Facture OCR Benchmark: Précision d'extraction des LLMs vs OCRs
Le traitement des factures est une opération commerciale critique mais laborieuse qui nécessite traditionnellement l'extraction de données manuelle et leur saisie dans les systèmes comptables. Cette approche manuelle prend du temps et est sujette aux erreurs humaines. Pour évaluer des alternatives automatisées, nous avons mené une analyse comparative des principales solutions de traitement de documents et des LLMs :
- Amazon Textract API
- Claude Sonnet 3.5
- Docsumo
- Google Document IA
- Microsoft Azure Document Intelligence
- Rossum
Notre étude a évalué les capacités de ces outils à extraire avec précision les données de divers formats et qualités de factures, dans le but de quantifier leur efficacité en tant qu'alternatives au traitement manuel.
Résultats du benchmark
Nous avons évalué les performances de traitement des factures pour des factures de qualité et de contraste variables. Alors que tous les outils ont démontré de bonnes performances avec des images de haute qualité, leur précision a considérablement diminué lors du traitement de documents de moindre qualité. Parmi les outils testés, Claude Sonnet 3.5 a affiché la meilleure précision globale et la meilleure résilience sur l'ensemble du spectre des qualités de documents.
Méthodologie
Mesure : Notre méthodologie d'évaluation s'est concentrée sur la précision de l'extraction de paires clé-valeur. Chaque champ extrait a été évalué à l'aide d'une classification binaire : extraction correcte ou extraction incorrecte/manquante. La mesure de la précision a été calculée à l'aide de la formule suivante :
Précision = (Nombre de paires clé-valeur correctement extraites) / (Nombre total de paires clé-valeur)
Cette méthodologie a permis une comparaison objective des performances d'extraction entre différents outils et types de documents.
Taille de l'échantillon : Trouver des données de factures est difficile car elles contiennent des informations personnelles telles que des e-mails et des noms. Nous avons utilisé plus de 400 paires clé-valeur provenant de 20 échantillons de factures accessibles au public.
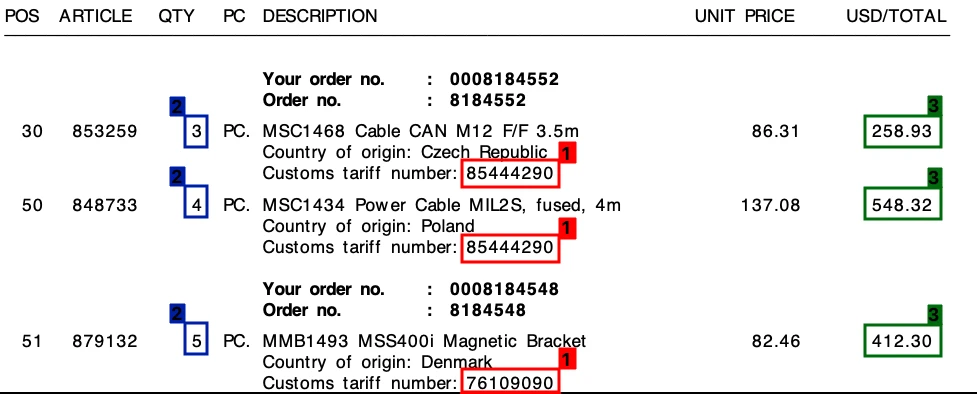
Échantillons : Bien que toutes les solutions aient traité correctement les images de haute qualité, la qualité d'extraction a diminué pour des images comme celles-ci :
Fine-tuning : Bien que les produits que nous avons essayés aient réussi à trouver les montants totaux, ils ont eu des difficultés à extraire les détails des prix. Il est possible d'obtenir de meilleurs résultats en affinant certains produits. Dans quelques produits, les utilisateurs peuvent cliquer sur une valeur de l'image pour corriger la sortie du modèle.
Pour être équitable envers tous les fournisseurs, nous n'avons effectué aucun fine-tuning. Avec le fine-tuning, tous les fournisseurs devraient être en mesure d'atteindre des taux de réussite plus élevés la deuxième fois qu'ils traitent ces documents. Cependant, notre objectif dans ce benchmark est axé sur les opérations autonomes, qui exigent que les modèles produisent des résultats corrects et fiables à partir de documents qu'ils n'ont jamais vus auparavant.
