El futuro de los modelos de lenguaje grandes
Descubra el futuro de los modelos de lenguaje grandes explorando enfoques prometedores, como el autoentrenamiento, la verificación de hechos y la especialización dispersa, que podrían abordar las limitaciones de los LLM.
Comparativa de tasas de éxito de los LLM
Claude Sonnet 4.6 lideró el benchmark con una puntuación global de 0.748, con las variantes base y thinking empatadas hasta tres decimales. Claude Opus 4.8 (0.702), Opus 4.6 base (0.706) y Opus 4.6 thinking (0.729) le siguieron, otorgando a Anthropic los cinco primeros puestos. El primer modelo no Anthropic fue Gemini 3.5 Flash, en su variante thinking con 0.625. Las variantes de GPT se agruparon entre 0.57 y 0.60, con puntuaciones de backend más altas compensadas por la inestabilidad del frontend. Vea más en nuestro artículo del benchmark.
Metodología del Benchmark de LLM
Evaluamos los principales modelos de lenguaje grandes en 10 tareas de desarrollo de software utilizando un entorno de ejecución CLI agéntico. Cada modelo se ejecutó 3 veces por tarea (30 muestras por modelo, 270 celdas de validación por iteración) para estabilizar las puntuaciones y medir la varianza por celda. Todos los modelos se accedieron a través de OpenRouter en condiciones idénticas, mismo entorno, mismas instrucciones de tarea, mismo hardware.
Modelos evaluados
El benchmark incluye modelos disponibles a través de la API a fecha de junio de 2026. Todas las variantes listadas a continuación se probaron de forma independiente:
- Claude Sonnet 4.6 (base y thinking)
- Claude Opus 4.8
- Claude Opus 4.6 (base y thinking)
- Claude Opus 4.7
- Gemini 3.5 Flash (base y thinking)
- GPT 5.5 (thinking)
- GPT 5.4 Mini
- GPT 5.3 Codex
- MiniMax M3
- Grok 4.3
- Qwen 3.6 Plus (base y thinking)
- GLM 5.1 (base y thinking)
- Deepseek V4 Pro (base y thinking)
Entorno de pruebas
Cada agente y tarea comienza en un entorno limpio. Las instrucciones de la tarea se proporcionan en un archivo TASK.md. Un monitor de latidos de 20 minutos supervisa cada ejecución. Registramos códigos de salida, tiempo de ejecución, creación de archivos de backend y frontend, y el uso de tokens en tiempo real en las categorías de entrada, salida y caché.
Las tareas van desde sistemas de reservas hasta paneles interactivos. Todas requieren gestión de proyectos multifile y un entregable full-stack funcional.
Puntuación
Validación del backend: Los proyectos generados se despliegan en entornos aislados y se prueban contra un contrato YAML canónico que cubre escenarios de camino feliz, manejo de errores (400/403/409) y consistencia de datos. Se utilizan dos modos:
- Modo adaptativo valida la funcionalidad incluso cuando los nombres de las rutas difieren de la especificación
- Modo estricto exige una adherencia exacta al contrato (rutas, códigos de estado, campos de respuesta)
Puntuación del backend por celda: backend_overall = has_backend × (0.7 × adaptive_pass_rate + 0.3 × strict_pass_rate)
Validación de la UI: La automatización del navegador simula flujos de usuario reales, incluyendo pre-vuelos, renderizado, envío de formulario de inicio de sesión y comportamiento posterior al inicio de sesión. Ocho pasos divididos en dos grupos:
- Pasos de infraestructura (pre-vuelo del backend, renderizado del frontend, formulario de inicio de sesión visible, envío del inicio de sesión, inicio de sesión 2xx, sin fallo en tiempo de ejecución)
- Pasos de comportamiento (señal de autenticación tras inicio de sesión, señal de comportamiento tras inicio de sesión)
Puntuación de la UI por celda: ui_score = (behavior_passed / (behavior_passed + behavior_failed)) × (infra_passed / infra_total)
Los pasos de comportamiento bloqueados se excluyen del denominador de comportamiento para que una celda no se penalice doblemente cuando la aplicación no se carga.
Puntuación final: Final Score = (0.7 × backend_overall) + (0.3 × ui_score)
El backend tiene mayor peso porque los fallos lógicos a nivel de API suelen invalidar cualquier éxito del frontend.
Medición de costes
El coste por celda se calcula a partir del uso de tokens extraído de la respuesta de la LLM API. Los tokens de entrada en caché se restan del total de tokens de entrada para obtener la entrada efectiva (solo tokens recién procesados). Los tokens de salida nunca se almacenan en caché y permanecen sin cambios. Las tarifas por token se obtienen de los Precios de LLM en el momento de la prueba.
