RAG Frameworks: LangChain vs LangGraph vs LlamaIndex
Nous avons benchmarké 5 frameworks RAG : LangChain, LangGraph, LlamaIndex, Haystack et DSPy, en construisant le même workflow RAG agentique avec des composants standardisés : modèles identiques (GPT-4.1-mini), embeddings (BGE-small), retriever (Qdrant) et outils (recherche web Tavily). Cela isole la véritable surcharge et l'efficacité en tokens de chaque framework.
Résultats du benchmark des frameworks RAG
Le benchmark comprenait 100 requêtes, chaque framework exécutant l'ensemble complet 100 fois pour fournir des moyennes stables.
- Tokens moyens : Total des tokens consommés lors de tous les appels LLM (routeur, évaluateur de documents, évaluateur de réponse et générateur), incluant les prompts (avec le contexte récupéré) et les complétions. Moins élevé = coût API réduit.
- Surcharge du framework : Temps d'orchestration pur (ms), le traitement interne du framework (logique de routage, gestion d'état, etc.), excluant les appels LLM API et outils. Moins élevé = framework plus léger.
Toutes les implémentations ont atteint une précision de 100% sur l'ensemble de test. Elles ont utilisé les mêmes modèles, températures, fournisseur de récupération, outil de recherche web et une limite partagée de tokens de contexte.
Principales conclusions
- Nous concentrons sur le contrôle de ce qui est contrôlable : Même famille de modèles et températures, max_tokens au niveau des nœuds, retriever (Qdrant + BGE-small, k=5, normalisation activée), fournisseur web (Tavily uniquement), politique de routage (heuristique + modèle), retour anticipé de la calculatrice, limite partagée de tokens de contexte, grille d'évaluation identique, instrumentation unifiée. Cela réduit considérablement les principaux facteurs de confusion dans nos mesures.
- La surcharge du framework est mesurable mais faible : Nous avons observé environ 3–14 ms par requête provenant de la logique d'orchestration. Ces différences sont réelles, mais ne constituent pas la principale source des écarts de latence >1 s ; la majeure partie du temps est consacrée aux E/S avec les modèles/outils externes.
- La performance suit les tokens (dans ces contraintes) : DSPy affiche la surcharge de framework la plus faible (~3,53 ms). Haystack (~5,9 ms) et LlamaIndex (~6 ms) suivent, tandis que LangChain (~10 ms) et LangGraph (~14 ms) sont plus élevés. La consommation de tokens est la plus faible pour Haystack (~1,57k), puis LlamaIndex (~1,60k) ; DSPy et LangGraph sont à ~2,03k, et LangChain à ~2,40k.
- Le routage/chemin d'outil importe : De légers changements dans le routage initial (retriever vs web vs calculatrice) et le comportement de repli affectent à la fois les tokens et le temps, même lorsque les prompts et les budgets sont alignés.
Pourquoi les différences persistent-elles ? L'« ADN du framework »
Malgré la standardisation, de petites variances dans le nombre de tokens et la latence subsistent. Celles-ci sont attribuables aux comportements inhérents de bas niveau de chaque framework, leur « ADN ».
- Sérialisation des prompts et messages : Chaque framework enveloppe le même contenu logique avec un formatage légèrement différent avant de l'envoyer au LLM, créant des écarts de tokens faibles mais constants.
- Assemblage du contexte : L'ordonnancement précis et l'inclusion des métadonnées dans le contexte concaténé peuvent différer légèrement selon le framework, affectant le nombre final de tokens.
- Départage de routage : Dans les cas limites, des différences subtiles dans la façon dont un framework analyse la sortie JSON du routeur peuvent conduire à un choix initial d'outil différent.
Dans cette configuration, l'empreinte en tokens semble être le facteur principal, plus que le temps d'exécution du framework.
