MongoDB Monitoring: SolarWinds vs New Relic vs Datadog
Instalamos SolarWinds, Datadog y New Relic en sistemas limpios ejecutando MongoDB 7.0 para probar. Revisamos el proceso completo de configuración de cada herramienta, documentando cada paso y obstáculo.
MongoDB Resultados de referencia de herramientas de monitoreo de rendimiento
Plataforma | Tiempo de configuración | Perfilado de consultas | Precisión de métricas | Uso de RAM | Mejor para |
|---|---|---|---|---|---|
5 min | ✅ | 100% preciso | Medio (500MB) | Optimización de producción | |
New Relic | 15 min | ❌ | Bajo (tasas de error de 23 a 800%) | Bajo (90MB) | Comprobaciones básicas de salud |
Datadog | 20+ min | ❌ | Poco claro | Medio (330MB) | Monitoreo multi-tecnología |
Resumen de rendimiento del monitoreo de MongoDB
- SolarWinds completó la configuración en 5 minutos con detección automática y proporcionó perfilado a nivel de consulta que a los demás les faltaba.
- New Relic tardó 15 minutos con pasos de verificación manual e informó métricas inexactas.
- Datadog requirió más de 20 minutos de edición de YAML y ofreció solo visibilidad básica.
También puede ver cómo estas plataformas monitorean MySQL y nuestro entorno de prueba y metodología
1. Experiencia de instalación y acogida
1. Solarwinds
SolarWinds terminó la integración de MongoDB en menos de 5 minutos. Solarwinds se abre con un modal simple: "¿Qué quieres monitorear?" Cuando selecciona rendimiento de base de datos, la plataforma muestra las bases de datos admitidas de antemano.
Después de seleccionar MongoDB, Solarwinds verifica los agentes existentes.
La plataforma detectó inmediatamente nuestro agente instalado previamente.
Una característica destacó: la interfaz muestra los detalles del agente (sistema operativo, ID de instancia en la nube, versión) directamente en la pantalla de selección. Sin buscar en menús desplegables.
Ahora SolarWinds solicita las credenciales de MongoDB. Ingresamos los detalles de conexión: localhost, método de autenticación (basado en contraseña), nombre de usuario y contraseña. El nombre de visualización se rellenó automáticamente con nuestra información del servidor, aunque utilizó el nombre de host interno completo en lugar del nombre del agente que habíamos especificado anteriormente.
Una rareza: el menú desplegable "Captura de consulta" apareció sin explicación. Seleccionamos "Registro" y continuamos, sin saber qué hacían las otras opciones.
La siguiente pantalla presentó tres comandos de base de datos para ejecutar. Cada comando tenía un botón de copiar. Los ejecutamos en MongoDB y hicimos clic en "Observar base de datos".
Aquí es donde Solarwinds nos impresionó. En lugar de pedirnos que averiguáramos los permisos, proporcionó comandos de copiar y pegar:
- Crear un usuario de monitoreo con credenciales específicas
- Conceder los privilegios necesarios (roles clusterMonitor y readAnyDatabase)
- Establecer el nivel de perfilado
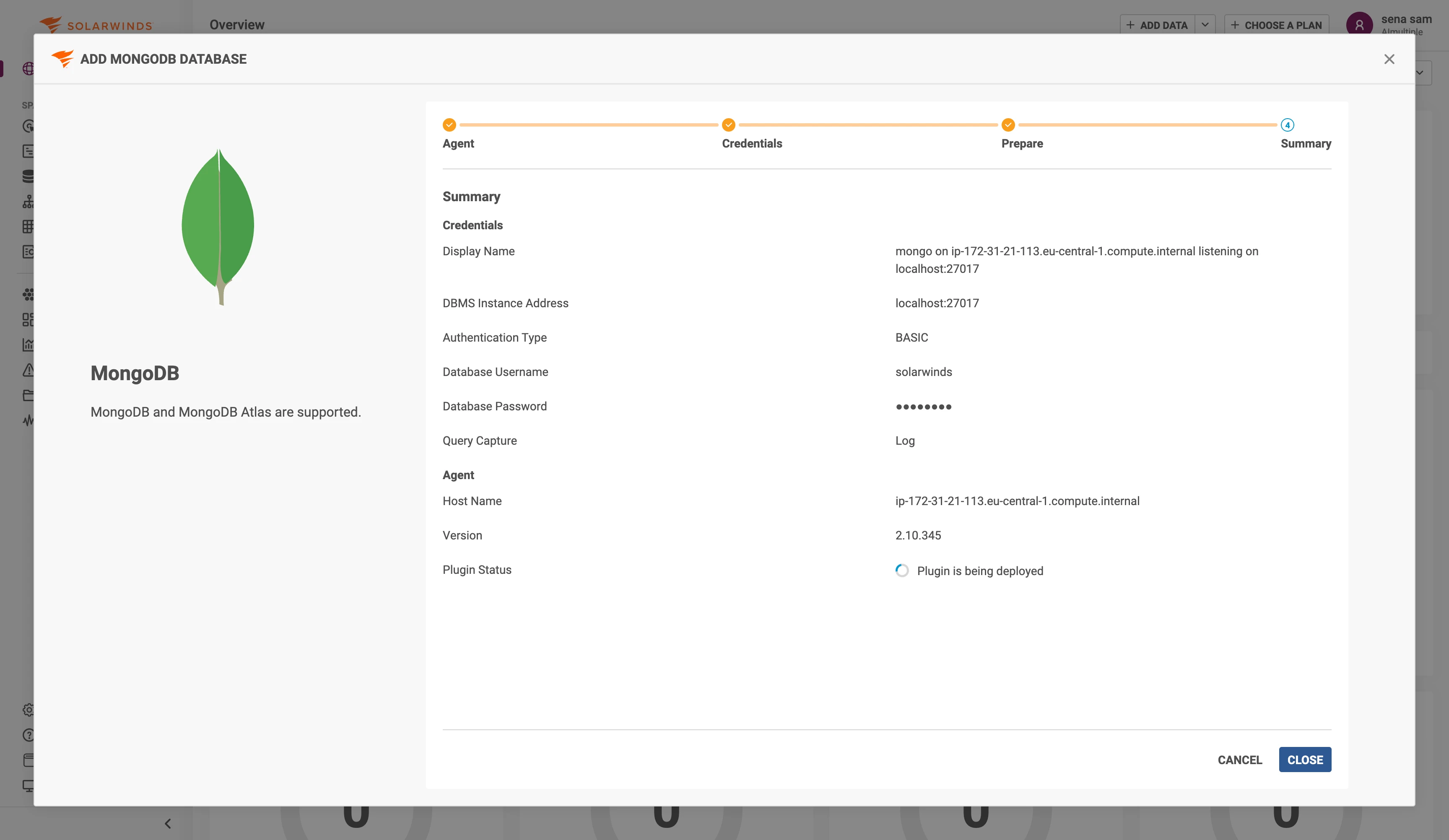
Apareció una pantalla de resumen mostrando nuestra configuración. El estado del plugin mostraba "El plugin se está implementando".
