Meilleurs 50+ agents IA open source répertoriés
Tout le monde a créé des agents IA, alors après des tests pratiques avec des agents de codage IA, des constructeurs d'agents IA et des outils d'utilisation de benchmarks pour évaluer leurs capacités dans le monde réel, nous avons compilé une liste des meilleurs 50+ agents IA open source. Cliquez sur les en-têtes de catégorie pour accéder directement à nos meilleurs choix :
Développement d'agents et infrastructure
- Frameworks d'agents (À construire soi-même)
- Outils d'automatisation et d'orchestration de flux de travail
Applications d'agents spécifiques au domaine
- Agents d'automatisation et de navigation web
- Outils de codage et de développement
- Outils de cybersécurité
- Créateurs de contenu vidéo IA
- Assistants financiers
- Assistants de santé
- Agents de recherche
- Assistants d'analyse de données
- Assistants personnels
Comment penser les agents IA ?
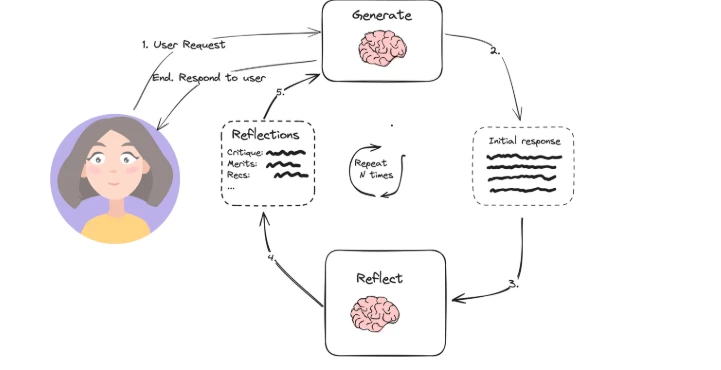
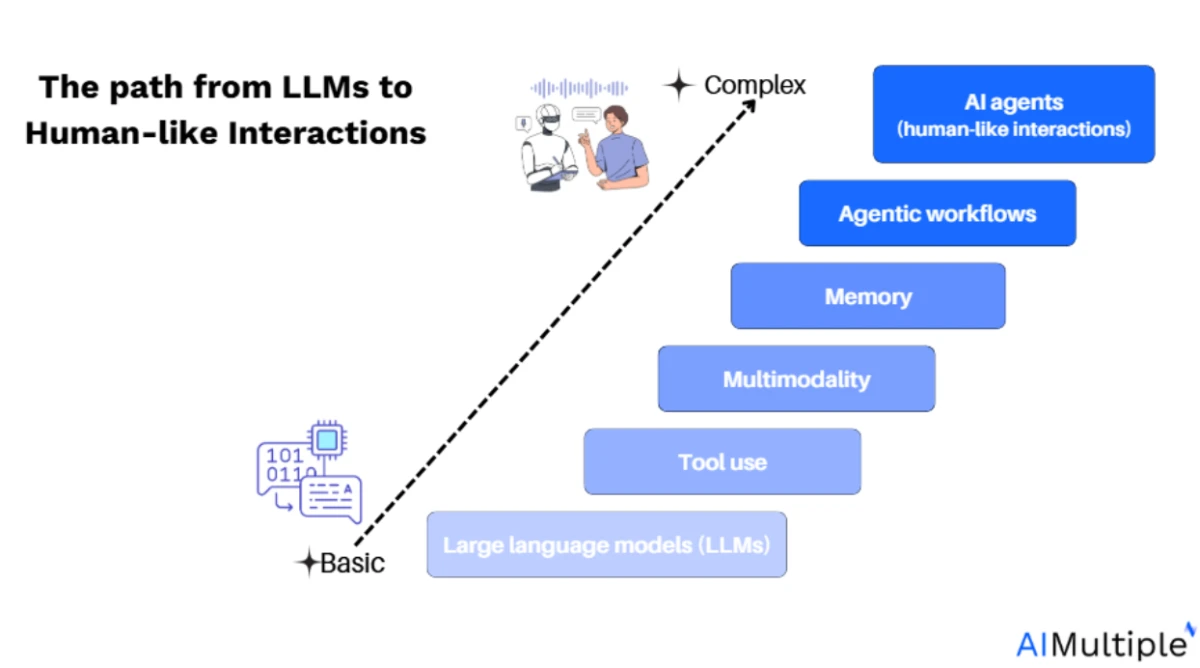
Un agent IA est un système composable qui combine planification, mémoire, utilisation d'outils et exécution itérative. Il forme une boucle structurée autour d'un LLM qui peut prendre des décisions, effectuer des actions et s'adapter à de nouvelles informations.
