Evaluación comparativa de herramientas de observabilidad RAG
Realizamos pruebas comparativas de cuatro plataformas de observabilidad RAG en una canalización LangGraph de 7 nodos en tres dimensiones prácticas: sobrecarga de latencia, esfuerzo de integración y compensaciones de la plataforma.
Métricas de sobrecarga de latencia
Explicación de las métricas:
La media es la latencia promedio en 150 llamadas a graph.invoke() medidas. Las evaluaciones de LLM-judge se ejecutan después de que finaliza el temporizador.
La mediana corresponde al percentil 50 de latencia. Las respuestas de la API de LLM tienen colas largas, por lo que la mediana es un mejor indicador del rendimiento típico de las consultas.
P95 es el percentil 95, la latencia en el peor de los casos para el 95% de las consultas.
La diferencia entre la latencia media y la latencia media entre la plataforma y la línea base sin monitorización es la diferencia entre ambas.
Para comprender en detalle nuestra evaluación y métricas, consulte nuestra metodología de referencia para las herramientas de observabilidad RAG.
Esfuerzo de integración por parte de la plataforma
Principales conclusiones
La varianza de la API de LLM empequeñece los gastos generales de monitorización.
La desviación estándar de referencia fue de 2645 ms. La sobrecarga máxima fue de 169 ms. Para medir la sobrecarga del SDK de forma aislada, sería necesario eliminar el LLM del proceso. Las pruebas de rendimiento de una sola ejecución de las herramientas de monitorización miden la varianza de la API, no la sobrecarga del SDK.
LangSmith requiere el menor código de integración.
Se añadieron 12 líneas respecto al código base (2 variables de entorno). Las herramientas basadas en decoradores (Weave, Laminar, Langfuse) requieren entre 29 y 40 líneas. La contrapartida: LangSmith captura todo (incluidas las llamadas internas a LangChain que quizás no necesites), mientras que las herramientas basadas en decoradores te dan un control explícito sobre lo que se rastrea.
Solo Langfuse y Laminar ofrecen alojamiento propio gratuito.
Ambos son de código abierto (MIT y Apache 2.0). LangSmith y Weave requieren contratos empresariales para implementaciones autohospedadas.
Weave y LangSmith lideran la coordinación de la evaluación.
Ambas herramientas incluyen orquestadores de evaluación completos que gestionan la iteración, predicción, puntuación y agregación de conjuntos de datos en una sola llamada. Langfuse proporciona infraestructura de puntuación ( create_score() ), pero deja la orquestación en manos del desarrollador. Las funciones de evaluación de Laminar son menos maduras: carece de interfaz de usuario para la comparación de experimentos y ofrece un número limitado de evaluadores predefinidos.
Langfuse tiene el menor costo por unidad a volumen.
$6/100k unidades a partir de 50M. LangSmith cobra por traza ($2.50-5/1k). Weave cobra por MB de datos ingeridos ($0.10/MB de exceso).
