Herramientas CLI de Agentic: Codex vs Claude Code
Las herramientas de línea de comandos de Agentic son herramientas de codificación con IA que permiten crear y eliminar archivos, ejecutar comandos, planificar y ejecutar la codificación de todo el proyecto. Evaluamos el rendimiento de las herramientas líderes en 10 escenarios reales de desarrollo web, realizando aproximadamente 600 comprobaciones de validación atómica por agente y más de 5000 ejecuciones de pruebas automatizadas en total, incluyendo la lógica del backend, la funcionalidad del frontend y la verificación de la consistencia en múltiples ejecuciones.
Resultados de referencia de Agentic CLI
Análisis del rendimiento de las herramientas CLI de Agentic
Codex tiene la puntuación general más alta (67,7 %) y el mejor rendimiento de backend (58,5 %). Su puntuación de backend supera en más de 5 puntos porcentuales a la del siguiente mejor rendimiento, Junie (54,3 %).
Junie ocupa el segundo lugar en la clasificación general (63,5%), combinando una sólida corrección del backend (54,3%) con un excelente rendimiento del frontend (85,0%). Su diferencia entre backend y frontend (30,7 puntos porcentuales) es moderada en comparación con otros agentes, y completó las 10 tareas con la infraestructura de backend lista en 9 de ellas.
Claude Code obtiene la puntuación más alta en el frontend (95,0 %), pero su puntuación en el backend (38,6 %) reduce su resultado general (55,5 %). Esto ilustra la dinámica principal del gráfico: el rendimiento del frontend es relativamente alto para varios agentes, mientras que la precisión del backend y la disciplina contractual son los factores que más influyen en la diferencia de posiciones en la clasificación.
La mayor diferencia entre la interfaz de usuario y el backend se observa en Claude Code (95,0 % de frontend frente a 38,6 % de backend). En cambio, Codex combina una alta puntuación en el frontend (89,2 %) con la mejor puntuación en el backend, razón por la cual lidera en general con una ponderación de 0,7 para el backend y 0,3 para el frontend.
Los agentes de menor rango fallan por diferentes razones. Goose obtiene una puntuación cercana a cero tanto en el backend (3,1 %) como en el frontend (10,0 %), lo que indica problemas básicos de ejecución y completitud. Forge y Cline muestran puntuaciones moderadas en el frontend (45,8 % y 33,3 %), pero puntuaciones bajas en el backend (20,1 % y 26,7 %), lo que concuerda con que los problemas de contrato y enrutamiento del backend dominan sus resultados.
Velocidad vs. puntuación y uso de fichas vs. puntuación
Evaluamos la eficiencia del tiempo de ejecución utilizando el tiempo de ejecución promedio (segundos), el uso efectivo de tokens (entrada + salida) y la puntuación de precisión combinada:
Aider se sitúa en la zona más equilibrada de la gráfica. Con una puntuación combinada del 52,7 %, completa las tareas en 257 segundos y consume 126 000 tokens. Es el único agente que combina una precisión media-alta con un tiempo de ejecución relativamente bajo y un consumo moderado de tokens.
Codex alcanza la puntuación general más alta (67,7%), pero a un coste mayor. Su tiempo de ejecución promedio es de 426 segundos y el uso de tokens es de 258.000. La compensación en eficiencia parece ser proporcional a su mejora en precisión.
Junie ocupa el segundo lugar en precisión (63,5 %) con un tiempo de ejecución promedio de 483 segundos y 370 000 tokens efectivos. En comparación con Codex, consume un 43 % más de tokens, lo que resulta en una disminución de 4,2 puntos porcentuales en la puntuación. Su relación token-precisión es menos favorable que la de Aider o Codex, pero supera a Claude Code tanto en precisión como en eficiencia de tokens.
Claude Code es el agente más caro entre los de mejor rendimiento. Ocupa el tercer lugar en precisión (55,5 %), pero requiere 745 segundos y 397 000 tokens. En comparación con Aider, Claude consume más del triple de tokens para obtener un aumento de 2,8 puntos porcentuales en la puntuación.
Kiro CLI es el agente más rápido, completando la operación en 168 segundos y obteniendo una puntuación combinada del 58,1 %. Sin embargo, Kiro no reveló el uso de tokens. En su lugar, medimos el consumo de créditos (46,1 créditos). Una comparación completa de eficiencia es incompleta para Kiro, pero considerando su consumo de créditos, es uno de los más económicos.
En el extremo inferior, Goose demuestra una eficiencia deficiente. Consume 300 000 tokens y tarda 587 segundos, obteniendo una puntuación de tan solo el 5,2 %. En este caso, un alto consumo de tokens no se traduce en una mayor precisión.
