15 Outils d'observabilité des agents IA: AgentOps & Langfuse
Les outils d'observabilité des agents IA, tels que Langfuse et Arize, aident à collecter des traces détaillées (un enregistrement de l'exécution d'un programme ou d'une transaction) et fournissent des tableaux de bord pour suivre les métriques en temps réel.
De nombreux frameworks d'agents, comme LangChain, utilisent le standard OpenTelemetry pour partager les métadonnées avec la surveillance agentique. De plus, de nombreux outils d'observabilité fournissent une instrumentation personnalisée pour une plus grande flexibilité.
Nous avons testé 15 plateformes d'observabilité pour les applications LLM et les agents IA. Chaque plateforme a été implémentée de manière pratique en configurant des flux de travail, en paramétrant les intégrations et en exécutant des scénarios de test. Nous avons benchmarké 4 outils d'observabilité pour mesurer s'ils introduisent une surcharge dans les pipelines de production. Nous avons également démontré un tutoriel d'observabilité LangChain utilisant Langfuse.
Benchmark de surcharge des outils de surveillance agentique
Nous avons intégré chaque plateforme d'observabilité dans notre système de planification de voyage multi-agent et exécuté 100 requêtes identiques pour mesurer leur surcharge de performance par rapport à une référence sans instrumentation. Lisez notre méthodologie de benchmark.
- LangSmith a démontré une efficacité exceptionnelle avec pratiquement aucune surcharge mesurable, ce qui le rend idéal pour les environnements de production critiques en termes de performances.
- Laminar a introduit une surcharge minimale de 5%, ce qui le rend très adapté aux environnements de production où la performance est critique.
- AgentOps et Langfuse ont montré une surcharge modérée de 12% et 15% respectivement, proxy un compromis raisonnable entre les fonctionnalités d'observabilité et l'impact sur les performances. Ces plateformes maintiennent une latence acceptable pour la plupart des cas d'utilisation en production.
Raisons potentielles des différences de performance
Notre benchmark indique que les différences de latence sont dues à la profondeur de l'instrumentation et à l'implication dans le chemin d'exécution, en particulier dans les flux de travail multi-agents. Les outils offrant une observabilité plus profonde au niveau des étapes ont montré une surcharge plus élevée, tandis que les approches de traçage plus légères sont restées plus proches de la référence.
1. Profondeur d'instrumentation sur le chemin d'exécution
Les outils d'observabilité ajoutent de la logique au flux d'exécution de l'agent pour capturer les traces et les métadonnées. Lorsque cette logique s'exécute de manière synchrone pendant le traitement de la requête, elle augmente directement la latence de bout en bout car l'agent doit effectuer ce travail supplémentaire avant de renvoyer une réponse.
Par exemple :
- LangSmith n'a ajouté pratiquement aucune surcharge mesurable (~0%), indiquant peu de travail synchrone,
- L'instrumentation plus profonde au niveau des étapes de Langfuse a contribué à une surcharge plus élevée (~15%).
2. Amplification des événements dans les pipelines multi-étapes
Dans les systèmes multi-agents, une seule requête utilisateur déclenche plusieurs actions d'agent. Lorsqu'un outil enregistre des données détaillées à chaque étape, le nombre total d'événements augmente rapidement, augmentant la surcharge de traitement et de gestion des traces à mesure que le flux de travail s'approfondit.
Dans les résultats du benchmark :
- Langfuse et AgentOps ont généré une surcharge nettement plus élevée (15% et 12%) dans notre flux de travail de planification de voyage multi-étapes
- LangSmith et Laminar ont émis moins d'événements par étape d'agent.
3. Surcharge d'évaluation et de validation en ligne
Certaines plateformes effectuent des vérifications ou une surveillance supplémentaires pendant l'exécution de l'agent. Bien que chaque vérification soit légère, les appliquer de manière répétée à toutes les étapes de l'agent ajoute une latence mesurable.
Par exemple :
- La surveillance au niveau du cycle de vie d'AgentOps a coïncidé avec une surcharge de 12%
- Laminar n'a montré aucune preuve d'évaluation en ligne affectant l'exécution, restant à ~5%.
4. Fréquence de sérialisation et de persistance
La capture de données d'observabilité détaillées nécessite la sérialisation des traces et leur écriture dans le stockage ou les backends externes. Un niveau de détail de trace plus élevé augmente la fréquence à laquelle cela se produit, ajoutant une surcharge d'E/S à chaque requête.
Dans notre benchmark :
- Le traçage détaillé des prompts, des sorties et des tokens de Langfuse a entraîné la surcharge la plus élevée (~15%)
- Les artefacts de trace plus légers de LangSmith sont restés proches de la référence.
5. Degré d'intégration avec le framework d'agent
Le degré d'intégration d'un outil avec le framework d'agent affecte les performances. Les intégrations plus étroites réduisent les étapes de traduction et d'orchestration, tandis que les SDK plus génériques ajoutent des couches de traitement supplémentaires.
Par exemple :
- L'alignement étroit de LangSmith avec l'exécution de l'agent a été corrélé à une surcharge d'environ 0%
- AgentOps et Langfuse ont montré un impact de latence plus élevé, conforme à des chemins d'intégration plus découplés.
