Top 3 Générateurs de Documents Synthétiques Comparés
Les générateurs de documents synthétiques créent des images de documents annotées et réalistes qui aident à entraîner et à évaluer des modèles d'apprentissage automatique sans dépendre de grands ensembles de données étiquetés manuellement.
Nous comparons 3 générateurs de documents synthétiques, Genalog, DocCreator et Tonic Textual, en créant plus de 2 500 documents synthétiques, en comparant leur efficacité dans des mises en page réalistes, des données numériques précises et des ensembles de données d'entraînement pour des tâches d'analyse de documents.
Résultats du benchmark de génération de documents
Les résultats montrent que
- Genalog et DocCreator sont des performers solides en termes d'utilité et de fidélité, Genalog étant légèrement meilleur pour la précision numérique.
- Tonic Textual excelle dans le réalisme de la mise en page visuelle mais est en retrait dans d'autres domaines, ce qui le rend plus adapté aux tâches nécessitant des documents réalistes.
Pour plus d'informations sur les métriques, lisez la méthodologie du benchmark.
- L'utilité mesure la performance des modèles entraînés sur des données synthétiques sur de vrais documents.
- La fidélité de la mise en page mesure dans quelle mesure l'arrangement spatial des éléments dans les documents synthétiques correspond à celui des documents réels.
- La fidélité numérique vérifie si les valeurs numériques dans les documents synthétiques ressemblent aux données réelles.
Commentaire sur les résultats : Pour mieux comprendre les différences de performance, le benchmark a également été réalisé en utilisant l'ensemble d'entraînement au lieu de l'ensemble de test séparé. Cette évaluation secondaire visait à déterminer si fournir aux modèles du matériel d'entraînement améliorerait leur capacité à reproduire des sorties structurées et numériquement précises.
Les résultats montrent que, même lorsqu'ils sont évalués sur les données d'entraînement, les modèles ont obtenu des scores légèrement plus élevés. Cela indique que les résultats reflètent la capacité des outils à gérer la tâche elle-même. Les résultats modérés sont probablement influencés par les limites de la qualité de l'OCR et la capacité du modèle entraîné, plutôt que par la procédure de benchmark elle-même.
Genalog
Genalog a été le plus performant dans l'ensemble. Ses documents synthétiques étaient très efficaces pour l'entraînement des modèles et maintenaient un bon équilibre entre des éléments de mise en page réalistes et une précision numérique. Les documents générés reflétaient étroitement la structure et l'espacement des vrais formulaires et reçus, les rendant adaptés à diverses tâches d'analyse de documents.
DocCreator
DocCreator a également produit des résultats de haute qualité. Les documents de ce générateur étaient presque aussi utiles pour l'entraînement que ceux de Genalog. Les mises en page étaient réalistes et les documents synthétiques préservaient les propriétés statistiques des nombres. La force de DocCreator réside dans la combinaison de la génération de mises en page diversifiées avec ses modèles de dégradation, rendant les sorties visuellement similaires aux documents réels numérisés.
Tonic Textual
Tonic Textual a donné des résultats mitigés. Bien que ce générateur de documents synthétiques ait produit des mises en page très propres et cohérentes, les documents étaient moins efficaces pour l'entraînement des modèles. De plus, les nombres synthétiques n'étaient pas toujours statistiquement similaires aux données réelles. Cela suggère que Tonic Textual est mieux adapté aux tâches axées sur l'apparence des documents ou le remplacement de PII respectueux de la vie privée plutôt qu'à un entraînement à grande échelle pour des tâches de structure de mise en page et d'extraction d'informations.
En mars 2026, Tonic Textual a remplacé son composant de liaison d'entités d'un modèle basé sur un LLM par un modèle basé sur BERT pour améliorer le débit.1 La même version (v391) a également ajouté un filtrage et un tri améliorés sur la page Datasets.2
Aperçu général
Genalog est l'outil le mieux équilibré, offrant à la fois des mises en page réalistes et des nombres précis.
DocCreator est solide pour les mises en page complexes et diversifiées et la dégradation des documents, avec de légères imprécisions numériques.
Tonic Textual est idéal pour les tâches axées sur la mise en page mais pas pour les tâches nécessitant des données numériques précises.
Aperçu de la méthodologie
Métriques d'évaluation
Chaque ensemble de données généré a été noté par rapport aux données originales en utilisant les métriques suivantes :
Score d'utilité
(Score FIE) : Un score compris entre 0 et 1, où plus élevé est mieux. Il est défini par le score F1 du modèle LayoutLMv3 entraîné sur les données synthétiques lorsqu'il est évalué sur l'ensemble de test réel. Un score élevé indique que les données synthétiques sont un substitut très efficace aux données réelles.