Voici comment y penser :
- Autonomie et flux de travail : Les agents IA vont de l'automatisation de base de tâches basée sur des workflows prédéfinis à des systèmes entièrement autonomes capables de décomposition d'objectifs, d'utilisation de mémoire et d'interaction avec des outils. Le défi technique central réside dans le maintien du contexte à travers les étapes et la coordination d'opérations en plusieurs étapes.
- Contexte et contrôle : Le véritable défi dans les agents IA est de s'assurer que le LLM dispose du contexte approprié à chaque étape. Cela inclut la gestion du contenu fourni au LLM et la garantie que l'agent exécute des tâches pertinentes basées sur un contexte à jour.
- Intégration d'outils : Construire des agents efficaces nécessite une intégration transparente avec des outils externes, des APIs et des sources de données. Des frameworks comme LangChain peuvent aider à intégrer ces ressources externes, mais le contrôle du flux de travail est essentiel pour adapter le comportement de l'agent à de nouvelles entrées.
- Avantages des frameworks d'agents : Tous les systèmes agentiques, qu'il s'agisse de simples workflows ou d'agents autonomes complexes, peuvent bénéficier des fonctionnalités centrales fournies par les frameworks agentiques. Ces fonctionnalités peuvent être construites de zéro ou tirées d'une plateforme open source existante, selon vos besoins.
Nouvelles normes
- Model Context Protocol (MCP) : La norme industrielle sur la façon dont les agents communiquent avec les sources de données externes. LangGraph intègre MCP pour permettre aux agents de « brancher et jouer » avec des bases de données et des outils locaux sans wrappers personnalisés.
- Stripe Agentic Commerce Protocol (ACP) : C'est la première norme industrielle vivante qui permet aux agents IA de gérer les paiements, les stocks et les expéditions de manière sécurisée. Il permet le « Checkout Agentique », où l'agent peut finaliser un achat pour l'utilisateur au sein d'une interface de chat.
Qu'est-ce qu'un agent IA exactement ?
Il n'existe pas de définition universellement acceptée de ce qui constitue un « agent IA ».
- L'IA traditionnelle définit les agents comme des systèmes qui interagissent avec leur environnement.
- L'enquête de Simon Willison auprès des praticiens présente une variété de définitions de travail de la part des participants de l'industrie.2
- La définition d'Anthropic expose des principes de conception pour construire des agents IA efficaces et alignés.3
- Les principaux cabinets de conseil soulignent le rôle des agents dans l'automatisation des workflows métier et la prise de décision.4 .
Nombre d'entre eux incluent explicitement les workflows et l'autonomie à la fin d'un spectre.
Nous sommes d'accord avec ces points de vue, c'est pourquoi nous ne fournissons pas de définition stricte. Nous énumérons plutôt les facteurs qui font qu'un système IA est considéré comme plus agentique :
- Environnement et objectifs :
- Les systèmes IA dans des environnements complexes, tels que ceux comportant de multiples tâches et des changements inattendus, sont agentiques.
- Les systèmes IA qui suivent des objectifs sans instruction sont agentiques.
- Interface utilisateur et supervision : Les systèmes IA capables d'apprendre des langues naturelles et les systèmes nécessitant moins de supervision utilisateur sont agentiques.
- Conception du système : Les systèmes qui utilisent des modèles de conception tels que l'utilisation d'outils (par ex., recherche web, programmation) ou la planification (par ex., réflexion, décomposition en sous-objectifs) sont agentiques.
