Top 25+ Fabricants de puces IA: NVIDIA et ses concurrents
D’après notre expérience de l’exécution du benchmark cloud GPU de AIMultiple avec 10 différents modèles de GPU dans 4 scénarios différents, voici les principales sociétés de matériel IA pour les charges de travail de centre de données. Suivez les liens pour voir notre raisonnement derrière chaque sélection :
25+ fabricants de puces IA par catégorie
*Les modèles sélectionnés sont basés sur les dernières annonces.
**ACCEL a été développé par des scientifiques chinois en collaboration avec Alibaba et China’s Semiconductor Manufacturing International Corporation (SMIC) 1
Tri : par catégorie. Les fournisseurs sont classés en fonction de leur part de marché estimée dans les 3 premières catégories (à savoir, producteur leader, cloud public, cloud IA public) car les chiffres de ventes ou l’utilisation du cloud peuvent être estimés. Les fournisseurs des trois dernières catégories (startup IA, producteur à venir, autres producteurs) sont triés par ordre alphabétique.
5 fournisseurs de puces IA mobiles
*Les puces les plus populaires et récentes sont sélectionnées.
5 puces IA de périphérie
La demande de traitement à faible latence a stimulé l’innovation dans les puces IA de périphérie. Les processeurs de ces puces sont conçus pour effectuer des calculs d’IA localement sur les appareils plutôt que de s’appuyer sur des solutions cloud :
*Il s’agit des valeurs maximales indiquées par les fournisseurs. TOPS signifie téra opérations par seconde.
Comprendre les architectures de puces IA : GPUs vs ASICs
Toutes les puces IA ne se valent pas. Bien que les fournisseurs ci-dessus soient en concurrence sur le même marché, ils utilisent des architectures de puces fondamentalement différentes :
- GPUs (Unités de traitement graphique) sont des processeurs à usage général qui peuvent gérer à la fois l’entraînement et l’inférence sur une large gamme de charges de travail d’IA. NVIDIA et AMD dominent cette catégorie.
- ASICs (Circuits intégrés spécifiques à une application) sont conçus sur mesure pour des tâches spécifiques. Certains prennent en charge à la fois l’entraînement et l’inférence (Google TPU, AWS Trainium), tandis que d’autres sont uniquement pour l’inférence (Groq LPU, AWS Inferentia).
Point clé :
Tous les ASICs ne sont pas réservés à l’inférence. Google TPU, AWS Trainium, Cerebras et SambaNova prennent en charge à la fois l’entraînement et l’inférence, tandis que Groq LPU et AWS Inferentia se concentrent exclusivement sur l’inférence.
Cette distinction est importante pour les acheteurs : les GPUs offrent de la flexibilité pour différentes charges de travail d’IA, tandis que les ASICs fournissent de meilleures performances par watt mais sont plus difficiles à reprogrammer lorsque les architectures de modèles changent.
Selon TrendForce2 , sur la base des taux de croissance des expéditions de serveurs IA, les expéditions d’ASICs personnalisés des fournisseurs cloud devraient croître de 44,6 % en 2026, tandis que les expéditions de GPU devraient augmenter de 16,1 %. Cela signale un changement dans le paysage du matériel IA, les hyperscalers investissant de plus en plus dans leurs propres puces.
Qui sont les principaux producteurs de puces IA ?
1. NVIDIA
NVIDIA conçoit des unités de traitement graphique (GPUs) pour le secteur du jeu depuis les années 1990. NVIDIA est un fabricant de puces sans usine (fabless) qui externalise la majeure partie de sa fabrication de puces à TSMC. Ses principales activités incluent :
Solutions d’IA de bureau
DGX Spark (anciennement Project Digits) est un superordinateur d’IA de bureau destiné aux ingénieurs et data scientists, équipé d’une puce Grace Blackwell Superchip comprenant un NVIDIA Blackwell RTX GPU doté de 6 144 cœurs CUDA et de cœurs Tensor de cinquième génération avec précision FP4, connecté via l’interconnexion puce à puce NVIDIA NVLink-C2C à un NVIDIA Grace CPU hautes performances à 20 cœurs, offrant jusqu’à 1 pétaflops de calcul IA et 128 Go de mémoire unifiée pour les agents sur l’appareil.3 4
NVIDIA et Microsoft s’associent pour fournir une plateforme Windows sécurisée pour les agents sur l’appareil, construite sur de nouvelles primitives de sécurité du système d’exploitation.5
Solutions pour datacenters
La société fabrique des puces IA selon ses architectures Ampere, Hopper et, plus récemment, Blackwell. Grâce à l’essor de l’IA générative, NVIDIA a obtenu d’excellents résultats ces dernières années, a atteint une valorisation de mille milliards de dollars et a consolidé son statut de leader des marchés du GPU et du matériel IA. Le graphique suivant montre comment le chiffre d’affaires de NVIDIA dans ce segment a progressé au fil des ans et est devenu la principale source de revenus de l’entreprise.
Source : rapports financiers de NVIDIA Corporation.6
DGX™ A100 et H100 ont été les puces IA phares de Nvidia, conçues pour l’entraînement et l’inférence en datacenters.7 NVIDIA a ensuite lancé
- les puces H200, B300 et GB300
- les serveurs HGX tels que HGX H200 et HGX B300 qui combinent 8 de ces puces
- la série NVL et le GB200 SuperPod qui regroupent encore plus de puces en grands clusters.8
GPUs cloud
Grâce à la puissance de son offre datacenter, NVIDIA bénéficie d’un quasi-monopole sur le marché de l’IA cloud, la plupart des fournisseurs cloud ne proposant que des GPU NVIDIA cloud.
