Benchmark des rerankers: Comparaison des 8 meilleurs modèles
Nous avons évalué 8 modèles de reranking sur environ 145 000 avis Amazon en anglais pour mesurer dans quelle mesure une étape de reranking améliore la recherche dense. Nous avons récupéré les 100 meilleurs candidats avec multilingual-e5-base, nous les avons rerankés avec chaque modèle, et nous avons évalué les 10 meilleurs résultats par rapport à 300 requêtes, chacune faisant référence à des détails concrets de son avis source. Le meilleur reranker a fait passer Hit@1 de 62,67 % à 83,00 % (+20,33pp).
Résultats du benchmark des rerankers
Métriques expliquées :
ΔHit@1 / ΔHit@10 montre l'amélioration par rapport à la ligne de base (sans reranker) en points de pourcentage (pp). Par exemple, +20,33pp signifie que le reranker a amélioré Hit@1 de 20,33 points de pourcentage par rapport aux 62,67 % de la ligne de base.
Hit@K mesure si un avis avec le bon product_id apparaît dans les K meilleurs résultats. La vérité terrain est le product_id de l'avis qui a généré la requête. Si un autre avis du même produit se retrouve dans le top-K, cela compte comme un hit. Hit@1 est le test le plus strict : le premier résultat provient-il du bon produit ? Hit@10 est plus tolérant : le bon produit se trouve-t-il quelque part dans les 10 premiers résultats ?
MRR@10 (Mean Reciprocal Rank) moyenne l'inverse du rang du premier résultat correct sur toutes les requêtes. Si le premier product_id correspondant est au rang 1, le score est de 1,0. Au rang 2, il est de 0,5. Au rang 10, il est de 0,1. Cela récompense les modèles qui placent le bon produit aussi haut que possible.
nDCG@10 (Normalized Discounted Cumulative Gain) évalue les positions de tous les avis correspondants dans le top-10, pas seulement le premier. Si le même produit a plusieurs avis dans l'ensemble des candidats et que plusieurs se retrouvent dans le top-10, nDCG crédite chacun en fonction de sa position. En pratique, la plupart des produits n'ont que 1 à 2 avis dans les 100 meilleurs candidats, donc nDCG et MRR évoluent de près.
Recall@10 mesure la fraction d'avis correspondants (même product_id) dans le top-10 par rapport à tous les avis correspondants dans l'ensemble complet des candidats (top-100). Si un produit a 3 avis dans le top-100 et que le reranker en place 2 dans le top-10, Recall@10 est de 2/3 pour cette requête. Comme la plupart des produits ont peu d'avis dupliqués dans l'ensemble des candidats, Recall@10 et Hit@10 sont presque identiques dans ce benchmark.
Décomposition de la latence
La latence de reranking mesure le temps nécessaire à chaque cross-encoder pour noter 100 documents candidats par rapport à la requête. Le temps de recherche vectorielle (~20 ms) est exclu car il reste constant sur toutes les exécutions et est indépendant du reranker.
Métriques de latence expliquées :
Rerank est le temps nécessaire au cross-encoder pour noter les 100 documents candidats par rapport à la requête. C'est là que les modèles diffèrent : un seul passage vers l'avant est rapide, tandis que le décodage autoregressif est lent.
P95 est la latence totale au 95e percentile. Certaines requêtes ont des textes d'avis plus longs, ce qui augmente le temps de tokenisation et de notation. P95 montre le pire cas que vous devriez attendre pour 95 % des requêtes.
Principales conclusions
Un modèle de 149M égale un modèle de 1,2B
gte-reranker-modernbert-base a 149M de paramètres, nemotron-rerank-1b a 1,2B. Les deux atteignent 83,00 % Hit@1 en anglais. L'architecture ModernBERT est 8 fois plus petite et offre une précision de premier plan identique.
Cela ne signifie pas que la taille du modèle est sans importance. nemotron prend légèrement l'avantage sur MRR@10 (0,8514 contre 0,8483) et Hit@10 (88,33 % contre 88,00 %), ce qui signifie qu'il classe les documents pertinents légèrement mieux sur l'ensemble du top-10. Mais pour la plupart des applications où obtenir le premier résultat correct est ce qui compte, le modèle de 149M suffit.