Segundos después, el estado cambió a "La implementación del plugin fue exitosa" con un enlace para ver el panel de control. Configuración completada.
Descubra SolarWinds Observability con monitoreo profundo de MongoDB y perfilado de consultas. Explore SolarWinds.
Visita el sitio web2. New Relic
New Relic tardó aproximadamente 15 minutos en configurarse, pero el tiempo no fue el verdadero problema. La fricción vino de responder preguntas que la plataforma ya debería haber conocido.
New Relic comienza en la página Integraciones y Agentes.
Buscamos "mongo" y encontramos múltiples integraciones relacionadas con MongoDB.
Después de seleccionar MongoDB, New Relic nos pidió elegir un método de instrumentación.
Seleccionamos "En un host" ya que nuestro agente ya estaba instalado. La siguiente pantalla preguntó por el sistema operativo. Seleccionamos Linux. Esto pareció innecesario ya que el agente ya se estaba ejecutando en el servidor, pero continuamos.
La siguiente pantalla pidió los detalles del host de MongoDB. El término "SCRAM" apareció sin explicación. La mayoría de la gente conoce esto como autenticación de nombre de usuario/contraseña, pero el término técnico añade confusión.
Después de hacer clic en continuar, New Relic nos preguntó en qué servidor instalar. Esta pregunta debería haber venido primero, no después de que ya hubiéramos ingresado los detalles de configuración. El agente ya estaba instalado en "aimultiple-benchmark", así que lo seleccionamos y continuamos.
La siguiente pantalla nos pidió verificar la compatibilidad de la versión de MongoDB. New Relic quería que ejecutáramos mongod --version y confirmáramos que la salida coincidía con sus requisitos. Tuvimos que copiar el comando, cambiar a nuestra terminal, ejecutarlo, verificar el número de versión y volver a hacer clic en continuar.
El agente ya está instalado en el servidor. Podría verificar esto automáticamente.
Después de hacer clic en continuar, llegamos al paso de creación de usuario. New Relic proporcionó un script de MongoDB para crear el usuario de monitoreo. Los comandos fueron claros, con asignaciones de roles adecuadas (clusterMonitor y readAnyDatabase). También tuvimos que ejecutar un comando de prueba de conexión para verificar que el usuario funcionara correctamente.
Este enfoque fue mejor que pedir acceso root, pero asumió que averiguaríamos dónde ejecutar estos comandos.
La siguiente pantalla nos pidió instalar el paquete de integración. Ahora New Relic quiere que instalemos manualmente usando yum. Aunque el agente ya está instalado en Ubuntu, la interfaz predetermina a Amazon Linux y proporciona comandos de instalación yum en lugar de apt. Esperábamos que la plataforma detectara el SO correcto desde el agente instalado automáticamente.
Ejecutamos el comando apt correcto para Ubuntu, luego pasamos a la siguiente pantalla. New Relic proporcionó un archivo de configuración YAML y nos dijo exactamente dónde ponerlo: /etc/newrelic-infra/integrations.d/. Al menos la ruta del archivo estaba clara.
Creó el archivo, pegamos la configuración y hicimos clic en Continuar. La pantalla final mostró un botón "Probar conexión". Lo hicimos clic y esperamos.
La prueba pasó. Configuración completada.
3. Datadog
Datadog tardó más de 20 minutos en completarse. La integración funcionó eventualmente, pero llegar allí requirió un esfuerzo manual significativo.
Después de iniciar sesión, fuimos a Integraciones y buscamos "mongo". Hicimos clic en MongoDB y apareció un modal.
La vista general mostraba qué incluye el monitoreo de MongoDB, pero hacer clic en "Instalar integración" solo abrió otra pantalla con instrucciones densas.
Aquí es donde Datadog nos abrumó. La pantalla mostraba una guía de referencia completa que cubría cada posible escenario de MongoDB: instancias independientes, conjuntos de réplicas, clústeres fragmentados, métodos de autenticación, configuración SSL y más.
Para alguien que solo intenta monitorear una sola instancia de MongoDB, el muro de texto pareció excesivo.
Desfilamos buscando los pasos básicos:
- Crear un usuario de monitoreo en MongoDB
- Editar el archivo de configuración YAML
- Reiniciar el agente de Datadog
Datadog proporcionó los comandos de MongoDB para crear el usuario, lo cual fue útil. Pero cuando se trató del archivo YAML, la documentación dijo editar conf.yaml sin indicar claramente dónde debería ir este archivo.
Sabíamos por experiencia que pertenece en /etc/datadog-agent/conf.d/mongo.d/, pero las instrucciones enterraron este detalle profundamente en la documentación.
Creó el usuario de MongoDB, escribimos la configuración YAML, la colocamos en el directorio correcto y reiniciamos el agente.
Luego volvimos a la interfaz de Datadog y hicimos clic en "Instalar integración".
El botón desapareció. Sin mensaje de confirmación, sin notificación de éxito, sin redirección a un panel de control. Nada.
Esperamos un momento, luego navegamos manualmente a la sección de Paneles de control y encontramos métricas de MongoDB comenzando a poblarse.
2. Consumo de recursos del agente
Monitoreamos cuánto recursos consumió cada agente mientras se ejecutaba. La prueba duró aproximadamente 10 minutos con los tres agentes recopilando datos simultáneamente de la misma instancia de MongoDB bajo carga.
Estresamos el sistema insertando 2 millones de registros en MongoDB usando un script que generó datos aleatorios. Esto simuló la actividad real de la base de datos mientras medíamos el uso de recursos del agente.
Consumo de CPU
Los tres agentes usaron recursos mínimos de CPU durante la prueba.
- New Relic mostró el consumo promedio de CPU más bajo, pero tuvo picos ocasionales que alcanzaron el 4%. Estos picos fueron breves y no afectaron el rendimiento del sistema.
