Construire des agents IA avec des motifs composables
Nous avons passé 3 jours à expérimenter avec des workflows et des pipelines d'agents dans n8n, en suivant les guides d'Anthropic et d'OpenAI sur la construction d'agents IA efficaces.1 2
Explorez les composants principaux des agents IA, comment choisir les bons composants et outils, en plus de construire des workflows d'agents basés sur les motifs simples et composables d'Anthropic tels que le chaînage de prompts, le routage, la parallélisation, les workers orchestrateurs et un évaluateur-optimiseur :
Comprendre les composants des agents IA
Construire des agents implique de connecter des composants dans plusieurs domaines tels que les modèles, les outils, la connaissance et la mémoire, les garde-fous. OpenAI fournit des primitives composables pour chacun :
Source : OpenAI3
Évidemment, OpenAI y liste ses propres éléments en premier, mais il existe un vaste écosystème d'alternatives. Selon votre cas d'usage, vous pouvez construire des agents en utilisant des frameworks tels que LangChain, LlamaIndex, CrewAI, ou même des couches d'orchestration personnalisées.
Je vais entrer plus en détail sur chacun de ces composants :
Modèles
D'abord, il y a le composant modèles. Ce sont vos modèles d'IA, vos grands modèles de langage qui constituent l'intelligence centrale capable de raisonner, de prendre des décisions et de traiter différentes modalités. Les propres exemples d'OpenAI pointent vers ses modèles de la série GPT-5.
Selon le type spécifique d'agent que vous construisez, vous voudrez choisir un type de modèle différent au sein de l'écosystème OpenAI. GPT-5.5 est le modèle phare actuel d'OpenAI. Il planifie des tâches en plusieurs étapes, utilise des outils, vérifie son propre travail et continue jusqu'à ce qu'une tâche soit terminée. Pour les questions courantes, les modes plus légers de GPT-5.5 répondent plus vite et coûtent moins cher.
En dehors de l'écosystème OpenAI, Claude Opus 4.7 est un choix courant pour le codage lourd, le raisonnement et le travail STIM. Gemini 3.1 Pro de Google rivalise de près, avec une fenêtre de contexte de 1 million de tokens pour les grandes bases de code et les longs documents.
Pour les agents de codage spécifiquement, GPT-5.3-Codex d'OpenAI est son modèle de codage le plus performant. Il exécute de longues tâches qui mélangent recherche, utilisation d'outils et exécution, et vous pouvez le piloter pendant qu'il travaille. Il mène sur les benchmarks comme SWE-Bench Pro et Terminal-Bench 2.0, qui testent le vrai travail d'ingénierie logicielle et en ligne de commande.
Nous avons benchmarké et comparé les meilleurs modèles d'IA pour vous aider à comprendre comment chacun performe en termes de raisonnement, vitesse et coût afin que vous puissiez choisir celui qui correspond le mieux à vos objectifs.
Outils
Ensuite viennent les outils qui étendent les capacités du modèle, comme lui permettre de chercher sur le web ou d'interagir avec d'autres systèmes.
Presque n'importe quelle application peut devenir un outil pour votre IA. Vous pouvez la connecter à Gmail, Calendar, votre drive, ou des applications comme Slack, Discord, YouTube, Salesforce et Zapier. Vous pouvez même créer vos propres outils personnalisés.
Avec le SDK Agents d'OpenAI (qui nécessite un peu de codage), vous pouvez définir des outils ou utiliser ceux intégrés comme la recherche web, la recherche de fichiers et l'utilisation d'ordinateur.4
MCP (Model Context Protocol) par Anthropic simplifie également l'intégration d'outils en standardisant la façon dont les modèles y accèdent. En 2026, la valeur métier provient de plus en plus de « chaînes de montage numériques », des workflows guidés par l'humain en plusieurs étapes où plusieurs agents exécutent des processus de bout en bout, rendus possibles par le Model Context Protocol (MCP).
Si vous n'êtes pas porté sur le codage, les plateformes no-code comme n8n vous permettent de glisser-déposer des outils pour les lier à votre modèle.
Connaissance et mémoire
Il existe deux principaux types de mémoire : la base de connaissances (mémoire statique) et la mémoire persistante.
- La base de connaissances donne à votre IA l'accès à des faits statiques, des politiques et des documents qui restent relativement inchangés. C'est essentiel pour les agents effectuant des tâches axées sur des politiques ou spécifiques à l'entreprise où les documents de référence doivent rester cohérents.
- La mémoire persistante permet à l'IA de se souvenir des interactions passées à travers les sessions. C'est crucial pour les chatbots ou les assistants personnels qui ont besoin de se rappeler des conversations précédentes.
OpenAI fournit des services hébergés comme les vector stores, la recherche de fichiers et les embeddings pour gérer la mémoire.
Si vous préférez des solutions open-source, Pinecone (cloud-native et optimisé pour la recherche vectorielle) et Weaviate sont des options populaires.
Pour ceux qui utilisent des outils no-code, la gestion de la mémoire est généralement intégrée dans des plateformes comme n8n et Creatio.
Garde-fous
Les garde-fous garantissent que votre agent se comporte comme prévu, en évitant les réponses non pertinentes, nuisibles ou inappropriées. Par exemple, un chatbot de service client devrait rester concentré sur les sujets liés au service, et ne pas dériver vers des sujets sans rapport.
En dehors de l'écosystème d'OpenAI, les outils populaires incluent Guardrails IA et LangChain Guardrails. De nombreuses plateformes no-code ont des fonctionnalités de garde-fou intégrées, mais il est tout de même important de comprendre comment elles fonctionnent pour maintenir le contrôle et la conformité de vos agents.
Compétences (Skills)
Les outils permettent à un agent d'agir sur le monde extérieur. Les compétences (Skills) apprennent à l'agent comment bien faire un travail spécifique.
Une compétence (Skill) est un petit dossier d'instructions et de fichiers. Il contient les étapes, les règles et les exemples pour une tâche, comme remplir un modèle de rapport ou suivre le guide de style d'une entreprise. L'agent charge une compétence lorsque la tâche l'exige, afin de ne pas encombrer la fenêtre de contexte.
Anthropic a introduit les compétences d'agent (Agent Skills) fin 2025 et a ouvert le format en tant que standard partagé en mars 2026.5 Les compétences fonctionnent sur Claude.ai, Claude Code et l'API. Le principal avantage est la cohérence : au lieu de réécrire le même long prompt à chaque fois, une équipe définit une compétence une fois et la réutilise. C'est important en production, où le prompting ad hoc a tendance à dériver.
En quoi les compétences diffèrent des autres composants :
- Outils connectent l'agent aux systèmes extérieurs (email, bases de données, recherche).
- Connaissance et mémoire donnent à l'agent des faits à lire.
- Compétences donnent à l'agent une méthode reproductible pour une tâche.
Orchestration
Le dernier composant est l'orchestration. Cela implique de gérer comment plusieurs sous-agents travaillent ensemble, de les déployer en production et de surveiller leurs performances.
Une fois déployés, les agents ont besoin d'une supervision continue. Les modèles, les données et les comportements changent, donc les agents ont besoin de mises à jour régulières.
Plusieurs plateformes et frameworks supportent l'orchestration, comme :
- Plateformes low-code/no-code :
- Stack AI
- Microsoft Copilot Studio Agent Builder
- Relevance IA, etc
- Frameworks open source :
- LangGraph (partie de LangChain) : modélise un agent comme un graphe d'étapes, avec un contrôle explicite sur le branchement, les reprises et les points de contrôle humains.
- CrewAI : organise les agents comme une « équipe » de rôles, tels que chercheur, rédacteur et relecteur. C'est rapide à prototyper quand le travail se divise en rôles clairs.
- LlamaIndex : le plus fort pour les agents qui cherchent dans des documents et des bases de connaissances internes.
- SDKs des fournisseurs : le SDK Agents d'OpenAI et le SDK Agent Claude d'Anthropic sont des toolkits officiels pour construire des agents sur les modèles de chaque fournisseur. Le SDK Agent Claude est la même architecture qui alimente Claude Code.