Le plus grand modèle n'est pas le meilleur
qwen3_reranker_4b a 4B de paramètres et prend plus d'une seconde par requête. Il atteint 77,67 % Hit@1, se classant quatrième derrière nemotron (1,2B), gte_modernbert (149M) et jina (560M). Vous payez 4,5 fois la latence de nemotron pour 5,3 points de pourcentage de précision en moins.
L'architecture de qwen3 utilise la modélisation du langage causal avec une approche de logit oui/non. Le modèle lit la paire requête-document et sort la probabilité de « oui, c'est pertinent ». C'est conceptuellement propre, mais l'inférence est coûteuse en raison de la surcharge du décodage autoregressif. Les modèles SequenceClassification (gte_modernbert, bge) et l'approche de modèle de prompt de nemotron traitent la paire en un seul passage vers l'avant, ce qui est fondamentalement plus rapide.
Jina offre le meilleur compromis vitesse-précision
jina_reranker_v3 atteint 81,33 % Hit@1 en 188 ms. nemotron atteint 83,00 % en 243 ms. Si vous avez besoin d'une latence totale inférieure à 200 ms par requête, Jina est le seul modèle du premier niveau à le fournir. L'écart de 1,67 point de pourcentage peut ne pas justifier les 55 ms supplémentaires dans un système de production servant des milliers de requêtes par seconde.
Un reranker rend les résultats pires
mxbai_rerank_xsmall (70M de paramètres) obtient 64,67 % Hit@1. La ligne de base sans aucun reranker obtient 62,67 %. L'amélioration est de seulement 2 points de pourcentage, ce qui est dans le bruit pour 300 requêtes. Avec 70M de paramètres, le modèle manque de capacité pour juger de manière fiable la pertinence requête-document sur des textes plus longs ou plus nuancés.
Un reranker n'est pas automatiquement bénéfique. Testez-le sur vos données réelles avant de le déployer.
Le retriever fixe le plafond
Tous les meilleurs rerankers convergent autour de 87-88 % Hit@10. Ce plafond provient du retriever. Si multilingual-e5-base ne place pas le bon document dans les 100 meilleurs candidats, aucun reranker ne peut le récupérer. Les 12 % restants de requêtes où chaque reranker échoue représentent des cas où le retriever dense a tout simplement manqué le document pertinent.
Améliorer au-delà de ce plafond nécessite un meilleur retriever, un pool de candidats plus grand, ou les deux. Nous avons testé les 250 meilleurs candidats et n'avons trouvé presque aucune amélioration par rapport aux 100 meilleurs, ce qui signifie que e5_base épuise ses candidats utiles bien avant le rang 250.
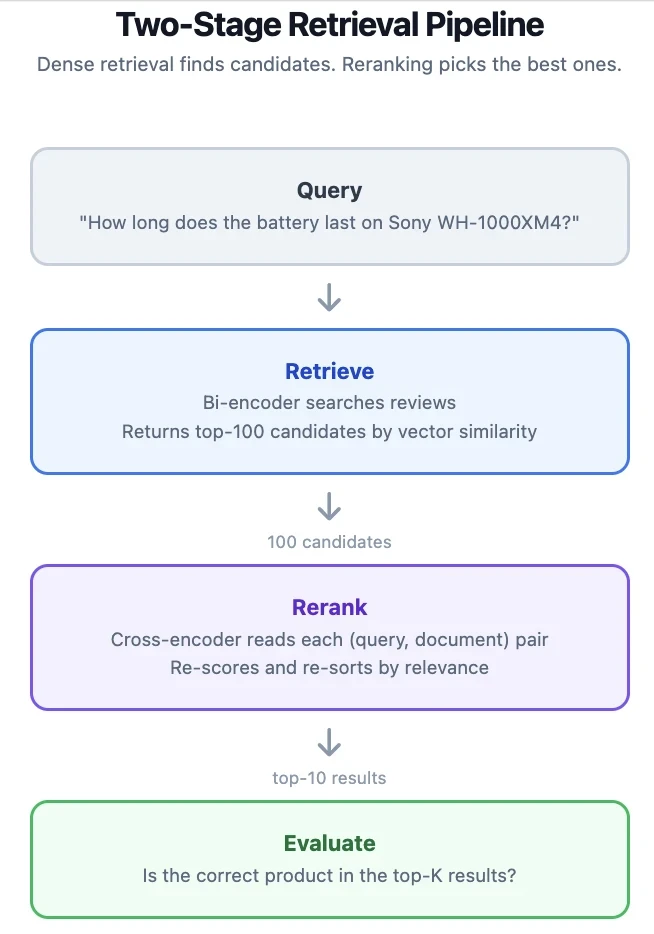
Fonctionnement des rerankers
Un retriever dense (bi-encoder) encode les requêtes et les documents indépendamment en vecteurs. La recherche est une recherche de plus proche voisin sur ces vecteurs. C'est rapide car vous n'encodez la requête qu'au moment de la recherche, mais le modèle ne voit jamais la requête et le document ensemble, il peut donc manquer des signaux de pertinence nuancés.