- Solarwinds mantuvo el uso de CPU más consistente, manteniéndose alrededor del 3% sin variación significativa.
- Datadog quedó en el medio, promediando poco más del 2% con un rendimiento estable durante toda la prueba.
Uso de memoria
El uso de memoria mostró diferencias más significativas entre los agentes.
New Relic consumió aproximadamente 5-6 veces menos memoria que Solarwinds. En nuestro servidor de prueba de 16 GB, esto se tradujo en:
- New Relic: ~90MB
- Datadog: ~330MB
- Solarwinds: ~500MB
Para la mayoría de los servidores de producción, estas cantidades no importarán. Pero si está ejecutando agentes en sistemas con recursos limitados o monitoreando cientos de bases de datos, la diferencia se suma.
El uso de memoria se mantuvo estable en los tres agentes durante toda la prueba. No se produjeron fugas de memoria ni crecimiento inesperado.
E/S de disco
La actividad del disco varió considerablemente entre los agentes.
SolarWinds realizó significativamente más lecturas de disco que los otros dos agentes, unas 40 veces más que New Relic y 1.5 veces más que Datadog. Esto sugiere que SolarWinds accede a datos almacenados localmente con más frecuencia, posiblemente para sus funciones de perfilado de consultas.
Datadog escribió menos en el disco, lo que indica que almacena en búfer menos datos localmente antes de enviarlos a la nube.
New Relic mostró el patrón de E/S más equilibrado con lecturas y escrituras moderadas.
Uso de red
El tráfico de red mostró cuántos datos envió cada agente a su backend.
Los tres agentes enviaron cantidades similares de datos a través de la red. Datadog transmitió ligeramente menos, posiblemente debido a una compresión más agresiva o tasas de muestreo diferentes.
El tráfico bidireccional tiene sentido, ya que los agentes envían métricas y reciben actualizaciones de configuración o comandos de la plataforma.
Resumen del impacto de recursos
Ninguno de estos agentes tensionará su sistema. Incluso bajo carga de base de datos con los tres ejecutándose simultáneamente, el consumo total de recursos se mantuvo muy por debajo del 10% para CPU y memoria combinados.
New Relic gana en eficiencia de memoria. Solarwinds usa más recursos pero ofrece un análisis más detallado a nivel de consulta. Datadog se queda en el medio.
Para la mayoría de los casos de uso, estas diferencias de recursos no influirán en su decisión. Elija según las características y la usabilidad, no por el consumo de recursos.
3. Capacidades de panel de control y monitoreo
Después de completar la configuración, necesitábamos ver qué muestra realmente cada plataforma. Ejecutamos la misma carga de trabajo en los tres: insertando 2 millones de registros en lotes de 5,000, seguidos de otros 5 millones de registros.
El script usó Node.js con Faker para generar nombres de datos de usuario aleatorios, correos electrónicos, direcciones y números de teléfono. Esto nos dio un conjunto de datos realista para monitorear.
Mientras se ejecutaban las inserciones, monitoreamos el consumo de recursos del agente en segundo plano.
La carga de trabajo puso estrés real en MongoDB, lo que nos permitió ver cómo cada plataforma capturó y mostró la actividad.
Panel de control de Solarwinds
Hicimos clic en "Bases de datos" en el menú izquierdo e inmediatamente vimos nuestra instancia de MongoDB. Un clic y apareció un panel de control completo.
La parte superior de la pantalla mostraba la salud de MongoDB, el tiempo de respuesta promedio, el rendimiento (consultas por segundo) y el recuento de errores. El gráfico de burbujas "Top 10 Service Breakdown" mostraba los patrones de consulta más utilizados con sus recuentos y porcentajes.
Los números contaron una historia. El rendimiento mostró 3 consultas por segundo en promedio. El desglose mostró 1,400 operaciones de inserción. ¿Por qué 1,400 en lugar de 7 millones?
Insertamos 7 millones de registros en lotes de 5,000. Eso son 1,400 operaciones por lotes. Solarwinds rastreó cada lote individual sin perder ninguno.
La pestaña Profiler mostró patrones de consulta con tiempos de ejecución promedio.
Nuestras consultas de inserción tardaron de 4 a 5 segundos cada una, lo que parece alto hasta que recuerde que cada consulta escribió 5,000 filas.
La pestaña Salud mostró todo funcionando sin problemas.
Detuvimos el servicio de MongoDB para ver qué tan rápido notaría Solarwinds. Dentro de 30-40 segundos, el estado de salud cambió a "Malo".
La pestaña Consultas proporcionó filtrado avanzado. Podía listar consultas que:
- Devolvieron errores
- Se ejecutaron sin índices adecuados
- Respondieron lentamente
- Generaron advertencias
Cada patrón de consulta mostraba cuándo apareció por primera vez, cuándo se ejecutó por última vez, cuántas muestras se capturaron y estadísticas de ejecución. Para la resolución de problemas, este nivel de detalle importa.
La pestaña Alertas nos permitió crear alertas específicas de MongoDB. Habíamos creado una alerta de memoria para el host anteriormente, pero ahora podíamos configurar notificaciones específicas de la base de datos.
La pestaña Recursos mostró métricas a nivel de host junto con estadísticas de MongoDB, CPU, memoria, disco y red. Este contexto ayuda a distinguir entre problemas de base de datos y problemas de infraestructura subyacentes.
La pestaña Asesores no tenía recomendaciones aún, pero proporcionó para MySQL en nuestra prueba anterior. Esperamos que ofrezca sugerencias de optimización a medida que recopile más datos de MongoDB.
Actualizaciones de IA: En octubre de 2025, SolarWinds lanzó el Agente de IA con la función IA Query Assist (actualmente en vista previa técnica). IA Query Assist analiza patrones de consulta de base de datos y propone reescrituras optimizadas para mejorar el rendimiento automáticamente. Root Cause Assist (ahora disponible generalmente) genera análisis claros de la causa raíz basados en alertas y anomalías para reducir el tiempo de resolución de problemas. Se planea una disponibilidad más amplia del Agente de IA en toda la cartera de SolarWinds para 20261 2 .
Panel de control de New Relic
Fuimos a la sección Paneles de control, pero no apareció ningún panel de control de MongoDB automáticamente.
Buscamos "mongo" en el catálogo de paneles de control y encontramos dos opciones de MongoDB.
Seleccionamos el panel de control regular de MongoDB y hicimos clic en "Configurar MongoDB".
