RAG Frameworks: LangChain vs LangGraph vs LlamaIndex
Comparamos 5 RAG frameworks: LangChain, LangGraph, LlamaIndex, Haystack y DSPy, construyendo el mismo flujo de trabajo RAG agéntico con componentes estandarizados: modelos idénticos (GPT-4.1-mini), embeddings (BGE-small), recuperador (Qdrant) y herramientas (búsqueda web Tavily). Esto aísla la sobrecarga real y la eficiencia de tokens de cada framework.
RAG frameworks benchmark results
El benchmark consistió en 100 consultas, con cada framework ejecutando el conjunto completo 100 veces para proporcionar promedios estables.
- Tokens promedio: Total de tokens consumidos en todas las llamadas a LLM (enrutador, calificador de documentos, calificador de respuestas y generador), incluye tanto los prompts (con contexto recuperado) como las completaciones. Menor = menor costo de API.
- Sobrecarga del framework: Tiempo puro de orquestación (ms), el procesamiento interno del framework (lógica de enrutamiento, gestión de estado, etc.), excluyendo las llamadas a LLM API y herramientas. Menor = framework más ligero.
Todas las implementaciones lograron una precisión del 100% en el conjunto de prueba. Se usaron los mismos modelos, temperaturas, proveedor de recuperación, herramienta de búsqueda web y un límite compartido de tokens de contexto.
Hallazgos clave
- Nos enfocamos en controlar lo controlable: Misma familia de modelos y temperaturas, max_tokens a nivel de nodo, recuperador (Qdrant + BGE-small, k=5, normalización activada), proveedor web (solo Tavily), política de enrutamiento (heurística + modelo), retorno temprano de la calculadora, límite compartido de tokens de contexto, rúbrica de calificación idéntica, instrumentación unificada. Esto reduce sustancialmente los principales factores de confusión en nuestras mediciones.
- La sobrecarga del framework es medible pero pequeña: Observamos ~3–14 ms por consulta debido a la lógica de orquestación. Estas diferencias son reales, pero no la principal fuente de las brechas de latencia >1 s; la mayor parte del tiempo se dedica a E/S con modelos/herramientas externos.
- El rendimiento sigue a los tokens (bajo estas restricciones): DSPy muestra la menor sobrecarga del framework (~3.53 ms). Haystack (~5.9 ms) y LlamaIndex (~6 ms) le siguen, mientras que LangChain (~10 ms) y LangGraph (~14 ms) son más altos. El uso de tokens es más bajo para Haystack (~1.57k), luego LlamaIndex (~1.60k); DSPy y LangGraph están en ~2.03k, y LangChain ~2.40k.
- La ruta de enrutamiento/herramienta importa: Pequeños cambios en el enrutamiento inicial (recuperador vs. web vs. calculadora) y el comportamiento de respaldo afectan tanto a los tokens como al tiempo, incluso cuando los prompts y presupuestos están alineados.
¿Por qué persisten las diferencias? El “ADN del framework”
A pesar de la estandarización, permanecen pequeñas variaciones en los conteos de tokens y la latencia. Estas son atribuibles a los comportamientos inherentes y de bajo nivel de cada framework, su “ADN”.
- Serialización de prompt y mensajes: Cada framework envuelve el mismo contenido lógico con un formato ligeramente diferente antes de enviarlo al LLM, creando pequeñas pero consistentes diferencias de tokens.
- Ensamblaje del contexto: El orden preciso y la inclusión de metadatos dentro del contexto concatenado pueden diferir ligeramente según el framework, afectando el conteo final de tokens.
- Desempates de enrutamiento: En casos límite, diferencias sutiles en cómo un framework analiza la salida JSON del enrutador pueden llevar a una elección inicial de herramienta diferente.
En esta configuración, la huella de tokens parece ser el principal impulsor, más que el tiempo de ejecución del framework.