Scores de fidélité
Ces métriques mesurent à quel point les documents synthétiques ressemblent aux documents réels.
- Fidélité de la mise en page (Score EMD) : La distance du transporteur de terre (dEMD) mesure la différence entre la distribution des points centraux des boîtes englobantes dans les documents réels par rapport aux documents synthétiques. C'est une valeur de 0 à 1, où plus bas est mieux. Un score faible signifie que les éléments de mise en page spatiale sont bien préservés.
- Fidélité numérique (Distance K-S) : La distance de Kolmogorov-Smirnov (DKS) mesure la différence maximale entre les fonctions de distribution cumulative (CDF) des valeurs numériques (par exemple, prix, quantités) dans les données réelles et synthétiques. Elle varie de 0 à 1, où plus bas est mieux. Un score faible signifie que le générateur reproduit avec précision les propriétés statistiques des nombres.
Toutes les métriques ont été normalisées lors du calcul.
Ensembles de données
FUNSD : Une collection de 199 formulaires numérisés caractérisés par du texte bruyant, des mises en page complexes et diversifiées et des annotations manuscrites. Il a été téléchargé plus de 1 500 fois le mois dernier. Cela teste la capacité d'un générateur à gérer des données non structurées et imparfaites. 3
- Nous divisons l'échantillon en deux : 80 % des données sont utilisées pour entraîner le modèle, tandis que les 20 % restants sont réservés aux tests après l'entraînement.
- Chaque outil a produit entre trois et six documents synthétiques pour chaque original, soit un total de plus de 2 500 documents synthétiques.
Évaluation des tâches
Pour mesurer l'utilité, un modèle LayoutLMv3 populaire avec 22K étoiles GitHub et plus de 750K téléchargements a été entraîné sur les données synthétiques générées par chaque outil de générateur de documents synthétiques. 4
La performance de ce modèle a ensuite été évaluée sur un ensemble de test retenu de documents réels provenant des ensembles de données d'origine. Cela mesure directement l'utilité des données synthétiques pour une tâche réelle.
Outils de génération synthétique
Genalog
Une bibliothèque Python open source de Microsoft pour générer des images de documents synthétiques avec du bruit synthétique. Elle fonctionne en prenant des modèles de texte + mise en page (écrits en HTML + CSS) et en les rendant via WeasyPrint, puis en appliquant des effets de dégradation (flou, bavures, bruit sel et poivre, opérations morphologiques).5
DocCreator
Un outil multiplateforme open source pour générer des images de documents synthétiques avec une vérité terrain associée. Il a été largement utilisé dans la recherche sur l'analyse et la reconnaissance d'images de documents (DIAR).6 ,7
Tonic Textual
