Test de base de données de graphe: Neo4j vs FalkorDB vs Memgraph
Nous avons testé Neo4j, FalkorDB et Memgraph sur un graphe synthétique dérivé de 120 000 avis produits Amazon (381K nœuds, 804K arêtes). Nous avons exécuté 12 modèles de requête avec 1 000 mesures chacun, testé l'ingestion sur 6 tailles de lot, maintenu une charge simultanée pendant 60 secondes avec jusqu'à 32 threads, et mesuré la mémoire, le démarrage à froid, la charge de travail mixte et l'impact des index.
FalkorDB a offert un débit plus élevé que Neo4j et Memgraph avec 8 threads.
Résultats du test de base de données de graphe
Débit simultané
QPS (requêtes par seconde) mesure combien de requêtes de lecture la base de données répond par seconde sous une charge multi-threadée soutenue. Chaque exécution dure 60 secondes. Plus c'est élevé, mieux c'est.
Latence des requêtes (p50)
p50 est la latence médiane : la moitié de toutes les requêtes se terminent plus vite que cette valeur. Plus c'est bas, mieux c'est.
- Recherche ponctuelle : Récupérer un seul nœud par ID. Les tables de hachage Redis de FalkorDB effectuent des recherches en mémoire O(1), environ 3 fois plus rapides.
- Traversée : Parcourir d'un nœud à ses voisins (1-saut) ou aux voisins des voisins (2-sauts). FalkorDB réalise le 2-saut en 2,9 fois plus rapide.
- Agrégation : Compter les avis par marque, calculer les notes moyennes en étoiles.
- Filtre + balayage : Filtrer les avis par note d'étoile sur l'ensemble du jeu de données.
Débit d'ingestion
Le débit d'ingestion mesure combien d'avis par seconde la base de données peut écrire. Chaque point sur le graphique correspond à une taille de lot différente : combien d'avis sont regroupés dans une seule requête. Plus c'est élevé, mieux c'est.
Avec une taille de lot de 1, Memgraph mène (1 427/s). À mesure que la taille du lot augmente, FalkorDB s'élance fortement et dépasse Memgraph autour du lot 500. Neo4j plafonne à ~10 600/s quelle que soit la taille du lot. Au lot 5 000, FalkorDB atteint 22 784/s, soit 77 fois sa performance au lot 1.
Vous pouvez en savoir plus sur notre test de base de données de graphe méthodologie.
Principales conclusions
FalkorDB atteint 6 693 QPS avec 8 threads, 6,7 fois Neo4j
Les structures de données en mémoire de Redis et sa boucle d'événements lui permettent de combiner des requêtes à faible latence avec un haut parallélisme. Après 8 threads, le débit plafonne car le cœur monothreadé de Redis est la limite. Neo4j atteint son pic à 16 threads (1 010 QPS) puis chute à 32 (927 QPS), ce qui indique une contention des threads.
FalkorDB démarre à froid en 1,1 ms, 82 fois plus rapide que Neo4j
Neo4j met 90 ms pour accepter sa première requête après un redémarrage. La première requête de réchauffement s'exécute en 274 ms, puis il faut environ 3 requêtes pour se stabiliser à 34 ms. FalkorDB est prêt en 1,1 ms, première requête à 0,4 ms. Dans une configuration de microservice ou serverless où les pods montent et descendent, cet écart compte.
Index : différence de 1 700 fois sur Neo4j, ~1 fois sur FalkorDB
Sans index, la requête deep_feature_products de Neo4j a pris 293 ms. Avec des index, 0,17 ms. C'est une différence de 1 712 fois. Memgraph a montré une sensibilité similaire (160-898 fois selon la requête). Les résultats de FalkorDB sont restés à peu près les mêmes avec ou sans index car les tables de hachage Redis fonctionnent déjà comme des index implicites.
Mémoire : 415 Mo vs 2 668 Mo pour le même graphe
- Memgraph : 415 Mo
- FalkorDB : 496 Mo
- Neo4j : 2 668 Mo (pile JMX utilisée)
La JVM de Neo4j pré-alloue 4 Go au démarrage, donc sa mémoire au niveau du processus (VmRSS) est toujours d'environ 5,2 Go, quelle que soit l'utilisation réelle des données. La métrique de pile JMX est celle qui compte. Le pic de 2,7 Go est le chiffre à utiliser pour la planification de la capacité.
