Top 20+ RAG frameworks agentiques
Le RAG agentique améliore le RAG traditionnel en boostant les performances des LLM et en permettant une plus grande spécialisation. Nous avons réalisé un benchmark pour évaluer ses performances en matière de routage entre plusieurs bases de données et de génération de requêtes.
Explorez les frameworks et bibliothèques de RAG agentique, les principales différences par rapport au RAG standard, les avantages et les défis pour exploiter tout leur potentiel.
Benchmark de RAG agentique : routage multi-bases de données et génération de requêtes
Nous avons utilisé notre méthodologie de benchmark de RAG agentique pour démontrer la capacité du système à sélectionner la base de données correcte parmi un ensemble de cinq bases distinctes, chacune contenant des informations contextuelles uniques, et à générer des requêtes SQL sémantiquement précises pour récupérer les bonnes données.
Dans le benchmark de RAG agentique, nous avons utilisé :
- Framework d'agent : Langchain
- Base de données vectorielle : ChromaDB
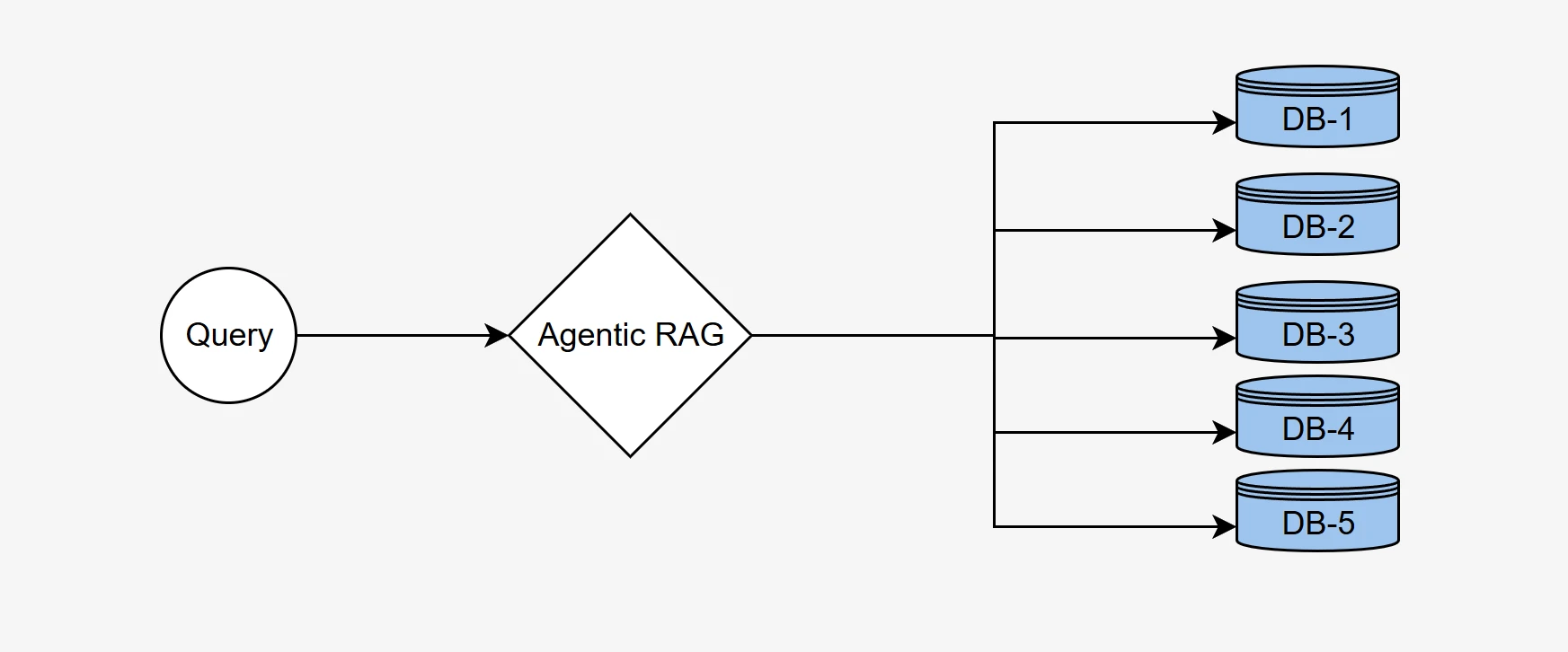
Dans de nombreux scénarios réels en entreprise, les données sont souvent réparties sur plusieurs bases de données, chacune contenant des informations spécialisées pertinentes pour des domaines ou des tâches spécifiques. Par exemple, une base de données peut stocker des données financières, tandis qu'une autre contient des données clients ou des détails d'inventaire.