Limitaciones
- Alcance de las tareas: Las 10 tareas son construcciones de aplicaciones web full-stack. El benchmark no cubre tareas de razonamiento puro, resolución de problemas científicos, resumen o cargas de trabajo específicas de dominio (legal, médico, financiero). Las puntuaciones reflejan específicamente la capacidad de codificación agéntica.
- Acceso solo vía API: Todos los modelos se probaron a través de la API. Despliegues locales o en las instalaciones de estos mismos modelos pueden producir resultados diferentes dependiendo de la cuantización, el hardware y la configuración de inferencia.
- Instantánea en el tiempo: Las versiones de los modelos cambian. Los resultados reflejan la versión de la API activa en el momento de la prueba. Una actualización del modelo puede mover las puntuaciones en cualquier dirección sin previo aviso del proveedor.
- Estilo de llamada a herramientas: Los modelos difieren en cómo estructuran las escrituras y ediciones de archivos (por ejemplo,
apply_patchde OpenAI empaqueta una diferencia completa del archivo en una sola llamada; los modelos de Anthropic escriben y reeditan a través de múltiples llamadas). El número de llamadas a herramientas no es un indicador directo de la calidad. - Entorno único: Todas las pruebas usaron Opencode como entorno del agente. Un entorno diferente puede producir clasificaciones relativas diferentes, particularmente para modelos cuyo comportamiento predeterminado está ajustado a patrones específicos de uso de herramientas.
Tendencias futuras de los modelos de lenguaje grandes
1- Verificación de hechos en tiempo real con datos en vivo
Los LLM acceden a fuentes externas durante las conversaciones en lugar de depender solo de los datos de entrenamiento. El modelo consulta bases de datos externas, recupera información actual y proporciona citas.
Limitación: Sigue cometiendo errores. Las citas no garantizan precisión; los modelos a veces citan fuentes incorrectamente o malinterpretan el contenido citado.
Copilot de Microsoft: Integra GPT-5.4 Thinking con datos en vivo de internet, introduciendo los modos “Respuesta rápida” y “Pensar más a fondo” para un razonamiento adaptado a distintos tipos de tareas.1 El agente Researcher combina GPT para la investigación inicial con Anthropic Claude revisando los resultados en busca de precisión y calidad de citas antes de la entrega, logrando una mejora del 13.8% en el benchmark de investigación profunda DRACO respecto a sistemas independientes.2
- ChatGPT: Busca en la web cuando se le pregunta sobre eventos recientes. Cita fuentes en las respuestas.
- Perplexity: Construido específicamente para búsqueda con citas. Cada respuesta incluye enlaces a las fuentes.
2- Datos de entrenamiento sintéticos
Los modelos generan sus propios conjuntos de datos de entrenamiento en lugar de requerir datos etiquetados por humanos.
Modelo automejorable de Google (investigación de 2023):
- El modelo crea preguntas
- Selecciona respuestas
- Se autoajusta con los datos generados
Mejora del rendimiento: del 74.2% al 82.1% en problemas de matemáticas GSM8K, del 78.2% al 83.0% en comprensión lectora DROP.
OpenAI, Anthropic y Google están utilizando datos sintéticos para complementar los conjuntos de datos etiquetados por humanos. Esto reduce los costes de etiquetado, pero introduce nuevos riesgos de sesgo; los modelos pueden amplificar sus propios errores.
Fuente: “Large Language Models Can Self-Improve”
Una encuesta de marzo de 2026 reveló que el 76% de los investigadores de IA cree que las ganancias al escalar computación y datos se han estancado, y los principales laboratorios informan de rendimientos decrecientes a pesar de inversiones masivas. El hallazgo sugiere que es más probable que el próximo salto en la capacidad de los LLM provenga de la innovación arquitectónica, como una mayor eficiencia de entrenamiento, arquitecturas dispersas o mejoras en el razonamiento, en lugar de simplemente escalar los enfoques existentes.3
3- Modelos de expertos dispersos (Mezcla de Expertos)
En lugar de activar toda la red neuronal para cada entrada, solo se activa un subconjunto relevante de parámetros, dependiendo de la tarea. El modelo enruta la entrada a “expertos” especializados dentro de la red. Solo los expertos activados procesan la consulta.
Ejemplos reales:
- Llama 4 Scout: 109B parámetros totales, 17B activos por token. La arquitectura de Mezcla de Expertos (MoE) ofrece una ventana de contexto de 10M tokens en una sola H100 GPU.
