LCM : De la tokenisation LLM à la représentation au niveau conceptuel
Les grands modèles de concepts (LCM) , tels qu'introduits par Meta dans leurs travaux sur « Large Concept Models », représentent un changement fondamental par rapport à la prédiction basée sur les jetons vers une représentation au niveau des concepts . 1
Les LCM diffèrent des LLM traditionnels de deux manières essentielles :
- Espace d'intégration de haute dimension : au lieu de travailler avec des séquences de jetons discrètes, les LCM effectuent toute la modélisation directement dans un espace d'intégration de haute dimension.
- Abstraction conceptuelle : la modélisation s’effectue au niveau des concepts sémantiques et abstraits, et non au sein d’un langage ou d’une modalité spécifique. De ce fait, les modèles de langage sont intrinsèquement indépendants du langage et de la modalité.
D'après les recherches de Meta, 2 Nous explorerons les composants essentiels des LCM et leur potentiel dans la recherche et le raisonnement sémantiques, en nous basant sur les benchmarks suivants :
Comprendre les limites des LLM : des symboles aux concepts
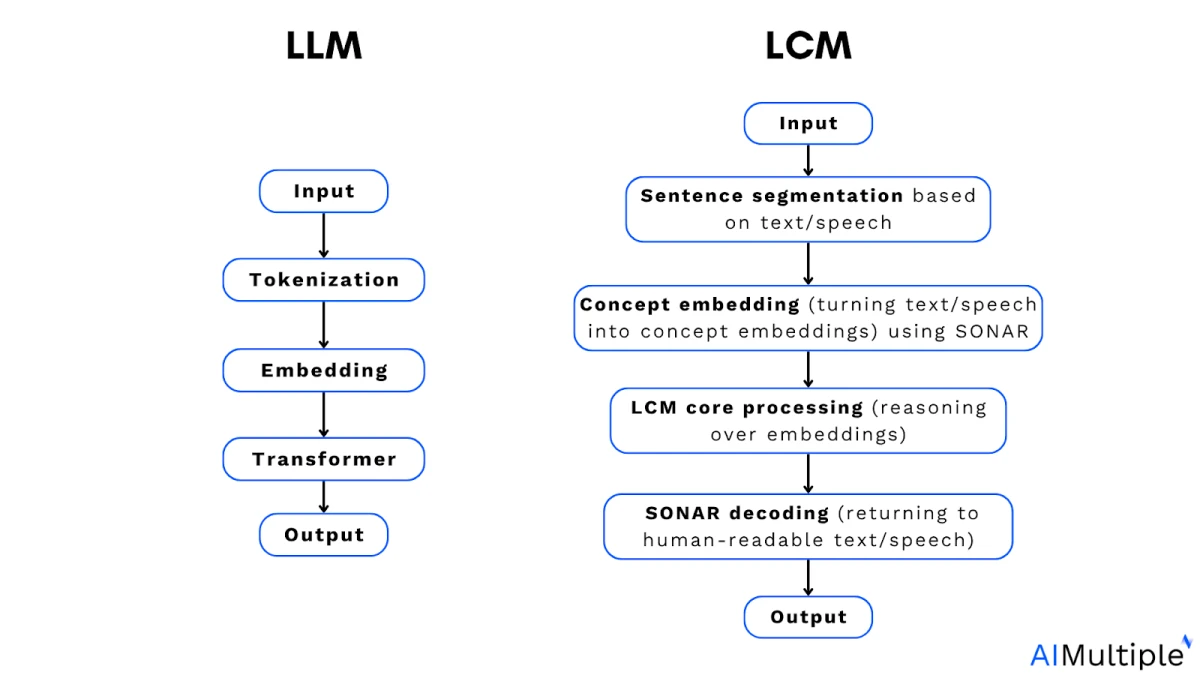
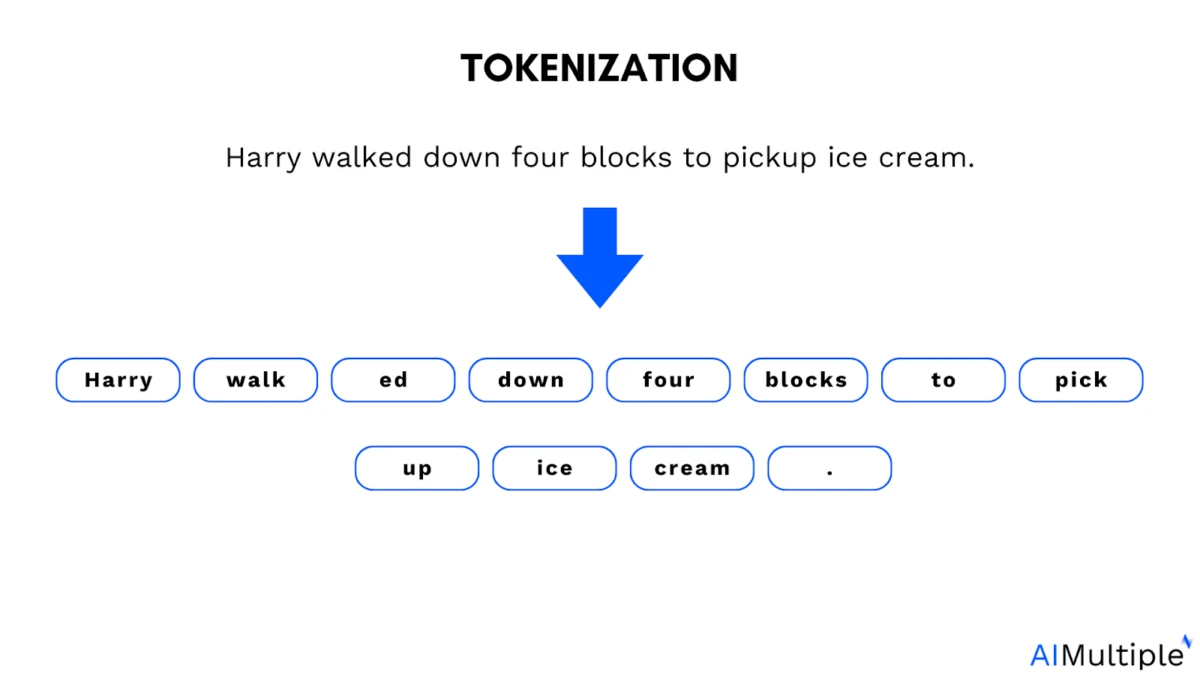
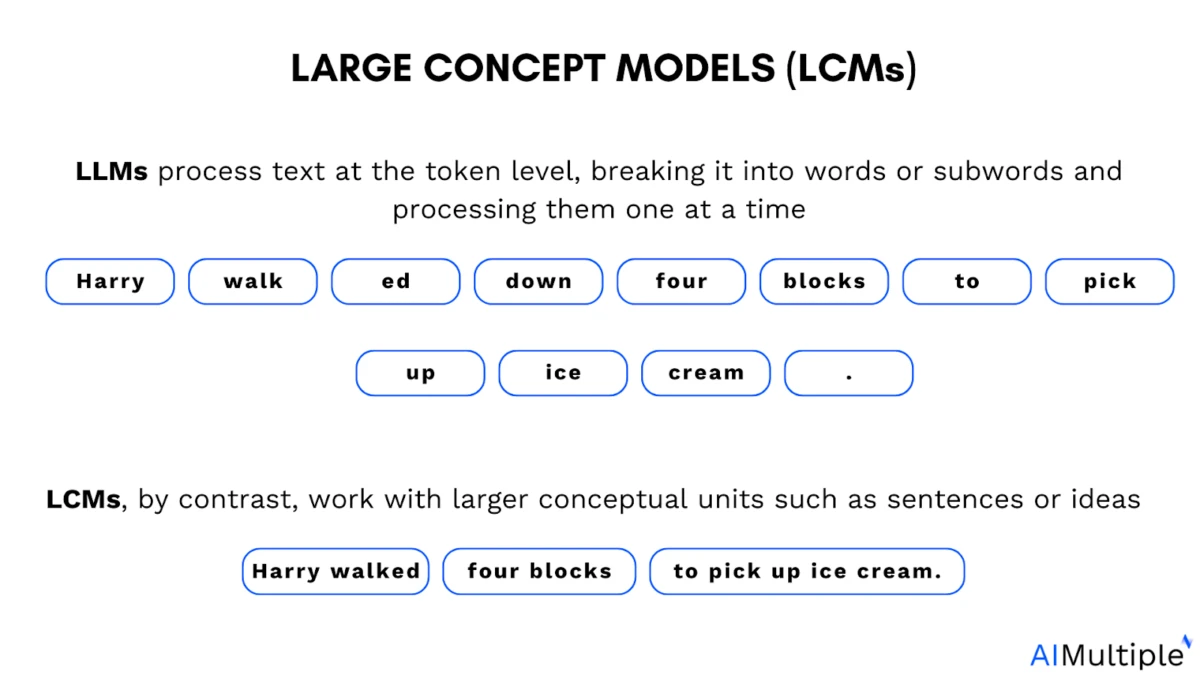
Le rôle de la tokenisation dans les LLM : Les grands modèles de langage (LLM) sont entraînés sur des tokens. Un token est un petit segment de texte. Il peut s’agir d’un mot entier, d’une partie de mot, ou même d’un seul caractère que le modèle traite comme une unité.
