LCM: De la tokenización LLM a la representación a nivel de concepto
Los modelos de conceptos grandes (LCM, por sus siglas en inglés) , introducidos por Meta en su trabajo sobre “Modelos de conceptos grandes”, representan un cambio fundamental de la predicción basada en tokens hacia la representación a nivel de concepto . 1
Los LCM se diferencian de los LLM tradicionales en dos aspectos clave:
- Espacio de incrustación de alta dimensión: en lugar de trabajar con secuencias de tokens discretas, los LCM realizan todo el modelado directamente en un espacio de incrustación de alta dimensión.
- Abstracción a nivel conceptual: El modelado se realiza a nivel de conceptos semánticos y abstractos, no dentro de un lenguaje o modalidad específicos. Esto hace que los modelos LCM sean inherentemente independientes del lenguaje y la modalidad.
De la investigación de Meta, 2 Exploraremos los componentes centrales de los LCM y su potencial en la búsqueda y el razonamiento semántico, basándonos en los siguientes puntos de referencia:
Comprender las limitaciones de los LLM: De los tokens a los conceptos.
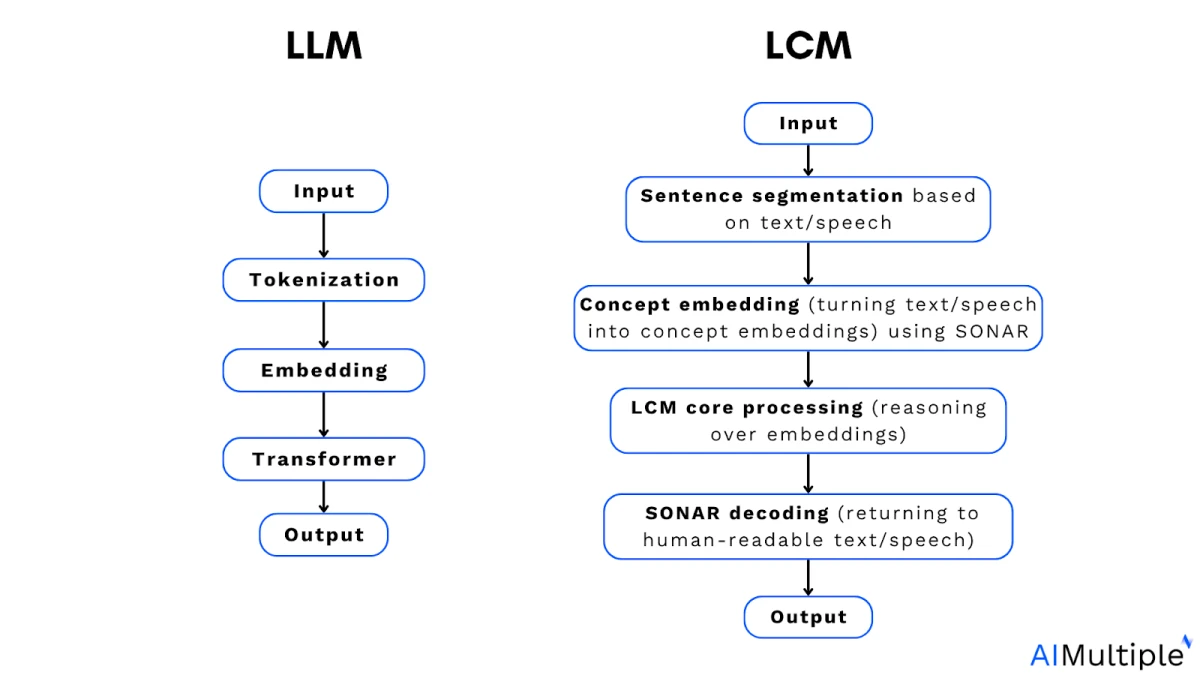
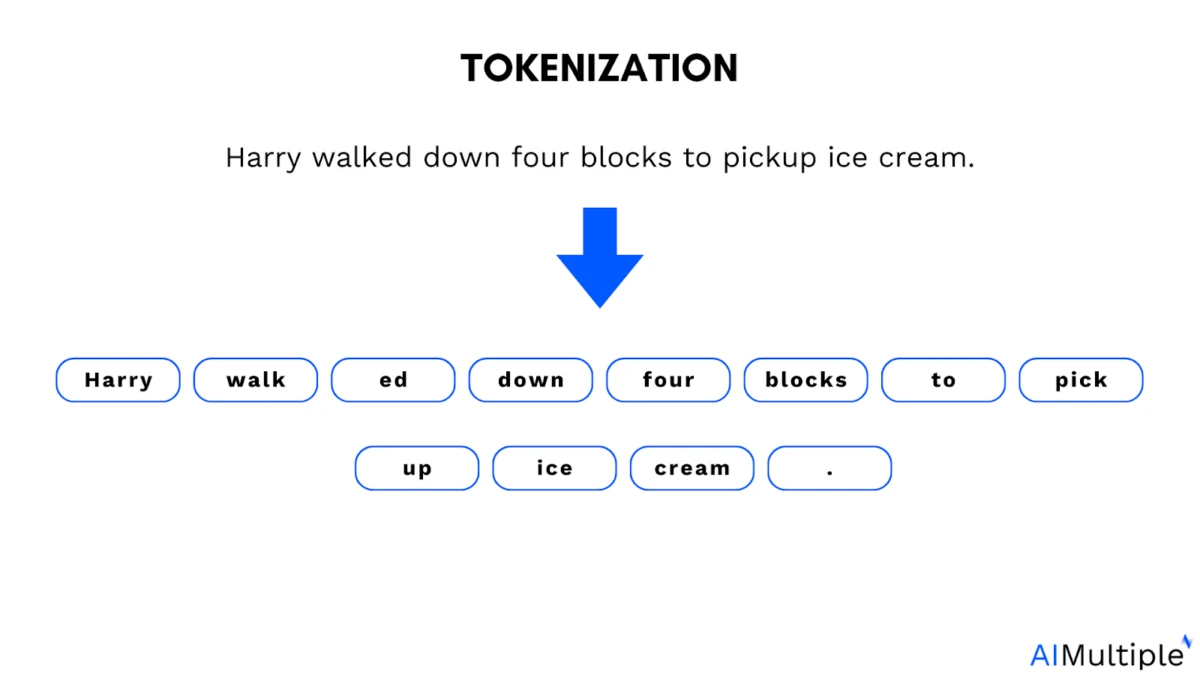
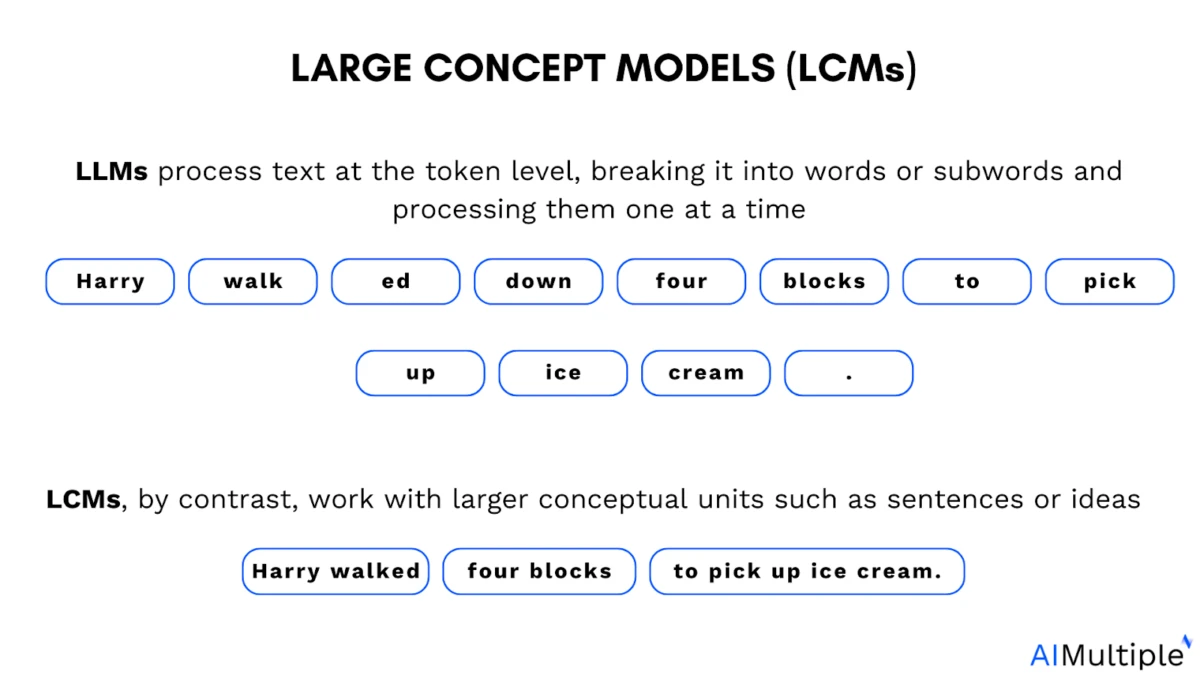
El papel de la tokenización en los modelos de lenguaje grandes (LLM): Los modelos de lenguaje grandes (LLM) se entrenan con tokens. Un token es un pequeño segmento de texto. Puede ser una palabra completa, parte de una palabra o incluso un solo carácter que el modelo procesa como una unidad.
