Los desafíos de scraping web más comunes
El scraping web se ha vuelto más difícil en los últimos años. Desde 2025, el scraping relacionado con la IA ha planteado importantes preocupaciones legales. Las plataformas y proveedores de infraestructura han adoptado nuevos métodos para controlar los rastreadores de IA y gestionar la recopilación de datos.
¿Cuáles son los principales desafíos del scraping web?
Existen muchos desafíos técnicos que enfrentan los web scrapers debido a las barreras establecidas por los propietarios de datos o sitios web para distinguir entre humanos y bots, y limitar el acceso no humano a su información. Los desafíos del scraping web se pueden dividir en estas categorías distintas:
Desafíos que surgen de los sitios web objetivo:
- Barrera de puntuación de confianza (detección invisible de bots)
- La contaminación de datos por contenido generado por IA
- Contenido dinámico
- Cambios en la estructura del sitio web
- Técnicas anti-scraping (bloqueadores de CAPTCHA, Robots.txt, bloqueadores de IP, Honeypots y huella digital del navegador)
Desafíos inherentes a las herramientas de scraping web:
- Escalabilidad
- Problemas legales y éticos
- Mantenimiento de la infraestructura
Riesgos legales y de cumplimiento
Las plataformas continúan enfrentando nuevas reclamaciones basadas en contratos, competencia desleal, privacidad y mal uso de datos. En 2025, Reddit demandó a Anthropic, alegando que Anthropic raspó comentarios de usuarios de Reddit para entrenar a Claude sin permiso. La demanda se centró en problemas de términos de uso y competencia desleal en lugar de derechos de autor.
Barrera de puntuación de confianza (detección invisible de bots)
El bloqueo estático (IP/User-Agent) ha sido reemplazado por una puntuación de confianza conductual continua. Los proveedores modernos anti-bot (Cloudflare, Akamai) rastrean el jitter del mouse y la velocidad de desplazamiento antes de un clic.
Los scrapers que saltan a un botón o hacen clic con precisión matemática son marcados con una puntuación de confianza baja, lo que lleva a bloqueos suaves donde los datos no se cargan sin un mensaje de error.
Solución:
Las herramientas estándar basadas en WebDriver/CDP son fácilmente detectadas por los sitios web. Utilice bibliotecas modernas como Nodriver, que se comunica directamente con Chrome para no dejar marcadores de automatización, o Camoufox, una versión endurecida de Firefox diseñada específicamente para el sigilo.1
Contaminación por contenido generado por IA
A medida que los scrapers ingieren datos para el entrenamiento, cada vez se encuentran más con el colapso del modelo, raspando accidentalmente alucinaciones generadas por IA que degradan la calidad de su propia salida. Esto hace que la autenticidad de los datos sea un desafío técnico en lugar de una verificación de calidad.
Solución:
Implemente una capa de validación previa al almacenamiento que calcule la perplejidad del texto raspado. El contenido generado por IA a menudo tiene una perplejidad artificialmente baja. Descarte los datos que caen por debajo de un cierto umbral de unicidad.
Contenido web dinámico
El contenido web dinámico plantea un desafío significativo para los web scrapers, ya que altera fundamentalmente cómo se entrega y muestra la información en una página web.
A diferencia de los sitios estáticos, donde todo el contenido está en el archivo HTML inicial, los sitios dinámicos construyen la página sobre la marcha, a menudo en respuesta al comportamiento del usuario. Tecnologías como AJAX (JavaScript y XML asíncronos) están en el núcleo de los sitios web dinámicos.
El problema principal es que las herramientas de scraping estándar no son navegadores web. Ven la carcasa HTML inicial, que puede contener marcadores de posición, animaciones de carga y etiquetas <script>, pero a menudo carece de los datos reales que desea extraer. Estas herramientas simples no ejecutan JavaScript.
Solución:
Para superar estos desafíos, los web scrapers deben evolucionar de simples analizadores HTML a herramientas que puedan renderizar completamente una página web como el navegador de un humano.
Un navegador sin cabeza es un navegador web sin una interfaz gráfica de usuario (GUI). Se ejecuta en segundo plano pero tiene todas las capacidades de un navegador estándar, incluido un motor de JavaScript potente.
Herramientas como Selenium, Puppeteer y Playwright le permiten controlar programáticamente los navegadores (como Chrome, Firefox o WebKit). Al utilizar estas herramientas avanzadas, puede crear web scrapers que puedan interactuar con sitios web complejos y dinámicos y acceder a contenido que sería completamente invisible para métodos de scraping web más simples.