Exemple de tokenisation :
Le problème
La tokenisation aide les modèles à décomposer le langage en éléments gérables, mais elle introduit également une contrainte. La plupart des modèles de langage fonctionnent sur des séquences de jetons discrets (par exemple, des sous-mots de texte ; des jetons visuels/audio produits par des encodeurs).
Les LLM peuvent intégrer de multiples modalités, mais leur objectif principal et leur représentation restent liés à la séquence , ce qui rend plus difficile la modélisation directe du sens au niveau conceptuel .
Les résultats de Cognition.ai avec Sonnet 4.5 le montrent clairement : le modèle détecte lorsque sa fenêtre de contexte est presque pleine, tire des conclusions hâtives et signale même les jetons restants, bien qu'inexacts. 3
La solution (Concepts)
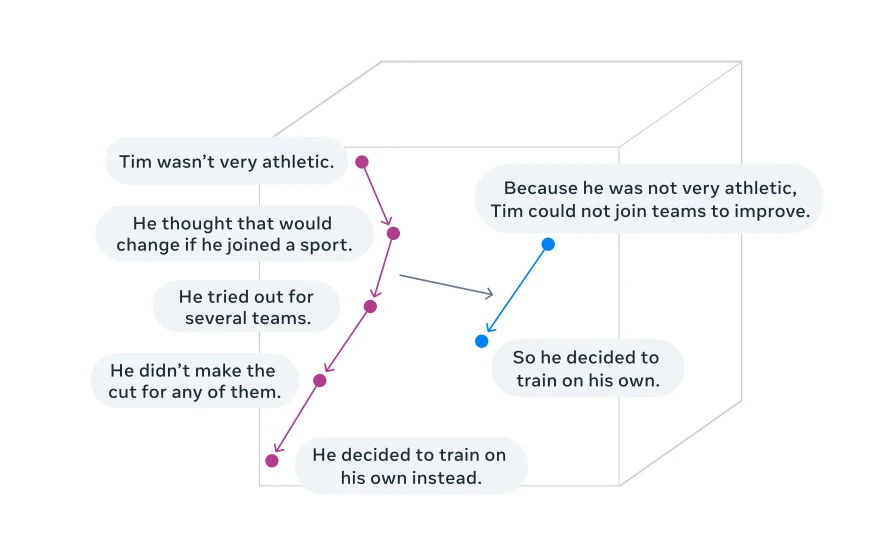
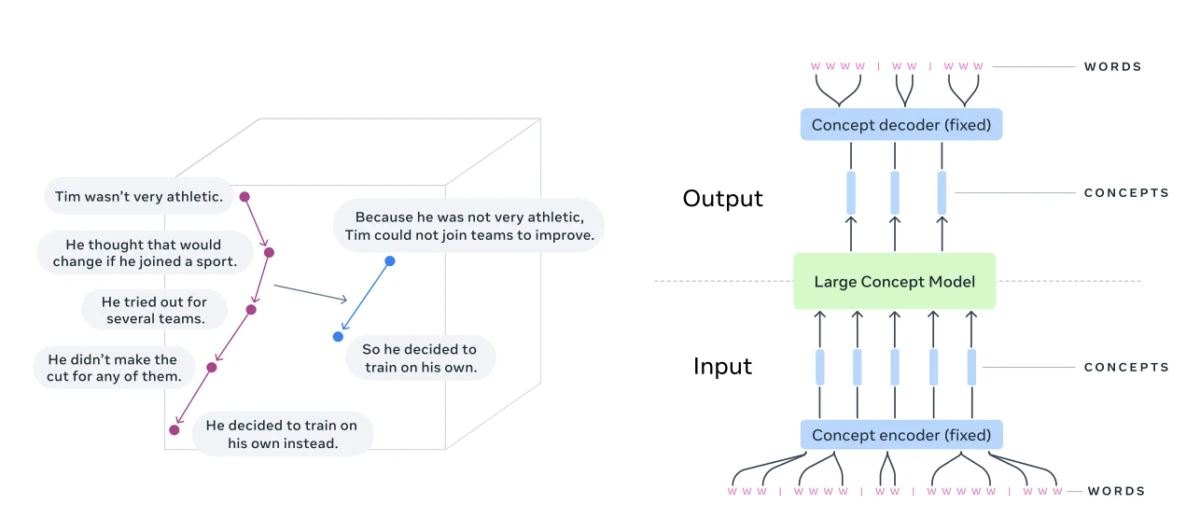
Visualisation du raisonnement dans un espace d'intégration de concepts (tâche de résumé) 4
Les concepts désignent des représentations de sens de niveau supérieur . Contrairement aux tokens, ils ne sont liés à aucune unité linguistique spécifique et peuvent être dérivés de textes ou de la parole ; le processus de raisonnement reste donc inchangé.