Pour une explication plus détaillée, nous avons précédemment énuméré ces facteurs et discuté de la manière dont ils définissent les systèmes IA agentiques.
Ces agents sont-ils entièrement autonomes ?
Pas encore. La plupart des agents IA open source améliorent l'autonomie des LLM en permettant l'utilisation d'outils, la prise de décision et la résolution de problèmes, mais ils nécessitent toujours des entrées structurées et une intervention humaine.
Des exemples comme Devon et PR-Agent suivent des workflows logiques prédéfinis ou par RL plutôt que de démontrer un comportement agentique complet. D'autres agents IA manquent encore de capacités (Apprentissage Autonome + Généralisation).
Quand (et quand ne pas) utiliser des agents IA
Toutes les applications de LLM ne nécessitent pas une complexité agentique. De nombreux cas d'usage sont mieux servis par une génération augmentée par récupération (RAG) légère.
Les systèmes agentiques introduisent une surcharge architecturale : gestion de la mémoire, orchestration des outils, gestion des erreurs et boucles de contrôle qui augmentent la latence et le coût. Par exemple, dans nos benchmarks, nous avons observé que les taux de succès des agents IA diminuaient après 35 minutes d'interaction humaine.
Pour atténuer ces risques, il est essentiel de tester les systèmes agentiques dans des environnements contrôlés et de mettre en place des garde-fous solides avant le déploiement.
Les agents sont les plus précieux lorsque les étapes ne peuvent pas être facilement prédites ou codées en dur. Ils sont particulièrement adaptés aux situations où :
- Les tâches sont dynamiques et en plusieurs étapes, avec une logique de branchement ou des sous-objectifs peu clairs.
- L'utilisation d'outils est conditionnelle ou adaptative, nécessitant que le système choisisse quel outil invoquer en fonction de l'entrée ou de l'état précédent.
- Une mémoire à long terme ou un contexte est nécessaire, à travers les sessions ou les étapes d'exécution.
- L'exécution doit répondre aux retours de l'environnement, tels que les résultats d'API, les sorties de recherche ou les actions échouées.
- Une collaboration humain-dans-la-boucle est nécessaire, où l'autonomie et la supervision doivent être mélangées (par ex., copilotes IA).
D'un autre côté, les workflows ou les appels LLM sans état sont préférables lorsque :
- La logique de la tâche est statique ou prévisible, comme le remplissage de formulaires ou la transformation de contenu.
- Une faible latence est critique, comme dans les interactions avec l'utilisateur.
- Minimiser le coût est essentiel, en particulier en évitant les appels récursifs au LLM et l'orchestration complexe.
Pour en savoir plus
Voici nos derniers benchmarks sur les infrastructures couramment utilisées par les systèmes agentiques :
- Navigateurs distants : Comment l'infrastructure de navigation permet aux agents d'interagir avec le web en toute sécurité.
- Benchmark Browser MCP : Principaux serveurs MCP pour l'utilisation d'outils et l'accès web.
Exemples d'agents IA open source
Certains outils décrits comme des « agents IA » ne sont en réalité pas si agentiques ; ces systèmes (par ex., Devon PR-agent) sont en grande partie des workflows IA basés sur RL, avec des LLM organisés par des chemins de code prédéfinis.
1. Frameworks d'agents (À construire soi-même)
Bibliothèques modulaires et SDKs pour les développeurs afin de construire des agents avec un contrôle sur la logique, la mémoire, les outils et l'orchestration.
✳️ Certains agents comme SmolAgents et Agno s'intègrent à la fois dans les catégories frameworks d'agents et automatisation de workflow.
Frameworks d'agents généraux
Frameworks qui se concentrent sur la construction d'agents, offrant des outils flexibles et personnalisables pour orchestrer des workflows, des configurations multi-agents et des cas d'usage généraux.
