Comparer les modèles relationnels fondamentaux
Nous avons évalué SAP-RPT-1-OSS par rapport au boosting gradient (LightGBM, CatBoost) sur 17 jeux de données tabulaires couvrant le spectre sémantique-numérique, les petites tables à forte sémantique, les jeux de données commerciaux mixtes et les grands jeux de données numériques à faible sémantique.
Notre objectif est de mesurer où les a priori sémantiques pré-entraînés d’un LLM relationnel peuvent offrir des avantages par rapport aux modèles d’arbres traditionnels et où ils rencontrent des difficultés en termes d’échelle ou de structure à faible sémantique.
SAP-RPT-1-OSS vs. Boosting gradient : Résultats du benchmark
- Taux de réussite : Représente le score normalisé moyen (0,0 à 1,0). Une barre plus élevée indique que le modèle est plus proche de la performance optimale possible pour les jeux de données de cette catégorie.
- 100 – 500 lignes (3 jeux de données) :
- Inclus : wine (178), sonar (208), vote (435).
- Résultat : SAP obtient les meilleurs résultats sur 2 des 3 jeux de données. Il atteint les scores les plus élevés sur wine et sonar, ce qui suggère que les a priori du LLM peuvent être bénéfiques lorsque les données d’entraînement sont rares. Cependant, CatBoost remporte une victoire étroite sur le jeu de données vote (moins de 0,1 %), indiquant que les modèles d’arbres restent très compétitifs même à petite échelle.
- 501 – 1 000 lignes (3 jeux de données) :
- Inclus : cylinder_bands (540), breast_cancer (569), credit_g (1 000).
- Résultat : SAP obtient les meilleurs résultats sur les 3 jeux de données. Sur cylinder_bands, SAP surpasse LightGBM de 5,5 %, probablement grâce à une meilleure gestion des descriptions sémantiques des défauts industriels, bien que des études d’ablation supplémentaires soient nécessaires pour confirmer ce mécanisme.
- 1 000 – 10 000 lignes (5 jeux de données) :
- Inclus : titanic (1,3K), car_evaluation (1,7K), spambase (4,6K), compas (5,2K), employee_salaries (9,2K).
- Résultat : SAP obtient les meilleurs résultats sur 4 des 5 jeux de données, performant particulièrement bien sur des tâches riches en texte comme spambase et titanic. Cependant, CatBoost surpasse nettement SAP sur compas de 10,4 %, indiquant des caractéristiques spécifiques au jeu de données qui favorisent les modèles d’arbres même dans cette gamme de taille.
- 10 000+ lignes (6 jeux de données) :
- Inclus : california_housing (20K), house_sales (21K), default_credit (30K), adult_income (48K), diamonds (53K), higgs_100k (98K).
- Résultat : À mesure que le volume de données augmente, l’avantage potentiel des connaissances a priori du LLM diminue. LightGBM et CatBoost obtiennent les meilleurs résultats sur 5 des 6 jeux de données, offrant une meilleure précision à une fraction du coût computationnel. La seule exception, california_housing, montre un avantage modeste de 1,7 % pour SAP.
1. Tableau des jeux de données des résultats du benchmark
Voici une analyse complète des performances des modèles sur les 17 jeux de données.
2. Analyse coût-efficacité
Nous avons calculé le coût computationnel direct pour chaque modèle en fonction du tarif de l'instance RunPod H200 à 3,59 $/heure.
SAP-RPT-1-OSS entraîne des coûts nettement plus élevés en raison du temps nécessaire au prétraitement par intégration textuelle et de la forte surcharge mémoire de l'architecture du LLM. En revanche, LightGBM et CatBoost terminent les tâches presque instantanément sur ce matériel. Les coûts ci-dessous reflètent le temps total écoulé (prétraitement + entraînement) pour une exécution de validation croisée à 3 plis.
Coût moyen par jeu de données (moyenne sur 17 jeux)
Répartition des coûts par taille de jeu de données
- Petits jeux de données (<1K lignes) : SAP est relativement peu coûteux (≈ 0,03 $ par exécution). Le taux de réussite élevé ici rend le coût négligeable.
- Grands jeux de données (>20K lignes) : SAP devient coûteux.
