Top 3 Generadores de Documentos Sintéticos Evaluados
Los generadores de documentos sintéticos crean imágenes de documentos realistas y anotadas que ayudan a entrenar y evaluar modelos de aprendizaje automático sin depender de grandes conjuntos de datos etiquetados manualmente.
Evaluamos 3 generadores de documentos sintéticos, Genalog, DocCreator y Tonic Textual, creando más de 2.500 documentos sintéticos y comparando su efectividad en diseños realistas, datos numéricos precisos y conjuntos de datos de entrenamiento para tareas de análisis de documentos.
Resultados de la evaluación de generación de documentos
Los resultados muestran que
- Genalog y DocCreator son los mejores en utilidad y fidelidad, siendo Genalog ligeramente mejor en precisión numérica.
- Tonic Textual destaca en realismo de diseño visual pero se queda atrás en otras áreas, lo que lo hace más adecuado para tareas que requieren documentos realistas.
Para más información sobre las métricas, lea la metodología de la evaluación.
- Utilidad mide qué tan bien funcionan los modelos entrenados con datos sintéticos en documentos reales.
- Fidelidad del diseño mide qué tan bien coincide la disposición espacial de los elementos en documentos sintéticos con los reales.
- Fidelidad numérica verifica si los valores numéricos en documentos sintéticos se asemejan a los datos reales.
Comentario sobre los resultados: Para comprender mejor las diferencias de rendimiento, la evaluación también se realizó utilizando el conjunto de entrenamiento en lugar del conjunto de prueba separado. Esta evaluación secundaria tuvo como objetivo determinar si proporcionar a los modelos material de entrenamiento mejoraría su capacidad para reproducir salidas estructuradas y numéricamente precisas.
Los resultados muestran que, incluso cuando se evalúan en los datos de entrenamiento, los modelos lograron puntuaciones ligeramente más altas. Esto indica que los resultados reflejan qué tan bien manejan las herramientas la tarea en sí. Los resultados moderados probablemente están influenciados por limitaciones en la calidad de OCR y la capacidad del modelo entrenado, más que por el procedimiento de evaluación en sí.
Genalog
Genalog tuvo el mejor rendimiento general. Sus documentos sintéticos fueron muy efectivos para el entrenamiento de modelos y mantuvieron un buen equilibrio entre elementos de diseño realistas y precisión numérica. Los documentos generados reflejaron estrechamente la estructura y el espaciado de formularios y recibos reales, lo que los hace adecuados para una variedad de tareas de análisis de documentos.
DocCreator
DocCreator también produjo resultados de alta calidad. Los documentos de este generador fueron casi tan útiles para el entrenamiento como los de Genalog. Los diseños fueron realistas y los documentos sintéticos preservaron las propiedades estadísticas de los números. La fortaleza de DocCreator radica en combinar la generación de diseños diversos con sus modelos de degradación, lo que hace que los resultados sean visualmente similares a documentos escaneados del mundo real.
Tonic Textual
Tonic Textual tuvo resultados mixtos. Aunque este generador de documentos sintéticos produjo diseños muy limpios y consistentes, los documentos fueron menos efectivos para entrenar modelos. Además, los números sintéticos no siempre fueron estadísticamente similares a los datos reales. Esto sugiere que Tonic Textual es más adecuado para tareas que se centran en la apariencia del documento o el reemplazo de información de identificación personal (PII) que preserva la privacidad, en lugar de un entrenamiento a gran escala para tareas de estructura de diseño y extracción de información.
En marzo de 2026, Tonic Textual cambió su componente de vinculación de entidades de un modelo basado en LLM a un modelo basado en BERT para mejorar el rendimiento.1 La misma versión (v391) también agregó filtrado y ordenamiento mejorados en la página de Conjuntos de datos.2
Visión general
Genalog es la herramienta más equilibrada, proporcionando tanto diseños realistas como números precisos.
DocCreator es sólido para diseños complejos y diversos y degradación de documentos, con pequeñas imprecisiones numéricas.
Tonic Textual es ideal para tareas centradas en el diseño pero no para tareas que requieren datos numéricos precisos.
Resumen de la metodología
Métricas de evaluación
Cada conjunto de datos generado se puntuó en comparación con los datos originales utilizando las siguientes métricas:
Puntuación de utilidad
(Puntuación F1 de KIE): Una puntuación entre 0 y 1, donde más alto es mejor. Se define por la puntuación F1 del modelo LayoutLMv3 entrenado con datos sintéticos cuando se evalúa en el conjunto de prueba real. Una puntuación alta indica que los datos sintéticos son un sustituto altamente efectivo de los datos reales.