NVIDIA a également lancé son offre DGX Cloud, fournissant une infrastructure GPU cloud directement aux entreprises, en contournant les fournisseurs cloud.
GPUs pour les graphismes
Xbox utilise un chipset co-développé par NVIDIA et Microsoft. Les GPUs de NVIDIA pour les utilisateurs grand public incluent la série GeForce.
Développements récents
DGX Cloud Lepton
Annoncé le 19 mai 2025 au Computex, DGX Cloud Lepton de NVIDIA est une place de marché qui met en relation les développeurs IA avec les fournisseurs cloud GPU de NVIDIA, notamment CoreWeave, Lambda et Crusoe. Il permet un accès flexible aux ressources GPU pour l’entraînement et l’inférence de modèles d’IA, en contournant les dépendances traditionnelles envers les fournisseurs cloud. Cela renforce la stratégie cloud de NVIDIA axée sur les entreprises.9
NVIDIA Dynamo
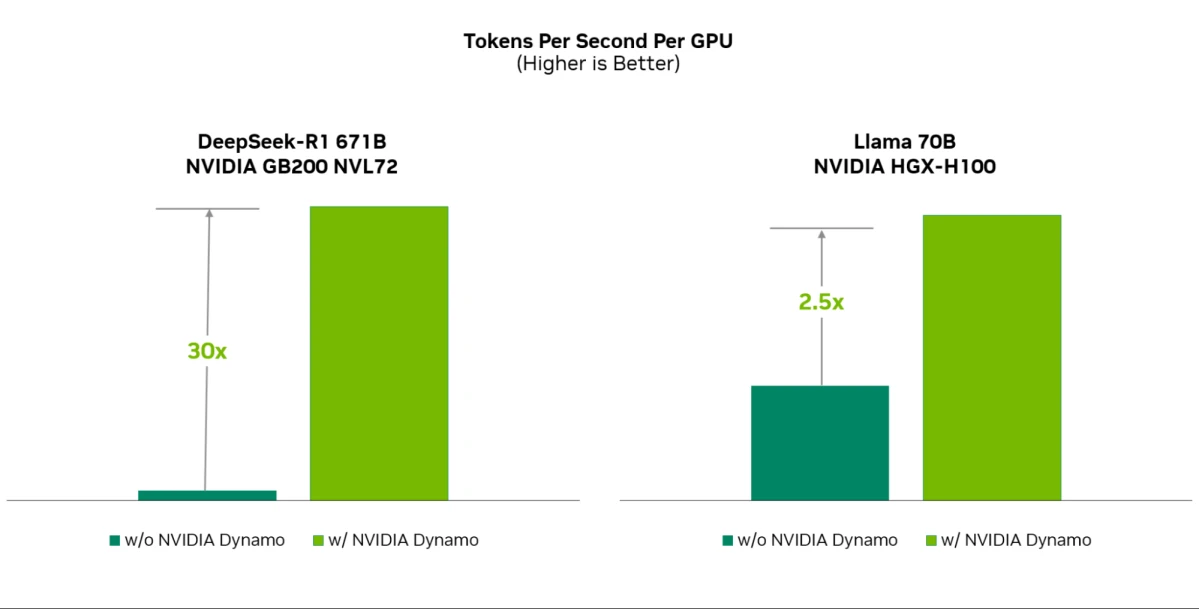
NVIDIA Dynamo, annoncé lors de GTC 2025, est un nouveau framework d’inférence open source conçu pour le déploiement à haut débit et à faible latence de modèles d’IA générative dans des environnements distribués, augmentant le service des requêtes jusqu’à 30x sur NVIDIA Blackwell comme le montre la figure ci-dessous. Ce framework, compatible avec des outils populaires comme PyTorch et TensorRT-LLM, utilise des innovations telles que les étapes d’inférence désagrégées et la planification dynamique des GPUs pour optimiser les performances et réduire les coûts. Disponible sur GitHub pour les développeurs et inclus dans les microservices NVIDIA NIM pour les solutions d’entreprise, Dynamo facilite le service d’IA générative évolutif et rentable, des systèmes mono-GPU aux systèmes multi-GPU.10
Serveurs RTX PRO NVIDIA et Enterprise IA Factory
Annoncés en mai 2025 au Computex, NVIDIA a présenté les serveurs RTX PRO équipés de GPUs RTX PRO 6000 Blackwell Server Edition, conçus pour les usines d’IA d’entreprise. Ces serveurs offrent une accélération universelle pour les applications d’IA, de conception, d’ingénierie et métier, prenant en charge des charges de travail telles que l’inférence IA multimodale, l’IA physique et les jumeaux numériques sur la plateforme NVIDIA Omniverse.
Le design validé NVIDIA Enterprise IA Factory, intégrant les serveurs RTX PRO, NVIDIA Spectrum-X Ethernet, les NVIDIA BlueField DPU et le logiciel NVIDIA IA Enterprise, permet à des partenaires comme Cadence, Foxconn et Lilly de construire des infrastructures d’IA sur site. Cette initiative accélère la transition du marché informatique à mille milliards de dollars vers les usines d’IA accélérées par GPU. 12
Plateforme NVIDIA Vera Rubin
La plateforme de nouvelle génération de NVIDIA après Blackwell Ultra, annoncée au CES 2026 et confirmée en production au Computex 2026, offre un entraînement 3,5× plus rapide et une inférence 5× plus rapide par rapport à Blackwell et est fabriquée en 3 nm TSMC avec HBM4.13 14 Le rack NVL72 offre une bande passante de 260 To/s.
DeepSeek
La sortie du modèle R1 de DeepSeek a montré que des modèles de pointe pouvaient être entraînés avec un nombre relativement faible de GPUs. Cela a entraîné une baisse du cours de l’action NVIDIA. Bien que cela ne constitue pas un conseil en investissement, cela peut être positif pour NVIDIA, car plus la puissance de calcul offre d’utilité, plus elle devrait être utilisée (paradoxe de Jevons15 ).