Plateformes d'observabilité des agents IA
Niveau 1 : Observabilité fine des LLM & prompts / sorties
* Les capacités listées dans ces colonnes sont des exemples illustratifs de ce que chaque outil peut surveiller lorsqu'il est étendu via des intégrations ou une personnalisation. Celles-ci ne sont pas exclusives à une seule plateforme.
Niveau 2 : Observabilité du flux de travail, du modèle et de l'évaluation
Niveau 3 : Observabilité du cycle de vie et des opérations de l'agent
Niveau 4 : Surveillance système et infrastructure (non natif agent)
Datadog (avec son module d'observabilité LLM) et Prometheus (via des exportateurs) sont de plus en plus utilisés aux côtés de Langfuse/LangSmith.
Plateformes de développement et d'orchestration d'agents :
- Des outils comme Flowise, Langflow, SuperAGI et CrewAI permettent de construire, d'orchestrer et d'optimiser les flux de travail des agents avec des interfaces sans code/low-code
Déploiement, éditions gratuites et tarification
Les éditions gratuites varient selon les limites d'utilisation (par ex., observations, traces, tokens ou unités de travail). Les prix de départ correspondent généralement à un forfait de base, qui peut comporter des restrictions sur les fonctionnalités, les utilisateurs ou les limites d'utilisation.
Weights & Biases (W&B Weave)
Cas d'utilisation : Déboguer les défaillances dans les systèmes multi-agents en traçant comment les erreurs se propagent à travers les appels d'agents.
Weights & Biases Weave enregistre des traces d'exécution structurées pour les systèmes multi-agents, en préservant les relations parent-enfant entre les appels d'agents. Les entrées, les sorties, les états intermédiaires, la latence et l'utilisation des tokens sont capturés par agent et par trace.
Fonctionnalités de surveillance de Weave
- Traçage hiérarchique des agents plutôt que des journaux de requêtes plats
- Attribution des coûts et de la latence au niveau de l'agent
- Support natif pour les évaluateurs appliqués directement aux traces.
Capacités d'évaluation
Weave fournit également des évaluateurs intégrés pour l'évaluation, notamment :
- HallucinationFreeScorer pour détecter les hallucinations,
- SummarizationScorer pour évaluer la qualité du résumé,
- EmbeddingSimilarityScorer pour la similarité sémantique,
- ValidJSONScorer et ValidXMLScorer pour la validation de format,
- PydanticScorer pour la conformité des schémas,
- OpenAIModerationScorer pour la sécurité du contenu,
- Des évaluateurs RAGAS comme ContextEntityRecallScorer,
- ContextRelevancyScorer pour l'évaluation de système RAG.
Idéal pour : Les équipes exécutant des flux de travail multi-étapes ou multi-agents qui ont besoin d'une analyse des causes profondes au niveau des traces plutôt que de métriques de surface.
Langfuse
Cas d'utilisation : Suivre les interactions LLM, gérer les versions de prompts et surveiller les performances du modèle avec les sessions utilisateur.
Langfuse offre une visibilité approfondie sur la couche des prompts, capturant les prompts, les réponses, les coûts et les traces d'exécution pour aider à déboguer, surveiller et optimiser les applications LLM.
Cependant, Langfuse peut ne pas convenir aux équipes qui préfèrent les flux de travail basés sur Git pour la gestion du code et des prompts, car son système de gestion de prompts externe peut ne pas offrir le même niveau de contrôle de version et de collaboration.
Fonctionnalités de surveillance de Langfuse
- Visibilité sur l'évolution des prompts et les schémas d'utilisation
- Analyse basée sur les sessions adaptée aux applications orientées utilisateur
- Modèle pratique de métadonnées et de tagging pour le filtrage et la révision
Fonctionnalités de niveau entreprise :
Certaines de ces fonctionnalités incluent :
- Niveaux de log : Ajustez la verbosité des logs pour des informations plus granulaires.
- Multi-modalité : Prend en charge le texte, les images, l'audio et d'autres formats pour les applications LLM multi-modales.
- Versions et versionnage : Suivez l'historique des versions et voyez comment les nouvelles versions affectent les performances du modèle.
- URLs de trace : Accédez aux traces détaillées via des URLs uniques pour une inspection et un débogage plus approfondis.
- Graphes d'agents : Visualisez les interactions et les dépendances des agents pour une meilleure compréhension du comportement des agents.
- Échantillonnage : Collectez des données représentatives des interactions à analyser sans submerger le système.
- Suivi des tokens et des coûts : Suivez l'utilisation des tokens et les coûts pour chaque appel de modèle, assurant une gestion efficace des ressources.
- Masquage : Protégez les données sensibles en les masquant dans les traces, assurant la confidentialité et la conformité.
Idéal pour : Les équipes itérant sur les prompts et surveillant l'utilisation en production, en particulier là où les sessions utilisateur sont importantes.
Galileo
Cas d'utilisation : Surveiller le coût/la latence, évaluer la qualité des sorties, bloquer les réponses dangereuses et fournir des correctifs exploitables.
Galileo suit les métriques de coût, de latence et de qualité des sorties tout en appliquant des vérifications de sécurité et de conformité en temps réel.
La plateforme combine l'observabilité traditionnelle (latence, coût, performance) avec le débogage et l'évaluation alimentés par l'IA (détection d'hallucinations, exactitude factuelle, cohérence, adhérence au contexte).