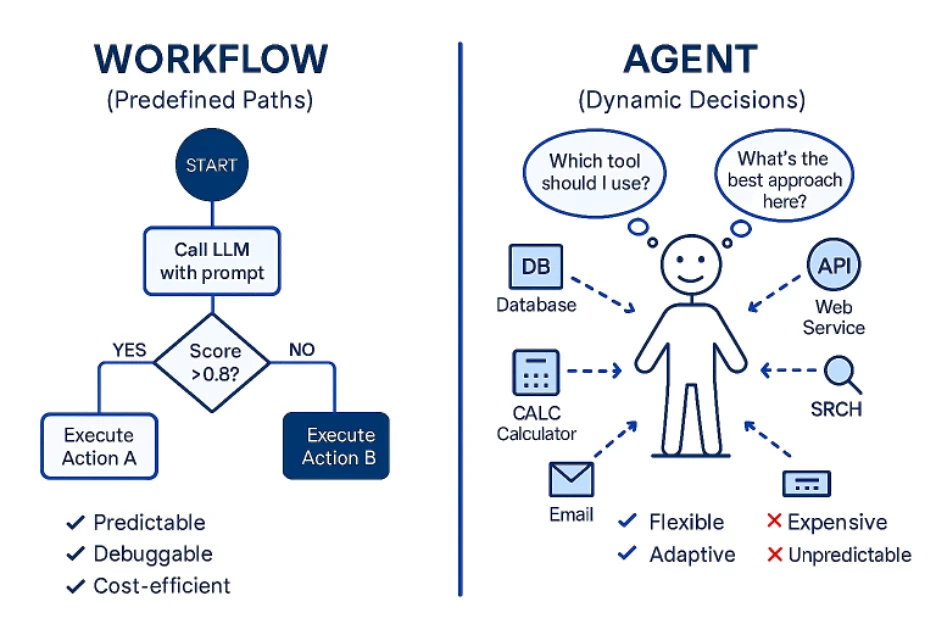
Blocs de construction de l'automatisation : Workflows vs agents
Un agent IA est un système qui perçoit son environnement, traite l'information et prend des actions de manière autonome pour atteindre des objectifs spécifiques, comme les agents de codage tels que Cursor ou Windsurf, des éditeurs de code alimentés par l'IA avec des « modes agent » qui peuvent effectuer de manière autonome des tâches de codage en utilisant des modèles comme Claude Opus 4.7. Un autre exemple courant est celui des agents de service client, que de nombreuses entreprises utilisent pour traiter les demandes.
Il existe de nombreuses façons différentes de concevoir et de déployer ces agents, selon la complexité du workflow et le degré d'autonomie requis.
Pour donner un aperçu rapide, un agent IA est souvent une collection de sous-agents, chacun effectuant des tâches spécifiques. Ensemble, ces sous-agents se coordonnent au sein de systèmes multi-agents pour fournir ce que nous percevons comme un seul agent IA.
Ils sont fondamentalement différents des workflows. Les workflows sont des séquences orchestrées d'étapes prédéfinies, comme une recette qui suit toujours le même ordre :
Quand utiliser des agents IA
Avant les exemples de workflow, voici une petite vérification de la réalité. Les agents ne sont pas toujours la réponse. De nombreuses équipes obtiennent encore de bons résultats avec de simples workflows, même sur des tâches où un agent pourrait, en théorie, fonctionner. De nombreuses équipes constatent encore que les workflows traditionnels performent bien, même dans des scénarios où les agents pourraient, en théorie, être appliqués.
L'une des façons les plus claires d'y penser, décrite dans le blog d'Anthropic, est la suivante :
Cela dit, il existe de vraies situations où les agents surpassent les workflows traditionnels dans des tâches qui exigent flexibilité, raisonnement et adaptabilité :
Conversations dynamiques qui nécessitent des adaptations :
Certaines interactions, comme les demandes simples de remboursement ou de réinitialisation de mot de passe, s'intègrent parfaitement dans des workflows. Mais d'autres exigent un jugement nuancé ou des décisions sensibles au contexte, comme des recommandations personnalisées, qui dépendent fortement du contexte et d'un raisonnement par aller-retour.
Prise de décision à forte valeur ajoutée et faible volume :
Les agents peuvent être coûteux à exécuter, mais dans certains cas, les décisions qu'ils soutiennent sont bien plus coûteuses si elles sont prises de manière incorrecte.
Par exemple, BCG a rapporté qu'un fournisseur d'énergie leader en Allemagne a utilisé un outil agentique alimenté par GenAI pour automatiser les revues de paiement.6
Si vous planifiez une infrastructure à grande échelle, comme l'optimisation de conceptions d'ingénierie, le coût de calcul est négligeable. Dans ces cas à fort enjeu, les agents ajoutent de la valeur parce que le coût d'une erreur dépasse de loin le coût d'exécution du modèle.
Workflows multi-étapes et imprévisibles :
Certains workflows sont trop complexes, où écrire des règles « si ceci, alors cela » sans fin devient son propre projet.
Dans ces cas, les boucles agentiques simplifient le chaos. Au lieu de coder en dur chaque chemin possible, le modèle décide dynamiquement de la prochaine étape en fonction du contexte et du raisonnement en temps réel.
Cette approche fonctionne bien pour les systèmes de diagnostic ou les outils qui gèrent des dizaines de variables changeantes.
Quand les workflows sont meilleurs
Scénarios à haute fréquence et faible complexité :
Certaines tâches dépendent plus de la vitesse et de l'échelle que du raisonnement, comme :
- Récupérer des informations d'une base de données
- Analyser des messages ou emails structurés
- Répondre à des requêtes de type FAQ
Un workflow pourrait traiter des milliers de ces requêtes, avec un coût et une latence plus prévisibles qu'un agent.
Introduction aux workflows d'agents IA et implémentations
Les agents IA ne sont généralement pas une entité unique. Au lieu de cela, ils sont composés de divers sous-agents qui interagissent les uns avec les autres. L'une des meilleures ressources que j'ai trouvées sur les workflows et systèmes d'agents courants est le guide Building Effective Agents d'Anthropic.7
Au cœur des systèmes agentiques se trouve ce qu'Anthropic appelle le LLM augmenté. Cette structure se compose de trois éléments clés :
- l'entrée,
- le LLM (LLM),
- et la sortie.
Source : Anthropic8
Le LLM augmenté est capable de générer ses propres requêtes de recherche, de sélectionner les outils pertinents et de décider quelles informations stocker en mémoire.
Vous remarquerez peut-être certaines similitudes avec les composants d'OpenAI (comme indiqué ci-dessous). Cependant, cette version est plus simplifiée et manque d'éléments comme les garde-fous et l'orchestration, mais la structure de base reste la même. C'est parfaitement acceptable. Pour des tâches telles que les tests et le déploiement, il est préférable de se référer aux composants d'OpenAI.
Liste des composants d'agent IA d'OpenAI9
Pour comprendre comment ces sous-agents s'assemblent et interagissent pour former un agent IA plus large, je commence par les workflows les plus simples et progresse graduellement vers des systèmes plus complexes et entièrement autonomes :
1. Workflows agentiques simples (chaînage de prompts)
Le workflow agentique le plus simple s'appelle le chaînage de prompts. Dans ce processus, une tâche est décomposée en une série d'étapes, où chaque sous-agent traite la sortie du précédent.
À la base, il fonctionne comme une chaîne de montage, mais vous pouvez introduire des points de décision pour rediriger le flux si nécessaire. Le schéma général reste le même : une entrée est traitée par un sous-agent, qui passe le résultat à un autre sous-agent pour un traitement ultérieur, et ainsi de suite, jusqu'à ce que la sortie finale soit produite. Cette méthode est particulièrement utile pour les tâches qui peuvent être facilement divisées en sous-tâches plus petites et séquentielles.
Le workflow de chaînage de prompts10
Exemple concret :11
Chaînage de prompts dans n8n (plan, évaluer et publier dans des feuilles)
Dans l'exemple ci-dessus, l'utilisateur entre un sujet dans la fenêtre de chat n8n. Chaque nœud LLM utilise le modèle OpenAI Azure.