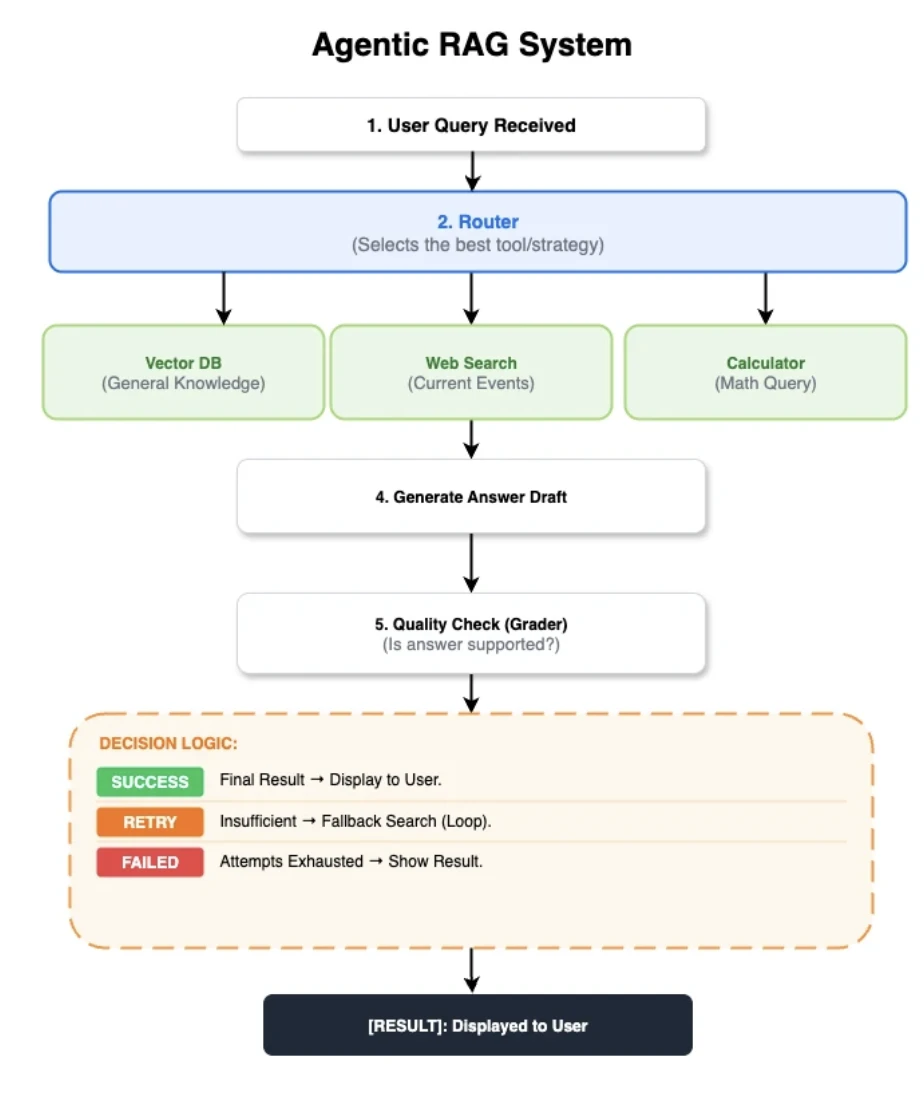
L'architecture RAG agentique partagée
Pour obtenir une comparaison équitable, les cinq implémentations ont été construites sur le même flux de contrôle :
- Routeur : Un nœud hybride modèle-et-heuristique qui choisit entre retriever, web_search ou calculator.
- Récupérer les documents : Récupère les 5 meilleurs documents depuis Qdrant en utilisant les embeddings normalisés BGE-small.
- Évaluer les documents : Un juge LLM évalue la pertinence des documents. S'ils ne sont pas pertinents, cela déclenche un repli vers la recherche web.
- Générer la réponse : Utilise un LLM avec température=0.0 et une limite partagée de tokens de contexte pour générer une réponse provisoire.
- Évaluer la réponse : Un second juge LLM évalue la réponse provisoire en termes de fondement, de contradictions (hallucinations) et d'exhaustivité.
- Solution de repli et retour anticipé : Une recherche web est déclenchée si la note de la réponse est insuffisante. Les résultats de la calculatrice, en revanche, sont renvoyés directement, en sautant les étapes de génération et d'évaluation.
Exemples de workflow
Scénario A — Résultat direct de la base de données :
Scénario B — Un événement récent déclenche l'outil web :
Scénario C — La calculatrice fournit un retour anticipé :
Scénario D — Base vectorielle insuffisante, bascule vers la recherche web :
Méthodologie des frameworks RAG
Les cinq implémentations ont atteint une précision de 100% sur notre ensemble de test de 100 requêtes, correspondant aux réponses de référence. C'était l'exigence fondamentale, garantissant que chaque framework pouvait exécuter avec succès le même workflow RAG agentique avant de mesurer les différences de performance.
1. Composants principaux et configuration
Les outils fondamentaux ont été standardisés pour éliminer les variables de performance à la source.
- LLM :
- Modèle : Tous les nœuds (routeur, générateur, évaluateur) ont utilisé le modèle openai/gpt-4.1-mini via l'API OpenRouter.
- Déterminisme : la température a été réglée sur 0.0 pour tous les appels LLM afin de garantir une cohérence maximale dans le routage, la génération et l'évaluation.
- Limites de tokens : Des limites strictes de max_tokens ont été appliquées : 256 pour le routeur et les évaluateurs, et 512 pour le générateur. Cela empêche les différences de latence causées par un framework générant des réponses excessivement longues.
- Modèle d'embedding et récupération :
- Modèle : Tous les frameworks ont utilisé BAAI/bge-small-en-v1.5 de HuggingFace.
- Normalisation : Une étape critique pour la performance, normalize_embeddings a été réglé sur True dans les cinq frameworks. (LangChain/LangGraph via encode_kwargs ; LlamaIndex via normalize=True ; Haystack via normalize_embeddings ; retriever DSPy normalisé.)
- Récupération : Le store vectoriel Qdrant a été interrogé avec k=5 (top 5 documents) dans toutes les implémentations.