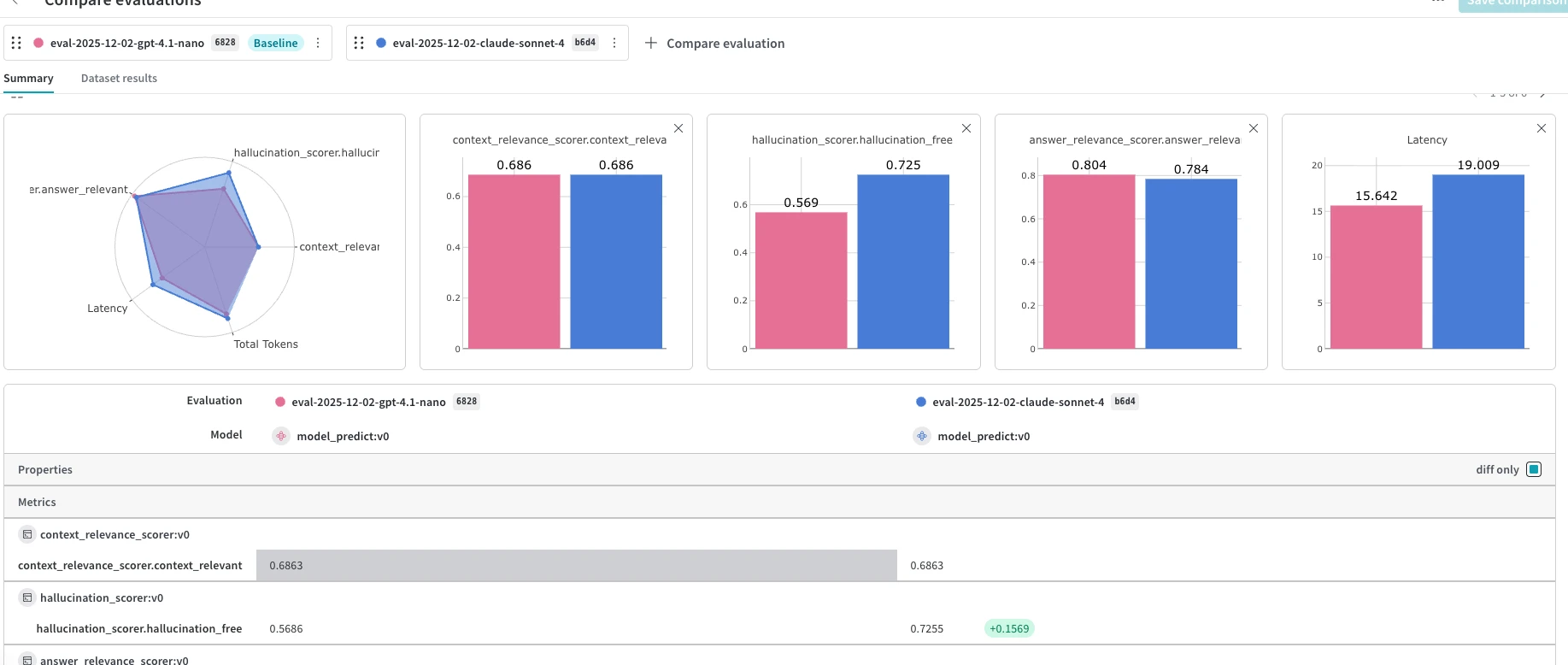
Capacidades de evaluación por plataforma
Pesos y sesgos (tejido)
- Orquestador de evaluación:
weave.Evaluation.evaluate()maneja la iteración, predicción, puntuación y agregación de conjuntos de datos en una sola llamada. 1 - Puntuadores personalizados: Subclase
Scorero cualquier función@weave.op() - Puntuadores predefinidos: Algunos (corrección, etc.)
- Gestión de conjuntos de datos:
weave.Datasetcon control de versiones,publish(),from_pandas() - Comparación de experimentos: pestaña Evaluaciones con vista de comparación + Tablas de clasificación
- Evaluación en línea:
EvaluationLogger, barandillas/monitores
LangSmith
- Orquestador de evaluación: función
evaluate()2 - Puntuadores personalizados:
(Run, Example) -> dict - Evaluadores predefinidos: Sí (corrección de control de calidad, distancia de incrustación, juez LLM basado en criterios)
- Gestión de conjuntos de datos: API CRUD completa, conjuntos de datos versionados.
- Comparación de experimentos: Comparación lado a lado por conjunto de datos
- Evaluación en línea: Colas de anotación, reglas automatizadas en trazas de producción
Laminado
- Orquestador de evaluación: La
evaluate()básica está disponible, pero se usa con menos frecuencia. 3 - Puntuadores personalizados: funciones decoradas
@observe() - Marcadores predefinidos: Mínimos
- Gestión de conjuntos de datos: interfaz de usuario + SDK limitado
- Comparación de experimentos: Manual
- Evaluación en línea:
@observe()en funciones de producción
Langfuse
- Orquestador de evaluación: No hay orquestador integrado. Bucle manual +
create_score()por traza 4 - Puntuadores personalizados: Cualquier código +
create_score(trace_id, name, value) - Puntuadores predefinidos: configuraciones de evaluación basadas en modelos en la interfaz de usuario.