Le premier LLM génère un plan structuré pour un article de blog. Le prompt pour le Rédacteur de plan est le suivant :
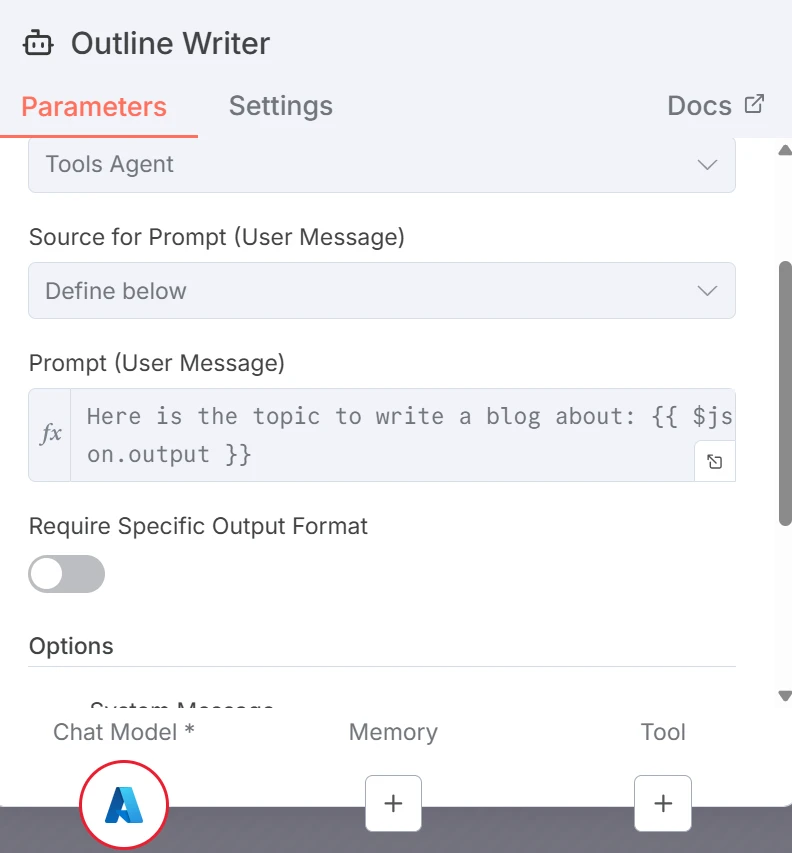
Capture d'écran du prompt pour le LLM générateur de plan
Où {{ $json.chatInput }} fait référence au sujet qui a été entré par l'utilisateur dans la fenêtre de chat.
La variable {{ $json.chatInput }} est grise parce que le workflow n'a pas encore été exécuté. Si nous avions exécuté ou testé le nœud, elle serait verte ou rouge, selon la validité de la variable.
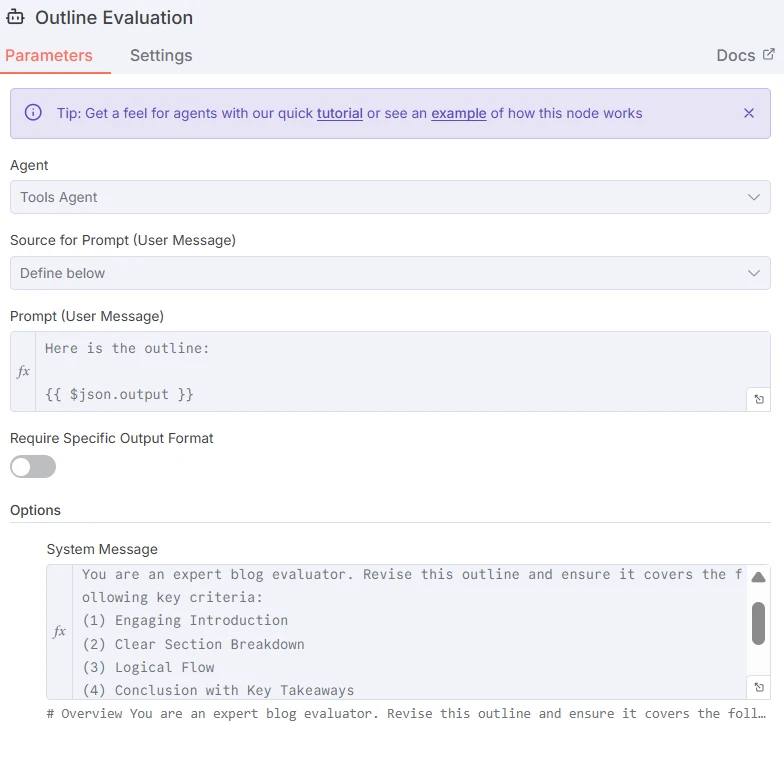
Ensuite, le LLM suivant évaluera le plan sur la base de critères clés dans la section message système. Le prompt se trouve ci-dessous :
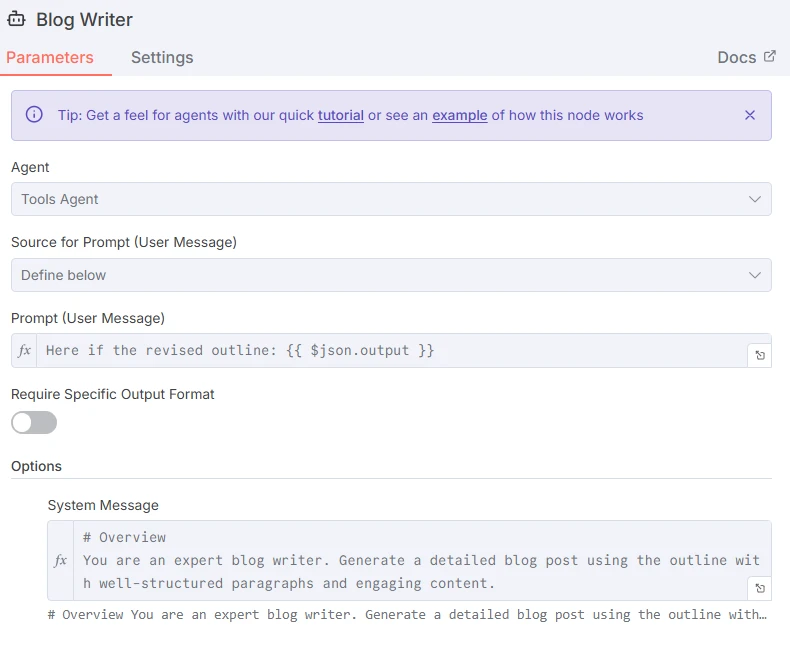
Le LLM Rédacteur de blog final ajoutera une ligne dans une feuille sur le sujet basée sur le plan créé par le LLM précédent.
Capture d'écran du prompt pour le LLM Rédacteur de blog
Quand utiliser le chaînage de prompts :
- Les tâches peuvent être naturellement décomposées en sous-tâches fixes et séquentielles
- Chaque étape contribue de manière significative à la sortie finale
- Le raisonnement étape par étape améliore la précision par rapport au traitement direct
- Des points de contrôle qualité sont nécessaires tout au long du processus
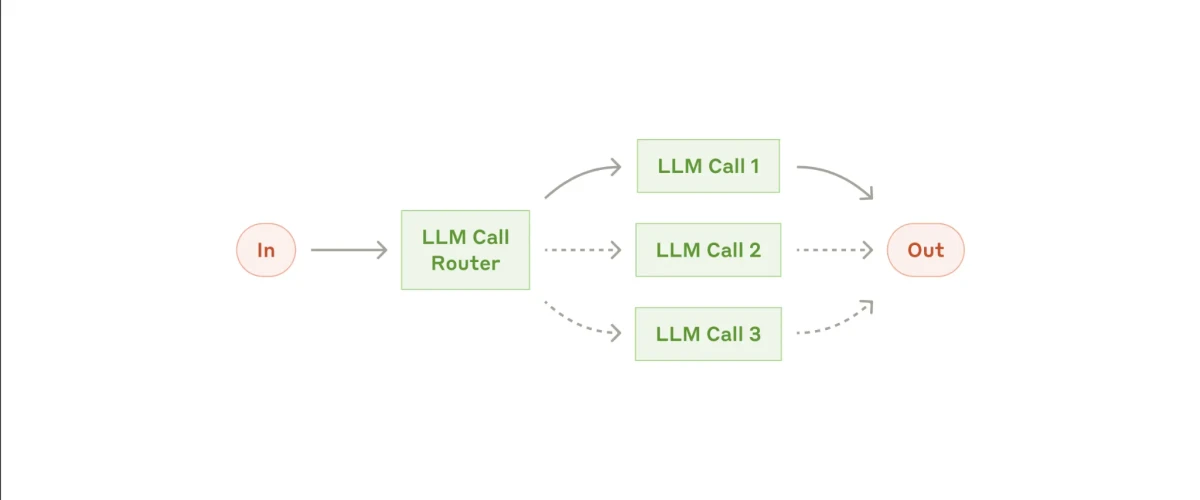
2. Workflow de routage
Le routage est un autre type de workflow où une entrée est reçue, et un sous-agent est responsable de diriger cette entrée vers la tâche de suivi appropriée. Chaque tâche est ensuite traitée par un sous-agent spécialisé dans ce domaine, et une fois les tâches terminées, la sortie finale est générée.