En general, un mayor consumo de tokens no se correlaciona consistentemente con una mayor precisión. El comportamiento arquitectónico de reintento y la estrategia de validación parecen influir más en el uso de tokens que la profundidad bruta de la resolución de problemas.
A continuación, puede consultar nuestra metodología .
Cómo funcionan las herramientas CLI de Agentic
Las herramientas CLI de Agentic son agentes autónomos que operan dentro de la terminal. Si bien la mayoría de los usuarios las implementan para tareas de programación, pueden ejecutar cualquier flujo de trabajo que se pueda realizar mediante comandos de shell.
Estos agentes suelen operar en un ciclo que consta de tres fases:
- Recopilar contexto
- Tomar medidas
- Verificar resultados
Tras la verificación, el agente recopila información contextual actualizada y repite el ciclo hasta que completa la tarea o alcanza una condición de parada.
El bucle está influenciado por dos fuentes:
- El usuario humano, que proporciona la tarea inicial y puede interrumpir la ejecución
- El modelo realiza planificación, razonamiento y selección de acciones.
El marco de trabajo del agente proporciona estructura al modelo. Define cómo debe planificar el modelo, cuándo debe ejecutar comandos, cómo debe validar los resultados y qué herramientas están disponibles. Estas herramientas pueden incluir la ejecución de comandos, el acceso al sistema de archivos, el control del navegador , el uso del equipo , integraciones con MCP o habilidades reutilizables.
Las distintas arquitecturas de agentes imponen diferentes estrategias de planificación, políticas de reintento y lógica de verificación. Algunos agentes priorizan la precisión y el razonamiento profundo a costa de un mayor consumo de tokens y una mayor latencia. Otros priorizan la velocidad y un menor coste, aunque con una menor robustez en su comportamiento.
Inteligencia de modelos frente a arquitectura de agentes
Las diferencias de rendimiento entre las herramientas CLI basadas en agentes no provienen de una sola fuente. Surgen de dos capas: el modelo base y el marco de orquestación que lo envuelve.
El modelo base determina la eficacia con la que el sistema comprende los requisitos, planifica tareas de varios pasos y genera código correcto. Si el modelo interpreta erróneamente una restricción o produce una lógica incorrecta, ninguna orquestación podrá compensar completamente ese error.
Sin embargo, la arquitectura del agente determina cómo se utiliza ese modelo. Decide cómo se recopila el contexto del espacio de trabajo, cuándo se ejecutan los comandos de la consola, cómo se validan las salidas y si el sistema reintenta la operación tras un fallo. Estas decisiones influyen en el comportamiento en tiempo de ejecución, el coste y la fiabilidad.
Dos agentes, impulsados por modelos igualmente capaces, pueden comportarse de manera diferente. Uno podría reintentar agresivamente tras un fallo parcial, consumiendo más tokens pero recuperándose de los errores iniciales. Otro podría finalizar rápidamente tras la primera inconsistencia. Uno podría exigir una validación estricta antes de continuar, mientras que el otro podría seguir adelante con suposiciones no verificadas.
Esta prueba de rendimiento evalúa el sistema completo. No aísla la inteligencia del modelo de la lógica de orquestación. Si un agente consume demasiados tokens o falla un contrato de backend, la causa puede estar en la calidad de la planificación, la política de reintentos, la gestión del contexto o la rigurosidad de la validación.
Comprender esta distinción es fundamental. Un alto uso de tokens no implica necesariamente un razonamiento más profundo, y una puntuación más baja no implica automáticamente una menor capacidad del modelo subyacente. En entornos autónomos, la arquitectura y el razonamiento del modelo interactúan continuamente.
Comportamientos del agente en la tarea 6
Evaluamos agentes en 10 tareas. A continuación, presentamos un análisis detallado de la Tarea 6 para ilustrar cómo se comportan las diferentes arquitecturas de agentes bajo las mismas restricciones.
Tarea 6: Sistema de gestión de incidencias (Web)
La tarea 6 requería construir un sistema de tickets de mesa de ayuda de pila completa con:
- Dos roles de usuario (cliente y agente)
- Autenticación basada en JWT
- Transiciones de flujo de trabajo de estado estricto
- Aislamiento de datos (código 404 en lugar de 403 para acceso entre usuarios)
- backend de FastAPI
- Interfaz React/Vue/Svelte + Vite
- Comandos de ejecución deterministas
La prueba de humo validó:
- chequeo médico
- Autenticación de doble rol
- Operaciones CRUD de tickets
- Tarea y respuestas
- Transiciones de estado
- Aplicación de roles
- aislamiento de datos
- Comportamiento de inicio de sesión y posterior al inicio de sesión en la interfaz de usuario
Esta tarea hace hincapié en la gestión del estado, la correcta autenticación, la disciplina de los contratos REST y la integración entre el frontend y el backend. Visita GitHub para ver los detalles de la tarea.
