L'avenir des grands modèles de langage
Découvrez l'avenir des grands modèles de langage en explorant des approches prometteuses, telles que l'auto-entraînement, la vérification des faits et l'expertise éparse, qui pourraient remédier aux limites des LLM.
Comparaison des taux de succès des LLMs
Claude Sonnet 4.6 a dominé le benchmark avec un score global de 0.748, les variantes de base et de réflexion étant à égalité jusqu'à la troisième décimale. Claude Opus 4.8 (0.702), Opus 4.6 base (0.706) et Opus 4.6 réflexion (0.729) ont suivi, conférant à Anthropic les cinq premières positions. Le premier modèle non-Anthropic était Gemini 3.5 Flash, en mode réflexion avec 0.625. Les variantes GPT se sont regroupées entre 0.57 et 0.60, les scores backend plus élevés étant compensés par une instabilité frontend. Pour en savoir plus, consultez notre article de benchmark.
Méthodologie du benchmark LLM
Nous avons évalué les principaux grands modèles de langage sur 10 tâches de développement logiciel en utilisant un harnais CLI agentique. Chaque modèle a été exécuté 3 fois par tâche (30 échantillons par modèle, 270 cellules de validation par itération) pour stabiliser les scores et mesurer la variance par cellule. Tous les modèles ont été accessibles via OpenRouter dans des conditions identiques, même harnais, mêmes instructions de tâche, même environnement matériel.
Modèles testés
Le benchmark couvre les modèles disponibles via API en juin 2026. Toutes les variantes listées ci-dessous ont été testées indépendamment :
- Claude Sonnet 4.6 (base et réflexion)
- Claude Opus 4.8
- Claude Opus 4.6 (base et réflexion)
- Claude Opus 4.7
- Gemini 3.5 Flash (base et réflexion)
- GPT 5.5 (réflexion)
- GPT 5.4 Mini
- GPT 5.3 Codex
- MiniMax M3
- Grok 4.3
- Qwen 3.6 Plus (base et réflexion)
- GLM 5.1 (base et réflexion)
- DeepSeek V4 Pro (base et réflexion)
Environnement de test
Chaque agent et chaque tâche démarrent dans un environnement propre. Les instructions de tâche sont fournies sous forme de fichier TASK.md. Un chien de garde de 20 minutes surveille chaque exécution. Nous enregistrons les codes de sortie, le temps d'exécution, la création de fichiers backend et frontend, et l'utilisation de tokens en temps réel dans les catégories d'entrée, de sortie et de cache.
Les tâches vont des systèmes de réservation aux tableaux de bord interactifs. Toutes nécessitent une gestion de projet multi-fichiers et un livrable full-stack fonctionnel.
Notation
Validation backend : Les projets générés sont déployés dans des environnements isolés et testés par rapport à un contrat YAML canonique couvrant les scénarios de succès, la gestion des erreurs (400/403/409) et la cohérence des données. Deux modes sont utilisés :
- Mode adaptatif valide la fonctionnalité même lorsque les noms des routes diffèrent de la spécification
- Mode strict exige une adhérence exacte au contrat (routes, codes de statut, champs de réponse)
Score backend par cellule : backend_overall = has_backend × (0.7 × adaptive_pass_rate + 0.3 × strict_pass_rate)
Validation UI : L'automatisation du navigateur simule des flux utilisateurs réels, y compris les pré-vérifications, le rendu, la soumission de connexion et le comportement post-connexion. Huit étapes réparties en deux groupes :
- Étapes d'infrastructure (pré-vérification backend, rendu frontend, formulaire de connexion visible, soumission de connexion, connexion 2xx, pas de plantage d'exécution)
- Étapes de comportement (signal d'authentification post-connexion, signal de comportement post-connexion)
Score UI par cellule : ui_score = (behavior_passed / (behavior_passed + behavior_failed)) × (infra_passed / infra_total)
Les étapes de comportement bloquées sont exclues du dénominateur de comportement afin qu'une cellule ne soit pas doublement pénalisée lorsque l'application ne se charge pas.
Score final : Final Score = (0.7 × backend_overall) + (0.3 × ui_score)
Le backend a un poids plus élevé car les défaillances logiques au niveau de l'API invalident généralement tout succès frontend.
Mesure des coûts
Le coût par cellule est calculé à partir de l'utilisation des tokens extraite de la réponse de l'LLM API. Les tokens d'entrée en cache sont soustraits du total des tokens d'entrée pour obtenir l'entrée effective (tokens nouvellement traités uniquement). Les tokens de sortie ne sont jamais mis en cache et restent inchangés. Les tarifs par token proviennent de LLM Pricing au moment du test.