Esto nos redirigió nuevamente a la configuración de la integración de MongoDB. La plataforma ya sabía que habíamos instalado MongoDB, ¿entonces por qué enviarnos de vuelta a la instalación? Hicimos clic en "Hecho" y procedimos al panel de control.
El panel de control se abrió completamente vacío. "No hay valor reportado para la verificación de servicio mongodb.can_connect."
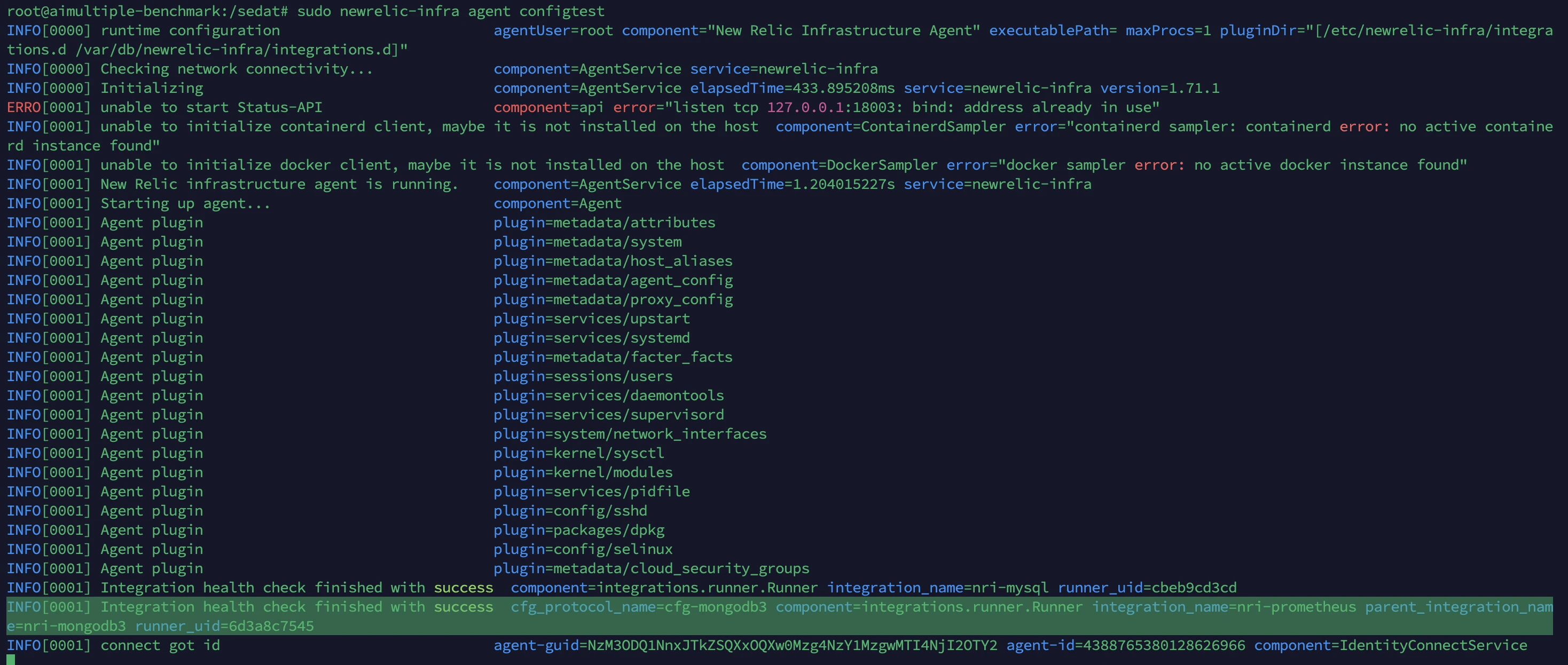
Verificamos nuestra configuración usando newrelic-infra agent configtest.
Cuando ejecutamos el comando newrelic-infra agent configtest para verificar problemas con nuestra configuración, notamos que integration_name estaba configurado como nri-prometheus. Durante la configuración del panel de control, New Relic mostró dos opciones de MongoDB, una de las cuales era la versión de Prometheus. Nada en la interfaz indicaba que esta era una integración diferente, por lo que nunca se me habría ocurrido que había seleccionado la de Prometheus. Esto no fue un error del usuario; simplemente no había orientación o distinción en la interfaz.
Volvimos e instalamos el panel de control " MongoDB (Prometheus)".
Esta vez, aparecieron datos.
Pero aquí está el problema: ¿cómo lo averiguaría un usuario normal? El proceso de instalación fue confuso, y ahora la selección del panel de control agregó otra capa de complejidad.