Códice
Instalación
Instalar globalmente con:
- npm install -g @openai/codex
Como alternativa, instálelo globalmente con Homebrew (macOS/Linux).
- brew install –cask codex
Autenticación
Tras configurar Codex, puede continuar con su cuenta de ChatGPT o con su clave API OpenAI. No hay opciones de proveedor disponibles.
Informe de tareas
Codex construyó un sistema funcionalmente correcto, pero se desvió del contrato REST especificado. La elección del método redujo el cumplimiento estricto a pesar de la lógica de negocio correcta.
Comportamiento del backend
La autenticación, las operaciones CRUD de tickets, las respuestas y las transiciones de estado funcionaron correctamente. La aplicación de roles y el aislamiento de datos se implementaron adecuadamente.
El problema principal fue la incompatibilidad del método HTTP. Codex implementó /tickets/{id}/assign y /tickets/{id}/status como puntos finales PATCH, mientras que la prueba de humo requería PUT.
El modo adaptativo recuperó parte de la funcionalidad al intentar métodos alternativos. El modo estricto falló en todos los pasos vinculados a esos puntos finales.
Comportamiento de la interfaz de usuario
El frontend superó todas las validaciones de la interfaz de usuario. El flujo de inicio de sesión y el estado posterior al inicio de sesión se comportaron correctamente.
Junio
Instalación
Junie está disponible a través de JetBrains Toolbox o como una interfaz de línea de comandos independiente:
- curl -fsSL https://junie.jetbrains.com/install | bash
Autenticación
Continúa con tu cuenta de JetBrains o genera una JUNIE_API_KEY en junie.jetbrains.com/cli, o exporta tu propia clave API desde Anthropic, OpenAI, Google u otros proveedores compatibles. Hay varias opciones de proveedores disponibles.
Informe de tareas
Junie creó un sistema full-stack completo en 327 segundos. La autenticación, las operaciones CRUD y el aislamiento de datos funcionaron correctamente. Dos decisiones de diseño de los puntos finales provocaron seis fallos en el backend. El frontend superó todas las validaciones funcionales, pero mostró una interfaz de solo texto sin estilo visual ni personalización de marca.
Comportamiento del backend
Junie generó un backend FastAPI con 8 archivos y un frontend React + Vite con Tailwind CSS. Los datos iniciales incluían 2 usuarios y 3 tickets con diferentes estados.
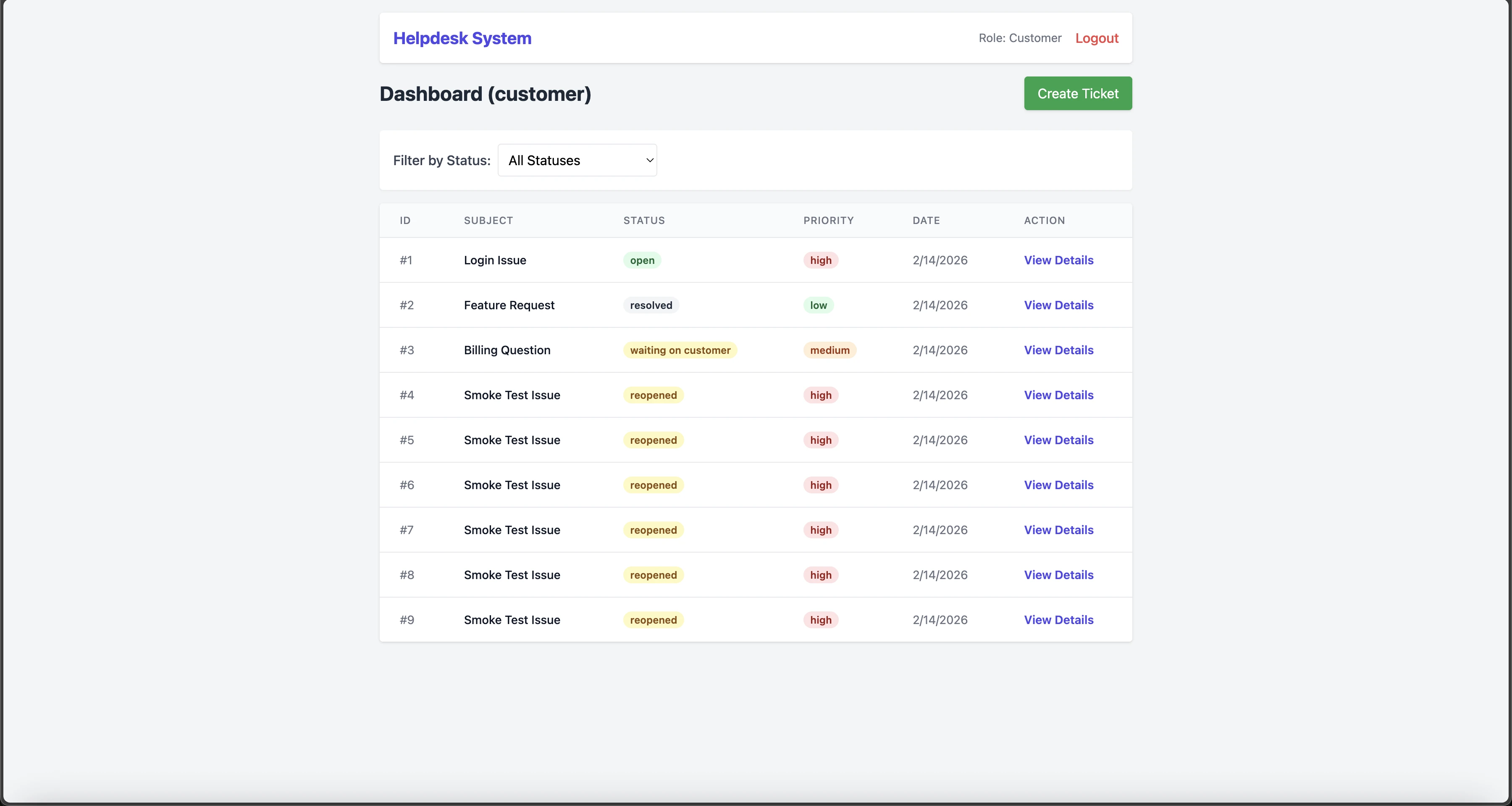
