Factura OCR Referencia: Precisión de extracción de LLMs vs OCRs
El procesamiento de facturas es una operación comercial crítica pero laboriosa que tradicionalmente requiere extracción de datos manual e ingreso en sistemas contables. Este enfoque manual consume mucho tiempo y es susceptible a errores humanos. Para evaluar alternativas automatizadas, realizamos un análisis comparativo de las principales soluciones de procesamiento de documentos y LLMs:
- Amazon Textract API
- Claude Sonnet 3.5
- Docsumo
- Google Document IA
- Microsoft Azure Document Intelligence
- Rossum
Nuestro estudio evaluó las capacidades de estas herramientas para extraer datos con precisión de diversos formatos y calidades de facturas, con el objetivo de cuantificar su eficacia como alternativas al procesamiento manual.
Resultados de la referencia
Evaluamos el rendimiento en el procesamiento de facturas en facturas de diferentes niveles de calidad y contraste. Si bien todas las herramientas demostraron un buen rendimiento con imágenes de alta calidad, su precisión disminuyó significativamente al procesar documentos de menor calidad. Entre las herramientas probadas, Claude Sonnet 3.5 mostró la mayor precisión general y resistencia en todo el espectro de calidades de documentos.
Metodología
Medición: Nuestra metodología de evaluación se centró en la precisión de la extracción de pares clave-valor. Cada campo extraído se evaluó mediante una clasificación binaria: extracción correcta o extracción incorrecta/faltante. La métrica de precisión se calculó utilizando la siguiente fórmula:
Precisión = (Número de pares clave-valor extraídos correctamente) / (Número total de pares clave-valor)
Esta metodología permitió una comparación objetiva del rendimiento de extracción entre diferentes herramientas y tipos de documentos.
Tamaño de la muestra: Encontrar datos de facturas es un desafío, ya que incluye información personal como correos electrónicos y nombres. Utilizamos más de 400 pares clave-valor de 20 muestras de facturas disponibles públicamente.
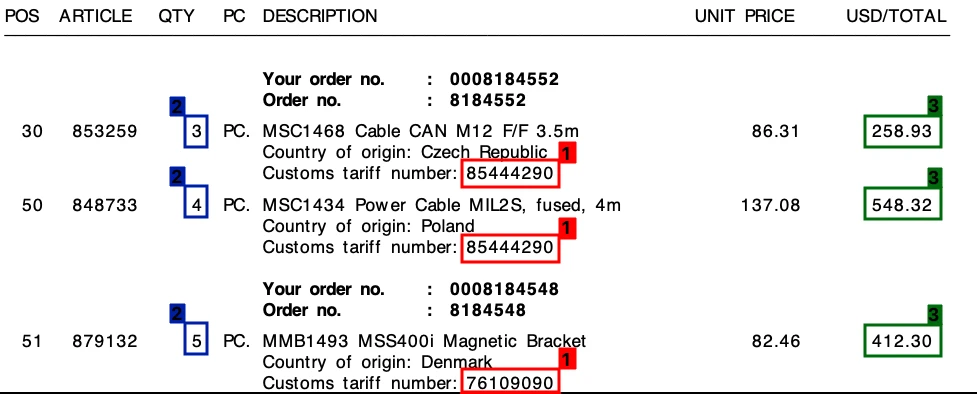
Muestras: Si bien todas las soluciones procesaron correctamente imágenes de alta calidad, la calidad de extracción disminuyó en imágenes como estas:
Fine-tuning: Aunque los productos que probamos tuvieron éxito en encontrar las cantidades totales, tuvieron problemas para extraer los detalles de precios. Es posible obtener mejores resultados mediante fine-tuning de algunos productos. En unos pocos productos, los usuarios pueden hacer clic en un valor en la imagen para corregir la salida del modelo.