- Mistral Devstral 2: Diseñado específicamente para tareas de ingeniería de software. 123B parámetros, ventana de contexto de 256K tokens. Alcanza un 72.2% en SWE-bench Verified, consolidándose como el modelo de codificación de peso abierto líder. Una variante más pequeña, Devstral Small 2 (24B parámetros), se ejecuta localmente en hardware de consumo bajo la licencia Apache 2.0.4
- En nuestro A-CODE-LLM Bench, tanto las variantes base como thinking de DeepSeek V4 Pro obtuvieron menos de 0.45 en general, con tiempos de finalización superiores a 1,700 segundos por tarea. La capacidad de codificación agéntica del modelo va por detrás de su sólido rendimiento en benchmarks de consulta única, lo que probablemente refleja una menor madurez en el uso de herramientas en comparación con los modelos de frontera de Anthropic y Google en esta etapa.
4- Integración en flujos de trabajo empresariales
Los LLM se integran directamente en los procesos de negocio en lugar de utilizarse como herramientas independientes.
Ejemplos reales:
- Salesforce Agentforce (anteriormente Einstein Copilot): Integra LLMs en las operaciones de CRM. Responde consultas de clientes, genera contenido y ejecuta acciones en Salesforce, basándose en los datos y metadatos de CRM de la organización a través de la Capa de Confianza de Einstein.5
- Microsoft 365 Copilot: Integrado en Word, Excel, PowerPoint y Outlook. Redacta documentos, analiza hojas de cálculo, genera presentaciones y resume hilos de correo electrónico, aprovechando los datos de la empresa a través de Microsoft Graph para fundamentar las respuestas en el contexto organizacional.6 El agente Researcher utiliza una arquitectura multimodelo donde GPT gestiona la investigación inicial y Claude revisa los resultados antes de la entrega, el primer despliegue comercial confirmado de proveedores de IA competidores dentro de un mismo producto empresarial.
- Anthropic Claude para Empresas: La separación de memoria basada en proyectos mantiene los contextos de trabajo distintos entre equipos. Claude Opus 4.6 introdujo equipos de agentes, permitiendo que múltiples agentes de Claude dividan tareas grandes en flujos de trabajo paralelos, cada uno responsable de un segmento y coordinándose con los demás simultáneamente. La misma versión integró a Claude directamente en PowerPoint como un panel lateral nativo (versión preliminar de investigación), lo que permite crear y editar presentaciones dentro de la aplicación sin transferencias de archivos.7
5- LLM híbridos con capacidades multimodales
Los grandes modelos multimodales integran múltiples formas de datos, como texto, imágenes y audio, lo que les permite comprender y generar contenido en diferentes tipos de medios.
- En nuestro A-CODE-LLM Bench, GPT 5.5 thinking obtuvo 0.597 con un tiempo promedio de finalización de 276 segundos, el modelo más rápido por encima de 0.50 en tiempo. El coste por celda de la API fue de $0.41–$0.45 para las variantes mini, aproximadamente un tercio del coste de Claude Sonnet 4.6 en rangos de puntuación similares.
- Gemini 2.5 Pro: Maneja de forma nativa texto, audio, imágenes, video y repositorios de código completos dentro de una ventana de contexto de 1M tokens. Disponible en Google IA Studio, Vertex IA y NotebookLM. Los precios comienzan en $1.25 por millón de tokens de entrada y $10 por millón de tokens de salida a través de la API.8
- Llama 4 Scout y Maverick: Los modelos de peso abierto de Meta utilizan fusion multimodal temprana de tokens de texto y visión, entrenados conjuntamente desde el principio en lugar de añadirse como módulos separados. Los modelos fueron preentrenados en 200 idiomas y recibieron soporte de ajuste fino específico para 12 idiomas, incluidos árabe, español, alemán e hindi.9
La capacidad multimodal es estándar en los modelos de frontera. El desafío restante es la consistencia: los modelos rinden bien en combinaciones comunes de imagen y texto, pero se degradan en contextos visuales poco frecuentes, entradas de baja resolución y razonamiento intermodal que requiere conectar evidencia visual y textual.
6- Modelos de razonamiento
Modelos que piensan los problemas paso a paso en lugar de generar respuestas inmediatas.
Este cambio de la predicción al razonamiento es fundamental para permitir:
- Comportamiento agéntico, donde los modelos planifican, ejecutan y adaptan tareas de forma autónoma.
- IA interpretable, donde los resultados son paso a paso y lógicamente sólidos, no solo verosímiles.
- Claude Sonnet 4.6: Líder actual de producción de Anthropic en benchmarks de codificación agéntica, con una puntuación de 0.748 en el A-CODE-LLM Bench de AIMultiple, por encima de todas las variantes de Opus. Utiliza pensamiento adaptativo, donde el modelo determina dinámicamente la profundidad del razonamiento en función de la complejidad de la tarea sin necesidad de cambio manual de modo. Precio: $3/$15 por millón de tokens. En SWE-bench Verified, Sonnet 4.6 alcanza el 79.6%, a un punto de Opus 4.7 (80.8%), a una quinta parte del coste.