La autenticación, las operaciones CRUD de tickets, las respuestas, la vista de detalles y el aislamiento de datos funcionaron correctamente. Nueve de los 16 pasos de la API se completaron con éxito.
Los seis pasos fallidos se debieron a dos problemas. Primero, /tickets/{id}/assign se implementó como POST en lugar del PUT esperado, lo que provocó que el paso de asignación fallara. Segundo, no existía un punto final dedicado /tickets/{id}/status. Las transiciones de estado se gestionaban a través de un punto final PUT unificado /tickets/{id} con un campo de cuerpo. La prueba de humo se dirigió directamente a /tickets/{id}/status y devolvió un error 404.
La lógica de transición se implementó correctamente. El mapa de transición válido establecía que de abierto a en curso, de en curso a esperando al cliente o resuelto, de resuelto a reabierto y de reabierto a en curso. En el gestor de actualizaciones unificado se incluían restricciones de rol para resolver (solo para agentes) y reabrir (solo para clientes). El punto final de asignación también realizaba automáticamente la transición de los tickets abiertos a en curso.
Comportamiento de la interfaz de usuario
La interfaz de usuario superó los 8 pasos de validación. El formulario de inicio de sesión se mostró correctamente, la autenticación se mantuvo y el comportamiento posterior al inicio de sesión funcionó según lo previsto. No se produjeron fallos en tiempo de ejecución ni errores en la consola.
Kiro CLI
Instalación
Para macOS/Linux/WSL:
- curl -fsSL https://cli.kiro.dev/install | bash
AppImage alternativa para Linux (opción portátil):
- Descargar: https://desktop-release.q.us-east-1.amazonaws.com/latest/kiro-cli.appimage
Luego ejecuta:
- chmod +x kiro-cli.appimage && ./kiro-cli.appimage
Autenticación
Puedes continuar con tu plan Kiro-Code. No hay opciones de proveedores disponibles.
Informe de tareas
Kiro logró la implementación más rápida y compacta. Las transiciones de estado, la aplicación de roles y el aislamiento de datos se implementaron correctamente a nivel lógico.
Sin embargo, el mismo patrón de diseño de punto final de actualización unificada que se observó en Aider provocó seis fallos en el contrato. Un problema con el ciclo de vida del frontend redujo aún más la puntuación de la interfaz de usuario. El sistema es estructuralmente sólido, pero se desvía del diseño de API especificado.