- Exemple : L'entraînement sur adult_income (48k lignes) prend environ 12 minutes au total pour 3 plis.
- Coût : 12 min X 0,06 $/min = 0,72 $ par expérience.
- Comparaison : LightGBM termine la même tâche pour 0,01 $.
Conclusion : Bien que 0,22 $ par jeu de données ne soit pas élevé en valeur absolue, SAP coûte 22 fois plus cher que la référence. Cette différence de coût peut être justifiée pour les petits jeux de données riches en sémantique où SAP montre des améliorations significatives de précision (par exemple, cylinder_bands avec +5,5 %), mais devient plus difficile à justifier pour les grands jeux de données où les modèles d’arbres obtiennent des performances égales ou supérieures à une fraction du coût.
3. Cadre d'analyse : Le spectre sémantique
Pour interpréter ces résultats, il est essentiel de comprendre comment nous avons sélectionné les données. Nous n’avons pas choisi les jeux de données au hasard ; nous avons sélectionné un ensemble de 17 jeux de données spécifiquement choisis pour couvrir le spectre sémantique-numérique.
Notre hypothèse principale était que SAP (étant basé sur un LLM) excellerait là où les données ont une signification linguistique, tandis que les modèles d’arbres domineraient dans les calculs numériques bruts. Nous avons classé nos jeux de données en trois groupes distincts :
Groupe A : Jeux de données à forte sémantique (6 jeux)
Caractéristiques : Les caractéristiques contiennent des descriptions textuelles riches, des étiquettes catégorielles avec une signification réelle (par exemple, « gel des frais de médecin »), ou une terminologie spécifique au domaine.
- Jeux de données :
- cylinder_bands : Défauts d'impression industriels.
- titanic : Noms et titres des passagers.
- vote : Dossiers de vote au Congrès (catégoriel « Oui/Non » sur des politiques).
- breast_cancer : Descriptions médicales des tumeurs.
- spambase : Fréquences des mots dans les e-mails.
- wine : Origines chimiques.
Groupe B : Données commerciales mixtes (6 jeux)
Caractéristiques : Le format tabulaire standard trouvé dans la plupart des bases de données d'entreprise, un mélange de valeurs numériques (salaire, âge) et de chaînes catégorielles (intitulé du poste, race, département).
- Jeux de données :
- employee_salaries : Intitulés de poste vs. salaire.
- compas : Historique criminel et données démographiques (attributs sensibles).
- adult_income : Données démographiques du recensement.
- credit_g : Profils de risque de crédit allemands.
- default_credit : Données de défaut de crédit taïwanaises.
- car_evaluation : Paramètres d'achat de véhicules.
Groupe C : Données numériques pures à faible sémantique (5 jeux)
Caractéristiques : Les caractéristiques sont des mesures abstraites, des relevés de capteurs ou des coordonnées physiques. Les noms des colonnes n'ont souvent pas d'importance ; seules les relations mathématiques comptent.
- Jeux de données :
- higgs_100k : Cinématique des particules en physique.
- diamonds : Dimensions physiques et prix.
- sonar : Rebonds d'énergie de fréquence.
- california_housing : Coordonnées Lat/Long et statistiques du recensement.
- house_sales : Immobilier du comté de King (principalement des caractéristiques numériques).
4. Analyse approfondie : Où SAP gagne et échoue
L'application du cadre d'analyse à nos résultats révèle quatre modèles de performance distincts. Le tableau ci-dessous résume exactement où SAP excelle et où il échoue.
Fondements conceptuels des modèles relationnels fondamentaux
L'objectif principal d'un modèle relationnel fondamental est de faire des prédictions précises et d'effectuer diverses tâches sur des tables structurées. Ces modèles doivent comprendre comment l'information est représentée à travers différentes tables, comment les entités sont liées par des relations, et comment l'information temporelle influence les résultats.
Les capacités clés de ces modèles incluent :
- Généralisation du schéma : La capacité de s'adapter à de nouveaux schémas relationnels sans réentraînement complet.
- Représentation unifiée des entrées : Gérer différents types de colonnes tels que les caractéristiques numériques, catégorielles et textuelles.