Limites
- Périmètre des tâches : Les 10 tâches sont toutes des constructions d'applications web full-stack. Le benchmark ne couvre pas les tâches de raisonnement pur, la résolution de problèmes scientifiques, le résumé ou les charges de travail spécifiques à un domaine (juridique, médical, financier). Les scores reflètent spécifiquement la capacité de codage agentique.
- Accès API uniquement : Tous les modèles ont été testés via l'API. Les déploiements locaux ou sur site des mêmes modèles peuvent produire des résultats différents selon la quantification, le matériel et la configuration d'inférence.
- Capture instantanée : Les versions des modèles changent. Les résultats reflètent la version de l'API active au moment du test. Une mise à jour du modèle peut faire évoluer les scores dans un sens ou dans l'autre sans préavis du fournisseur.
- Style d'appel d'outil : Les modèles diffèrent dans la manière dont ils structurent les écritures et les modifications de fichiers (par exemple,
apply_patchd'OpenAI regroupe un diff complet du fichier en un seul appel ; les modèles Anthropic écrivent et rééditent sur plusieurs appels). Le nombre d'appels d'outils n'est pas un indicateur direct de la qualité. - Harnais unique : Tous les tests ont utilisé Opencode comme harnais d'agent. Un harnais différent peut produire des classements relatifs différents, en particulier pour les modèles dont le comportement par défaut est optimisé pour des modèles d'utilisation d'outils spécifiques.
Tendances futures des grands modèles de langage
1- Vérification des faits en temps réel avec des données en direct
Les LLM accèdent à des sources externes lors des conversations au lieu de se fier uniquement aux données d'entraînement. Le modèle interroge des bases de données externes, récupère des informations actuelles et fournit des citations.
Limite : Fait encore des erreurs. Les citations ne garantissent pas l'exactitude ; les modèles citent parfois des sources de manière incorrecte ou interprètent mal le contenu cité.
Microsoft Copilot : Intègre GPT-5.4 Thinking avec des données Internet en direct, introduisant les modes « Quick Response » et « Think Deeper » pour un raisonnement adapté à différents types de tâches.1 L'agent Researcher combine GPT pour la recherche initiale avec Anthropic Claude examinant les résultats pour l'exactitude et la qualité des citations avant livraison, ce qui donne une amélioration de 13.8% sur le benchmark de recherche approfondie DRACO par rapport aux systèmes autonomes.2
- ChatGPT : Recherche sur le web lorsqu'on l'interroge sur des événements récents. Cite des sources dans les réponses.
- Perplexity : Conçu spécifiquement pour la recherche citée. Chaque réponse inclut des liens vers les sources.
2- Données d'entraînement synthétiques
Les modèles génèrent leurs propres jeux de données d'entraînement au lieu de nécessiter des données étiquetées par des humains.
Modèle auto-améliorant de Google (recherche 2023) :
- Le modèle crée des questions
- Élabore des réponses
- S'ajuste finement sur les données générées
Amélioration des performances : de 74.2% à 82.1% sur les problèmes mathématiques GSM8K, de 78.2% à 83.0% sur la compréhension de lecture DROP.
OpenAI, Anthropic et Google utilisent tous des données synthétiques pour compléter les jeux de données étiquetés par des humains. Cela réduit les coûts d'étiquetage des données mais introduit de nouveaux risques de biais ; les modèles peuvent amplifier leurs propres erreurs.
Source : « Large Language Models Can Self-Improve »
Un sondage de mars 2026 a révélé que 76% des chercheurs en IA pensent que les gains issus de la mise à l'échelle du calcul et des données ont atteint un plateau, les principaux laboratoires rapportant des rendements décroissants malgré des investissements massifs. Ce constat suggère que le prochain saut de capacité des LLM proviendra plus probablement d'innovations architecturales, telles qu'une meilleure efficacité d'entraînement, des architectures éparses ou des améliorations du raisonnement, plutôt que d'une simple poursuite de la mise à l'échelle des approches existantes.3
3- Modèles experts épars (Mixture of Experts)
Au lieu d'activer l'ensemble du réseau de neurones pour chaque entrée, seul un sous-ensemble pertinent de paramètres s'active, en fonction de la tâche. Le modèle aiguille les entrées vers des « experts » spécialisés au sein du réseau. Seuls les experts activés traitent la requête.
Exemples concrets :
- Llama 4 Scout : 109B paramètres totaux, 17B actifs par token. L'architecture Mixture of Experts (MoE) offre une fenêtre de contexte de 10M tokens sur un seul H100 GPU.