Ejemplo de tokenización:
El problema
La tokenización ayuda a los modelos a dividir el lenguaje en partes manejables, pero también introduce una limitación. La mayoría de los modelos de lenguaje natural operan sobre secuencias de tokens discretos (por ejemplo, subpalabras de texto; tokens visuales/auditivos producidos por codificadores).
Los LLM pueden incorporar múltiples modalidades, pero su objetivo central y su representación siguen estando ligados a una secuencia , lo que dificulta modelar el significado directamente a nivel conceptual .
Los resultados de Cognition.ai con Sonnet 4.5 lo demuestran claramente: el modelo detecta cuando su ventana de contexto está casi llena, se apresura a sacar conclusiones e incluso informa sobre los tokens restantes, aunque de forma imprecisa. 3
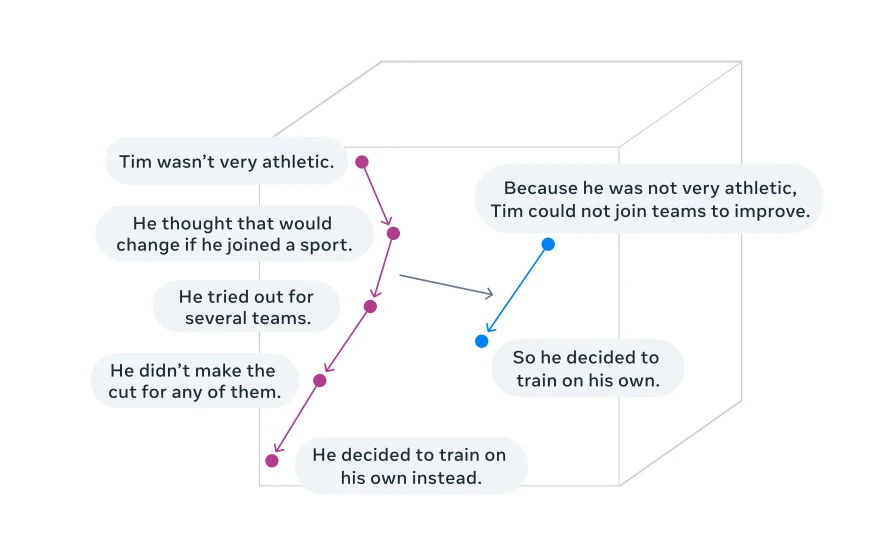
La solución (Conceptos)
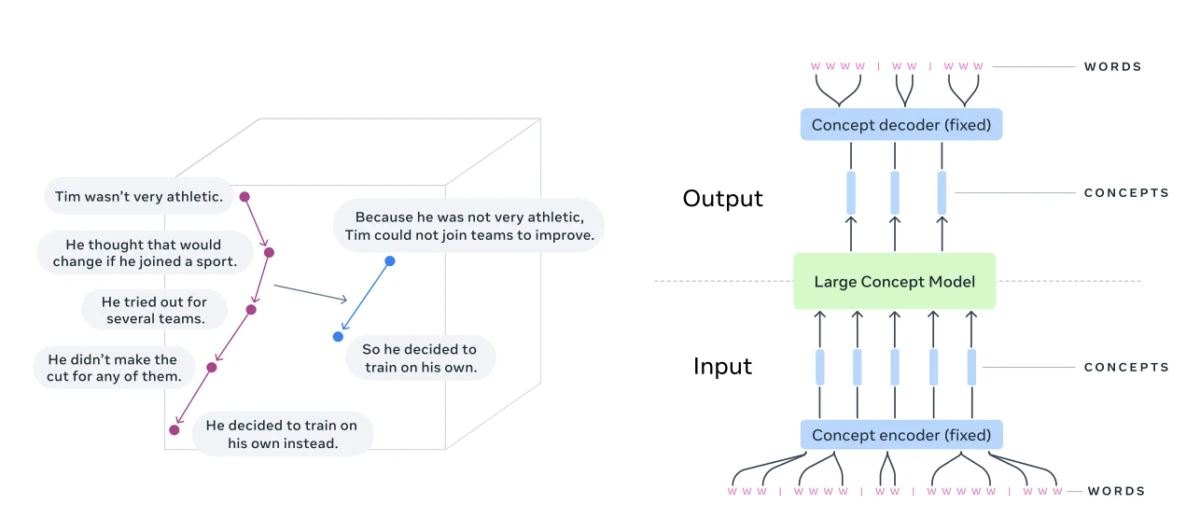
Visualización del razonamiento en un espacio de incrustación de conceptos (tarea de resumen) 4
Los conceptos se refieren a representaciones de significado de orden superior . A diferencia de los tokens, no están vinculados a ninguna unidad lingüística específica y pueden derivarse de texto o habla, por lo que el proceso de razonamiento sigue siendo el mismo.