Cela permet :
- Meilleure gestion des contextes longs grâce à un raisonnement portant sur des idées globales plutôt que sur des fragments.
- Un raisonnement plus abstrait puisque les opérations sont effectuées au niveau de la signification.
- Processus indépendant de la langue et de la modalité pour gérer les tâches multilingues et multimodales sans nécessiter de pipelines de traitement distincts pour chaque type d'entrée.
Que sont les maquettes conceptuelles à grande échelle ?
En revanche, les grands modèles de concepts (LCM) visent à représenter et à raisonner sur des concepts sémantiques dans un espace d'intégration continu, non lié à une langue ou une modalité unique.
Architecture fondamentale d'un modèle conceptuel à grande échelle (LCM) :
Source : Meta 5
Composants essentiels des LCM
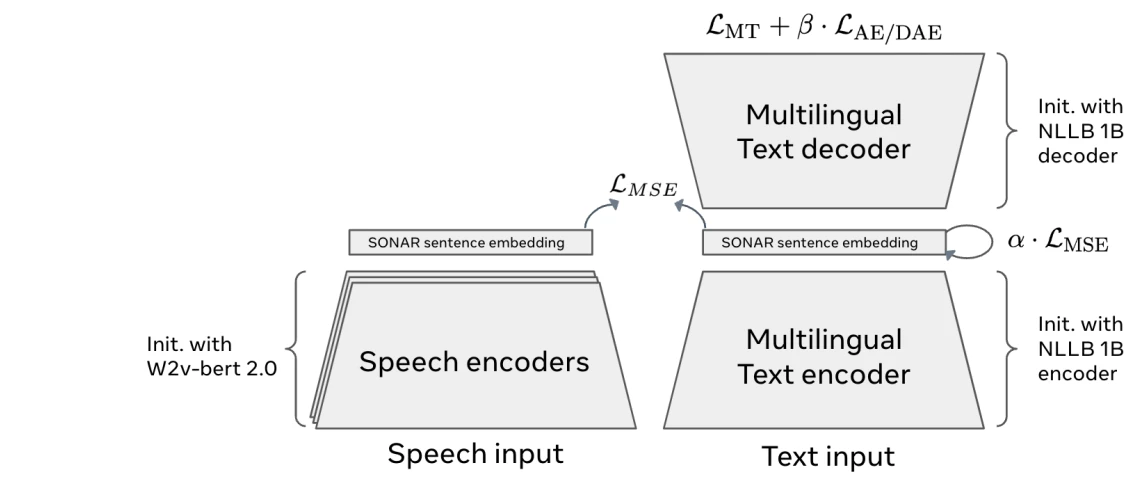
1. Encodage SONAR (transformation de texte ou de parole en représentations vectorielles de concepts)
architecture SONAR 6
La première étape d'un modèle de concept étendu (LCM) est l' encodeur de concepts , qui convertit le texte ou la parole en un espace d'intégration partagé. Au lieu de découper l'entrée en jetons, il représente des phrases entières sous forme d'intégrations mathématiques qui capturent leur signification.
Les LCM utilisent SONAR , un espace d'intégration multilingue et multimodal qui prend en charge plus de 200 langues textuelles et 76 pour la parole.
Par exemple, les phrases « I love you » en anglais et « Te quiero » en espagnol sont placées côte à côte dans cet espace car elles expriment la même idée. En opérant à ce niveau conceptuel, les LCM gagnent en inclusivité, en efficacité et en évolutivité par rapport aux modèles basés sur des jetons.
Pourquoi SONAR est-il meilleur que les intégrations traditionnelles ?
Méthodes traditionnelles :
- mBERT : Fournit des plongements multilingues, mais ceux-ci ne sont pas alignés de manière cohérente au niveau de la phrase , ce qui rend les tâches interlinguistiques moins efficaces.
Avantages du SONAR :
- Compatible avec toutes les langues : plus de 200 langues pour la saisie et l’affichage de texte (s’appuyant sur le projet « No Language Left Behind » de Meta). 76 langues pour la saisie vocale et l’anglais pour la sortie vocale.
- Alignement interlingue : Les phrases ayant la même signification apparaissent proches les unes des autres, quelle que soit la langue.
- Raisonnement de niveau supérieur : Puisque les unités sont des phrases (ou des concepts), les modèles peuvent effectuer des tâches telles que la synthèse ou la traduction en manipulant directement les idées.