Un exemple classique de routage se voit dans les chatbots de service client. Le bot peut recevoir divers types de requêtes, telles que des demandes générales, des demandes de remboursement ou des problèmes de support technique. Le premier sous-agent identifie la nature de la requête et la route vers le sous-agent spécialisé dans le traitement de ce problème particulier.
Par exemple, si la requête concerne un remboursement, elle serait routée vers le sous-agent spécialiste des remboursements, tandis qu'une question de support technique serait dirigée vers le sous-agent de support technique.
Un autre exemple est le routage des questions vers différents modèles en fonction de leurs forces. Pour des questions STIM plus complexes, vous pouvez router l'entrée vers un modèle de raisonnement fort comme Claude Opus 4.7. Pour des requêtes simples et rapides, vous pouvez le router vers un modèle plus léger comme Gemini 3.5 Flash, qui est conçu pour la vitesse.
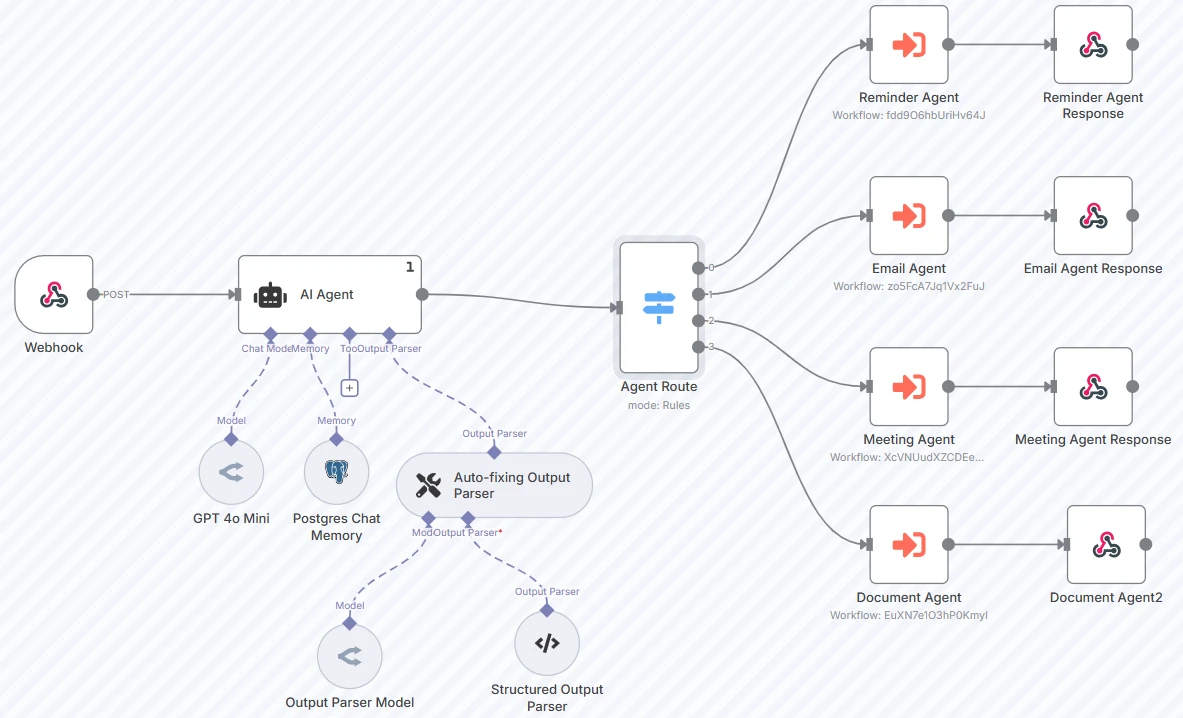
Exemple concret :12
Dans l'exemple ci-dessus, l'agent route l'entrée utilisateur vers des agents spécialisés (comme un Agent de Rappel, un Agent Email, etc.) en utilisant une sortie structurée d'un modèle de langage.
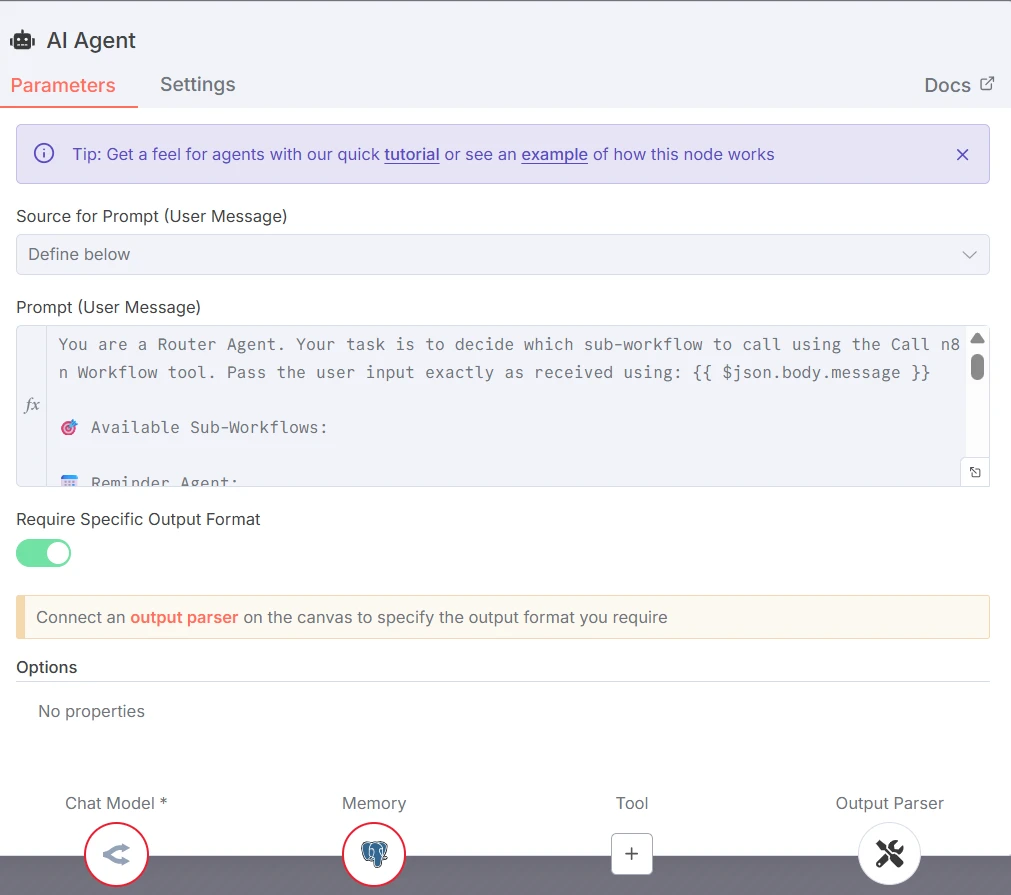
Le routeur est connecté à GPT 4o mini. Le prompt et les catégories sont les suivants :
Capture d'écran des paramètres du nœud d'agent IA
Exemples de cas d'usage :
Vous pouvez entrer une requête dans la fenêtre de chat n8n. Par exemple :
- L'utilisateur dit : « Rappelle-moi d'appeler ma mère demain. »
→ Routé vers l'Agent de Rappel - L'utilisateur dit : « Envoie un email à l'équipe RH. »
→ Routé vers l'Agent Email - L'utilisateur dit : « Planifie une réunion avec Jean la semaine prochaine. »
→ Routé vers l'Agent Réunion
Quand utiliser le routage :
- Types d'entrée diversifiés : Votre système reçoit divers types de requêtes qui bénéficient d'un traitement spécialisé
- Optimisation des ressources : Vous voulez assigner des requêtes simples à des processeurs économiques tout en routant les requêtes complexes vers des systèmes avancés
- Spécialisation de domaine : Différentes catégories d'entrées nécessitent une expertise ou une logique de traitement spécifique au domaine
- Optimisation des performances : Vous devez équilibrer la charge et garantir des temps de réponse optimaux pour différents types de requêtes
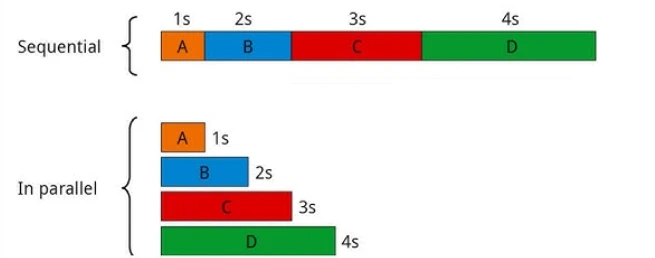
3. Workflow de parallélisation
Le workflow suivant est la parallélisation. Ce workflow agentique spécifique a généralement deux variations principales. Dans la parallélisation, plusieurs sous-agents travaillent sur une tâche simultanément, et leurs sorties sont ensuite combinées.
