Principales 6 herramientas de código abierto para el descubrimiento de datos sensibles
Las siguientes herramientas se seleccionan según la actividad en GitHub y se ordenan por la cantidad de estrellas de GitHub en orden descendente. Cubren los casos de uso principales para el descubrimiento de datos sensibles: catalogación de metadatos con linaje, escaneo sin agentes y detección basada en API de PII, datos PCI y credenciales en reposo.
Lea más: Herramientas de descubrimiento y clasificación de datos sensibles, Software DLP.
Características administrativas
Herramienta | Panel gráfico | Basado en búsqueda | Linaje de datos | Sistema de base de datos federado |
|---|---|---|---|---|
DataHub | ✅ | ✅ | ✅ | ✅ |
Apache – Atlas | ✅ | ✅ | ✅ | ❌ |
Marquez | ✅ | ✅ | ✅ | No compartido. |
OpenDLP | ❌ | ❌ | ❌ | ❌ |
Piiano Vault – ReDiscovery | ❌ | No compartido. | ❌ | ❌ |
Nightfall IA – Sensitive data scanner | ✅ | ✅ | ❌ | ❌ |
Descripciones de características:
- Panel gráfico – permite visualizar sus hallazgos de datos.
- Basado en búsqueda funcionalidad – permite buscar activos de datos.
- Linaje de datos – permite a los usuarios visualizar cómo se generan, transforman, transmiten y utilizan los datos en un sistema a lo largo del tiempo.
- Sistema de base de datos federado – mapea múltiples sistemas de bases de datos autónomos en una sola base de datos federada.
Estas funcionalidades (especialmente el linaje de datos y las capacidades de búsqueda) permiten a las empresas:
- Descubrir la ubicación de su información personal (PII), industria de tarjetas de pago (PCI) datos, etc., almacenados en múltiples bases de datos, aplicaciones y puntos finales de usuarios.
- Cumplir con los estándares de protección de datos y privacidad regulatorios de la industria, como el Reglamento General de Protección de Datos (GDPR) y la Ley de Privacidad del Consumidor de California (CCPA).
Características de seguridad de datos
Descripciones de características:
- Enmascaramiento de datos– permite ocultar datos modificando sus letras y números originales, de modo que no tengan valor para intrusos no autorizados mientras siguen siendo utilizables para empleados autorizados.
- Prevención de pérdida de datos (DLP) – detecta posibles brechas de datos y las previene bloqueando datos sensibles.
Categorías y estrellas de GitHub
Selección y ordenamiento de herramientas:
- Número de reseñas: 10+ estrellas de GitHub.
- Publicación de actualización: Se lanzó al menos una actualización la semana pasada a partir de noviembre de 2024.
- Ordenamiento: Las herramientas se ordenan por estrellas de GitHub en orden descendente.
DataHub
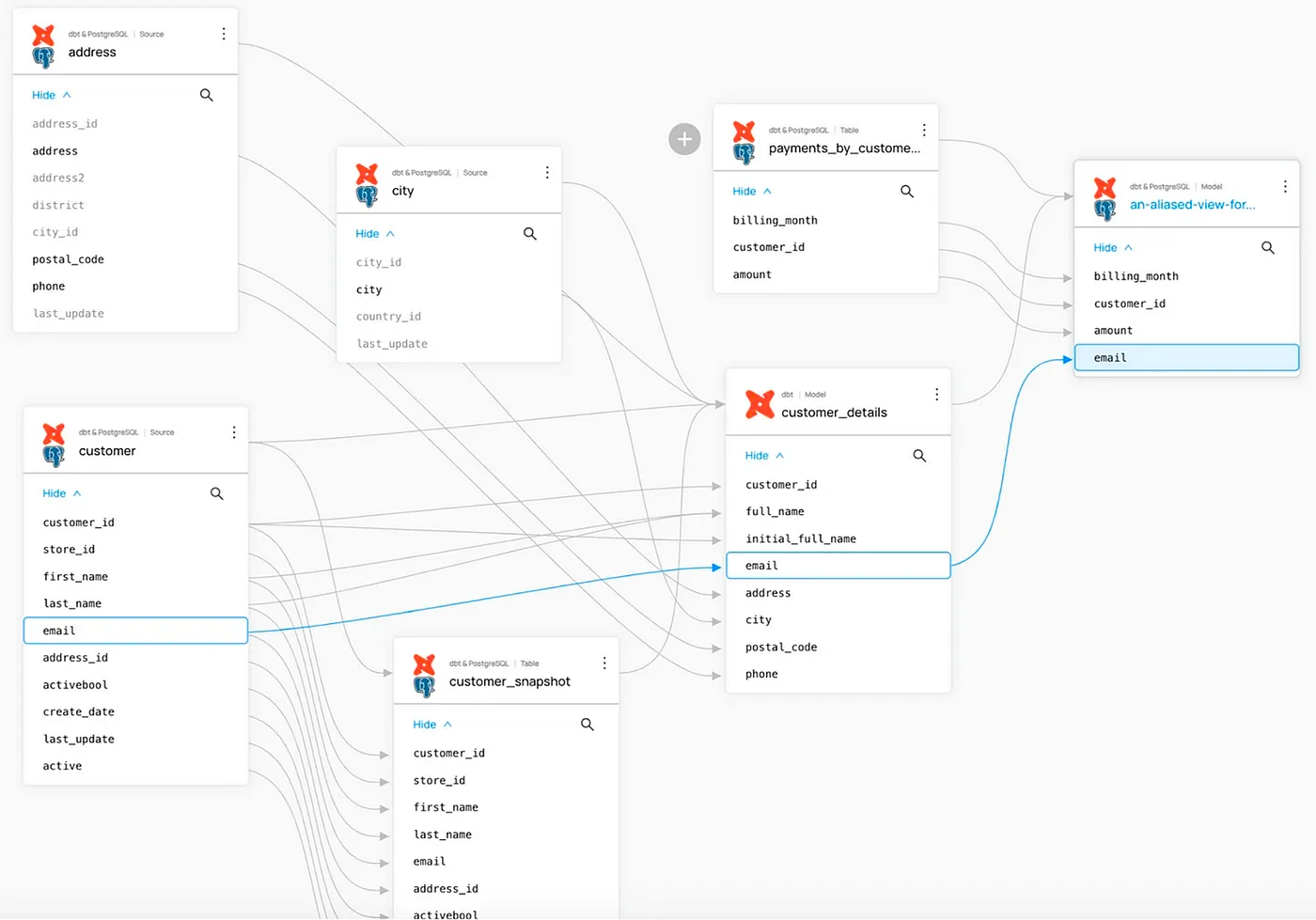
DataHub es una plataforma unificada de código abierto para el descubrimiento de datos sensibles, la observabilidad y la gobernanza, construida por Acryl Data y LinkedIn. También se ofrece comercialmente por Acryl Data como una oferta SaaS alojada en la nube.
Características clave:
- Linaje de datos a nivel de columna: rastrea el flujo de datos desde la fuente hasta el consumo a través de plataformas.
- Calidad de datos asistida por IA: la detección de anomalías señala problemas de calidad de datos automáticamente.
- Extensibilidad: REST APIs, SDK de Python e integración con LangChain para construir agentes con acceso a metadatos de DataHub.
- 80+ conectores nativos: Snowflake, BigQuery, Redshift, Hive, Athena, Postgres, MySQL, SQL Server, Trino, Looker, Power BI, Tableau, Okta, LDAP, S3, Delta Lake y otros.
Consideración: La arquitectura de DataHub ejecuta múltiples servicios interconectados (GMS, consumidor MCE, consumidor MAE, índice de búsqueda, almacén de gráficos). Las implementaciones de producción generalmente requieren Kubernetes. La complejidad de configuración es el punto doloroso más citado en la comunidad.
Apache – Atlas
Apache Atlas es una herramienta de código abierto para la gestión y gobernanza de metadatos, diseñada principalmente para Hadoop y ecosistemas de big data. Soporta clasificación, seguimiento de linaje y búsqueda en activos de datos en entornos construidos sobre Hive, HBase, Kafka, Spark, Sqoop y Storm.