- Traduction zéro-shot : Peut traduire entre langues et modalités sans formation directe pour chaque paire .
LLM vs LCM
2. Traitement de base LCM (raisonnement sur les plongements)
Le noyau LCM correspond à l'étape de raisonnement, où le modèle génère de nouveaux concepts en fonction du contexte. Contrairement aux LLM, qui prédisent un jeton à la fois, le noyau LCM prédit des phrases ou des concepts entiers , opérant à un niveau sémantique supérieur.
La difficulté réside dans la production d'embeddings continus conditionnés par le contexte. Les LLM génèrent des distributions de probabilité sur des jetons discrets, tandis que les LCM doivent générer directement des vecteurs qui capturent le sens.
Pour remédier à cela, les chercheurs ont proposé plusieurs approches, notamment :
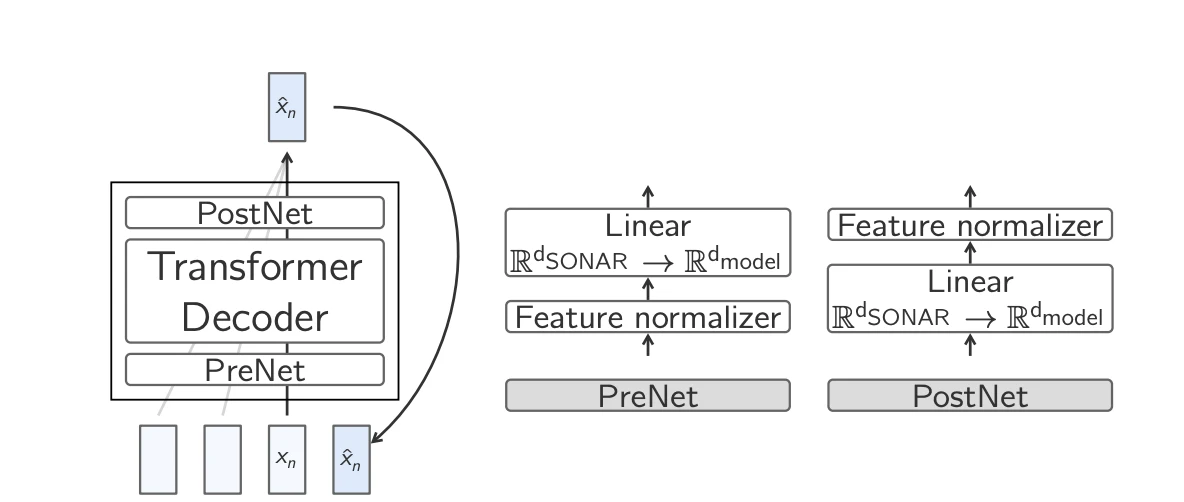
- Base-LCM : Transformer standard prédisant l’embedding : La méthode la plus simple consiste à entraîner un Transformer à prédire directement le prochain embedding, en minimisant l’erreur quadratique moyenne (EQM) . Bien qu’efficace en principe, cette approche présente des difficultés car un contexte donné peut mener à plusieurs continuations valides, mais sémantiquement distinctes.
Base-LCM 7
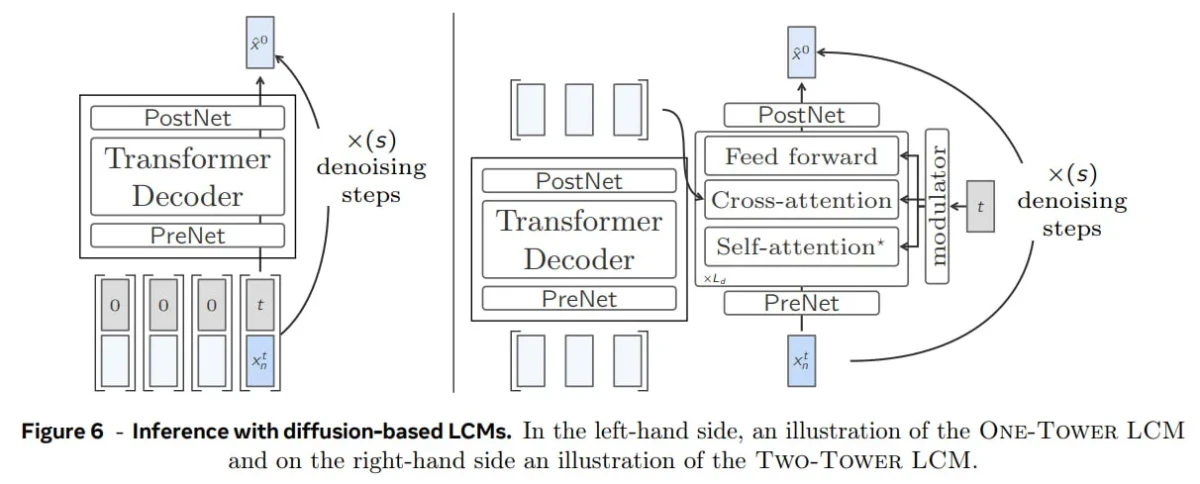
- LCM basé sur la diffusion : Variations structurelles pour la contextualisation et le débruitage : Inspirée par la génération d’images, cette variante utilise un processus de diffusion . Elle génère de manière autorégressive des concepts, un à la fois, en effectuant des étapes de débruitage pour chaque concept généré.