- Gestión de conjuntos de datos: interfaz de usuario + conjuntos de datos API
- Comparación de experimentos: Manual (filtrado de sesiones)
- Evaluación en línea:
create_score()en trazas en vivo, colas de anotación humana
Comparación de precios
Nivel gratuito y retención de datos
Planes de pago y precios de uso
Los precios indicados corresponden a marzo de 2026 y pueden variar con el tiempo. Consulte el sitio web de cada proveedor para obtener las tarifas más actualizadas.
Implementación en la nube, autoalojada y de código abierto
Visibilidad de rastreo y depuración
- Weave muestra una vista de árbol de las llamadas decoradas con
@weave.op(). Al hacer clic en un nodo, se muestran las entradas, las salidas y la temporización. La pestaña Evals enlaza los rastros con los resultados de la evaluación. - LangSmith captura automáticamente el gráfico de ejecución completo de LangChain, incluyendo los pasos internos de la cadena. La vista de seguimiento incluye el recuento de tokens, el desglose de la latencia y las estimaciones de costes por llamada a LLM.
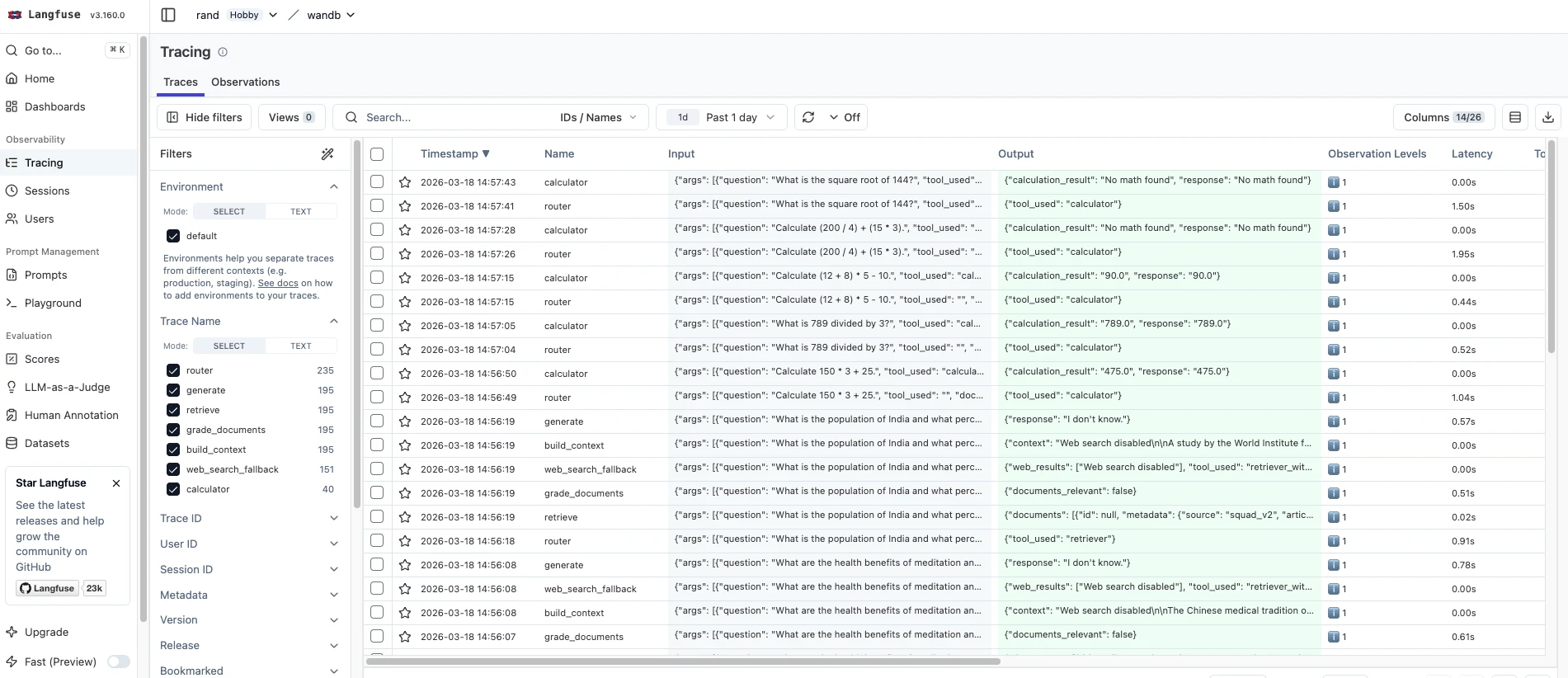
- Langfuse muestra los rastros con intervalos. El seguimiento de sesiones agrupa varias consultas del mismo usuario. El seguimiento de costes está integrado en la vista de rastro.