Une solution de masquage et de synthèse dans des formats de documents réels (PDF, Word). Il prétend scanner des documents non structurés, identifier des entités nommées (par exemple, PII), les masquer ou les remplacer par des valeurs synthétiques, et produire des documents anonymisés dans des formats similaires.
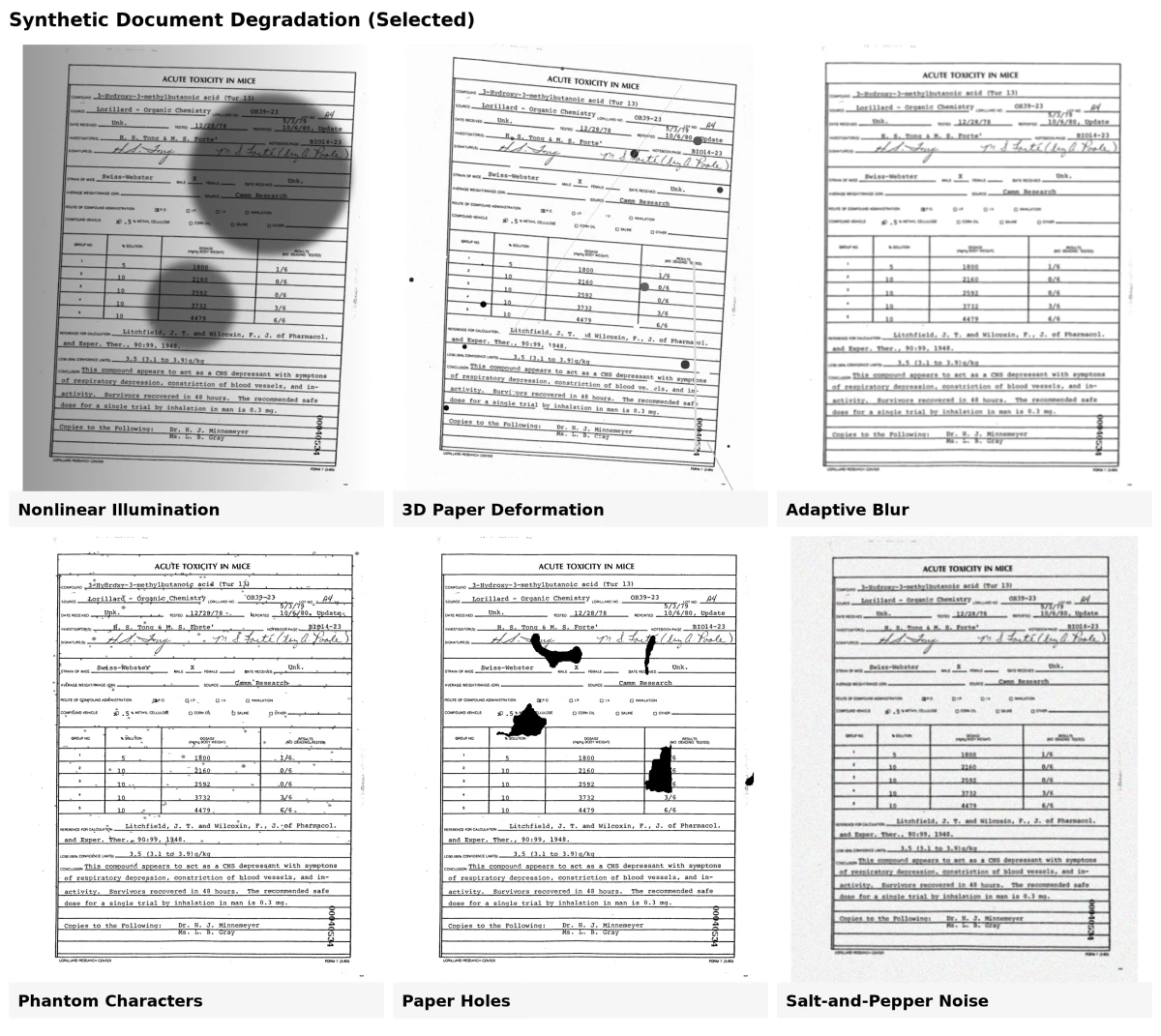
8 Méthodes de dégradation de documents synthétiques
La génération de documents synthétiques inclut souvent l'ajout de défauts réalistes pour faire ressembler les données artificielles aux documents du monde réel. Ces défauts, ou modèles de dégradation, aident à entraîner des modèles qui fonctionnent mieux sur des documents bruyants, anciens ou numérisés. Ces outils appliquent plusieurs transformations physiques et visuelles pour simuler des imperfections courantes des documents.8
1. Dégradation de l'encre
Ce modèle simule le fanage, les taches ou les traînées causés par le vieillissement ou une impression de mauvaise qualité. Il ajoute de petites taches d'encre ou supprime des parties de lettres pour imiter la décomposition réelle de l'encre.
2. Caractères fantômes
Les anciens outils d'impression laissaient souvent de faibles contours ou des marques « fantômes » autour des lettres. Le modèle de caractère fantôme recrée ceux-ci en insérant des défauts extraits de vrais numérisations entre les caractères imprimés.
3. Trous de papier
Des trous de différentes formes et tailles sont ajoutés aléatoirement aux documents, reproduisant des déchirures ou des marques de poinçon observées sur des papiers usés.
4. Transpercement
Cet effet imite l'encre qui traverse de l'autre côté de la page. Il utilise à la fois les images avant et arrière d'un document pour recréer la façon dont l'encre se transfère partiellement à travers le papier.
5. Flou adaptatif
La numérisation ou la photographie de documents crée souvent un léger flou. Ce modèle compare de vrais exemples flous et applique un flou similaire en utilisant des filtres gaussiens, gardant le résultat subtil et réaliste.
6. Déformation 3D du papier
Les documents peuvent se plier, se replier ou se courber lors de la numérisation ou de la photographie. En utilisant des maillages 3D de vrais papiers, ce modèle recrée ces formes et effets d'éclairage, aidant à entraîner des modèles pour l'analyse de documents basée sur la caméra.
7. Éclairage non linéaire
Un éclairage inégal lors de la numérisation peut rendre un côté d'un document plus sombre. Ce modèle ajuste la luminosité en fonction des angles de lumière simulés et de la courbure de la page, reproduisant l'effet d'un mauvais éclairage.
8. Bruit sel et poivre
Ajoute des pixels noirs et blancs aléatoires pour simuler la poussière, la texture du papier ou le bruit du capteur de numérisation. Cet effet « sel et poivre » aide à créer l'apparence granuleuse des numérisations numériques anciennes ou de mauvaise qualité.