- Intégration du contexte temporel et structurel : Capturer les dépendances dans le temps et entre les entités liées par des clés primaires et étrangères.
- Transférabilité : Effectuer des tâches prédictives sur de nouveaux jeux de données grâce au pré-entraînement et à l'apprentissage zéro-shot.
Griffin
Griffin est l'une des premières tentatives à grande échelle de construire un modèle relationnel fondamental unifié. Il représente les données relationnelles comme un graphe hétérogène temporel, où chaque ligne devient un nœud et les arêtes correspondent aux relations de clé étrangère. Ses caractéristiques principales incluent :
Encodeur de caractéristiques unifié
- Les caractéristiques catégorielles et textuelles sont encodées avec un encodeur de texte pré-entraîné, tandis que les valeurs numériques utilisent un encodeur flottant appris.
- Les métadonnées telles que les noms de table, les noms de colonne et les types de lien sont intégrées pour aider le modèle à reconnaître le schéma relationnel.
- Les intégrations de tâches permettent à un seul modèle d'effectuer des tâches de régression et de classification avec des décodeurs partagés.
Passage de messages et attention
Griffin intègre des réseaux neuronaux de passage de messages avec un module d'attention croisée. Le composant de passage de messages agrège l'information au sein et entre les relations, tandis que l'attention croisée se concentre sur les cellules pertinentes au sein de chaque ligne. Cette conception aide le modèle à gérer des données variées et à maintenir le contexte entre les entités connectées.
Pré-entraînement et affinage
Le modèle est pré-entraîné sur des jeux de données à table unique via une tâche de complétion de cellules masquées, puis affiné sur des bases de données relationnelles pour des tâches spécifiques. Des expériences sur de grands benchmarks relationnels montrent que Griffin surpasse les modèles GNN traditionnels et les modèles à table unique en termes de précision et d'efficacité d'apprentissage par transfert.
Figure 1 : Graphique montrant le cadre du modèle Griffin.1
Transformateur relationnel
Alors que Griffin se concentre sur l'agrégation de graphes, le Transformateur Relationnel (RT) applique des architectures de transformateurs directement aux bases de données relationnelles. Il traite chaque cellule comme un jeton enrichi de sa valeur, de son nom de colonne et de son nom de table.
Représentation des entrées
Chaque jeton combine :
- Une intégration de valeur qui dépend de son type de données (numérique, texte ou date-heure).
- Une intégration de schéma générée à partir du texte de la table et de la colonne.
- Un jeton masque utilisé lorsque la valeur est cachée pendant le pré-entraînement.
Cette structure permet au RT de traiter des bases de données relationnelles aux schémas différents tout en conservant un format d'entrée cohérent.
Attention relationnelle
RT introduit un mécanisme d'attention relationnelle qui opère au niveau de la cellule. Il inclut :
- Attention par colonne pour apprendre les distributions de valeurs au sein des colonnes.
- Attention par caractéristique pour combiner les attributs au sein de la même ligne ou de lignes parentes liées.
- Attention par voisin pour agréger l'information provenant des lignes enfants connectées.
Ensemble, ces couches d'attention forment un transformateur de graphe relationnel qui modélise les dépendances entre lignes, colonnes et tables.
Résultats d'entraînement et de transfert
RT est pré-entraîné sur des bases de données relationnelles provenant de RelBench. Dans des expériences, le modèle pré-entraîné a atteint jusqu'à 94 % des performances des modèles entièrement supervisés dans des contextes zéro-shot. Il a également appris plus rapidement lors de l'affinage, nécessitant moins d'étapes d'entraînement pour atteindre une haute précision.2
Cette approche suggère que les bases de données relationnelles partagent des motifs transférables entre domaines et que la tokenisation au niveau des cellules fournit une base pratique pour les tâches prédictives sur des données structurées.
RelBench
RelBench est conçu pour faire progresser l'apprentissage profond relationnel, qui se concentre sur l'apprentissage end-to-end à partir de données réparties sur plusieurs tables liées dans des bases de données relationnelles.
Étant donné que les bases de données relationnelles restent le système de gestion de données dominant dans l'industrie et la science, RelBench fournit un cadre standardisé et reproductible pour évaluer les modèles qui opèrent directement sur des structures relationnelles plutôt que de s'appuyer sur un aplatissement manuel des caractéristiques.
