Top 6 Outils de découverte de données sensibles open source
Les outils suivants sont sélectionnés en fonction de l'activité GitHub et triés par nombre d'étoiles GitHub dans l'ordre décroissant. Ils couvrent les principaux cas d'utilisation pour la découverte de données sensibles : catalogage des métadonnées avec lignage, analyse sans agent et détection basée sur API des données PII, PCI et des identifiants au repos.
Lire la suite : Outils de découverte et de classification des données sensibles, Logiciels DLP.
Fonctionnalités administratives
Outil | Tableau de bord graphique | Basé sur la recherche | Lignage des données | Système de base de données fédéré |
|---|---|---|---|---|
DataHub | ✅ | ✅ | ✅ | ✅ |
Apache – Atlas | ✅ | ✅ | ✅ | ❌ |
Marquez | ✅ | ✅ | ✅ | Non partagé. |
OpenDLP | ❌ | ❌ | ❌ | ❌ |
Piiano Vault – ReDiscovery | ❌ | Non partagé. | ❌ | ❌ |
Nightfall AI – Sensitive data scanner | ✅ | ✅ | ❌ | ❌ |
Descriptions des fonctionnalités :
- Tableau de bord graphique – permet de visualiser vos résultats de données.
- Basé sur la recherche fonctionnalité – permet de rechercher des actifs de données.
- Lignage des données – permet aux utilisateurs de visualiser comment les données sont générées, transformées, transmises et utilisées dans un système au fil du temps.
- Système de base de données fédéré – mappe plusieurs systèmes de bases de données autonomes en une seule base de données fédérée.
Ces fonctionnalités (en particulier le lignage des données et les capacités de recherche) permettent aux entreprises de :
- Révéler l'emplacement de leurs informations personnelles (PII), données de l'industrie des cartes de paiement (PCI), etc., stockées dans plusieurs bases de données, applications et terminaux utilisateurs.
- Se conformer aux normes réglementaires de protection des données et de confidentialité de l'industrie telles que le Règlement général sur la protection des données (RGPD) et le California Consumer Privacy Act (CCPA).
Fonctionnalités de sécurité des données
Descriptions des fonctionnalités :
