Évaluation comparative des outils de révision de code par IA
Avec l'utilisation accrue des outils de codage par IA, les bases de code sont devenues plus vulnérables, ce qui a accru le besoin de révisions de code efficaces. Pour répondre à cela, nous présentons RevEval (IA Code Review Eval), qui compare les quatre principaux outils de révision de code par IA sur 309 pull requests provenant de dépôts de tailles variées et évalue leurs performances en utilisant les retours de 10 développeurs et d'un LLM-as-a-judge.
Résultats du benchmark
CodeRabbit s'est classé comme l'outil de révision de code le plus performant sur 51% des 309 PRs :
Pour mesurer le classement, nous avons utilisé les scores du LLM-as-a-judge. Nous avons examiné quel outil de révision de code par IA a obtenu le score le plus élevé pour chaque PR (évalué à l'aide de notre LLM-as-a-judge), puis calculé le pourcentage de toutes les PRs dans lesquelles chaque outil s'est classé premier.
CodeRabbit a obtenu le score le plus élevé à la fois dans les évaluations humaines manuelles et les évaluations par LLM-as-a-judge, suivi par Greptile et GitHub Copilot :
Lors du calcul du score moyen, les trois catégories d'évaluation ont été pondérées de manière égale. Les scores des grands dépôts et des petits dépôts ont été évalués par LLM-as-a-judge, et les évaluations des développeurs ont été effectuées manuellement pour vérifier les scores du LLM-as-a-judge.
Évaluations humaines
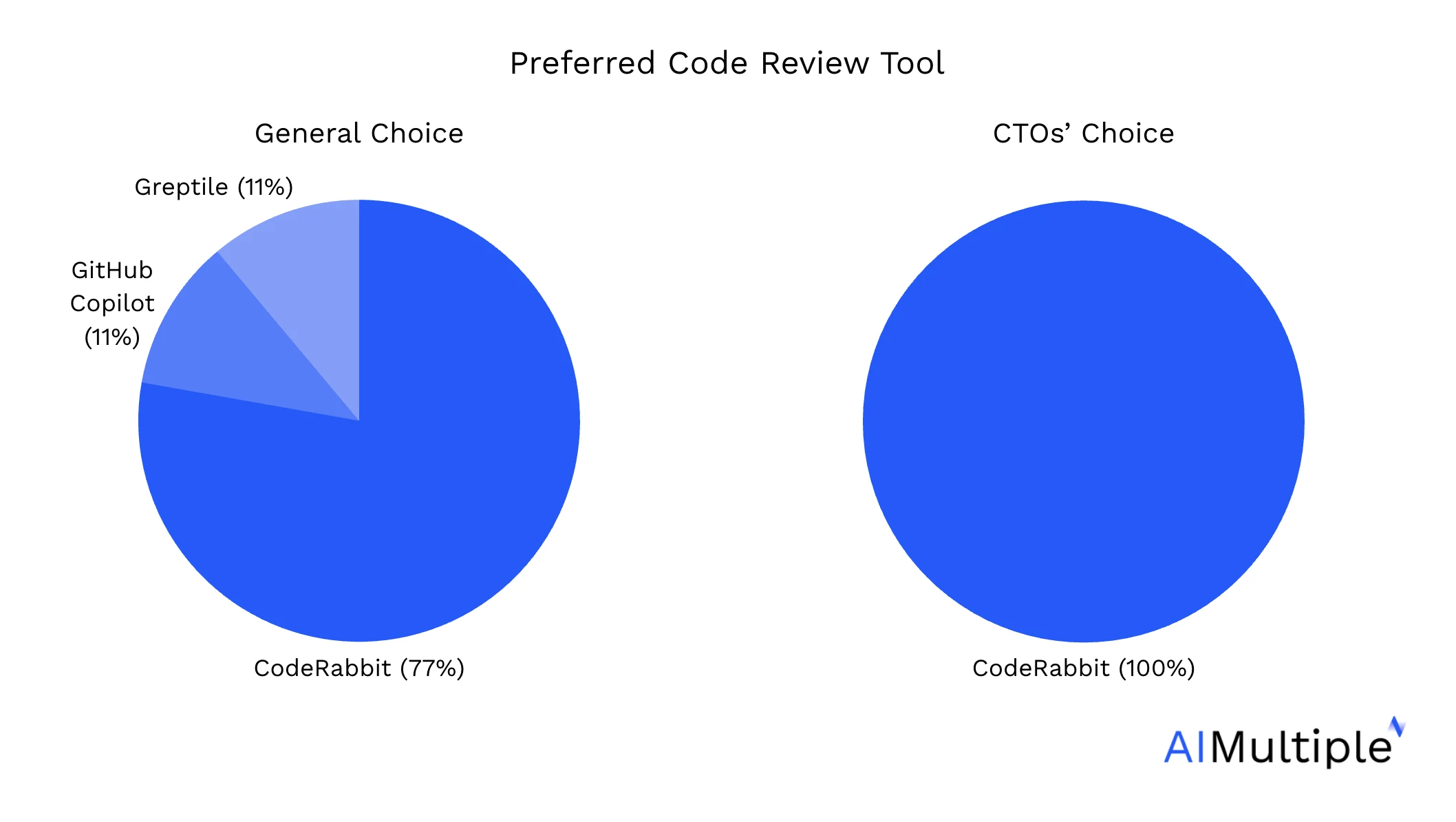
Nous avons demandé aux développeurs qui ont participé aux évaluations quel outil de révision de code par IA ils préféreraient intégrer dans leurs flux de travail. Étant donné que les CTO jouent un rôle décisionnel clé dans le développement logiciel, nous avons mis en évidence leurs réponses dans un graphique séparé :
Comparaison détaillée
Nous avons calculé le nombre moyen de bugs par PR en comptant tous les bugs/problèmes signalés par chaque outil de révision de code et en divisant par le nombre total de PRs (309). Toutes les PRs de notre base de code ne contiennent pas de bugs ou de problèmes. GitHub Copilot ne signale pas explicitement lorsqu'il détecte un bug dans une PR ; par conséquent, il a été exclu de cette comparaison.
