Top 5 des frameworks d'IA agentiques open source
Nous avons comparé 4 frameworks open source agentiques populaires sur 2 000 exécutions (5 tâches, 100 exécutions chacune par framework), en mesurant la latence de bout en bout, la consommation de tokens et les différences architecturales.
Benchmark des frameworks d'IA agentiques
Nous avons examiné comment les frameworks eux-mêmes influencent le comportement des agents et l'impact qui en résulte sur la latence et la consommation de tokens.
LangGraph est le framework le plus rapide avec les valeurs de latence les plus basses sur toutes les tâches, tandis que LangChain présente la latence et la consommation de tokens les plus élevées.
Sur 5 tâches et 2 000 exécutions, LangChain se révèle être le framework le plus économe en tokens, tandis qu'AutoGen domine en matière de latence ; LangGraph et LangChain suivent de près. CrewAI affiche le profil global le plus lourd.
Tâche 1 : Agrégation de base
Tout d'abord, nous avons mesuré la surcharge de chaque framework lors de l'appel d'un seul outil et du retour du résultat, sans effectuer de raisonnement complexe.
LangChain & LangGraph : Pour les tâches simples, ils s'exécutent presque aussi vite que du code non agentique, les deux terminant en moins de 5 secondes avec moins de 900 tokens de prompt. L'architecture à machine d'état de LangGraph n'introduit aucune latence notable par rapport à LangChain à ce niveau de simplicité ; la surcharge de la gestion d'état se matérialise à mesure que la complexité des tâches augmente.
AutoGen : Se situe légèrement au-dessus de LangChain et LangGraph en termes de latence et de consommation de tokens, reflétant le coût de base de sa boucle de conversation multi-agents, deux agents échangeant des messages même pour une tâche en une seule étape.
CrewAI : Même lorsqu'on lui demande d'effectuer un seul appel d'outil, il présente ce que l'on pourrait appeler un « surcoût managérial », consommant près de 3 fois plus de tokens que LangChain et prenant presque 3 fois plus de temps. Le processus de vérification en plusieurs étapes entre ses personas Planificateur et Analyste offre une approche approfondie mais gourmande en ressources qui privilégie l'exhaustivité à la vitesse. Ce coût est structurel : il apparaît indépendamment de la complexité de la tâche.
Tâche 2 : Analyse comparative des revenus (gestion d'état)
Dans la tâche 2, nous voulions observer la capacité des frameworks à conserver deux groupes de filtres différents en mémoire (persistance d'état) et à les combiner.
CrewAI
Dans notre analyse des logs, nous avons constaté que CrewAI offre le plus haut niveau de transparence de l'infrastructure parmi les frameworks, mais au prix de la consommation de ressources la plus élevée.
Au lieu de renvoyer immédiatement les données récupérées, CrewAI valide à plusieurs reprises ses propres processus via un mécanisme d'auto-révision. Ce comportement exploratoire l'a amené à atteindre la limite configurée max_iter=10, laissant certaines exécutions bloquées dans une boucle de réflexion continue sans produire de sortie JSON.
La cause profonde de ce comportement est que CrewAI injecte des instructions à plusieurs niveaux dans le prompt système, attribuant à chaque agent un rôle, un objectif et un historique, tout en imposant une boucle de style ReAct Pensée → Action → Observation à chaque étape. Même pour les tâches simples, le LLM ne peut pas sauter ce cérémonial et produit consciencieusement des monologues internes verbeux, ce qui s'aggrave encore dans les scénarios multi-agents.
CrewAI a consommé près de deux fois plus de tokens que les autres frameworks et a mis plus de trois fois plus de temps que LangChain, ce qui le rend plus adapté aux transitions d'état complexes et à la prise de décision multifactorielle plutôt qu'aux tâches simples de récupération de données.
LangChain
Le framework le plus rapide et le plus rentable. Dans nos logs, nous avons observé que LangChain termine la tâche en 5-6 étapes sans détour : Charger → Filtrer → Calculer → Filtrer → Calculer → Sortie. Comme sa gestion d'état est très simple, le surcoût est quasi nul et la latence est la plus faible parmi tous les frameworks.
AutoGen
A offert des performances très équilibrées. Dans la tâche 2, il a égalé LangGraph presque exactement en termes d'utilisation de tokens et de latence, montrant que le surcoût de la boucle de conversation ne s'aggrave pas significativement lorsque la chaîne de tâches reste linéaire.
Cependant, il ajoute parfois une étape de vérification supplémentaire pour confirmer les paramètres lors du processus d'appel d'outil, ce qui le rend légèrement plus lent que LangChain. Lorsqu'il rencontre une erreur dans un appel d'outil ou que les données ne reviennent pas comme prévu, il met immédiatement à jour son raisonnement à l'étape suivante et arrive au bon JSON. Comme il gère les sorties d'outils comme un flux conversationnel, c'est l'un des frameworks les plus résilients face aux erreurs logiques.
LangGraph
Dans cette tâche, LangGraph est le framework le plus stable grâce à son architecture basée sur les graphes. Dans ses logs, nous avons observé que l'état est transporté de manière très propre tout au long de l'exécution. Le risque de contamination des données ou d'interférence entre segments est au niveau le plus bas dans ce framework. Sur l'ensemble des 100 exécutions, il a produit des résultats avec presque le même nombre d'étapes et dans la même plage de latence.
Tâche 3 : Analyse de seuils (discipline numérique)
Dans cette tâche, nous voulions voir avec quelle précision les frameworks traduisent des conditions numériques en langage naturel, telles que « moins d'un an d'ancienneté » et « plus de 70 $ de frais mensuels », en paramètres d'outil précis comme tenure_max=12 et charges_min=70.0.
Le LLM sait effectuer cette conversion ; ce que nous voulions vraiment tester, c'est si le framework peut protéger ces paramètres tout au long de ses propres mécanismes de nouvelle tentative, du contexte de nouveau prompt et des cycles de gestion d'état.
LangChain & LangGraph
Les deux frameworks ont transmis les paramètres (tenure_max=12, charges_min=70) directement à l'outil exactement tels que le LLM les a produits, sans aucune modification ni boucle de nouveau prompt. Cette efficacité se reflète dans les chiffres : les deux frameworks ont terminé la tâche 3 en moins de 9 secondes avec moins de 1 800 tokens de prompt, le plus bas dans cette tâche.