- Claude Opus 4.7: El buque insignia de Anthropic en razonamiento complejo de múltiples pasos y visión (98.5% en el benchmark de agudeza visual de XBOW, frente al 54.5% de la generación anterior). Precio: $5/$25 por millón de tokens. En el benchmark de AIMultiple, Opus 4.7 obtuvo 0.61, por debajo de Sonnet 4.6 (0.748) y Opus 4.8 (0.702), principalmente debido a una mayor latencia (1,562 segundos de media por tarea) que degradó las puntuaciones de la UI. La brecha frente a Sonnet se amplía en tareas de razonamiento abstracto como ARC-AGI-2.
- Claude Opus 4.8: Lanzado después de Opus 4.7, recuperándose de la regresión del 4.7 en codificación agéntica. Obtuvo 0.702 en el A-CODE-LLM Bench, quinto en la clasificación general. Completó la tarea de referencia en 34 segundos, el modelo más rápido del benchmark en esa tarea, utilizando solo 6 llamadas a herramientas. Precio: $2.92 por celda en condiciones de benchmark ($15/$75 por millón de tokens).
7- Modelos ajustados para dominios específicos
Modelos entrenados con datos especializados para industrias específicas en lugar de un entrenamiento de propósito general.
Google, Microsoft y Meta han lanzado importantes modelos propietarios de dominio específico y ajustados para casos de uso empresariales, además de sus ofertas de propósito general.
Estos LLM especializados pueden reducir las alucinaciones y aumentar la precisión al aprovechar el preentrenamiento específico del dominio, la alineación del modelo y el ajuste fino supervisado.
Programación
GitHub Copilot: Ajustado con repositorios de código. En julio de 2025, 20 millones de desarrolladores usaban GitHub Copilot, un aumento interanual del 400%, y el 90% de las empresas Fortune 100 lo utilizan. Autocompleta código, genera funciones y sugiere correcciones de errores.10
Finanzas
BloombergGPT: 50 mil millones de parámetros, LLM entrenado con un conjunto de datos de 363 mil millones de tokens de documentos financieros de Bloomberg, superando a modelos de tamaño comparable en benchmarks de PLN financiero, incluyendo análisis de sentimiento, reconocimiento de entidades nombradas y respuesta a preguntas.11
Salud
Med-PaLM 2 de Google: Ajustado con conjuntos de datos médicos, alcanzó más del 85% de precisión en preguntas tipo USMLE (Examen de Licencia Médica de EE. UU.), el primer LLM en alcanzar un rendimiento de nivel experto en este benchmark. Impulsa MedLM, la familia de modelos fundacionales para la salud de Google Cloud.12
Derecho
ChatLAW: Un modelo de lenguaje de código abierto entrenado específicamente con conjuntos de datos del dominio legal chino.13
8- IA ética y mitigación de sesgos
Las empresas se centran cada vez más en la IA ética y la mitigación de sesgos en el desarrollo y despliegue de modelos de lenguaje grandes.
- Anthropic y OpenAI realizaron una evaluación de alineamiento mutuo a mediados de 2025, probando los modelos públicos de cada uno en busca de adulación, tendencias a denunciar irregularidades y comportamientos de autopreservación. El ejercicio encontró adulación en todos los modelos probados, incluyendo casos en los que los modelos validaban decisiones perjudiciales de usuarios simulados con creencias delirantes. Anthropic desarrolló posteriormente el marco de pruebas Bloom específicamente para evaluar este comportamiento en nuevos modelos.
- Anthropic también lanzó Claude Mythos Preview (Project Glasswing), un modelo solo por invitación, puesto a disposición de un pequeño conjunto de organizaciones específicamente para encontrar y corregir vulnerabilidades de ciberseguridad en los principales sistemas operativos y navegadores web. Anthropic ha declarado que no tiene previsto hacer que este modelo esté disponible de forma general. El enfoque de acceso controlado representa un nuevo marco para el despliegue de modelos especializados de alta capacidad cuando el perfil de riesgo requiere un lanzamiento restringido.14
- Google DeepMind: Publicó “The Ethics of Advanced IA Assistants”, ofreciendo el primer tratamiento sistemático de las cuestiones éticas y sociales planteadas por los agentes de IA, abarcando la alineación de valores, los riesgos de manipulación, el antropomorfismo, la privacidad y la equidad. La evaluación de IA Responsable de la compañía incluyó más de 350 ejercicios de equipo rojo adversario e introdujo un nuevo Nivel de Capacidad Crítica específicamente para la manipulación dañina, tratándolo como un riesgo de nivel frontera junto a los ciberataques y las amenazas QBRN.