Calendrier : Tous les tests ont été réalisés en décembre 2024.
Prochaines étapes
Augmentation du nombre de participants : Étant donné que cette étude donne un aperçu des capacités actuelles de traitement des factures via les grands modèles de langage (LLMs), les technologies OCR et les outils spécialisés de traitement des factures, nous prévoyons d'élargir notre analyse en intégrant d'autres LLMs de pointe afin de fournir un benchmark plus complet des solutions automatisées de traitement des factures.
Augmentation de la taille et de la diversité de l'échantillon.
Qu'est-ce que l'OCR de factures ?
L'analyse des factures utilise des outils automatisés tels que le NLP, le NLU, l'OCR et d'autres technologies d'extraction de données pour extraire les données des factures dans divers formats, tels que les PDF et les images.
Un analyseur de factures est un programme logiciel qui extrait des informations telles que
Nom du fournisseur
Numéro de facture
Montant dû
et les saisit dans un format lisible par machine. Ces données peuvent être utilisées pour de multiples fonctions, telles que l'automatisation des comptes fournisseurs, la clôture comptable de fin de mois et la gestion des factures.
Le logiciel d'analyse est généralement intégré à un système de traitement des factures qui automatise l'ensemble du processus, de la réception d'une facture au paiement.
Comment fonctionnent les outils d'OCR de factures ?
Les documents écrits dans un certain langage de balisage sont lus et traités par des analyseurs. Ils décomposent le document en éléments plus petits, appelés tokens, et examinent chaque token pour déterminer ce qu'il signifie et où il se situe dans la structure du document.
Pour ce faire, les analyseurs doivent connaître en profondeur la grammaire du langage de balisage en question. Cela leur permet de reconnaître chaque token et de déterminer les connexions exactes entre eux.
Le processus comprend 5 étapes :
1. Saisie
Les factures peuvent être reçues dans divers formats, notamment papier, e-mail ou formats électroniques tels que PDF ou XML. Le logiciel d'analyse de factures accepte généralement ces factures comme entrée.
2. Reconnaissance optique de caractères (OCR)
Si la facture est au format papier numérisé ou image, l'analyseur utilise la technologie OCR pour extraire le texte de l'image. Cela permet à l'analyseur d'accéder aux données contenues dans la facture.
Certaines solutions d'analyse de factures utilisent des outils d'OCR basés sur l'IA ou des LLMs qui extraient automatiquement les informations des PDF, des photos et des documents numérisés sans avoir besoin de nouvelles règles ou de modèles. Cela est dû au fait que l'IA peut gérer des documents semi-structurés et inconnus et s'améliorer avec le temps. Les informations extraites peuvent être personnalisées pour n'inclure que des tableaux ou des entrées de données spécifiques.
3. Extraction de données
L'analyseur extrait ensuite des informations spécifiques de la facture, telles que le nom du fournisseur, le numéro de facture, la date et les détails des articles. Cela est généralement réalisé en utilisant une combinaison de reconnaissance de formes et d'algorithmes d'apprentissage automatique.
Certains logiciels d'analyse de factures ont la capacité d'extraire des informations clés telles que la date de facturation, le numéro, les numéros d'identification fiscale et divers totaux en utilisant des filtres prédéfinis :
Certains outils d'analyse offrent la possibilité d'extraire les informations des lignes de factures ayant un format cohérent en créant un analyseur de document distinct pour chaque fournisseur ou partenaire commercial spécifique :
4. Validation des données
Une fois les données extraites, l'analyseur valide les informations pour s'assurer qu'elles sont exactes et complètes. Cela peut inclure la vérification que la date est au bon format, que le nom du fournisseur correspond à une liste prédéfinie de fournisseurs, ou que les détails des articles correspondent au format attendu.
5. Sortie des données
Les données extraites et validées sont ensuite produites dans un format pouvant être facilement importé dans le système comptable ou ERP de l'utilisateur. Cela peut se présenter sous la forme d'un fichier CSV, d'un enregistrement de base de données ou directement dans un logiciel de comptabilité.