- Masquage des données– permet de masquer les données en modifiant leurs lettres et chiffres d'origine, de sorte qu'elles n'aient aucune valeur pour les intrus non autorisés tout en restant utilisables par les employés autorisés.
- Prévention de la perte de données (DLP) – détecte les violations de données potentielles et les empêche en bloquant les données sensibles.
Catégories et étoiles GitHub
Sélection et tri des outils :
- Nombre d'avis : 10+ étoiles GitHub.
- Publication de mise à jour : Au moins une mise à jour a été publiée la semaine dernière en novembre 2024.
- Tri : Les outils sont triés par étoiles GitHub dans l'ordre décroissant.
DataHub
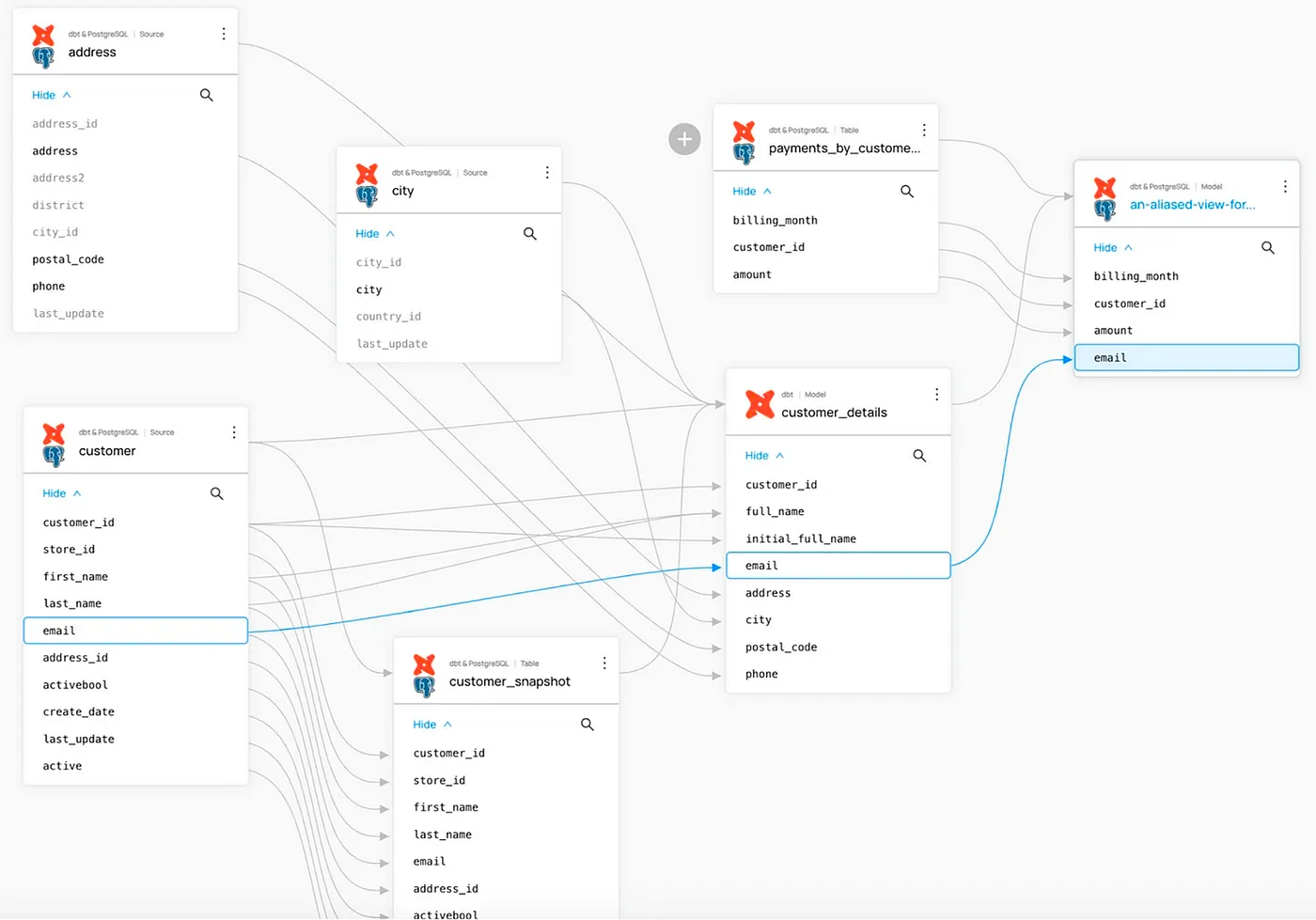
DataHub est une plateforme unifiée open source pour la découverte de données sensibles, l'observabilité et la gouvernance, développée par Acryl Data et LinkedIn. Elle est également proposée commercialement par Acryl Data en tant qu'offre SaaS hébergée dans le cloud.
Fonctionnalités clés :
- Lignage des données au niveau des colonnes : trace le flux de données de la source à la consommation à travers les plateformes.
- Qualité des données assistée par IA : la détection d'anomalies signale automatiquement les problèmes de qualité des données.
- Extensibilité : REST APIs, SDK Python et intégration LangChain pour créer des agents ayant accès aux métadonnées DataHub.
- 80+ connecteurs natifs : Snowflake, BigQuery, Redshift, Hive, Athena, Postgres, MySQL, SQL Server, Trino, Looker, Power BI, Tableau, Okta, LDAP, S3, Delta Lake et autres.
Considération : L'architecture de DataHub exécute plusieurs services interconnectés (GMS, consommateur MCE, consommateur MAE, index de recherche, stockage de graphes). Les déploiements en production nécessitent généralement Kubernetes. La complexité de la configuration est le point de douleur le plus fréquemment cité dans la communauté.
Apache – Atlas
Apache Atlas est un outil open source pour la gestion et la gouvernance des métadonnées, conçu principalement pour Hadoop et les écosystèmes de big data. Il prend en charge la classification, le suivi du lignage et la recherche dans les actifs de données dans les environnements construits sur Hive, HBase, Kafka, Spark, Sqoop et Storm.