- Mistral Devstral 2 : Conçu spécifiquement pour les tâches d'ingénierie logicielle. 123B paramètres, fenêtre de contexte de 256K tokens. Atteint 72.2% sur SWE-bench Verified, s'imposant comme le modèle de codage open-weight de référence. Une variante plus petite, Devstral Small 2 (24B paramètres), fonctionne localement sur du matériel grand public sous licence Apache 2.0.4
- Dans notre bench A-CODE-LLM, les variantes de base et de réflexion de DeepSeek V4 Pro ont toutes deux obtenu un score inférieur à 0.45 au global, avec des temps d'exécution dépassant 1 700 secondes par tâche. La capacité de codage agentique du modèle est en retard par rapport à ses solides performances sur les benchmarks à requête unique, reflétant probablement une maturité d'utilisation d'outils plus faible par rapport aux modèles frontières d'Anthropic et Google à ce stade.
4- Intégration dans les flux de travail d'entreprise
Les LLM sont intégrés directement dans les processus métier plutôt que d'être utilisés comme des outils autonomes.
Exemples concrets :
- Salesforce Agentforce (anciennement Einstein Copilot) : Intègre les LLM dans les opérations CRM. Répond aux questions des clients, génère du contenu et exécute des actions dans Salesforce, en s'appuyant sur les données CRM et les métadonnées de l'organisation via la couche de confiance Einstein.5
- Microsoft 365 Copilot : Intégré dans Word, Excel, PowerPoint et Outlook. Rédige des documents, analyse des feuilles de calcul, génère des présentations et résume des fils de discussion, en s'appuyant sur les données de l'entreprise via Microsoft Graph pour ancrer les réponses dans le contexte organisationnel.6 L'agent Researcher utilise une architecture multi-modèle où GPT gère la recherche initiale et Claude examine les résultats avant livraison, le premier déploiement commercial confirmé de fournisseurs d'IA concurrents au sein d'un même produit d'entreprise.
- Anthropic Claude pour entreprise : La séparation de la mémoire par projet maintient les contextes de travail distincts entre les équipes. Claude Opus 4.6 a introduit les équipes d'agents, permettant à plusieurs agents Claude de diviser des tâches plus importantes en flux de travail parallèles, chacun responsable d'un segment et coordonné avec les autres simultanément. La même version a intégré Claude directement dans PowerPoint en tant que panneau latéral natif (aperçu de recherche), permettant de créer et de modifier des présentations dans l'application sans transfert de fichiers.7
5- LLM hybrides avec capacités multimodales
Les grands modèles multimodaux intègrent plusieurs formes de données, telles que le texte, les images et l'audio, ce qui leur permet de comprendre et de générer du contenu sur différents types de médias.
- Dans notre bench A-CODE-LLM, GPT 5.5 réflexion a obtenu 0.597 avec un temps d'exécution moyen de 276 secondes, le modèle plus rapide au-dessus de 0.50 en temps. Le coût API par cellule était de 0.41 $ à 0.45 $ pour les variantes mini, environ un tiers du coût de Claude Sonnet 4.6 pour des plages de scores similaires.
- Gemini 2.5 Pro : Gère nativement le texte, l'audio, les images, la vidéo et des dépôts de code entiers dans une fenêtre de contexte de 1M tokens. Disponible via Google IA Studio, Vertex IA et NotebookLM. Prix à partir de 1.25 $ par million de tokens d'entrée et 10 $ par million de tokens de sortie via l'API.8
- Llama 4 Scout et Maverick : Les modèles open-weight de Meta utilisent une multimodalité par fusion précoce des tokens texte et vision, entraînés ensemble dès le départ plutôt qu'ajoutés en modules séparés. Les modèles ont été pré-entraînés dans 200 langues et bénéficient d'un ajustement fin spécifique pour 12 langues, dont l'arabe, l'espagnol, l'allemand et l'hindi.9
La multimodalité est standard parmi les modèles de pointe. Le défi restant est la cohérence : les modèles fonctionnent bien sur les combinaisons texte-image courantes mais se dégradent sur les contextes visuels rares, les entrées basse résolution et le raisonnement intermodal qui nécessite de relier des preuves visuelles et textuelles.
6- Modèles de raisonnement
Des modèles qui réfléchissent aux problèmes étape par étape plutôt que de générer des réponses immédiates.
Ce passage de la prédiction au raisonnement est crucial pour permettre :
- Le comportement agentique, où les modèles planifient, exécutent et adaptent des tâches de manière autonome.
- L'IA interprétable, où les résultats sont étape par étape et logiquement solides, pas seulement plausibles.
- Claude Sonnet 4.6 : Leader actuel de la production d'Anthropic sur les benchmarks de codage agentique, obtenant 0.748 dans le bench A-CODE-LLM d'AIMultiple, au-dessus de toutes les variantes Opus. Utilise la réflexion adaptative, où le modèle détermine dynamiquement la profondeur du raisonnement en fonction de la complexité de la tâche sans nécessiter de changement de mode manuel. Tarification 3 $/15 $ par million de tokens. Sur SWE-bench Verified, Sonnet 4.6 atteint 79.6%, à un point d'Opus 4.7 (80.8%), pour un cinquième du coût.