Navegadores remotos
Otra solución son los navegadores de scraping, también llamados navegadores remotos. Son navegadores gestionados por empresas de datos web. También permiten a los web scrapers interactuar con JavaScript.
Cambios en la estructura del sitio web
Los sitios web se están mejorando continuamente. Estas alteraciones pueden afectar la disposición, el diseño o el código subyacente de un sitio. El impacto de un cambio menor:
- Por ejemplo, si un desarrollador decide cambiar la clase del elemento de precio de price a current-price para mayor claridad, las instrucciones del scraper fallarán:
- El scraper ya no podrá encontrar el precio. Podría devolver un error, un valor vacío o, peor aún, podría capturar accidentalmente la pieza de datos incorrecta que resulta estar en una ubicación similar.
- Debido a que estos cambios pueden ocurrir en cualquier momento y sin previo aviso, el código del scraper necesita constantemente ajustes potenciales.
Solución
En lugar de depender de selectores altamente específicos y frágiles, los desarrolladores pueden escribir selectores más inteligentes. Por ejemplo, en lugar de buscar un <span> con la clase exacta price, un analizador adaptable podría buscar un <span> que esté ubicado junto al texto "Precio:" o uno que contenga un signo de dólar ($).
Las verificaciones automáticas pueden ejecutarse periódicamente para validar los datos raspados. Supongamos que el campo de precio comienza a devolver valores vacíos para todos los productos. En ese caso, el sistema puede alertar automáticamente al desarrollador de que la estructura del sitio web probablemente haya cambiado y que el analizador necesita actualizarse.
LLMs
Los modelos de IA pueden utilizarse para identificar elementos a raspar o pueden utilizarse para recopilar datos de páginas web. Aunque añaden latencia y costo al scraping, aumentan la adaptabilidad de los web scrapers.
Técnicas anti-scraping
Muchos sitios web emplean tecnologías anti-scraping para prevenir o dificultar las actividades de scraping web. Los siguientes puntos proporcionan una visión general de algunas de las medidas anti-bot más comunes encontradas en el proceso de scraping web:
Bloqueadores de CAPTCHA
Los sitios web utilizan CAPTCHA cuando sospechan que un visitante podría ser un bot. Esto es común en páginas web para registro de usuarios, formularios de inicio de sesión, secciones de comentarios y durante los procesos de pago para artículos de alta demanda.
Las implementaciones de CAPTCHA excesivamente agresivas pueden bloquear "buenos bots", como el bot de Google que rastrea la web para indexar páginas para resultados de búsqueda. Si el rastreador de Google es bloqueado, las páginas de un sitio web pueden no indexarse correctamente, lo que puede afectar negativamente sus prácticas de SEO y su clasificación en los motores de búsqueda.
Solución:
Para navegar este obstáculo, los scrapers deben estar equipados con un mecanismo para resolver estos desafíos. Aunque es efectivo, el uso de un servicio de resolución de CAPTCHA añade otra capa de complejidad y costo financiero al proyecto de scraping web, ya que estos servicios suelen cobrar por CAPTCHA resuelto.
Robots.txt
Desde 2025, la gobernanza de rastreadores se ha expandido más allá del clásico robots.txt. Cloudflare introdujo controles de rastreadores de IA, funciones gestionadas de robots.txt, Política de Señales de Contenido y herramientas de Pago por Rastreo que permiten a los editores bloquear, permitir o cobrar a los rastreadores por el acceso.2
Solución:
El enfoque correcto es encontrar una forma oficialmente sancionada de obtener los datos web. La mejor alternativa es ver si el sitio web ofrece una API para el acceso a datos. Si no hay ninguna API pública disponible, el siguiente paso es la comunicación directa. Puede contactar al propietario del sitio web o al propietario de los datos, explicando quién es y qué pretende hacer con los datos.
Bloqueo de IP
El bloqueo de IP (también conocido como prohibición de IP) es una de las medidas anti-scraping más comunes y fundamentales empleadas por los sitios web. Cuando el servidor de un sitio web detecta un tráfico inusualmente alto desde una sola dirección IP, lo marca como sospechoso. Una vez que su IP está bloqueada, cualquier solicitud adicional de su scraper será rechazada.