Neo4j a gagné l'agrégation la plus lourde
FalkorDB a eu la latence la plus faible sur 11 requêtes sur 12. L'exception était agg_feature_sentiment (groupe par sentiment avec filtrage), où l'optimiseur de requêtes de Neo4j a produit un meilleur plan d'exécution : 131 ms contre 152 ms pour FalkorDB.
Charge de travail mixte (80 % lecture, 20 % écriture)
8 threads, 60 secondes, zéro erreur sur les trois bases de données :
- FalkorDB : 50 223 ops (837 QPS)
- Neo4j : 44 256 ops (738 QPS)
- Memgraph : 28 040 ops (467 QPS)
Les opérations d'écriture n'ont pas dégradé de manière notable les performances de lecture sur aucune d'elles.
Architectures dans ce test
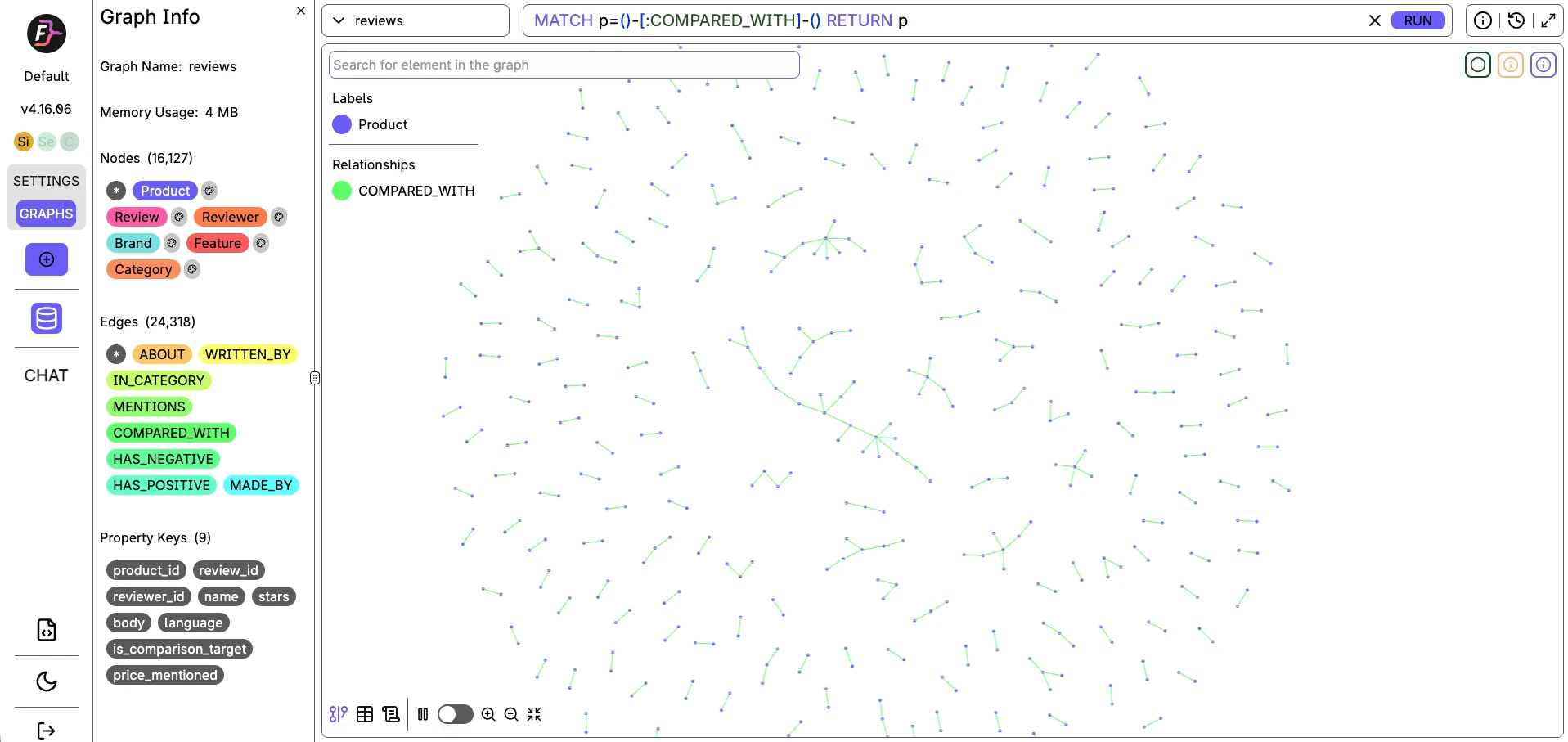
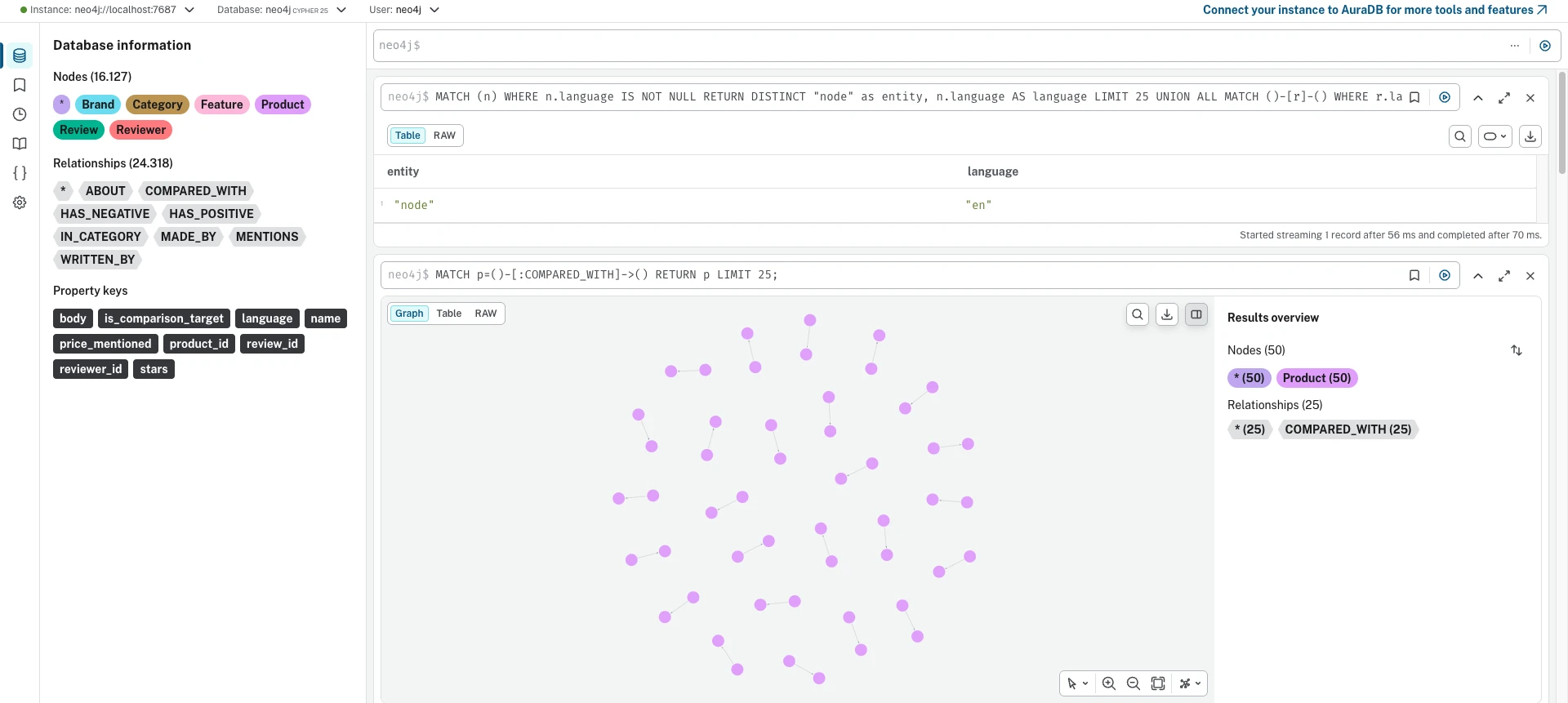
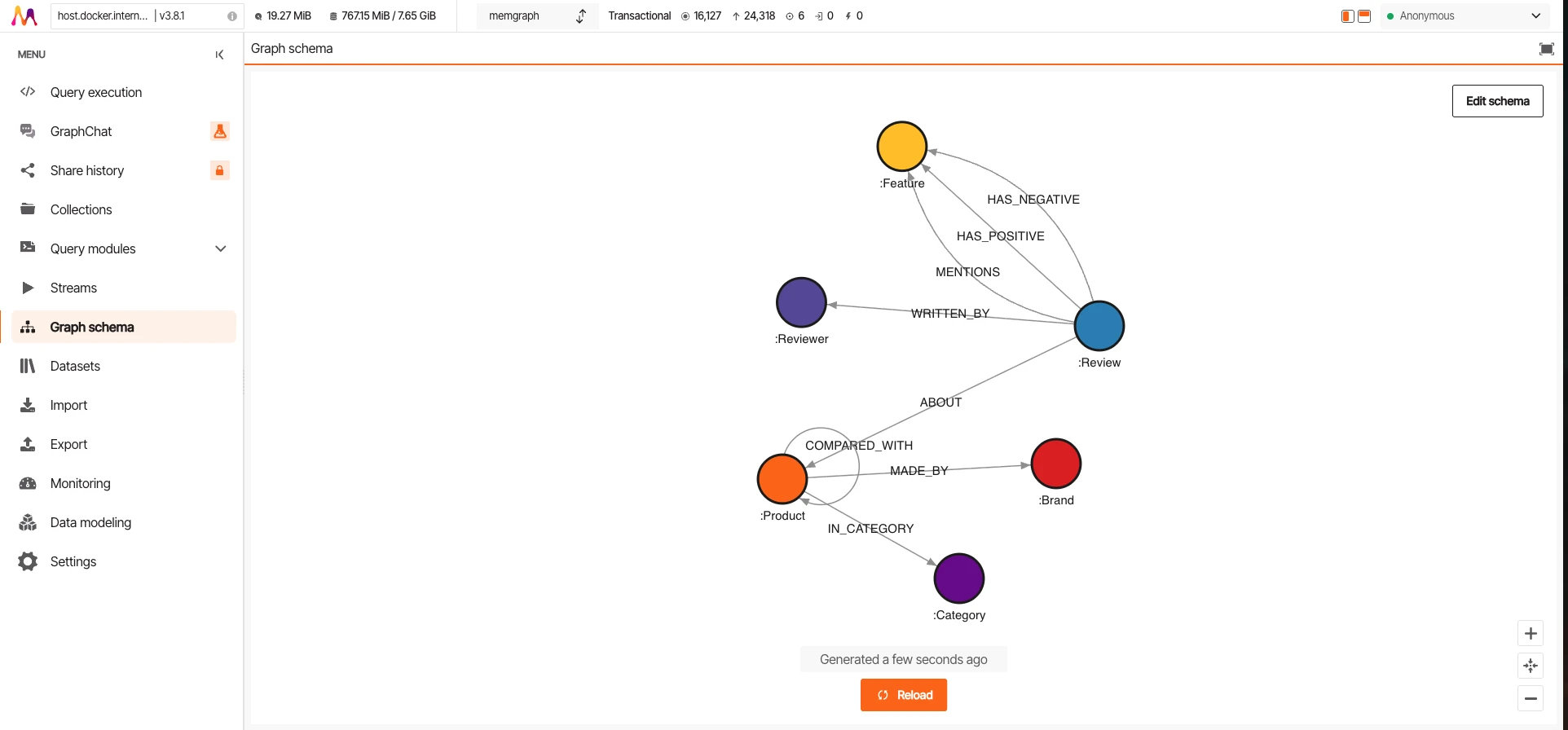