- Claude Opus 4.7 : Le flagship d'Anthropic sur le raisonnement complexe en plusieurs étapes et la vision (98.5% sur le benchmark d'acuité visuelle XBOW, contre 54.5% pour la génération précédente). Tarif 5 $/25 $ par million de tokens. Dans le benchmark d'AIMultiple, Opus 4.7 a obtenu 0.61, en dessous de Sonnet 4.6 (0.748) et d'Opus 4.8 (0.702), principalement en raison d'une latence plus élevée (1 562 secondes en moyenne par tâche) dégradant les scores UI. L'écart avec Sonnet se creuse sur les tâches de raisonnement abstrait comme ARC-AGI-2.
- Claude Opus 4.8 : Sorti après Opus 4.7, corrigeant la régression d'Opus 4.7 en codage agentique. A obtenu 0.702 au bench A-CODE-LLM, cinquième au classement général. A terminé la tâche de base en 34 secondes, le modèle plus rapide du benchmark sur cette tâche avec seulement 6 appels d'outils. Tarification : 2.92 $ par cellule dans les conditions du benchmark (15 $/75 $ par million de tokens).
7- Modèles affinés spécifiques à un domaine
Des modèles entraînés sur des données spécialisées pour des secteurs spécifiques au lieu d'un entraînement généraliste.
Google, Microsoft et Meta ont tous publié d'importants modèles propriétaires spécifiques à un domaine et des modèles affinés ciblant des cas d'usage d'entreprise, en plus de leurs offres généralistes.
Ces LLM spécialisés peuvent entraîner moins d'hallucinations et une précision accrue en exploitant le pré-entraînement spécifique au domaine, l'alignement du modèle et l'ajustement fin supervisé.
Codage
GitHub Copilot : Affiné sur les dépôts de code. En juillet 2025, 20 millions de développeurs utilisent GitHub Copilot, une augmentation de 400% en glissement annuel, et 90% des entreprises du Fortune 100 l'utilisent. Il autocomplète le code, génère des fonctions et suggère des corrections de bogues.10
Finance
BloombergGPT : 50 milliards de paramètres, LLM entraîné sur un jeu de données de 363 milliards de tokens de documents financiers Bloomberg, surpassant les modèles de taille comparable sur les benchmarks financiers NLP, y compris l'analyse de sentiment, la reconnaissance d'entités nommées et la réponse aux questions.11
Santé
Google Med-PaLM 2 : Affiné sur des jeux de données médicaux, a atteint plus de 85% de précision sur les questions de type USMLE, le premier LLM à atteindre un niveau de performance expert sur ce benchmark. Il alimente MedLM, la famille de modèles fondamentaux pour la santé de Google Cloud.12
Droit
ChatLAW : Un modèle de langage open source spécifiquement entraîné sur des jeux de données juridiques chinois.13
8- IA éthique et atténuation des biais
Les entreprises se concentrent de plus en plus sur l'IA éthique et l'atténuation des biais dans le développement et le déploiement des grands modèles de langage.
- Anthropic et OpenAI ont mené une évaluation d'alignement mutuelle mi-2025, testant les modèles publics de l'autre pour la flatterie, les tendances à la dénonciation et les comportements d'auto-préservation. L'exercice a révélé de la flatterie chez tous les modèles testés, y compris des cas où les modèles validaient des décisions nuisibles d'utilisateurs simulés ayant des croyances délirantes. Anthropic a ensuite développé le cadre de test Bloom spécifiquement pour évaluer ce comportement dans les nouveaux modèles.
- Anthropic a également publié Claude Mythos Preview (Project Glasswing), un modèle sur invitation uniquement mis à disposition d'un petit ensemble d'organisations spécifiquement pour trouver et corriger des vulnérabilités de cybersécurité dans les principaux systèmes d'exploitation et navigateurs web. Anthropic a déclaré ne pas prévoir de rendre ce modèle généralement disponible. L'approche d'accès contrôlé représente un nouveau cadre pour déployer des modèles spécialisés hautement performants où le profil de risque exige un déploiement restreint.14
- Google DeepMind : A publié « The Ethics of Advanced IA Assistants », offrant le premier traitement systématique des questions éthiques et sociétales soulevées par les agents IA, couvrant l'alignement des valeurs, les risques de manipulation, l'anthropomorphisme, la vie privée et l'équité. L'évaluation Responsible IA de l'entreprise a inclus plus de 350 exercices d'équipe rouge adversariale et introduit un nouveau niveau de capacité critique spécifiquement pour la manipulation nuisible, la traitant comme un risque de niveau frontière aux côtés des cyberattaques et des menaces NRBC.