- Une seule tour : une seule pile de transformateurs gère à la fois la contextualisation et le débruitage, ce qui permet de conserver une conception efficace et compacte.
- Modèle à deux tours : Il divise le processus en deux parties : un contextualiseur pour comprendre le contexte et un débruiteur pour affiner les plongements lexicaux, offrant plus de flexibilité au prix d’une complexité accrue.
- LCM quantifié : plongements discrétisés : Une autre option consiste à discrétiser les plongements en unités symboliques plus grandes. Cela rapproche la tâche de celle des LLM, où le modèle génère des éléments discrets, mais ici les « jetons » représentent des blocs de sens beaucoup plus grands et sémantiquement plus riches.
3. Décodage SONAR (retour à un texte ou une parole lisible par l'homme)
La dernière étape d'un LCM est le décodeur de concepts , qui transforme les représentations abstraites en texte ou en parole naturelle.
Étant donné que les concepts sont stockés dans un espace d'intégration partagé , ils peuvent être décodés dans n'importe quel langage ou modalité pris en charge sans avoir à relancer le processus de raisonnement.
Cette conception indépendante de la langue permet à un LCM de recevoir des données en allemand, de raisonner sur des concepts et de produire une sortie en japonais. Elle facilite également l'extension du modèle : de nouveaux encodeurs ou décodeurs (par exemple pour la langue des signes ou les systèmes de transcription vocale) peuvent être ajoutés sans avoir à réentraîner l'intégralité du modèle.
En séparant la « pensée » de l’expression, le décodeur garantit que les LCM restent à la fois flexibles et adaptables aux applications multilingues et multimodales.
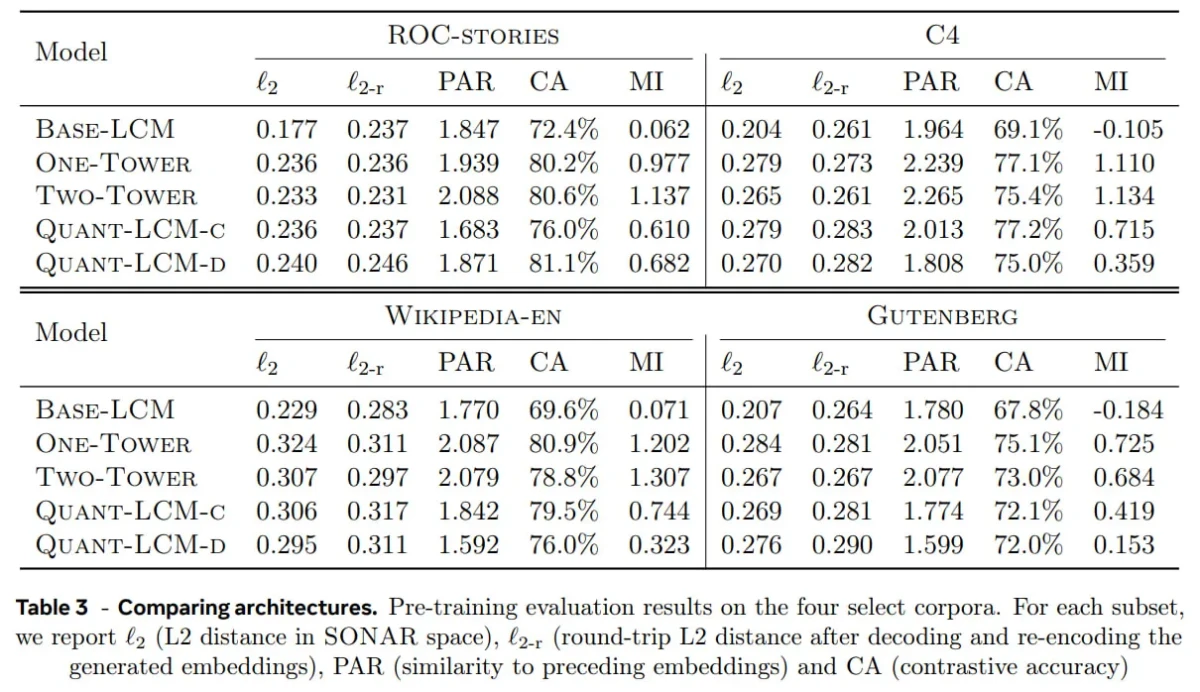
Évaluation comparative des architectures LCM
Meta ont pré-entraîné des LCM sur l' ensemble de données FineWeb-Edu (en anglais uniquement) et les ont évalués sur quatre benchmarks :
- Histoires ROC (raisonnement narratif),
- C4 (texte à l'échelle du Web),
- Wikipédia-en (connaissance encyclopédique),
- Gutenberg (texte long).