Un système de RAG agentique efficace doit pouvoir router intelligemment la requête d'un utilisateur vers la base de données la plus pertinente afin de récupérer des informations précises. Ce processus implique l'analyse de la requête, la compréhension du contexte et la sélection de la source de données appropriée parmi un ensemble de bases de données disponibles.
Processus de réflexion de l'agent
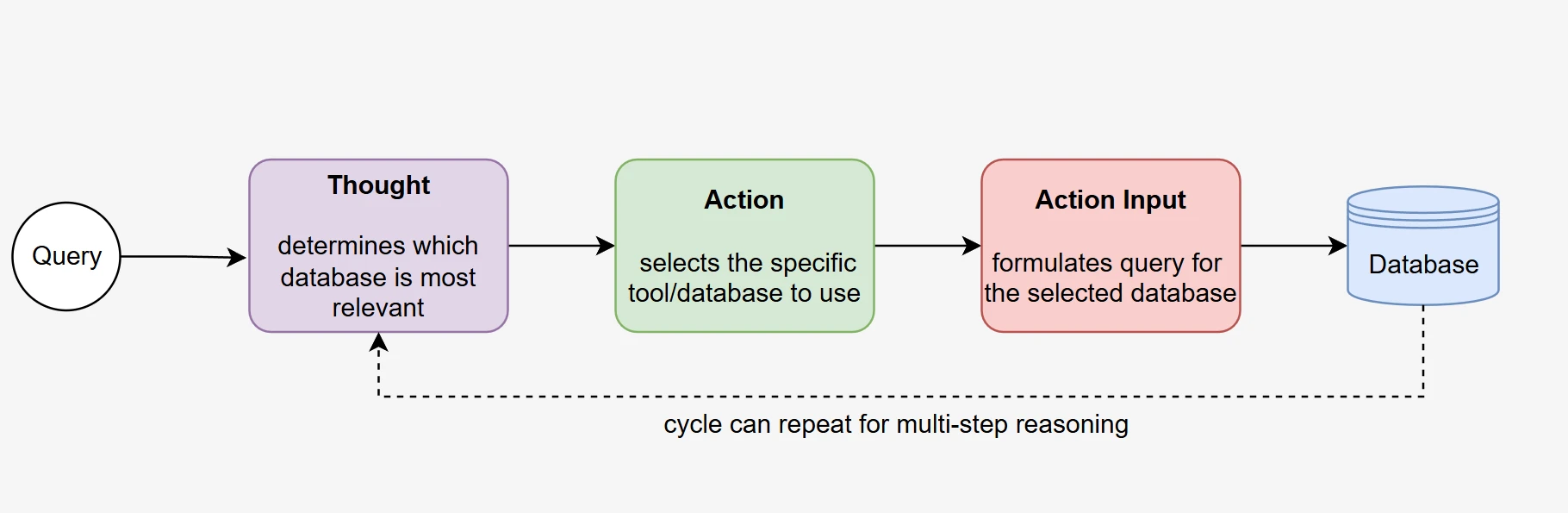
Au cœur d'un système de RAG agentique se trouve la capacité du LLM à raisonner et à agir de manière autonome pour atteindre un objectif. Notre approche basée sur l'appel de fonctions permet aux modèles de démontrer un véritable comportement agentique grâce à une sélection autonome de la base de données et une collecte itérative d'informations.
Prise de décision autonome : L'agent analyse la requête entrante de l'utilisateur et détermine de manière autonome quelle fonction de base de données appeler en fonction du contexte de la requête et des descriptions de fonctions disponibles. Ce processus décisionnel se déroule sans règles de routage prédéterminées, démontrant ainsi de véritables capacités de raisonnement.
Exécution en plusieurs étapes : L'agent effectue généralement plusieurs appels de fonction en séquence, d'abord pour identifier et accéder à la base de données pertinente, puis pour recueillir des informations détaillées sur le schéma, et enfin pour affiner sa compréhension avant de générer la requête SQL. Ce processus itératif reflète les approches de résolution de problèmes humaines.
Capacité d'auto-correction : Lorsque les appels de fonction initiaux ne fournissent pas suffisamment d'informations, l'agent peut décider de manière autonome d'effectuer des appels supplémentaires avec des paramètres affinés, démontrant un comportement adaptatif qui va au-delà des simples systèmes de récupération.
Comportement orienté vers un objectif : Tout au long du processus, l'agent maintient l'objectif de générer une requête SQL précise, en utilisant chaque résultat d'appel de fonction pour éclairer les décisions et actions ultérieures.
Ce modèle d'interaction autonome en plusieurs tours différencie fondamentalement le RAG agentique des systèmes RAG traditionnels qui suivent des chemins prédéterminés et des mécanismes de récupération en un seul coup.
Méthodologie de benchmark de RAG agentique
Ce benchmark évalue la capacité des grands modèles de langage (LLMs) à fonctionner comme des agents autonomes au sein d'un pipeline de génération augmentée par récupération (RAG). Plus précisément, il mesure deux compétences fondamentales :
- Routage de base de données : La capacité de l'agent à identifier et sélectionner correctement la base de données la plus pertinente parmi plusieurs candidates pour une question en langage naturel.