Solución:
Un proxy es un servidor intermediario que se sitúa entre su scraper y el sitio web objetivo. Cuando envía una solicitud a través de un proxy, el sitio web ve la solicitud provenir de la dirección IP del proxy, no de su propia dirección IP. Dos tipos poderosos de proxies para este propósito:
- Proxies rotativos: Su herramienta de scraping web se configura para usar este grupo, y con cada nueva solicitud (o después de un número determinado de solicitudes), rota automáticamente a una dirección IP diferente. Esto distribuye sus solicitudes a través de múltiples direcciones IP, por lo que ninguna supera los límites de velocidad del sitio web.
- Proxies residenciales: Las direcciones IP en un grupo de proxy residencial pertenecen a conexiones a Internet reales de grado consumidor proporcionadas por Proveedores de Servicios de Internet (ISP) a propietarios de viviendas. Dado que el tráfico se origina en una dirección IP residencial legítima, es casi imposible para un sitio web distinguir la solicitud de un scraper de la de un usuario humano genuino.
Trampas Honeypot
Los honeypots son sistemas informáticos diseñados para atraer a hackers y evitar que accedan a sitios web. Una trampa honeypot suele aparecer como una parte legítima del sitio web y contiene datos que un atacante podría apuntar.
Si un bot de rastreo intenta extraer el contenido de una trampa honeypot, entrará en un bucle infinito de solicitudes y no podrá extraer más datos.
Por qué los bots caen en ello
Un usuario humano interactúa con la versión renderizada y visual de un sitio web y nunca vería ni haría clic en este enlace oculto. Sin embargo, muchos scrapers simples no renderizan la página visualmente.
Funcionan analizando el código fuente HTML sin procesar y extrayendo programáticamente todos los enlaces (etiquetas <a href="...">) que encuentran. Dado que el enlace honeypot existe en el HTML, el bot ingenuo lo verá y lo seguirá, como cualquier otro enlace legítimo.
Solución
En lugar de analizar el HTML sin procesar, utilice un navegador sin cabeza, como Selenium, Puppeteer o Playwright. Además, al definir ubicaciones específicas y predecibles para los enlaces que desea seguir, puede reducir la probabilidad de que su scraper tropiece con un enlace honeypot que se haya colocado intencionalmente en una parte oscura del HTML.
Huella digital del navegador
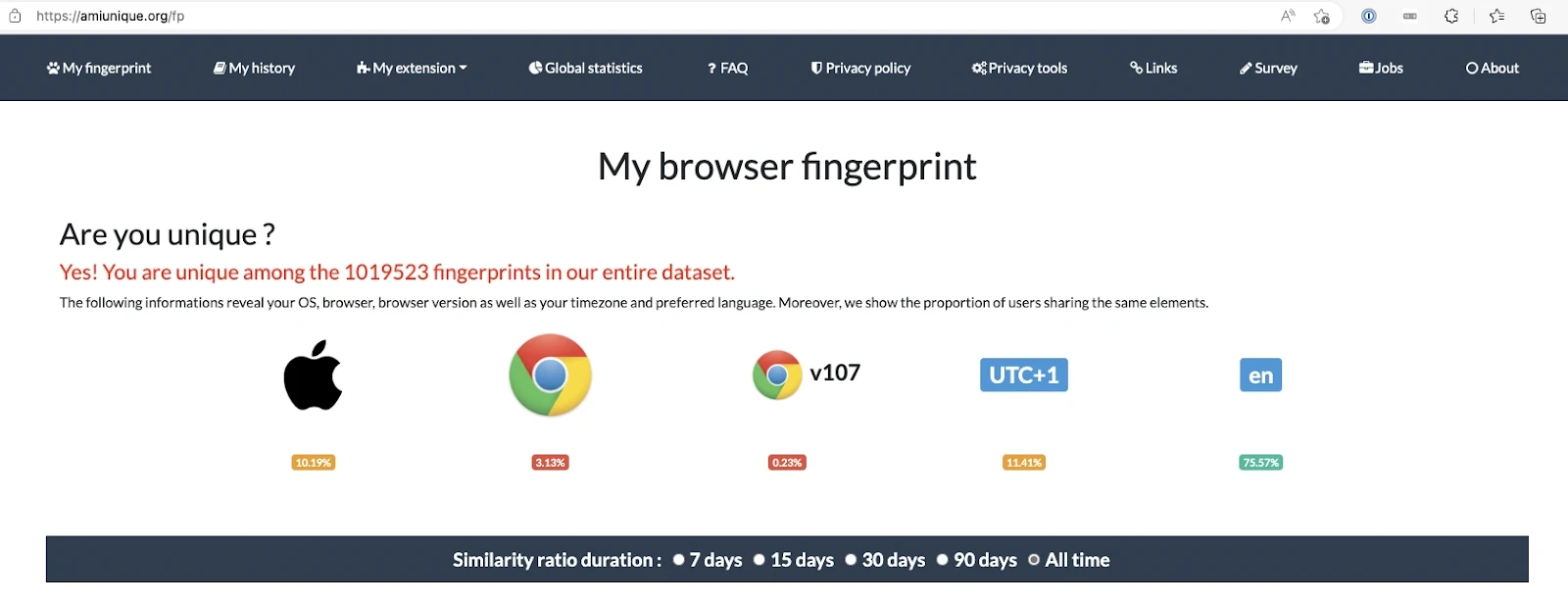
La huella digital del navegador es un método utilizado por los sitios web para recopilar información sobre sus visitantes a través de sus direcciones IP. Cada vez que accede a un sitio web, su dispositivo emite una solicitud de conexión al sitio para cargar su contenido. Esto permite que el sitio web recupere y almacene los datos transmitidos por su navegador sobre su dispositivo.