Ces ensembles de données ont été choisis pour couvrir divers types de textes, allant de courts récits à de grandes bases de connaissances et à des documents volumineux.
Points clés à retenir :
Les modèles LCM basés sur la diffusion (QUANT-LCM-C, QUANT-LCM-D) sont les plus performants . Leur processus itératif de débruitage s'est avéré plus efficace pour modéliser les prolongements de concepts, ce qui conduit à une précision et une cohérence sémantiques accrues.
Comment interpréter les données de référence :
- ℓ₂, ℓ₂-r : Plus la valeur est basse, plus les plongements sont précis et cohérents.
- PAR : Le juste milieu est la meilleure solution, il démontre une cohérence sans effondrement.
- CA : Plus élevé = meilleur alignement sémantique.
- MI : Plus élevé = résultats plus informatifs.
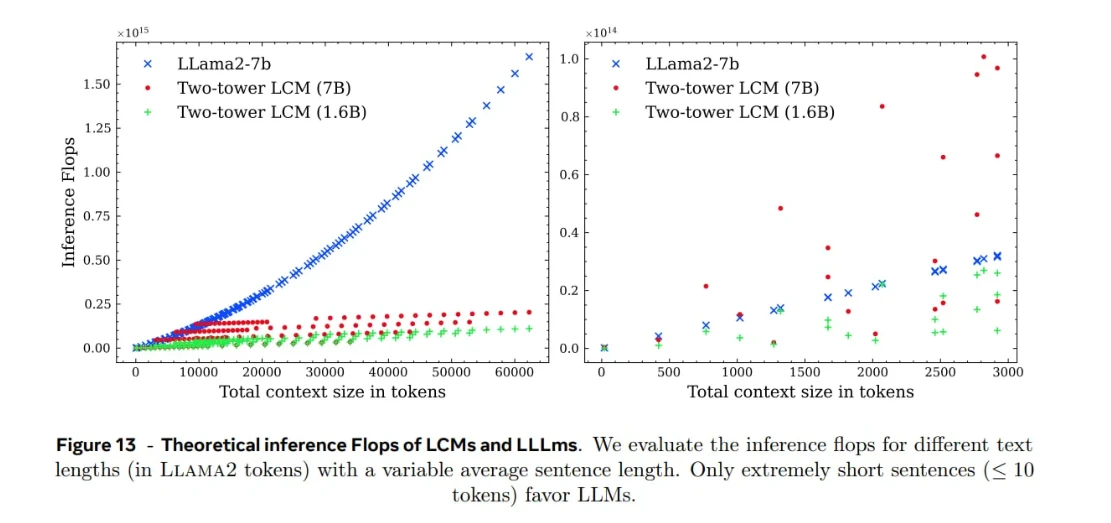
Évaluation comparative de l'efficacité du LCM
Les expériences de Meta ont montré que les modèles LCM s'adaptent mieux à la longueur du contexte que les modèles LLM lorsqu'ils traitent une même quantité de texte. Cet avantage provient du fait qu'un concept correspond à une phrase complète , qui comprend plusieurs tokens. Comme il y a moins de concepts que de tokens, le modèle a moins d'unités à traiter et l'attention quadratique devient moins gourmande en ressources.
Points clés à retenir :
Il est important de noter que ces gains d'efficacité dépendent fortement de la façon dont le texte est segmenté en phrases . La longueur des phrases, divisées en paragraphes, influe sur le nombre de concepts et, par conséquent, sur la charge de calcul.
Chaque inférence LCM comporte également trois étapes :
- Encodage SONAR (texte ou parole : plongements lexicaux)
- Raisonnement Transformer-LCM (intégrations de traitement)
- Décodage SONAR (intégrations : texte ou parole)
Ce pipeline introduit une surcharge, notamment pour les entrées courtes :
Pour les phrases courtes (moins de ~10 jetons), les LLM peuvent être plus efficaces que les LCM, car les étapes d'encodage et de décodage l'emportent sur les avantages du traitement au niveau conceptuel.