- Génération SQL : La capacité de l'agent à générer une requête SQL précise en utilisant le schéma de la base de données sélectionnée.
Jeu de données
Le benchmark utilise le jeu de données BIRD-SQL1 , un benchmark académique largement adopté pour les tâches de text-to-SQL. BIRD-SQL fournit des questions en langage naturel associées à des identifiants de base de données de référence et à des requêtes SQL de référence, ce qui le rend idéal pour évaluer à la fois la précision du routage et la qualité de la génération de requêtes.
À partir du jeu de données complet BIRD-SQL, nous avons constitué un sous-ensemble de 500 questions réparties sur cinq bases de données distinctes couvrant des domaines variés :
Chaque question a exactement une base de données cible correcte. La réponse à chaque question se trouve dans une base de données spécifique, obligeant l'agent à prendre une décision de routage définitive.
Défi d'ambiguïté sémantique
Pour évaluer les capacités de raisonnement de l'agent au-delà de la simple correspondance de mots-clés en surface, nous avons introduit une similarité sémantique inter-bases de données comme facteur de confusion délibéré lors de la sélection des questions.
Processus de sélection des questions :
- Toutes les questions candidates des cinq bases de données ont été vectorisées à l'aide de sentence transformers (
all-MiniLM-L6-v2). - Les paires de questions inter-bases de données ont été calculées et classées par similarité cosinus.
- Les questions dont le score de similarité cosinus inter-bases de données était supérieur à 0.70 ont été intentionnellement priorisées pour inclusion, créant ainsi des scénarios où des questions sémantiquement similaires appartiennent à des bases de données totalement différentes.
Exemple de confusion sémantique :
Question A (base de données financière) : « Pour le client dont le prêt a été approuvé pour la première fois le 1993/7/5, quel est le taux d'augmentation de son solde de compte du 1993/3/22 au 1998/12/27 ? »
Question B (base de données carte_de_débit) : « Pour le client qui a payé 634.8 le 2012/8/25, quel a été le taux de diminution de la consommation de l'année 2012 à 2013 ? »
Les deux questions suivent des schémas sémantiques presque identiques : elles identifient un client spécifique par le biais d'un événement de transaction, puis calculent un taux de variation sur une période donnée. Pourtant, les bases de données correctes diffèrent totalement ; l'une nécessite des données de prêt et de compte, tandis que l'autre nécessite des données de transaction et de consommation. Cela oblige l'agent à effectuer un raisonnement contextuel plus approfondi sur le domaine des données plutôt que de se fier à des mots-clés financiers de surface qui correspondraient aux deux bases de données.
Environnement de base de données
Le schéma et une brève description en langage naturel de chaque base de données ont été stockés dans ChromaDB, une base de données vectorielle utilisée pour une récupération sémantique efficace. La collection de chaque base de données contient :
- Une description de haut niveau du domaine et de l'objectif de la base de données
- Des documents de schéma par table, incluant les noms de colonnes, les types de données et les descriptions de valeurs
Cette configuration permet à l'agent de récupérer les informations de schéma pertinentes par recherche sémantique après avoir sélectionné une base de données cible.
Architecture de l'agent
Une architecture agentique basée sur l'appel de fonctions a été utilisée pour tous les modèles afin de garantir une comparaison équitable et standardisée. Chacune des cinq bases de données était représentée comme une fonction appelable distincte (outil) avec des paramètres standardisés. Cette conception exploite les capacités natives d'appel de fonction de chaque modèle, permettant aux modèles de manière autonome :
- Analyser la question entrante
- Sélectionner et invoquer la fonction de base de données appropriée
- Recevoir les informations de schéma en tant que réponse de fonction
- Invoquer éventuellement des fonctions supplémentaires pour affinement
- Générer la requête SQL finale
Cette approche maintient une méthodologie d'évaluation cohérente entre différentes familles de modèles, y compris les modèles traditionnels et les modèles optimisés pour le raisonnement.
Flux de processus agentique
Le système implémente une véritable boucle agentique en plusieurs tours plutôt qu'un pipeline fixe :
- Analyse de la question : L'agent reçoit la question en langage naturel accompagnée des descriptions des cinq fonctions de base de données disponibles.
- Sélection de la base de données (appel d'outil) : L'agent sélectionne et appelle de manière autonome la fonction de base de données qu'il juge la plus pertinente. Il s'agit d'un véritable appel de fonction ; l'agent reçoit le schéma en tant que réponse structurée d'outil dans le même contexte de conversation.
- Raisonnement sur le schéma : L'agent observe le schéma renvoyé et raisonne sur les tables et colonnes pertinentes pour la question.