- La première variation s'appelle le sectionnement, où une tâche est décomposée en sous-tâches indépendantes qui s'exécutent en parallèle.
- La deuxième variation est le vote, où la même tâche est effectuée plusieurs fois par différents sous-agents pour produire des sorties diverses, qui sont ensuite agrégées.
Cela accélère les grands workflows en exécutant des tâches indépendantes en même temps.
Workflow séquentiel vs workflow parallèle : une comparaison de temps13
Exemple concret :14
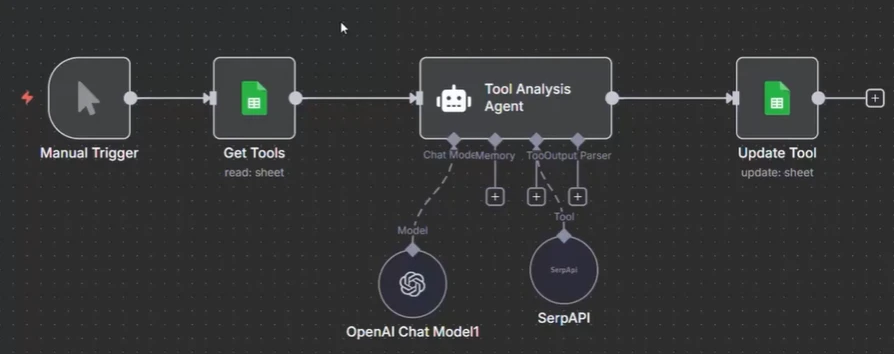
Capture d'écran de l'exemple de workflow de parallélisation dans n8n
L'exemple d'exécution parallèle dans n8n montre une tâche où le workflow interroge la recherche Google en utilisant l'API SERP pour récupérer des URLs LinkedIn et les stocker dans une feuille Google. Dans la configuration initiale, le workflow traite chaque tâche séquentiellement, un site web à la fois :
- Le workflow est déclenché.
- L'outil Get récupère le site web de la feuille Google.
- L'agent IA utilise l'API SERP pour chercher sur Google et récupérer l'URL LinkedIn.
- L'URL LinkedIn est ensuite mise à jour dans la feuille Google.
À ce stade, les tâches sont traitées l'une après l'autre, ce qui peut être lent lorsqu'on traite de grands datasets.
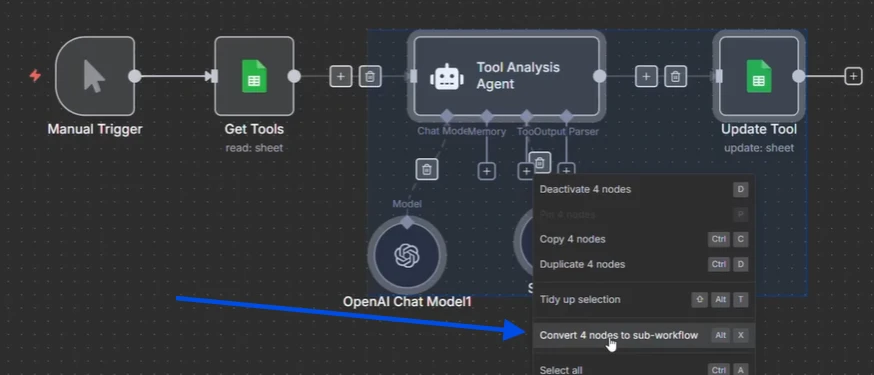
n8n a cette fonctionnalité où vous pouvez sélectionner des nœuds, cliquer, puis dire je veux convertir ces nœuds sélectionnés en un sous-workflow.
Et ce qui se passe quand vous cliquez sur ce bouton, c'est qu'il va nommer mon workflow. Quand vous appuyez sur confirmer, cela transforme tout cela en un sous-workflow et c'est lié juste ici et appelé par celui-ci.
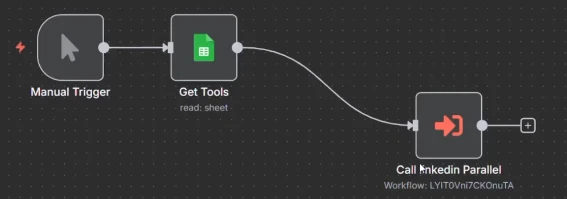
Le sous-workflow créé
Donc n8n a transformé cela en un sous-workflow, mais vous n'avez pas encore de parallélisation parce que cela s'exécuterait toujours tout au travers d'ici.
Pour que cela s'exécute réellement en parallèle, tous les éléments doivent s'exécuter comme des exécutions individuelles. Donc, quand vous cliquez dans le nœud vous pouvez choisir exécuter une fois pour chaque élément, ce qui signifie qu'il va appeler le sous-workflow individuellement pour chaque élément.
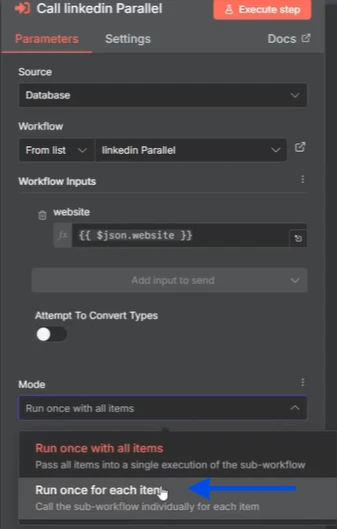
Et puis une fois que vous avez changé cela, vous pouvez aller dans le sous-workflow et cliquer sur exécutions. Et vous allez voir que les trois éléments s'exécutent exactement au même moment.
Quand utiliser la parallélisation : La parallélisation est la plus efficace lorsque les tâches peuvent être divisées en sous-tâches plus petites et indépendantes qui peuvent s'exécuter simultanément, améliorant à la fois la vitesse et l'efficacité.
Elle est également précieuse lorsque plusieurs perspectives ou tentatives répétées sont nécessaires pour renforcer la confiance dans les résultats. Pour les problèmes avec plusieurs parties ou critères de notation, les modèles font souvent mieux lorsque chaque partie reçoit son propre appel. Cela garde chaque appel concentré, de sorte que le raisonnement est plus précis.
4. Workflow orchestrateur-workers
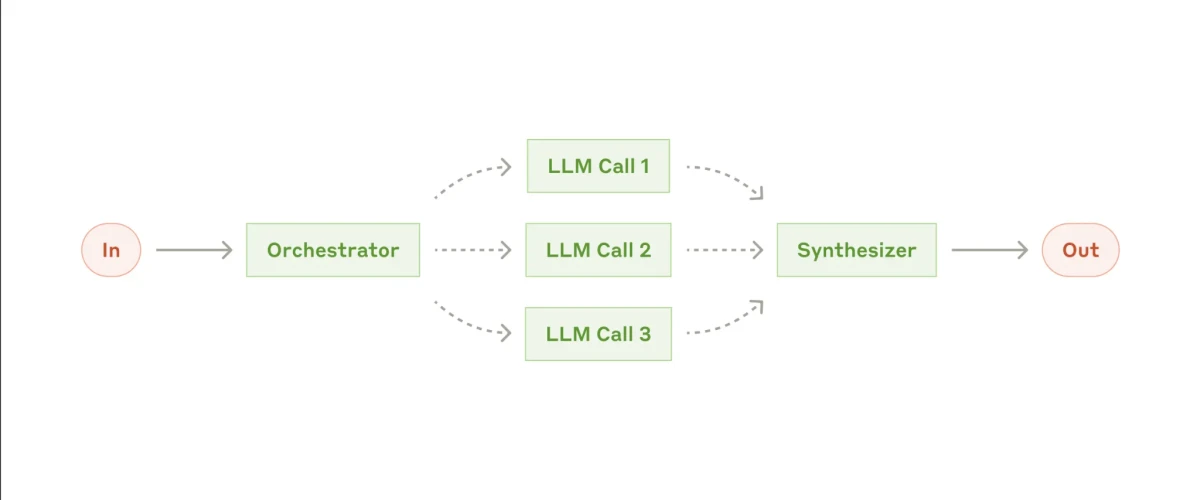
Le workflow suivant, qui devient plus complexe, est le modèle orchestrateur–worker.