- LangGraph – Orchestration de workflow LLM basée sur graphe – LangGraph est un logiciel propriétaire, mais il fournit une bibliothèque open source pour le développement d'agents. Idéal pour les pipelines RAG, la mémoire d'agent/ la gestion d'état, et les configurations multi-agents.
- AutoGen – Collaboration multi-agents asynchrone – Conçu pour coordonner des agents utilisant des outils via des APIs de type chat. Idéal pour automatiser des workflows complexes, en particulier dans la génération autonome de code.
- CrewAI – Framework multi-agents no-code/low-code – L'un des outils les plus simples pour commencer, offrant des modèles d'agents prêts à l'emploi (par ex., agent de préparation de réunion).
Frameworks d'agents spécialisés
Frameworks avec un focus spécialisé sur des types spécifiques de comportements d'agents ou d'intégrations d'agents.
- Camel – Simulation d'agents basée sur les rôles – Optimisé pour des agents collaboratifs et de jeu de rôle utilisant un raisonnement structuré. Idéal pour l'automatisation de workflow et la génération de données synthétiques.
- Mastra – Développement d'agents intégré au frontend – Basé sur JavaScript, idéal pour intégrer des agents dans des applications orientées utilisateur.
- PydanticAI – Contrôle minimal d'agent typé – Fournit une validation stricte et des chemins logiques transparents avec Pydantic.
- Cybersecurity IA (CAI) – Framework d'agents de cybersécurité piloté par IA – Fournit des tests de pénétration, la découverte de vulnérabilités et le red teaming avec des capacités humain-dans-la-boucle, en exploitant de grands modèles de langage et des intégrations avec des outils comme Nmap.
- Atomic Agents – Constructeur d'agent granulaire avec schéma d'abord – Conçu pour une structure d'agent granulaire et une logique composable.
- SmolAgents – SDK d'agent léger pour développeurs – Abstraction minimale, achemine la logique via Python au lieu de JSON.
Environnements d'exécution d'agents (Agents autonomes pré-construits)
Agents autonomes pré-construits que vous pouvez lancer immédiatement (comme une application). Généralement capables d'exécuter des tâches de manière autonome à partir d'objectifs en langage naturel.
Entièrement autonomes :
- Auto-GPT – Décomposition d'objectifs et exécution autonome – Décompose les objectifs en sous-tâches et les réalise à l'aide d'outils, de mémoire et de raisonnement. Offre des agents pré-construits et une interface low-code.
- AIlice – Exécution de tâches généraliste locale – Exécute des tâches complexes sur l'appareil, prend en charge les outils locaux et la manipulation de fichiers. Vise à créer un assistant IA, similaire à JARVIS, basé sur le LLM open source.
- Manus IA – Opérations en bac à sable généraliste. Exécute des outils et des workflows dans un bac à sable sécurisé, capable de gérer des opérations multi-domaines et en plusieurs étapes de manière autonome. Il a été acquis par Meta, s'intégrant à l'écosystème « Personal Ambient Intelligence » de Meta.5
Partiellement autonomes :
- BabyAGI – Exécuteur de boucle de tâches itérative – Crée, priorise et exécute des listes de tâches dans une boucle de rétroaction. Idéal pour les expériences de génération de tâches.
Basés sur navigateur/interface :
- AgentGPT – Agent autonome déployé dans le navigateur – Permet aux utilisateurs de créer et d'exécuter des agents de tâches via une interface web. Léger, idéal pour l'expérimentation.
- OpenManus – Agent de navigateur persistant – Conçu pour des workflows couvrant plusieurs sessions dans des environnements de navigateur. Utilise des outils comme Playwright pour automatiser les interactions web. Idéal pour une utilisation avec les pipelines d'automatisation existants. L'installation est rapide avec Conda.
2. Automatisation et orchestration de flux de travail
Outils qui automatisent les workflows et intègrent plusieurs plateformes ou services, souvent avec la capacité d'intégrer des agents IA.
Automatisation et intégration générales de flux de travail
Plateformes qui connectent les APIs, déclenchent des événements et automatisent des tâches, facilitant la construction et l'intégration de workflows à travers différents systèmes.