Défis de l'extraction manuelle des données de factures
L'extraction manuelle des données des factures et leur saisie dans un système peut être difficile pour les entreprises, car il existe plusieurs complexités :
Erreur humaine
Les factures peuvent contenir une grande quantité de données, et la saisie manuelle augmente le risque d'erreurs, telles que les fautes de frappe, la transposition de chiffres et les saisies incorrectes. Les inexactitudes dans la saisie des données sont responsables d'environ 600 milliards de dollars de pertes annuelles.1 Les processus tels que la gestion des comptes fournisseurs nécessitent une exportation correcte des données à partir des documents financiers.
Chronophage
En moyenne, il faut 17 jours, soit environ 75% d'un mois, pour traiter manuellement une seule facture.2
De nombreuses informations importantes figurent sur les factures, et elles sont toutes présentées sous forme de paires clé-valeur où chaque élément sert à la fois de clé et de valeur. Le processus d'extraction manuelle de ces paires prend du temps et nécessite plusieurs inspections pour garantir l'exactitude. Même certains algorithmes d'OCR ont du mal à détecter les valeurs extraites sans contexte. Le traitement automatisé des factures peut aider les employés à se concentrer sur des tâches plus complexes.
Manque de normalisation
Les factures de différents fournisseurs peuvent avoir des formats différents. Chaque facture est générée avec un format unique qui peut poser des difficultés lors du traitement et de l'interprétation de ces modèles. Les documents, tels que les e-mails, le papier et les PDF, peuvent passer par de nombreux enregistrements numériques et papier avant d'être approuvés pour le paiement, ce qui rend l'extraction manuelle des données difficile et sujette aux erreurs.
Inefficacité des processus
Le traitement manuel des factures, qui engendre un coût moyen de près de 23 $ par facture3 , peut être à la fois chronophage et coûteux, conduisant à un processus inefficace et répétitif.
Risque de perte de données
Il existe un risque de perte de données si les factures sont perdues ou endommagées ou si les données ne sont pas saisies correctement dans le système.
Les logiciels d'OCR rencontrent souvent des difficultés pour extraire les lignes des factures également. En effet, les tableaux de transactions peuvent manquer de lignes horizontales ou verticales, ce qui rend difficile pour le traitement de factures par OCR d'établir un contexte pour les éléments extraits. Les factures numériques ou les images de factures collectées peuvent être utilisées dans ce processus.
Comment choisir votre fournisseur de traitement des factures ?
1. Fournit une solution conforme aux politiques de confidentialité des données de votre entreprise.
La politique de confidentialité des données de votre entreprise peut être un frein à l'utilisation d'APIs externes telles qu'Amazon AWS Textract. La plupart des fournisseurs proposent des solutions sur site, de sorte que les politiques de confidentialité des données n'empêcheraient pas nécessairement votre entreprise d'utiliser une solution de capture de factures. Le flux de travail des comptes fournisseurs doit être traité avec une attention particulière car il implique fréquemment des informations commerciales et financières confidentielles.
2. Fournit une structure de données cohérente quel que soit le texte sur les documents.
Il existe deux façons de fonctionner pour les entreprises de capture de factures basées sur l'apprentissage profond. Des entreprises comme Textract renvoient des paires clé-valeur. Ainsi, par exemple, si une facture appelle le montant total « Montant brut », une autre l'appelle « Montant total », et une autre facture allemande l'appelle « Summe », Textract vous donne les données dans 3 structures différentes pour ces 3 documents.
Dans l'un, vous avez une paire clé-valeur avec la clé « Montant brut », dans un autre « Montant total » et dans la facture allemande, vous obtenez « Summe ». D'autres fournisseurs ont conçu des structures de données cohérentes qui fonctionnent pour toutes les factures. Dans les 3 scénarios, vous obtiendriez « Montant total », qui est la clé qu'ils utilisent dans leur fichier de sortie. Cela facilite l'analyse et le traitement car vous n'avez pas à gérer de nombreux formats de données structurés différents.
3. Demandez les taux de faux positifs et d'extraction manuelle des données
Exécutez ensuite un projet de preuve de concept (PoC) pour voir les taux réels sur les factures reçues par votre entreprise.