Comportamiento del backend
Kiro generó una implementación completa y compacta en aproximadamente 97 segundos. El backend consistía en un archivo main.py de 324 líneas, y el frontend era una aplicación React de un solo archivo de 276 líneas. En total, se generaron solo 9 archivos. Los datos iniciales incluían 4 tickets de muestra con diferentes estados.
La autenticación, las operaciones CRUD de tickets, las respuestas, la vista de detalles y el aislamiento de datos funcionaron correctamente. Nueve de los 16 pasos de la API se completaron con éxito.
Los seis pasos que fallan corresponden a /tickets/{id}/assign y /tickets/{id}/status. Kiro implementó un endpoint PATCH unificado /tickets/{id} que actualiza el estado, la prioridad y la asignación mediante campos JSON. La lógica de negocio es correcta, pero la estructura del endpoint no coincide con el contrato previsto, lo que genera respuestas 404.
Comportamiento de la interfaz de usuario
La comprobación previa del backend se realizó correctamente y el frontend se inició sin problemas. Vite se lanzó sin fallos en tiempo de ejecución.
Sin embargo, el formulario de inicio de sesión no se cargó. Playwright agotó el tiempo de espera tras 7 segundos esperando el campo de entrada de correo electrónico. El diagnóstico de la consola mostró un error 422 durante la carga inicial de la página, probablemente causado por una llamada a /auth/me ejecutada al montar la aplicación sin un token válido. Esto impidió que se cargara el componente de inicio de sesión y bloqueó los pasos restantes de la interfaz de usuario.
Código Claude
Instalación
Para macOS/Linux/WSL, dependiendo de su gestor de paquetes preferido, puede instalar Claude Code con cualquiera de las siguientes opciones:
- curl -fsSL https://claude.ai/install.sh | bash
- brew install –cask codex
Autenticación
Tras configurar Claude Code, puede continuar con su cuenta de Claude. No hay opciones de proveedores disponibles.
Informe de tareas
Claude Code produjo uno de los códigos base más estructurados para esta tarea. Sin embargo, un problema fundamental de validación de JWT dejó el backend inutilizable.
Esto pone de relieve una distinción clave en la evaluación de agentes: la integridad estructural no compensa la corrección de la autenticación.
También consumió el mayor volumen de tokens entre los agentes evaluados en la Tarea 6.
Comportamiento del backend
Los puntos finales de inicio de sesión devolvieron el código 200 y emitieron tokens JWT correctamente. Sin embargo, todas las solicitudes autenticadas posteriores devolvieron el código 401: "No se pudieron validar las credenciales".
La causa principal parece ser una discrepancia entre OAuth2PasswordBearer(tokenUrl=”auth/login”) y el prefijo de ruta /auth. El adaptador Smoke detectó correctamente el punto final de inicio de sesión, pero el middleware no aceptó los tokens emitidos.
Como resultado, 13 de los 16 pasos del backend fallaron.
Además, Claude Code implementó un único punto final PATCH /tickets/{id} para las actualizaciones en lugar de puntos finales dedicados /assign y /status. Sin embargo, esta decisión de diseño se volvió irrelevante debido al fallo de autenticación.
Comportamiento de la interfaz de usuario
El formulario de inicio de sesión se mostró correctamente. El envío del formulario devolvió el código 200. Sin embargo, después de iniciar sesión, Playwright detectó un fallo de navegación:
“El contexto de ejecución quedó destruido.”
Los registros del navegador mostraron respuestas 401 en las llamadas a la API autenticadas, lo que provocó que se rompiera el estado posterior al inicio de sesión.
Ayudante
Instalación
Si ya tienes instalado Python 3.8-3.13, primero instala Aider:
- python -m pip instalar instalación-ayder
- ayudante-instalación
Autenticación
Inicie sesión en su cuenta OpenRouter y autorícela, o exporte su clave API en su entorno con:
- export OPENROUTER_API_KEY=”sk-or-v1-…”
Informe de tareas
Aider era el constructor más rápido y eficiente en cuanto al uso de tokens. Sin embargo, el diseño de su API se desviaba de las especificaciones y la interfaz de inicio de sesión no se mostraba correctamente.
Comportamiento del backend
La autenticación, las operaciones CRUD de tickets, las respuestas, la vista detallada y el aislamiento de datos se implementaron correctamente.
En lugar de usar puntos finales dedicados para /assign y /status, Aider utilizó un punto final PUT unificado /tickets/{id} para todas las actualizaciones. La prueba de humo esperaba puntos finales separados, lo que provocó errores 404 en los pasos de asignación y estado.