Limites des grands modèles de langage (LLMs)
1- Hallucinations
Les modèles génèrent des informations apparemment plausibles mais incorrectes.
Le classement des hallucinations Vectara est la référence de synthèse ancrée la plus citée du secteur. Sur le jeu de données Vectara original, les modèles Gemini de Google occupent systématiquement les premières positions, les variantes Gemini Flash atteignant des taux d'hallucination inférieurs à 1%. La famille GPT d'OpenAI se situe entre 0.8% et 2.0%.
Vectara a lancé un benchmark significativement plus difficile fin 2025, 7 700 articles (contre 1 000 auparavant), documents plus longs jusqu'à 32K tokens, et contenu couvrant le droit, la médecine, la finance et la technologie. Les résultats sur ce nouveau jeu de données révèlent un schéma contre-intuitif : les modèles de raisonnement qui excellent sur des tâches complexes hallucinent souvent davantage en synthèse ancrée que les modèles plus petits et plus rapides. La plupart des modèles de classe réflexion affichent des taux d'hallucination supérieurs à 10% sur le jeu de données plus difficile, tandis que les modèles plus légers comme les variantes Gemini Flash maintiennent des taux plus bas.15
Remarque : Aucun benchmark unique ne donne un « taux d'hallucination » définitif pour un modèle. Une évaluation responsable croise au moins deux benchmarks mesurant des choses différentes : une tâche ancrée (Vectara), une tâche de connaissance ouverte, et spécifie la version exacte du modèle et les conditions d'appel.
Tous les modèles hallucinent. La fréquence a considérablement diminué, passant d'environ 21% en 2021 à moins de 5% pour les meilleurs sur les benchmarks standard, mais elle n'est pas éliminée. Les applications critiques nécessitent toujours une vérification humaine.
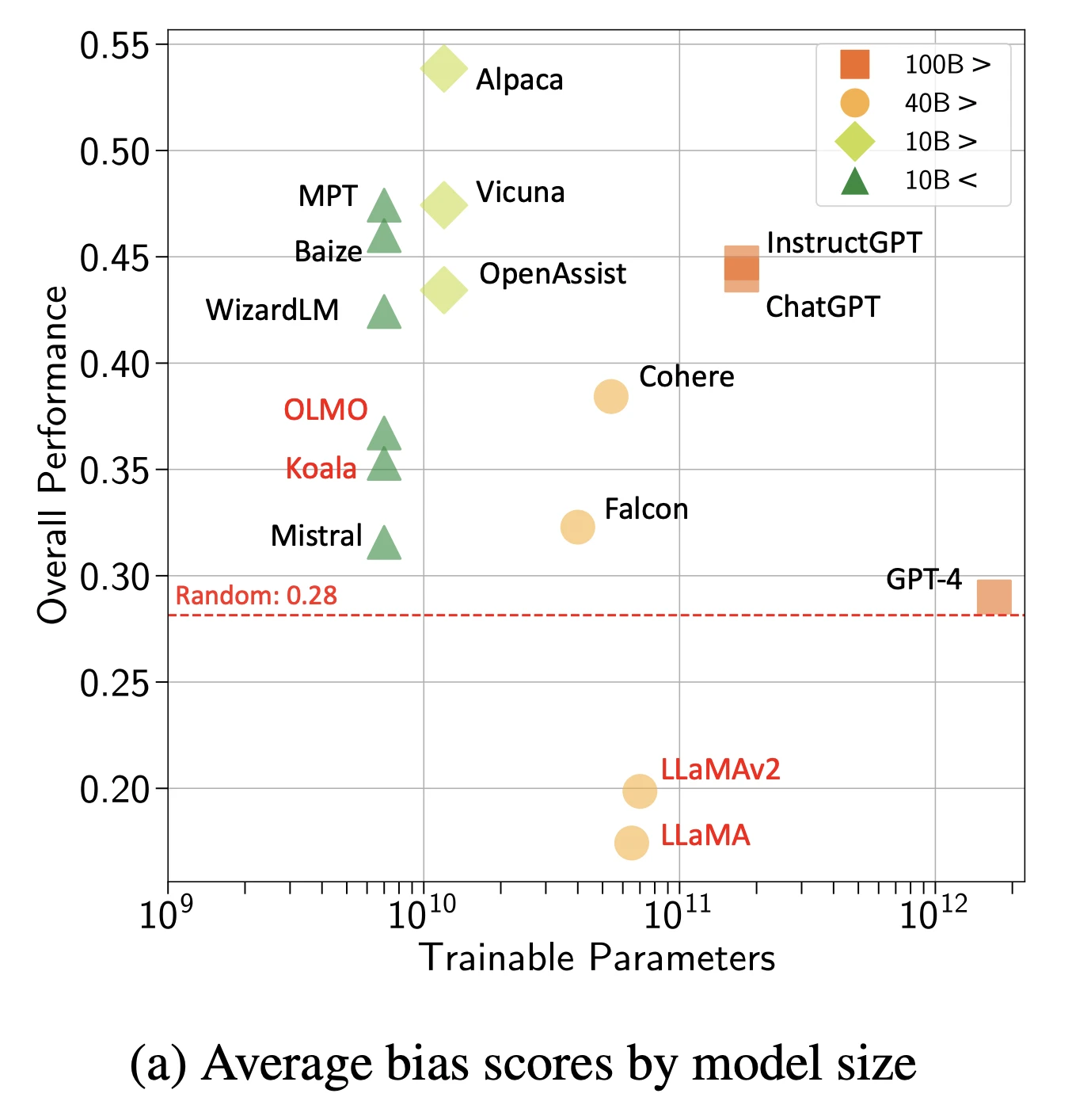
2- Biais
Les modèles absorbent et amplifient les biais sociaux des données d'entraînement.