Esto permite:
- Mejor manejo de contextos extensos mediante el razonamiento sobre ideas completas en lugar de sobre fragmentos aislados.
- Razonamiento más abstracto, ya que las operaciones se realizan a nivel de significado.
- Proceso independiente del idioma y la modalidad para gestionar tareas multilingües y multimodales sin necesidad de procesos separados para cada tipo de entrada.
¿Qué son los modelos conceptuales a gran escala?
Por el contrario, los modelos de conceptos grandes (LCM, por sus siglas en inglés) tienen como objetivo representar y razonar sobre conceptos semánticos en un espacio de incrustación continuo, no vinculado a ningún idioma o modalidad en particular.
Arquitectura fundamental de un modelo conceptual a gran escala (LCM):
Fuente: Meta 5
Componentes principales de los LCM
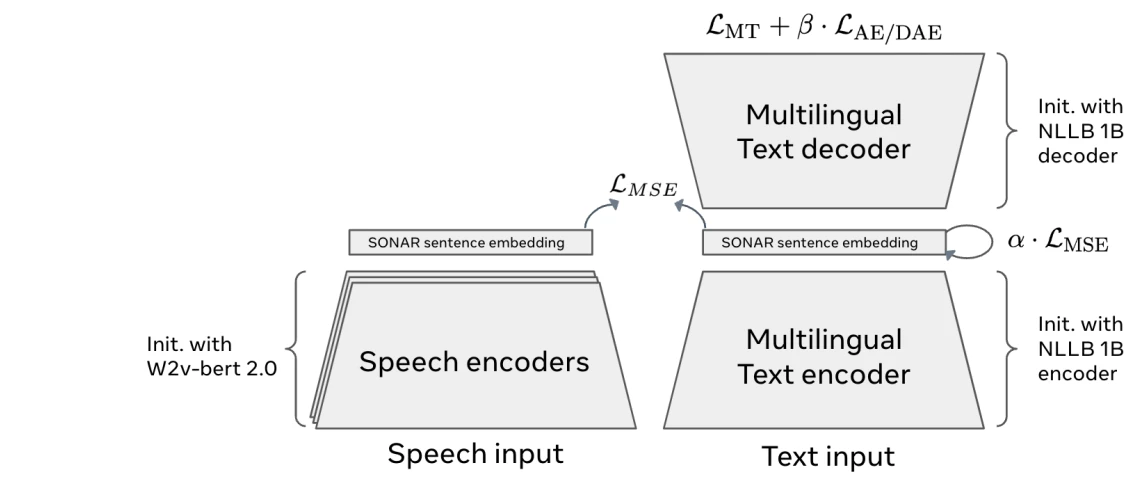
1. Codificación SONAR (conversión de texto o voz en incrustaciones de conceptos)
Arquitectura SONAR 6
La primera etapa de un Modelo de Conceptos Grandes (MCG) es el codificador de conceptos , que convierte texto o voz en un espacio de incrustación compartido. En lugar de dividir la entrada en tokens, representa oraciones completas como incrustaciones matemáticas que capturan su significado.
Los LCM utilizan SONAR , un espacio de incrustación multilingüe y multimodal que admite más de 200 idiomas de texto y 76 para voz.
Por ejemplo, las frases "I love you" en inglés y "Te quiero" en español se ubican cerca una de la otra en este espacio porque expresan la misma idea. Al operar a este nivel conceptual, los LCM logran mayor inclusividad, eficiencia y escalabilidad que los modelos basados en tokens.
¿Por qué SONAR es mejor que los sistemas integrados tradicionales?
Métodos tradicionales:
- mBERT : Proporciona incrustaciones multilingües, pero no están alineadas de forma consistente a nivel de oración , lo que hace que las tareas entre idiomas sean menos efectivas.
Ventajas del SONAR:
- Independiente del idioma : más de 200 idiomas para entrada y salida de texto (basado en el proyecto No Language Left Behind de Meta). 76 idiomas para entrada de voz e inglés para salida de voz.
- Alineación interlingüística : Las oraciones con el mismo significado aparecen juntas, independientemente del idioma.
- Razonamiento de nivel superior : Dado que las unidades son oraciones (o conceptos), los modelos pueden realizar tareas como resumir o traducir manipulando ideas directamente.