Quand nous voulions mesurer si les seuils numériques sont préservés sans que le framework n'interfère, ces deux-là ont répondu à nos attentes : quel que soit le paramètre généré, c'est celui qui a été exécuté.
AutoGen
AutoGen réussit pleinement en matière de précision numérique. Dans certaines exécutions, on a observé que le framework ajoutait une étape de vérification avant de transmettre le paramètre généré par le LLM à l'outil, ce qui signifie que le framework consacrait une étape supplémentaire tout en préservant le paramètre. Avec 2 480 tokens et 8 secondes, il a égalé la latence de LangChain malgré l'étape supplémentaire, confirmant que le surcoût de vérification est réel mais faible. Il a répondu à nos attentes en termes d'intégrité des paramètres, l'étape de confirmation introduisant un coût marginal en tokens plutôt qu'une pénalité de latence significative.
CrewAI
Le comportement le plus notable a été observé avec CrewAI, qui a terminé la tâche 3 en 30 secondes avec 4 360 tokens, le plus élevé dans cette tâche. Deux modèles d'échec distincts sont ressortis de l'analyse des logs.
Dans certaines exécutions, une valeur qui aurait dû être 68.81% a été renvoyée sous la forme 0.6878 (ratio décimal). Cela indique que la sérialisation de la sortie du framework peut priver la sortie du LLM de son contexte d'origine.
Les logs montrent que le LLM a initialement produit les bons paramètres, tenure_max=12 et charges_min=70. Cependant, une fois que CrewAI est entré dans une boucle « Échec de l'analyse », le framework a poussé le LLM à reconsidérer. Dans le contexte du nouveau prompt, le LLM a déplacé le seuil à tenure_max=14 et a complètement désactivé le filtre charges_min, produisant un taux d'attrition de 46.84%, qui est en fait le taux d'attrition de tous les clients ayant une ancienneté inférieure à 14. C'était exactement le scénario que nous voulions observer : le mécanisme de nouvelle tentative du framework peut corrompre un paramètre que le LLM avait correctement défini.
Tâche 4 : Résilience aux erreurs et capacité de pivotement
Dans cette tâche, nous voulions voir comment chaque framework gère les scénarios perturbateurs et observer l'impact sur la latence et la consommation de tokens. L'outil génère 3 types d'erreurs différents successivement (Réseau, Délai d'attente, Limite de débit), poussant l'agent dans une impasse. Les deux premières erreurs demandent à l'agent de réessayer, et après avoir réessayé les deux, l'erreur de limite de débit entrante indique à l'agent d'attendre 10 secondes. Une fois que l'agent a attendu et réessayé, l'outil commence à fonctionner normalement.
LangGraph & AutoGen
Ces deux frameworks ont trouvé des solutions alternatives de manière autonome face aux défaillances d'outils dans cette tâche.
Lorsque l'outil a renvoyé un avertissement de limite de débit, au lieu de faire une pause et d'attendre, ces agents ont décidé d'abandonner complètement l'outil défaillant et de trouver une voie alternative. Leur approche était : « Puisque cet outil ne fonctionne pas, je vais filtrer chaque méthode de paiement une par une, calculer le taux d'attrition pour chacune séparément, puis combiner les résultats moi-même. »
Méthode : Au lieu d'accomplir la tâche avec un seul appel d'outil, ils l'ont décomposée en utilisant deux outils distincts, un pour le filtrage et un pour le calcul, traitant chaque PaymentMethod (chèque électronique, chèque postal, etc.) individuellement.
Ces agents fonctionnent avec un raisonnement orienté vers les objectifs plutôt qu'une dépendance au chemin. Si le chemin le plus court n'est pas disponible, ils peuvent construire un plan d'exécution alternatif en quelques secondes.
LangGraph a atteint 15 010 tokens de prompt dans la tâche 4, le nombre de tokens le plus élevé pour une seule tâche sur l'ensemble du benchmark, car sa machine d'état a accumulé l'historique croissant de chaque appel d'outil manuel dans le contexte à chaque étape. AutoGen a suivi avec 10 750 tokens, un peu plus contenu grâce à sa gestion conversationnelle des résultats intermédiaires. Malgré cela, les deux ont terminé en environ 24-27 secondes, confirmant que le coût supplémentaire en tokens ne s'est pas traduit par une latence significative car le pivotement lui-même a été rapide.
CrewAI
Bien qu'ayant montré la consommation de tokens la plus élevée dans les tâches précédentes, CrewAI a affiché la consommation de tokens la plus faible) mais les valeurs de latence les plus élevées dans cette tâche.
Pourquoi le nombre de tokens le plus bas ?
CrewAI n'est pas passé par une solution de contournement manuelle de 10-15 étapes comme ses concurrents. Lorsqu'il a rencontré des erreurs, au lieu de réinjecter à plusieurs reprises tout l'historique et les données intermédiaires complexes dans le LLM à chaque étape, il a construit une boucle de raisonnement plus ciblée et modulaire. En évitant la verbosité inutile, il est devenu le framework le plus rentable dans cette tâche.
Pourquoi une latence élevée ?
La structure managériale de CrewAI fait une pause et réévalue le plan lorsqu'elle rencontre une erreur. Lorsqu'il a reçu l'avertissement d'attente de 10 secondes, il a passé plus de temps dans la phase de « planification stratégique ». De plus, plutôt que de pivoter vers un autre outil pour le filtrage, il a constamment choisi d'attendre que l'outil principal récupère ou de tenter avec l'outil stable, ce qui a prolongé la durée globale.
LangChain
LangChain a subi sa transformation la plus significative dans cette tâche, prouvant pourquoi la résilience dépend d'une configuration appropriée.
Lors de notre première exécution, LangChain a planté à chaque tentative avec une erreur de connexion (ConnectionError).
L'AgentExecutor par défaut de LangChain traite les exceptions Python brutes levées à l'intérieur d'un outil comme des erreurs fatales et met fin au processus. Contrairement à ses concurrents, il n'applique pas par défaut la philosophie « les erreurs sont des observations ». Comme l'agent ne voit jamais l'erreur, il n'a aucune chance de raisonner à son sujet.
Nous avons enveloppé l'appel d'outil dans langchain_agent.py avec un bloc try-except. Cela a converti l'erreur en un message lisible que l'agent pouvait traiter.