Fonctionnalités de surveillance de Galileo
- Identification des modes de défaillance au-delà des erreurs de surface (ex., hallucinations conduisant à des entrées d'outils invalides)
- Retour prescriptif tel que des suggestions de modification de prompt ou des ajouts few-shot
- Couplage étroit entre les résultats d'évaluation et les correctifs recommandés.
Idéal pour : Les organisations qui priorisent la qualité des sorties, la sécurité et les cycles d'itération rapides avec une remédiation guidée.
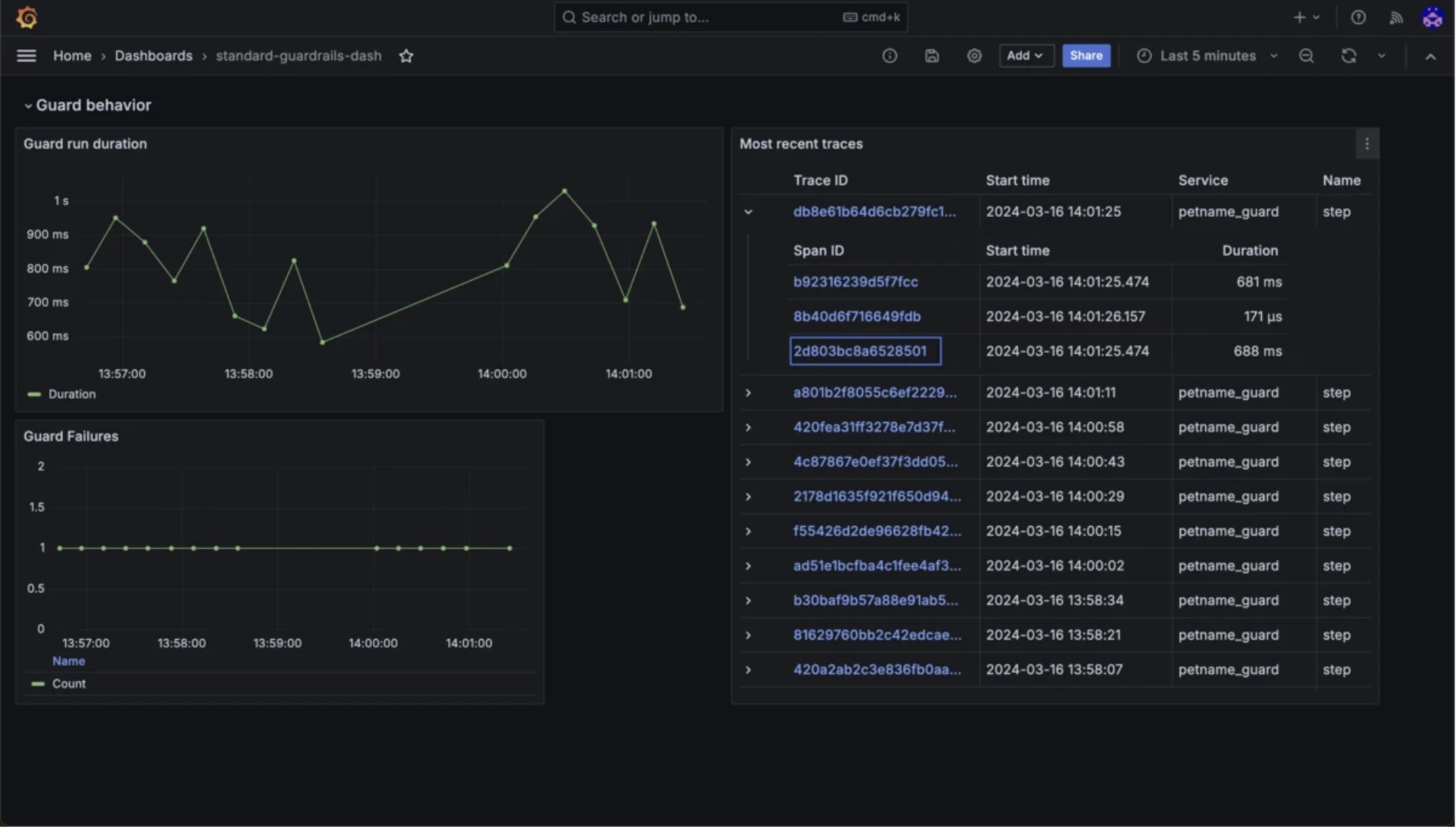
Guardrails IA
Cas d'utilisation : Prévenir les sorties nuisibles, valider les réponses LLM et assurer la conformité avec les politiques de sécurité
Guardrails valide les entrées et sorties LLM par rapport à des règles configurables, y compris la toxicité, les biais, l'exposition PII, les hallucinations de drapeau et la conformité de format.
Fonctionnalités de surveillance de Guardrails IA
- Validation déterministe via les spécifications RAIL
- Gardes d'entrée pour la détection d'injection de prompt et de jailbreak
- Nouvelles tentatives automatiques en cas d'échec de validation.
Idéal pour
Les équipes qui doivent appliquer des garanties strictes de sécurité, de conformité ou de formatage avant que les réponses ne soient renvoyées.