Génération de documents synthétiques comme solution aux défis de l'analyse de mise en page
Le défi de l'analyse de mise en page
Comprendre la structure des documents est plus difficile que de lire le texte. Les outils OCR peuvent extraire des mots, mais ils n'expliquent pas le rôle de chaque bloc, tel que les titres, les tableaux ou les figures.
Pour faire face à ce défi, des méthodes ont été développées :
Les méthodes précoces d'analyse de mise en page étaient basées sur des règles. Elles reposaient sur des règles géométriques et une analyse de texture pour diviser les pages en blocs. Bien qu'utiles, ces approches nécessitaient un réglage manuel intensif et ne généralisaient pas bien.
Les approches d'apprentissage automatique comme les machines à vecteurs de support (SVM) et les modèles de mélange gaussien (GMM) ont amélioré cela en apprenant à partir des données.9 Cependant, ils dépendaient toujours de caractéristiques conçues à la main et luttaient face à la diversité des documents du monde réel.
L'apprentissage profond a transformé le domaine. Les réseaux de neurones convolutifs (CNN) ont rendu possible de traiter la reconnaissance de mise en page comme une détection d'objets, identifiant les tableaux, les figures ou les formules de la même manière que les modèles détectent les objets dans les images naturelles.10 Certains modèles combinent également des caractéristiques de texte et d'image pour des résultats plus précis.
Le défi de l'apprentissage profond : nécessite de grands ensembles de données étiquetés pour l'entraînement.
Données synthétiques comme solution : Le processus de génération de documents synthétiques offre une façon évolutive de créer des données d'entraînement annotées sans le coût de l'étiquetage manuel.
Les modèles génératifs apportent maintenant des possibilités plus avancées. Les autoencodeurs variationnels (VAE), les modèles basés sur l'attention et les GAN peuvent apprendre les modèles structurels des documents et produire de nouvelles mises en page réalistes.11
Différences clés entre les générateurs de documents synthétiques
Les trois générateurs de documents synthétiques comparés diffèrent par leur objectif, la qualité de la sortie et l'utilisabilité :
- Genalog : Le mieux équilibré pour les mises en page réalistes et la précision numérique. Son flux de travail basé sur Python avec des modèles HTML/CSS et des modèles de dégradation le rend idéal pour l'entraînement de modèles d'apprentissage automatique dans diverses tâches d'analyse de documents.
- DocCreator : Solide pour générer des documents visuellement complexes et dégradés, préservant la diversité de la mise en page. Légèrement moins précis numériquement que Genalog, mais efficace pour les tâches nécessitant une simulation réaliste de documents numérisés.
- Tonic Textual : Excellent pour des mises en page propres et visuellement cohérentes et une synthèse de données respectueuse de la vie privée. Moins adapté à la précision numérique ou aux ensembles de données d'entraînement complets, le rendant meilleur pour les tâches axées sur la mise en page ou le remplacement de PII.
Ces différences reflètent leurs approches principales : Genalog équilibre le réalisme et la fidélité des données, DocCreator met l'accent sur la variété de la mise en page et la dégradation des documents, et Tonic Textual privilégie l'apparence et la vie privée. Cela aide les utilisateurs à sélectionner le bon outil en fonction de la priorité : efficacité de l'entraînement, réalisme de la mise en page ou anonymisation des données.
Autres générateurs de documents synthétiques couramment utilisés
YData SDK : Offre un générateur de documents synthétiques capable de produire des documents synthétiques de haute qualité au format PDF, DOCX ou HTML, souvent utilisé pour contourner les obstacles de conformité en matière de confidentialité.12
DoGe : Un outil open source spécifiquement conçu pour synthétiser des numérisations de documents réalistes comportant du texte significatif, des titres et des tableaux pour l'entraînement de Document AI.13
DocXPand : Spécialisé dans la génération de documents d'identité (passeports, cartes d'identité) basés sur les normes ISO, remplissant des modèles avec de fausses informations et des visages générés par IA.14
Lectures complémentaires
- Benchmark et meilleures pratiques de génération de données synthétiques
- Top 25 des cas d'utilisation des données synthétiques
- Utilisateurs synthétiques expliqués : Top 7 des outils de recherche utilisateur IA
Citez ce benchmark
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{phd2026,
author = {PhD., Ezgi Arslan,},
title = {{Top 3 Générateurs de Documents Synthétiques Comparés}},
year = {2026},
month = mar,
howpublished = {\url{https://aimultiple.com/synthetic-document-generator}},
note = {AIMultiple. Consulté le 18 Mars 2026}
}



Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.