Comportement après correction : Après avoir appliqué la correction, nous avons observé dans les logs de LangChain qu'il a montré exactement le même raisonnement que LangGraph. Il a reçu 3 erreurs de l'outil, a immédiatement changé de stratégie et a pivoté pour utiliser deux outils distincts, un pour le filtrage et un pour le calcul, a traité chaque méthode de paiement individuellement et a combiné les résultats.
LangChain est en réalité tout aussi capable et adaptable que LangGraph, mais comme la gestion des erreurs du framework était désactivée par défaut, il n'a pas eu l'occasion de démontrer cette capacité. Une fois correctement configuré, il a atteint le résultat correct en utilisant la même approche de voie alternative.
Pourquoi ces différences se sont-elles produites ? (analyse de l'architecture des frameworks)
Si le comportement de l'agent dépendait uniquement du LLM (GPT-5.2), tous les frameworks auraient dû se comporter de manière similaire. Cependant, les différences nettes dans ces ratios sont enracinées dans les mécanismes de boucle interne propres aux frameworks :
1. LangGraph & AutoGen (90% de pivotement) :
LangGraph fonctionne sur une architecture de machine d'état, tandis qu'AutoGen fonctionne sur un modèle basé sur la conversation. Dans les deux systèmes, les erreurs sont traitées en boucle de rétroaction. Dans LangGraph, l'état qui reçoit l'erreur passe au nœud suivant ; dans AutoGen, l'agent proxy transmet l'erreur à l'assistant sous forme de message de chat. Ce mécanisme d'incitation constant force l'agent à continuer à chercher une solution. Comme l'agent est confronté à plusieurs reprises à la question « J'ai une erreur, que dois-je faire ? », la probabilité qu'il décide d'emprunter une voie manuelle alternative s'élève à 90%.
2. LangChain (65% de pivotement / 35% d'attente) :
LangChain fonctionne sur une architecture AgentExecutor séquentielle. Même avec la gestion des erreurs en place, sa boucle d'exécution a une structure plus linéaire et se concentre principalement sur la production d'une réponse finale. Si l'outil génère des erreurs pendant 3-4 étapes, LangChain préfère parfois attendre que l'outil réussisse à la prochaine tentative ou produise un résultat à partir du contexte existant, plutôt que de pivoter vers une stratégie alternative. Comme le verrouillage d'état de LangChain est plus flexible que celui de LangGraph, son ratio attente/solution directe se situe autour de 35%.
3. CrewAI (0% de pivotement) :
CrewAI fonctionne sur une architecture de processus managérial. Ses agents sont enveloppés dans des définitions de Rôle et de Tâche. Lorsque des erreurs se produisent, son architecture interne déclenche généralement une logique d'auto-correction ou de nouvelle tentative. Cependant, un changement radical de stratégie comme « abandonnons tout le plan et faisons un filtrage manuel en 5 étapes » entre en conflit avec la structure de plan managérial de CrewAI. Il fonctionne avec la discipline de « Je dois réparer l'outil qui m'a été donné ou utiliser l'alternative la plus proche » plutôt que d'abandonner complètement son plan. C'est fondamentalement une approche centrée sur le plan plutôt qu'une approche centrée sur l'objectif.
Tâche 5 : Orchestration des données non structurées (routage des données non structurées)
Dans la tâche 5, nous avons observé comment les frameworks se comportent lorsqu'ils rencontrent des colonnes JSON et de texte long (LongText) dans un CSV. Les agents devaient d'abord découvrir le type de données de ces colonnes, puis sélectionner les bons outils de traitement, soit séquentiellement, soit en parallèle.
Dans le monde réel, la gestion des données non structurées exige qu'un agent aille au-delà des données tabulaires standard et travaille avec des blobs JSON, des paragraphes en texte libre ou des objets imbriqués.
Pour qu'un framework gère correctement ce type de données, il doit bien faire deux choses :
1- une intelligence de découverte qui comprend quel outil convient à quel type de données
2- un mécanisme d'orchestration qui coordonne plusieurs appels d'outils indépendants.
Nous avons conçu la tâche 5 spécifiquement pour mesurer ces deux capacités séparément.
AutoGen
AutoGen a offert une performance solide dans cette tâche, terminant avec 8 170 tokens de prompt et une latence médiane de 47 secondes, le résultat le plus rapide et le plus économe en tokens de la tâche 5.
La boucle de conversation au cœur de son architecture, la messagerie entre AssistantAgent et UserProxyAgent, est généralement considérée comme une structure qui conduit à la verbosité. Cependant, dans la tâche 5, cette structure s'est transformée en avantage.
En examinant l'historique de la conversation, le LLM a reconnu que les colonnes Metadata et SupportNotes étaient indépendantes l'une de l'autre. Il a ensuite envoyé une seule réponse TOOL CALLS listant 4 outils simultanément : inspect_column(Metadata), inspect_column(SupportNotes), parse_json_column(…) et summarize_text_column(…) se sont tous exécutés en parallèle. Cela lui a permis de terminer la tâche en 3 tours de LLM, avec le moins de tokens et le moins d'étapes.
La raison technique de ce comportement est claire : le moteur d'exécution d'outils d'AutoGen exécute la liste tool_calls renvoyée par le LLM de manière atomique et collecte les résultats en une seule étape de conversation. La philosophie « gérer la conversation » du framework permet naturellement d'ouvrir plusieurs canaux parallèles en même temps, et les chiffres de tokens et de latence le confirment directement.
LangGraph
LangGraph a terminé avec 9 150 tokens de prompt et 70 secondes de médiane, proche d'AutoGen en tokens mais plus lent en temps. Son architecture de machine d'état a affiché à la fois sa plus grande force et sa faiblesse la plus notable simultanément dans la tâche 5.
Dans chaque exécution, la boucle nœud llm → nœud tools → llm accumule toutes les sorties d'outils précédentes dans l'état et les transmet au LLM. Cette structure garantit que l'agent n'oublie jamais rien, ce qui est normalement un avantage significatif.