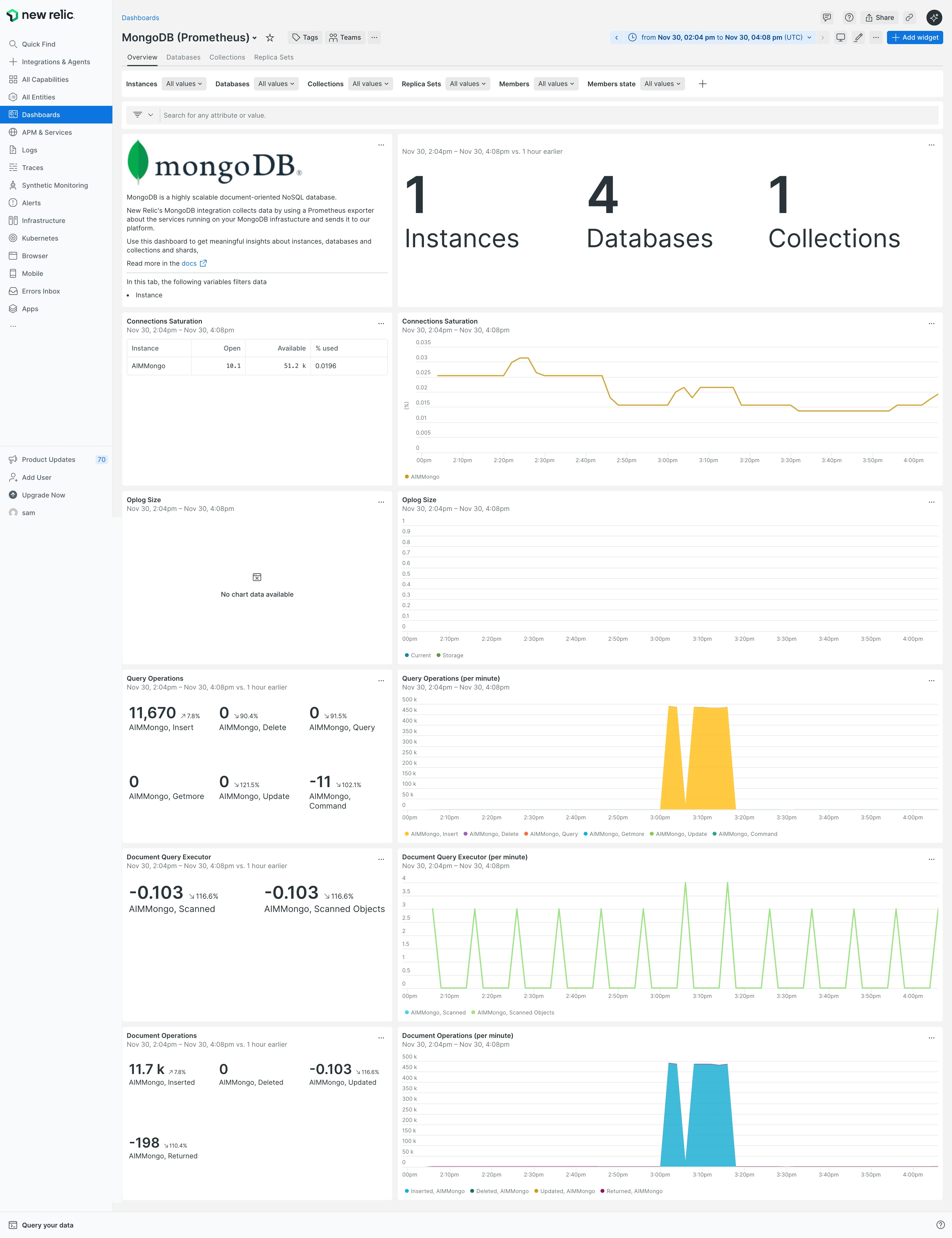
La disposición del panel de control se sintió extraña. La parte superior mostraba información total de servidores y bases de datos que cambia una vez al año, pero ocupó el mejor espacio en pantalla.
Debajo de eso, "Saturación de conexión" apareció prominentemente. Esta métrica solo importa cuando algo está mal. ¿Por qué ponerlo en la parte superior?
La sección "Operaciones de consulta" informó 11,670 inserciones. El número estaba mal. Insertamos 7 millones de registros en 1,400 operaciones por lotes. El gráfico no coincidía con la realidad.
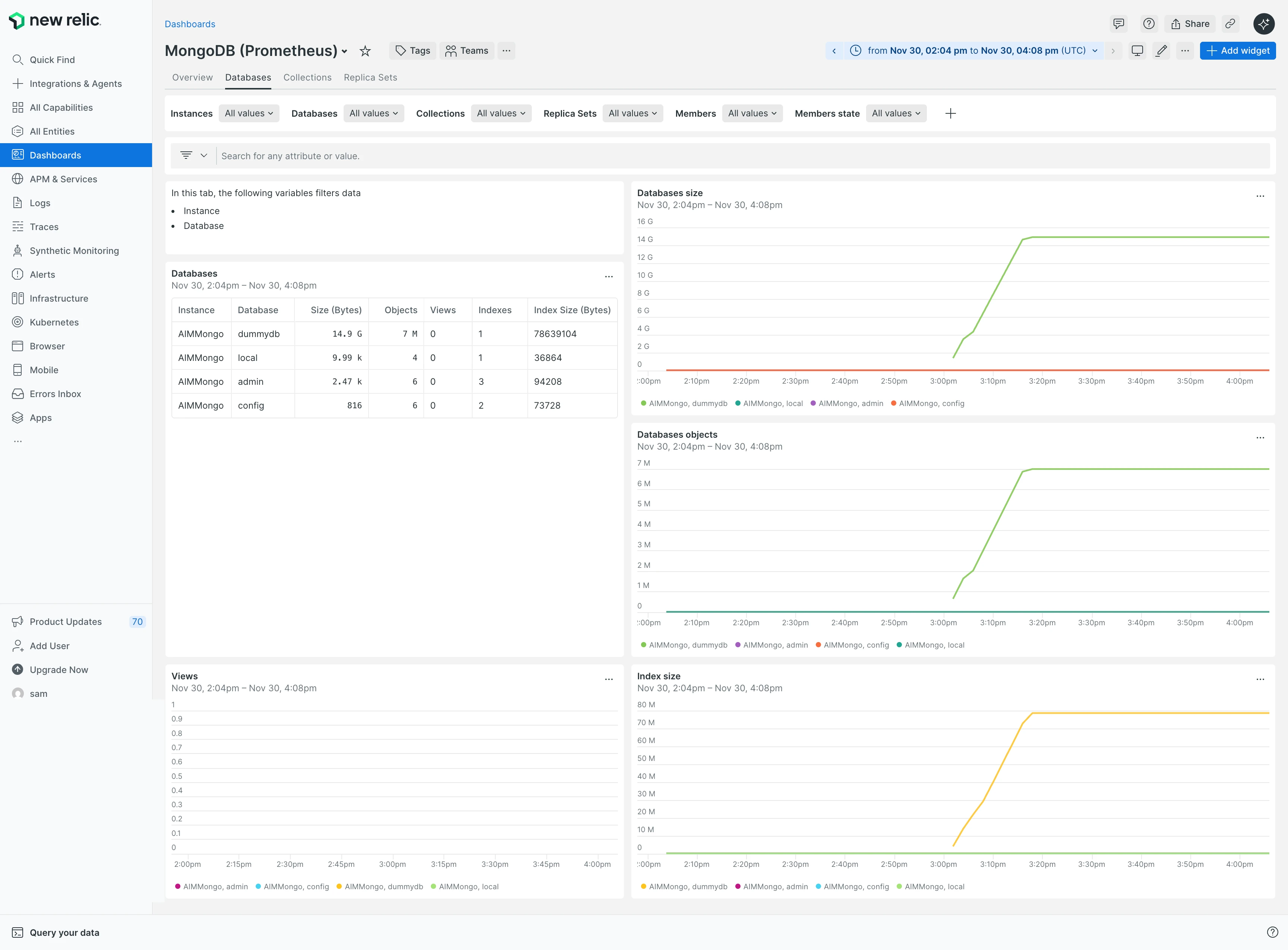
La pestaña Bases de datos mostró el tamaño de la base de datos, recuentos de objetos y tamaños de índice. Estos números fueron correctos7 millones de objetos. New Relic obtiene estos datos consultando MongoDB directamente ("¿Cuántos documentos tienes?"). Pero el conteo de consultas en tiempo real falló.