Características clave
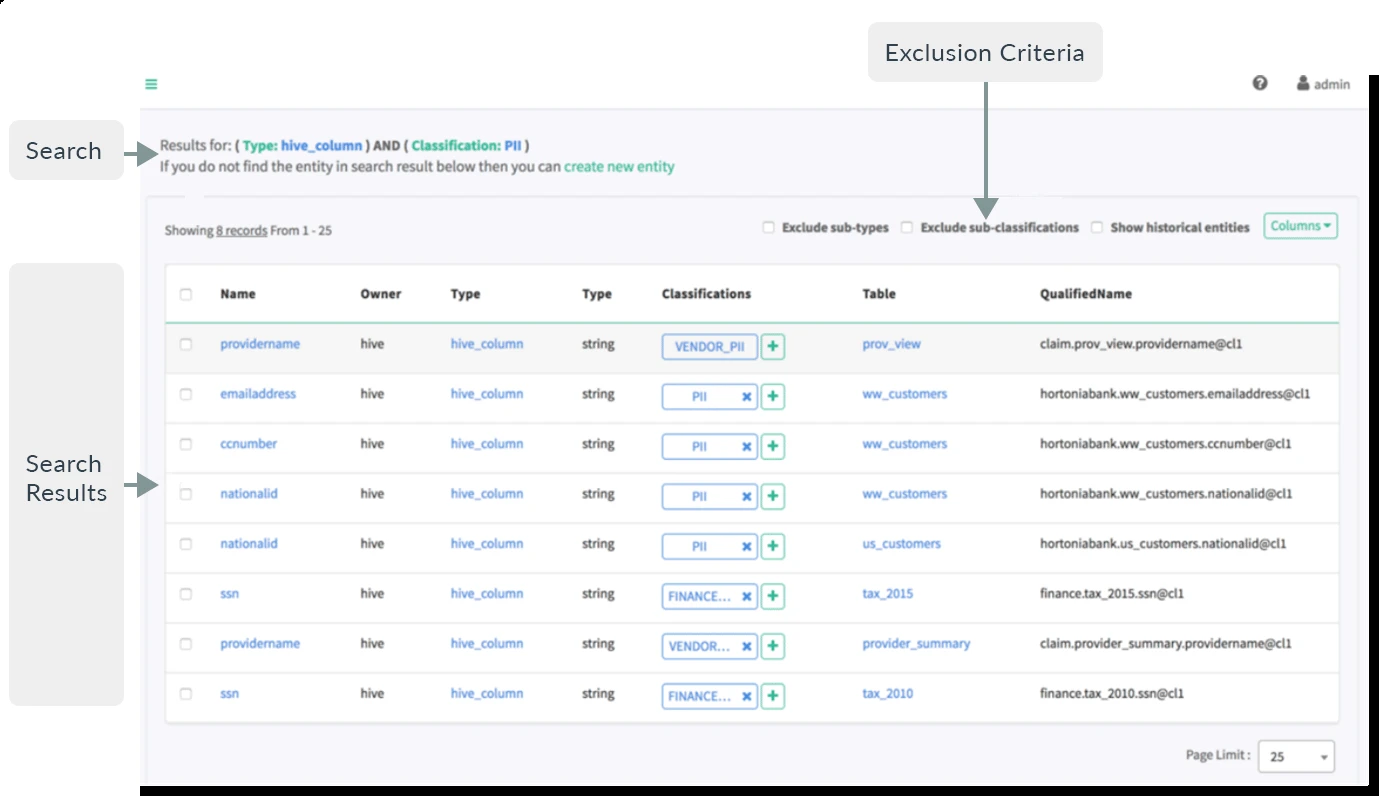
- Clasificación dinámica: Apache Atlas permite crear clasificaciones personalizadas como PII (Información de Identificación Personal), EXPIRES_ON, DATA_QUALITY y SENSITIVE.
- Tipos de metadatos: La plataforma proporciona tipos de metadatos predefinidos para entornos Hadoop y no Hadoop. Esto permite a los usuarios gestionar metadatos para varias fuentes de datos, como HBase, Hive, Sqoop, Kafka y Storm.
- SQL-lenguaje de consulta similar (DSL): La plataforma soporta un lenguaje específico de dominio (DSL) que proporciona funcionalidad de consulta similar a SQL para buscar entidades. Esto lo hace accesible para usuarios familiarizados con SQL.
- Integración con herramientas externas: Apache Hive, Apache Spark, Kafka y Presto, lo que lo hace adaptable para entornos de big data.
Consideraciones:
- Configurar Atlas en un entorno multicloud es complejo, especialmente al conectar AWS, Azure y Databricks APIs. Atlas no tiene conectores nativos para estas plataformas; se requiere configuración adicional para registrar el linaje de AWS Redshift o Azure Synapse.