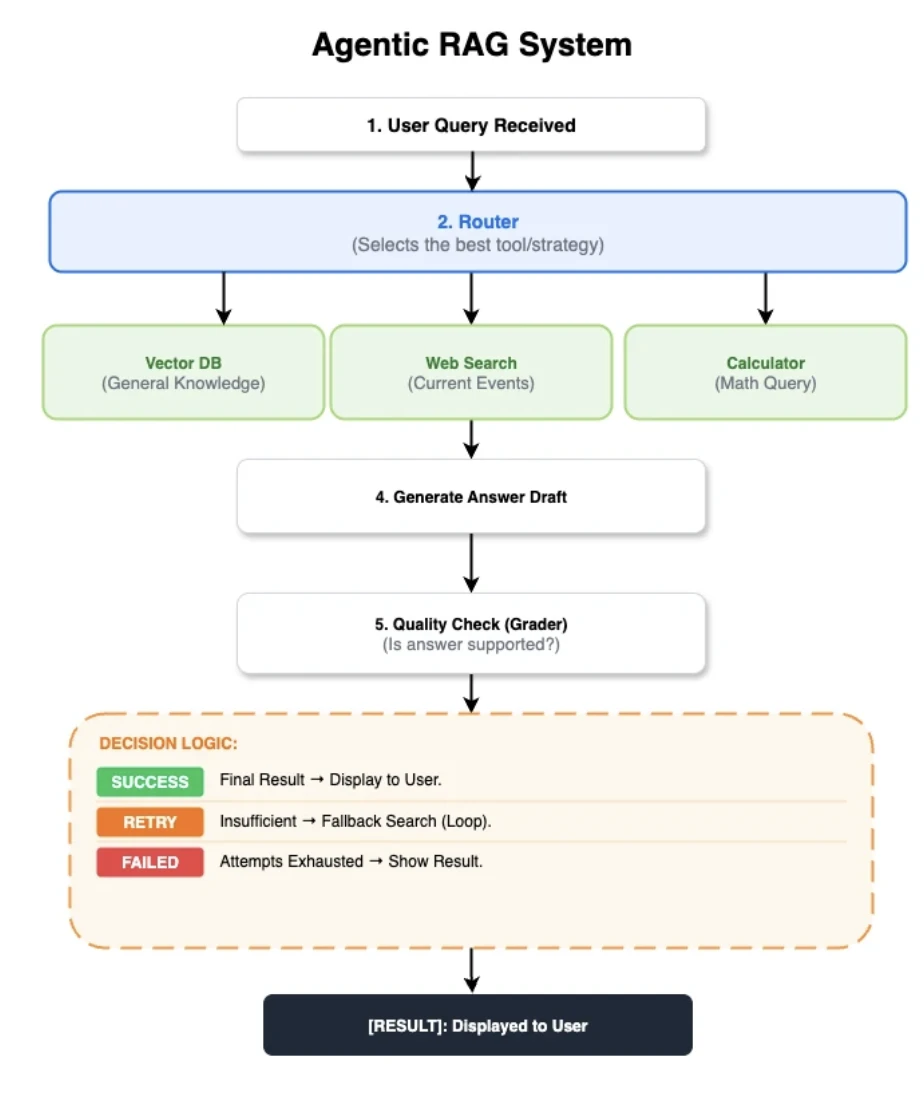
La arquitectura compartida de RAG agéntico
Para lograr una comparación justa, las cinco implementaciones se construyeron con el mismo flujo de control:
- Enrutador: Un nodo híbrido modelo-y-heurística que elige entre recuperador, búsqueda web o calculadora.
- Recuperar documentos: Obtiene los 5 mejores documentos de Qdrant usando embeddings normalizados BGE-small.
- Calificar documentos: Un juez LLM evalúa la relevancia del documento. Si es irrelevante, activa un respaldo de búsqueda web.
- Generar respuesta: Utiliza un LLM con temperatura=0.0 y un límite compartido de tokens de contexto para generar un borrador de respuesta.
- Calificar respuesta: Un segundo juez LLM evalúa el borrador en cuanto a fundamentación, contradicciones (alucinaciones) y completitud.