- Récupération optionnelle : Si l'agent détermine que la base de données sélectionnée ne contient pas les informations requises, il peut appeler une autre fonction de base de données, permettant une auto-correction sans intervention externe.
- Génération SQL : Sur la base du contexte accumulé (question + observation du schéma), l'agent produit la requête SQL finale.
Ce flux conversationnel en plusieurs tours différencie le benchmark des approches traditionnelles de RAG en un seul coup. L'agent conserve un contexte complet à travers les tours, peut observer les résultats de ses actions et peut affiner de manière itérative son approche, marques d'un véritable comportement agentique.
Propriétés architecturales clés :
- La conversation est continue, l'agent voit son propre raisonnement antérieur et les réponses des outils
- Aucune limite de tour artificielle n'est imposée ; l'agent décide quand il dispose d'informations suffisantes
- La sélection de la base de données et la génération SQL se produisent toutes deux au sein de la même session agentique
- Le nombre d'appels d'outils par question est enregistré comme métrique supplémentaire pour analyser l'efficacité de l'agent
Processus d'évaluation
Pour chaque question du benchmark :
Étape 1 : Évaluation du routage de base de données
Le premier appel de fonction de base de données de l'agent est enregistré comme sa décision de routage. Celle-ci est comparée à la base de données de référence spécifiée dans le jeu de données BIRD-SQL.
Métrique : Précision du routage de base de données (% de sélections correctes sur le nombre total de questions)
Étape 2 : Évaluation de la qualité SQL
La requête SQL générée par l'agent est évaluée à l'aide d'une approche LLM-en-tant-que-juge. Un modèle juge distinct (Claude 4 Sonnet) reçoit à la fois le SQL généré par l'agent et le SQL de référence BIRD-SQL, et attribue un score de similarité sémantique sur une échelle de 0 à 5 :
Décision de conception importante : La qualité du SQL est évaluée lorsque l'agent sélectionne la bonne base de données. Si l'agent a routé vers la mauvaise base de données, il reçoit un score automatique de 0, car une requête SQL contre un mauvais schéma est intrinsèquement dénuée de sens. Cela garantit que la métrique de qualité SQL reflète purement la capacité de génération de requêtes, non contaminée par les erreurs de routage.
Métriques :
- Score moyen de qualité SQL (sur 5.0), calculé sur les questions correctement routées
- Taux de correspondance parfaite : pourcentage de questions correctement routées obtenant un score de 5/5
Variables contrôlées
Pour garantir une comparaison équitable entre les modèles :
- Tous les modèles reçoivent des invites système et des définitions d'outils identiques
- La température est fixée à 0 pour des sorties déterministes
- Aucune ingénierie d'invite spécifique au modèle ni exemple few-shot n'est fourni (évaluation zero-shot)
- Le champ evidence (indices spécifiques au domaine) de BIRD-SQL est retenu pour tous les modèles afin de mesurer le raisonnement non assisté
- Tous les modèles accèdent à la même instance ChromaDB avec des embeddings de schéma identiques
Frameworks et bibliothèques de RAG agentique
Les frameworks de RAG agentique permettent aux systèmes d'IA de rechercher des informations, de raisonner, de prendre des décisions et d'agir. Principaux outils et bibliothèques qui alimentent le RAG agentique :
Cette liste inclut les outils qui répondent aux critères suivants :
- 50+ étoiles sur GitHub.
- Utilisation courante dans les projets de RAG agentique.
Notez que dans le tableau :
- Utilisation d'outils fait référence à la capacité native d'un système à router et appeler des outils au sein de son environnement.
- Type d'outil fait référence au domaine d'utilisation principal des outils, tel que :
- Frameworks de RAG agentique sont conçus spécifiquement pour construire, déployer ou configurer des systèmes de RAG agentique.
- Bibliothèques d'agents permettent la création d'agents intelligents capables de raisonner, de prendre des décisions et d'exécuter des tâches en plusieurs étapes.
- Frameworks LLMOps gèrent le cycle de vie des LLM et optimisent le déploiement et l'utilisation des LLM au sein des systèmes basés sur des agents.
- LLMs qui ont des capacités intégrées d'appel d'outil et de routage, permettant une prise de décision dynamique. D'autres LLM peuvent nécessiter des APIs externes ou des intégrations pour activer la fonctionnalité d'agent.
- Vérification de l'utilisation d'outils et des types d'agents est obtenue par des sources publiques.
Qu'est-ce que le RAG agentique ?