- Los servicios de catalogación nativos de la nube (por ejemplo, AWS Glue) pueden ofrecer un seguimiento de linaje con menor sobrecarga para equipos ya comprometidos con un solo proveedor de nube.
- Atlas es más adecuado para organizaciones que ejecutan Hadoop, Spark y Hive a escala. Los equipos sin una pila centrada en Hadoop encontrarán que su arquitectura agrega complejidad innecesaria.
Marquez
Marquez es un catálogo de datos de código abierto para recopilar, agregar y visualizar metadatos de un ecosistema de datos. Proporciona una interfaz web UI y REST API para navegar por conjuntos de datos, comprender sus dependencias y rastrear cambios a través de pipelines de datos.
- Buscar conjuntos de datos: Los usuarios pueden buscar fácilmente conjuntos de datos, ver sus atributos y comprender sus dependencias en todo el ecosistema de datos.
- Visualizar linaje: El gráfico de linaje en Marquez proporciona una vista clara e interactiva de cómo se conectan y transforman los conjuntos de datos a través de flujos de trabajo. Esto es crucial para comprender pipelines de datos, rastrear errores y garantizar la fiabilidad de los datos.
- Repositorio centralizado de metadatos: Marquez agrega metadatos de diversas fuentes, consolidándolos en un solo sistema para un acceso y gestión fáciles.
Ejemplo de flujo de trabajo: Para inspeccionar metadatos de linaje, navegue a la interfaz de usuario de Marquez y busque un trabajo (por ejemplo, etl_delivery_7_days) usando el cuadro de búsqueda. Desde el conjunto de datos de salida del trabajo (public.delivery_7_daysYou can view the dataset name, schema, description, and upstream inputs.
Piiano Vault – ReDiscovery
Piiano Vault es una bóveda de privacidad para almacenar y asegurar datos personales sensibles dentro de su propio entorno en la nube. En lugar de escanear bases de datos existentes en busca de datos sensibles, Vault está diseñado como el almacén autorizado para los campos más sensibles: números de tarjetas de crédito, números de cuentas bancarias, identificaciones nacionales (SSN), nombres, correos electrónicos y números de teléfono, instalados junto con sus bases de datos de aplicaciones existentes.
Vault se implementa dentro de su arquitectura mediante Docker o Kubernetes (gráficos Helm disponibles). Los SDK están disponibles para Python (Django ORM), TypeScript, Java y Go. El repositorio vault-releases se actualizó por última vez en agosto de 2025.
Distinción de caso de uso: Vault no es un escáner de descubrimiento de datos. Es un sistema de almacenamiento estructurado para datos sensibles que las organizaciones quieren centralizar y proteger, no una herramienta para encontrar datos sensibles ya dispersos en sistemas existentes.
Nightfall
Nightfall es una plataforma DLP nativa de IA comercial, no una herramienta completamente de código abierto. Sus repositorios de GitHub incluyen scripts de escáner de código abierto (Apache 2.0) que utilizan la API de Nightfall para escanear directorios, exportaciones y copias de seguridad. La ejecución de escaneos requiere una clave API de Nightfall y llama al motor de detección comercial de Nightfall. El nivel gratuito permite hasta 100 escaneos por mes en repositorios públicos y privados.
Capacidades del escáner de código abierto (nivel gratuito):
- Escanea el historial completo de commits de repositorios públicos y privados.
- Detecta credenciales, secretos, PII y números de tarjetas de crédito.
- Ejecuta hasta 100 escaneos por mes.
Característica distintiva: Nightfall puede enviar alertas a Slack cuando se detectan violaciones y enviar resultados a un SIEM, herramienta de informes o punto final de webhook.
Ejemplo de caso de uso: Escanee una copia de seguridad de Salesforce para detectar datos sensibles en reposo. El escáner (1) envía archivos de copia de seguridad a la API de Nightfall para escanear, (2) ejecuta un servidor webhook local para recibir resultados y (3) exporta hallazgos a un archivo CSV.
La URL anterior es proporcionada por Nightfall. Es la URL firmada temporalmente de S3 para recuperar los hallazgos sensibles que Nightfall identificó.
Lectura adicional
Cita esta investigación
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sezer, Sena},
title = {{Principales 6 herramientas de código abierto para el descubrimiento de datos sensibles}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/open-source-sensitive-data-discovery}},
note = {AIMultiple. Recuperado el 24 de Junio de 2026}
}


Sé el primero en comentar
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.