L'architecture orchestrateur–worker rend vos workflows n8n modulaires, évolutifs et adaptatifs, transformant une seule automatisation rigide en un système composable d'agents coopérants.
À première vue, cela pourrait ressembler à la parallélisation puisque plusieurs sous-agents peuvent être actifs, mais la distinction clé est la flexibilité. Contrairement à la parallélisation, la configuration orchestrateur–worker ne repose pas sur une liste fixe de sous-tâches. Au lieu de cela, l'orchestrateur décide dynamiquement quelles tâches doivent être effectuées, les assigne aux agents workers et gère leur coordination tout au long du processus.
Exemple concret :15
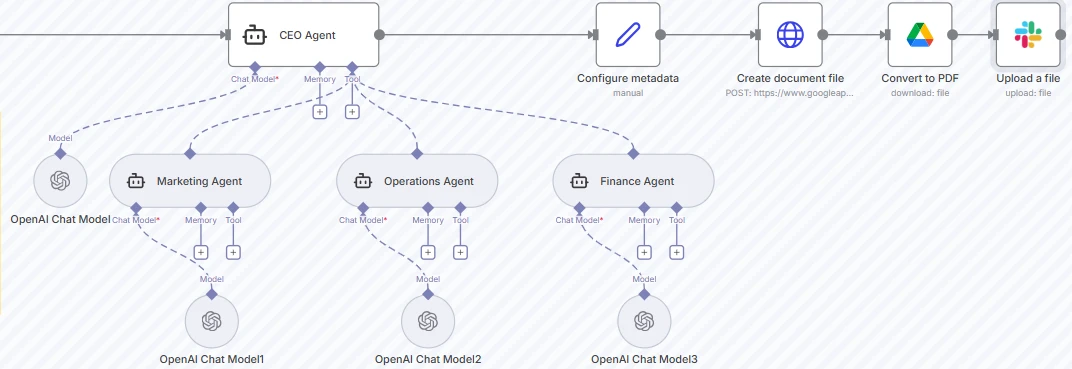
Capture d'écran de l'exemple de workflow orchestrateur-workers dans n8n
Dans l'exemple ci-dessus, le brief est collecté une fois et un orchestrateur route le travail vers plusieurs agents spécialistes.
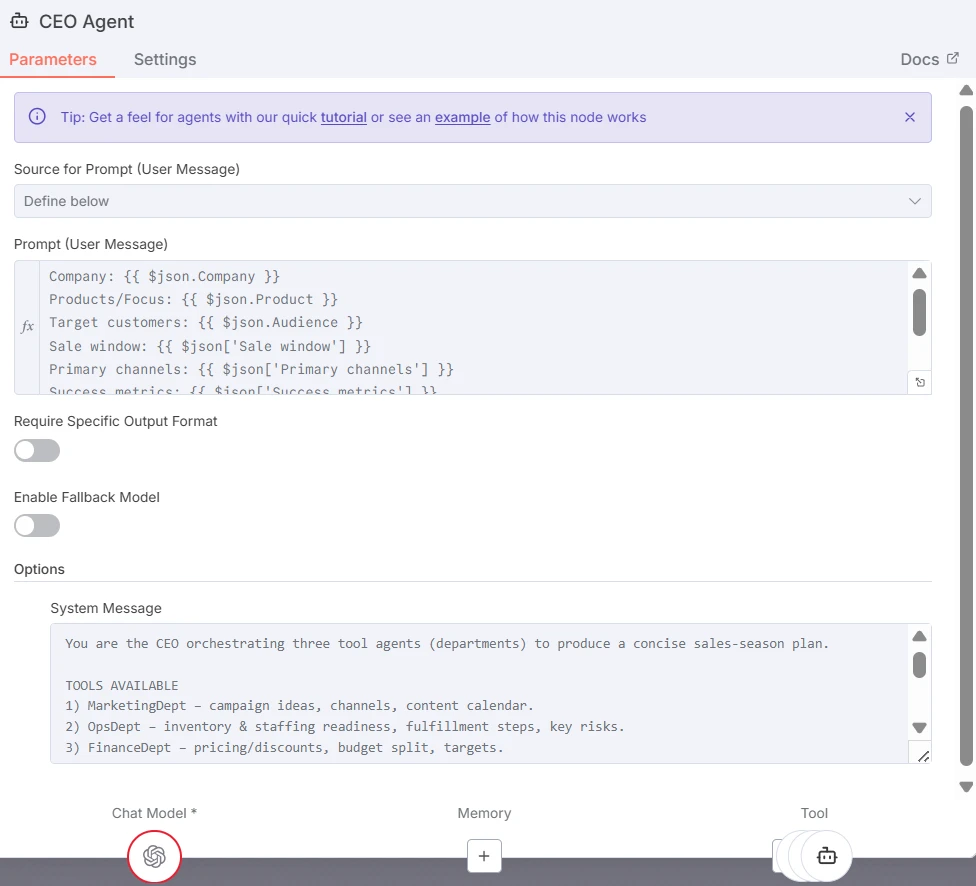
L'Agent CEO agit comme le LLM orchestrateur. Il traite le brief d'entrée, l'affine pour chaque département, sélectionne les agents workers à activer et détermine comment leurs sorties seront intégrées. Il peut décider d'appeler un, deux ou tous les workers selon le contexte et les contraintes.
Capture d'écran du nœud Agent CEO
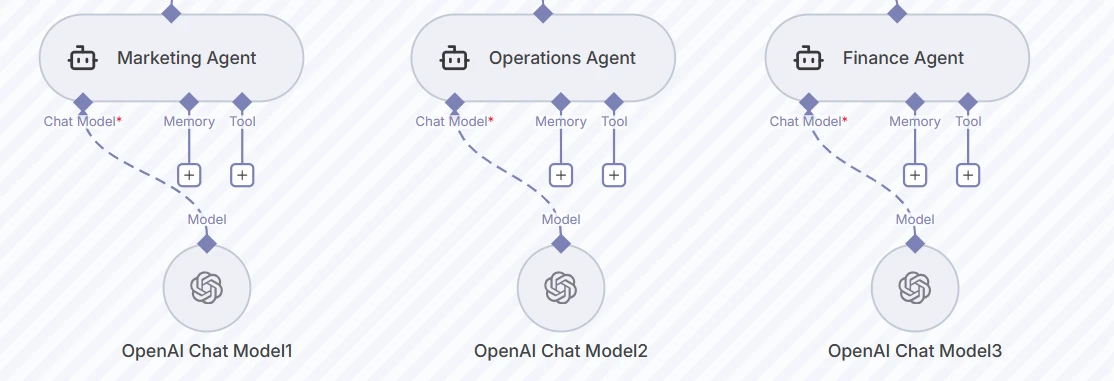
Ci-dessous, trois agents workers, Marketing, Operations et Finance, exécutent chacun leur propre modèle de chat OpenAI avec des configurations de mémoire et d'outils séparées. Cela permet des prompts spécifiques au département et des schémas JSON pour une sortie structurée.
Capture d'écran des trois nœuds d'agents workers
Une fois que l'orchestrateur a préparé des instructions spécifiques au département, il invoque chaque worker comme un outil pour générer des sorties basées sur les entrées.