- Traducción de cero disparos : Puede traducir entre idiomas y modalidades sin entrenamiento directo para cada par .
LLM frente a LCM
2. Procesamiento central de LCM (razonamiento sobre incrustaciones)
El núcleo de LCM es la etapa de razonamiento, donde el modelo genera nuevos conceptos basados en el contexto. A diferencia de los LLM, que predicen un token a la vez, el núcleo de LCM predice oraciones o conceptos completos , operando a un nivel semántico superior.
El desafío reside en producir incrustaciones continuas condicionadas al contexto. Los LLM generan distribuciones de probabilidad sobre tokens discretos, pero los LCM deben generar directamente vectores que capturen el significado.
Para abordar esta cuestión, los investigadores han propuesto varios enfoques, entre ellos:
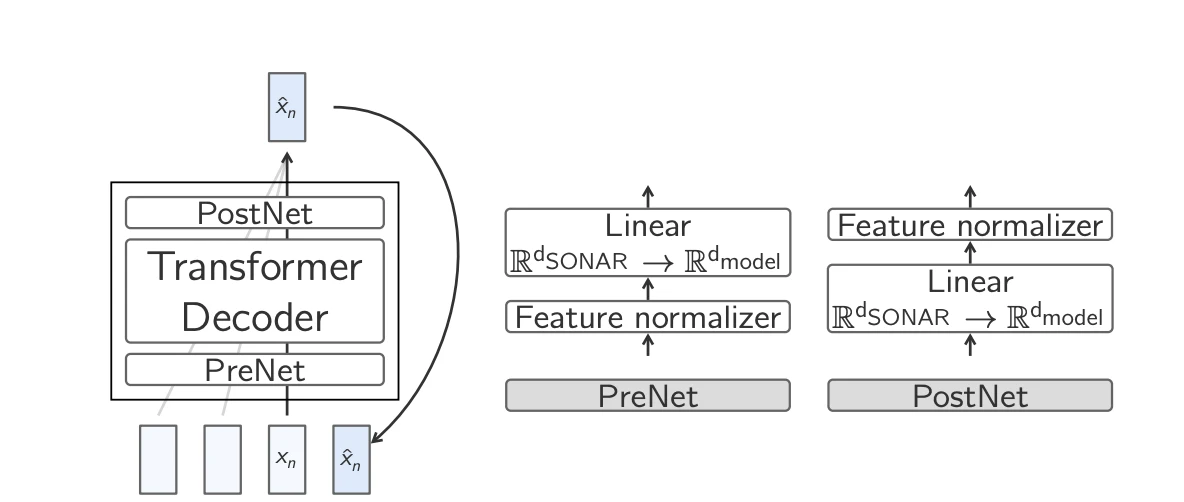
- Base-LCM: Predicción de incrustaciones con Transformer estándar: El método más sencillo consiste en entrenar un Transformer para predecir directamente la siguiente incrustación, minimizando la pérdida de error cuadrático medio (MSE) . Si bien es efectivo en principio, este enfoque presenta desafíos, ya que un contexto dado puede dar lugar a múltiples continuaciones válidas, aunque semánticamente distintas.
LCM base 7
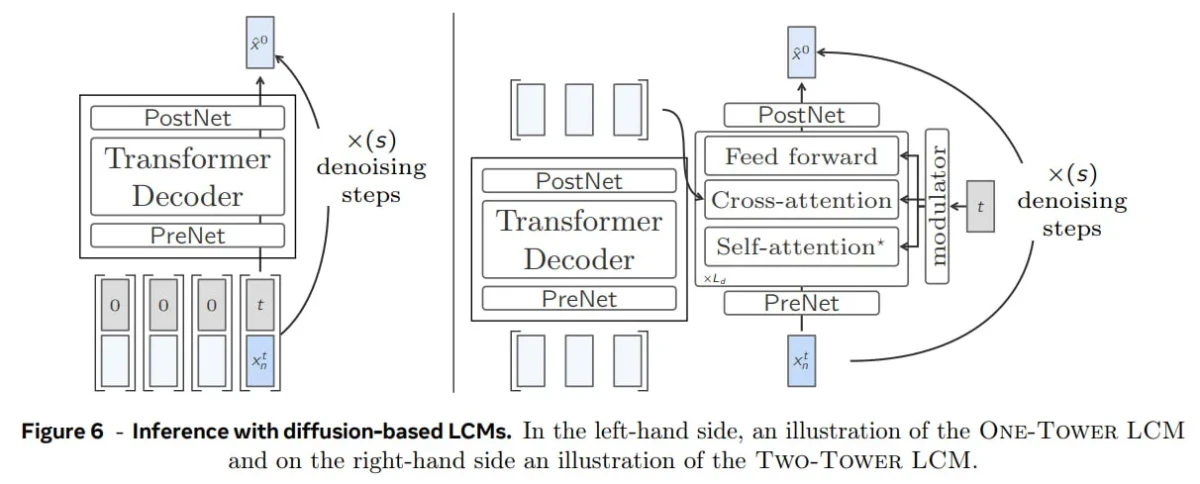
- LCM basado en difusión: Variaciones estructurales para la contextualización y la reducción de ruido: Inspirada en la generación de imágenes, esta variante utiliza un proceso de difusión . Genera conceptos de forma autorregresiva, uno a la vez, realizando pasos de reducción de ruido para cada concepto generado.