Cependant, dans la tâche 5, cette force a joué contre lui. LangGraph trouvait les bons outils et construisait le bon segment. Mais même après la fin de l'analyse, il détectait des ambiguïtés dans l'état qui s'accumule, interprétant les étapes terminées comme encore en attente, et déclenchait à plusieurs reprises des appels d'outils supplémentaires. Bien qu'il ait récupéré les données nécessaires et qu'il soit sur le point de produire la bonne réponse, le signal « étape manquante » de la machine d'état s'est déclenché et l'agent est entré dans des boucles inutiles. En conséquence, le nombre d'appels d'outils par exécution variait entre 6 et 16. Le pouvoir de l'état de « ne jamais rien oublier » faisait parfois apparaître des étapes terminées comme incomplètes, ramenant l'agent dans des cycles redondants et poussant la latence 23 secondes au-dessus d'AutoGen malgré un nombre de tokens comparable.
CrewAI
Les performances de CrewAI dans la tâche 5 ont produit la plus grande variance sur l'ensemble du benchmark. Dans certaines exécutions, il a suivi une séquence parfaite avec 5 appels d'outils, sans détour, s'exécutant comme un script. Dans ces exécutions, la structure managériale définie par les rôles et les tâches de CrewAI a fonctionné exactement comme prévu : lorsque l'agent comprenait clairement son rôle, il se comportait de manière prévisible et avec discipline.
Cependant, dans d'autres exécutions (par exemple, exécution 16 : 35 appels d'outils), un chaos complet s'en est suivi. La cause profonde était le monologue interne (Thought) que CrewAI génère à chaque étape. Après avoir correctement construit le segment avec le bon filtre, le monologue intérieur de l'agent a commencé à se demander si des filtres supplémentaires devaient également être appliqués. Après avoir vu le résultat, il a douté de la validité du segment actuel ou si le précédent devait avoir la priorité. Ce doute l'a poussé à recharger les données à partir de zéro. Ensuite, il a filtré à nouveau, est entré dans une autre boucle de vérification, a douté à nouveau et a répété cette spirale 8 fois.
Dans CrewAI, chaque Thought produit une évaluation indépendante, et ces évaluations invalident parfois des étapes précédemment vérifiées. Le réflexe de « vérification continue » du processus managérial, dans certaines exécutions, a poussé l'agent à remettre en question ses propres décisions correctes.
LangChain
La structure AgentExecutor de LangChain est intrinsèquement séquentielle, et la tâche 5 est là où cette contrainte était la plus visible. Avec 10 070 tokens de prompt et 86 secondes de médiane, c'était le framework le plus lent dans cette tâche malgré un nombre de tokens qui n'était pas le plus élevé.
Il effectue un seul appel d'outil à chaque étape, reçoit le résultat, puis passe à la suite, ce qui signifie que 4 outils indépendants ont nécessité 4 tours distincts de LLM avec 4 périodes d'attente distinctes. La médiane de 47 secondes d'AutoGen contre les 86 secondes de LangChain est une mesure directe du coût de l'exécution séquentielle par rapport à l'exécution parallèle.
Dans la tâche 5, le nombre d'outils de LangChain s'est établi à 9 ou 15. Ces deux groupes pointent vers deux stratégies typiques : dans certaines exécutions, il a sauté l'étape d'inspection et est passé directement à l'analyse et au résumé (9 outils), tandis que dans d'autres, il a inspecté chaque colonne d'abord avant de traiter (15 outils). L'identité d'exécuteur linéaire de LangChain est devenue claire ici : il n'a montré ni l'efficacité parallèle d'AutoGen ni le chaos monologique de CrewAI.
Gestion des données non structurées et architecture des frameworks
Les résultats de cette tâche révèlent que l'efficacité avec laquelle un framework peut gérer les données non structurées (JSON, LongText) est directement liée à son mécanisme de boucle interne :
Les frameworks capables d'appels d'outils parallèles (AutoGen) peuvent traiter des colonnes de données indépendantes en une seule étape. Dans les scénarios réels impliquant de grands objets JSON et de nombreuses colonnes de texte, cette différence se traduit par un avantage considérable en termes de coût et de vitesse.
Les frameworks avec des boucles pilotées par l'état (LangGraph) excellent dans la cohérence des données, mais comportent le risque de réévaluer les étapes terminées accumulées dans l'historique.
Les frameworks basés sur les monologues (CrewAI) sont profondément capables de comprendre le type et la signification des données, mais cette profondeur se transforme parfois en questionnements excessifs et en boucles.
Les frameworks d'exécution linéaire (LangChain) traitent séparément les différentes branches des données non structurées, produisant un résultat intermédiaire entre les deux mondes.
GitHub : croissance des étoiles des frameworks agentiques
Comparer les frameworks d'IA agentiques
Les frameworks d'IA agentiques varient selon plusieurs dimensions clés, et comprendre ces différences est essentiel pour faire des comparaisons pertinentes.
Orchestration multi-agents
L'orchestration multi-agents coordonne plusieurs agents d'IA spécialisés pour s'attaquer à des workflows complexes qui dépassent les capacités d'un seul agent. Plutôt que de construire un agent monolithique, l'orchestration répartit le travail entre des agents ayant des rôles, des outils et des expertises distincts. Chaque framework propose des approches différentes de la coordination des agents.
LangGraph
LangGraph est un framework relativement bien connu et se distingue comme une option clé pour les développeurs qui construisent des systèmes d'agents.
Coordination multi-agents explicite : Vous pouvez modéliser plusieurs agents comme des nœuds individuels ou des groupes, chacun avec sa propre logique, mémoire et rôle dans le système.