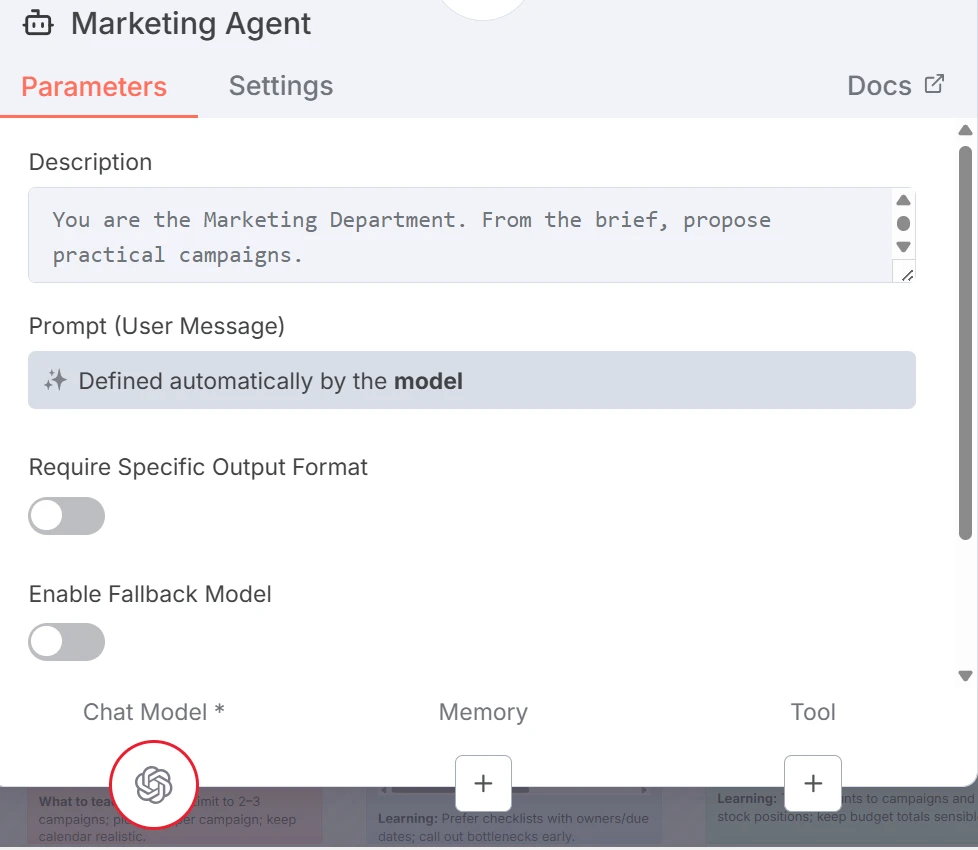
Par exemple, l'Agent Marketing crée des campagnes (nom, canal, KPI).
Nœud outil IA (Agent Marketing)
Après que les sorties des workers sont générées, le CEO Agent compile et fusionne les réponses des départements en un seul plan cohérent. Le workflow écrit ensuite le plan dans un Doc Google, ajoute des métadonnées, le convertit en PDF et le télécharge automatiquement pour partage ou révision.
Capture d'écran des nœuds de création de document, conversion et téléchargement
Lors de l'exécution, l'orchestrateur détermine quels agents activer, coordonne leur collaboration et combine leurs sorties en un rapport complet, démontrant comment les workflows orchestrateur–worker permettent des systèmes IA flexibles, modulaires et composables.
Quand utiliser le workflow orchestrateur workers : Cette approche est particulièrement précieuse pour résoudre des problèmes ouverts ou évolutifs où les étapes requises ne peuvent pas être connues à l'avance.
Exemples où le workflow orchestrateur–worker est utile :
- Tâches de codage : Lors du développement ou du débogage de produits logiciels complexes qui nécessitent des changements coordonnés sur plusieurs fichiers, où les fichiers exacts et les modifications peuvent être déterminés pendant l'exécution.
- Recherche et collecte d'informations : Dans les tâches qui impliquent de chercher, collecter et analyser des données de sources multiples, où les informations pertinentes ne peuvent pas être entièrement identifiées à l'avance et doivent être découvertes dynamiquement.
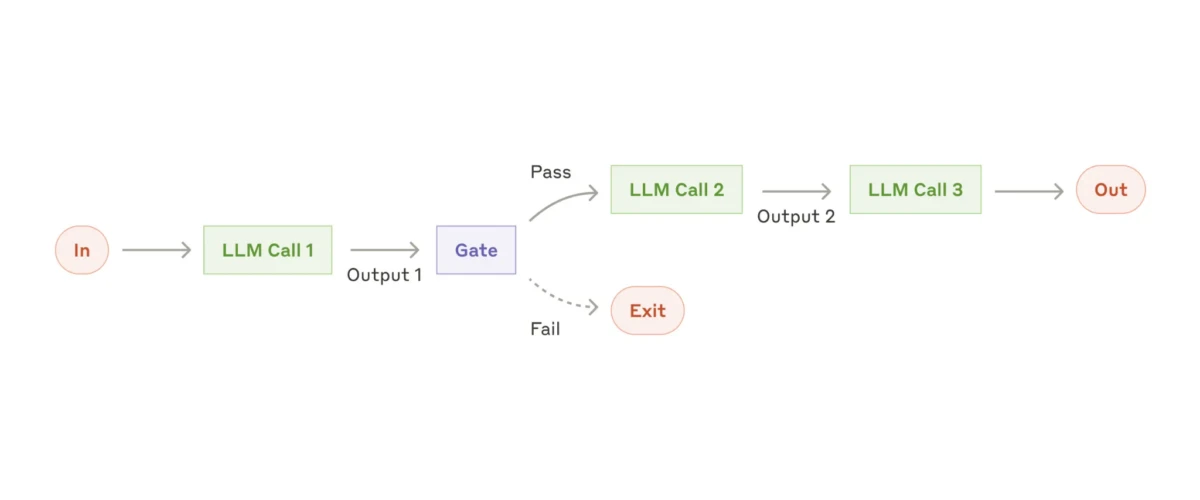
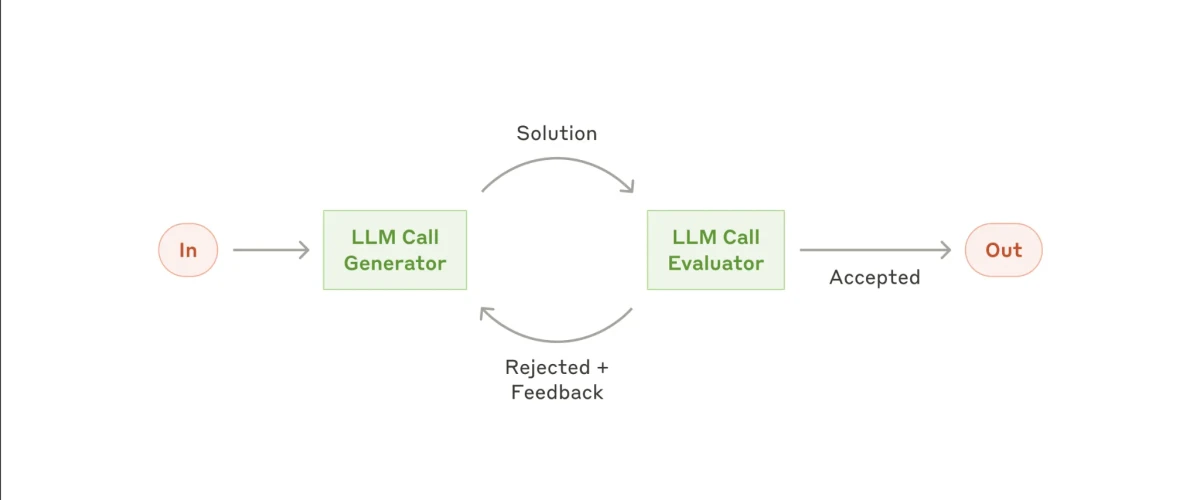
5. Workflow évaluateur-optimiseur
Encore plus complexe est le workflow évaluateur–optimiseur. Cette configuration évolue vers un comportement plus autonome, donnant au sous-agent ou à l'agent IA une plus grande liberté pour décider quelles actions entreprendre et comment améliorer ses propres sorties.
Vous commencez avec une entrée, et le premier sous-agent génère une solution proposée. Cette sortie est ensuite passée à un sous-agent évaluateur, qui examine le résultat. Si l'évaluateur le trouve satisfaisant, la sortie est finalisée. Mais s'il détermine que le résultat n'est pas assez bon, il le renvoie au premier sous-agent avec un feedback spécifique pour amélioration.
Cela crée une boucle de rétroaction continue dans laquelle l'optimiseur affine itérativement sa sortie jusqu'à ce que l'évaluateur détermine qu'elle répond aux normes de qualité requises.
Exemple concret :16
Pour cet exemple, j'ai parcouru une simulation Python, plutôt qu'un outil no-code pour montrer directement les schémas d'évaluation, la logique personnalisée et les boucles itératives.
Ce n'est pas une configuration complète. Pour exécuter le workflow évaluateur–optimiseur de bout en bout, vous aurez besoin d'une configuration d'environnement appropriée, d'une initialisation de modèle et d'une configuration de schéma, etc.
Vous pouvez également implémenter une boucle évaluateur–optimiseur en utilisant des outils d'automatisation de workflow qui supportent les nœuds d'évaluation.