- Una sola torre: una única pila de transformadores se encarga tanto de la contextualización como de la reducción de ruido, lo que mantiene un diseño eficiente y compacto.
- Modelo de dos torres: divide el proceso en dos partes: un contextualizador para comprender el contexto y un eliminador de ruido para refinar las incrustaciones, lo que ofrece mayor flexibilidad a costa de una mayor complejidad.
- LCM cuantificado: Incrustaciones discretizadas: Otra opción es discretizar las incrustaciones en unidades simbólicas más grandes. Esto hace que la tarea se asemeje más a la de los LLM, donde el modelo genera elementos discretos, pero aquí los "tokens" representan fragmentos de significado mucho más grandes y semánticamente más ricos.
3. Decodificación del SONAR (conversión a texto o voz legible para humanos)
El paso final de un LCM es el decodificador de conceptos , que transforma las incrustaciones abstractas de nuevo en texto o voz natural.
Dado que los conceptos se almacenan en un espacio de incrustación compartido , se pueden decodificar en cualquier idioma o modalidad compatible sin necesidad de volver a ejecutar el proceso de razonamiento.
Este diseño independiente del idioma permite que un modelo LCM reciba información en alemán, razone en términos conceptuales y genere resultados en japonés. Además, facilita la escalabilidad: se pueden añadir nuevos codificadores o decodificadores (como para sistemas de lenguaje de señas o de conversión de voz a texto) sin necesidad de volver a entrenar todo el modelo.
Al mantener el "pensamiento" separado de la expresión, el decodificador garantiza que los LCM sigan siendo flexibles y adaptables para aplicaciones multilingües y multimodales.
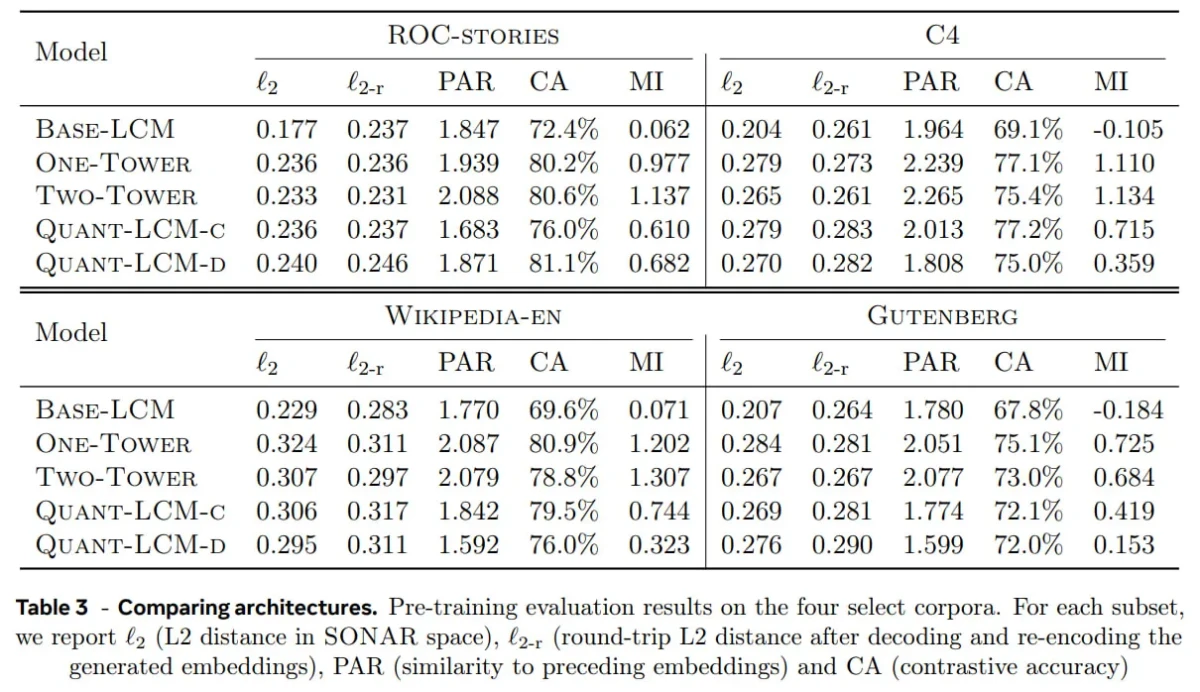
Evaluación comparativa de arquitecturas LCM
Meta preentrenó modelos LCM en el conjunto de datos FineWeb-Edu (solo en inglés) y los evaluó en cuatro puntos de referencia:
- Historias ROC (razonamiento narrativo),
- C4 (texto a escala web),
- Wikipedia-en (conocimiento enciclopédico),
- Gutenberg (texto extenso).