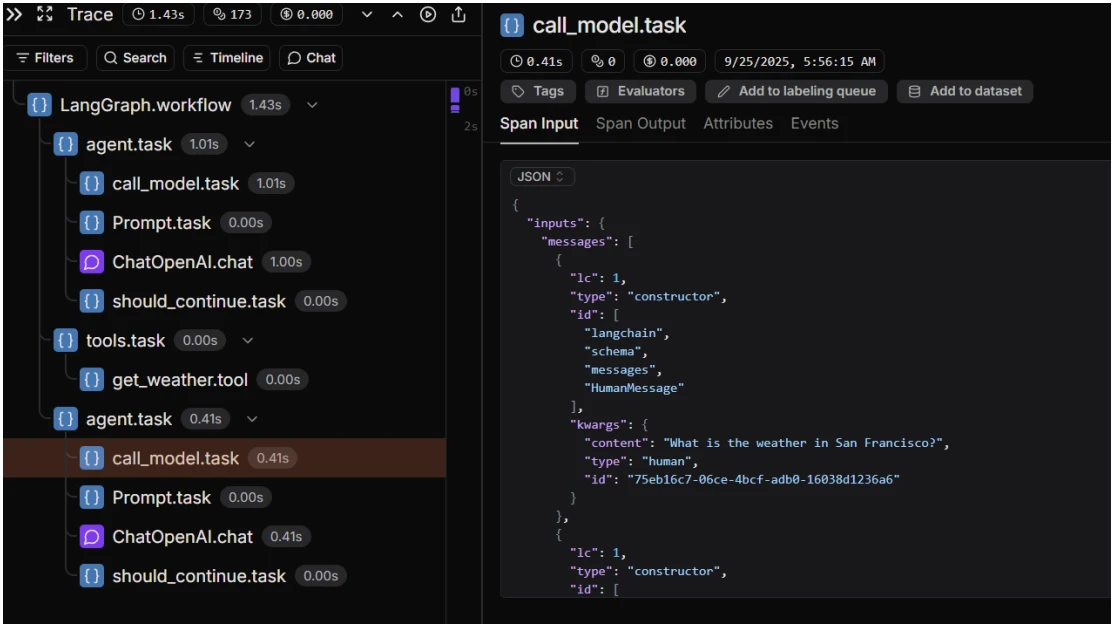
LangSmith
Cas d'utilisation : Débogage du raisonnement des agents et des appels d'outils (centré sur LangChain)
LangSmith capture des traces de raisonnement complètes pour les agents basés sur LangChain, y compris les prompts, le contexte récupéré, la logique de sélection d'outils, les entrées/sorties d'outils, les erreurs et les exceptions.
Fonctionnalités de surveillance de LangSmith
- Inspection étape par étape des chemins de décision des agents
- Relecture de l'exécution et comparaison côte à côte entre les prompts, modèles ou outils
- Intégration étroite avec LangChain via des callbacks.
Idéal pour
Les équipes construisant avec LangChain qui ont besoin de déboguer en détail un raisonnement incorrect ou l'invocation d'outils.
Langtrace IA
Cas d'utilisation : Identifier les goulots d'étranglement de coût et de latence dans les applications LLM
Langtrace suit le nombre de tokens, la durée d'exécution, les coûts API et les paramètres de requête à travers les pipelines LLM en utilisant des traces compatibles OpenTelemetry.
Fonctionnalités de surveillance de Langtrace IA
- Alignement OpenTelemetry pour l'intégration avec les backends existants
- Visibilité sur les facteurs de coût et de latence par étape
- Versionnage léger des prompts et environnement de test.
Idéal pour : Les équipes optimisant les performances et les dépenses à travers les flux de travail LLM plutôt que d'évaluer la qualité des sorties.
Arize (Phoenix)
Cas d'utilisation : Surveiller la dérive du modèle, détecter les biais et évaluer les sorties LLM avec des systèmes de notation complets
Phoenix se concentre sur la dérive comportementale, la détection de biais et la notation LLM-as-a-judge pour la pertinence, la toxicité et l'exactitude.
Cependant, il a une surcharge d'intégration plus élevée par rapport aux proxies légers et ne gère pas le versionnage des prompts aussi proprement que les outils dédiés.
Fonctionnalités de surveillance de Phoenix
- Cœur open-source avec extensions d'entreprise optionnelles
- Environnement de développement de prompt interactif
- Détection de dérive pour suivre les changements de comportement dans le temps
- Vérifications de biais pour identifier les biais de réponse,
- Notation LLM-as-a-judge pour l'exactitude, la toxicité et la pertinence.
Idéal pour : Les équipes surveillant le comportement du modèle à long terme et le risque de régression plutôt que l'itération de prompt.
Agenta
Cas d'utilisation : Trouver quel prompt fonctionne le mieux sur quel modèle
Agenta compare les réponses des modèles en termes de coût, de latence et de qualité des sorties en utilisant des entrées partagées et un contexte contrôlé.
Fonctionnalités de surveillance d'Agenta
- Évaluation côte à côte des modèles
- Aide à la décision en pré-production.
Idéal pour : L'évaluation en phase précoce et la sélection de modèles.
AgentOps.ai
Cas d'utilisation : Surveiller le raisonnement des agents, suivre les coûts et déboguer les sessions en production
AgentOps capture les traces de raisonnement, les appels d'outils/API, l'état de session, le comportement de mise en cache et les métriques de coût pour les agents déployés.
Fonctionnalités de surveillance d'AgentOps
- Relecture de session pour le débogage en production
- Accent sur le comportement des agents en direct plutôt que sur l'évaluation hors ligne.
Idéal pour : Les équipes exécutant des agents en production qui ont besoin de visibilité opérationnelle.