Vous pouvez consulter notre méthodologie ci-dessous.
Fonctionnalités
* Fournie par la fonctionnalité « agentic pre-merge checks » de CodeRabbit. Elle valide automatiquement les pull requests par rapport aux normes de qualité et aux exigences organisationnelles personnalisées avant la fusion, et renvoie des résultats de réussite/échec avec des explications directement dans la procédure de PR. Chaque vérification peut être configurée pour avertir les développeurs ou bloquer entièrement les fusions. Bien que GitHub Copilot, Cursor BugBot et Greptile proposent des fonctionnalités de révision de PR, ils fonctionnent comme des systèmes consultatifs offrant des retours et des suggestions plutôt que comme des cadres de validation systématiques.
** Cursor et GitHub Copilot peuvent offrir plus de capacités au-delà de leurs composants de révision de code ; seules les fonctionnalités de Cursor Bugbot et de GitHub Copilot Code Review sont incluses dans notre comparaison.
Les fonctionnalités varient selon les plans d'abonnement, donc certaines fonctionnalités marquées comme disponibles ci-dessus peuvent ne pas être disponibles dans votre abonnement.
Dans les révisions de code automatisées, CodeRabbit, GitHub Copilot et Cursor Bugbot étaient plus faciles à configurer que Greptile car les révisions de code automatisées ne peuvent pas être activées pour un dépôt vide dans Greptile.
Analyse approfondie des fonctionnalités
CodeRabbit
- 40+ linters et scanners de sécurité intégrés.
- Instructions personnalisées basées sur les motifs AST.
- S'adapte aux retours des développeurs au fil du temps.
- Les développeurs peuvent taguer @coderabbitai pour poser des questions de suivi, demander des corrections, interroger les recommandations.
- Prend en charge les serveurs MCP personnalisés pour un contexte supplémentaire.
GitHub Copilot Code Review
- Le bouton « Implement suggestion » transmet la tâche à l'agent de codage Copilot.
- Intégration étroite avec l'écosystème GitHub.
- Instructions personnalisées via copilot-instructions.md.
Greptile
- Apprend les normes de codage de l'équipe à partir de l'historique des commentaires de PR.