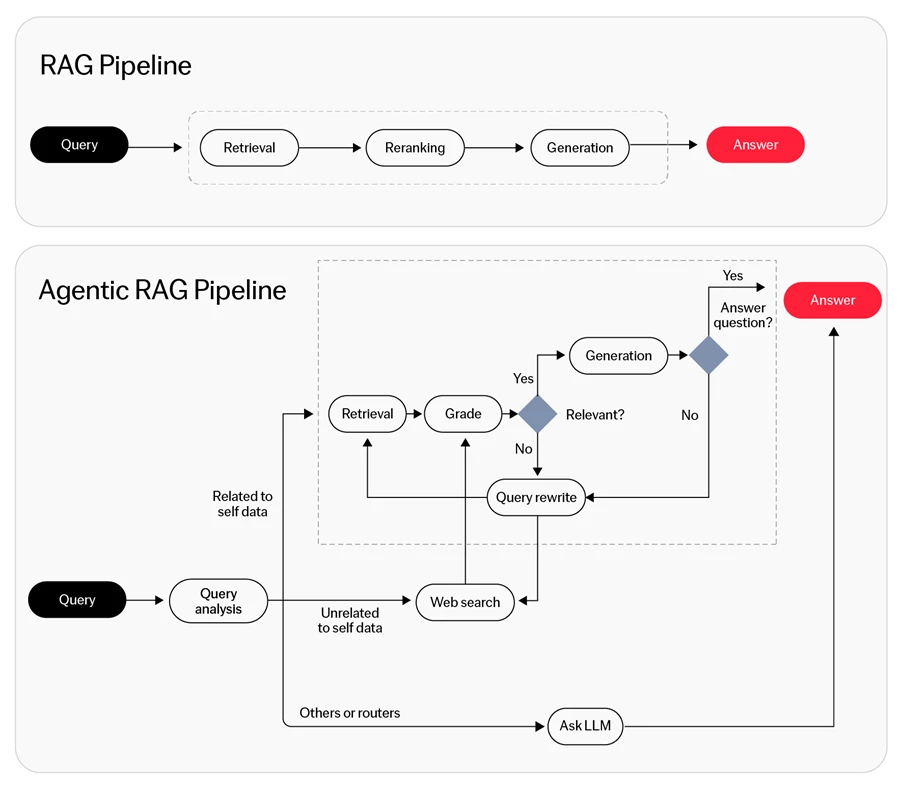
La génération augmentée par récupération agentique (RAG) est un framework d'IA qui combine des techniques de récupération avec des modèles génératifs pour permettre une prise de décision dynamique et une synthèse des connaissances. Cette approche intègre la précision du RAG traditionnel avec les capacités génératives de l'IA avancée, visant à améliorer l'efficience et l'efficacité des tâches pilotées par l'IA.
Limites des systèmes RAG traditionnels
Le RAG agentique vise à surmonter les limitations rencontrées avec le système RAG standard, telles que :
- Difficulté de priorisation de l'information : Les systèmes RAG peinent souvent à gérer et prioriser efficacement les données au sein de grands ensembles de données, ce qui peut réduire les performances globales.
- Intégration limitée des connaissances expertes : Ces systèmes peuvent sous-évaluer le contenu spécialisé de haute qualité, favorisant plutôt des informations générales.
- Faible compréhension contextuelle : Bien que capables de récupérer des données, ils échouent fréquemment à en comprendre pleinement la pertinence ou comment elles s'alignent avec la requête spécifique.
Comment construire un RAG agentique
1. Utilisation d'outils
- Utiliser des routeurs : La première étape consiste à utiliser des routeurs pour déterminer s'il faut récupérer des documents, effectuer des calculs ou réécrire la requête. Cette approche ajoute des capacités de prise de décision pour router les demandes vers plusieurs outils, permettant aux grands modèles de langage (LLMs) de sélectionner les pipelines appropriés.
- Intégration d'appels d'outils : Il s'agit de créer une interface permettant aux agents de se connecter aux outils sélectionnés. Les utilisateurs peuvent tirer parti des LLM dotés de capacités d'appel d'outils ou construire les leurs pour :
- Choisir une fonction à exécuter.
- Déduire les arguments nécessaires pour cette fonction.
- Améliorer la compréhension des requêtes au-delà des pipelines RAG traditionnels, permettant des tâches comme les requêtes de base de données ou le raisonnement complexe.
2. Implémentation de l'agent
- Agents à appel unique : Une requête déclenche un seul appel à l'outil approprié, renvoyant la réponse. Cela est efficace pour les tâches simples, mais peut échouer avec des requêtes vagues ou complexes.
- Agents multi-appels : Cette approche consiste à diviser les tâches entre des agents spécialisés, chaque agent se concentrant sur une sous-tâche spécifique. Par exemple :
- Agent récupérateur : Optimise la récupération de requêtes en temps réel.
- Agent gestionnaire : Gère la délégation des tâches et l'orchestration.
3. Raisonnement multi-étapes
Pour les flux de travail complexes, les agents utilisent des boucles de raisonnement pour effectuer un raisonnement itératif en plusieurs étapes tout en conservant une mémoire des étapes intermédiaires. Ces boucles impliquent :
- L'appel de plusieurs outils.