Puntuaciones de fidelidad
Estas métricas miden qué tan estrechamente se asemejan los documentos sintéticos a los reales.
- Fidelidad del diseño (Puntuación EMD): La distancia del transportista de tierra (dEMD) mide la diferencia entre la distribución de los puntos centrales de los cuadros delimitadores en los documentos reales frente a los sintéticos. Es un valor de 0 a 1, donde más bajo es mejor. Una puntuación baja significa que los elementos de diseño espacial están bien preservados.
- Fidelidad numérica (Distancia K-S): La distancia de Kolmogorov-Smirnov (DKS) mide la diferencia máxima entre las funciones de distribución acumulativa (CDF) de los valores numéricos (por ejemplo, precios, cantidades) en los datos reales y sintéticos. Varía de 0 a 1, donde más bajo es mejor. Una puntuación baja significa que el generador reproduce con precisión las propiedades estadísticas de los números.
Todas las métricas se normalizaron durante el cálculo.
Conjuntos de datos
FUNSD: Una colección de 199 formularios escaneados caracterizados por texto ruidoso, diseños complejos y diversos y anotaciones manuscritas. Fue descargado más de 1.500 veces el mes pasado. Esto prueba la capacidad de un generador para manejar datos no estructurados e imperfectos. 3
- Dividimos la muestra en dos: el 80% de los datos se utiliza para entrenar el modelo, mientras que el 20% restante se reserva para pruebas después del entrenamiento.
- Cada herramienta produjo entre tres y seis documentos sintéticos por cada original, resultando en un total de más de 2.500 documentos sintéticos.
Evaluación de tareas
Para medir la utilidad, un modelo popular LayoutLMv3 con 22K estrellas en GitHub y más de 750K descargas se entrenó con los datos sintéticos generados por cada herramienta de generador de documentos sintéticos. 4
El rendimiento de este modelo se evaluó luego en un conjunto de prueba retenido de documentos reales de los conjuntos de datos originales. Esto mide directamente qué tan útiles son los datos sintéticos para una tarea del mundo real.
Herramientas de generación sintética
Genalog
Una biblioteca de Python de código abierto de Microsoft para generar imágenes de documentos sintéticos con ruido sintético. Funciona tomando plantillas de texto + diseño (escritas en HTML + CSS) y renderizándolas a través de WeasyPrint, luego aplicando efectos de degradación (desenfoque, sangrado, ruido de sal y pimienta, operaciones morfológicas).5
DocCreator
Una herramienta multiplataforma de código abierto para generar imágenes de documentos sintéticos con verdad asociada. Ha sido ampliamente utilizada en investigación de Análisis y Reconocimiento de Imágenes de Documentos (DIAR).6 ,7