Para ser justos con todos los proveedores, no realizamos ningún fine-tuning. Con fine-tuning, todos los proveedores deberían poder alcanzar tasas de éxito más altas la segunda vez que procesen estos documentos. Sin embargo, nuestro enfoque en esta referencia está en las operaciones autónomas, que requieren que los modelos produzcan resultados correctos y confiables a partir de documentos que no han visto antes.
Línea de tiempo: Todas las pruebas se completaron en diciembre de 2024.
Próximos pasos
Aumentando participantes: Dado que este estudio proporciona información sobre las capacidades actuales de procesamiento de facturas en los modelos de lenguaje grandes (LLMs), tecnologías OCR y herramientas especializadas de procesamiento de facturas, planeamos expandir nuestro análisis incorporando LLMs adicionales de última generación para proporcionar una referencia más completa de soluciones automatizadas de procesamiento de facturas.
Aumento del tamaño de la muestra y diversidad.
¿Qué es el OCR de facturas?
El análisis de facturas utiliza herramientas automatizadas como NLP, NLU, OCR y otras tecnologías de extracción de datos para extraer datos de facturas en varios formatos, como PDFs e imágenes.
Un analizador de facturas es un programa de software que extrae información como
Nombre del proveedor
Número de factura
Importe vencido
y lo ingresa en un formato legible por máquina. Estos datos pueden utilizarse para múltiples funciones, como automatizar las cuentas por pagar, completar cierres contables de fin de mes y gestionar facturas.
El software analizador generalmente se integra en un sistema de procesamiento de facturas que automatiza todo el proceso desde la recepción de una factura hasta el pago.
¿Cómo funcionan las herramientas de OCR de facturas?
Los documentos escritos en un determinado lenguaje de marcado son leídos y manejados por los analizadores. Dividen el documento en piezas más pequeñas, llamadas tokens, y examinan cada token para determinar qué significa y dónde encaja dentro de la estructura del documento.
Para hacer esto, los analizadores necesitan conocer bien la gramática del lenguaje de marcado en cuestión. Esto les permite reconocer cada token y determinar las conexiones exactas entre ellos.
El proceso incluye 5 pasos:
1. Entrada
Las facturas pueden recibirse en una variedad de formatos, incluidos papel, correo electrónico o formatos electrónicos como PDF o XML. El software analizador de facturas normalmente aceptará estas facturas como entrada.
2. Reconocimiento Óptico de Caracteres (OCR)
Si la factura está en formato de papel escaneado o imagen, el analizador utilizará la tecnología OCR para extraer texto de la imagen. Esto permite al analizador acceder a los datos contenidos en la factura.
Algunas soluciones de análisis de facturas utilizan herramientas OCR impulsadas por IA o LLMs que extraen automáticamente información de PDFs, fotos y documentos escaneados sin necesidad de nuevas reglas o plantillas. Esto se debe a que la IA puede manejar documentos semiestructurados y desconocidos y mejorar con el tiempo. La información extraída se puede personalizar para incluir solo tablas o entradas de datos específicas.
3. Extracción de datos
Luego, el analizador extraerá información específica de la factura, como el nombre del proveedor, número de factura, fecha y detalles de los artículos. Esto generalmente se logra utilizando una combinación de reconocimiento de patrones y algoritmos de aprendizaje automático.
Algunos software de análisis de facturas tienen la capacidad de extraer información clave como la fecha de la factura, el número, los números de identificación fiscal y varios totales mediante el uso de filtros predefinidos:
Algunas herramientas de análisis ofrecen la capacidad de extraer información de líneas de facturas con un formato consistente creando un analizador de documentos separado para cada diseño específico de proveedor o socio comercial:
4. Validación de datos
Una vez que se han extraído los datos, el analizador validará la información para garantizar que sea precisa y completa. Esto puede incluir verificar que la fecha esté en el formato correcto, que el nombre del proveedor coincida con una lista predefinida de proveedores o que los detalles del artículo coincidan con el formato esperado.
5. Salida de datos
Los datos extraídos y validados se emiten luego en un formato que se puede importar fácilmente al sistema contable o ERP del usuario. Esto puede ser en forma de archivo CSV, registro de base de datos o directamente en un software de contabilidad.