Braintrust
Cas d'utilisation : Trouver quel prompt, dataset ou modèle fonctionne le mieux avec une évaluation détaillée et une analyse des erreurs
Braintrust évalue les prompts, les datasets et les modèles par rapport aux sorties attendues, en suivant la latence, le coût, les erreurs d'outils et les métriques d'exécution.
Fonctionnalités de surveillance de Braintrust
- Évaluer des datasets de test avec des entrées et des sorties attendues, puis comparer les prompts ou les modèles côte à côte en utilisant des variables comme
{{input}},{{expected}}et{{metadata}}. - Ventilations des métriques incluant la qualité d'exécution des outils
Idéal pour : Les équipes benchmarkant les modèles et les prompts avant le déploiement.
AgentNeo
Cas d'utilisation : Déboguer les interactions multi-agents, tracer l'utilisation des outils et évaluer les flux de travail de coordination
AgentNeo suit la communication des agents, l'utilisation des outils, les graphes d'exécution et le coût et la latence par agent via un SDK Python.
Fonctionnalités de surveillance d'AgentNeo
- Open-source et exécutable localement
- Tableau de bord local interactif (
localhost:3000) pour la surveillance en temps réel des flux de travail multi-agents. - Intégration utilisant des décorateurs (ex.,
@tracer.trace_agent,@tracer.trace_tool)
Idéal pour : Les équipes d'ingénierie expérimentant avec des systèmes multi-agents.
Laminar
Cas d'utilisation : Suivre les performances à travers différents LLM frameworks et modèles.
Laminar suit les spans d'exécution, les coûts, l'utilisation des tokens et les percentiles de latence à travers les frameworks et modèles LLM.
Fonctionnalités de surveillance de Laminar
- Analyse de performance agnostique au framework
- Inspection fine des spans.
Idéal pour : L'analyse comparative des performances à travers des piles hétérogènes.
Helicone
Cas d'utilisation : Suivre les flux de travail multi-étapes des agents et analyser les schémas de session utilisateur.
Helicone capture les volumes de requêtes, les coûts, les erreurs, les tendances de latence et les flux de travail des agents au niveau de la session.
Fonctionnalités de surveillance d'Helicone
- Visibilité du parcours utilisateur
- Analyse des tendances historiques.
Idéal pour : Les équipes produit surveillant les schémas d'utilisation et le comportement au niveau de l'utilisateur.
Coval
Cas d'utilisation : Simuler des milliers de conversations d'agents, tester les interactions vocales/chat et valider le comportement avant le déploiement.
Coval simule des milliers de conversations pour mesurer l'achèvement des tâches, l'exactitude et l'efficacité des appels d'outils.
Fonctionnalités de surveillance de Coval
- Tests d'agents basés sur la simulation
- Détection automatique de régression
- Support des agents vocaux et textuels.
Idéal pour : La validation avant déploiement et la détection de régression.
Datadog
Cas d'utilisation : Observabilité de l'infrastructure et des applications avec corrélation des signaux LLM.
Datadog collecte les métriques d'infrastructure (CPU, mémoire, réseau), les données de performance des applications (latence, taux d'erreur, débit) et les logs. Pour les applications LLM, il peut ingérer l'utilisation des tokens, le coût par requête, la latence du modèle et les signaux liés à la sécurité tels que les tentatives d'injection de prompt.
Fonctionnalités de surveillance de Datadog
- Observabilité étendue à l'échelle du système sur l'infrastructure, les applications et les charges de travail IA