Faux positifs sont des factures qui sont auto-traitées mais comportent des erreurs d'extraction de données. Ceux-ci sont difficiles à identifier et peuvent perturber les opérations. Par exemple, une extraction incorrecte des montants des paiements serait problématique. La minimisation de ce phénomène doit être la priorité absolue.
Extraction manuelle des données est nécessaire lorsque le système d'extraction automatique des données a une confiance limitée dans son résultat. Cela peut être dû à un format de facture différent, une mauvaise qualité d'image ou une erreur d'impression du fournisseur. Il est également important de minimiser cela, mais il y a un compromis entre les faux positifs et l'extraction manuelle des données. Avoir plus d'extraction manuelle des données peut être préférable à avoir des faux positifs.
Il s'agit du premier benchmark quantitatif que nous avons vu dans ce domaine et nous suivrons une méthodologie similaire pour préparer notre propre benchmark.
4. Utilisez un PoC pour mesurer le taux d'automatisation potentiel
Cela dépend du nombre de champs que vous prévoyez de capturer à partir des documents. Un ensemble typique d'environ 10 champs, comprenant des éléments tels que l'identifiant de bon de commande, le nom du fournisseur, etc., peut permettre la saisie de données dans l'ERP et les paiements.
Les fournisseurs de bonnes pratiques atteignent environ 80% de STP en extrayant tous ces quelque 10 champs avec presque aucune erreur environ 80% du temps. Bien qu'il puisse y avoir des erreurs de temps en temps, la vérification manuelle des paiements les plus importants peut garantir qu'aucun paiement erroné significatif ne passe à travers les mailles du filet.
5. Demandez les options de traitement avancées proposées par le fournisseur
L'extraction est la première étape de la collecte de données ; elle doit être suivie du traitement des données dans la plupart des cas. Par exemple, les factures doivent être vérifiées pour la conformité à la TVA (par exemple, les factures nationales sans TVA doivent expliquer pourquoi la TVA est exclue), et le non-respect de cette obligation pourrait entraîner des amendes importantes pour l'entreprise, selon le pays.
6. Demandez comment la solution apprend à connaître les nouvelles factures
Les meilleures solutions disposent d'une interface permettant à votre équipe d'aider à guider la solution. Lorsqu'un employé de votre entreprise sélectionne les paires clé-valeur, la solution de capture de factures en prend note afin d'être plus confiante lors du traitement d'une facture similaire la prochaine fois.
7. Évaluez la facilité d'utilisation de leur solution de saisie manuelle des données
Elle sera utilisée par le personnel du back-office de votre entreprise lorsqu'il traite manuellement les factures qui ne peuvent pas être traitées automatiquement avec confiance.
Au-delà de cela, les meilleures questions d'approvisionnement ont du sens. Par exemple :
- Quelle est l'adoption de leur solution ? Ont-ils des clients du Fortune 500 ?
- Leurs clients sont-ils satisfaits de leur solution et de leur support ? Il pourrait être bon d'interroger une connaissance d'une entreprise qui utilise déjà leur solution. Étant donné que l'automatisation des factures n'est pas une solution qui améliorerait le marketing ou les ventes d'une entreprise, même les concurrents pourraient partager entre eux leur point de vue sur les solutions d'automatisation des factures.
- Quelles sont les options pour intégrer la solution dans les systèmes de votre entreprise (par exemple, ERP) ? Le service informatique est-il d'accord avec l'approche d'intégration ?
- Quel est leur coût total de possession (TCO) ? Différentes solutions utilisent différentes unités de tarification (par exemple, prix par page ou prix par document), ce qui rend cette comparaison difficile. Cependant, en utilisant un échantillon de vos archives, vous pourriez avoir une estimation du coût.
Pour en savoir plus
Citez ce benchmark
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Facture OCR Benchmark: Précision d'extraction des LLMs vs OCRs}},
year = {2026},
month = jan,
howpublished = {\url{https://aimultiple.com/invoice-ocr}},
note = {AIMultiple. Consulté le 22 Janvier 2026}
}

Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.