- Avec les dépôts de motifs, les développeurs peuvent référencer des dépôts connexes dans greptile.json pour fournir un contexte supplémentaire.
- Les développeurs peuvent répondre avec @greptileai pour des questions de suivi ou des suggestions de correction.
- Greptile apprend des retours positifs/négatifs.
- Diagrammes de séquence auto-générés pour toutes les PRs.
Cursor BugBot
- Après qu'un bug est identifié par BugBot, les développeurs peuvent utiliser le bouton « Fix in Cursor » pour ouvrir rapidement Cursor afin de corriger le bug.
- Les développeurs peuvent personnaliser leurs règles de révision de code dans les fichiers BUGBOT.md.
Nous avions également l'intention d'évaluer Graphite ; cependant, en raison d'un bug dans leur tableau de bord, nous n'avons pas pu activer les révisions de code automatisées pour les nouveaux dépôts. Nous avons contacté leur équipe d'assistance le 25 octobre 2025, mais la réponse n'a pas résolu le problème. Malgré des e-mails de suivi et un message dans leur canal Slack, le problème est resté non résolu.
Composants et intégrations
* Toutes ces solutions prennent en charge GitHub.
Méthodologie
Nous avons créé des dépôts de benchmark distincts pour chaque outil au sein de notre organisation GitHub dédiée.
Après avoir activé les révisions de code automatiques pour chaque outil dans son dépôt assigné, nous avons ouvert des pull requests en séquence, attendu que l'outil termine sa révision, puis fermé les PRs pour enregistrer les résultats. Nous n'avons modifié ni ajusté aucun paramètre des outils. Chaque outil a été évalué en utilisant sa configuration par défaut, exactement telle qu'installée.
Notre flux de travail commence par le clonage du dépôt source tel qu'il existait à une date de référence sélectionnée, puis la relecture des pull requests soumises après cette date une par une, en préservant la structure originale du dépôt.
Nous avons utilisé les versions de novembre 2025 de tous les produits. Notre benchmark comprenait deux gammes différentes de dépôts sources :
1. Dépôts bien connus, de taille moyenne à grande
Nous avons cherché à voir dans quelle mesure les outils de révision de code par IA comprennent les dépôts aux structures larges et complexes. Nous avons fait réviser 289 PRs au total sur 7 dépôts.
2. Petits et nouveaux dépôts
Nous sommes conscients que nous ne pouvons pas fournir à notre LLM-as-a-judge l'
intégralité du dépôt dans les grands dépôts, car leurs fenêtres de contexte ne sont pas suffisantes pour cela. Par conséquent, pour surmonter cela, nous avons également évalué les 3 à 5 premières PRs de dépôts nouveaux et petits. Les serveurs MCP correspondent parfaitement à nos besoins. Nous avons donc choisi 8 serveurs MCP officiels et avons fait réviser 20 PRs sur ceux-ci.
Notre dataset contient du code écrit par des développeurs expérimentés. Nous n'avons pas évalué les performances sur des bases de code entièrement générées par IA.
Évaluations des développeurs
Nous avons sélectionné aléatoirement 35 PRs et les avons assignées à 10 développeurs, chaque PR étant évaluée 5 fois par des développeurs. Notre objectif en répétant l'évaluation était de minimiser les biais des développeurs. Les développeurs ont évalué les résultats de manière indépendante de tout fournisseur.
La plupart d'entre eux sont parvenus aux mêmes conclusions de haut niveau :
- Les révisions détaillées de CodeRabbit sont utiles, et il réussit bien dans la détection des bugs.