- Large écosystème d'intégration (900+ intégrations) permettant la corrélation entre le comportement de l'IA et la santé de l'infrastructure
Idéal pour : Les organisations qui veulent corréler le comportement LLM avec l'infrastructure sous-jacente et la performance des applications plutôt que d'inspecter le raisonnement de l'agent ou le prompt
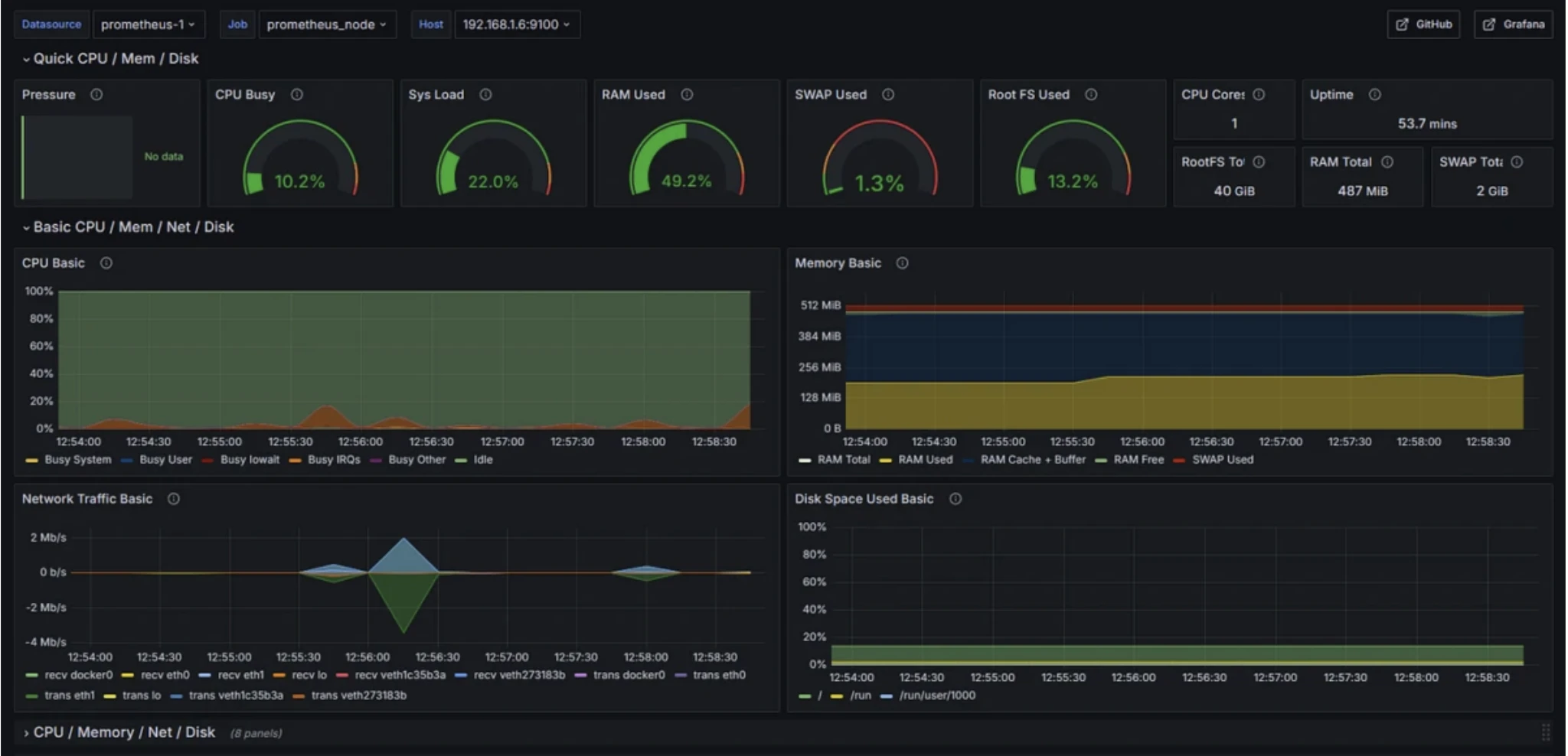
Prometheus
Cas d'utilisation : Surveiller la performance du système, suivre les métriques d'application et configurer des alertes pour les problèmes d'infrastructure.
Prometheus est un système de surveillance open-source qui collecte (scrape) des métriques de séries temporelles à partir de points de terminaison HTTP à intervalles réguliers pour suivre l'infrastructure, les applications, les bases de données, les conteneurs et les métriques métier personnalisées.
Fonctionnalités de surveillance de Prometheus
- Collecte de métriques de séries temporelles via le scraping basé sur le pull
- PromQL pour l'interrogation, l'agrégation et les conditions d'alerte
- Écosystème d'exportateurs (ex., Node Exporter) pour une couverture système étendue
Idéal pour : La surveillance de l'infrastructure et des applications avec des alertes basées sur des règles.
Grafana
Cas d'utilisation : Visualiser les métriques, construire des tableaux de bord et router les alertes à travers les données LLM, d'agent et d'infrastructure.
Grafana est une plateforme de visualisation et d'analytique open-source qui s'intègre avec des sources de données telles que Prometheus, OpenTelemetry et Datadog pour fournir des tableaux de bord d'observabilité unifiés.
Fonctionnalités de surveillance de Grafana
- Tableaux de bord couvrant les métriques, les logs et les traces
- Corrélation inter-systèmes pour les signaux LLM, d'agent et d'infrastructure
- Routage d'alertes et gestion des notifications.
Idéal pour : La visualisation centralisée de l'observabilité et la réponse aux incidents.
Tutoriel : Observabilité LangChain avec Langfuse
Nous avons construit un pipeline LangChain multi-étapes avec trois étapes :
- analyse de la question
- génération de réponse
- vérification de la réponse
Après avoir configuré le pipeline, nous l'avons connecté à Langfuse pour surveiller et suivre l'exécution en temps réel. Ce faisant, nous avons pu explorer comment Langfuse nous aide à recueillir des informations détaillées sur les performances, les coûts et le comportement de l'application IA.
Voici ce que nous avons observé via Langfuse :
Aperçu du tableau de bord
Langfuse nous a fourni plusieurs tableaux de bord qui nous donnent une visibilité sur différents aspects de la performance du pipeline :
- Tableau de bord des coûts : Il suit les dépenses sur tous les appels API, avec des ventilations détaillées par modèle et par période.
- Gestion de l'utilisation : Il surveille les métriques d'exécution, telles que le nombre d'observations et l'allocation des ressources, nous aidant à suivre comment les ressources sont utilisées pendant l'exécution.
- Tableau de bord de latence : Ce tableau de bord nous a aidés à analyser les temps de réponse, à détecter les goulots d'étranglement et à visualiser les tendances de performance.
Métriques d'utilisation
Le tableau de bord des métriques d'utilisation nous a donné les informations suivantes sur la performance du système :
- Nombre total de traces : Nous avons suivi huit traces, chacune proxy un cycle complet de question-réponse dans le pipeline.
- Nombre total d'observations : En moyenne, chaque trace avait 16 observations, reflétant la nature multi-étapes du processus.