Cependant, étant donné que les performances des systèmes GPU s’améliorent plusieurs fois par an grâce aux avancées dans la conception des puces et les interconnexions, les acheteurs feraient bien de ne pas acheter au-delà de leurs besoins annuels, sous peine de se retrouver avec des systèmes obsolètes.
Tarifs douaniers et restrictions à l’exportation
NVIDIA est désormais autorisé à exporter des processeurs IA avancés vers le marché chinois, marquant un changement par rapport aux exigences précédentes de ne vendre que des versions dégradées. Cependant, ces exportations se heurtent à de nouveaux obstacles logistiques et financiers : les puces fabriquées à Taïwan doivent désormais transiter par les États-Unis pour des tests par des tiers, ce qui déclenche un nouveau tarif de sécurité nationale de 25 %.
Malgré le rétablissement de l’accès au matériel haut de gamme, les surcoûts et la complexité de la chaîne d’approvisionnement continuent d’inciter le gouvernement et l’industrie chinoise des semi-conducteurs à développer des alternatives locales compétitives. Bien que les puces chinoises soient actuellement moins performantes que la dernière technologie de NVIDIA, ces barrières commerciales garantissent que le développement national reste une priorité stratégique, ce qui pourrait remettre en cause la domination de NVIDIA sur le marché à l’avenir.16
Concurrence sur le marché de l’inférence
Si NVIDIA domine le marché de l’entraînement IA, la concurrence s’intensifie dans le domaine de « l’inférence », c’est-à-dire le déploiement de modèles d’IA pour des tâches réelles. Des entreprises comme AMD et de nombreuses startups, dont Untether IA et Groq, développent des puces qui visent à offrir des solutions d’inférence plus économiques, en mettant particulièrement l’accent sur une consommation énergétique réduite.
Les nouvelles techniques d’IA de « raisonnement » exigent davantage de puissance de calcul. NVIDIA estime que le raisonnement favorisera son architecture à long terme et s’attend à ce que le marché de l’inférence finisse par éclipser celui de l’entraînement en taille, même si sa part de marché est plus petite. 17
2. AMD
AMD est un fabricant de puces sans usine proposant des CPUs, des GPUs et des accélérateurs IA.
AMD a lancé le MI300 pour les charges de travail d’entraînement IA en juin 2023 et rivalise avec NVIDIA pour gagner des parts de marché. Des startups, des instituts de recherche, des entreprises et des géants de la technologie ont adopté le matériel AMD en 2023, le matériel IA de Nvidia étant devenu difficile à se procurer en raison de la demande en forte hausse, avec l’essor de l’IA générative déclenché par le lancement de ChatGPT.18 19 20
En 2025, AMD a annoncé l’acquisition d’une équipe talentueuse d’ingénieurs en matériel et logiciels IA de Untether IA, une entreprise développant des puces d’inférence IA économes en énergie pour les fournisseurs de périphérie et les datacenters d’entreprise. Cette opération renforce les capacités de compilation IA, de développement de noyaux et de conception de puces d’AMD, consolidant ainsi sa position sur le marché de l’inférence. Par ailleurs, AMD a acquis la startup de compilation Brium pour optimiser les performances IA sur ses GPUs pour datacenters Instinct pour les applications d’entreprise.21
AMD commercialisera la série MI350 pour remplacer le MI300 et concurrencer le H200 de NVIDIA. AMD affirme que le MI325X, une autre puce récente, offre des performances d’inférence de pointe. En février 2026, Meta a annoncé un accord d’infrastructure à long terme avec AMD pour déployer jusqu’à 6 GW de AMD Instinct GPUs, l’un des plus gros contrats d’approvisionnement en GPU non-NVIDIA de l’histoire et un soutien majeur à la feuille de route matérielle IA d’AMD.22 23
AMD collabore également avec des sociétés de machine learning comme Hugging Face pour permettre aux data scientists d’utiliser son matériel plus efficacement.24
L’écosystème logiciel est crucial car les performances matérielles dépendent fortement de l’optimisation logicielle. Par exemple, AMD et NVIDIA ont eu un désaccord public sur le benchmarking du H100 et du MI300. Le désaccord portait sur le package et le type de virgule flottante à utiliser dans le benchmark. Selon les derniers benchmarks, il semble que le MI300 soit meilleur ou équivalent au H100 pour l’inférence d’un LLM 70B.25
Logiciels
Bien que le matériel d’AMD rattrape celui de NVIDIA, ses logiciels sont à la traîne en termes de facilité d’utilisation. Alors que CUDA fonctionne sans problème pour la plupart des tâches, les logiciels AMD nécessitent une configuration importante. 26
Écosystème
Comme NVIDIA, AMD investit de manière sélective chez les utilisateurs de ses solutions pour favoriser l’adoption de son matériel. 27
3. Intel
Intel est l’acteur le plus important du marché des CPUs et possède une longue histoire dans le développement de semi-conducteurs. Contrairement à NVIDIA et AMD, Intel utilise sa propre fonderie pour fabriquer ses puces.
Gaudi3 est le dernier processeur accélérateur IA d’Intel. 28 Cependant, les prévisions de ventes d’Intel pour Gaudi3 étaient d’environ 500 millions de dollars pour 2024, ce qui est nettement inférieur aux milliards que AMD prévoit de réaliser en 2024.