- Respaldo y retorno temprano: Se activa una búsqueda web si la calificación de la respuesta es insuficiente. Sin embargo, los resultados de la calculadora se devuelven directamente, omitiendo los pasos de generación y calificación.
Ejemplos de flujo de trabajo
Escenario A — Acierto directo desde la base de datos:
Escenario B — Evento reciente activa la herramienta web:
Escenario C — La calculadora proporciona un retorno temprano:
Escenario D — BD de vectores insuficiente, recurre a búsqueda web:
RAG frameworks methodology
Todas las cinco implementaciones lograron un 100% de precisión en nuestro conjunto de prueba de 100 consultas, coincidiendo con las respuestas de referencia. Este fue el requisito fundamental, asegurando que cada framework pudiera ejecutar con éxito el mismo flujo de trabajo RAG agéntico antes de medir las diferencias de rendimiento.
1. Componentes principales y configuración
Las herramientas fundamentales se estandarizaron para eliminar las variables de rendimiento en la fuente.
- LLMs:
- Modelo: Todos los nodos (enrutador, generador, calificador) utilizaron el modelo openai/gpt-4.1-mini a través de la API de OpenRouter.
- Determinismo: la temperatura se fijó en 0.0 para todas las llamadas a LLM para garantizar la máxima consistencia en el enrutamiento, generación y calificación.
- Límites de tokens: Se aplicaron límites estrictos de max_tokens: 256 para el enrutador y los calificadores, y 512 para el generador. Esto evita diferencias de latencia causadas por que un framework genere respuestas excesivamente largas.
- Embedding model & retrieval:
- Modelo: Todos los frameworks utilizaron BAAI/bge-small-en-v1.5 de HuggingFace.
- Normalización: Un paso crítico para el rendimiento, normalize_embeddings se estableció en True en los cinco frameworks. (LangChain/LangGraph mediante encode_kwargs; LlamaIndex mediante normalize=True; Haystack mediante normalize_embeddings; recuperador DSPy normalizado.)
- Recuperación: Se consultó el almacén de vectores Qdrant para k=5 (top 5 documentos) en todas las implementaciones.
- Tooling:
- Búsqueda web: El benchmark se restringió a solo Tavily (max_results=3).
- Calculadora: Las cinco implementaciones utilizaron la librería sympy para el análisis y evaluación de expresiones matemáticas, garantizando capacidades idénticas.
2. RAG control flow & policy
El proceso de “toma de decisiones” del agente se reflejó explícitamente en todos los ámbitos.
- Lógica de enrutamiento: Se implementó una estrategia de enrutamiento híbrida en los cinco scripts para equilibrar la inteligencia del modelo con reglas deterministas:
- Primero, una ruta heurística basada en regex verifica patrones obvios de calculadora o búsqueda web (por ejemplo, símbolos matemáticos, años como “2024”).
- Luego, un nodo enrutador LLM toma su propia decisión.
- La decisión final prioriza la heurística para calculadoras, en caso contrario se difiere a la elección del LLM.
- Presupuestación de contexto: Esta es una de las estandarizaciones más críticas. Antes de llamar al nodo generar_respuesta, todo el contexto de documentos recuperados y los resultados de búsqueda web se concatenan y luego se truncan a un límite compartido de 2000 tokens utilizando una utilidad común truncate_to_token_budget. Esto garantiza que el LLM generador en cada framework reciba una entrada del mismo tamaño exacto, evitando que algún framework se vea favorecido o perjudicado por la verbosidad de su contexto recuperado.
- Política de calificación de respuestas:
- Rúbrica indulgente: El nodo calificar_respuesta utiliza un prompt idéntico e indulgente en todos los frameworks, instruyendo al juez LLM para que acepte respuestas semánticamente similares y razonablemente completas.