Un reranker (cross-encoder) prend une paire requête-document comme entrée unique. Le modèle prête attention aux deux textes conjointement, capturant les relations que l'encodage indépendant manque. Le coût est que vous devez exécuter le modèle une fois par candidat, vous ne pouvez donc vous permettre de noter qu'un petit pool.
Architectures dans ce benchmark
Nous avons testé quatre architectures de cross-encoder différentes :
Les modèles SequenceClassification (bge_base, bge_v2_m3, mxbai_xsmall, gte_modernbert) prennent une paire [query, document] comme entrée et sortent un score de logit unique. C'est l'approche la plus simple et la plus courante.
Nemotron utilise un format de modèle de prompt : « question:{q} passage:{p} ». L'entrée ressemble à du texte brut plutôt qu'à une paire structurée, mais le modèle sort toujours un score de pertinence unique via SequenceClassification. Le préentraînement LLM (basé sur Llama) lui donne une forte compréhension du langage.
Les rerankers Qwen3 utilisent la modélisation du langage causal. Le modèle lit la paire et génère un jugement oui/non. Le score est log P(oui) / (P(oui) + P(non)). Cela nécessite toute la machinerie autoregressive, ce qui explique la latence plus élevée.
Jina v3 utilise un API personnalisé (model.rerank()) qui gère la tokenisation et la notation en interne. L'architecture sous-jacente utilise l'attention croisée, mais l'interface abstrait les détails.
Méthodologie du benchmark des rerankers
- GPU : NVIDIA H100 PCIe 80 Go via Runpod
- Base de données vectorielle : Qdrant 1.12.0 (binaire local), distance cosinus
- Retriever : multilingual-e5-base (768-dim). Préfixe de requête :
"query: ", préfixe de document :"passage: " - Logiciel : transformers 5.2.0, PyTorch 2.8.0, CUDA 12.8.1
- Jeu de données : Sous-ensemble en anglais d'Amazon Reviews Multi (Kaggle).1 ~145k avis après filtrage pour un minimum de 100 caractères. Chaque avis a un product_id, un texte d'avis et une note en étoiles.
- Génération de requête : Claude Sonnet 4.6 via OpenRouter. 300 requêtes en anglais (5 types : factuel, opinion, utilisation, résolution de problèmes, comparaison de fonctionnalités). Chaque requête doit faire référence à des détails spécifiques de son avis source ; les questions génériques (score de spécificité < 4/5) sont filtrées.
- Format du document :
"Review Title: {title}\nReview: {body}" - Pipeline : Récupérer les 100 meilleurs candidats avec multilingual-e5-base, reranker avec cross-encoder, retourner le top-10. La ligne de base saute le reranking et retourne directement le top-10 du retriever.
- Vérité terrain : correspondance exacte du product_id uniquement. Pas de repli par similarité cosinus. Pas de crédit partiel pour des produits sémantiquement similaires.