Fonctionnalités clés
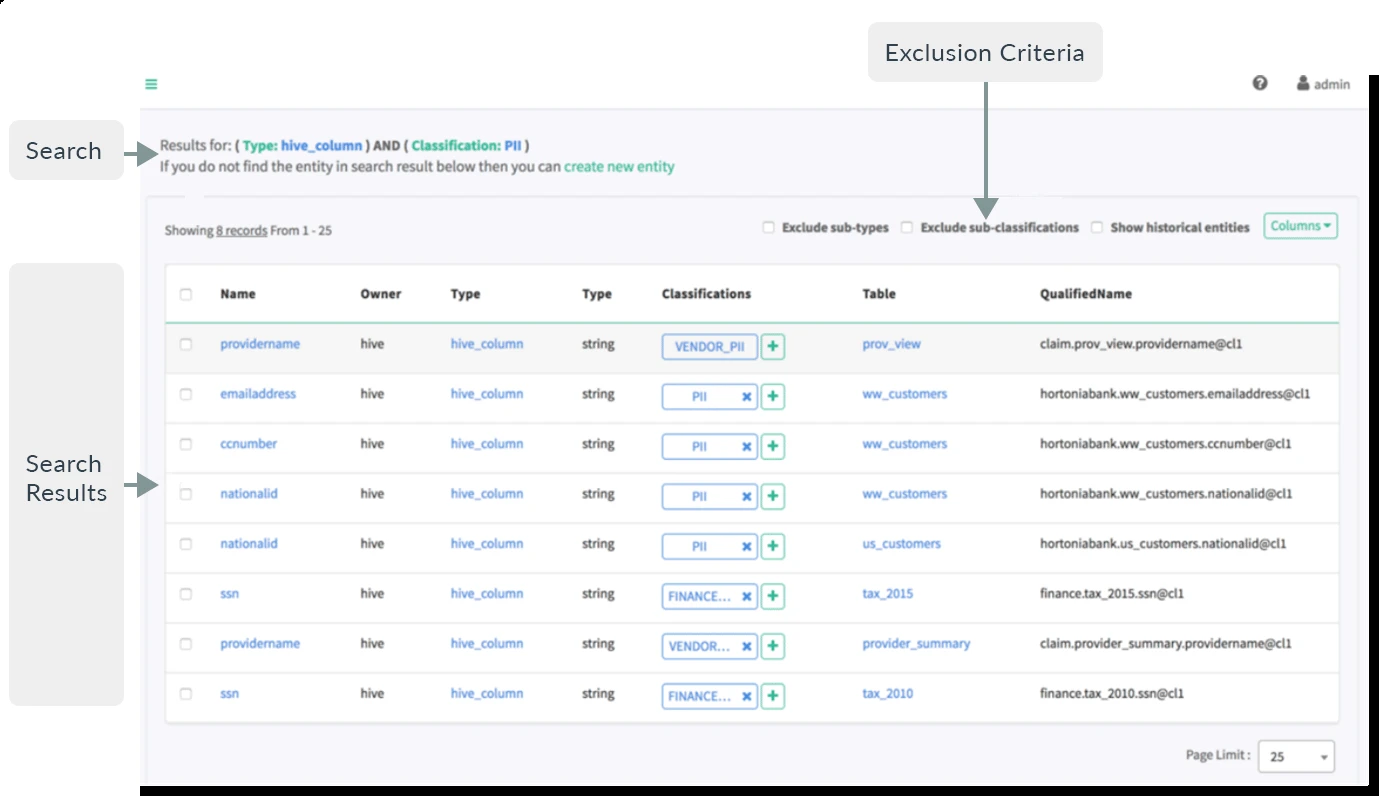
- Classification dynamique : Apache Atlas permet de créer des classifications personnalisées telles que PII (Personally Identifiable Information), EXPIRES_ON, DATA_QUALITY et SENSITIVE.
- Types de métadonnées : La plateforme fournit des types de métadonnées prédéfinis pour les environnements Hadoop et non Hadoop. Cela permet aux utilisateurs de gérer les métadonnées pour plusieurs sources de données, telles que HBase, Hive, Sqoop, Kafka et Storm.
- SQL-like query language (DSL): La plateforme prend en charge un langage spécifique au domaine (DSL) qui fournit une fonctionnalité de requête de type SQL pour rechercher des entités. Cela le rend accessible aux utilisateurs familiers avec SQL.
- Intégration avec des outils externes : Apache Hive, Apache Spark, Kafka et Presto, le rendant adaptable aux environnements de big data.
Considérations :
- La configuration d'Atlas dans un environnement multi-cloud est complexe, en particulier lors de la liaison des Azure, Databricks et API AWS. Atlas ne dispose pas de connecteurs natifs pour ces plateformes ; une configuration supplémentaire est requise pour enregistrer le lignage depuis AWS Redshift ou Azure Synapse.