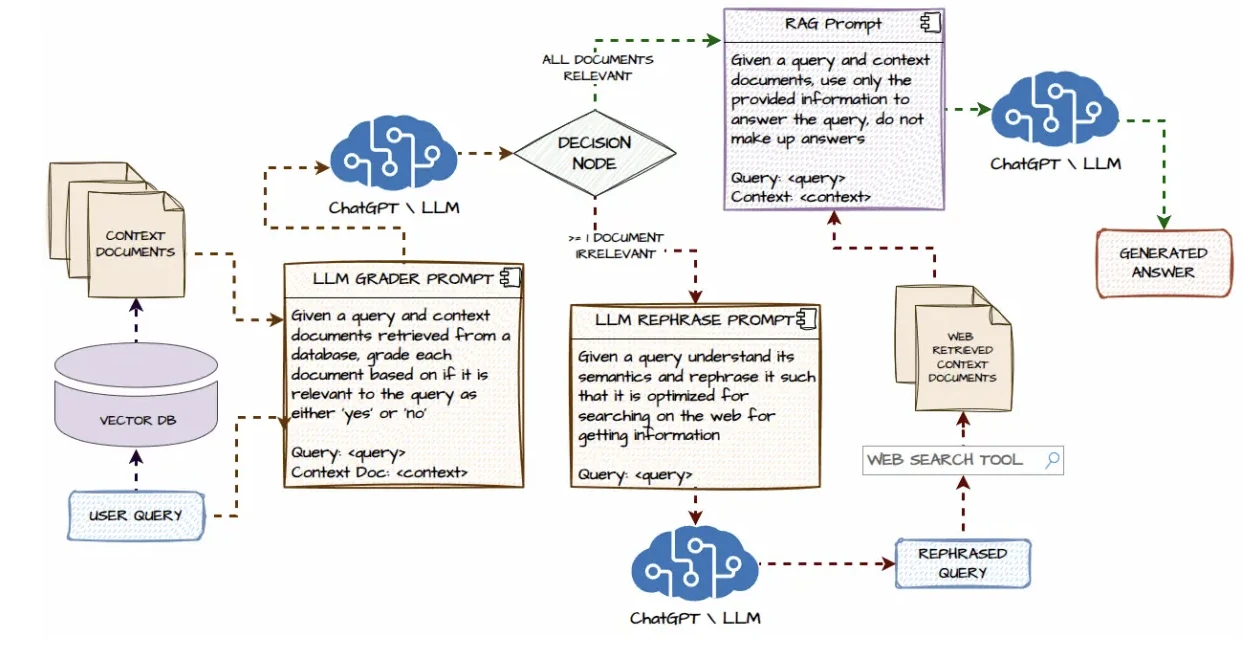
Il crée des workflows d'IA à travers les APIs et les outils. Ainsi, il est bien adapté au RAG et aux pipelines personnalisés.
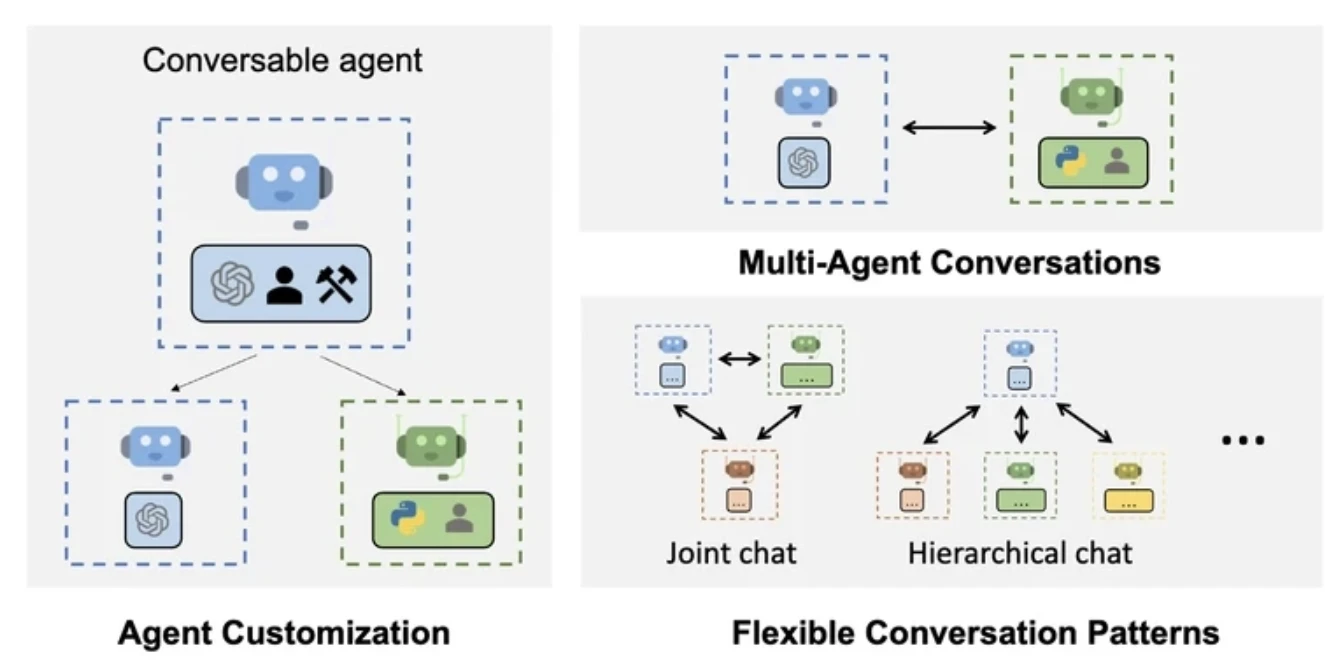
AutoGen
AutoGen permet à plusieurs agents de communiquer en s'échangeant des messages en boucle. Chaque agent peut répondre, réfléchir ou appeler des outils en fonction de sa logique interne.
Il offre une collaboration asynchrone entre agents, ce qui le rend particulièrement utile pour les scénarios de recherche et de prototypage où le comportement des agents nécessite des expérimentations ou des perfectionnements itératifs.