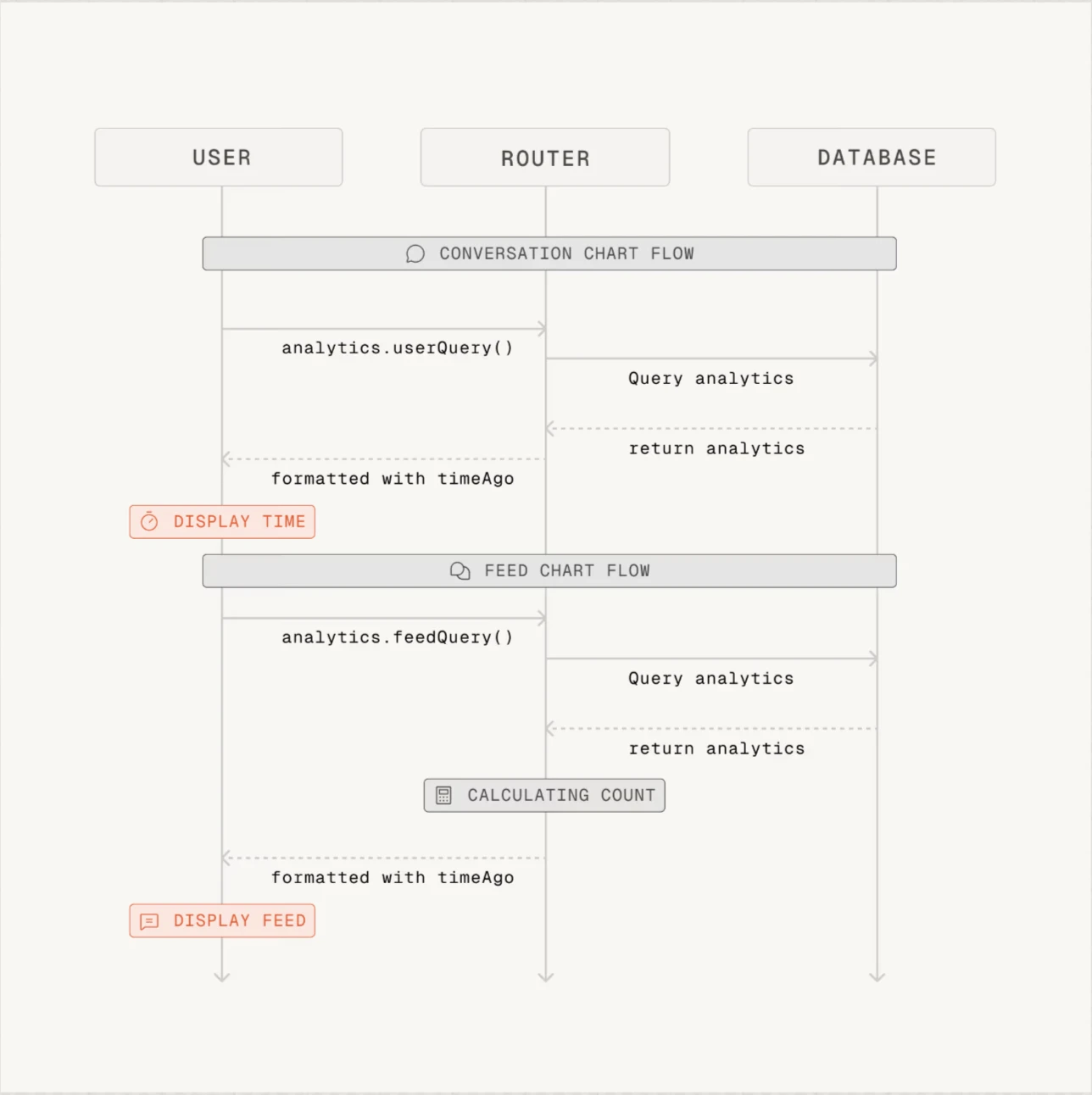
- Greptile a fourni des résumés réussis, mais les diagrammes de séquence qu'il a générés ne sont pas nécessaires pour certaines PRs.
Figure 1 : Exemple de diagramme de séquence fourni par Greptile. Greptile génère les diagrammes pour chaque PR.1
- GitHub Copilot réussit très bien à trouver les fautes de frappe dans le code et fait des suggestions pertinentes ; son analyse est plus courte que celles de CodeRabbit et Greptile.
- Cursor Bugbot fournit une analyse moins détaillée et moins précise.
Après les évaluations, ils ont également déclaré qu'ils commenceront à les utiliser dans leurs propres dépôts comme outil de support pour les développeurs.
LLM-as-a-Judge
Nous avons utilisé GPT-5 pour évaluer les révisions. Après l'évaluation, nous avons utilisé GPT-4o pour structurer la sortie au format JSON.