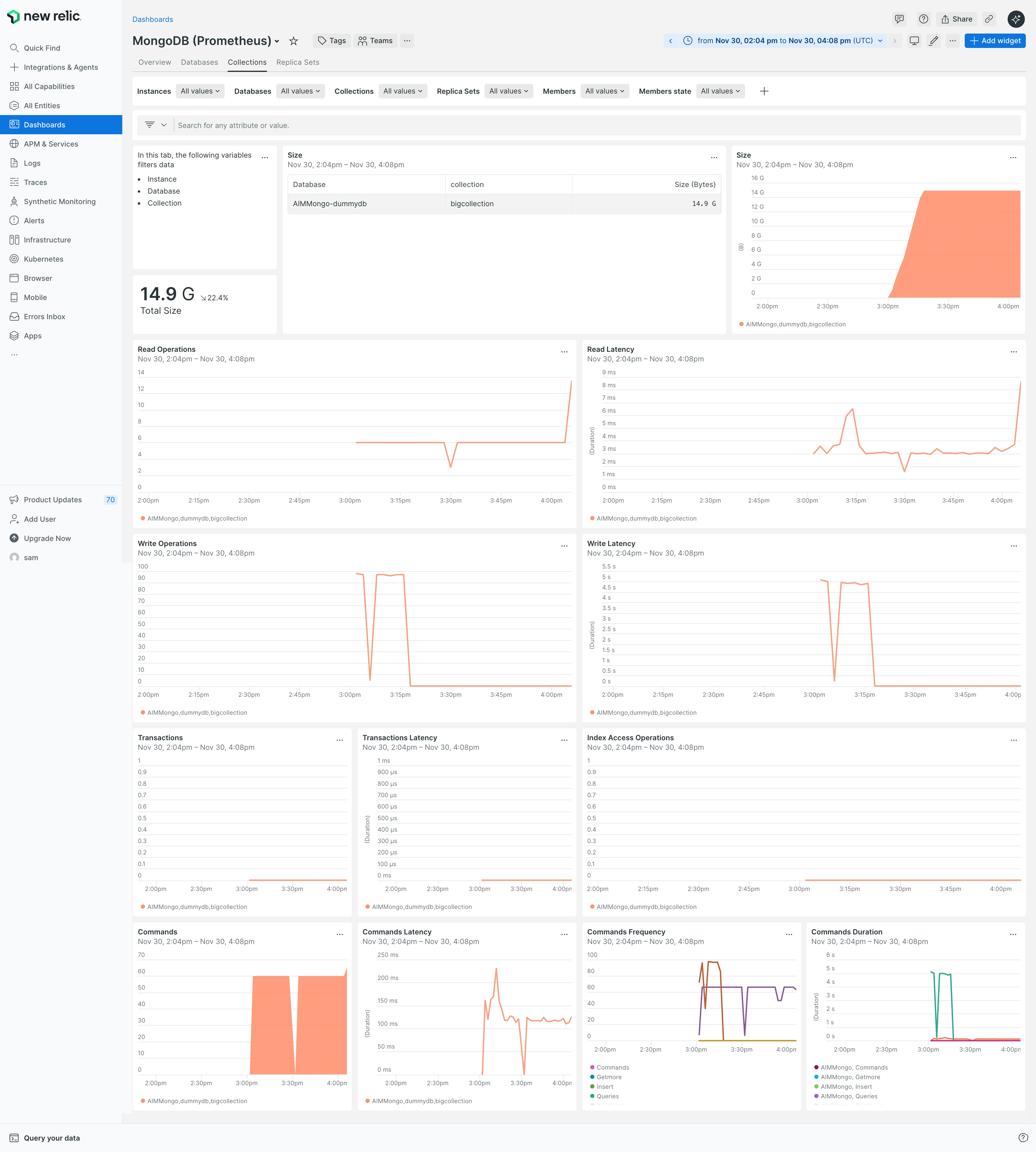
La pestaña Colecciones incluyó gráficos útiles para métricas a nivel de colección: tamaño (con vistas de tabla y gráfico), tamaño total con cambio porcentual, recuento de operaciones de lectura, latencia de lectura, recuento de operaciones de escritura, latencia de escritura, recuentos de transacciones, latencia de transacción, operaciones de acceso a índice, recuentos de ejecución de comandos, latencia de comandos, frecuencia de comandos y duración de comandos.
Notablemente ausente: métricas de host. No pudimos ver CPU, memoria, disco o uso de red para el servidor que ejecuta MongoDB. SolarWinds incluyó este contexto, pero Datadog, al igual que New Relic, no.
Más importante aún, no existía ningún análisis a nivel de consulta en ningún lugar. Sin patrones de consulta, sin perfilado, sin identificación de consultas lentas, sin detección de índices faltantes. Para la resolución de problemas de bases de datos, estas características importan.
Panel de control de Datadog
Hicimos clic en "Paneles de control" en el menú izquierdo. Apareció automáticamente un panel de control " MongoDB – Vista general".
Lo abrimos, pero estaba vacío.
El problema tomó tiempo en diagnosticarse. Durante la instalación, la configuración de autodescubrimiento de Datadog requería especificar qué bases de datos monitorear usando una coincidencia de patrón. El patrón predeterminado no coincidía con el nombre de nuestra base de datos. Datadog nunca mencionó esto durante la configuración.
Cambiamos todos los patrones a .* (coincidir con todo) y reiniciamos el agente.
Pero ¿por qué estaba el panel de control completamente vacío? Incluso sin métricas específicas de la base de datos, el tiempo de actividad, los recuentos de conexiones y las estadísticas del servidor deberían haber aparecido. No lo hicieron.
Ejecutamos datadog-agent check mongo para depurar. El archivo de configuración tenía un error de sangría. El formato estricto de YAML nos atrapó. Después de arreglarlo y volver a ejecutar nuestra prueba de carga con 5 millones de inserciones, los datos finalmente aparecieron.
Inmediatamente nos encontramos con problemas con el panel de control. La sección Registros mostró "No accesible" aunque habíamos configurado la recopilación de registros en nuestro archivo YAML. El proceso de configuración de Datadog informó que todo estaba bien, pero los registros aún no funcionaban.