Estos conjuntos de datos se seleccionaron para abarcar diversos tipos de texto, desde narraciones breves hasta grandes bases de conocimiento y documentos extensos.
Conclusiones clave:
Los LCM basados en difusión (QUANT-LCM-C, QUANT-LCM-D) son los que ofrecen el mejor rendimiento . Su proceso iterativo de eliminación de ruido demostró ser más eficaz para modelar continuaciones de conceptos, lo que se traduce en una mayor precisión y coherencia semántica.
Cómo interpretar los datos de referencia:
- ℓ₂, ℓ₂-r: Menor = incrustaciones más precisas y consistentes.
- PAR: El término medio es lo mejor, muestra coherencia sin colapsar.
- CA: Mayor = mejor alineación semántica.
- MI: Cuanto mayor sea el valor, más informativos serán los resultados.
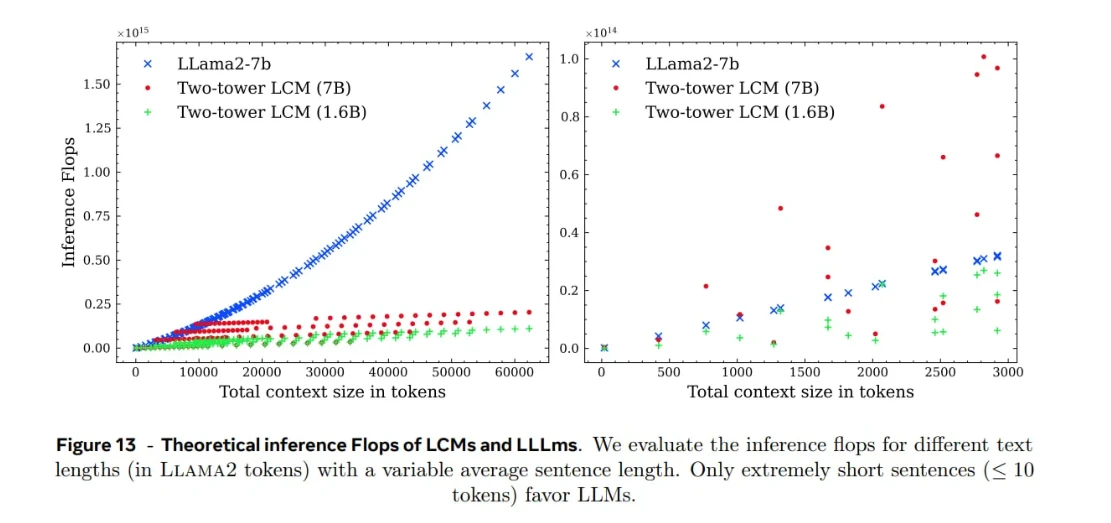
Evaluación comparativa de la eficiencia de LCM
Los experimentos de Meta demostraron que los LCM escalan bien con la longitud del contexto en comparación con los LLM al manejar la misma cantidad de texto. Esta ventaja proviene del hecho de que un concepto corresponde a una oración completa , que incluye múltiples tokens. Dado que hay menos conceptos que tokens, el modelo tiene menos unidades que procesar y la atención cuadrática se vuelve menos exigente.
Conclusiones clave:
Cabe destacar que estas mejoras en la eficiencia dependen en gran medida de cómo se segmenta el texto en oraciones . La división de los párrafos en oraciones más cortas o más largas afectará la cantidad de conceptos y, por lo tanto, la carga computacional.
Cada inferencia de MCM también implica tres etapas:
- Codificación SONAR (texto o voz: incrustaciones)
- Razonamiento Transformer-LCM (procesamiento de incrustaciones)
- Decodificación SONAR (incrustaciones: texto o voz)
Este proceso introduce una sobrecarga, especialmente para entradas cortas:
Para oraciones cortas (de menos de ~10 tokens), los LLM pueden ser más eficientes que los LCM, ya que los pasos de codificación y decodificación superan los beneficios del procesamiento a nivel de concepto.