Les versions précédentes de RelBench ont introduit 11 bases de données relationnelles couvrant des domaines tels que la santé, les réseaux sociaux, le commerce électronique et le sport, avec 70 tâches prédictives conçues pour être à la fois stimulantes et pertinentes au domaine.3
En janvier 2026, RelBench v2 a été publié, ajoutant quatre nouvelles bases de données (SALT, RateBeer, arXiv et MIMIC-IV) et 40 tâches prédictives supplémentaires, incluant une nouvelle catégorie de tâches de saisie semi-automatique qui évaluent la capacité d'un modèle à prédire des colonnes existantes dans une base de données relationnelle.
La sortie a également étendu l'accès aux données via l'intégration CTU, permettant d'accéder à plus de 70 jeux de données relationnels via ReDeLEx ; ajouté une connectivité directe à la base de données SQL ; et intégré sept jeux de données du référentiel 4DBInfer au format RelBench.
Au-delà des jeux de données et des tâches, RelBench fournit une implémentation open-source de référence pour l'apprentissage profond relationnel basée sur des réseaux neuronaux graphiques, utilisant PyTorch Geometric pour la construction de graphes et PyTorch Frame pour la modélisation tabulaire, ainsi qu'un classement public pour suivre les progrès.
La sortie v2 a également introduit plusieurs améliorations d'utilisabilité et de performance, incluant des étiquettes optionnelles censurées dans le temps, la prise en charge de la métrique NDCG dans la prédiction de liens, une génération plus rapide d'intégrations de phrases et une gestion configurable du cache.4
VIEIRA
VIEIRA adopte une approche différente en se concentrant sur la programmation avec des modèles fondamentaux plutôt que sur la construction d'un moteur prédictif unique. Il étend le compilateur logique probabiliste SCALLOP avec un langage déclaratif qui intègre des grands modèles de langage, des modèles de vision et d'autres composants pré-entraînés comme prédicats étrangers.5
Paradigme relationnel
Dans VIEIRA, les modèles fondamentaux sont traités comme des fonctions sans état avec des entrées et sorties relationnelles. Cela permet de composer des modèles tels que GPT, CLIP ou SAM selon des règles logiques. Par exemple :
- Un programme peut utiliser GPT pour extraire des connaissances à partir de texte et les stocker sous forme de relations structurées.
- CLIP peut classer des images et les lier à des étiquettes textuelles dans une table.
Applications
Le cadre prend en charge :
- Raisonnement sur les dates et les mathématiques à l’aide de GPT.
- Raisonnement sur les liens de parenté à l’aide d’extraction de texte et d’inférence logique.
- Question-réponse combinant récupération et raisonnement.
- Question-réponse visuelle et édition d’image par composition multimodale.
En unifiant la logique symbolique et l’inférence neuronale, VIEIRA permet aux analystes de données et aux développeurs de construire des systèmes interprétables qui utilisent des modèles fondamentaux pré-entraînés pour répondre à des requêtes prédictives sur des données structurées et des images.