La disposición del panel de control no tenía mucho sentido para nuestro caso de uso. La sección superior se centró en estadísticas de fragmentación. No estábamos ejecutando un clúster fragmentado. El medio mostró métricas de conjunto de réplicas. No teníamos conjuntos de réplicas. La parte inferior volvió a la fragmentación nuevamente. Aproximadamente el 60% del panel de control mostraba secciones vacías para funciones que no estábamos usando.
La información útil ocupaba quizás el 40% de la pantalla: tiempo de actividad, uso de memoria, E/S de red, consultas por segundo y latencia de lectura/escritura. Sin análisis de consultas, sin perfilado, sin detección de consultas lentas, sin recomendaciones de índices.
Incluso no pudimos determinar cuántas operaciones se ejecutaron desde este panel de control.
Entorno de prueba y metodología
Ejecutamos las tres herramientas en configuraciones idénticas para garantizar una comparación justa. Cada prueba usó:
- Base de datos: MongoDB 7.0 Community Edition
- Servidor: Instancia AWS m6i.xlarge
- Punto de partida: Instalación nueva con el agente de monitoreo principal ya instalado
Los tres proveedores requieren que instale su agente base antes de agregar integraciones específicas, como MongoDB. Completamos ese paso con anticipación, por lo que nuestra prueba se centró puramente en la experiencia de integración de MongoDB.
Lo que medimos:
- Complejidad de configuración: Número de pasos manuales, configuración automática versus manual, claridad de las instrucciones y si la interfaz nos guió o nos dejó buscando los siguientes pasos.
- Consumo de recursos del agente: CPU, memoria, E/S de disco y uso de red durante inactividad y bajo carga (insertando 7 millones de registros).
- Capacidades de monitoreo: Calidad del panel de control, precisión de métricas, análisis a nivel de consulta y funciones de resolución de problemas.
Consideraciones de seguridad
Se reveló una vulnerabilidad grave llamada "MongoBleed", que afecta a las versiones del servidor MongoDB anteriores a 8.0.17, 7.0.28, 6.0.27 y anteriores. Esta vulnerabilidad de lectura fuera de límites no autenticada podría permitir que los atacantes accedan a datos de memoria sensibles. Las organizaciones que ejecutan MongoDB deben actualizar inmediatamente a versiones parcheadas: 8.2.3, 8.0.17, 7.0.28, 6.0.27, 5.0.32 o 4.4.303 4 . Al seleccionar herramientas de monitoreo, asegúrese de que admitan métodos de autenticación seguros y no introduzcan riesgos de seguridad adicionales.
Nos acercamos a cada herramienta como lo haría un usuario regular, sin leer la documentación con anticipación y sin capacitación previa. Si algo no era evidente en la interfaz, lo notamos.
Veredicto final
Nos propusimos responder una pregunta simple: ¿qué plataforma de monitoreo hace que la integración de MongoDB sea más fácil para equipos no técnicos?
Después de instalar los tres, ejecutar cargas de trabajo idénticas y evaluar paneles de control, la respuesta quedó clara. Nuestra evaluación se basa en la integración básica de MongoDB de Datadog a partir de enero de 2025. Datadog ha lanzado desde entonces Monitoreo de bases de datos (DBM) para MongoDB (diciembre de 2024), que proporciona capacidades significativamente más profundas, incluido perfilado de consultas, análisis de operaciones lentas, planes de explicación y monitoreo de réplicas. El producto DBM aborda muchas de las limitaciones identificadas en esta referencia5 .
Solarwinds: Construido para el monitoreo de bases de datos
SolarWinds ganó esta comparación de manera decisiva. La plataforma detectó inmediatamente nuestro agente, nos guió a través de la configuración de credenciales mediante comandos de copiar y pegar, e implementó automáticamente la integración. La configuración tardó 5 minutos.
El panel de control apareció instantáneamente con información relevante. El perfilado de consultas mostró exactamente qué operaciones consumieron más recursos. La plataforma capturó las 1,400 operaciones por lotes sin perder ninguna. Cuando detuvimos MongoDB, SolarWinds detectó el fallo dentro de los 40 segundos.
La pestaña Consultas nos permite filtrar por errores, índices faltantes, respuestas lentas y funciones de advertencia que apoyan directamente la optimización de bases de datos. Se esperaba que la función Asesores proporcionara recomendaciones (aunque no generamos suficientes datos para activar ninguna durante nuestra prueba).
Solarwinds se centró en lo que realmente necesitan los administradores de bases de datos: análisis de consultas, perfilado de rendimiento y conocimientos accionables.
New Relic: Perdido en la configuración
New Relic tardó 15 minutos en configurarse, pero el tiempo no fue el principal problema. La plataforma hizo preguntas en el orden incorrecto, requirió verificación manual de cosas que el agente podría verificar automáticamente y nos obligó a instalar paquetes manualmente.
La confusión del panel de control empeoró las cosas. Instalamos el monitoreo de MongoDB, pero seleccionar el panel de control predeterminado resultó en una pantalla vacía. Solo después de profundizar en los archivos de configuración nos dimos cuenta de que habíamos seleccionado el tipo de integración incorrecto. Un usuario normal no lo averiguaría.
Cuando finalmente aparecieron los datos, las métricas estaban mal. New Relic informó 11,670 inserciones después de realizar 1,400 operaciones por lotes, totalizando 7 millones de registros. La plataforma subestimó en un orden de magnitud.
Más críticamente, New Relic no proporcionó ningún análisis a nivel de consulta. Sin perfilado, sin detección de consultas lentas, sin identificación de índices faltantes. Para la resolución de problemas de bases de datos, estas omisiones importan.
Datadog: Se requiere trabajo manual
Datadog requirió más de 20 minutos de configuración y la mayor configuración manual. Editamos los archivos YAML, determinamos dónde colocarlos y reiniciamos los servicios desde la línea de comandos.
El panel de control apareció automáticamente pero no mostró nada. La configuración de autodescubrimiento usó un patrón que no coincidía con nuestra base de datos. Después de corregir el patrón y corregir errores de sangría YAML, los datos finalmente se poblaron.
El propio panel de control resultó estar mal diseñado para MongoDB de instancia única. El sesenta por ciento de la pantalla estaba vacío, con secciones para fragmentación y conjuntos de réplicas, funciones que no estábamos usando. El 40% restante ofreció métricas básicas: tiempo de actividad, memoria, E/S de red, consultas por segundo y latencia.