De plus, Langfuse nous permet de suivre les schémas d'utilisation, l'allocation des ressources et les heures de pointe au cours des 7 derniers jours, nous aidant à comprendre quand le système est le plus actif et comment les ressources sont réparties dans le temps.
Inspection des traces
En explorant une trace individuelle, nous avons pu voir des informations d'exécution détaillées :
- Lignes de trace : Chaque ligne représente une exécution complète du pipeline avec un ID de trace unique.
- Métriques de latence : Le temps d'exécution variait, allant de 0.00s à 34.08s.
- Nombre de tokens : Le tableau de bord suivait l'utilisation des tokens d'entrée/sortie, ce qui aide à la gestion des coûts et de l'efficacité.
- Filtrage par environnement : Nous pouvions filtrer les traces en fonction des environnements de déploiement (ex., développement, production).
Détails d'une trace individuelle
Nous avons exploré la trace plus en détail pour comprendre la décomposition de l'exécution :
- Architecture de chaîne séquentielle : La trace affichait un flux visuel montrant chaque étape, en partant de SequentialChain → LLMChain → ChatOpenAI, avec une structure hiérarchique.
- Suivi des entrées/sorties : La question originale, « Quels sont les avantages d'utiliser Langfuse pour l'observabilité des agents IA ? » a été suivie à chaque étape, ainsi que les sorties respectives produites par l'IA à chaque étape.
- Analyse des tokens : Nous avons observé que 1 203 tokens ont été utilisés pour l'entrée et 1 516 tokens pour la sortie, ce qui a des implications de coût liées à l'utilisation des tokens et aide à optimiser la gestion des ressources.
- Données de temporisation : La latence totale pour la trace complète était de 34.08s, décomposée pour chaque composant :
- SequentialChain → 14.02s
- LLMChain → 10.25s
- ChatOpenAI → 9.81s
- Informations sur le modèle : Langfuse a confirmé l'utilisation du modèle Anthropic Claude-Sonnet-4, avec des détails sur les paramètres spécifiques, y compris la configuration de la température.
- Sortie formatée : Les vues Preview et JSON étaient fournies pour le débogage, donnant des informations sur la réponse du modèle sous forme lisible par l'homme et sous forme lisible par machine.
Analyse automatisée
Langfuse a également fourni des évaluations automatisées de nos réponses :
- Évaluation de la qualité : Le système a évalué la structure, la cohérence et la complétude des réponses, soulignant des sections bien organisées mais suggérant que les réponses pourraient être plus concises.
- Suggestions d'amélioration : Il a identifié les sections avec redondance, suggérant où la formulation pourrait être améliorée, et a combiné les points connexes pour rendre la réponse plus transparente et plus efficace.
- Aperçus de performance : Le système a donné un retour sur l'utilisation des tokens et la pertinence de la réponse, nous aidant à optimiser l'efficacité tout en garantissant que la sortie reste utile et pertinente.
- Retour structuré : Le retour était organisé en catégories, nous permettant d'aborder des domaines spécifiques d'amélioration de manière ciblée.
Analytique utilisateur
Langfuse suit les interactions détaillées entre les utilisateurs et l'agent IA :
- Chronologie d'activité des utilisateurs : Affiche la première et la dernière interaction pour chaque utilisateur, aidant à identifier les utilisateurs actifs par rapport aux utilisateurs dormants. Nous pouvons voir quand les utilisateurs ont interagi avec le système pour la première et la dernière fois.
- Suivi du volume d'événements : Suit le nombre d'événements déclenchés par chaque utilisateur. Par exemple, certains utilisateurs ont généré plus de 2 000 événements, montrant leur niveau d'engagement avec le système.
- Analyse de la consommation de tokens : Surveille le nombre total de tokens consommés par chaque utilisateur. L'utilisation des tokens variait de 6,59K à 357K tokens, fournissant des informations sur l'utilisation des ressources.
- Attribution des coûts : Décompose les coûts associés à chaque utilisateur, facilitant le suivi des dépenses et l'optimisation de l'allocation budgétaire pour l'utilisation des ressources.
- Identification de l'utilisateur : Utilise des identifiants utilisateur anonymisés pour maintenir la confidentialité tout en suivant les interactions individuelles des utilisateurs, aidant à l'analyse de l'utilisation sans compromettre la confidentialité des utilisateurs.
La vue de session nous permet de suivre les détails granulaires des interactions utilisateur :
- Flux de conversation complet : Montre l'interaction complète question-réponse, facilitant le suivi de toute la conversation du début à la fin.
- Visibilité de l'implémentation : Affiche le code Python réel utilisé pendant la session, donnant un aperçu de l'implémentation technique.
- Corrélation entrée/sortie : Lie les questions des utilisateurs aux réponses correspondantes du système, nous aidant à dépanner et à identifier où des problèmes ont pu survenir dans la conversation.
- Métadonnées de session : Inclut des détails techniques tels que le minutage, le contexte utilisateur et les données d'implémentation spécifiques, offrant une vue complète de l'exécution de la session.
Quand ne pas utiliser les outils d'observabilité
- Développement en phase précoce : Si vous êtes encore en train de valider l'adéquation produit-marché ou de construire vos premiers flux de travail d'agents, l'accent devrait être mis sur la fonctionnalité de base plutôt que sur une observabilité étendue.