Études de cas
SAP Hana Cloud
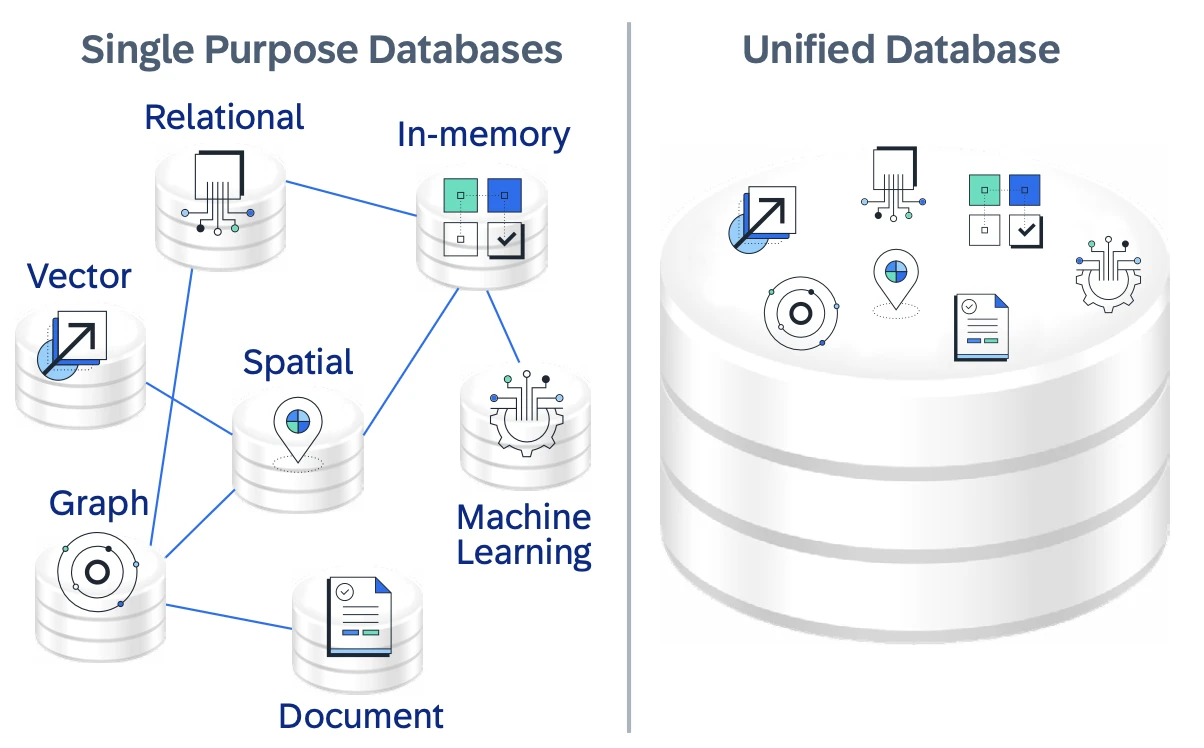
SAP HANA Cloud est une base de données cloud-native entièrement gérée conçue pour servir de fondation de données unifiée pour les applications d'entreprise combinant transactions, analyses et IA. Plutôt que de servir de base de données relationnelle à usage unique, SAP HANA Cloud est positionné comme une plateforme multi-modèle permettant aux organisations de construire des « applications de données intelligentes » sur leurs données opérationnelles d'entreprise.
SAP HANA Cloud combine le traitement en mémoire avec le stockage sur disque et l'intégration du lac de données pour répondre à différents besoins de performance et de coût. Cette conception flexible prend en charge les charges de travail en temps réel tout en s'adaptant dynamiquement à l'évolution des volumes de données et de l'utilisation.
Un élément différenciant clé est son moteur multi-modèle natif, qui prend en charge les données relationnelles, JSON/document, graphiques, spatiales et vectorielles au sein d'une seule base de données. Cela permet aux applications de combiner des requêtes SQL, des relations graphiques et des recherches de similarité vectorielle sans déplacer les données entre différents systèmes, simplifiant ainsi l'architecture et réduisant la latence.
Intégré à la plateforme SAP Business Technology, SAP HANA Cloud s'interconnecte directement avec des sources de données SAP et non SAP, y compris un accès en direct sans réplication, et fournit par défaut une sécurité, une disponibilité et une conformité de niveau entreprise.
Dans l'ensemble, SAP HANA Cloud est une plateforme de données relationnelle et native IA dans laquelle la base de données relationnelle sert de couche fondamentale pour les analyses, les données multi-modèles et les applications d'IA d'entreprise.
Figure 2 : Image montrant la base de données unifiée de Hana et
le traitement de données multi-modèles.6
Le sap-rpt-1 de SAP
sap-rpt-1 introduit un unique modèle relationnel fondamental qui effectue une large gamme de tâches prédictives par apprentissage dans le contexte. Plutôt que de réentraîner un nouveau modèle pour chaque cas d'utilisation, les utilisateurs fournissent quelques exemples du modèle cible, comme « clients ayant payé à temps » et « clients ayant payé en retard ». Le modèle reconnaît alors le modèle et produit immédiatement des prédictions précises pour de nouvelles données.