Limitaciones de los modelos de lenguaje grandes (LLMs)
1- Alucinaciones
Los modelos generan información plausible pero incorrecta.
El ranking de alucinaciones de Vectara es el benchmark de resumen fundamentado más referenciado del sector. En el conjunto de datos original de Vectara, los modelos Gemini de Google ocupan sistemáticamente los primeros puestos, con variantes de Gemini Flash logrando tasas de alucinación inferiores al 1%. La familia GPT de OpenAI se agrupa entre el 0.8% y el 2.0%.
Vectara lanzó un benchmark significativamente más difícil a finales de 2025: 7,700 artículos (frente a los 1,000 anteriores), documentos más largos de hasta 32K tokens, y contenido que abarca derecho, medicina, finanzas y tecnología. Los hallazgos en el nuevo conjunto de datos revelan un patrón contraintuitivo: los modelos de razonamiento y pensamiento que destacan en tareas complejas frecuentemente alucinan más en resumen fundamentado que modelos más pequeños y rápidos. La mayoría de los modelos de clase pensante muestran tasas de alucinación superiores al 10% en el conjunto de datos más difícil, mientras que modelos ligeros como las variantes de Gemini Flash mantienen tasas más bajas.15
Nota: Ningún benchmark único ofrece una “tasa de alucinación” definitiva para un modelo. Una evaluación responsable cruza al menos dos benchmarks que midan cosas diferentes: una tarea fundamentada (Vectara), una tarea de conocimiento abierto, y especifica la versión exacta del modelo y las condiciones de llamada.
Todos los modelos alucinan. La frecuencia se ha reducido sustancialmente, de aproximadamente el 21% en 2021 a menos del 5% para los mejores en benchmarks estándar, pero no se ha eliminado. Las aplicaciones críticas aún requieren verificación humana.
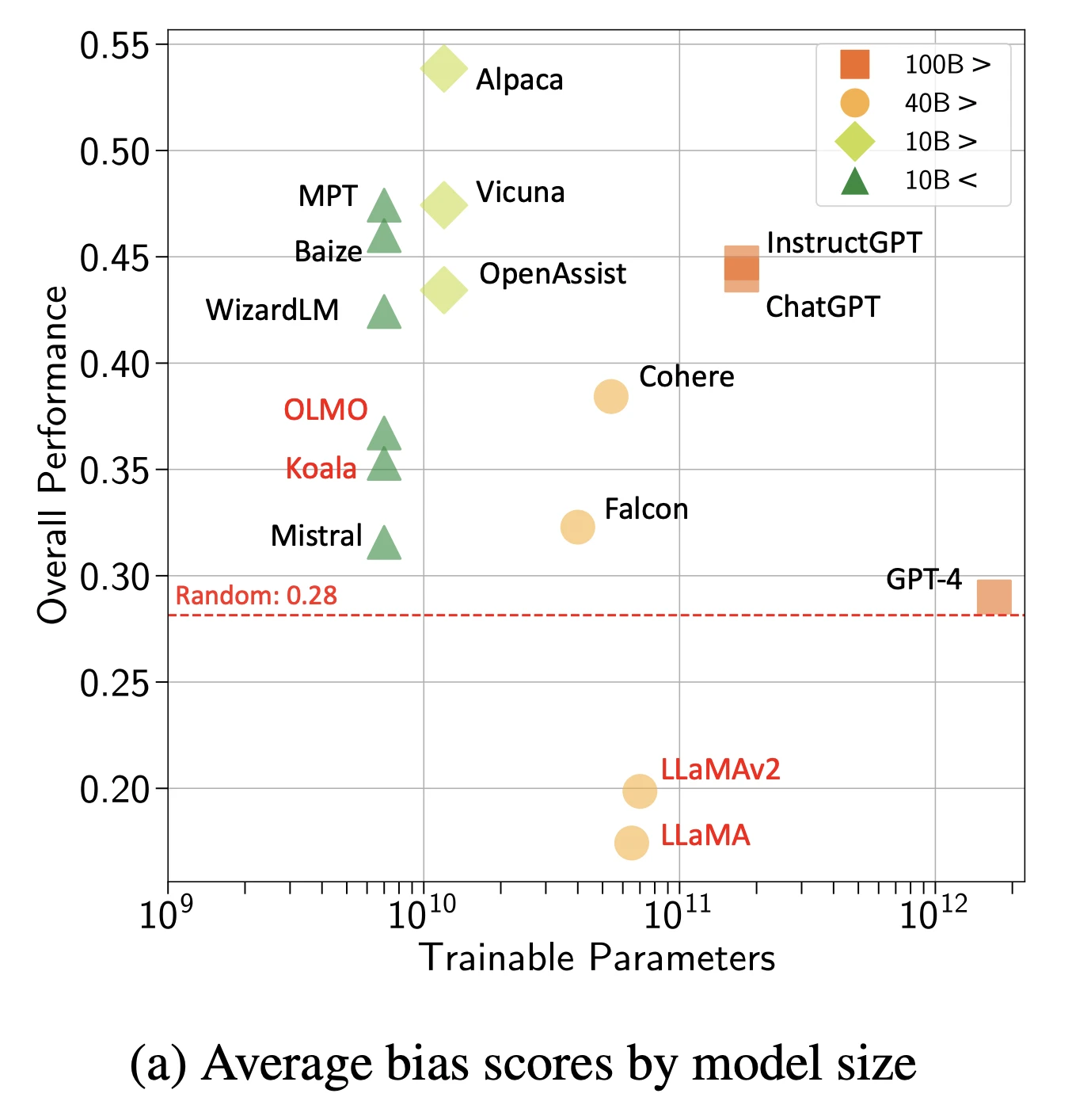
2- Sesgo
Los modelos absorben y amplifican los sesgos sociales de los datos de entrenamiento.