- La récupération de données et la validation de leur pertinence.
- La réécriture des requêtes si nécessaire.
Les frameworks définissent souvent plusieurs agents pour gérer des sous-tâches spécifiques, assurant une exécution efficace du processus global.
4. Approches hybrides : combiner récupération et exécution
Une approche hybride combine des pipelines de récupération avec des stratégies d'exécution dynamiques :
- Stratégies d'embedding et de récupération vectorielle pour l'accès aux documents.
- Capacités d'appel d'outils pour la résolution dynamique de requêtes.
- Collaboration multi-agent pour des sous-tâches spécialisées.
Quelle est la différence entre le RAG et le RAG agentique ?
Voici les forces et les faiblesses du RAG par rapport au RAG agentique selon différents aspects :
- Ingénierie des invites
- RAG traditionnel : Repose fortement sur l'optimisation manuelle des invites.
- RAG agentique : Ajuste dynamiquement les invites en fonction du contexte et des objectifs, réduisant ainsi le besoin d'intervention manuelle.
- Conscience contextuelle
- RAG traditionnel : A une conscience contextuelle limitée et repose sur des processus de récupération statiques.
- RAG agentique : Prend en compte l'historique de la conversation et adapte dynamiquement les stratégies de récupération en fonction du contexte.
- Autonomie
- RAG traditionnel : Manque d'actions autonomes et ne peut pas s'adapter à des situations évolutives.
- RAG agentique : Effectue des actions en temps réel et s'ajuste en fonction du retour d'information et des observations en temps réel.
- Raisonnement
- RAG traditionnel : Nécessite des classifieurs et des modèles supplémentaires pour le raisonnement multi-étapes et l'utilisation d'outils.
- RAG agentique : Gère le raisonnement multi-étapes en interne, éliminant le besoin de modèles externes.
- Qualité des données
- RAG traditionnel : N'a pas de mécanisme intégré pour évaluer la qualité des données ou garantir l'exactitude.
- RAG agentique : Évalue la qualité des données et effectue des vérifications post-génération pour garantir des sorties précises.
- Flexibilité
- RAG traditionnel : Fonctionne avec des règles statiques, limitant l'adaptabilité.
- RAG agentique : Emploie des stratégies de récupération dynamiques et ajuste son approche si nécessaire.
- Efficacité de la récupération
- RAG traditionnel : La récupération est statique et souvent coûteuse en raison d'inefficacités.
- RAG agentique : Optimise les récupérations pour minimiser les opérations inutiles, réduisant les coûts et améliorant l'efficacité.
- Simplicité
- RAG traditionnel : Offre une configuration simple avec moins de complexités de configuration.
- RAG agentique : Implique des configurations plus complexes pour prendre en charge des opérations dynamiques et contextuelles.
- Prévisibilité
- RAG traditionnel : Cohérent et basé sur des règles, mais rigide dans son comportement.
- RAG agentique : Le comportement peut varier dynamiquement en fonction du contexte et des observations en temps réel.
- Coût des déploiements
- RAG traditionnel : Moins cher pour les configurations de base, mais peut entraîner des coûts opérationnels plus élevés à long terme.
- RAG agentique : Nécessite un investissement initial plus élevé en raison de fonctionnalités avancées et de capacités dynamiques.
Modèles à long contexte vs RAG agentique : quand la récupération devient inutile
La révolution de la fenêtre de contexte de 2025-2026 remet en question une hypothèse centrale dans l'architecture RAG. Les modèles prennent désormais en charge 1 à 2 millions de tokens, ce qui pose une question fondamentale : quand le traitement direct du contexte surpasse-t-il les agents de récupération complexes ?
Le paysage contextuel en mutation
Les fenêtres de contexte se sont considérablement élargies, passant de 128k tokens début 2024 à plus de 1M en 2026. Des recherches récentes utilisant des romans complets comme données de test révèlent que cette expansion crée de nouveaux compromis architecturaux que les ingénieurs doivent prendre en compte.4
Le coût computationnel du traitement de contextes massifs doit être mis en balance avec la complexité d'ingénierie et les points de défaillance potentiels des systèmes de récupération. Traiter 1M tokens élimine la compression avec perte du découpage et de l'indexation, mais à un coût par requête élevé.
Le problème du goulot d'étranglement de la récupération
La recherche sur les documents longs identifie une limitation sévère dans les approches RAG traditionnelles. La récupération top-k standard crée ce que les chercheurs appellent un « goulot d'étranglement de la récupération » : lorsque la récupération initiale manque le morceau pertinent, le système ne dispose d'aucun mécanisme de récupération.