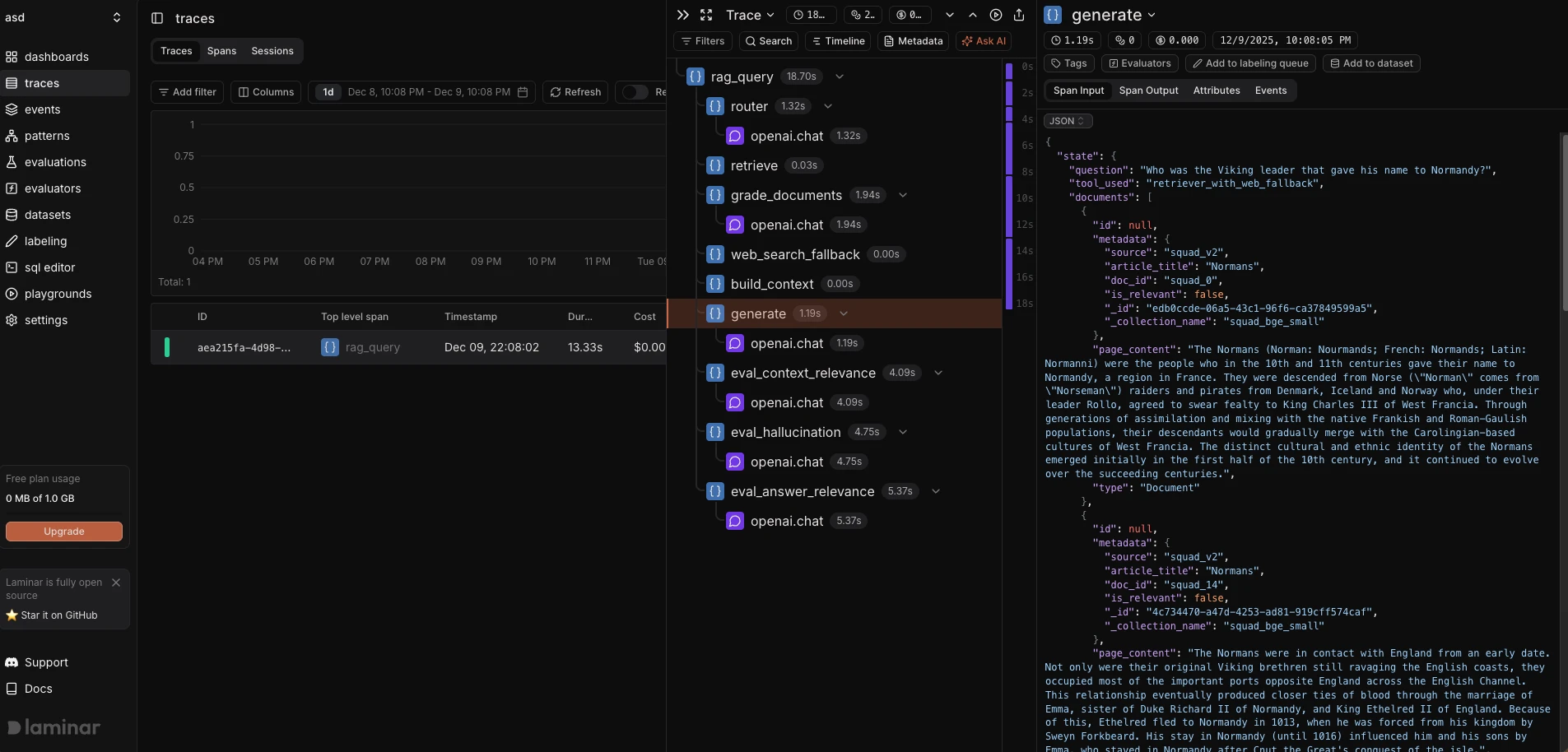
- Laminar muestra una línea de tiempo de intervalos similar a las herramientas de rastreo distribuido. Las funciones decoradas con
@observe()aparecen como intervalos con captura de entrada/salida.
¿Qué herramienta para qué caso de uso?
- Canalización LangChain, se busca un seguimiento sin esfuerzo: LangSmith. Autoinstrumentación de variables de entorno, +12 líneas de código.
- Ya utilizamos W&B, necesitamos orquestación de evaluación: Weave.
weave.Evaluation+ control de versiones de conjuntos de datos + tablas de clasificación. - Necesita alojamiento propio sin contrato empresarial: Langfuse. Código abierto (MIT), Docker Compose, región de datos de la UE.
- ¿Desea observabilidad de código abierto, pero no necesita un orquestador de evaluación?: Laminar. Apache 2.0, decorador ligero
@observe(). - Producción de alto volumen, sensible al costo: Langfuse. $6/100 000 unidades para un volumen superior a 50 millones.
- Se necesitan tanto rastreo como evaluación integrada: Weave o LangSmith. Orquestadores de evaluación completos con gestión de conjuntos de datos.
Metodología de referencia para herramientas de observabilidad RAG
Hardware : Apple M4, 16 GB de RAM, macOS 26.3