Sin análisis de consultas. Sin perfilado. Sin recomendaciones de optimización. No pudimos determinar con precisión los recuentos de operaciones en el panel de control.
Sin análisis de consultas. Sin perfilado. Sin recomendaciones de optimización. No pudimos determinar con precisión los recuentos de operaciones en el panel de control.
Actualización crítica (diciembre de 2024): Después de completar esta referencia, Datadog lanzó Monitoreo de bases de datos (DBM) para MongoDB, lo que cambia significativamente esta evaluación. DBM para MongoDB ahora proporciona:
- Análisis de operaciones lentas con muestras de consultas detalladas
- Planes de explicación para optimización de consultas
- Monitoreo del estado de réplicas y visualización de salud del clúster
- Información a nivel de operación e identificación de cuellos de botella de rendimiento
- Integración con monitoreo de rendimiento de aplicaciones para resolución de problemas unificada
DBM representa una actualización sustancial de la integración básica de MongoDB probada en esta referencia e incluye muchas de las funciones de análisis a nivel de consulta que estaban ausentes durante nuestras pruebas6 7 . Las organizaciones que evalúan Datadog para el monitoreo de MongoDB deben evaluar específicamente el producto Monitoreo de bases de datos en lugar de la integración básica probada aquí.
¿Qué herramienta de monitoreo de BD realmente funciona cuando no eres un experto en DevOps?
La experiencia de configuración
SolarWinds se abrió con un modal preguntando qué quieres monitorear. Eliges "rendimiento de base de datos", seleccionas MongoDB y la plataforma encuentra inmediatamente el agente que ya instalaste, mostrándote el sistema operativo, el ID de instancia en la nube y el número de versión allí mismo en la pantalla de selección. Luego te da tres comandos de copiar y pegar para ejecutar en MongoDB, maneja las credenciales y confirma la implementación. Cinco minutos, de principio a fin.
New Relic tardó quince minutos, y el tiempo ni siquiera fue el verdadero problema. La interfaz seguía haciendo preguntas que el agente podría haber respondido por sí mismo, como qué sistema operativo y qué versión de MongoDB, a pesar de que el agente ya estaba en el servidor. En un momento, predeterminó comandos de instalación de Amazon Linux, aunque claramente estábamos ejecutando Ubuntu. El paso que finalmente rompió la experiencia: hay dos opciones de integración de MongoDB en el catálogo de paneles de control, una estándar y otra basada en Prometheus, y nada en la interfaz las distingue. Seleccionamos la incorrecta, obtuvimos un panel de control vacío y solo lo averiguamos profundizando en los archivos de configuración.
Datadog requirió más de veinte minutos de edición de YAML, adivinar rutas de archivos y reiniciar servicios desde la línea de comandos. La documentación ofrecida durante la configuración no es una guía; es un manual de referencia completo que cubre instancias independientes, conjuntos de réplicas, clústeres fragmentados y configuración SSL, todo a la vez, para alguien que solo quiere monitorear una base de datos. Cuando finalmente aparecieron los datos, el panel de control lideró con estadísticas de fragmentación y métricas de conjunto de réplicas. No teníamos ninguno. Aproximadamente el sesenta por ciento de la pantalla estaba vacío.
Precisión de métricas bajo carga
SolarWinds contó 1,400. Exactamente correcto. New Relic informó 11,670, incorrecto por un orden de magnitud sin una explicación obvia, y perdió un pico de memoria durante toda la prueba. Cuando detuvimos el servicio de MongoDB, SolarWinds detectó el fallo dentro de los treinta a cuarenta segundos.
En el consumo de recursos: New Relic usó alrededor de 90 MB de RAM, Datadog alrededor de 330 MB y SolarWinds alrededor de 500 MB en nuestro servidor de 16 GB. SolarWinds realizó aproximadamente cuarenta veces más lecturas de disco que New Relic, probablemente debido al trabajo de perfilado de consultas local. Para la mayoría de los entornos, nada de esto impulsará su decisión.
La función que realmente los separa
Cada herramienta de monitoreo le dirá que algo es lento. La pregunta es si le dice por qué.
SolarWinds ofrece perfilado a nivel de consulta. La pestaña Profiler mostró exactamente qué patrones de consulta se estaban ejecutando, cuánto tardó cada uno y cuántas muestras se capturaron. Puede filtrar por consultas que se ejecutaron sin un índice, devolvieron errores o generaron advertencias.
New Relic y Datadog mostraron solo métricas agregadas para latencia, recuentos de conexiones y totales de operaciones. Sin perfilado, sin identificación de consultas lentas, sin detección de índices faltantes. Para confirmar que una base de datos está activa, viable. Para diagnosticar por qué está luchando, un callejón sin salida.
Nota: Datadog lanzó un producto de Monitoreo de bases de datos para MongoDB en diciembre de 2024, después de nuestras pruebas, que agrega análisis de operaciones lentas, planes de explicación y visibilidad a nivel de consulta. Probamos la integración estándar, que sigue siendo lo que la mayoría de los usuarios encuentran primero.
SolarWinds: Si la optimización de bases de datos es su verdadera preocupación. Métricas precisas, configuración rápida y la única plataforma aquí que le dice no solo que una consulta es lenta sino qué hacer al respecto.
New Relic: Si ya lo está usando para APM y necesita salud básica de base de datos en el mismo lugar. Rastrear una solicitud lenta desde el navegador a través del código hasta la llamada de base de datos es genuinamente útil. No confíe en él para recuentos de operaciones precisos.
Datadog: Si se siente cómodo con la configuración manual y quiere una plataforma en toda una pila compleja. Las más de 600 integraciones justifican la fricción de configuración para el equipo adecuado.
Cita esta investigación
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{dogan2026,
author = {Dogan, Sedat and Sezer, Sena},
title = {{MongoDB Monitoring: SolarWinds vs New Relic vs Datadog}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/mongodb-monitoring}},
note = {AIMultiple. Recuperado el 12 de Junio de 2026}
}







, PyMongo")







![Pantalla de prueba de conexión mostrando estado 'No probado']](https://aimultiple.com/wp-content/uploads/2025/12/11.png.webp "Pantalla de prueba de conexión mostrando estado 'No probado']")





, Disponibilidad 98.3%, Tiempo de respuesta 23.53ms, Rendimiento 0.88 OPS, Errores 0 EPS y gráfico de burbujas Top 10 Service Breakdown")








'")

'")




Sé el primero en comentar
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.