Comportamiento de la interfaz de usuario
La interfaz mostraba el contenido, pero el formulario de inicio de sesión no aparecía. Playwright agotó el tiempo de espera al intentar ingresar el correo electrónico. Los pasos posteriores de la interfaz de usuario quedaron bloqueados.
Código abierto
Instalación
Para macOS/Linux/WSL:
- curl -fsSL https://opencode.ai/install | bash
Instalar globalmente con:
- npm i -g opencode-ai
Para macOS/Linux, tenga en cuenta su gestor de paquetes preferido:
- bun add -g opencode-ai
- brew install anomalyco/tap/opencode
- paru -S código abierto
Autenticación
Hay muchas opciones de proveedores, seleccione el que desee y autentíquese con /connect.
Informe de tareas
OpenCode produjo la implementación que mejor se ajustaba a las especificaciones, con una única desviación en un caso límite. Además, consumió el menor volumen de tokens entre todos los agentes que participaron en esta tarea.
Comportamiento del backend
La autenticación, las operaciones CRUD, las respuestas, la asignación, las transiciones de estado, la aplicación de roles y el aislamiento de datos se implementaron correctamente.
Los puntos finales /tickets/{id}/assign y /tickets/{id}/status se implementaron según lo previsto.
El único paso que falló ocurrió cuando el agente intentó cambiar el estado a "en curso" después de la asignación. Dado que la operación de asignación ya había cambiado el estado del ticket a "en curso", la segunda transición devolvió un error 400 debido a la estricta aplicación de la regla de no operación.
El comportamiento del sistema en segundo plano era lógicamente correcto, pero la prueba básica preveía un éxito idempotente para las transiciones repetidas.
Comportamiento de la interfaz de usuario
La interfaz de usuario superó los 8 pasos de validación. El inicio de sesión se visualizó correctamente, la autenticación se mantuvo y el comportamiento posterior al inicio de sesión funcionó según lo previsto.
Fragua
Instalación
Para macOS/Linux/WSL:
- curl -fsSL https://opencode.ai/install | bash
Autenticación
Configure sus credenciales de proveedor de forma interactiva mediante:
- Inicio de sesión del proveedor de Forge
Y elige tu proveedor.
Informe de tareas
Una única configuración errónea de enrutamiento desencadenó fallos en cascada en el sistema backend. El número relativamente bajo de tokens de salida sugiere una profundidad de implementación limitada.
Comportamiento del backend
El inicio de sesión se realizó correctamente y se emitieron los tokens.
La creación del ticket devolvió redirecciones 307 en lugar de 200/201. Debido a que la creación del ticket falló, los pasos subsiguientes que hacen referencia a $created_ticket.id fallaron con errores 422.
Es probable que las respuestas 307 se deban al comportamiento de redirección de la barra diagonal final en FastAPI.
Los puntos finales /assign y /status devolvieron 404.
Comportamiento de la interfaz de usuario
El frontend mostraba el contenido, pero los componentes de inicio de sesión no se renderizaban correctamente debido a errores de ejecución en AuthContext.tsx. Los pasos posteriores de la interfaz de usuario quedaron bloqueados.
Gemini CLI
Instalación
Ejecuta al instante con:
- npx @google/gemini-cli
Instalar globalmente con:
- npm install -g @google/gemini-cli
Instalar globalmente con Homebrew (macOS/Linux):
- brew install gemini-cli
Instalar globalmente con MacPorts (macOS):
- sudo port install gemini-cli
Instalar con Anaconda (para entornos restringidos):
- conda create -y -n gemini_env -c conda-forge nodejs
- conda activate gemini_env
Autenticación
Opción 1: Iniciar sesión con Google (inicio de sesión OAuth utilizando su cuenta Google):
Inicia Géminis y escribe:
- export GOOGLE_CLOUD_PROJECT=”TU_ID_DE_PROYECTO”
Entonces, comienza con Géminis.
Opción 2: Clave API de Gemini
Inicia Géminis y escribe:
- export GEMINI_API_KEY=”TU_CLAVE_API”
Entonces, comienza con Géminis.
Opción 3: IA de vértice
Inicia Géminis y escribe:
- exportar GOOGLE_API_KEY=”TU_CLAVE_API”
- exportar GOOGLE_GENAI_USE_VERTEXAI=true
Informe de tareas
Gemini CLI generó un backend robusto, pero falló debido a la incompatibilidad de la cadena de herramientas del frontend. Además, consumió el mayor volumen de tokens entre las implementaciones de backend exitosas.
Comportamiento del backend
La autenticación, las operaciones CRUD, las respuestas, la asignación, la aplicación de roles y el aislamiento de datos se implementaron correctamente.