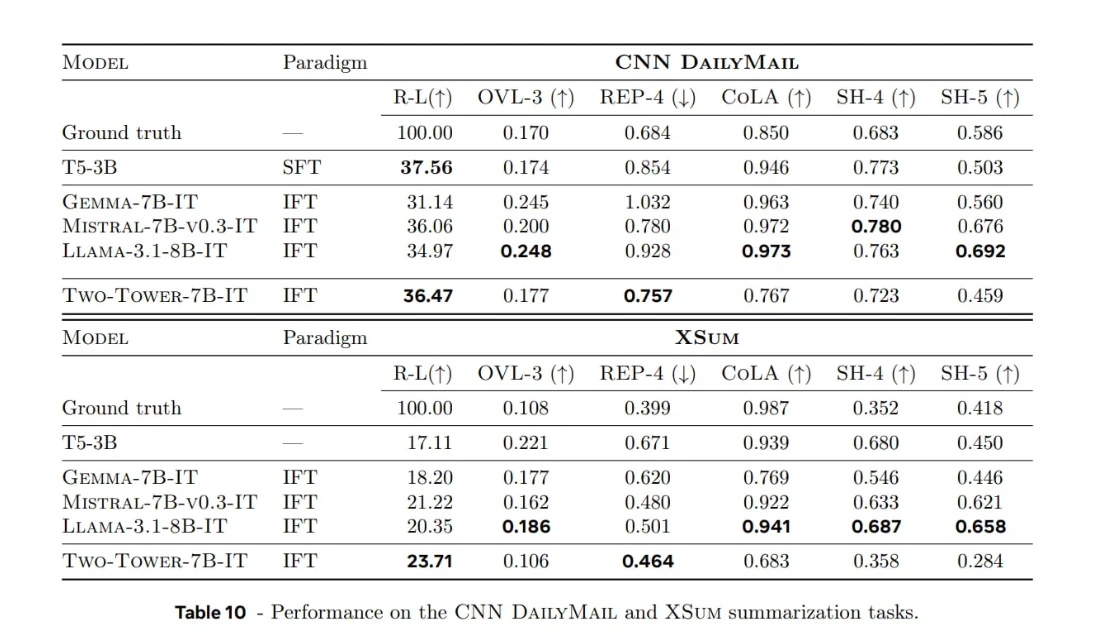
Comparaison des modèles de langage (LCM) et des modèles de langage traditionnels (LLM) pour les tâches de résumé
Meta a également évalué un LCM basé sur la diffusion (7B paramètres) sur des ensembles de données de résumé d'actualités (par exemple, CNN/DailyMail, XSum) et l'a comparé aux LLM traditionnels.
Descriptions des paradigmes :
- SFT : formation spécialisée sur des exemples de résumé.
- IFT : entraînement plus large sur des ensembles de données d’instructions, afin que le modèle apprenne la synthèse comme l’une de ses nombreuses compétences.
Descriptions des paramètres :
- ROUGE-L : Chevauchement avec les résumés de référence.
- OVL-3 : Taux de chevauchement des trigrammes d'entrée, mesurant la redondance du texte source.
- REP-4 : Rapport de répétition de quatre grammes en sortie, mesurant la répétition dans les résumés générés.
- Métriques SEAHORSE Q4 et Q5 : Mesures de qualité et de cohérence.
- Classificateur basé sur CoLA : Acceptabilité linguistique évaluée des phrases générées.
Points clés à retenir :
Force:
- Le modèle LCM de diffusion démontre une forte cohérence et un alignement contextuel dans la synthèse de textes longs, en particulier lors du traitement de contextes volumineux.
Mises en garde et considérations :
- L'évaluation cible principalement les tâches génératives (résumé) plutôt que des benchmarks généraux comme MMLU.
- La manière dont les paragraphes sont divisés en phrases (par exemple, la façon dont vous définissez les « concepts ») a un impact important sur les performances.
- En matière de fluidité et d'acceptabilité linguistiques , les LLM basés sur les tokens, comme LLaMA-3.1-8B et Mistral-7B, conservent un avantage certain. Bien que les LCM soient prometteurs, ils n'offrent pas encore de gains significatifs sur tous les plans, notamment en termes de fluidité et de flexibilité.
Citer cette recherche
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{LCM : De la tokenisation LLM à la représentation au niveau conceptuel}},
year = {2026},
month = jan,
howpublished = {\url{https://aimultiple.com/large-concept-models}},
note = {AIMultiple. Retrieved Janvier 23, 2026}
}

Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.