Desafíos con la extracción manual de datos de facturas
La extracción manual de datos de facturas y su ingreso en un sistema puede ser un desafío para las empresas, ya que existen varias complejidades:
Error humano
Las facturas pueden contener una gran cantidad de datos, y la entrada manual aumenta el riesgo de errores, como errores tipográficos, transposición de números y entrada incorrecta de datos. Las inexactitudes en la entrada de datos son responsables de unas pérdidas anuales estimadas de $600 mil millones.1 Procesos como las cuentas por pagar necesitan una exportación de datos correcta de los documentos financieros.
Consume mucho tiempo
En promedio, se necesitan 17 días, o aproximadamente el 75% de un mes, para procesar manualmente una sola factura.2
Muchas piezas importantes de información se incluyen en las facturas, y todas se presentan en un estilo de clave-valor donde cada elemento sirve tanto como clave como valor. El proceso de extraer manualmente estos pares consume mucho tiempo y requiere múltiples inspecciones para garantizar la precisión. Incluso algunos algoritmos de OCR luchan por detectar valores extraídos sin contexto. El procesamiento automatizado de facturas puede ayudar a los empleados a concentrarse en tareas más complejas.
Falta de estandarización
Las facturas de diferentes proveedores pueden tener diferentes formatos. Cada factura se genera con un formato único que puede presentar dificultades al procesar e interpretar estos patrones. Los documentos, como correos electrónicos, papel y PDFs, pueden pasar por muchos registros digitales y en papel antes de ser aprobados para el pago, lo que hace que la extracción manual de datos sea desafiante y propensa a errores.
Ineficiencia del proceso
El manejo manual de facturas, que incurre en un costo promedio de casi $23 por factura3 , puede ser tanto lento como costoso, lo que lleva a un proceso ineficiente y repetitivo.
Potencial de pérdida de datos
Existe el riesgo de perder datos si las facturas se pierden o se dañan o si los datos no se ingresan correctamente en el sistema.
El software de OCR a menudo enfrenta dificultades para extraer líneas de artículos de las facturas. Esto se debe a que las tablas de transacciones pueden carecer de líneas horizontales o verticales, lo que dificulta que el procesamiento de facturas ocr establezca contexto para los elementos extraídos. Las facturas digitales recopiladas o las imágenes de facturas se pueden utilizar en este proceso.
¿Cómo elegir su proveedor de procesamiento de facturas?
1. Proporciona una solución acorde con las políticas de privacidad de datos de su empresa.
La política de privacidad de datos de su empresa puede ser un obstáculo para el uso de APIs externas como Amazon AWS Textract. La mayoría de los proveedores ofrecen soluciones locales, por lo que las políticas de privacidad de datos no necesariamente impedirían que su empresa utilice una solución de captura de facturas. El flujo de trabajo de cuentas por pagar debe tratarse con especial cuidado, ya que a menudo involucra información comercial y financiera confidencial.
2. Proporcionar una estructura de datos consistente independientemente del texto en los documentos.
Hay dos formas en que funcionan las empresas de captura de facturas basadas en aprendizaje profundo. Empresas como Textract devuelven pares clave-valor. Así, por ejemplo, si una factura llama al importe total "Gross amount", otra lo llama "Total amount" y una factura alemana lo llama "Summe", Textract le entrega los datos en 3 estructuras diferentes para estos 3 documentos.
En uno, tiene un par clave-valor con la clave "Gross amount", en otro "Total amount" y en el alemán, obtiene "Summe". Otros proveedores diseñaron estructuras de datos consistentes que funcionan para todas las facturas. En los 3 escenarios, obtendría "Total amount", que es la clave que utilizan en su archivo de salida. Esto facilita el análisis y el procesamiento, ya que no necesita lidiar con muchos formatos de datos estructurados diferentes.