Figure : Scores globaux de biais par modèle et taille
Source : Arxiv16
Types de biais observés :
- Biais de genre dans les suggestions de profession
- Biais racial dans les simulations de tri de CV
- Biais d'âge dans les recommandations de santé
- Biais socio-économique dans le contenu éducatif
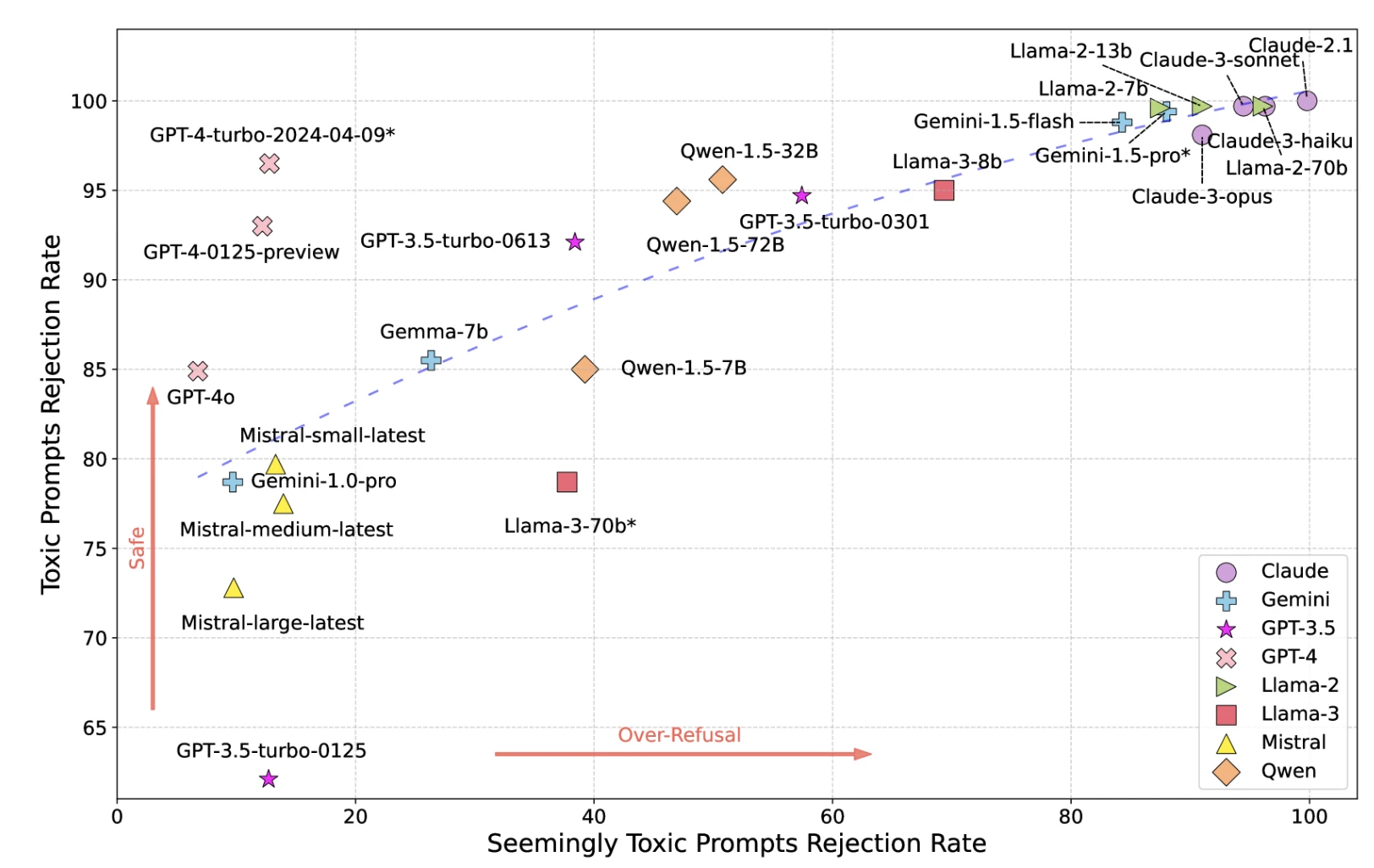
3- Toxicité
Les modèles peuvent générer du contenu nuisible, offensant ou toxique malgré les mesures de sécurité.