Figura: Puntuaciones generales de sesgo por modelos y tamaño
Fuente: Arxiv16
Tipos de sesgo observados:
- Sesgo de género en las sugerencias de ocupación
- Sesgo racial en simulaciones de selección de currículums
- Sesgo de edad en recomendaciones sanitarias
- Sesgo socioeconómico en contenidos educativos
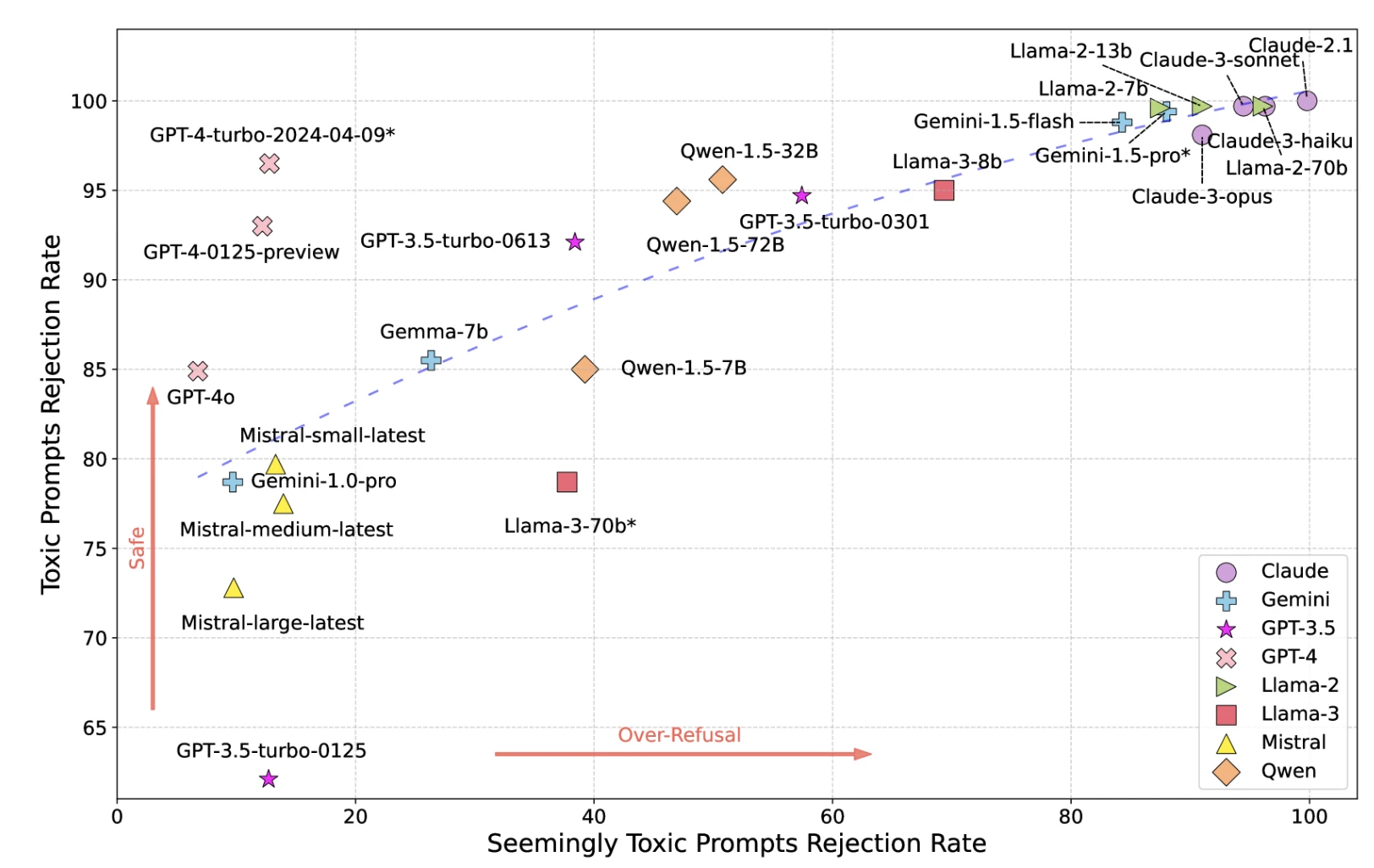
3- Toxicidad
Los modelos pueden generar contenido dañino, ofensivo o tóxico a pesar de las medidas de seguridad.
