Détection de régression des requêtes : Établit des lignes de base historiques et utilise la détection d'anomalies pour identifier automatiquement les dégradations de performance de requête non intentionnelles dans les requêtes fréquemment utilisées. Le système exécute automatiquement des diagnostics lorsque la durée de la requête augmente de manière inattendue, aidant à identifier et résoudre les problèmes avant qu'ils n'affectent les utilisateurs.
Fonctionnalités standard dans les outils de surveillance de base de données
Tous les outils de surveillance de base de données suivent des métriques similaires, mais la profondeur et la présentation varient considérablement.
Métriques de performance
Utilisation du CPU : Montre la consommation de puissance de traitement. Lorsque le CPU atteint 80 %, votre base de données a du mal à gérer les demandes. Des pics se produisent lors de requêtes complexes ou de vagues de trafic.
Consommation de mémoire : Suit l'utilisation de la RAM pour la mise en cache des données et des résultats de requêtes. Le manque de mémoire force la base de données à lire depuis le disque, ce qui est plusieurs ordres de grandeur plus lent que la RAM.
Taux d'I/O disque : Mesure la vitesse de lecture/écriture. Un I/O élevé ralentit tout votre système. Cela révèle si vous avez besoin de stockage plus rapide ou si les requêtes scannent des données inutiles.
Débit réseau : Surveille le transfert de données entre la base de données et les applications. Une utilisation réseau élevée peut indiquer un transfert de données excessif par requête.
Exécution des requêtes
Requêtes lentes : Identifie les requêtes dépassant les seuils de temps (généralement 1 à 5 secondes). Une requête lente peut verrouiller des ressources et se propager dans un ralentissement à l'échelle du système.
Plans d'exécution : Montre la stratégie de la base de données, les index qu'elle utilise et comment elle joint les tables. Révèle pourquoi les requêtes sont lentes.
Nombre de requêtes : Suit la fréquence d'exécution. Une requête modérément lente s'exécutant 10 000 fois par minute cause plus de dégâts qu'une requête très lente s'exécutant une fois par heure.
Temps de réponse moyens : Établit des lignes de base pour détecter la dégradation des performances.
Surveillance des connexions
Connexions actives : Chaque connexion consomme de la mémoire. Trop de connexions épuisent les ressources.
Utilisation du pool de connexions : Suit l'efficacité avec laquelle les applications réutilisent les connexions. Le regroupement empêche la surcharge constante d'ouverture/fermeture.
Tentatives de connexion échouées : Signale les limites de connexion atteintes, les problèmes réseau ou les problèmes d'authentification.
Contention des ressources
Attentes de verrou : Une requête a besoin de données qu'une autre requête a verrouillées. La requête en attente reste inactive.
Interblocages : Deux requêtes attendent chacune des verrous que l'autre détient. La base de données doit en tuer une pour continuer.
Sessions de blocage : Montre quelles requêtes empêchent les autres de s'exécuter. Une longue transaction peut bloquer des dizaines d'autres.
Suivi du stockage
Croissance de la taille de la base de données : Aide à la planification de la capacité. Vous devez savoir quand l'espace disque vient à manquer.
Utilisation de l'espace table : Identifie quelles tables consomment le plus de stockage.
Fragmentation des index : À mesure que les données changent, les index se dispersent sur le disque. Les index fragmentés ralentissent les requêtes.
Surveillance des sauvegardes
Statut du travail de sauvegarde : Confirme que les sauvegardes ont réellement été exécutées. Des sauvegardes échouées signifient aucune option de récupération.
Tailles des fichiers de sauvegarde : Suit la taille au fil du temps. Des changements soudains indiquent des problèmes.
Objectifs de point de récupération : Mesure la perte de données potentielle. Des sauvegardes quotidiennes risquent une perte de données de 24 heures.
Santé de la réplication
Retard entre le principal et les répliques : Montre à quel point les répliques sont en retard. Un retard élevé crée des données obsolètes et des problèmes de cohérence.
Erreurs de réplication : Alertes lorsque les données ne parviennent pas à être copiées vers les répliques, risquant la perte de données.
Statut de synchronisation : Confirme que les répliques reçoivent activement des mises à jour.
Mécanismes d'alerte
Les outils envoient des notifications par e-mail, Slack, PagerDuty (rotations de garde), webhooks (intégrations personnalisées) et SMS (urgences critiques).
Personnalisation du tableau de bord
Va des interfaces de glisser-déposer (conviviales pour les débutants) aux fichiers de configuration JSON (puissants mais techniques).
La différence clé : Tous les outils couvrent ces bases. Ils diffèrent par la profondeur de l'analyse des requêtes, la prise en charge des bases de données et la qualité de l'intégration. Nos benchmarks ont révélé que seul SolarWinds fournissait un profilage au niveau des requêtes, les autres ne montrant que des métriques agrégées.
Analyse des fonctionnalités différenciatrices
Informations alimentées par l'IA et l'apprentissage automatique
SolarWinds utilise l'apprentissage automatique pour prédire les anomalies en fonction des modèles de base de données. L'IA Davis de Dynatrace fournit une analyse de la cause racine automatisée et inter-piles, ce qui est crucial pour les environnements complexes à forte transaction.
Surveillance sans agent
LogicMonitor est le seul outil offrant une surveillance sans agent, utilisant un collecteur léger pour collecter des données via des protocoles standard et des API, ce qui simplifie le déploiement dans des environnements hybrides et cloud complexes.
Fonctionnalités de sécurité et de conformité
Datadog se distingue par l'obfuscation automatique des informations personnellement identifiables (PII) et un contrôle d'accès basé sur les rôles granulaire. Cela nettoie automatiquement les informations personnellement identifiables des données de requête, garantissant la conformité avec les réglementations de protection des données pour les industries réglementées (par exemple, soins de santé, services financiers).
Observabilité complète de la pile
Dynatrace et New Relic offrent une visibilité au-delà de la base de données, traçant les transactions des interactions utilisateur finales à travers le code d'application jusqu'aux requêtes de base de données. Cela accélère le dépannage en fournissant une vue complète de la manière dont les performances de la base de données affectent l'expérience utilisateur.
Analyse du temps d'attente
SolarWinds excelle dans l'analyse du temps d'attente, qui se concentre sur l'identification de la cause racine du ralentissement de la base de données (par exemple, I/O disque, contention de verrou) plutôt que de simplement reconnaître qu'elle est lente. Cela fournit des informations plus exploitables pour une optimisation ciblée.
Écosystème d'intégration
Datadog mène avec plus de 600 intégrations préconstruites, permettant des flux de travail transparents avec les outils DevOps existants, les pipelines CI/CD et les systèmes de gestion des incidents.
Pour aller plus loin
- Logiciels de prévention des pertes de données (DLP)
- Top 13 des plateformes de données d'entraînement
Citer cette recherche
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Meilleurs outils de surveillance des performances de base de données: Comparaison des 5 meilleures plateformes}},
year = {2026},
month = mar,
howpublished = {\url{https://aimultiple.com/database-monitoring-tools}},
note = {AIMultiple. Consulté le 16 Mars 2026}
}

Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.