Chaque base de données livre sa propre interface de gestion. Ces captures d'écran montrent le même jeu de données (16 127 nœuds, 24 318 arêtes) chargé dans les trois, exécutant la même requête de traversée COMPARED_WITH.
FalkorDB
FalkorDB est un module de graphe construit sur le magasin de clés-valeurs en mémoire de Redis. Les requêtes sont openCypher, mais en dessous ce sont des tables de hachage Redis. C'est pourquoi les recherches ponctuelles se situent entre 0,044 et 0,048 ms.
Les deux autres bases de données dans ce test ont mesuré 2 à 3 fois plus élevées sur les mêmes requêtes. Le compromis est que le cœur monothreadé de Redis signifie que le débit simultané cesse de s'étendre au-delà de 8 threads
Neo4j
Neo4j fonctionne sur la JVM. La compilation JIT signifie que les requêtes répétées deviennent plus rapides avec le temps (réchauffement : 274 ms -> 34 ms). Les pauses GC affectent la latence de queue mais sont détectées par la suppression des valeurs aberrantes IQR. L'optimiseur de requêtes gère bien les plans d'agrégation complexes, et c'est de là que vient la victoire agg_feature_sentiment. Le coût est l'allocation préalable de 4 Go de pile et la surcharge GC.
Memgraph
Memgraph est écrit en C++. Pas de surcharge JVM. 415 Mo pour l'ensemble des données, le plus bas des trois. Le plus rapide pour les insertions individuelles (1 427/s) grâce à une surcharge minimale par requête. Mais il est en retard sur le débit simultané (pic de 684 QPS). Compatible Bolt, il fonctionne donc avec le pilote Neo4j.