Notre flux de travail d'évaluation comprend :
- Pour les grands dépôts : le corps original de la PR, le diff et les commentaires/révisions des outils.
- Pour les petits dépôts : l'ensemble de la base de code, le corps original de la PR, le diff et les commentaires/révisions des outils.
Voici le prompt complet que nous avons utilisé :
Évaluez chaque outil sur ces dimensions (échelle 1-5) :
1. Exactitude
Les problèmes identifiés sont-ils réellement de vrais problèmes/bugs/corrections dans le code ?
– 5 (Excellent) : Tous les problèmes identifiés sont de vrais problèmes
– 4 (Bon) : La plupart des problèmes sont réels, quelques erreurs mineures d'identification
– 3 (Acceptable) : Mélange de vrais problèmes et de problèmes discutables
– 2 (Mauvais) : La plupart des problèmes identifiés ne sont pas de réels problèmes
– 1 (Échec) : Ne peut pas identifier les vrais problèmes, toutes les conclusions sont incorrectes
2. Complétude
A-t-il détecté les problèmes importants ? Dans quelle mesure la révision est-elle complète ?
– 5 (Excellent) : Détecte tous les problèmes critiques et la plupart des plus importants.
– 4 (Bon) : Détecte les problèmes majeurs, en manque quelques-uns mineurs
– 3 (Acceptable) : Détecte certains problèmes importants mais présente des lacunes notables
– 2 (Mauvais) : Manque plusieurs problèmes critiques
– 1 (Échec) : Manque tous ou presque tous les problèmes critiques
3. Actionnabilité
Les suggestions sont-elles claires et implémentables ? Inclut-il des correctifs ? S'il n'y a pas de bugs dans le code, écrivez « null » pour l'actionnabilité de tous les outils, ne donnez aucun score à aucun outil pour cette PR.
– 5 (Excellent) : Toutes les suggestions incluent des correctifs clairs et sont directement implémentables
– 4 (Bon) : La plupart des suggestions ont des indications claires, certaines incluent des correctifs
– 3 (Acceptable) : Les suggestions sont assez claires mais manquent de correctifs pour certains problèmes
– 2 (Mauvais) : Les suggestions sont pour la plupart peu claires ou non implémentables
– 1 (Échec) : Aucune suggestion ou indication claire fournie
4. Profondeur
Montre-t-il une compréhension de la logique et de l'objectif du code ?
– 5 (Excellent) : Démontre une compréhension approfondie de la logique du code, de l'architecture et de l'objectif
– 4 (Bon) : Montre une bonne compréhension avec des lacunes mineures
– 3 (Acceptable) : Compréhension superficielle, manque de contexte
– 2 (Mauvais) : Explications superficielles ou incorrectes du comportement du code
– 1 (Échec) : Aucune compréhension de la logique et de l'objectif du code
Format de sortie
Pour chaque outil, fournissez :
1. Raisonnement détaillé : Qu'a-t-il trouvé ? A-t-il manqué des problèmes importants ? Correctifs inclus ? Compréhension approfondie de la base de code ? Exemples spécifiques.
2. Scores individuels (1-5 pour chaque dimension, en utilisant l'échelle ci-dessus)
Exemple de sortie
Outil A :
Raisonnement : L'outil A a démontré une excellente exactitude en identifiant une véritable fuite de mémoire dans la logique de regroupement de connexions à la ligne 145, en fournissant un correctif spécifique utilisant un gestionnaire de contexte. Il a également détecté la gestion d'erreur manquante dans le endpoint API avec du code actionnable. Le score de complétude reflète que bien qu'il ait trouvé des problèmes majeurs, il a manqué la condition de concurrence dans le gestionnaire asynchrone qui pourrait causer des problèmes en production. Les 4 commentaires étaient substantiels et directement implémentables. La profondeur était forte, montrant une compréhension des motifs de gestion des ressources et de la propagation des erreurs dans la base de code.