Le RAG agentique résout ce problème grâce à un affinement itératif des requêtes. Des études montrent que les systèmes agentiques résolvent avec succès une part significative des problèmes qui échouent complètement avec une récupération en un seul coup. La boucle autonome permet aux agents de reformuler les requêtes lorsque les tentatives initiales renvoient des informations insuffisantes.5
Cependant, lorsque les données tiennent dans des fenêtres de contexte élargies, le traitement direct à long contexte surpasse même les systèmes de récupération agentiques sophistiqués. L'écart de performance existe parce que le modèle peut raisonner sur l'ensemble du document simultanément, évitant la fragmentation inhérente à la récupération par morceaux.
Différents types de modèles de RAG agentique
Parmi les agents qui exploitent les grands modèles de langage (LLMs) au sein des frameworks de génération augmentée par récupération (RAG), citons :
- Agent de routage : Utilise un LLM (LLM) pour le raisonnement agentique afin de sélectionner le pipeline de génération augmentée par récupération (RAG) le plus approprié (par exemple, résumé ou réponse à des questions) pour une requête donnée. L'agent détermine le meilleur choix en analysant la requête d'entrée.
- Agent de planification de requête en un seul coup : Décompose les requêtes complexes en sous-requêtes plus petites, les exécute à travers divers pipelines RAG avec différentes sources de données, et combine les résultats en une réponse complète.
- Agent d'utilisation d'outils : Améliore les frameworks RAG standard en incorporant des sources de données externes (par exemple, APIs, bases de données) pour fournir un contexte supplémentaire. Cela permet un traitement plus enrichi des requêtes à l'aide des LLMs.
- Agent ReAct : Intègre le raisonnement et l'action pour le traitement de requêtes séquentielles en plusieurs parties. Il maintient un état en mémoire et invoque itérativement des outils, traite leurs sorties et détermine les étapes suivantes jusqu'à ce que la requête soit entièrement résolue.
- Agent de planification et d'exécution dynamiques : Destiné à gérer des requêtes plus complexes, cet agent sépare la planification de haut niveau de l'exécution. Il utilise un LLM comme planificateur pour concevoir un graphe de calcul des étapes nécessaires pour répondre à la requête et emploie un exécuteur pour effectuer ces étapes efficacement. L'accent est mis sur la fiabilité, l'observabilité, la parallélisation et l'optimisation pour les environnements de production.
Avantages du RAG agentique
Le RAG agentique améliore les LLMs grâce à :
- Approche autonome et orientée objectif : Contrairement au RAG traditionnel, le RAG agentique agit comme un agent autonome, prenant des décisions pour atteindre des objectifs définis et poursuivre des interactions plus profondes et plus significatives.
- Conscience contextuelle et sensibilité améliorées : Le RAG agentique prend en compte dynamiquement l'historique de la conversation, les préférences de l'utilisateur, les interactions antérieures et le contexte actuel pour fournir des réponses pertinentes et éclairées et une prise de décision.
- Récupération dynamique et raisonnement avancé : Il utilise des méthodes de récupération intelligentes adaptées aux requêtes, tout en évaluant et en vérifiant l'exactitude et la fiabilité des données récupérées.
- Orchestration multi-agent : Il coordonne plusieurs agents spécialisés, décomposant les requêtes en tâches gérables et assurant une coordination transparente pour fournir des résultats précis.
- Précision accrue avec vérification post-génération : Les modèles de RAG agentique effectuent des contrôles de qualité sur le contenu généré, garantissant la meilleure réponse possible et combinant les LLMs avec des systèmes basés sur des agents pour des performances supérieures.
- Adaptabilité et apprentissage : Ces systèmes apprennent et s'améliorent continuellement au fil du temps, améliorant les capacités de résolution de problèmes, la précision et l'efficacité, et s'adaptant à divers domaines pour des tâches spécifiques.
- Utilisation flexible d'outils : Les agents peuvent exploiter des outils externes tels que des moteurs de recherche, des bases de données ou des APIs pour améliorer la collecte, le traitement et la personnalisation des données pour diverses applications.
Défis du RAG agentique
- Qualité des données : Des sorties fiables nécessitent des données de haute qualité et organisées. Des défis apparaissent lors de l'intégration et du traitement de divers ensembles de données, y compris des données textuelles et visuelles, pour répondre aux exigences des requêtes des utilisateurs. De plus, les processus de récupération de données doivent également garantir l'exactitude et la cohérence.
- Conseil : Implémentez des outils de nettoyage automatisé des données et des techniques de validation des données pilotées par l'IA pour garantir une intégration cohérente et de haute qualité des données sur les ensembles de données textuelles et visuelles.
- Évolutivité : Une gestion efficace des ressources système et des processus de récupération est essentielle à mesure que le système se développe. À mesure que les requêtes des utilisateurs et les volumes de données augmentent, la gestion du traitement en temps réel et par lots pour la récupération de données supplémentaires devient un défi important.