Le modèle est conçu avec un mécanisme d'attention bidimensionnel qui capture les relations entre lignes et colonnes, tout en intégrant des métadonnées telles que les noms de table et de colonne dans des intégrations vectorielles. Cette conception lui permet de comprendre la sémantique des schémas relationnels et l'information temporelle au sein des tables commerciales.
L'approche de SAP apporte plusieurs avantages aux analystes de données et aux utilisateurs métiers :
- Un seul modèle fonctionnant sur plusieurs tables et domaines.
- Pas besoin de réaffinage répété ou de développement personnalisé.
- Accès à des informations prédictives en quelques minutes plutôt que semaines.
- Intégration avec les entrepôts de données existants et les systèmes SAP.
En intégrant sap-rpt-1 dans l'écosystème SAP, les experts métiers peuvent interagir directement avec leurs propres données et recevoir des prédictions via des interfaces intuitives. Le résultat est un chemin plus rapide des données structurées aux décisions actionnables, sans ingénierie manuelle des caractéristiques.
Figure 3 : Facteur de réduction d'erreur de sap-rpt-1-large par rapport aux références d'IA étroite dans les domaines SAP.
Fin 2025, SAP a confirmé que SAP-RPT-1 est généralement disponible via le hub d'IA générative dans SAP IA Foundation (SAP IA Core).
Le modèle est proposé en deux variantes de production :
- SAP-RPT-1-small, optimisé pour des prédictions à faible latence et haut débit,
- SAP-RPT-1-large, conçu pour privilégier la précision prédictive.
Cette sortie officialise le rôle de SAP-RPT-1 en tant que modèle fondamental déployable dans la pile d'IA d'entreprise de SAP, plutôt qu'une simple fonctionnalité de recherche.
De plus, SAP propose le SAP-RPT Playground, un environnement web sans code où les utilisateurs peuvent tester l'apprentissage dans le contexte avec leurs propres données ou des exemples fournis par SAP.
SAP-ABAP-1
SAP-ABAP-1 est un modèle fondamental conçu pour soutenir les cas d'utilisation de productivité des développeurs basés sur l'IA pour les clients et partenaires SAP.
Il est disponible via le hub d'IA générative de SAP et a été entraîné sur plus de 250 millions de lignes de code ABAP, 30 millions de lignes de code CDS et une documentation technique étendue. Le modèle est optimisé pour comprendre et expliquer le code ABAP, mettre en évidence les meilleures pratiques et fournir un accès aux connaissances de développement SAP à jour.
SAP propose un accès d'essai gratuit à SAP-ABAP-1 via le hub d'IA générative, avec des fonctionnalités supplémentaires prévues pour 2026.7
Kumo.IA’s KumoRFM : un transformateur de graphe relationnel pour l'analyse prédictive
Kumo.IA, fondée par le professeur de Stanford Jure Leskovec, a créé KumoRFM, un modèle relationnel fondamental qui utilise un transformateur de graphe relationnel pour analyser les bases de données relationnelles et les entrepôts de données. Il représente les données relationnelles comme un graphe hétérogène temporel, où chaque entité est un nœud et les clés primaires et étrangères forment des arêtes entre les tables.
Cette approche basée sur les graphes permet à KumoRFM d'apprendre à partir de plusieurs tables simultanément et de s'adapter à de nouveaux schémas relationnels. Le modèle est pré-entraîné sur des sources de données variées et peut se généraliser à de nouveaux jeux de données sans construire de modèles séparés pour chaque tâche prédictive.
KumoRFM peut être utilisé via différentes interfaces selon le niveau d'expertise de l'utilisateur :
- PQL (Langage de requête prédictive) : Un langage de requête spécialisé pour définir des requêtes prédictives sur des données structurées.
- Interface en langage naturel : Pour les utilisateurs non techniques, les entrées en langage naturel sont automatiquement traduites en requêtes PQL.
- SDK Python : Permet aux développeurs d'intégrer le modèle dans des pipelines et applications d'IA d'entreprise.
L'architecture de KumoRFM échantillonne dynamiquement la base de données pour créer des sous-graphes de contexte et des sous-graphes de prédiction. Ces sous-graphes sont traités par le transformateur de graphe relationnel, qui capture les dépendances et l'information temporelle entre les entités liées. Par apprentissage dans le contexte, le modèle fournit des prédictions précises et peut expliquer son processus de raisonnement.