3. Pregunte por las tasas de falsos positivos y extracción manual de datos
Luego ejecute un proyecto de Prueba de Concepto (PoC) para ver las tasas reales en las facturas recibidas por su empresa.
Falsos positivos son facturas que son auto-procesadas pero tienen errores en la extracción de datos. Estos son difíciles de identificar y pueden interrumpir las operaciones. Por ejemplo, la extracción incorrecta de los importes de pago sería problemática. Minimizar esto debería ser el enfoque absoluto.
Extracción manual de datos es necesaria cuando el sistema de extracción automatizada de datos tiene una confianza limitada en su resultado. Esto podría deberse a un formato de factura diferente, una mala calidad de imagen o un error de impresión del proveedor. Esto también es importante de minimizar, pero hay un equilibrio entre los falsos positivos y la extracción manual de datos. Tener más extracción manual de datos puede ser preferible a tener falsos positivos.
Esta es la primera evaluación comparativa cuantitativa que hemos visto en este espacio y seguiremos una metodología similar para preparar nuestra propia evaluación comparativa.
4. Aprovechar una PoC para medir la tasa de automatización potencial
Esto depende de la cantidad de campos que espera capturar de los documentos. Un conjunto típico de ~10 campos, que incluye elementos como ID de orden de compra, nombre del proveedor, etc., puede permitir la entrada de datos en ERP y pagos.
Los proveedores de mejores prácticas logran ~80% STP al extraer todos estos ~10 campos casi sin errores ~80% del tiempo. Aunque puede haber errores de vez en cuando, verificar manualmente los pagos más grandes puede garantizar que ningún pago incorrecto significativo pase desapercibido.
5. Pregunte por las opciones de procesamiento avanzadas proporcionadas por el proveedor
La extracción es el primer paso en la recopilación de datos; en la mayoría de los casos, debe ir seguida del procesamiento de datos. Por ejemplo, las facturas deben verificarse para el cumplimiento del IVA (por ejemplo, las facturas nacionales sin IVA deben explicar por qué se excluye el IVA), y no hacerlo podría resultar en multas significativas para la empresa, según el país.
6. Pregunte cómo aprende la solución sobre nuevas facturas
Las mejores soluciones tienen una interfaz que permite a su equipo ayudar a guiar la solución. A medida que un empleado de su empresa selecciona los pares clave-valor, la solución de captura de facturas toma nota para poder estar más segura sobre una factura similar la próxima vez.
7. Evaluar la facilidad de uso de su solución de entrada manual de datos
Será utilizada por el personal administrativo de su empresa a medida que procesen manualmente las facturas que no se pueden procesar automáticamente con confianza.
Más allá de esto, las preguntas de adquisiciones de mejores prácticas tienen sentido. Por ejemplo:
- ¿Qué tan ampliamente adoptada está su solución? ¿Tienen clientes Fortune 500?
- ¿Están contentos sus clientes con la solución y el soporte? Podría ser bueno preguntar a un conocido de una empresa que ya esté utilizando su solución. Dado que la automatización de facturas no es una solución que mejoraría el marketing o las ventas de una empresa, incluso los competidores podrían compartir entre sí su opinión sobre las soluciones de automatización de facturas.
- ¿Cuáles son las opciones para integrar la solución en los sistemas de su empresa (por ejemplo, ERP)? ¿Está el departamento de TI de acuerdo con el enfoque de integración?
- ¿Cuál es su Costo Total de Propiedad (TCO)? Las diferentes soluciones utilizan diferentes unidades de precios (por ejemplo, precio por página o precio por documento), lo que dificulta esta comparación. Sin embargo, utilizando una muestra de sus archivos, podría tener una estimación del costo.
Lectura adicional
Cita este benchmark
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Factura OCR Referencia: Precisión de extracción de LLMs vs OCRs}},
year = {2026},
month = jan,
howpublished = {\url{https://aimultiple.com/invoice-ocr}},
note = {AIMultiple. Recuperado el 22 de Enero de 2026}
}

Sé el primero en comentar
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.