- Manejo de fallos: La lógica para manejar un análisis JSON fallido del calificador se estandarizó. Si la salida del calificador no es un JSON válido, el sistema predetermina una calificación permisiva (fundamentado=True, completo=True), imitando un escenario del mundo real donde no se querría que un analizador frágil haga fallar una respuesta que de otro modo sería buena. Los campos estructurados de DSPy se devuelven (sin análisis JSON), esto se registra como una diferencia de robustez, no como una ventaja de rendimiento.
- Retorno temprano de la calculadora: Como se ve en el código, una llamada exitosa al nodo calculadora establece directamente la respuesta final y termina el flujo de trabajo de forma anticipada. Esta es una optimización significativa que se aplica de manera consistente, evitando que la ruta de la calculadora invoque innecesariamente los LLMs de generar y calificar_respuesta.
- Alineación con DSPy. Para mantener la equidad con las líneas base no-CoT, DSPy utiliza dspy.Predict (sin CoT) para el Enrutador y el Generador de Respuestas. Las firmas reflejan los contratos de nodos de otros frameworks; cuando está disponible, los conteos de tokens utilizan el uso reportado por el modelo, de lo contrario se recurre a tiktoken.
3. Instrumentación y métricas
El proceso de medición fue idéntico, utilizando utilidades y principios compartidos.
- Latencia: Se utilizó time.perf_counter() de alta precisión para todas las mediciones de tiempo. La Sobrecarga del Framework se calcula consistentemente como Latencia Total – Latencia de Llamadas Externas.
- Tokenización: Todos los conteos de tokens para prompts y completaciones se calcularon utilizando tiktoken, la codificación cl100k_base, asegurando una única fuente de verdad para las métricas de tokens. La métrica de “Tokens promedio” reportada en los resultados representa la suma acumulada de todos los tokens de entrada (prompt) y salida (completación) para cada llamada a LLM (por ejemplo, enrutador, calificadores, generador) dentro de un único flujo de trabajo de consulta.
- Gestión de estado: Aunque la sintaxis de implementación varía (TypedDict de LangGraph, clase de LlamaIndex, diccionario de LangChain), la estructura del estado es funcionalmente idéntica. Cada framework pasa el mismo conjunto de claves (pregunta, documentos, resultados_web, etc.) entre nodos, asegurando que la lógica de flujo de control opere sobre la misma información.
Al imponer estas estrictas estandarizaciones a nivel de código, este benchmark pretende ir más allá de las comparaciones superficiales y ofrecer un análisis replicable del rendimiento de los frameworks bajo una política fija de RAG.
Interpretando los resultados:
- Se puede concluir: En esta configuración específica y altamente controlada, la sobrecarga de orquestación tiende a ser menor; las diferencias están impulsadas principalmente por los conteos de tokens y las rutas de herramientas.
- En esta configuración específica y altamente controlada, la sobrecarga del framework es insignificante.
- Las diferencias de rendimiento fueron impulsadas por el conteo de tokens y las variaciones en las rutas de herramientas.
- No se puede generalizar: Los resultados son específicos de esta arquitectura, modelos, prompts, recuperador y proveedor web; cambiar estos puede alterar las clasificaciones.
Experiencia del desarrollador: una comparación cualitativa
El rendimiento no es el único factor; cómo se siente construir con un framework es igualmente importante.
- LangGraph: El gráfico declarativo
Utiliza un paradigma primero el gráfico. Defines nodos y los conectas con aristas (incluyendo add_conditional_edges), así el flujo de control es parte de la arquitectura. El estado se tipifica mediante un TypedDict con actualizaciones estilo reductor (Annotated[…, add]).- Elige LangGraph para: flujos de trabajo complejos con múltiples ramas, reintentos y ciclos; su estructura escala en robustez y mantenibilidad a medida que los agentes crecen.
- LlamaIndex: Orquestación imperativa
Un script procedural donde el flujo de control es el estándar de Python if/else; el “gráfico” vive en tu código. El estado es una clase dedicada PipelineState, y el framework proporciona primitivas de recuperación limpias (VectorStoreIndex → .as_retriever(k=5)).- Elige LlamaIndex para: flujos de trabajo legibles y de un solo archivo donde valoras una lógica procedural clara y una depuración sencilla.