Méthodologie du test de base de données de graphe
Environnement
- RunPod 8 vCPU (AMD EPYC x86_64), 32 Go RAM, Ubuntu 24.04 LTS
- Installation native, pas de Docker. Les trois bases de données sur la même machine, connexions localhost.
- Python 3.12.3. Sessions persistantes pour les tests monothreadés, sessions par appel depuis un pool de connexions pour les tests multithreadés.
Données
- 120 000 avis synthétiques générés à partir de Zipf (marques, fonctionnalités) et de Poisson (entités, relations) distributions, seed fixe=42.
- 6 types de nœuds : Avis, Produit, Examinateur, Marque, Fonctionnalité, Catégorie
- 8 types d'arêtes : ABOUT, WRITTEN_BY, IN_CATEGORY, MADE_BY, HAS_POSITIVE, HAS_NEGATIVE, MENTIONS, COMPARED_WITH
Requêtes
12 modèles Cypher répartis en 5 catégories : recherche ponctuelle (3), traversée 1-saut (2), traversée 2-sauts (2), agrégation (3), filtre (1), balayage complet (1). Chaque requête paramétrée s'exécute avec 10 valeurs de paramètres différentes, 100 fois chacune, pour 1 000 mesures par requête par base de données.
Les paramètres sont échantillonnés à partir de l'espace d'ID complet en utilisant une sélection pondérée par Zipf, afin que les éléments populaires et rares soient testés.
Trois exemples :
Recherche ponctuelle : Récupérer un seul nœud par ID indexé
Traversée 2-sauts : Parcourir d'une marque à travers ses produits vers leurs avis
Agrégation : Balayage complet du graphe avec jointure multi-sauts et calcul
Mesure
- Chronométrage :
time.perf_counter_ns(), 500 requêtes de réchauffement, 100 exécutions par requête minimum - Statistiques : 10 000 échantillons bootstrap, IC 95 %, suppression des valeurs aberrantes IQR (facteur 3,0). Les données brutes et filtrées sont toutes deux signalées.
- Mémoire : Neo4j via pile JMX utilisée (VmRSS est sans signification car la JVM pré-alloue), FalkorDB via Redis
used_memory_rss, Memgraph via/proc/{pid}/statusVmRSS.
Équité
- Même taille de pool de connexions, nombre de réchauffement, requêtes Cypher, données et machine pour les trois bases de données.
- Test simultané : charge soutenue de 60 secondes à 1, 2, 4, 8, 16 et 32 threads avec un pool_size=32 fixe. Mix de requêtes : 40 % traversée 1-saut, 30 % traversée 2-sauts, 20 % agrégation, 10 % traversée 3-sauts.
Bases de données testées
Limitations
Machine unique, nœud unique par base de données. Pas de test de distribution ou de cluster. Le clustering Enterprise de Neo4j et la réplication de Memgraph sont hors du champ d'application.
Données synthétiques avec des distributions dérivées de vrais avis Amazon. Peut ne pas correspondre aux modèles de charge de travail de production spécifiques.
Non mesuré : persistance/récupération disque, recherche plein texte, algorithmes de graphe (PageRank, détection de communauté) et charges de travail à forte écriture (>50 % écritures).
Pilotes différents : Neo4j et Memgraph ont utilisé le pilote Python Neo4j, FalkorDB a utilisé le sien. La différence de surcharge était
Conclusion
FalkorDB a gagné 11 requêtes sur 12, a atteint 6 693 QPS et a démarré à froid en 1,1 ms. Pour les charges de travail de graphe à forte lecture, c'est l'option la plus rapide dans ce test. Memgraph est l'option la plus économe en mémoire (415 Mo contre 2,7 Go). Neo4j offre l'écosystème le plus large : RBAC, clustering, surveillance et un optimiseur de requêtes qui gère mieux les plans d'agrégation complexes que l'une ou l'autre alternative.
L'architecture détermine le plafond. Les clusters distribués, les graphes de plus de 1 million de nœuds et les charges de travail à forte écriture sont les tests qui pourraient remanier ces classements.
Citer cette recherche
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{sari2026,
author = {Sarı, Ekrem},
title = {{Test de base de données de graphe: Neo4j vs FalkorDB vs Memgraph}},
year = {2026},
month = apr,
howpublished = {\url{https://aimultiple.com/graph-databases}},
note = {AIMultiple. Consulté le 15 Avril 2026}
}
Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.