- Goulots d'étranglement API : Si vos principaux problèmes sont les coûts d'API, la latence ou la mise en cache, la priorité immédiate devrait être d'optimiser ces domaines, et non de suivre les métriques au niveau du système.
- Optimisation du modèle : Si les améliorations sont principalement motivées par la sélection du modèle, le fine-tuning ou l'ingénierie des prompts, les outils d'observabilité pour la dérive et les biais peuvent ne pas encore être nécessaires.
Quand utiliser les outils d'observabilité
- Production à grande échelle : Lorsque vous opérez avec plusieurs modèles, agents ou chaînes, les outils d'observabilité sont essentiels pour surveiller les performances et garantir la santé du système.
- Applications orientées entreprise ou client : Pour les applications où la fiabilité, la sécurité et la conformité sont non négociables, les outils d'observabilité fournissent la visibilité et le contrôle nécessaires.
- Surveillance continue : Lorsque vous devez surveiller la dérive, les biais, les performances et les problèmes de sécurité au fil du temps, qui ne peuvent pas être facilement capturés avec des scripts de base ou des vérifications manuelles, les outils d'observabilité sont cruciaux.
- Scénarios à haut risque : Dans les environnements où le coût d'une défaillance (ex., hallucinations, sorties dangereuses) est significatif, l'observabilité garantit que les risques sont minimisés et que les problèmes sont détectés tôt.
Méthodologie du benchmark
Pour évaluer la surcharge de performance des plateformes d'observabilité dans les applications LLM en production, nous avons développé une approche de benchmarking systématique utilisant un flux de travail agentique réel.
Application de test
Nous avons construit un système de planification de voyage multi-agent séquentiel utilisant LangChain qui traite les requêtes de voyage en langage naturel à travers cinq étapes :
- Agent analyseur : Extrait les données structurées (origine, destination, dates, durée) de l'entrée utilisateur
- Agent de recherche de vols : Récupère les vols disponibles via l'API Amadeus
- Agent de rapport météo : Récupère les prévisions météo de destination en utilisant WeatherAPI
- Agent de recommandation d'activités : Suggère des activités en fonction des conditions météorologiques
- Agent planificateur de voyage : Synthétise toutes les sorties en un itinéraire complet
Le système utilise Claude 4 Haiku via OpenRouter pour tous les appels LLM et intègre des APIs externes pour les données en temps réel.
Conception du benchmark
Établissement de la référence : Nous avons d'abord mesuré la performance de l'application sans aucune instrumentation d'observabilité, en exécutant 100 requêtes identiques pour établir une référence de comparaison.
Intégration de la plateforme : Nous avons ensuite intégré cinq plateformes d'observabilité leaders (LangSmith, Laminar, AgentOps, Langfuse) une par une, en instrumentant les mêmes points de traçage sur toutes les plateformes pour assurer la cohérence.
Exécution séquentielle : Chaque plateforme a été testée indépendamment en exécutant toutes les 100 requêtes consécutivement avant de passer à la plateforme suivante. Cette approche minimise la variabilité due aux facteurs externes comme les conditions réseau ou les limites de taux d'API.
Environnement contrôlé : Tous les tests ont été exécutés sur la même infrastructure de serveur avec des ensembles de requêtes identiques pour assurer une comparaison équitable. Pour isoler la surcharge des variations de latence induites par le LLM, nous avons configuré le modèle avec temperature=0 et structuré les prompts pour minimiser la variabilité des réponses entre les exécutions.
Métriques collectées
Pour chaque plateforme, nous avons mesuré la latence moyenne et calculé la surcharge comme la latence supplémentaire introduite par rapport à la référence : ((Platform Latency - Base Latency) / Base Latency) × 100
FAQ
L'observabilité est la capacité à comprendre le fonctionnement interne d'un agent IA en examinant les signaux externes tels que les logs, les métriques et les traces.
Pour les agents IA, cela implique de surveiller les actions, l'utilisation des outils, les interactions avec les modèles et les réponses pour dépanner et améliorer les performances.
L'observabilité des agents est cruciale pour suivre et améliorer les performances de l'IA en permettant :
Comprendre les compromis : Elle aide à mesurer les métriques clés comme l'exactitude et le coût, facilitant l'équilibre entre la performance et l'utilisation des ressources.
Mesurer la latence : Le suivi de la latence en temps réel offre des informations sur les temps de réponse, aidant à optimiser les performances des agents.
Détecter les entrées malveillantes : L'observabilité aide à identifier les langages nuisibles et les injections de prompts, permettant une intervention rapide pour prévenir les problèmes.
Surveillance des retours utilisateurs : En observant les interactions et les retours des utilisateurs, l'observabilité fournit des données précieuses pour l'amélioration continue et le fine-tuning des agents.
Les composants clés incluent :
– Suivi des actions : Surveiller chaque étape prise par l'agent.
– Utilisation des outils : Observer les outils et ressources que l'agent utilise.
– Mesure de la latence : Surveiller les temps de réponse pour optimiser les performances.
– Évaluations : Évaluer le comportement de l'agent et les performances du modèle.
– Détection d'entrées malveillantes : Identifier les prompts nuisibles ou les attaques.
Citer cette recherche
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{15 Outils d'observabilité des agents IA: AgentOps & Langfuse}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/agentic-monitoring}},
note = {AIMultiple. Consulté le 2 Juillet 2026}
}














.")





Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.