Canalización RAG : LangGraph StateGraph con 7 nodos (enrutador, recuperador, clasificador de documentos, sistema de búsqueda web alternativo, calculadora, constructor de contexto, generador)
LLM : openai/gpt-4.1-nano vía OpenRouter (temperatura 0.0)
Enrutador LLM : google/gemini-2.5-flash vía OpenRouter (salida estructurada)
Evaluación LLM : google/gemini-2.5-pro vía OpenRouter
Base de datos vectorial : Qdrant 1.12 (Docker local), distancia coseno, 1204 documentos SQuAD
Incrustaciones : BAAI/bge-small-en-v1.5 (384 dimensiones, inferencia por CPU)
Recuperación de candidatos : los 5 documentos principales por consulta.
Conjunto de consultas : 30 consultas seleccionadas, 20 factuales (recuperación de base de conocimiento), 5 de múltiples saltos (requieren combinar información), 5 matemáticas (enrutadas al nodo de calculadora).
Pipeline : se descarta el calentamiento de 3 consultas. 5 pasadas completas sobre las 30 consultas por plataforma. Total: 150 ejecuciones medidas por plataforma. Temporizador: time.perf_counter() solo envuelve graph.invoke() . Las evaluaciones de LLM-judge se ejecutan después de que el temporizador se detiene. gc.collect() entre iteraciones y plataformas. Primero la línea base, luego cada plataforma secuencialmente.