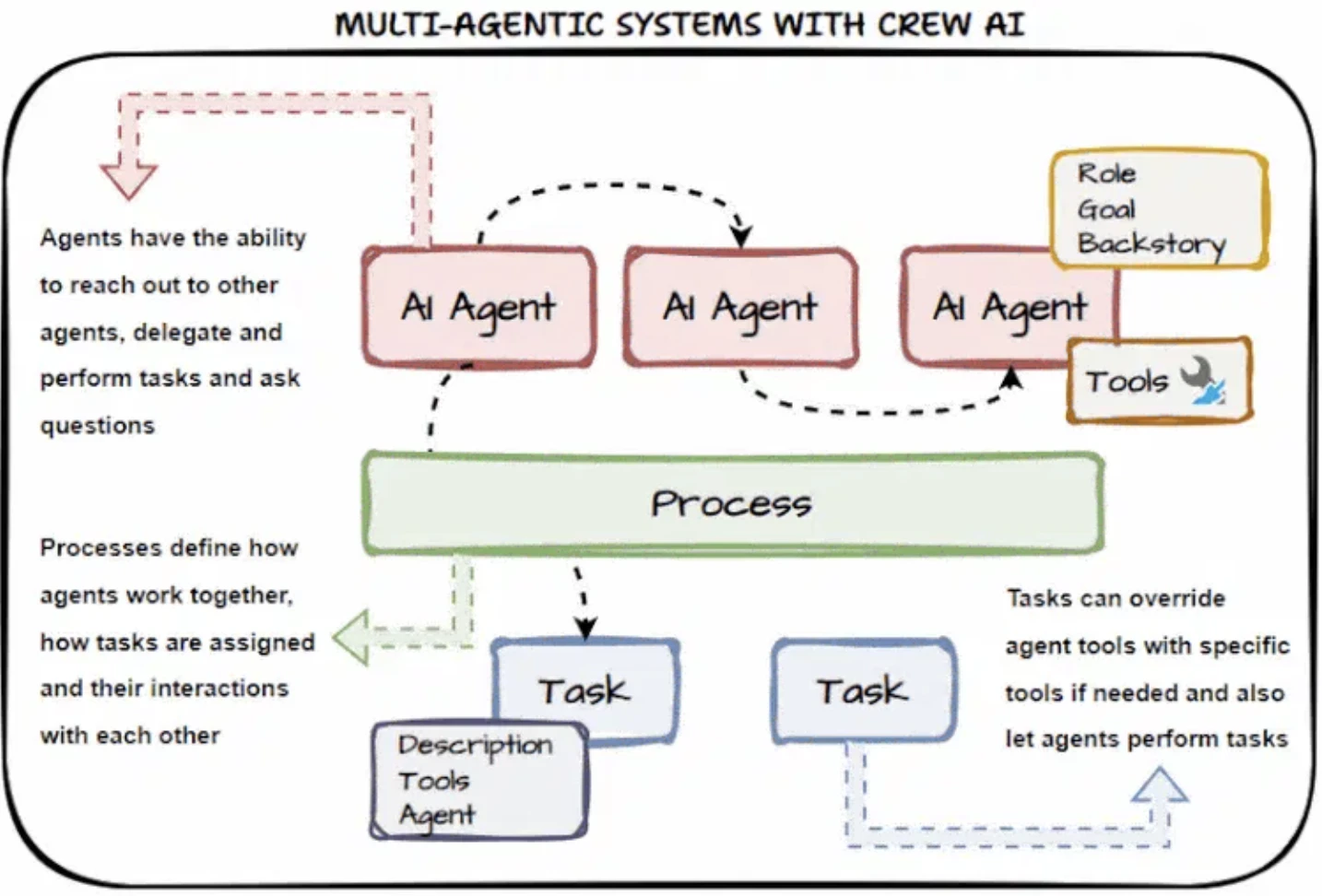
CrewAI
CrewAI gère la plupart de la logique de bas niveau pour vous et fournit une orchestration multi-agents :
- S'intègre avec des outils de surveillance pour le traçage et le débogage
- Contrôle d'exécution intégré via des Flows avec logique conditionnelle, boucles et gestion d'état
- Prend en charge la coordination multi-agents hiérarchique (manager-worker) et structurée
OpenAI Swarm
Swarm est un framework multi-agents expérimental et léger pour le prototypage. Les agents travaillent séquentiellement par transferts, en transférant les tâches tout en maintenant un contexte partagé. Il utilise des routines en langage naturel et des outils Python pour des workflows flexibles.
LangChain
LangChain est un framework pour construire des applications LLM à agent unique avec des outils de RAG. Il fournit des composants modulaires comprenant des chaînes, des outils, de la mémoire et de la récupération pour les workflows de traitement de documents.
LangChain fonctionne principalement selon des modèles d'exécution à agent unique où un agent gère le workflow.
Définition des agents et des fonctions
LangGraph
LangGraph adopte une approche basée sur les graphes pour la conception d'agents, où chaque agent est représenté comme un nœud qui maintient son propre état. Ces nœuds sont connectés via un graphe orienté, permettant une logique conditionnelle, une coordination multi-équipes et un contrôle hiérarchique. Cela vous permet de construire et de visualiser des graphes multi-agents avec des nœuds superviseurs pour une orchestration évolutive.
LangGraph utilise des fonctions annotées et structurées qui attachent des outils aux agents. Vous pouvez construire des nœuds, les connecter à divers superviseurs et visualiser comment les différentes équipes interagissent. Pensez-y comme si vous donniez à chaque membre de l'équipe une description de poste détaillée. Cela facilite la construction et le test d'agents qui travaillent ensemble.
AutoGen
AutoGen définit les agents comme des unités adaptatives capables de routage flexible et de communication asynchrone. Les agents interagissent entre eux (et éventuellement avec les humains) en échangeant des messages, permettant une résolution collaborative des problèmes. Comme LangGraph, il utilise des fonctions annotées et structurées.
CrewAI
CrewAI adopte une approche de conception basée sur les rôles. Chaque agent se voit attribuer un rôle (par exemple, Chercheur, Développeur) et un ensemble de compétences, de fonctions ou d'outils auxquels il peut accéder. La définition des fonctions se fait par le biais d'annotations structurées.
OpenAI Swarm
OpenAI Swarm utilise un modèle basé sur les routines où les agents sont définis par le biais de prompts et de docstrings de fonctions. Il ne dispose pas d'orchestration formelle ni de modèles d'état, s'appuyant plutôt sur des workflows structurés manuellement. Le comportement des fonctions est inféré par le LLM via les docstrings (Swarm identifie ce que fait une fonction en lisant sa description), ce qui rend cette configuration flexible mais moins précise.
LangChain
LangChain utilise une architecture basée sur des chaînes où un seul agent orchestrateur gère les appels aux modèles de langage et aux divers outils. Il définit les fonctions via des interfaces explicites comme les toolkits et les modèles de prompts.
Bien que principalement axé sur les workflows centralisés, LangChain prend en charge des extensions pour les configurations multi-agents, mais ne dispose pas de communication intégrée d'agent à agent.
Mémoire
Capacités de mémoire :
- Avec état : Indique si le framework prend en charge la mémoire persistante entre les exécutions.
- Contextuel : Indique s'il prend en charge la mémoire à court terme via l'historique des messages ou le passage de contexte.
Les fonctionnalités de mémoire sont un élément clé de la construction de systèmes agentiques pour se souvenir du contexte et s'adapter au fil du temps :
- Mémoire à court terme : Garde une trace des interactions récentes, permettant aux agents de gérer des conversations à plusieurs tours ou des workflows étape par étape.