Exactitude : 5
Complétude : 4
Actionnabilité : 5
Profondeur : 4
Outil B :
Raisonnement : L'outil B a correctement identifié la vulnérabilité de validation d'entrée à la ligne 89 et a fourni une correction claire utilisant l'assainissement des paramètres. Cependant, la complétude a considérablement souffert car il a manqué la vulnérabilité de sécurité critique dans le flux d'authentification qui permet la réutilisation des tokens. L'actionnabilité était principalement bonne – les suggestions incluaient des extraits de code. La profondeur était acceptable mais superficielle, se concentrant sur des vérifications de surface plutôt que sur la compréhension du modèle de sécurité ou des implications du flux de données.
Exactitude : 4
Complétude : 1
Actionnabilité : 4
Profondeur : 2
Outils à évaluer : CodeRabbit, Cursor Bugbot, Github Copilot, Greptile
Soyez objectif et approfondi. Utilisez des exemples spécifiques des révisions pour étayer vos scores.
Qu'est-ce que la révision de code par IA ?
La révision de code par IA est l'analyse automatisée du code source à l'aide de modèles de machine learning, principalement des grands modèles de langage (LLMs), pour identifier les bugs, les inefficacités et les vulnérabilités potentielles. En plus de détecter les problèmes, ces systèmes peuvent fournir des explications contextuelles, suggérer des corrections concrètes et générer des correctifs qui aident les développeurs à améliorer à la fois la qualité et la maintenabilité du code. De nombreux outils de révision par IA aident également à la documentation en résumant les modifications et en produisant des commentaires descriptifs ou des explications pour le code nouvellement ajouté.
Parce que les modèles d'IA peuvent évaluer le code rapidement et à grande échelle, ils accélèrent considérablement le processus de révision et facilitent la détection précoce des problèmes tout en maintenant des normes de codage cohérentes dans les projets de grande envergure ou à évolution rapide.
Dans les environnements de développement modernes assistés par IA tels que Cursor ou Claude Code, les développeurs peuvent involontairement perdre la trace de l'évolution de leur base de code lorsqu'ils pratiquent le « vibe coding » ou s'appuient fortement sur des suggestions auto-générées. Cela peut introduire des vulnérabilités cachées ou des incohérences logiques. Les outils de révision de code par IA aident à atténuer ces risques en fournissant une couche supplémentaire d'analyse structurée et systématique pour valider et améliorer le code généré par IA.
Avantages de la révision de code par IA
Efficacité et rapidité
Les outils de révision de code par IA peuvent analyser le code en temps réel, fournissant un retour immédiat et signalant les problèmes potentiels au fur et à mesure que les développeurs travaillent. Ils sont capables de détecter des erreurs et des vulnérabilités de sécurité que les réviseurs humains pourraient négliger, en particulier dans les bases de code volumineuses ou en évolution rapide. En automatisant les vérifications de routine, ces outils permettent aux développeurs de se concentrer sur le raisonnement de haut niveau, la résolution de problèmes complexes et les décisions architecturales.
Amélioration de la qualité du code
Les outils de révision de code par IA aident à maintenir des normes de codage cohérentes entre les équipes en identifiant les incohérences stylistiques et les écarts par rapport aux meilleures pratiques. Ils offrent également des retours détaillés et des recommandations sur un large éventail de problèmes de codage, des améliorations mineures aux bugs significatifs. Au fil du temps, les développeurs peuvent apprendre de ces retours, affiner leurs habitudes de codage et adopter de nouvelles techniques qui renforcent la qualité globale de leur travail.
Limites et défis
Dépendance excessive aux outils d'IA
Une préoccupation courante avec la révision de code par IA est la dépendance excessive aux retours automatisés. Bien que l'IA puisse être une source précieuse d'informations, elle ne doit pas être traitée comme un substitut complet à l'expertise humaine. Les révisions automatisées peuvent accélérer les flux de travail, mais les réviseurs humains restent essentiels pour garantir l'exactitude, la conscience du contexte et l'alignement avec les objectifs du projet. Dans notre benchmark, les développeurs ont constamment déclaré qu'ils ne s'appuieraient pas aveuglément sur ces outils. Ils les considéraient comme des assistants qui complètent le jugement humain plutôt que de le remplacer.