Variable controlada : Todas las plataformas comparten el mismo código de canalización, instancias LLM, configuración del recuperador y conjunto de consultas. La única variable es la capa de observabilidad.
Pruebas estadísticas: IC del 95% mediante distribución t, U de Mann-Whitney (no paramétrica, bilateral) para significancia, d de Cohen para tamaño del efecto, método IQR para detección de valores atípicos.
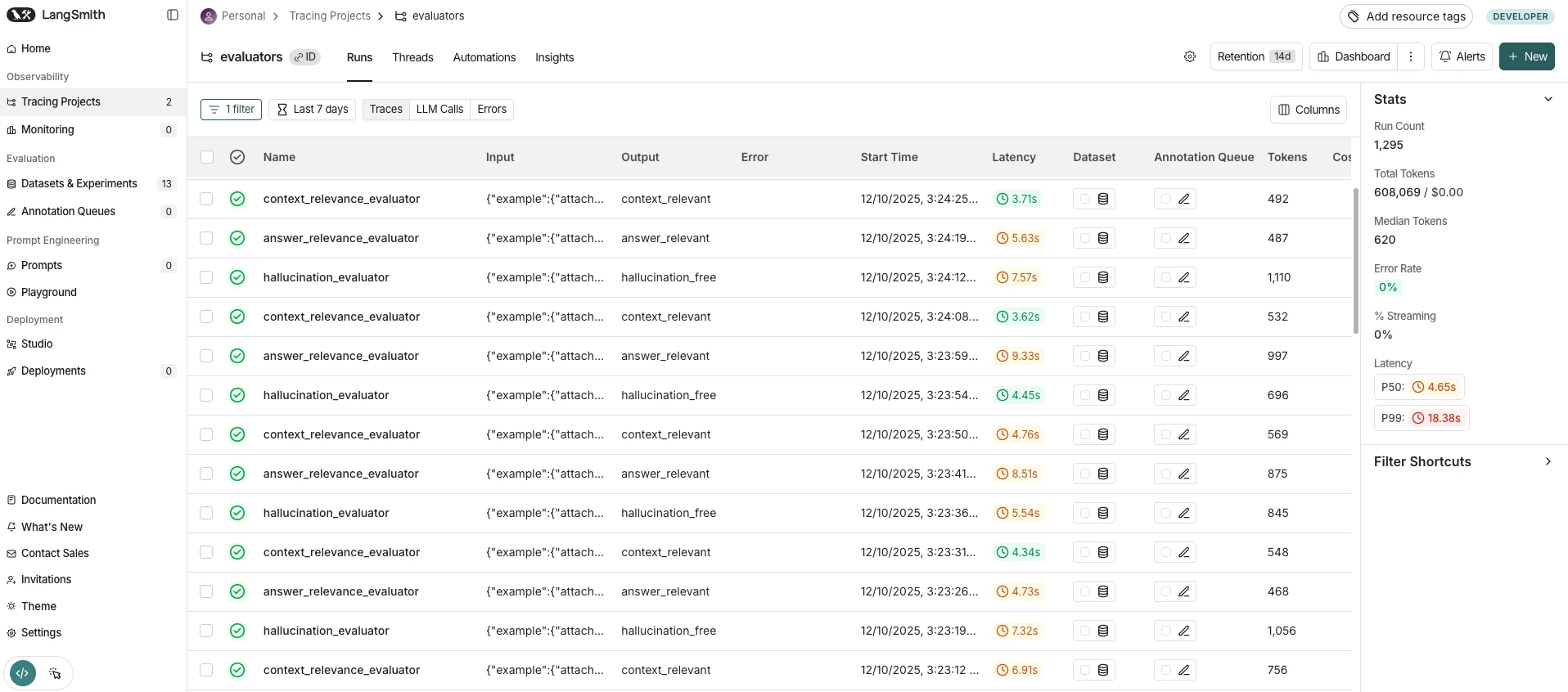
Herramientas probadas
Cómo funciona la observabilidad de RAG
Cada herramienta empaqueta las llamadas a funciones instrumentadas como un "trace" (un árbol de "spans") y las envía a un servidor. La sobrecarga proviene de tres operaciones en cada llamada: (1) creación del span al inicio, (2) serialización de la carga útil al finalizar y (3) transmisión en segundo plano. La mayoría de las herramientas transmiten de forma asíncrona, pero la creación y serialización del span se realizan en línea.