- n8n – Automatisation visuelle de workflow et intégration d'APIs – Connecte les applications, les déclencheurs et les flux de données à l'aide d'un éditeur de nœuds. Il combine la construction visuelle no-code avec du code JavaScript/Python personnalisé et prend en charge plus de 400 intégrations. Vous pouvez l'auto-héberger, exécuter des workflows d'agents IA avec LangChain. Idéal pour les personnes techniques.
- PlanExe – Outil de planification LLM vers Gantt/WBS – Planificateur IA similaire à la recherche approfondie d'OpenAI. Convertit les objectifs en langage naturel en chronologies structurées à l'aide de LlamaIndex.
- Agno ✳️ – Constructeur de workflow et d'agent convivial pour les développeurs – Il s'adapte à la fois comme outil d'automatisation de workflow (aidant à automatiser des tâches et des workflows) et comme constructeur d'agents.
- SmolAgents ✳️ – SDK d'agent léger pour développeurs – SmolAgents est suffisamment flexible pour s'intégrer à la fois comme un SDK d'agent léger (pour les frameworks d'agents) et comme un outil de workflow (car il s'intègre avec les modèles Hugging Face).
- Windmill – Plateforme de développement open source et moteur de workflow – Convertit les scripts en UIs, APIs et tâches cron ; prend en charge Python, TypeScript, Go, et d'autres langages.
- Activepieces – Plateforme d'automatisation open source – Constructeur visuel de workflow auto-hébergé pour automatiser des tâches et intégrer des applications avec un minimum de code. Il prend en charge 280+ serveurs MCP pour exécuter des tâches IA distribuées et des chaînes d'agents à grande échelle.
- Huginn – Automatisation web et gestion d'agents – Construit des agents pour automatiser des tâches basées sur le web et la surveillance.
- Node-RED – Développement basé sur les flux pour l'IoT et les données en temps réel – Intègre des services et automatise des tâches avec un éditeur de flux basé sur navigateur.
Orchestration de workflows multi-agents
Frameworks conçus pour coordonner des agents en interaction à travers des workflows structurés et intégrer des systèmes multi-agents.
- HyperAgent – Orchestration d'agents sur tout le cycle de vie logiciel – Les agents travaillent ensemble pour planifier, coder et vérifier les tâches d'ingénierie.
- Supercog – agentic – Orchestration modulaire avec des blocs logiques réutilisables – Conçu pour une automatisation évolutive, structurée et basée sur des équipes.
3. Automatisation et navigation web
Agents naviguant de manière autonome sur des sites web et effectuant des tâches en plusieurs étapes, telles que le remplissage de formulaires, l'extraction de données et l'automatisation de la navigation web.
Agents web autonomes et copilotes
Agents autonomes généralistes (capables d'interagir avec le web) :
- AgenticSeek – Agent de navigation web entièrement autonome – Entièrement local Manus IA. Se spécialise dans l'extraction de données et le remplissage de formulaires, automatisant les tâches basées sur le web.
- Agent-E – Agent d'automatisation de navigateur sensible au DOM – Se concentre sur l'interaction avec les pages web en analysant le (Document Object Model) DOM, idéal pour cliquer sur des boutons et remplir des formulaires.
- AutoWebGLM – Agent web basé sur LLM – Utilise l'apprentissage par renforcement et la simplification HTML pour une meilleure navigation sur des sites web complexes.
Agents de navigation web basés sur la vision (multimodaux) :
- Autogen extension WebSurfer – Agent web multimodal – Combine entrée texte et visuelle (captures d'écran) pour améliorer l'interaction web.
- Skyvern – Agent IA avec vision par ordinateur – Automatise les workflows en utilisant des LLMs et la vision par ordinateur, traitant à la fois les éléments textuels et visuels.
- WebVoyager – Agent web doté de vision – Utilise le texte et les captures d'écran pour améliorer la navigation sur les sites web riches en images.