- Mémoire à long terme : Stocke des informations persistantes entre les sessions, telles que les préférences de l'utilisateur ou l'historique des tâches.
- Mémoire d'entité : Suit et met à jour les connaissances sur des objets, des personnes ou des concepts spécifiques mentionnés au cours des interactions (par exemple, se souvenir d'un nom d'entreprise ou d'un ID de projet mentionné précédemment).
LangGraph
LangGraph utilise deux types de mémoire : la mémoire intra-thread, qui stocke les informations au cours d'une seule tâche ou conversation, et la mémoire inter-thread, qui enregistre les données entre les sessions. Les développeurs peuvent utiliser MemorySaver pour enregistrer le déroulement d'une tâche et le lier à un thread_id spécifique. Pour le stockage à long terme, LangGraph prend en charge des outils comme InMemoryStore ou d'autres bases de données. Cela offre un contrôle flexible sur la façon dont la mémoire est délimitée et conservée entre les exécutions.
AutoGen
AutoGen utilise un modèle de mémoire contextuelle. Chaque agent conserve un contexte à court terme via un objet context_variables, qui stocke l'historique des interactions. Il ne dispose pas de mémoire persistante intégrée.
CrewAI
CrewAI fournit une mémoire en couches prête à l'emploi. Il stocke la mémoire à court terme dans un magasin vectoriel ChromaDB, les résultats récents des tâches dans SQLite et la mémoire à long terme dans une table SQLite distincte (basée sur les descriptions de tâches). De plus, il prend en charge la mémoire d'entité en utilisant des embeddings vectoriels. Cette configuration de mémoire est automatiquement mise en place lorsque memory=True est activé,
OpenAI Swarm
Swarm est sans état et ne gère pas la mémoire de manière native. Les développeurs peuvent transmettre manuellement la mémoire à court terme via context_variables, et éventuellement intégrer des outils externes ou des couches de mémoire tierces (par exemple, mem0) pour stocker un contexte à plus long terme.
LangChain
LangChain prend en charge à la fois la mémoire à court terme et la mémoire à long terme grâce à des composants flexibles. La mémoire à court terme est généralement gérée via des tampons en mémoire qui suivent l'historique de la conversation au cours d'une session. Pour la mémoire à long terme, LangChain s'intègre à des magasins vectoriels externes ou à des bases de données pour conserver les embeddings et les données de récupération.
Les développeurs peuvent personnaliser les portées et les stratégies de mémoire en utilisant des classes de mémoire intégrées, permettant une gestion efficace de la mémoire contextuelle et de la mémoire spécifique aux entités à travers les interactions.
Human-in-the-loop
LangGraph
LangGraph prend en charge des points d'arrêt personnalisés (interrupt_before) pour mettre le graphe en pause et attendre une saisie utilisateur en cours d'exécution.
AutoGen
AutoGen prend en charge de manière native les agents humains via UserProxyAgent, permettant aux humains de réviser, d'approuver ou de modifier les étapes pendant la collaboration des agents.
CrewAI :
CrewAI permet un retour après chaque tâche en définissant human_input=True ; l'agent fait une pause pour recueillir une saisie en langage naturel de la part de l'utilisateur.
OpenAI Swarm
OpenAI Swarm n'offre pas de HITL intégré.
LangChain
LangChain permet d'insérer des points d'arrêt personnalisés dans les chaînes ou les agents pour mettre en pause l'exécution et demander une saisie humaine. Cela prend en charge la révision, le retour ou l'intervention manuelle à des points définis du workflow.
Intégration du Model Context Protocol (MCP) dans les frameworks d'IA agentique
Les agents d'IA doivent interagir avec des outils externes tels que des bases de données, des APIs, des systèmes de fichiers et des applications métier. Sans norme, chaque framework devait créer des intégrations personnalisées pour chaque outil, créant un écosystème fragmenté. Le MCP résout ce problème en fournissant un protocole universel qui permet à n'importe quel agent de se connecter à n'importe quel outil via une interface unique.
Comment chaque framework s'intègre avec le MCP
LangGraph
LangGraph se connecte aux serveurs MCP via un adaptateur qui découvre automatiquement les outils disponibles et les convertit dans un format compatible avec LangChain. Les agents peuvent ensuite utiliser ces outils de manière transparente parallèlement à leurs capacités natives.
AutoGen
AutoGen fournit une intégration MCP intégrée via son module d'extension. Les développeurs peuvent se connecter aux serveurs MCP et rendre tous leurs outils disponibles aux agents AutoGen avec seulement quelques lignes de code.
CrewAI
Les agents CrewAI peuvent référencer directement les serveurs MCP dans leur configuration en utilisant des URLs simples ou des paramètres structurés. Le framework gère automatiquement le cycle de vie de la connexion et la gestion des erreurs.
OpenAI Swarm
Swarm bénéficie du support MCP natif d'OpenAI dans tout son écosystème. Étant donné qu'OpenAI a intégré le MCP dans ChatGPT et son SDK Agents, Swarm peut tirer parti de cette infrastructure directement.
LangChain
LangChain offre des capacités d'appel d'outils MCP où des fonctions Python servent de ponts vers les serveurs MCP. Cela permet de récupérer des outils de diverses sources et de les intégrer dans des chaînes, des agents et d'autres composants LangChain sans wrappers personnalisés.
Que font réellement les frameworks d'IA agentiques ?
Les frameworks d'IA agentiques aident à l'ingénierie des prompts et à la gestion de la circulation des données vers et depuis les LLM. À un niveau de base, ils aident à structurer les prompts pour que le LLM réponde dans un format prévisible et à acheminer les réponses vers le bon outil, la bonne API ou le bon document.
Si vous construisiez à partir de zéro, vous définiriez manuellement le prompt, extrairiez l'outil que le LLM souhaite utiliser et déclencheriez l'appel d'API correspondant. Les frameworks rationalisent cela en :
- Orchestration des prompts : Construction, gestion et acheminement de prompts complexes vers les LLM
- Intégration d'outils : Permettre aux agents d'appeler des APIs externes, des bases de données, des fonctions de code, etc.