Figura: Mapa de toxicidad de los LLM
Fuente: Investigadores de UCLA y UC Berkeley17
*GPT-4-turbo-2024-04-09*, Llama-3-70b*, y Gemini-1.5-pro* se utilizan como moderadores, los resultados podrían estar sesgados hacia estos 3 modelos.
Las medidas de seguridad estrictas reducen la toxicidad pero aumentan los falsos positivos (rechazan solicitudes inofensivas). Las medidas laxas permiten el paso de la toxicidad.
4- Ventana de Contexto Limitaciones
Cada modelo tiene una capacidad de memoria fija, el número de tokens que puede procesar en una sola sesión. Si se supera ese límite, el modelo trunca el contenido anterior o rechaza la solicitud. La diferencia práctica entre modelos es lo suficientemente amplia como para importar en cargas de trabajo reales.
Ventanas de contexto más recientes:
- Llama 4 Scout (Meta): 10M tokens (~7.5M palabras), la ventana de contexto verificada en producción más grande entre los modelos líderes.18 En la práctica, esto significa cargar bases de código completas, archivos legales o historiales de conversaciones de varios días sin fragmentar.
- Gemini 2.5 Pro: 1,048,576 tokens (~780,000 palabras), con entrada multimodal nativa de texto, audio, imágenes y video dentro de la misma ventana. La recuperación se mantiene al 100% hasta 530,000 tokens y al 99.7% en el límite completo de 1 millón de tokens.
- Claude Sonnet 4.6: 1M tokens (~750,000 palabras) con precios estándar, disponible sin cabeceras beta ni configuración especial.19
- GPT-5.5: Ventana de contexto de 1M tokens a nivel de API.20
Una ventana de contexto grande no implica automáticamente un mejor rendimiento en toda ella. La recuperación se degrada hacia la mitad de contextos muy largos en la mayoría de los modelos, y los costes escalan con la longitud de entrada: procesar 1M tokens cuesta significativamente más que procesar 10K tokens en el mismo modelo. Para la mayoría de las cargas de trabajo en producción, la cuestión práctica no es qué modelo tiene la ventana más grande, sino qué modelo recupera de forma fiable en las longitudes de contexto que su caso de uso realmente requiere.
5- Corte de conocimiento estático
Los modelos se basan en conocimientos preentrenados con una fecha de corte específica. No tienen acceso a información posterior al entrenamiento a menos que se conecten a fuentes externas.
Problemas:
- Información desactualizada sobre eventos actuales
- Incapacidad para manejar desarrollos recientes
- Menor relevancia en dominios dinámicos (tecnología, finanzas, medicina)
Solución: Integración de búsqueda web. ChatGPT, Claude y Perplexity ofrecen búsqueda en tiempo real. Pero la búsqueda no elimina las alucinaciones; los modelos a veces malinterpretan los resultados de búsqueda.
Principales plataformas de LLM
GPT-5.5
El buque insignia actual de OpenAI se lanzó el 23 de abril de 2026. Construido en torno a un esfuerzo de razonamiento configurable, los desarrolladores establecen la profundidad de pensamiento por solicitud (desde none hasta xhigh), para que las consultas simples no consuman cómputo reservado para problemas difíciles. El modelo destaca en codificación agéntica, uso de ordenadores y tareas de largo recorrido donde necesita mantener el contexto a través de grandes sistemas y verificar su propio trabajo durante la ejecución.21
Quién lo usa: Desarrolladores, empresas y creadores de contenido. La mayor base de usuarios entre los LLM.
Limitaciones: $5/$30 por millón de tokens, el precio base más alto de esta lista. Sigue alucinando. Requiere integración de búsqueda web para cualquier cosa posterior a su fecha de corte de entrenamiento.