Variables de entorno vs decoradores vs instrumentación del SDK
Instrumentación de variables de entorno (LangSmith). Al configurar LANGCHAIN_TRACING_V2=true , se activan los ganchos de rastreo integrados en LangChain y LangGraph. Cada llamada a LLM, invocación de recuperador y nodo del gráfico se captura automáticamente. No se requieren cambios en el código de la canalización.
(Weave, Laminar, Langfuse). El desarrollador envuelve cada función con un decorador ( @weave.op() , @observe() ). Las funciones sin decorador no se rastrean.
Limitaciones
Carga de trabajo de consulta secuencial de un solo hilo. Las solicitudes concurrentes en producción pueden modificar el perfil de sobrecarga debido a la contención de vaciado asíncrono.
Las API externas de LLM (OpenRouter) dominan la latencia total, comprimiendo la sobrecarga de monitorización relativa. La inferencia local (por ejemplo, Ollama) aumentaría proporcionalmente la sobrecarga.
Solo se admiten sistemas backend en la nube. Las implementaciones autohospedadas de Langfuse y Laminar podrían tener una sobrecarga diferente, ya que omiten la transmisión de red a un servicio de rastreo externo.
La fase de calentamiento elimina los costos de arranque en frío. Las implementaciones sin servidor experimentarían una mayor sobrecarga en la primera solicitud debido a la inicialización del SDK.
LangSmith registra todas las llamadas internas de LangChain, no solo las de los 7 nodos de la canalización. Otras plataformas solo rastrean las funciones decoradas. Esto hace que la comparación se centre en ámbitos de instrumentación diferentes, no en cargas de trabajo equivalentes.
Los datos de precios se han recopilado hasta marzo de 2026. Verifique las tarifas actuales en el sitio web de cada proveedor.
Conclusión
La latencia no es un criterio útil para elegir entre estas herramientas. Las cuatro añadieron menos de 170 ms a una canalización donde las llamadas a la API de LLM tardan entre 1000 y 3000 ms, y ninguna de las diferencias fue estadísticamente significativa.
LangSmith es la opción más rápida para integrarse si utilizas LangChain de 12 líneas y tienes trazabilidad completa. Tanto Weave como LangSmith ofrecen orquestación de evaluación, algo que Langfuse y Laminar no ofrecen. Langfuse y Laminar son las únicas opciones si necesitas autogestionar tu infraestructura sin un contrato empresarial.
Lecturas adicionales
Explore otros puntos de referencia RAG, como:
- Modelos de incrustación: OpenAI vs Gemini vs Cohere
- Los 16 mejores modelos de incrustación de código abierto para RAG
- Base de datos de vectores principales para RAG: Qdrant vs Weaviate vs Pinecone
- Comparativa de Reranker: Los 8 mejores modelos comparados
- Modelos de incrustación multimodal: Apple vs Meta vs OpenAI
- Comparativa RAG gráfica frente a RAG vectorial
- Los 10 mejores modelos de incrustación multilingüe para RAG
Cita esta investigación
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{sar2026,
author = {Sarı, Ekrem},
title = {{Evaluación comparativa de herramientas de observabilidad RAG}},
year = {2026},
month = mar,
howpublished = {\url{https://aimultiple.com/rag-monitoring}},
note = {AIMultiple. Retrieved Marzo 23, 2026}
}
Sé el primero en comentar
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.