Kumo propose deux options de déploiement adaptées aux environnements d'entreprise :
- Plateforme SaaS : Un service cloud basé sur Apache Spark pour un accès facile et une évolutivité
- Natif entrepôt de données : Permet aux organisations d'utiliser leurs propres données dans Snowflake ou Databricks sans les déplacer en dehors de leur environnement sécurisé
Contrairement aux graphes de connaissances traditionnels qui nécessitent une définition manuelle du schéma, KumoRFM construit automatiquement son graphe relationnel à partir de sources structurées. Cela le rend particulièrement adapté à l'eCommerce, la finance et la santé, où les relations, les motifs temporels et le contexte évolutif sont essentiels pour des prédictions fiables.
Les capacités clés de KumoRFM incluent :
- Flexibilité à travers différentes tables et structures de schéma.
- Compatibilité avec divers types de colonnes et identifiants personnalisés.
- Adaptation à des tâches spécifiques au moment de l'inférence.
- Précision élevée et interprétabilité dans les tâches prédictives.
Figure 4 : L'image montre comment les modèles relationnels fondamentaux (RFMs) fonctionnent dans plusieurs domaines, tels que l'eCommerce, la finance et la santé, pour faire des prédictions, fournir des explications et évaluer les résultats.8
Méthodologie du benchmark
Configuration et environnement du benchmark
Pour garantir des comparaisons équitables entre les arbres liés au CPU et les modèles accélérés par GPU, nous avons utilisé un environnement haute performance capable de gérer efficacement les deux.
- Matériel : Instance RunPod avec un NVIDIA H200 140GB GPU.
- Logiciel : Python 3.12 avec bibliothèques figées pour la reproductibilité :
- scikit-learn 1.5.2, lightgbm 4.5.0, catboost 1.2.7
- torch 2.5.1, pandas 2.2.3, numpy 2.1.3
- sap-rpt-oss (Source : GitHub officiel)
- Reproductibilité : random_state=42 a été utilisé de manière cohérente pour toutes les divisions, initialisations et modèles.
Jeux de données : Le spectre sémantique
Nous avons évalué les modèles sur 17 jeux de données d'apprentissage supervisé provenant d'OpenML et de Scikit-Learn. Plutôt qu'une sélection aléatoire, nous avons sélectionné cet ensemble pour couvrir le « spectre sémantique-numérique », testant l'hypothèse que les LLM excellent là où les caractéristiques contiennent une signification linguistique plutôt que de simples statistiques brutes.
L'inventaire :
- Petits et sémantiques (<1K lignes) :
- wine (178), sonar (208), vote (435), cylinder_bands (540), breast_cancer (569).
- Moyens/mixtes (1K – 10K lignes) :
- credit_g (1K), titanic (1,3K), car_evaluation (1,7K), spambase (4,6K), compas (5,2K), employee_salaries (9,2K).
- Grands/numériques (10K+ lignes) :
- california_housing (20K), house_sales (21K), default_credit (30K), adult_income (48K), diamonds (53K), higgs (échantillonné à 100K).
Tâches couvertes :
- 11 tâches de classification binaire
- 2 tâches de classification multiclasse
- 4 tâches de régression
Configurations des modèles et prétraitement
Nous avons visé une « comparaison de praticien » réaliste, utilisant des paramètres par défaut solides plutôt qu'un réglage exhaustif des hyperparamètres.
LightGBM & CatBoost
Pour garantir une comparaison équitable avec le modèle SAP computationnellement lourd, nous avons augmenté les estimateurs par défaut robustes.
- LightGBM : n_estimators=500, learning_rate=0,05, num_leaves=31. S'exécute sur CPU (n_jobs=-1).
- CatBoost : iterations=500, learning_rate=0,05, depth=6. S'exécute sur GPU (task_type=" GPU ").
- Prétraitement : Encodage d'étiquettes simple pour les catégorielles ; pas de mise à l'échelle pour les numériques ; imputation par la médiane/le mode pour les valeurs manquantes.