Pour en savoir plus sur l'automatisation et la navigation web open source, voici un aperçu structuré de certains des meilleurs outils et agents :
Agents d'utilisation d'ordinateur
Kits d'outils d'automatisation et de scraping web
RPA web basée sur LLM et extensions de navigateur
4. Codage et développement
Agents IA conçus pour assister les tâches de codage, fournissant un support en temps réel aux développeurs via des suggestions de code, le débogage et l'automatisation de tâches.
Agents de codage basés sur CLI
- Codex CLI – Outil d'interaction multi-mode (suggérer, éditer, exécuter) – Améliore les workflows des développeurs via la ligne de commande en offrant des suggestions et des modifications de code.
- OpenDevin – Assistant de codage IA open source – Aide aux tâches de programmation, offrant des suggestions de code pour divers langages. Notez qu'OpenDevin a récemment été renommé OpenHands pour refléter sa mission élargie de « All Hands IA ».6
- Aider – Assistant de programmation en binôme IA – Intégré à votre terminal pour une assistance au codage, prenant en charge l'autocomplétion, le débogage et l'automatisation de tâches.
Éditeurs de code IA
- Neovim – Éditeur de code intégré à l'IA – Plugins alimentés par l'IA fournissant des complétions de code, du refactoring.
- Visual Studio Code (VS Code) – Outil de complétion et de débogage de code alimenté par l'IA – Offre des suggestions de code et l'autocomplétion via GitHub Copilot, intégré aux environnements IDE pour les développeurs.
- Cursor – Éditeur de code intégré à l'IA – Construit avec une complétion de code alimentée par l'IA en temps réel.
Constructeurs d'applications par prompt (Vibe coding)
Alternatives open source à v0 / lovable / Bolt :
- Dyad – Constructeur d'applications IA open source – Outil local-first, no-code pour construire des applications pilotées par IA avec des commandes en langage naturel.
- vx.dev – Constructeur d'applications IA open source – Un outil local-first, low-code axé sur la transformation de prompts en langage naturel en applications.
5. Cybersécurité
Agents IA conçus pour améliorer les opérations de cybersécurité, y compris des tâches telles que les tests de pénétration, la découverte de vulnérabilités, le red teaming et la détection autonome de menaces.
- YAWNING TITAN – Simulation de cybersécurité abstraite basée sur graphes – Prend en charge l'entraînement d'agents pour des opérations cybernétiques autonomes en se concentrant sur des environnements basés sur des graphes.
- bumpgen – Agent de gestion de paquets – Met à niveau les paquets npm (gestionnaire de paquets Node.js) automatiquement.
- Cyber-Security LLM Agents – Tâches de cybersécurité pilotées par LLM – Construit sur AutoGen. Utilisé dans diverses applications de recherche pour démontrer l'automatisation EDR avec ChatGPT et un CI/CD automatisé pour l'ingénierie de détection.
6. Création de contenu vidéo IA
Agents IA qui aident à générer, éditer et améliorer du contenu visuel et multimédia, y compris l'art, les images et les vidéos.
- Mochi – Génération texte-vidéo – Convertit des prompts textuels en vidéo, en se concentrant sur la création de courtes vidéos. Bien adapté pour générer rapidement des vidéos à partir de descriptions textuelles.
- CogVideo – Génération texte-vidéo – Convertit des prompts textuels en vidéo avec une haute fidélité, permettant la création image-vidéo. Un outil plus avancé pour une génération vidéo de haute qualité à partir de texte ou d'images.
- Allegro – Génération texte-vidéo – Convertit des prompts textuels en vidéo en mettant l'accent sur la création de contenu créatif. Cet outil met l'accent sur la synthèse vidéo créative à partir de texte pour produire des récits visuels uniques.
- DALL·E (versions open source) – Génération texte-vidéo – Génère des images à partir de descriptions textuelles, transformant les prompts écrits en contenu visuel détaillé et créatif.
7. Finance
Agents IA qui fournissent une amélioration par apprentissage par renforcement automatisé ou une analyse de données financières en temps réel.