- Conseil : Utilisez une infrastructure cloud évolutive et des frameworks de calcul distribué pour gérer efficacement des charges de données croissantes. Intégrez un équilibrage de charge dynamique pour la gestion des requêtes en temps réel.
- Explicabilité : Garantir la transparence dans la prise de décision renforce la confiance. Fournir des informations claires sur la manière dont les réponses aux requêtes des utilisateurs sont générées, en particulier lors de l'exploitation de données textuelles et visuelles, reste un défi persistant.
- Conseil : Tirez parti des outils d'explicabilité de l'IA comme SHAP ou LIME pour rendre les prédictions des modèles interprétables et intégrez des tableaux de bord de visualisation pour clarifier le raisonnement derrière les réponses.
- Confidentialité et sécurité : Des protocoles de communication sécurisés et une protection solide des données sont essentiels. La gestion des données sensibles ou confidentielles nécessite des mécanismes de chiffrement robustes et de conformité lors du stockage, de la récupération de données supplémentaires et du traitement.
- Conseil : Utilisez un chiffrement de bout en bout et des solutions de gestion des accès, et assurez la conformité aux réglementations sur la protection des données telles que le RGPD ou le CCPA. Utilisez des passerelles API sécurisées pour la récupération de données supplémentaires.
- Préoccupations éthiques : Aborder les biais, l'équité et les abus est crucial pour un déploiement responsable de l'IA. Garantir des réponses impartiales à diverses requêtes d'utilisateurs reste une considération clé dans la conception d'une IA éthique.
- Conseil : Déployez des plateformes d'IA responsable et des outils de gouvernance de l'IA pour faire face aux biais de l'IA et respecter les quatre principes directeurs de l'IA.
Perspectives d'avenir
Les dernières recherches sur le RAG agentique incluent des axes d'amélioration tels que :
- Intégration de graphes de connaissances : Améliore le raisonnement en exploitant des relations de données complexes.
- Technologies émergentes : Intégration d'outils tels que les ontologies et le web sémantique pour faire progresser les capacités du système.
- Collaboration d'agents spécialisés : Des agents ayant une expertise dans différents domaines (par exemple, ventes, marketing, finance) travaillent ensemble dans un flux de travail coordonné pour répondre à des tâches complexes.
- Optimisation de la qualité : Remédier aux sorties incohérentes pour améliorer la fiabilité et la précision des systèmes multi-agents.
Pour aller plus loin
Explorez d'autres benchmarks de RAG, tels que :
- Top 10 modèles d'embedding multilingues pour le RAG
- Modèles d'embedding : OpenAI vs Gemini vs Cohere
- Top 16 modèles d'embedding open source pour le RAG
- Meilleure base de données vectorielle pour le RAG : Qdrant vs Weaviate vs Pinecone
- Benchmark de reranker : les 8 meilleurs modèles comparés
- Modèles d'embedding multimodaux : Apple vs Meta vs OpenAI
FAQ
La génération augmentée par récupération (RAG) est une technique qui combine des méthodes basées sur la récupération avec des modèles génératifs pour améliorer la récupération d'informations et la génération de réponses.
Explorez davantage la technique de génération augmentée par récupération et les modèles courants.
Un agent est un programme informatique conçu pour observer son environnement, prendre des décisions et exécuter des actions de manière autonome afin d'atteindre des objectifs spécifiques sans intervention humaine directe.
Utilisation dans les systèmes d'IA
Les agents sont utilisés pour automatiser des tâches, optimiser des processus et prendre des décisions intelligentes dans des environnements dynamiques. Selon leur complexité, les agents peuvent aller de simples systèmes basés sur des règles à des modèles avancés utilisant des techniques d'apprentissage.
Types d'agents
Agents réactifs : Fonctionnent en fonction de l'état actuel de l'environnement et suivent des règles prédéfinies, sans utiliser d'expériences passées.
Agents cognitifs : Stockent les expériences passées et les utilisent pour analyser des schémas et prendre des décisions, permettant un apprentissage à partir d'interactions antérieures.
Agents collaboratifs : Interagissent avec d'autres agents ou systèmes pour atteindre des objectifs partagés, souvent au sein de systèmes multi-agents où la coordination et le partage d'informations sont essentiels.
Le RAG agentique peut être meilleur pour les tâches nécessitant une prise de décision plus dynamique et contextuelle et des interactions itératives, mais son efficacité dépend du cas d'utilisation spécifique et des besoins de mise en œuvre.
Le RAG vanilla récupère et génère passivement des réponses basées sur un modèle requête-réponse statique, tandis que le RAG agentique intègre des processus itératifs, une prise de décision et des interactions dynamiques pour affiner les réponses ou gérer des tâches complexes.
Citez ce benchmark
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sarı, Ekrem},
title = {{Top 20+ RAG frameworks agentiques}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/agentic-rag}},
note = {AIMultiple. Consulté le 17 Juillet 2026}
}




Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.