Sin embargo, el punto final /tickets/{id}/status no estaba presente en absoluto, lo que provocaba que todos los pasos de transición de estado devolvieran un error 404.
Comportamiento de la interfaz de usuario
El frontend no se inició. Se instaló Vite 7.3.1, que requiere Node.js 20.19 o superior, mientras que el entorno de prueba ejecuta Node.js 18.18.0. La API crypto.hash requerida por Vite no estaba disponible.
Como resultado, la interfaz de usuario nunca se inició y obtuvo una puntuación de 0/8.
Cline
Instalación
Instalar globalmente con:
- npm install -g cline
Autenticación
Al escribir `cline auth`, puedes seleccionar tu cuenta de Cline o continuar con el proveedor que prefieras.
Informe de tareas
El mecanismo de limitación de errores de Cline interrumpió la compilación antes de su finalización. La estructura del backend muestra la intención arquitectónica correcta, pero los problemas de registro de rutas y la implementación incompleta impidieron la validación funcional.
La ausencia de una interfaz de usuario y los fallos en cascada del sistema de backend hacen que este resultado sea uno de los más débiles en la Tarea 6.
Comportamiento del backend
Cline generó un backend con cinco archivos: main.py, models.py, schemas.py, auth.py y database.py, junto con un archivo requirements.txt. La estructura incluía modelos adecuados, andamiaje de autenticación JWT y stubs de endpoints.
Sin embargo, el agente alcanzó su límite de ocho errores durante el desarrollo del backend y se interrumpió antes de completar el sistema.
Solo los puntos finales de inicio de sesión funcionaron correctamente. Tres de los 16 pasos de la API se completaron con éxito.
La creación del ticket devolvió redirecciones 307 en lugar de 200 o 201, probablemente debido a discrepancias en la ruta con la barra diagonal final. Dado que la creación del ticket falló, el valor de $created_ticket.id nunca se capturó. Todos los pasos posteriores que hacían referencia al ID del ticket pasaron el valor de cadena literal, lo que provocó errores 422.
Los puntos finales /tickets/{id}/assign y /tickets/{id}/status no se implementaron, lo que resultó en respuestas 404.
Esto produjo un patrón de fallos en cascada similar al de Forge, donde un problema de enrutamiento inicial invalidó los pasos posteriores.
Comportamiento de la interfaz de usuario
El backend se inició correctamente. Sin embargo, el directorio frontend/ estaba vacío y no existía ningún archivo package.json.
Solo se completó con éxito el paso de verificación previa del servidor. Todos los demás pasos de la interfaz de usuario quedaron bloqueados.
Ganso
Instalación
Para macOS/Linux/WSL:
- curl -fsSL https://github.com/block/goose/releases/download/stable/download_cli.sh | bash
Modelo: Vista previa del Gemini 3 Pro (a través de OpenRouter)
Tiempo: 1297 s
Tokens: 17k de entrada / 752 de salida
Puntuación de la API: 60%
Puntuación de la interfaz de usuario: 0%
Goose demostró una capacidad limitada de autocorrección, pero no logró completar el requisito de pila completa. Los problemas de fiabilidad durante las repeticiones generan inquietudes sobre la estabilidad.
Comportamiento del backend
La autenticación, las operaciones CRUD de tickets, las respuestas, la vista detallada y el aislamiento de datos funcionaron correctamente.
Sin embargo, los puntos finales /assign y /status no se implementaron, lo que provocó respuestas 404 para todos los pasos relacionados.
En una versión anterior, Goose encontró errores de compatibilidad con bcrypt, que se corrigieron automáticamente al fijar la versión de la dependencia, y finalmente lanzó el backend.
Una ejecución posterior falló debido a un error de decodificación de flujo después de generar un mínimo de archivos.
Comportamiento de la interfaz de usuario
No se creó ningún frontend. El directorio del frontend estaba vacío y no existía ningún archivo package.json. La prueba de interfaz de usuario falló inmediatamente.
Herramientas de codificación de IA
Las herramientas de codificación de IA se pueden agrupar en tres categorías:
- Agentic CLI: Herramientas para flujos de trabajo de desarrollo basados en terminal, que permiten generar, editar y refactorizar código mediante indicaciones e interacciones de línea de comandos.
- Ejemplos: Aider, Junie, Opencode, Claude Code, Codex
- Editores de código de IA : También conocidos como IDE agenciales, estas herramientas proporcionan una interfaz gráfica de usuario similar a la de VS Code (la mayoría de ellas están basadas en VS Code).