Tonic Textual
Una solución para la redacción y síntesis en formatos de documentos del mundo real (PDF, Word). Afirma escanear documentos no estructurados, identificar entidades nombradas (por ejemplo, PII), redactarlos o reemplazarlos con valores sintéticos y generar documentos desidentificados en formatos similares.
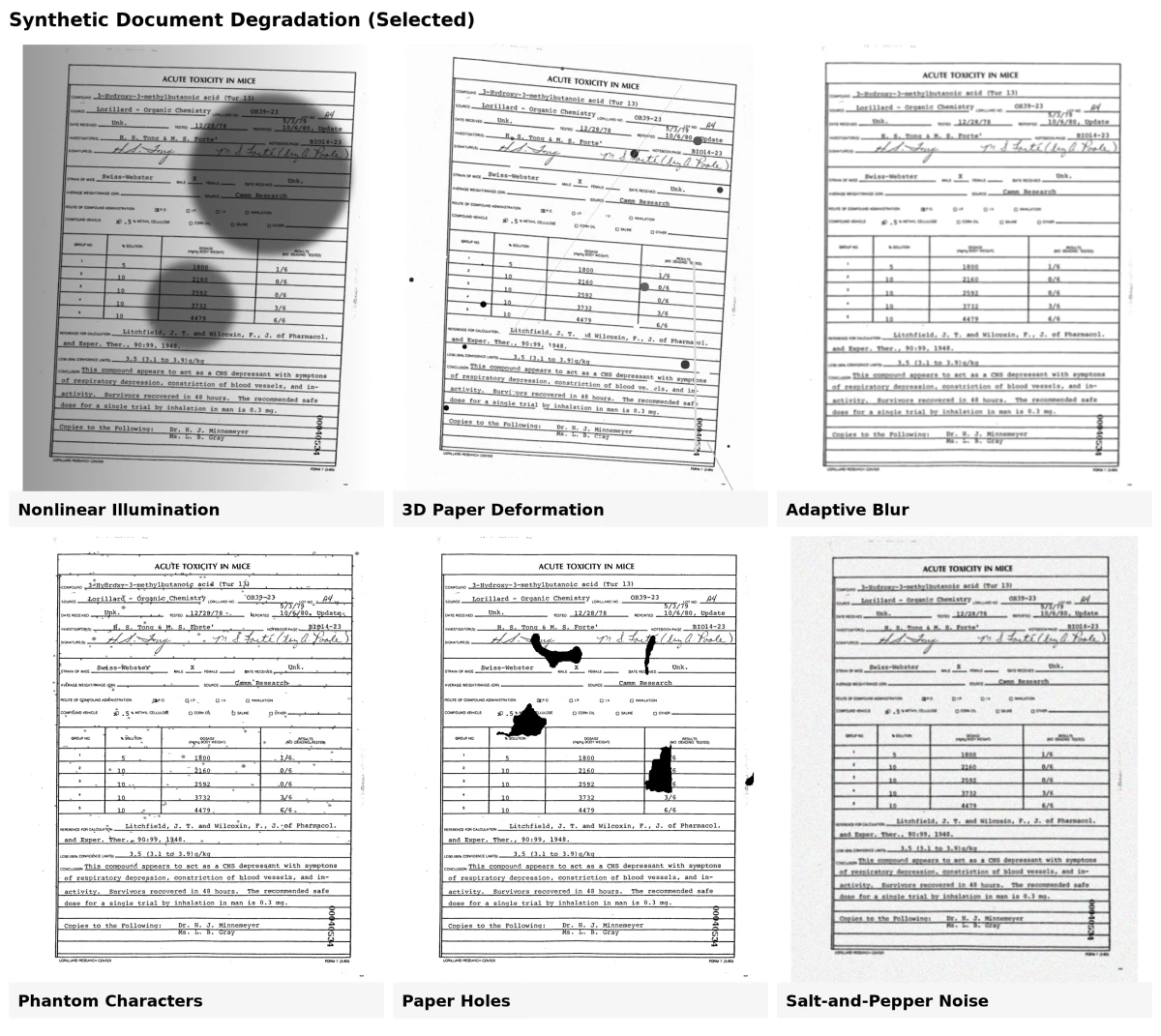
8 Métodos de degradación de documentos sintéticos
La generación de documentos sintéticos a menudo incluye agregar defectos realistas para que los datos artificiales se asemejen a documentos del mundo real. Estos defectos, o modelos de degradación, ayudan a entrenar modelos que funcionan mejor en documentos ruidosos, envejecidos o escaneados. Estas herramientas aplican varias transformaciones físicas y visuales para simular imperfecciones comunes en documentos.8
1. Degradación de tinta
Este modelo simula el desvanecimiento, las manchas o las rayas causadas por el envejecimiento o la impresión de baja calidad. Agrega pequeñas manchas de tinta o elimina partes de las letras para imitar la degradación real de la tinta.
2. Caracteres fantasma
Las antiguas herramientas de impresión a menudo dejaban contornos tenues o marcas "fantasma" alrededor de las letras. El modelo de caracteres fantasma recrea estos insertando defectos extraídos de escaneos reales entre los caracteres impresos.
3. Agujeros en el papel
Se agregan agujeros de diferentes formas y tamaños aleatoriamente a los documentos, replicando rasgaduras o marcas de perforación vistas en papeles desgastados.
4. Sangrado
Este efecto imita la tinta que se filtra a través del otro lado de la página. Utiliza tanto las imágenes frontal como posterior de un documento para recrear cómo la tinta se transfiere parcialmente a través del papel.
5. Desenfoque adaptativo
Escanear o fotografiar documentos a menudo crea un ligero desenfoque. Este modelo compara ejemplos reales desenfocados y aplica un desenfoque similar usando filtros gaussianos, manteniendo el resultado sutil y realista.
6. Deformación 3D del papel
Los documentos pueden doblarse, plegarse o curvarse al escanearse o fotografiarse. Usando mallas 3D de papeles reales, este modelo recrea estas formas y efectos de iluminación, ayudando a entrenar modelos para el análisis de documentos basado en cámaras.
7. Iluminación no lineal
La iluminación desigual durante el escaneo puede hacer que un lado de un documento parezca más oscuro. Este modelo ajusta el brillo según los ángulos de luz simulados y la curvatura de la página, reproduciendo el efecto de una iluminación deficiente.