- LangChain: Imperativo con componentes declarativos
La orquestación sigue siendo un script de Python, pero las tareas individuales son pequeñas cadenas componibles utilizando el operador | (por ejemplo, prompt | llm | parser). El estado es un diccionario de Python flexible y no tipado.- Elige LangChain para: Prototipado rápido o equipos que ya están en el ecosistema de LangChain y prefieren componer pequeñas unidades declarativas dentro de un controlador imperativo más grande.
- Haystack: Orquestación manual basada en componentes Componentes tipados y reutilizables (@component) con E/S explícitas, mientras que el flujo de control permanece en Python simple (if/else). Fácil de intercambiar LLM/recuperador/backends web, además de instrumentación por paso de primera clase (tiempo externo vs. del framework).
- Elige Haystack para: pipelines listas para producción, testeables con contratos claros y control detallado.
- DSPy: Programas con prioridad de firma (menos líneas de código)
Define una tarea mediante una firma (entradas/salidas + intención), luego la implementa con Módulos que encapsulan el prompting y las llamadas a LLM. Centraliza el manejo de prompts/uso y elimina el código pegamento; intercambiar internos (por ejemplo, Predict ↔ CoT) no cambia el contrato.- Elige DSPy para: mínimo código repetitivo, flujos legibles de un solo archivo, desarrollo basado en contratos (con optimizadores opcionales).
Intercambiando rendimiento óptimo por comparabilidad
- LangGraph podría destacar con sus optimizaciones nativas de grafos cuando se le permite usar ejecución paralela, almacenamiento en caché de estado y su sistema de aristas condicionales para lógica de ramificación compleja.
- DSPy podría mostrar resultados dramáticamente diferentes al usar sus optimizadores de firma (como MIPROv2) y el prompting de Cadena de Pensamiento, lo que puede mejorar significativamente la calidad de las respuestas.
- Haystack podría aprovechar su almacenamiento en caché listo para producción, características de procesamiento por lotes y optimizaciones a nivel de componente que deshabilitamos por equidad.
- LlamaIndex podría beneficiarse de sus estrategias avanzadas de indexación, motores de consulta y capacidades multimodales que no se ejercitaron en este benchmark.
- LangChain podría brillar con su extenso ecosistema de herramientas y las optimizaciones de LCEL (LangChain Expression Language) cuando no está limitado a nuestro conjunto de herramientas estandarizado.
El “mejor” framework depende de si optimizas para: velocidad de desarrollo, mantenibilidad, rendimiento o patrones arquitectónicos específicos.
Conclusión
En un pipeline de RAG agéntico bien ajustado, la sobrecarga de orquestación suele ser una porción pequeña. Lo que mueve la aguja es cuántos tokens procesas y qué herramientas invocas, ambas moldeadas por los prompts, la recuperación y el enrutamiento. El framework “correcto” depende en última instancia del estilo de orquestación preferido de tu equipo: gráficos declarativos (LangGraph), scripts imperativos (LlamaIndex), cadenas componibles (LangChain), componentes modulares (Haystack) o programas con prioridad de firma (DSPy) que minimizan el código repetitivo.
Lectura adicional
Explora otros benchmarks de RAG, como:
- Modelos de Embedding: OpenAI vs Gemini vs Cohere
- Mejor Base de Datos de Vectores para RAG: Qdrant vs Weaviate vs Pinecone
- Benchmark de RAG agéntico: enrutamiento multi-base de datos y generación de consultas
- RAG híbrido: Potenciando la Precisión del RAG
Cita este benchmark
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sarı, Ekrem},
title = {{RAG Frameworks: LangChain vs LangGraph vs LlamaIndex}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/rag-frameworks}},
note = {AIMultiple. Recuperado el 3 de Junio de 2026}
}
Sé el primero en comentar
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.