Sous la direction du nouveau PDG Lip-Bu Tan (nommé en mars 2025), la stratégie IA d’Intel s’est clarifiée autour de solutions à l’échelle du rack.29 Intel a annulé sa puce GPU Falcon Shores pour se tourner vers Jaguar Shores, un accélérateur IA de nouvelle génération à l’échelle du rack basé sur le nœud de processus 18A d’Intel, et a fait de nouvelles annonces matérielles IA au Computex 2026, notamment son processeur Xeon 6+ sur le nœud 18A et le GPU pour datacenter Crescent Island.30 31
Quels fournisseurs de cloud public produisent des puces IA ?
4. AWS
AWS produit des puces Trainium pour l’entraînement de modèles et des puces Inferentia pour l’inférence. Bien qu’AWS soit le leader du marché du cloud public, il a commencé à développer ses propres puces après Google.
Des centaines de milliers de puces Trainium2 sont utilisées pour former le cluster Project Rainier, qui alimente les modèles de LLM d’Anthropic.
5. Google Cloud Platform
Le TPU de Google Cloud est la puce d’accélération de machine learning dédiée qui alimente des produits Google comme Translate, Photos, Search, Assistant et Gmail. Google a annoncé ses TPUs en 2016.32 Le dernier TPU Trillium est la 6ᵉ génération.33
Google a présenté Ironwood. Cette dernière génération est spécifiquement conçue pour les « modèles pensants » complexes tels que les LLMs et les MoE, offrant un traitement parallèle massif (4 614 TFLOPs par puce) et pouvant monter jusqu’à 42,5 exaflops dans des pods de 9 216 puces.34
Ironwood apporte des avancées significatives par rapport à Trillium, notamment une efficacité énergétique 2x supérieure, 6x de capacité de mémoire haute bande passante (192 Go/puce), 4,5x de bande passante HBM (7,2 TPbps/puce) et 1,5x de vitesse d’interconnexion inter-puces (1,2 Tbps). Il dispose également d’un SparseCore amélioré pour les grands embeddings. Google produit également le bien plus petit Edge TPU pour des besoins différents, conçu pour le déploiement sur des dispositifs de périphérie comme les smartphones et le matériel IoT.
6. Alibaba
Alibaba produit des puces telles que le Hanguang 800 pour l’inférence. Cependant, certaines organisations nord-américaines, européennes et australiennes (par exemple, dans l’industrie de la défense) peuvent ne pas préférer utiliser Alibaba Cloud pour des raisons géopolitiques.
7. IBM
IBM a annoncé sa dernière puce de deep learning, l’unité d’intelligence artificielle (AIU), en 2022.35 . IBM envisage d’utiliser ces puces pour alimenter sa plateforme d’IA générative Watsonx.36
L’AIU IBM s’appuie sur le processeur IBM Telum, qui alimente les capacités de traitement IA des serveurs mainframe IBM Z. Lors de son lancement, les cas d’usage mis en avant du processeur Telum incluaient la détection de fraude.37
IBM a également démontré que la fusion du calcul et de la mémoire peut conduire à des gains d’efficacité. Cela a été démontré dans le prototype de processeur North Pole.38
8. Huawei
Le HiSilicon Ascend 910C de Huawei fait partie de la famille de puces Ascend 910 introduite en 2019.
En raison des sanctions, les laboratoires d’IA en Chine ne peuvent pas acheter les puces les plus récentes et les plus performantes auprès d’entreprises américaines comme NVIDIA ou AMD. Par conséquent, ils expérimentent avec l’Ascend 910C.
Le cloud de Huawei héberge les modèles DeepSeek, et un chercheur de DeepSeek affirme qu’il peut atteindre 60 % des performances d’inférence du NVIDIA H100. 39
Quels fournisseurs de cloud IA produisent leurs propres puces ?
Ces fournisseurs ne disposent pas de clouds publics dotés de capacités complètes comme les hyperscalers. Ils proposent des services cloud limités, généralement axés sur l’inférence IA. Nous avons pu nous inscrire à ces services sans contacter les équipes commerciales :
9. Groq
Groq a été fondée par d’anciens employés de Google. L’entreprise propose les LPU, un nouveau modèle d’architecture de puce IA, visant à faciliter l’adoption de leurs systèmes par les entreprises. La startup a déjà levé environ 350 millions de dollars et produit ses premiers modèles, tels que le processeur GroqChip™, l’accélérateur GroqCard™, etc.
L’entreprise se concentre sur l’inférence LLM et a publié des benchmarks pour Llama-2 70B.40
Récemment, Groq a obtenu un engagement d’investissement significatif de 1,5 milliard de dollars de l’Arabie saoudite pour étendre la livraison de ses puces IA avancées au pays. Cet investissement servira à agrandir le datacenter existant de Groq à Dammam, en Arabie saoudite, construit en partenariat avec Aramco Digital.41
Au premier trimestre 2024, l’entreprise a indiqué que 70 000 développeurs s’étaient inscrits sur sa plateforme cloud et avaient créé 19 000 nouvelles applications.42
Le 1er mars 2022, Groq a acquis Maxeler, qui dispose de solutions de calcul haute performance (HPC) pour les services financiers.43
10. SambaNova Systems
SambaNova Systems a été fondée en 2017 pour développer des systèmes matériels-logiciels à hautes performances et haute précision pour les charges de travail d’IA générative à grand volume. L’entreprise a levé plus de 1,5 milliard de dollars au total, dont une levée de fonds de série E de 350 millions de dollars en février 2026.44
En février 2026, SambaNova a dévoilé la puce SN50, sa dernière unité de données reconfigurable (RDU), revendiquant une vitesse maximale 5x plus rapide que les puces concurrentes et un coût total de possession 3x inférieur à celui des GPUs pour les charges de travail d’IA agentique. La SN50 offre 5x plus de calcul par accélérateur et 4x plus de bande passante réseau que la génération précédente SN40L, et prend en charge une architecture mémoire à trois niveaux pour les modèles de plus de 10 billions de paramètres et des longueurs de contexte de plus de 10 millions de tokens.45
SoftBank Corp. sera le premier client à déployer la SN50 dans ses datacenters IA de nouvelle génération au Japon.