Claude Opus 4.8 / Sonnet 4.6
Claude Sonnet 4.6 lidera el A-CODE-LLM Bench de AIMultiple con una puntuación global de 0.748 a $1.26–$1.33 por celda, por encima de todas las variantes de Opus probadas. Claude Opus 4.8 le sigue con 0.702, recuperándose de la regresión de Opus 4.7 (0.61) a $2.92 por celda. Opus 4.7 sigue siendo el mejor en tareas complejas de razonamiento de varios pasos y visión (98.5% en el benchmark de agudeza visual de XBOW), pero su tiempo promedio de finalización de 1,562 segundos en flujos de trabajo agénticos eleva el coste total a $3.08 por celda, el modelo más caro del benchmark.
Tanto Sonnet 4.6 como las variantes de Opus utilizan pensamiento adaptativo: el modelo determina la profundidad del razonamiento en función de la complejidad de la tarea sin necesidad de un cambio de modo manual. Sonnet 4.6 realizó la menor cantidad de llamadas a herramientas por tarea entre los modelos de Anthropic (51 base, 48 thinking), alcanzando la puntuación más alta del benchmark con menos iteraciones que las variantes de Opus (56–70 llamadas a herramientas). Los equipos de agentes, disponibles en toda la línea de producción de Anthropic, permiten que múltiples instancias de Claude dividan una tarea en flujos de trabajo paralelos coordinados en tiempo real.
Quién lo usa: Desarrolladores y empresas que ejecutan codificación agéntica, flujos de trabajo de investigación o pipelines multiagente. Los equipos que priorizan la eficiencia de costes utilizan Sonnet 4.6; los equipos que ejecutan cargas de trabajo con mucho uso de visión o razonamiento complejo utilizan Opus 4.7.
Limitaciones: El pensamiento extendido es más lento y más caro por token. La brecha de rendimiento frente a Sonnet se amplía en tareas de razonamiento abstracto (ARC-AGI-2). Opus 4.8 tiene un precio de $15/$75 por millón de tokens.
Gemini 3.5 Flash
Gemini 3.5 Flash thinking obtuvo 0.625, el resultado no Anthropic más alto a $1.30 por celda y 390 segundos de promedio de finalización. La variante base puntuó por debajo de thinking con un coste mayor ($0.56 por celda de referencia), debido a la sobrescritura (131 líneas para una tarea cuya solución de referencia es de ~50 líneas).
Llama 4 Scout
El modelo MoE de peso abierto de Meta. 109B parámetros totales, 17B activos por token, se ejecuta en una sola NVIDIA H100 GPU con cuantización int4. La implicación práctica es que una ventana de contexto de 10M tokens es accesible sin un contrato de centro de datos.22 La multimodalidad de fusion temprana significa que el texto y la visión se procesan conjuntamente desde la primera capa en lugar de combinarse en la etapa de salida. Disponible bajo la Licencia Comunitaria Llama 4 de Meta.
Quién lo usa: Investigadores, organizaciones que necesitan despliegue en las instalaciones, desarrolladores que evitan la dependencia de un proveedor y equipos donde el coste a escala hace que los precios de la API sean insostenibles.
Limitaciones: El rendimiento depende en gran medida de la configuración de alojamiento y las elecciones de cuantización. Requiere inversión en infraestructura y capacidad de operaciones de ML. Menor pulido de producción que los modelos comerciales.
DeepSeek V4
El modelo de cuarta generación de DeepSeek está disponible como vista previa. Utiliza una arquitectura MoE de 1 billón de parámetros, aproximadamente un 50% más grande que V3, con capacidades multimodales en texto, imagen y video. Thinking in Tool-Use permite al modelo razonar internamente antes de llamar a herramientas externas y verificar los resultados de las herramientas contra su propia lógica, que es el diferenciador central para flujos de trabajo agénticos. El precio de entrada de la API comienza en $0.27 por millón de tokens (fallo de caché), aproximadamente 18x más barato que GPT-5.5.23
Preguntas frecuentes
Un LLM es un modelo de IA diseñado para generar y comprender texto similar al humano mediante el análisis de grandes cantidades de datos.
Estos modelos fundacionales se basan en técnicas de aprendizaje profundo y normalmente involucran redes neuronales con muchas capas y un gran número de parámetros, lo que les permite capturar patrones complejos en los datos con los que se entrenan.
Cita esta investigación
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sezer, Sena},
title = {{El futuro de los modelos de lenguaje grandes}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/future-of-large-language-models}},
note = {AIMultiple. Recuperado el 25 de Junio de 2026}
}
Sé el primero en comentar
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.