- Mémoire : Maintenir l'état entre les tours ou les sessions (court et long terme)
- Intégration RAG : Permettre la récupération de connaissances à partir de sources externes
- Coordination multi-agents : Structurer la façon dont les agents collaborent ou délèguent des tâches
Frameworks d'IA agentiques : cas d'utilisation réels
LangGraph – Planificateur de voyage multi-agents
Un projet de production construit avec LangGraph présente un assistant de voyage multi-agents avec état qui extrait des données de vol et d'hôtel (en utilisant les APIs Google Flights & Hotels) et génère des recommandations de voyage.4
CrewAI – Créateur de contenu agentique
Le dépôt d'exemples officiel de CrewAI comprend des flux tels que la planification de voyage, la stratégie marketing, l'analyse boursière et les assistants de recrutement, où des agents spécifiques à des rôles (par exemple, « Chercheur », « Rédacteur ») collaborent sur des tâches.5
CrewAI transforme un brief de contenu de haut niveau en un article complet en utilisant Groq.
Fonctionnalités principales des frameworks d'IA agentiques
Support des modèles :
- La plupart sont agnostiques au modèle, prenant en charge plusieurs fournisseurs de LLM (par exemple, OpenAI, Anthropic, modèles open source).
- Cependant, les structures de prompts système varient selon le framework et peuvent être plus performantes avec certains modèles qu'avec d'autres.
- L'accès et la personnalisation des prompts système sont souvent essentiels pour des résultats optimaux.
Outillage :
- Tous les frameworks prennent en charge l'utilisation d'outils, un élément central de l'activation des actions des agents.
- Offrent des abstractions simples pour définir des outils personnalisés.
- La plupart prennent en charge le Model-Context-Protocol (MCP), soit nativement, soit via des extensions de la communauté.
Mémoire / État :
- Utilisent le suivi d'état pour maintenir une mémoire à court terme entre les étapes ou les appels de LLM.
- Certains aident les agents à conserver les interactions ou le contexte antérieurs au sein d'une session.
RAG (Retrieval-Augmented Generation) :
- La plupart incluent des options de configuration faciles pour le RAG, en intégrant des bases de données vectorielles ou des magasins de documents.
- Cela permet aux agents de référencer des connaissances externes pendant l'exécution.
Autres fonctionnalités courantes
- Prise en charge de l'exécution asynchrone, permettant des appels d'agents ou d'outils simultanés.
- Gestion intégrée des sorties structurées (par exemple, JSON).
- Prise en charge des sorties en streaming où le modèle génère les résultats de manière incrémentielle.
- Fonctionnalités d'observabilité de base pour la surveillance et le débogage des exécutions d'agents.
Méthodologie du benchmark
1. Structure des tâches
Tâche 1 : Mesure si un seul appel d'outil peut être effectué avec le bon paramètre. Le surcoût de l'infrastructure de base du framework est le plus clairement révélé dans ce scénario simple.
Tâche 2 : Nécessite de conserver les résultats de deux groupes de filtres distincts en mémoire et de les combiner en une seule sortie. La gestion de l'état et la coordination multi-segments sont testées.
Tâche 3 : Mesure si les conditions numériques en langage naturel sont traduites en paramètres d'outil sans distorsion. Le véritable test est de savoir si les mécanismes de nouvelle tentative et de nouveau prompt du framework peuvent préserver ces paramètres.
Tâche 4 : Un outil génère des erreurs Réseau, Délai d'attente et Limite de débit successivement. On mesure si le framework change de stratégie face à ces erreurs.
Tâche 5 : L'agent doit d'abord découvrir les colonnes JSON et LongText, puis appeler les bons outils avec les bons paramètres de portée. On observe si le framework exécute les outils indépendants en parallèle ou séquentiellement.
À quoi ressemble réellement une tâche
Pour rendre la configuration concrète, voici la tâche 5, la tâche la plus complexe du benchmark des frameworks d'IA agentiques. Chaque framework a reçu le même prompt et le même ensemble d'outils ; seul le framework enveloppant le LLM a changé.
Prompt donné à l'agent :
Analysez les clients désabonnés (Churn='Yes') qui paient plus de 100 en MonthlyCharges.
- Filtrez le jeu de données sur Churn='Yes'.
- Inspectez les colonnes « Metadata » et « SupportNotes » pour découvrir leurs types de données.
- Extrayez la distribution de « device_type » de la colonne JSON « Metadata ».
- Comptez les mots-clés de réclamation dans la colonne de texte libre « SupportNotes ».
Renvoyez le résultat au format JSON uniquement.
Sortie JSON requise :
Pourquoi cette tâche discrimine entre les frameworks : l'agent doit planifier une chaîne de quatre appels d'outils, conserver le segment filtré en état à chaque appel et reconnaître qu'une colonne est JSON tandis que l'autre est du texte libre. Un framework qui exécute les colonnes indépendantes en parallèle (AutoGen) termine beaucoup plus vite qu'un autre qui les exécute séquentiellement (LangChain), et un framework qui réévalue les étapes terminées (LangGraph, CrewAI) boucle inutilement. Le schéma JSON strict nous permet de noter l'exactitude automatiquement.
2. Configuration
Tous les frameworks ont utilisé le même modèle LLM (openai/gpt-5.2) et la même valeur de température (0.1). Pour toutes les tâches, chaque agent a reçu les mêmes outils et les mêmes prompts. Chaque framework a été configuré dans sa structure native : LangChain avec AgentExecutor, LangGraph avec StateGraph, AutoGen avec AssistantAgent + UserProxyAgent et CrewAI avec Agent + Task + Crew.
Le jeu de données IBM Telco Customer Churn (7 032 clients) a été utilisé. L'état des outils a été réinitialisé avant chaque exécution. 100 exécutions indépendantes ont été effectuées pour chaque combinaison framework-tâche.
Les limites maximales d'itérations ont été définies en fonction de la complexité de la tâche : 10 pour les tâches 1, 2 et 3 ; 20 pour la tâche 4 en raison de la boucle d'outils instable ; et 20 pour la tâche 5 en raison de la chaîne de découverte en 4 étapes.
Citez ce benchmark
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Şipi, Nazlı},
title = {{Top 5 des frameworks d'IA agentiques open source}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/agentic-frameworks}},
note = {AIMultiple. Consulté le 6 Juillet 2026}
}

Commentaires 1
Partagez vos idées
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.
Thank you for this informative and detailed article! It helped me get a reading on these frameworks.