- Variable contrôlée : Seul le modèle de reranker change entre les expériences. Retriever, nombre de candidats, ensemble de requêtes et critères d'évaluation sont identiques sur toutes les exécutions.
- Pas de fine-tuning : Tous les modèles évalués zero-shot avec les poids HuggingFace par défaut.
- Latence : Reranking (notation cross-encoder de 100 candidats). Mesuré par requête sur GPU.
Modèles testés
Limitations
Ce benchmark utilise un seul retriever (multilingual-e5-base). Un autre retriever produirait des ensembles de candidats différents et pourrait changer le classement des rerankers. Les résultats reflètent la performance de chaque reranker avec ce retriever spécifique, et non la qualité du reranker isolément.
Nous avons testé sur des avis de produits en anglais d'Amazon. Les performances sur d'autres domaines (articles scientifiques, documents juridiques, code) ou d'autres langues seront différentes.
Le nombre de candidats est fixé à 100. Certains rerankers pourraient classer différemment avec 20 ou 200 candidats. Nous avons testé 250 candidats et n'avons trouvé aucune amélioration notable, suggérant que 100 est suffisant pour e5_base, mais d'autres retrievers peuvent se comporter différemment.
300 requêtes est une taille d'échantillon modérée. Les trois meilleurs modèles (nemotron, gte_modernbert, jina) sont séparés par moins de 2 points de pourcentage. Avec un ensemble de requêtes plus grand, ces classements pourraient changer. L'écart entre le premier niveau et le dernier niveau (20+ points de pourcentage) est robuste.
Conclusion
Les rerankers fonctionnent. Le meilleur modèle de ce benchmark fait passer Hit@1 de 62,67 % à 83,00 % (+20,33pp), ce qui signifie que 20 requêtes sur 100 qui retournaient auparavant le mauvais document en premier retournent maintenant le bon. C'est un gain significatif pour un composant qui ajoute moins de 250 ms de latence.
La découverte la plus utile est que la taille du modèle ne détermine pas la qualité du reranker. gte-reranker-modernbert-base à 149M de paramètres égale nemotron-rerank-1b à 1,2B sur Hit@1. Le modèle Qwen3 de 4B se classe quatrième. Si vous choisissez un reranker pour un système de production, commencez par les modèles plus petits. Vous n'aurez peut-être jamais besoin des plus grands.
Pour les applications sensibles à la latence, jina-reranker-v3 est l'option la plus forte sous 200 ms. Pour une précision maximale sans contrainte de latence, nemotron-rerank-1b et gte-reranker-modernbert-base partagent la première place. Pour les équipes avec un budget GPU, gte-modernbert est le gagnant clair : même précision que le modèle de 1,2B pour une fraction de l'empreinte mémoire.
Un motif s'est maintenu sur toutes les expériences : le retriever fixe le plafond. Aucun reranker n'a poussé Hit@10 au-dessus de 88 %, car les 12 % restants de documents corrects n'apparaissaient jamais dans les 100 meilleurs candidats. Investir dans un meilleur retriever produira probablement des gains plus importants que le passage entre les trois meilleurs rerankers.
Pour aller plus loin
Explorez d'autres benchmarks RAG, tels que :
- Modèles d'embedding : OpenAI vs Gemini vs Cohere
- Top 16 modèles d'embedding open source pour RAG
- Meilleure base de données vectorielle pour RAG : Qdrant vs Weaviate vs Pinecone
- Benchmark Agentic RAG : Routage multi-bases de données et génération de requêtes
- Modèles d'embedding multimodaux : Apple vs Meta vs OpenAI
- RAG hybride : Amélioration de la précision RAG
- Top 10 modèles d'embedding multilingues pour RAG
Citez ce benchmark
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{sari2026,
author = {Sarı, Ekrem},
title = {{Benchmark des rerankers: Comparaison des 8 meilleurs modèles}},
year = {2026},
month = feb,
howpublished = {\url{https://aimultiple.com/rerankers}},
note = {AIMultiple. Consulté le 26 Février 2026}
}Résultats et horodatages de 9 points de données. Téléchargez les données utilisées dans cet article sous forme de fichier ZIP contenant un fichier CSV et un README.

Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.