- Les services de catalogage natifs du cloud (par exemple, AWS Glue) peuvent offrir un suivi du lignage avec moins de surcharge pour les équipes déjà engagées auprès d'un seul fournisseur de cloud.
- Atlas convient mieux aux organisations exécutant Hadoop, Spark et Hive à grande échelle. Les équipes sans stack centrée sur Hadoop trouveront que son architecture ajoute une complexité inutile.
Marquez
Marquez est un catalogue de données open source pour collecter, agréger et visualiser les métadonnées d'un écosystème de données. Il fournit une interface utilisateur Web et une API REST pour parcourir les ensembles de données, comprendre leurs dépendances et suivre les modifications via des pipelines de données.
- Rechercher des ensembles de données : Les utilisateurs peuvent facilement rechercher des ensembles de données, voir leurs attributs et comprendre leurs dépendances dans tout l'écosystème de données.
- Visualiser le lignage : Le graphique de lignage dans Marquez fournit une vue claire et interactive de la manière dont les ensembles de données sont connectés et transformés via des flux de travail. Cela est crucial pour comprendre les pipelines de données, tracer les erreurs et assurer la fiabilité des données.
- Entrepôt de métadonnées centralisé : Marquez agrège les métadonnées de diverses sources, les consolidant dans un seul système pour un accès et une gestion faciles.
Exemple de flux de travail : Pour inspecter les métadonnées de lignage, naviguez vers l'interface utilisateur Marquez et recherchez un travail (par exemple, etl_delivery_7_days) à l'aide de la zone de recherche. À partir de l'ensemble de données de sortie du travail (public.delivery_7_daysYou can view the dataset name, schema, description, and upstream inputs.
Piiano Vault – ReDiscovery
Piiano Vault est un coffre-fort de confidentialité pour stocker et sécuriser les données personnelles sensibles au sein de votre propre environnement cloud. Plutôt que d'analyser les bases de données existantes à la recherche de données sensibles, Vault est conçu comme le magasin autoritaire pour les champs les plus sensibles : numéros de carte de crédit, numéros de compte bancaire, identifiants nationaux (SSNs), noms, e-mails et numéros de téléphone, installés à côté de vos bases de données d'applications existantes.
Vault est déployé dans votre architecture via Docker ou Kubernetes (Helm charts disponibles). Des SDK sont disponibles pour Python (Django ORM), TypeScript, Java et Go. Le dépôt vault-releases a été mis à jour pour la dernière fois en août 2025.
Distinction des cas d'utilisation : Vault n'est pas un scanner de découverte de données. C'est un système de stockage structuré pour les données sensibles que les organisations souhaitent centraliser et protéger, et non un outil pour trouver des données sensibles déjà dispersées dans les systèmes existants.
Nightfall
Nightfall est une plateforme DLP native à l'IA commerciale, et non un outil entièrement open source. Ses dépôts GitHub incluent des scripts d'analyse open source (Apache 2.0) qui utilisent l'API de Nightfall pour analyser les répertoires, les exports et les sauvegardes. L'exécution des analyses nécessite une clé API Nightfall et appelle le moteur de détection commercial de Nightfall. La version gratuite permet jusqu'à 100 analyses par mois sur les dépôts publics et privés.
Fonctionnalités du scanner open source (version gratuite) :
- Analyse l'historique complet des commits des dépôts publics et privés.
- Détecte les identifiants, les secrets, les PII et les numéros de carte de crédit.
- Exécute jusqu'à 100 analyses par mois.
Fonctionnalité distinctive : Nightfall peut envoyer des alertes à Slack lorsque des violations sont détectées et pousser les résultats vers un SIEM, un outil de reporting ou un point de terminaison webhook.
Exemple de cas d'utilisation : Analysez une sauvegarde Salesforce pour détecter les données sensibles au repos. Le scanner (1) soumet les fichiers de sauvegarde à l'API de Nightfall pour analyse, (2) exécute un serveur webhook local pour recevoir les résultats et (3) exporte les résultats vers un fichier CSV.
L'URL ci-dessus est fournie par Nightfall. C'est l'URL S3 signée temporairement pour récupérer les résultats sensibles que Nightfall a identifiés.
Pour aller plus loin
Citer cette recherche
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sezer, Sena},
title = {{Top 6 Outils de découverte de données sensibles open source}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/open-source-sensitive-data-discovery}},
note = {AIMultiple. Consulté le 24 Juin 2026}
}


Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.