SAP-RPT-1-OSS
Nous avons configuré SAP pour équilibrer performance et coût selon nos expériences préliminaires de configuration.
- Configuration : max_context_size=4096, bagging=4.
- Note :
- Contexte : Les tests sur adult_income ont montré qu'augmenter le contexte de 4096 à 8192 triplait le temps d'exécution (4 min à 12 min) pour un gain de précision négligeable (0,917 vs 0,917 ROC-AUC).
- Bagging : Augmenter le bagging de 4 à 8 (paramètre par défaut de SAP utilisé dans l'article9 ) offrait des rendements décroissants.
- Prétraitement : Aucun. Le DataFrame pandas brut est transmis directement. Le modèle encode à l’aide d’intégrations textuelles (sentence-transformers/all-MiniLM-L6-v2).
Protocole d'évaluation
Stratégie de validation croisée
Nous avons utilisé une validation croisée à 3 plis avec mélange.
- Nous avons réduit la validation croisée standard à 5 plis à 3 plis pour tenir compte des temps d'inférence lents de SAP (gain de 40 % en temps) tout en maintenant la validité statistique.
- Division : StratifiedKFold pour la classification ; K-Fold standard pour la régression.
Métriques et diagnostics
Nous sommes allés au-delà de la simple précision pour obtenir une vue d'ensemble de la performance du modèle :
- Métriques principales de classement : ROC-AUC (binaire), Précision équilibrée (multiclasse), R² (régression).
- Diagnostics secondaires : Nous avons suivi le coefficient de corrélation de Matthews (MCC) et la perte logarithmique pour nous assurer que les gains n'étaient pas des artefacts du déséquilibre des classes, et la MAPE pour la calibration des erreurs de régression.
- Calcul du coût : Basé sur le temps total écoulé (prétraitement + entraînement + inférence) sur l'instance RunPod H200 (3,59 $/h).
Signification statistique
Nous avons appliqué un test de Wilcoxon signé (p<0,05) aux comparaisons par paires de modèles pour déterminer si les différences de performance étaient statistiquement significatives ou du bruit aléatoire.
Limites et validité interne
Nous reconnaissons explicitement les contraintes suivantes dans notre méthodologie :
- Configurations standardisées vs réglage : Nous avons utilisé des configurations fixes et robustes par défaut pour tous les modèles plutôt que d'effectuer une optimisation exhaustive des hyperparamètres (par exemple, CV imbriqué ou balayages Optuna). Bien que cela garantisse une base cohérente, il convient de noter que les modèles d'arbres voient souvent leurs performances s'améliorer avec un réglage spécifique au jeu de données, ce qui pourrait réduire les écarts dans le « groupe concurrentiel ».
- Limites d'échelle des données : Notre analyse s'est concentrée sur des jeux de données de moins de 100 000 lignes pour simuler des scénarios d'entreprise de taille moyenne typiques. Nous avons observé que l'avantage du LLM diminue à mesure que le volume de données augmente, mais nous n'avons pas étendu les tests à des échelles de millions de lignes où la latence et le coût d'inférence deviendraient probablement les contraintes principales.
- Uniformité de l'infrastructure : Pour maintenir un environnement de test cohérent, nous avons exécuté tous les modèles sur le même matériel NVIDIA H200. LightGBM et CatBoost sont fortement optimisés pour les CPU grand public ; par conséquent, dans un environnement de production dédié uniquement aux modèles d'arbres, l'écart de coût serait probablement plus important.
- Généralisation au-delà de la sémantique : Notre hypothèse du « spectre sémantique » a prédit avec succès de nombreux résultats, mais la forte performance du LLM sur des jeux de données abstraits comme sonar et california_housing suggère des capacités au-delà de la compréhension linguistique. Cela indique que le modèle pourrait également exploiter des motifs de régularisation en haute dimension, un phénomène qui mérite une investigation plus approfondie au-delà de la portée de cette étude initiale.
Citer cette recherche
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{ermut2026,
author = {Ermut, Sıla and Sarı, Ekrem},
title = {{Comparer les modèles relationnels fondamentaux}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/relational-foundation-model}},
note = {AIMultiple. Consulté le 2 Juillet 2026}
}


 fonctionnent dans plusieurs domaines.")
Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.