SambaNova a également annoncé une collaboration stratégique pluriannuelle avec Intel pour fournir des solutions d’inférence IA, associant les systèmes de SambaNova aux processeurs Intel Xeon, aux GPUs Intel et aux réseaux Intel pour alimenter une infrastructure d’inférence évolutive comme alternative aux solutions centrées sur les GPUs.
SambaNova Systems loue sa plateforme aux entreprises via SambaCloud. Cette approche de plateforme IA en tant que service rend ses systèmes plus faciles à adopter et encourage la réutilisation du matériel pour l’économie circulaire.46
Quelles sont les principales startups de puces IA ?
Nous aimerions également présenter quelques startups du secteur des puces IA dont nous pourrions entendre les noms plus souvent à l’avenir.
11. Cerebras
Cerebras a été fondée en 2015 et est le seul grand fabricant de puces à se concentrer sur les puces à l’échelle de la plaquette. 47 Les puces à l’échelle de la plaquette présentent des avantages en termes de parallélisme par rapport aux GPUs, grâce à leur bande passante mémoire plus élevée. Cependant, la conception et la fabrication de telles puces constituent une technologie émergente.
Les puces Cerebras comprennent :
- WSE-1 avec 1,2 billion de transistors et 400 000 cœurs de traitement.
- WSE-2, avec 2,6 billions de transistors et 850 000 cœurs, a été annoncé en avril 2021. Il utilisait le processus 7 nm de TSMC.
- WSE-3, doté de 4 billions de transistors et de 900 000 cœurs IA, a été annoncé en mars 2024. Il utilise le processus 5 nm de TSMC.48
Le système de Cerebras collabore avec des sociétés pharmaceutiques telles qu’AstraZeneca et GlaxoSmithKline et des laboratoires de recherche qui s’appuient dessus pour leurs simulations. Il cible également les créateurs de LLMs, car ses puces peuvent réduire les coûts d’inférence pour les modèles de pointe.
Cerebras propose également ses puces sur son cloud aux entreprises.
12. d-Matrix
d-Matrix suit une approche novatrice, abandonnant l’architecture traditionnelle de von Neumann au profit du calcul en mémoire. Si cette approche a le potentiel de résoudre le goulot d’étranglement entre mémoire et calcul, elle est nouvelle et non éprouvée. En novembre 2025, d-Matrix a levé 275 millions de dollars dans le cadre d’une série C codirigée par Bullhound Capital, Triatomic Capital et Temasek, avec la participation de M12 de Microsoft en tant qu’investisseur de suivi, valorisant l’entreprise à 2 milliards de dollars.49 50
En juin 2026, d-Matrix est entrée en production complète avec sa plateforme d’inférence IA Corsair, basée sur une architecture de chiplet de calcul en mémoire SRAM, des tests indépendants ayant démontré une amélioration de vitesse de plus de 10x par rapport aux alternatives uniquement GPU pour les charges de travail d’inférence IA.51
13. Rebellions
Une startup basée en Corée a levé 124 millions de dollars en 2024 et se concentre sur l’inférence LLM.52
Rebellions a fusionné avec une autre société coréenne de conception de semi-conducteurs, SAPEON, et a atteint une valorisation de licorne en 2024.53
En juillet 2025, Rebellions a obtenu un investissement du géant technologique Samsung dans le cadre d’une levée de fonds visant jusqu’à 200 millions de dollars, avant une introduction en bourse (IPO) prévue. L’entreprise a levé 220 millions de dollars depuis sa création en 2020 et collabore avec Samsung pour commercialiser sa puce de deuxième génération, Rebel-Quad (comprenant quatre puces Rebel IA), plus tard en 2025, en tirant parti du processus de fabrication 4 nanomètres de Samsung. 54
14. Tenstorrent
Le dernier processeur Blackhole Tensix de Tenstorrent offre 664 TFLOPS (BLOCKFP8) de performances, associé à 32 Go de mémoire GDDR6 et une bande passante mémoire de 512 Go/s.
La carte P150a est vendue au prix de 1 399 dollars et dispose de quatre ports QSFP-DD 800G pour la mise à l’échelle multi-cartes. Le modèle d’entrée de gamme P100a démarre à 999 dollars.55
Tenstorrent propose une pile logicielle entièrement open source. L’entreprise a levé 700 millions de dollars pour une valorisation de plus de 2,6 milliards de dollars auprès d’investisseurs, dont Jeff Bezos, en décembre 2024. 56
15. Positron
Positron a été fondée en 2023 et se concentre exclusivement sur l’inférence de modèles de transformeurs. L’entreprise adopte une approche ASIC, en construisant du matériel spécialisé optimisé spécifiquement pour les architectures de transformeurs plutôt que pour le calcul GPU à usage général.
Produits :
- Atlas (en cours de livraison) : un serveur d’inférence pour transformeurs doté de 8x accélérateurs de transformeurs Positron Archer avec 256 Go de HBM totale. L’entreprise revendique >4x de performance par watt et >3x de performance par dollar par rapport aux systèmes NVIDIA Hopper, en benchmark sur Llama 3.1 8B avec calcul BF16.57
- Titan (à venir en 2027) : un système de nouvelle génération avec plus de 8 To de mémoire alimenté par 4x puces personnalisées Asimov, conçu pour prendre en charge jusqu’à 16 billions de paramètres et des fenêtres de contexte de plus de 10 millions de tokens dans un format 4U refroidi par air.58
- Asimov (à venir en 2027) : un circuit intégré d’accélérateur d’inférence personnalisé avec plus de 2 To de mémoire par puce.