Figure : Carte de toxicité des LLM
Source : UCLA, UC Berkeley Researchers17
*GPT-4-turbo-2024-04-09*, Llama-3-70b*, et Gemini-1.5-pro* sont utilisés comme modérateur, les résultats pourraient être biaisés en faveur de ces 3 modèles.
Des mesures de sécurité strictes réduisent la toxicité mais augmentent les faux positifs (refus de requêtes inoffensives). Des mesures laxistes laissent passer la toxicité.
4- Fenêtre de contexte : Limitations
Chaque modèle a une capacité de mémoire fixe, le nombre de tokens qu'il peut traiter en une seule session. Si cette limite est dépassée, le modèle tronque le contenu antérieur ou refuse la requête. L'écart pratique entre les modèles est suffisamment important pour impacter les charges de travail réelles.
Fenêtres de contexte les plus récentes :
- Llama 4 Scout (Meta) : 10M tokens (~7.5M mots), la plus grande fenêtre de contexte vérifiée en production parmi les modèles de pointe.18 En pratique, cela signifie charger des bases de code entières, des archives juridiques ou des historiques de conversation de plusieurs jours sans découpage.
- Gemini 2.5 Pro : 1 048 576 tokens (~780 000 mots), avec entrée multimodale native (texte, audio, images et vidéo) dans la même fenêtre. Rappel de 100% jusqu'à 530 000 tokens et 99.7% à la limite d'un million de tokens.
- Claude Sonnet 4.6 : 1M tokens (~750 000 mots) au tarif standard, disponible sans en-tête bêta ni configuration spéciale.19
- GPT-5.5 : Fenêtre de contexte de 1M tokens au niveau de l'API.20
Une grande fenêtre de contexte ne signifie pas automatiquement de meilleures performances sur toute sa longueur. Le rappel se dégrade vers le milieu des contextes très longs sur la plupart des modèles, et les coûts augmentent avec la longueur d'entrée : traiter 1M tokens coûte beaucoup plus cher que traiter 10K tokens sur le même modèle. Pour la plupart des charges de travail de production, la question pratique n'est pas quel modèle a la plus grande fenêtre, mais quel modèle récupère de manière fiable aux longueurs de contexte réellement nécessaires pour votre cas d'usage.
5- Coupure des connaissances statiques
Les modèles s'appuient sur des connaissances pré-entraînées avec une date de coupure spécifique. Ils n'ont pas accès aux informations postérieures à l'entraînement, sauf s'ils sont connectés à des sources externes.
Problèmes :
- Informations obsolètes sur l'actualité
- Incapacité à gérer les développements récents
- Moins de pertinence dans les domaines dynamiques (technologie, finance, médecine)
Solution : Intégration de la recherche web. ChatGPT, Claude et Perplexity proposent tous une recherche en temps réel. Mais la recherche n'élimine pas les hallucinations ; les modèles interprètent parfois mal les résultats de recherche.
Principales plateformes LLM
GPT-5.5
Le flagship actuel d'OpenAI a été publié le 23 avril 2026. Construit autour d'un effort de raisonnement configurable, les développeurs définissent la profondeur de réflexion par requête (de none à xhigh), afin que les requêtes simples ne consomment pas le calcul réservé aux problèmes difficiles. Le modèle excelle en codage agentique, utilisation d'ordinateur et tâches à long horizon où il doit garder le contexte à travers de grands systèmes et vérifier son propre travail en cours d'exécution.21
Qui l'utilise : Développeurs, entreprises et créateurs de contenu. La plus grande base d'utilisateurs parmi les LLM.
Limites : 30 $ par million de tokens, le tarif de base le plus élevé de cette liste. Hallucine encore. Nécessite une intégration de recherche web pour tout ce qui dépasse sa date de coupure d'entraînement.