- FinRL – Apprentissage par renforcement automatisé pour le trading – Apprend et exécute de manière autonome des stratégies de trading basées sur les données de marché, s'adaptant aux environnements financiers dynamiques.
- OpenBB Terminal – Analyse de données financières – Fournit des informations financières autonomes pour le trading en temps réel, permettant aux professionnels de l'investissement de prendre des décisions éclairées.
8. Santé
Agents IA qui aident au diagnostic médical, au suivi des maladies et aux informations de santé en analysant les données des patients et les rapports médicaux.
- HIA (Health Insights Agent) – Analyse de rapports médicaux – Analyse les rapports médicaux et fournit des informations de santé.
- IA-HealthCare-Assistant – Diagnostic et suivi de maladies – Diagnostique et suit les maladies à l'aide des données des patients.
9. Recherche
Agents IA qui aident à la collecte de données, aux revues de littérature et aux tests d'hypothèses, rationalisant le processus de recherche.
- ChemCrow – Agent de recherche en chimie autonome – Intègre des LLMs avec des outils de chimie pour planifier et exécuter des tâches expérimentales et computationnelles complexes en analyse chimique.
- GPT Researcher – Assistant de recherche général autonome – Effectue des recherches en ligne structurées, analyse le contenu et compile des rapports de recherche détaillés avec une intervention minimale de l'utilisateur.
10. Analyse de données
Agents IA qui traitent, analysent et interprètent les données pour fournir des informations exploitables et soutenir la prise de décision.
Finance
- FinRobot – Agent d'analyse de données financières – Automatise l'interprétation et le reporting de données financières à l'aide de grands modèles de langage.
Business intelligence et interrogation
- Wren IA – Agent d'informations métier texte-SQL – Convertit les questions en langage naturel en requêtes SQL pour le reporting métier.
- Entaoai – Outil d'ingénierie de données assisté par GenAI – Fournit une interface de chat pour les tâches d'interrogation et de transformation de données.
- Vanna IA – Agent langage naturel vers SQL – Génère des requêtes SQL basées sur les prompts de l'utilisateur pour explorer des ensembles de données structurés.
Réseaux sociaux
- Twitter Personality Agent – Agent d'analyse des réseaux sociaux – Analyse l'historique des tweets pour déduire des traits comportementaux et de personnalité.
11. Assistance personnelle
Agents IA qui aident à la gestion des tâches, à la planification et à l'organisation personnelle, améliorant la productivité et la gestion du temps.
- VacAIgent (agent CrewAI pré-construit) – Assistant de planification de voyage –Génère de manière autonome des itinéraires de voyage complets en utilisant Streamlit et des LLMs.
- Inbox Zero – Assistant email – priorise, classe et résume les messages en utilisant le traitement du langage naturel et l'intégration Gmail.
- Cal – Agent de planification de calendrier – Automatise la création, la reprogrammation et le résumé de réunions via une interaction basée sur LLM.