Positron a levé une série B de plus de 230 millions de dollars début 2026, avec des investisseurs dont QIA, Arm Holdings, Arena et Jump Trading.59
Atlas est actuellement utilisé par des entreprises de réseautage, de jeux, de modération de contenu, de CDN et de Token-as-a-Service. Positron affirme que son système Atlas a démontré une latence de bout en bout 3x inférieure pour les charges de travail d’inférence de trading par rapport à des systèmes H100 comparables, tout en consommant un tiers de la puissance.
Les puces de Positron sont conçues, fabriquées et assemblées aux États-Unis.
16. _etched
Leur approche sacrifie la flexibilité au profit de l’efficacité en gravant l’architecture du transformeur dans leurs puces.
L’équipe affirme que
- Sohu a construit le premier ASIC de transformeur au monde.
- Ces 8 puces Sohu peuvent générer >500 000 tokens/seconde, soit un ordre de grandeur de plus que ce que peuvent réaliser 8 NVIDIA B200.
Actuellement, ces données reposent sur les mesures internes de l’équipe. Les équipes d’AIMultiple n’ont pas encore rencontré de benchmarks ou de références clients. Nous sommes curieux de savoir :
- Que se passe-t-il lorsque le modèle devient obsolète ? Les utilisateurs doivent-ils acheter une nouvelle puce, ou l’ancienne puce peut-elle être reconfigurée avec le modèle suivant ?
- Comment ont-ils réalisé leur benchmark ? Quelle quantification et quel modèle ont été utilisés ?
Nous mettrons à jour ces informations dès que l’équipe d’_etched publiera plus de détails. Il sera intéressant de voir si le fait de graver des modèles dans les puces sera durable, étant donné la publication de nouveaux modèles tous les quelques mois.
17. Taalas
Taalas a été fondée début 2023 et adopte l’approche la plus extrême en matière de spécialisation des puces IA : câbler directement des modèles individuels dans du silicium personnalisé, produisant ce que l’entreprise appelle des « Hardcore Models ».60 L’entreprise affirme pouvoir transformer n’importe quel modèle d’IA jamais vu en silicium personnalisé en deux mois.
L’architecture de Taalas unifie le stockage et le calcul sur une seule puce à une densité de niveau DRAM, éliminant ainsi le besoin de HBM, de packaging avancé, d’empilement 3D, de refroidissement liquide ou d’I/O haut débit. L’entreprise décrit cela comme une simplification radicale de la pile matérielle.
Produits :
- HC1 (disponible maintenant) : un démonstrateur technologique câblé avec Llama 3.1 8B, fabriqué en 6 nm TSMC avec 53 milliards de transistors. Taalas revendique 17 000 tokens par seconde par utilisateur, ce qui, selon elle, est près de 10x plus rapide que l’état de l’art actuel, tout en coûtant 20x moins cher à construire et en consommant 10x moins d’énergie dans un serveur refroidi par air de 2,5 kW. Cependant, le modèle utilise une quantification personnalisée agressive en 3 bits et 6 bits, ce qui introduit des dégradations de qualité par rapport aux références GPU.61
- HC2 (prévu) : une plateforme de deuxième génération offrant une densité plus élevée, une exécution plus rapide et des formats standard à virgule flottante de 4 bits pour résoudre les limitations de quantification du HC1.
Taalas a levé plus de 200 millions de dollars mais déclare n’avoir dépensé que 30 millions de dollars pour commercialiser son premier produit avec une équipe de 24 personnes.
18. Extropic
Extropic a levé un tour de 14 millions de dollars fin 2023 pour utiliser la thermodynamique pour le calcul. L’entreprise n’a pas encore sorti de puce.
19. Vaire
Vaire est une startup basée au Royaume-Uni qui est pionnière dans le calcul réversible, une approche innovante visant à créer des puces à énergie quasi nulle. Contrairement au calcul traditionnel, où l’énergie est dissipée sous forme de chaleur, le calcul réversible recycle une part significative de l’énergie pour les calculs ultérieurs.
Vaire a démontré une puce de test capable de récupérer 50 % de son énergie, montrant le potentiel de la technologie à réduire la consommation d’énergie des charges de travail d’IA et à contourner les limitations physiques, ou « mur thermique », qui mettent au défi la fabrication moderne de semi-conducteurs. 62
20. Fractile
Fractile est une startup britannique de puces d’inférence IA qui est sortie de l’ombre en juillet 2024 avec 15 millions de dollars de financement pour défier NVIDIA sur l’inférence de modèles de pointe.63
L’entreprise construit des processeurs qui entrelacent physiquement la mémoire et le calcul sur la même puce, ce qui, selon elle, résout le double impératif de faible latence et de haut débit que les GPUs ne peuvent pas satisfaire pour l’inférence de modèles de pointe. Fractile affirme que sa conception peut exécuter des modèles de pointe jusqu’à 25x plus rapidement et pour 1/10e du coût des solutions existantes, avec l’objectif de servir des milliers de tokens par seconde à des milliers d’utilisateurs simultanés.
Fractile a son siège à Londres et son ingénierie matérielle à Bristol, et a fait l’objet d’un article du Financial Times en mars 2025 dans le cadre d’une vague de startups axées sur l’inférence qui défient la domination de NVIDIA.64
Quels sont les futurs producteurs de matériel IA ?
Bien qu’il s’agisse de solutions de matériel IA intéressantes, les benchmarks sur leur efficacité sont actuellement limités car ils sont nouveaux sur le marché.