- Ejemplos: Antigravedad, Cursor, Código Kiro, Windsurf
- Creadores de aplicaciones a partir de indicaciones : plataformas de bajo código/sin código para crear aplicaciones utilizando indicaciones en lenguaje natural y flujos de trabajo visuales.
- Ejemplos: Bolt, Lovable, v0.dev, Firebase Studio, Dazl
Herramientas de revisión de código basadas en IA
A medida que el código generado por IA se vuelve más común, las herramientas de revisión de código son esenciales para detectar errores y vulnerabilidades. Evaluamos las mejores herramientas en 309 solicitudes de extracción (PR) en nuestra prueba comparativa RevEval .
¿Qué pueden hacer las herramientas CLI basadas en agentes?
En herramientas como Codex, Junie, Kiro y Claude Code, las capacidades comunes incluyen:
- Trabajo integral de código: Crear y modificar archivos, corregir errores, refactorizar código y ejecutar pruebas o analizadores de código directamente desde la terminal.
- Flujos de trabajo basados en agentes: Realizan tareas de varios pasos, como encadenamiento de tareas, resolución de problemas, búsqueda y depuración iterativa.
- Git y gestión de proyectos: Revisa el historial, resuelve fusiones, gestiona ramas y crea confirmaciones o solicitudes de extracción.
- Command ejecución y automatización: Ejecuta comandos de shell, automatiza análisis y traduce lenguaje natural en operaciones CLI complejas.
- Manejo de contexto profundo: Opera en repositorios completos teniendo en cuenta las dependencias y la estructura del proyecto.
- Flexibilidad del modelo: Admite múltiples modelos en la nube y, en algunos casos, modelos locales; algunas herramientas permiten usar su propia clave API o elegir entre diferentes planes.
- Acceso controlado o en entorno aislado: Ofrece modos que van desde la solo lectura hasta la automatización completa, a menudo con entornos aislados por motivos de seguridad.
Metodología
Evaluamos a los agentes en una configuración de ejecución única para medir sus capacidades autónomas sin intervención humana. Posteriormente, los agentes fueron evaluados mediante nuestras pruebas de humo de backend y frontend para medir la preparación de la infraestructura y la corrección del comportamiento.
Las puntuaciones reflejan la fiabilidad con la que cada agente produjo sistemas ejecutables y cuántos requisitos funcionales superaron la validación.
Configuración del modelo
Nuestro objetivo era utilizar Google's gemini-3-pro-preview debido a su amplia ventana de contexto , adecuada para la orquestación de múltiples archivos y las indicaciones de tareas extensas. Sin embargo, algunas CLI de agentes están estrechamente vinculadas a proveedores específicos:
- Claude Code fue evaluado utilizando claude-opus-4-5-20251101 a través de la API oficial de Anthropic.
- Codex fue evaluado utilizando gpt-5.2-codex-medium a través de la configuración nativa de OpenAI.
Para estos agentes, la arquitectura actual de la interfaz de línea de comandos (CLI) no admite proveedores de modelos alternativos. Cada agente se evaluó con su configuración predeterminada. No se modificaron la temperatura, las políticas de reintento ni los parámetros de razonamiento.
Nuestro objetivo de evaluación era separar y medir:
- Capacidad de compilación (¿puede el agente generar código ejecutable?)
- Corrección del comportamiento del backend
- Corrección del comportamiento del frontend
- Fiabilidad de la orquestación autónoma
Versiones de la interfaz de línea de comandos (mediados de febrero de 2026)
- Opencode: v1.2.10
- Cline: v3.41
- Ayudante: v0.86.0
- Gemini CLI: v0.29.0
- Forge: v1.28.0
- Códice: 0.104.0
- Ganso: v1.25.0
- Claude Código: v2.1.62
- Junio: 888.212
- Kiro CLI: 1.26.0
Para obtener información sobre la metodología de evaluación, visite: Metodología de referencia para la codificación de IA
Leer más
Para aquellos que exploran el ecosistema más amplio de herramientas de desarrollo basadas en agentes, aquí están nuestros últimos puntos de referencia:
- Comparativa de MCP : Una comparación de los mejores servidores MCP para acceso web.
- Navegadores remotos : Cómo la infraestructura de navegadores emergente permite a los agentes de IA interactuar con la web de forma segura.
Cita este benchmark
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Kalelioğlu, Berk},
title = {{Herramientas CLI de Agentic: Codex vs Claude Code}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/agentic-cli}},
note = {AIMultiple. Retrieved Junio 3, 2026}
}Resultados y marcas de tiempo de 200 puntos de datos. Descargue los datos utilizados en este artículo como un archivo ZIP que contiene 2 archivos CSV y un README.




Sé el primero en comentar
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.