Construire des systèmes d'agents IA
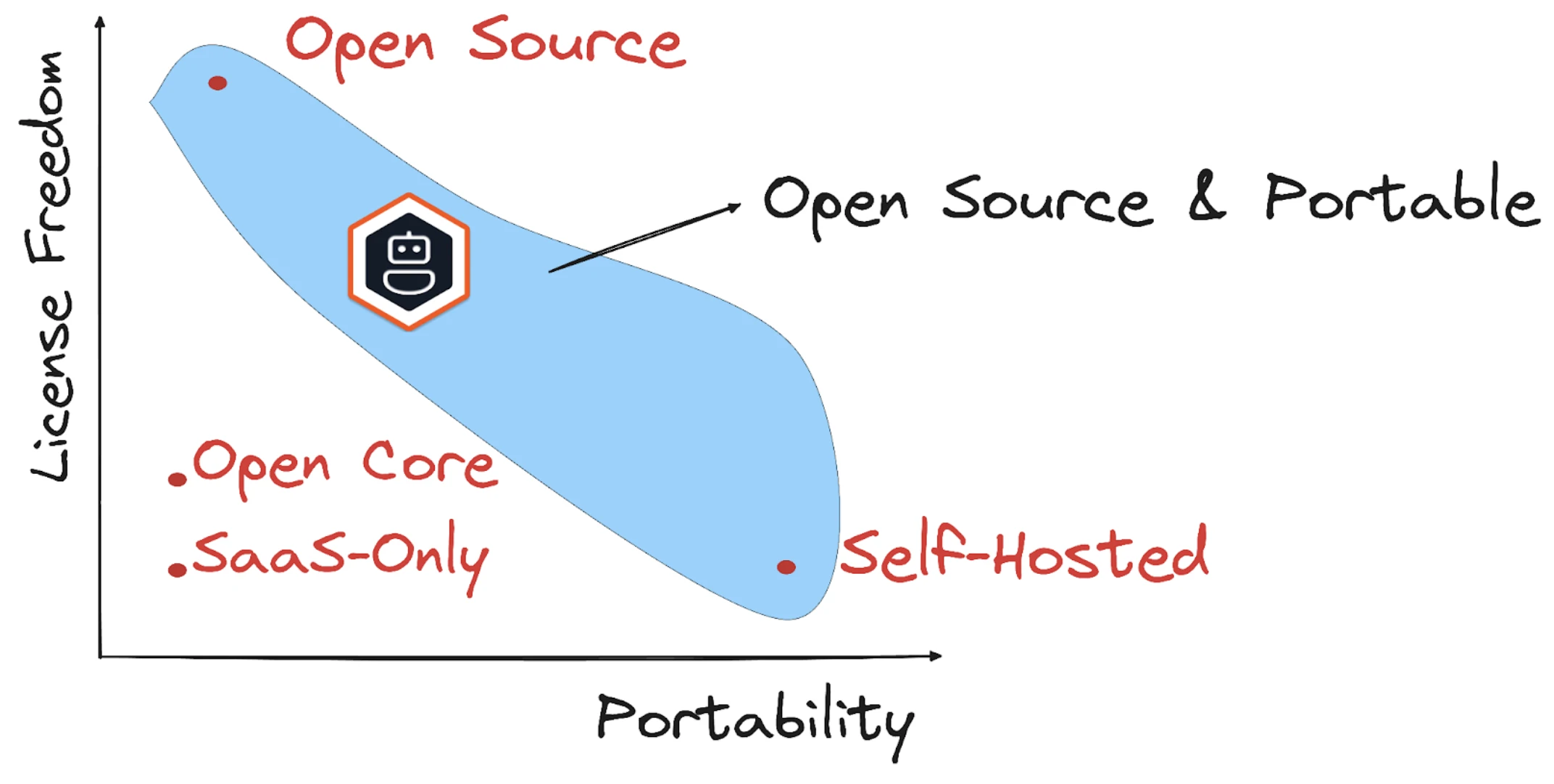
De nombreux frameworks d'IA sont contrôlés par un seul fournisseur ou des repos publics, mais étroitement gouvernés.
Ces projets évoluent souvent vers des modèles open core : le code de base reste gratuit, mais l'orchestration multi-agents, l'observabilité ou le contrôle fin peuvent être verrouillés derrière des licences commerciales. Dans certains écosystèmes « ouverts », l'utilisation en production nécessite souvent d'adopter un backend propriétaire.
Source7
Projets concrets d'agents IA
De notre expérience, voici quelques agents IA et leurs applications :
- Éditeurs de code IA pour le développement d'APIs en construisant une App
- Capture d'écran vers exécution de code pour la génération de sites web IA
- Agents d'utilisation d'ordinateur pour commander des livraisons, faire une réservation de restaurant ou concevoir une pièce.
Autres projets d'agents IA autonomes :
Autres projets d'agents IA par framework :
Pour aller plus loin
Citer cette recherche
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Şimşek, Hazal},
title = {{Meilleurs 50+ agents IA open source répertoriés}},
year = {2026},
month = may,
howpublished = {\url{https://aimultiple.com/open-source-ai-agents}},
note = {AIMultiple. Consulté le 14 Mai 2026}
}
Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.