21. Apple
Le projet ACDC d’Apple serait axé sur la construction de puces pour l’inférence IA dans les datacenters, avec une production de masse prévue au second semestre 2026.65 Apple est déjà un concepteur majeur de puces, avec ses semi-conducteurs utilisés dans les iPhones, iPads et MacBooks. Apple renforce sa stratégie d’IA embarquée avec le framework Core IA, qui exécute des modèles entièrement sur le silicium Apple sans dépendance de serveur, soutenu par un dépôt de modèles Core IA open source sur GitHub.66 67
22. Meta
L’accélérateur d’entraînement et d’inférence de Meta (MTIA) est une famille de processeurs pour les charges de travail d’IA telles que l’entraînement des modèles LLaMa de Meta.
Le dernier modèle MTIA, Next Gen MTIA, est basé sur la technologie 5 nm de TSMC et offrirait 3x les performances du MTIA v1. Le MTIA sera hébergé dans des racks contenant jusqu’à 72 accélérateurs.68
MTIA est actuellement destiné à un usage interne de Meta. Cependant, à l’avenir, si Meta lançait une offre d’IA générative pour les entreprises basée sur LLaMa, ces puces pourraient alimenter cette offre.
23. Microsoft Azure
Lors de Hot Chips 2024, Microsoft a dévoilé Maia 100, son premier accélérateur IA personnalisé conçu pour optimiser les charges de travail IA à grande échelle dans Azure grâce à une co-optimisation matérielle et logicielle. Construit sur le processus N5 de TSMC avec une mémoire avancée et une technologie d’interconnexion, Maia 100 vise un haut débit et des formats de données variés, offrant aux développeurs une flexibilité via son SDK pour un déploiement rapide de modèles PyTorch et Triton. Microsoft a lancé Maia 200 (nom de code Braga) le 26 janvier 2026, en tant qu’accélérateur IA axé sur l’inférence pour Azure, conçu pour réduire les coûts des tokens IA et offrir des performances par dollar 30 % supérieures à celles des systèmes existants.69
24. OpenAI
OpenAI finalise la conception de sa première puce IA avec Broadcom et TSMC en utilisant la technologie 3 nanomètres de TSMC. La direction de l’équipe puces d’OpenAI a de l’expérience dans la conception de TPUs chez Google, et l’objectif est de produire leur puce en masse en 2026. La puce Project Titan d’OpenAI, co-développée avec Broadcom et fabriquée sur le processus 3 nm de TSMC, est en bonne voie pour une production de masse au second semestre 2026.70 71
Samsung a conclu un accord pour fournir de la mémoire HBM4 pour la puce Titan, allouant apparemment plus de 50 % de sa capacité de fonderie de Pyeongtaek aux dies de base HBM4 à cette fin.72 OpenAI et Broadcom ont annoncé la puce d’inférence Jalapeño, une collaboration stratégique d’environ 10 milliards de dollars visant 10 GW de calcul IA déployé d’ici 2029 pour réduire la dépendance d’OpenAI vis-à-vis de NVIDIA.73
Quels sont les autres producteurs de puces IA ?
25. Graphcore
Graphcore est une entreprise britannique fondée en 2016. Elle a annoncé sa puce IA phare sous le nom d’IPU-POD256. Graphcore a déjà été financée à hauteur d’environ 700 millions de dollars.
L’entreprise a des partenariats stratégiques avec des sociétés de stockage de données comme DDN, Pure Storage et Vast Data. Les puces IA de Graphcore servent des instituts de recherche tels que l’Oxford-Man Institute of Quantitative Finance, l’Université de Bristol et l’Université de Californie à Berkeley.
La viabilité à long terme de l’entreprise était menacée car elle perdait environ 200 millions de dollars par an.74 Graphcore a été rachetée par SoftBank pour plus de 600 millions de dollars en octobre 2024.75
26. Mythic
Mythic a été fondée en 2012 et se concentre sur l’IA en périphérie. Mythic suit une voie non conventionnelle, une architecture de calcul analogique, qui vise à fournir un traitement IA en périphérie économe en énergie.
Elle a développé des produits tels que l’AMP M1076 et la carte clé MM1076, et a déjà levé environ 165 millions de dollars de financement.76
Mythic a licencié la plupart de son personnel et a restructuré ses activités avec sa levée de fonds en mars 2023.77
27. Speedata
Fondée en 2019 à Tel Aviv, Speedata développe une unité de traitement analytique (APU) conçue pour accélérer les charges de travail d’analyse de données massives et d’IA. Il s’agit d’un APU ciblant les charges de travail Apache Spark, avec des plans pour prendre en charge d’autres plateformes majeures d’analyse de données.
Speedata a levé 44 millions de dollars dans le cadre d’un tour de Série B en juin 2025, mené par Walden Catalyst Ventures, 83North et d’autres, portant son financement total à 114 millions de dollars. L’entreprise affirme que son APU surpasse les processeurs à usage général et les GPUs en remplaçant des racks de serveurs par une seule puce, offrant des performances et une efficacité énergétique supérieures pour le traitement des données.78
28. Axelera IA
Fondée en juillet 2021 à Eindhoven, aux Pays-Bas, Axelera IA est spécialisée dans la technologie d’accélération matérielle pour l’IA destinée à la vision par ordinateur et à l’IA générative. L’entreprise développe Titania, un chiplet d’inférence IA basé sur son architecture de calcul en mémoire numérique (D-IMC), conçu pour accélérer les charges de travail IA de la périphérie au cloud.