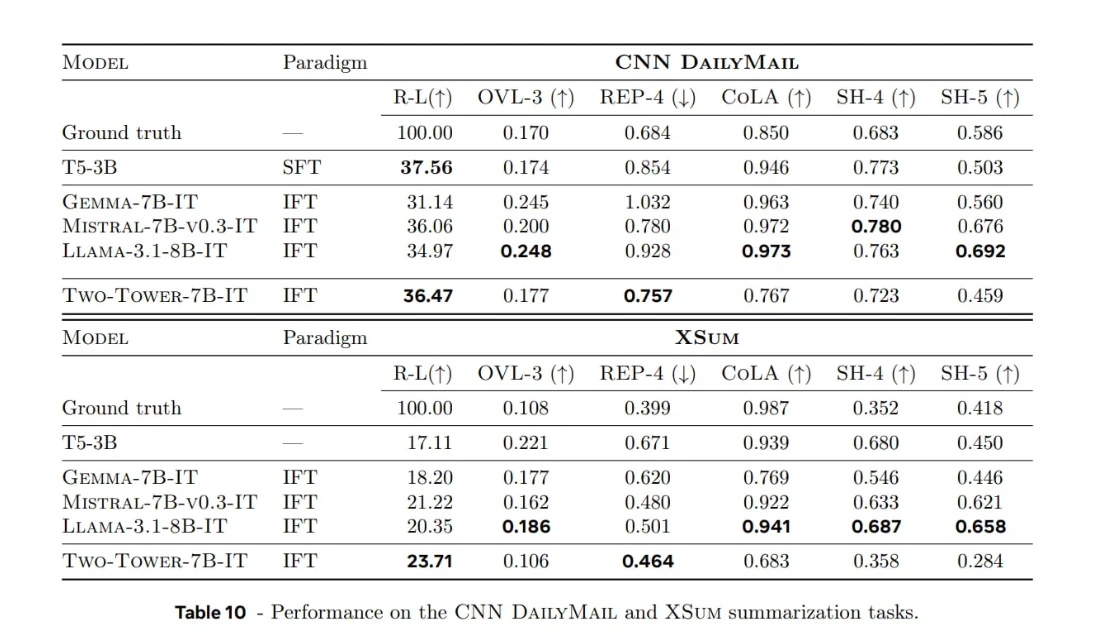
LCM frente a LLM tradicionales en tareas de resumen
Meta también puso a prueba un LCM basado en difusión (7B parámetros) en conjuntos de datos de resumen de noticias (por ejemplo, CNN/DailyMail, XSum) y lo comparó con LLM tradicionales.
Descripciones de paradigmas:
- SFT : formación especializada en ejemplos de resumen.
- IFT : entrenamiento más amplio en conjuntos de datos de instrucciones, de modo que el modelo aprenda a resumir como una de sus muchas habilidades.
Descripción de los parámetros:
- ROUGE-L : Superposición con los resúmenes de referencia.
- OVL-3 : Índice de superposición de trigramas de entrada, que mide la redundancia del texto fuente.
- REP-4 : Índice de repetición de cuatro gramos de salida, que mide la repetición en los resúmenes generados.
- Métricas SEAHORSE Q4 y Q5 : Medidas de calidad y coherencia.
- Clasificador basado en CoLA : Evaluó la aceptabilidad lingüística de las oraciones generadas.
Conclusiones clave:
Fortaleza:
- El modelo LCM de difusión demuestra una fuerte coherencia y alineación contextual en la generación de resúmenes extensos, especialmente al procesar contextos amplios.
Advertencias y consideraciones:
- La evaluación se centra principalmente en tareas generativas (resumen) en lugar de en parámetros de referencia generales como MMLU.
- La forma en que se dividen los párrafos en oraciones (por ejemplo, cómo se definen los "conceptos") influye enormemente en el rendimiento.
- En cuanto a fluidez y aceptabilidad lingüística , los modelos LLM basados en tokens, como LLaMA-3.1-8B y Mistral-7B, siguen aventajando a los demás. Si bien los modelos LCM son prometedores, aún no ofrecen mejoras claras en todas las métricas, especialmente en fluidez o flexibilidad.
Cita esta investigación
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{LCM: De la tokenización LLM a la representación a nivel de concepto}},
year = {2026},
month = jan,
howpublished = {\url{https://aimultiple.com/large-concept-models}},
note = {AIMultiple. Retrieved Enero 23, 2026}
}

Sé el primero en comentar
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.