8. Ruido de sal y pimienta
Agrega píxeles negros y blancos aleatorios para simular polvo, textura de papel o ruido del sensor de escaneo. Este efecto de "sal y pimienta" ayuda a crear la apariencia granulada de escaneos digitales envejecidos o de baja calidad.
Generación de documentos sintéticos como solución para desafíos de análisis de diseño
El desafío del análisis de diseño
Entender la estructura de los documentos es más difícil que leer el texto. Las herramientas de OCR pueden extraer palabras, pero no explican el papel de cada bloque, como títulos, tablas o figuras.
Para hacer frente a este desafío, se han desarrollado métodos:
Métodos tempranos para el análisis de diseño se basaron en reglas. Se basaron en reglas geométricas y análisis de textura para dividir páginas en bloques. Aunque útiles, estos enfoques requerían un ajuste manual intensivo y no se generalizaban bien.
Enfoques de aprendizaje automático como las Máquinas de Vectores de Soporte (SVM) y los Modelos de Mezcla Gaussiana (GMM) mejoraron esto aprendiendo de los datos.9 Sin embargo, aún dependían de características creadas a mano y luchaban con la diversidad de documentos del mundo real.
El aprendizaje profundo transformó el campo. Las redes neuronales convolucionales (CNN) hicieron posible tratar el reconocimiento de diseño como detección de objetos, identificando tablas, figuras o fórmulas de la misma manera que los modelos detectan objetos en imágenes naturales.10 Algunos modelos también combinan características de texto e imagen para obtener resultados más precisos.
El desafío del aprendizaje profundo: requiere grandes conjuntos de datos etiquetados para entrenar.
Datos sintéticos como solución: El proceso de generación de documentos sintéticos ofrece una forma escalable de crear datos de entrenamiento anotados sin el costo del etiquetado manual.
Modelos generativos ahora traen posibilidades más avanzadas. Los autoencoders variacionales (VAE), los modelos basados en atención y las GAN pueden aprender patrones estructurales de documentos y producir nuevos diseños realistas.11
Diferencias clave entre generadores de documentos sintéticos
Los tres generadores de documentos sintéticos evaluados difieren en enfoque, calidad de salida y usabilidad:
- Genalog: El más equilibrado tanto para diseños realistas como para precisión numérica. Su flujo de trabajo basado en Python con plantillas HTML/CSS y modelos de degradación lo hace ideal para entrenar modelos de aprendizaje automático en diversas tareas de análisis de documentos.
- DocCreator: Sólido en la generación de documentos visualmente complejos y degradados, preservando la diversidad de diseño. Ligeramente menos preciso numéricamente que Genalog, pero efectivo para tareas que requieren simulación de documentos escaneados realistas.
- Tonic Textual: Destaca en diseños limpios y visualmente consistentes y síntesis de datos que preserva la privacidad. Menos adecuado para precisión numérica o conjuntos de datos de entrenamiento completos, lo que lo hace mejor para tareas centradas en el diseño o reemplazo de PII.
Estas diferencias reflejan sus enfoques principales: Genalog equilibra realismo y fidelidad de datos, DocCreator enfatiza la variedad de diseño y la degradación de documentos, y Tonic Textual prioriza la apariencia y la privacidad. Esto ayuda a los usuarios a seleccionar la herramienta correcta según si la prioridad es la efectividad del entrenamiento, el realismo del diseño o la desidentificación de datos.
Otros generadores de documentos sintéticos comúnmente utilizados
YData SDK: Ofrece un Generador de documentos sintéticos capaz de producir documentos sintéticos de alta calidad en formatos PDF, DOCX o HTML, a menudo utilizado para eludir obstáculos de cumplimiento de privacidad.12
DoGe: Una herramienta de código abierto diseñada específicamente para sintetizar escaneos de documentos realistas que presentan texto significativo, encabezados y tablas para el entrenamiento de Document IA.13
DocXPand: Especializado en la generación de documentos de identidad (pasaportes, tarjetas de identificación) basados en normas ISO, rellenando plantillas con información falsa y caras generadas por IA.14
Lecturas adicionales
- Evaluación y mejores prácticas de generación de datos sintéticos
- Top 25 casos de uso de datos sintéticos
- Usuarios sintéticos explicados: Top 7 herramientas de investigación de usuarios con IA
Cita este benchmark
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{phd2026,
author = {PhD., Ezgi Arslan,},
title = {{Top 3 Generadores de Documentos Sintéticos Evaluados}},
year = {2026},
month = mar,
howpublished = {\url{https://aimultiple.com/synthetic-document-generator}},
note = {AIMultiple. Recuperado el 18 de Marzo de 2026}
}



Sé el primero en comentar
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.