Gestion des faux positifs et des faux négatifs
Les faux positifs se produisent lorsque l'outil identifie incorrectement du code fonctionnel comme problématique, tandis que les faux négatifs se produisent lorsque de véritables problèmes ne sont pas détectés. Dans notre évaluation, la préoccupation la plus importante concernait les faux négatifs. Les outils étaient plus susceptibles de négliger des problèmes importants que de générer des avertissements incorrects. Cela souligne la nécessité d'une amélioration continue des modèles et algorithmes sous-jacents.
Pour relever ces défis, les outils de révision de code par IA doivent évoluer grâce à un meilleur entraînement, une gestion du contexte améliorée et des capacités de raisonnement plus précises.
Bonnes pratiques pour l'utilisation des révisions de code par IA
Conseils d'experts
Associez les révisions IA aux perspectives humaines : Utilisez les révisions de code par IA parallèlement aux révisions humaines pour garantir que le code est à la fois techniquement solide et aligné sur les objectifs du projet.
Personnalisez les règles en fonction de votre projet : Ajustez les règles de l'outil d'IA pour correspondre aux normes de codage de votre projet afin de réduire les alertes inutiles.
Utilisez les retours de l'IA comme outil d'apprentissage : Considérez les suggestions de l'IA comme un moyen d'apprendre et de s'améliorer, en les discutant avec votre équipe pour comprendre pourquoi et comment éviter des problèmes similaires à l'avenir.
Remerciements
Nous exprimons notre sincère gratitude aux développeurs qui ont contribué par leur temps et leur expertise à effectuer les évaluations manuelles :
Aziz Durmaz (CTO dans une entreprise de transport et logistique)
Berk Kalelioğlu (co-fondateur d'un studio de développement de jeux vidéo)
Elif Ece Örnek (ingénieure logicielle dans un site web de voyage)
Haydar Külekçi (consultant dans une entreprise de technologies de recherche et d'IA)
Mehmet Şirin Can (responsable du développement chez AIMultiple)
Mehmet Korkmaz (CTO dans une entreprise de médias dans l'industrie de l'e-sport et des jeux vidéo)
Murat Orno (ancien CTO d'une plateforme de paiement régionale avec 500+ employés)
Orçun Candan (développeur full-stack chez AIMultiple)
Yalçın Börlü (ingénieur logiciel senior dans une entreprise de santé et bien-être)
Yiğit Dinç (co-fondateur d'une entreprise de technologie juridique)
Nous remercions également les développeurs et les mainteneurs des dépôts open-source inclus dans notre benchmark pour leur travail et leurs précieuses contributions à la communauté.
Anonymisation des identités originales des développeurs
Pour mener le benchmark de manière responsable, nous avons anonymisé tous les noms et adresses e-mail des développeurs originaux lors de la relecture des pull requests des dépôts upstream. Parce que les dépôts du benchmark sont publics, préserver les informations originales des auteurs pourrait exposer involontairement des données personnelles et créer le risque de notifier les développeurs chaque fois qu'une pull request recréée est ouverte ou mise à jour. Bien que GitHub ne notifie généralement pas les auteurs lorsque leurs commits sont rejoués dans un dépôt séparé, nous avons considéré comme une bonne pratique d'éviter toute possibilité de notifications non désirées, de problèmes d'attribution ou de préoccupations de confidentialité.
L'anonymisation garantit que :
- Les développeurs ne sont pas dérangés par des milliers d'événements de PR automatisés.
- Les informations personnelles ne sont pas republiées dans un dépôt public différent.
- Les benchmarks restent impartiaux, empêchant les outils ou les juges LLM d'être influencés par des noms d'auteurs reconnaissables.
- Les normes éthiques et de confidentialité sont maintenues lors du travail avec des contributions open-source.
Seules les métadonnées d'identité ont été modifiées ; tout le code, les diffs, l'ordre des commits et les structures de fichiers ont été préservés exactement pour maintenir l'authenticité et la reproductibilité du benchmark.
Citez ce benchmark
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Alper, Şevval},
title = {{Évaluation comparative des outils de révision de code par IA}},
year = {2026},
month = mar,
howpublished = {\url{https://aimultiple.com/ai-code-review-tools}},
note = {AIMultiple. Consulté le 13 Mars 2026}
}
Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.