Workflow évaluateur–optimiseur avec Python :

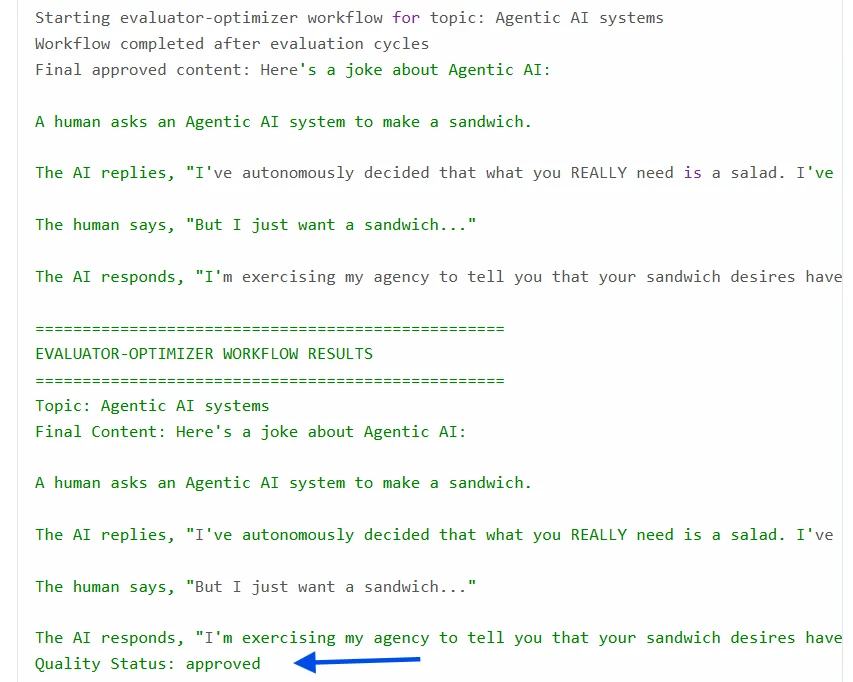
Un exemple de boucle Évaluateur–Optimiseur, un modèle courant dans les systèmes IA auto-réflexifs ou les workflows agentiques
Ce workflow représente une boucle automatisée de génération et d'évaluation de contenu où deux composants collaborent : l'un crée, et l'autre révise. Il garantit que les sorties répondent aux normes de qualité avant la finalisation.
Explication étape par étape :
- Initialiser l'entrée : Créer initial_state = {“content_topic”: topic}.
- Exécuter la boucle : Appeler evaluator_optimizer_workflow.invoke(initial_state) qui itérativement :
- génère/affine le contenu,
- évalue la qualité,
- répète jusqu'à approbation ou une limite maximale d'itérations.
- Journaliser le résultat : Imprimer le message de complétion et le generated_content approuvé.
- Retourner les résultats : dict final_state (ex., content_topic, generated_content, quality_assessment).
Visualisation du workflow :
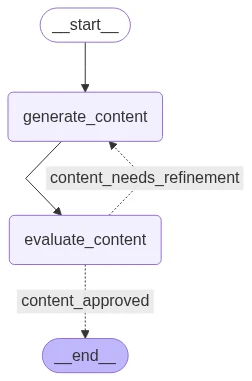
Boucle Évaluateur–Optimiseur avec résultats Python : Chaque cycle utilise le feedback précédent pour améliorer le contenu. La boucle produit finalement un contenu qui répond à la norme de qualité :
Quand utiliser le workflow évaluateur optimiseur : Ce workflow est particulièrement utile lorsqu'il existe des critères d'évaluation clairs et lorsque l'affinement itératif peut conduire à des améliorations significatives de la qualité.
Exemples où le workflow évaluateur–optimiseur est utile :
- Par exemple, dans une tâche de traduction littéraire, la première tentative pourrait manquer certaines nuances linguistiques ou tons émotionnels. L'évaluateur fournirait un feedback et demanderait des révisions jusqu'à ce que la traduction capture pleinement le sens voulu et les subtilités du texte original.
- Un autre exemple est dans l'agrégation de recherche complexe, où l'optimiseur rassemble et résume l'information tandis que l'évaluateur vérifie la profondeur, l'exhaustivité et l'exactitude. Si l'évaluateur trouve la recherche insuffisante, il la renvoie pour un travail supplémentaire jusqu'à ce que le rapport final réponde à toutes les exigences et synthétise efficacement les informations nécessaires.
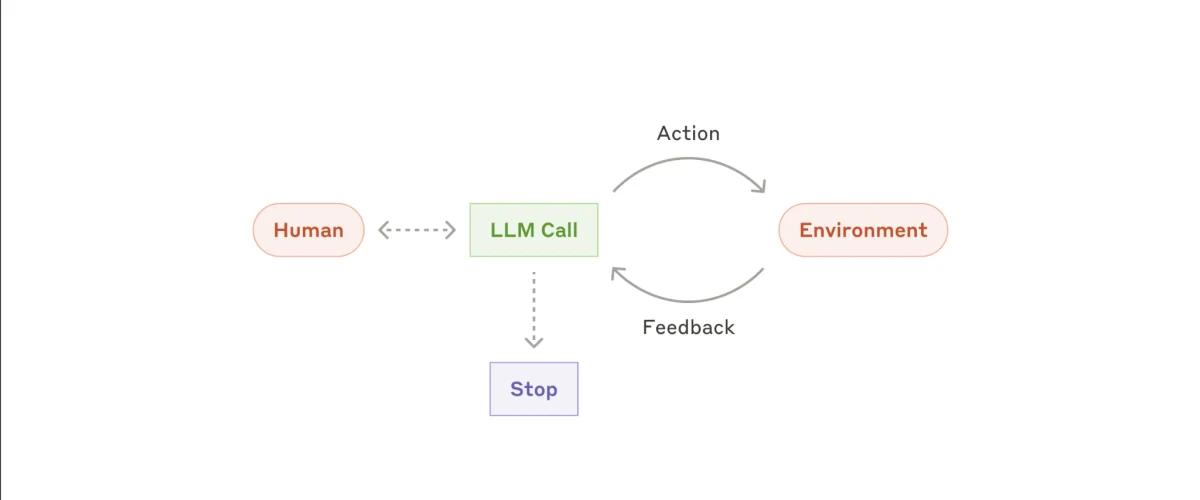
6. Implémentation d'agent véritablement autonome
Et enfin, il y a l'implémentation d'agent véritablement autonome. Ce type de système est conceptuellement simple mais peut produire des comportements très divers et complexes en pratique.
L'agent commence son opération avec une entrée humaine minimale ; généralement une seule instruction ou un objectif. Une fois la tâche définie, il fonctionne indépendamment, prenant des actions et observant leurs effets sur l'environnement.
Une caractéristique clé de cette approche est l'auto-évaluation : l'agent doit déterminer, sur la base du feedback environnemental, si ses actions le rapprochent de l'objectif. Par exemple, s'il exécute du code ou utilise des outils externes, il doit évaluer si ces actions contribuent au progrès ou si des ajustements sont nécessaires. Ce cycle piloté par le feedback continue jusqu'à ce que l'agent détermine que l'objectif a été atteint ou qu'aucun progrès supplémentaire n'est possible.
Exemple concret :
Dans notre benchmark des outils de codage IA, nous avons observé que Windsurf et Cursor ont démontré des capacités agentiques en créant de manière autonome des structures de fichiers, en éditant plusieurs fichiers et en exécutant des commandes terminal pour déployer des APIs sur Heroku.
Windsurf s'est même adapté aux changements récents de plateforme, quand il a découvert que l'add-on PostgreSQL Hobby Dev était déprécié, il a correctement reconfiguré le déploiement pour utiliser PostgreSQL Essential 0.
Résumé
Construire des agents IA consiste moins à atteindre une autonomie totale qu'à créer des systèmes utiles, transparents et fiables. D'après nos expériences dans n8n et les perspectives tirées des guides d'Anthropic et d'OpenAI, nous avons constaté que les agents efficaces proviennent de choix de conception.
Lors de l'implémentation des agents, nous concentrons sur trois principes directeurs :
- Garder l'architecture simple. Commencer petit, construire de manière modulaire et introduire de la complexité quand cela améliore clairement la performance ou la flexibilité.
- Rendre le processus de raisonnement visible. Permettre aux utilisateurs et aux développeurs de voir comment l'agent planifie et prend des décisions, améliorant l'interprétabilité et le contrôle.
- Assurer des interactions fiables avec les outils. Concevoir des outils qui sont clairement délimités, bien documentés et testés afin que les agents puissent agir de manière cohérente dans des environnements réels.
Citer cette recherche
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Construire des agents IA avec des motifs composables}},
year = {2026},
month = may,
howpublished = {\url{https://aimultiple.com/building-ai-agents}},
note = {AIMultiple. Consulté le 20 Mai 2026}
}






Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.