Axelera IA a obtenu jusqu’à 61,6 millions d’euros de financement auprès de l’entreprise commune EuroHPC et des États membres dans le cadre du projet DARE en mars 2025, après un précédent tour de financement de série B de 68 millions de dollars. Cela porte son financement total à plus de 200 millions de dollars en trois ans. Axelera IA vise à déployer Titania d’ici 2028 pour répondre à la demande croissante de solutions IA performantes, rentables et durables, en soulignant sa capacité à améliorer le débit et l’efficacité par rapport aux solutions cloud traditionnelles.79
Partenaires de fonderie et rôle de TSMC
En tant que leader mondial des fonderies pures, TSMC fabrique des semi-conducteurs selon les conceptions des clients plutôt que de créer ses propres puces, ce qui la distingue d’entreprises comme NVIDIA et AMD. Bien que Samsung Foundry et les services de fonderie d’Intel soient concurrents dans ce domaine, TSMC conserve une avance technologique.
Ses technologies de processus avancées, notamment ses nœuds pionniers 5 nm et 3 nm, offrent la combinaison essentielle de performance et d’efficacité énergétique requise pour les applications d’IA de pointe, comme le montrent ses partenariats de fabrication avec les concepteurs de puces IA énumérés ci-dessous :
Plans d’expansion
TSMC demande à Nvidia, AMD, Broadcom et Qualcomm d’investir dans une coentreprise pour gérer la division fonderie d’Intel, en conservant le contrôle opérationnel mais moins de 50 % de propriété. Cette initiative, soutenue par l’administration Trump, intervient après que TSMC a annoncé des plans d’investissement important aux États-Unis et vise à relancer Intel et à renforcer la fabrication de puces américaine. L’accord se heurte à des difficultés en raison des différences de processus, mais s’appuie sur les atouts de TSMC en tant que fonderie de premier plan.80 81
Quels sont les fabricants de puces IA en Chine ?
En raison des sanctions américaines empêchant de nombreuses entreprises chinoises d’acquérir les puces IA les plus avancées d’AMD et de NVIDIA, les acheteurs chinois ont augmenté leurs achats auprès des producteurs locaux.
Outre Huawei et Alibaba traités ci-dessus, voici les principaux producteurs de puces IA en Chine :
- Cambricon se concentre sur le matériel IA et prévoit environ 150 millions de dollars de ventes au cours de son dernier exercice. 82
- Baidu utilise des puces Kunlun dans son cloud et conçoit la 3ᵉ génération de puces. Kunlun 2 était comparable au NVIDIA A100.
- Biren, fondée par d’anciens de NVIDIA, produit les puces GPU BR106 et BR110.
- Moore Threads produit les GPUs MTT S2000.
FAQ
Les puces et les équipements qui les fabriquent sont les machines les plus complexes jamais construites par l’homme. Bien qu’il existe de nombreuses entreprises dans l’écosystème des semi-conducteurs, nous sommes concentrés dans cet article sur les concepteurs de puces comme NVIDIA.
La plupart des concepteurs de puces externalisent la fabrication auprès de fonderies comme TSMC. Les fonderies utilisent des équipements de lithographie produits par des sociétés comme ASML pour fabriquer ces puces. L’écosystème est soutenu par des fournisseurs comme Arm et Synopsys qui fournissent de la propriété intellectuelle et des outils de conception.
Comme on le voit ci-dessus, un nombre croissant de paramètres, la taille des ensembles de données et la puissance de calcul ont permis aux modèles d’IA générative de devenir plus précis. Pour construire de meilleurs modèles de deep learning et alimenter des applications d’IA générative, les organisations ont besoin d’une puissance de calcul et d’une bande passante mémoire accrues.
Les puces à usage général puissantes (comme les CPUs) ne peuvent pas prendre en charge les modèles de deep learning hautement parallélisés. Par conséquent, les puces IA (par exemple, les GPUs) qui permettent des capacités de calcul parallèle sont de plus en plus demandées.
Les hyperscalers répondent à cela en concevant leurs propres puces, un processus qui prend des années. Les autres doivent suivre l’une de ces voies pour construire leurs propres modèles d’IA : louer de la capacité auprès de fournisseurs de GPUs cloud ou acheter du matériel auprès des principaux fabricants de puces IA répertoriés dans cet article.
Le matériel IA est également appelé unités de traitement neuronal (NPUs), accélérateurs IA ou processeurs de deep learning (DLPs).
Pour en savoir plus
Pour des comparaisons pratiques de performances des puces couvertes dans cet article, consultez nos benchmarks :
- Benchmark multi-GPU : comment les NVIDIA B200, H200, H100 et AMD MI300X évoluent en configurations 1, 2, 4 et 8-GPU pour l’inférence LLM, avec une analyse du débit, de la latence et du coût par token.
- Benchmark de concurrence GPU : comment les NVIDIA B200, H200, H100 et AMD MI300X gèrent de 1 à 512 requêtes simultanées, y compris le débit système, la vitesse par requête, la latence de bout en bout et les tokens par dollar à chaque niveau de concurrence.
Références
Citer cette recherche
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Top 25+ Fabricants de puces IA: NVIDIA et ses concurrents}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/ai-chip-makers}},
note = {AIMultiple. Consulté le 25 Juin 2026}
}
Commentaires 2
Partagez vos idées
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.
You forgot to include Tesla with their DOJO supercomputer. From the ground-up, the supercomputer was specifically designed for machine learning and image recognition - which means that every component was designed for it including, but not limited to, PCI board design, CPU, RAM, cooling, power, scalable hardware design and software. If I'm not mistaken, the AI is also the second most widely tested and used in the "wild", just below that of Google due to Google using it in their Search.
Thank you for your feedback, Dave! Here we are only covering companies that sell the chips that they produce. Therefore, companies like Tesla that build supercomputers for their own use or companies that embed chips in their products are out of our scope.
surprised that brainchip (akida) missing in this report. any reasons?
All included companies here raised $100+M. Last time we collected the data, that wasn't the case for akida. Why don't you reach out to us at info@aimultiple.com and let's discuss why it should be included. Thank you!