Los sitios web pueden acumular detalles extensos sobre el dispositivo de un usuario, lo que les permite personalizar sugerencias para sus visitantes utilizando la huella digital del navegador. Por ejemplo, el sitio web objetivo puede extraer datos sobre sus agentes de usuario, encabezado HTTP, configuraciones de idioma y complementos instalados.
Fuente: AmIUnique
El desafío para los scrapers
La huella digital del navegador plantea un desafío significativo porque los scrapers, por defecto, tienen huellas digitales extrañas e inconsistentes.
- Huellas digitales genéricas: Un scraper básico que utiliza una biblioteca simple enviará un conjunto mínimo de encabezados y no tendrá complementos, resolución de pantalla u otros atributos "humanos".
- Huellas digitales inconsistentes: Un scraper podría utilizar proxies rotativos, lo que hace que su dirección IP aparezca desde Alemania en una solicitud y desde Japón en la siguiente.
Solución
Utilice navegadores sin cabeza como Selenium, Puppeteer o Playwright. Estos son motores de navegador reales que generan una huella digital más completa y creíble desde el principio en comparación con las bibliotecas HTTP simples.
También puede mantener una lista de cadenas de User-Agent estándar y del mundo real y rotarlas para diferentes sesiones. Asegúrese de que los encabezados HTTP enviados también sean consistentes con los de un navegador real.
Escalabilidad
Es posible que necesite raspar una gran cantidad de datos web de múltiples sitios web para obtener información sobre la inteligencia de precios, la investigación de mercado y las preferencias de los clientes. A medida que aumenta la cantidad de datos a raspar, necesita un web scraper altamente escalable para realizar múltiples solicitudes en paralelo.
Solución:
Necesita utilizar un web scraper diseñado para manejar solicitudes asíncronas para mejorar la velocidad y recopilar grandes cantidades de datos más rápidamente.
El scraping de datos asíncrono es una técnica que permite a un scraper enviar múltiples solicitudes a diferentes sitios web sin esperar a que cada uno responda antes de enviar la siguiente.
Por ejemplo, si un sitio web tarda en responder, un scraper asíncrono puede continuar enviando y procesando solicitudes a otros sitios web más rápidos mientras tanto.
Mantenimiento de la infraestructura
Para mantener un rendimiento óptimo del servidor, es esencial actualizar o expandir regularmente recursos como el almacenamiento para acomodar volúmenes de datos crecientes y las complejidades del scraping web. Debe actualizar continuamente su infraestructura de scraping web para mantenerse al día con las demandas cambiantes.
Construir y gestionar una infraestructura de scraping requiere una amplia gama de habilidades técnicas. Esto incluye administración de servidores, gestión de redes, optimización de bases de datos y el conocimiento especializado necesario para eludir los mecanismos anti-bot.
Solución:
Cuando externalice sus requisitos de scraping web, asegúrese de que el proveedor de servicios ofrezca características integradas como un rotador de proxy y un analizador de datos. Además, el proveedor debe ofrecer opciones escalables y actualizar regularmente su infraestructura para satisfacer las necesidades cambiantes.
Cita esta investigación
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Los desafíos de scraping web más comunes}},
year = {2026},
month = may,
howpublished = {\url{https://aimultiple.com/web-scraping-challenges}},
note = {AIMultiple. Recuperado el 13 de Mayo de 2026}
}
Sé el primero en comentar
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.