Claude Opus 4.8 / Sonnet 4.6
Claude Sonnet 4.6 est en tête du bench A-CODE-LLM d'AIMultiple avec un score global de 0.748 pour un coût de 1.26 à 1.33 $ par cellule, au-dessus de toutes les variantes Opus testées. Claude Opus 4.8 suit avec 0.702, corrigeant la régression d'Opus 4.7 (0.61) pour un coût de 2.92 $ par cellule. Opus 4.7 reste le meilleur sur les tâches de raisonnement complexe en plusieurs étapes et de vision (98.5% sur le benchmark d'acuité visuelle XBOW), mais son temps d'exécution moyen de 1 562 secondes dans les flux de travail agentiques porte le coût total à 3.08 $ par cellule, ce qui en fait le modèle plus cher du benchmark.
Sonnet 4.6 et les variantes Opus utilisent la réflexion adaptative : le modèle détermine la profondeur du raisonnement en fonction de la complexité de la tâche sans nécessiter de changement de mode manuel. Sonnet 4.6 a effectué le moins d'appels d'outils par tâche parmi les modèles Anthropic (51 en base, 48 en réflexion), atteignant le meilleur score de benchmark avec moins d'itérations que les variantes Opus (56 à 70 appels d'outils). Les équipes d'agents, disponibles sur toute la gamme de production d'Anthropic, permettent à plusieurs instances de Claude de diviser une tâche en flux de travail parallèles coordonnés en temps réel.
Qui l'utilise : Développeurs et entreprises exécutant du codage agentique, des flux de travail de recherche ou des pipelines multi-agents. Les équipes privilégiant l'efficacité des coûts utilisent Sonnet 4.6 ; celles ayant des charges de travail intensives en vision ou raisonnement complexe utilisent Opus 4.7.
Limites : La réflexion étendue est plus lente et plus coûteuse par token. L'écart de performance avec Sonnet se creuse sur les tâches de raisonnement abstrait (ARC-AGI-2). Opus 4.8 est tarifé à 15 $/75 $ par million de tokens.
Gemini 3.5 Flash
Gemini 3.5 Flash réflexion a obtenu 0.625, le meilleur résultat non-Anthropic pour un coût de 1.30 $ par cellule et 390 secondes de temps d'exécution moyen. La variante de base a obtenu un score inférieur à celui de la réflexion pour un coût plus élevé (0.56 $ par cellule de référence), en raison de réécritures (131 lignes pour une tâche dont la solution de référence fait environ 50 lignes).
Llama 4 Scout
Modèle MoE open-weight de Meta. 109B paramètres totaux, 17B actifs par token, fonctionne sur un seul NVIDIA H100 GPU avec quantification int4. L'implication pratique est qu'une fenêtre de contexte de 10M tokens est accessible sans contrat de centre de données.22 La multimodalité par fusion précoce signifie que le texte et la vision sont traités conjointement dès la première couche, plutôt que combinés à l'étape de sortie. Disponible sous la licence Llama 4 Community de Meta.
Qui l'utilise : Chercheurs, organisations nécessitant un déploiement sur site, développeurs évitant le verrouillage fournisseur, et équipes pour lesquelles le coût à l'échelle rend la tarification API insoutenable.
Limites : Les performances dépendent fortement de la configuration d'hébergement et des choix de quantification. Nécessite un investissement en infrastructure et une capacité d'opérations ML. Moins de finition de production que les modèles commerciaux.
DeepSeek V4
Le modèle de quatrième génération de DeepSeek est disponible en aperçu. Utilise une architecture MoE de mille milliards de paramètres, environ 50% plus grand que V3, avec des capacités multimodales couvrant texte, image et vidéo. La réflexion en utilisation d'outils permet au modèle de raisonner en interne avant d'appeler des outils externes et de vérifier les résultats des outils par rapport à sa propre logique, ce qui est le différenciateur clé pour les flux de travail agentiques. Le prix d'entrée de l'API commence à 0.27 $ par million de tokens (cache-miss), soit environ 18 fois moins cher que GPT-5.5.23
FAQ
Un LLM est un modèle d'IA conçu pour générer et comprendre du texte semblable à celui d'un humain en analysant de grandes quantités de données.
Ces modèles fondamentaux sont basés sur des techniques d'apprentissage profond et impliquent généralement des réseaux de neurones avec de nombreuses couches et un grand nombre de paramètres, leur permettant de capturer des motifs complexes dans les données sur lesquelles ils sont entraînés.
Citer cette recherche
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sezer, Sena},
title = {{L'avenir des grands modèles de langage}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/future-of-large-language-models}},
note = {AIMultiple. Consulté le 25 Juin 2026}
}
Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.