- Outillage :
- Recherche web : Le benchmark a été restreint à Tavily uniquement (max_results=3).
- Calculatrice : Les cinq implémentations ont utilisé la bibliothèque sympy pour l'analyse et l'évaluation d'expressions mathématiques, garantissant des capacités identiques.
2. Flux de contrôle et politique RAG
Le processus de « prise de décision » de l'agent a été explicitement reproduit dans tous les frameworks.
- Logique de routage : Une stratégie de routage hybride a été implémentée dans les cinq scripts pour équilibrer l'intelligence du modèle avec des règles déterministes :
- Une heuristique basée sur les regex (heuristic_route) vérifie d'abord les motifs évidents de calculatrice ou de recherche web (par exemple, symboles mathématiques, années comme « 2024 »).
- Un nœud routeur LLM (router_node) prend ensuite sa propre décision.
- La décision finale priorise l'heuristique pour la calculatrice, sinon elle s'en remet au choix du LLM.
- Budgétisation du contexte : C'est l'une des standardisations les plus critiques. Avant que le nœud generate_answer ne soit appelé, tout le contexte des documents récupérés et les résultats de recherche web sont concaténés puis tronqués à une limite partagée de 2000 tokens en utilisant un utilitaire commun truncate_to_token_budget. Cela garantit que le LLM générateur de chaque framework reçoit une entrée de taille exactement identique, empêchant qu'un framework ne soit avantagé ou désavantagé par la verbosité de son contexte récupéré.
- Politique d'évaluation des réponses :
- Grille d'évaluation indulgente : Le nœud grade_answer utilise un prompt indulgent identique dans tous les frameworks, demandant au juge LLM d'accepter les réponses sémantiquement similaires et raisonnablement complètes.
- Gestion des échecs : La logique de gestion d'un échec d'analyse JSON de l'évaluateur a été standardisée. Si la sortie de l'évaluateur n'est pas un JSON valide, le système revient par défaut à une évaluation permissive (grounded=True, complete=True), imitant un scénario réel où l'on ne voudrait pas qu'un parseur fragile fasse échouer une réponse par ailleurs bonne. DSPy renvoie des champs structurés (pas d'analyse JSON), ceci est consigné comme une différence de robustesse, pas un avantage de performance.
- Retour anticipé de la calculatrice : Comme on le voit dans le code, un appel réussi au nœud calculator_node définit directement la réponse finale et termine le workflow de manière anticipée. C'est une optimisation significative qui est appliquée de manière cohérente, empêchant le chemin de la calculatrice d'invoquer inutilement les LLM de génération et d'évaluation de réponse.
- Alignement DSPy. Pour maintenir l'équité avec les références non-CoT, DSPy utilise dspy.Predict (pas de CoT) pour le routeur et le générateur de réponses. Les signatures reflètent les contrats de nœuds des autres frameworks ; lorsque disponible, le nombre de tokens utilise la consommation rapportée par le modèle, sinon recours à tiktoken.
3. Instrumentation et métriques
Le processus de mesure était identique, utilisant des utilitaires et des principes partagés.
- Latence : time.perf_counter() de haute précision a été utilisé pour toutes les mesures de temps. La surcharge du framework est calculée de manière cohérente comme Latence totale – Latence des appels externes.
- Tokenisation : Tous les comptages de tokens pour les prompts et les complétions ont été calculés à l'aide de tiktoken, l'encodage cl100k_base, garantissant une source unique de vérité pour les métriques de tokens. La métrique « Tokens moyens » rapportée dans les résultats représente la somme cumulée de tous les tokens d'entrée (prompt) et de sortie (complétion) pour chaque appel LLM (par exemple, routeur, évaluateurs, générateur) au sein d'un seul workflow de requête.
- Gestion d'état : Bien que la syntaxe d'implémentation varie (TypedDict de LangGraph, classe de LlamaIndex, dictionnaire de LangChain), la structure de l'état est fonctionnellement identique. Chaque framework transmet le même ensemble de clés (question, documents, web_results, etc.) entre les nœuds, garantissant que la logique du flux de contrôle opère sur les mêmes informations.
En appliquant ces standardisations strictes au niveau du code, ce benchmark vise à dépasser les comparaisons superficielles et à offrir une analyse reproductible de la performance des frameworks dans le cadre d'une politique RAG fixe.
Interpréter les résultats :
- Vous pouvez conclure : Dans cette configuration spécifique et hautement contrôlée, la surcharge d'orchestration tend à être mineure ; les différences sont principalement dues au nombre de tokens et aux chemins d'outils.
- Dans cette configuration spécifique et hautement contrôlée, la surcharge du framework est négligeable.
- Les différences de performance étaient dues au nombre de tokens et aux variations de chemin d'outil.
- Vous ne pouvez pas généraliser : Les résultats sont spécifiques à cette architecture, ces modèles, ces prompts, ce retriever et ce fournisseur web ; les modifier peut changer les classements.
Expérience développeur : une comparaison qualitative
La performance n'est pas le seul facteur ; la sensation qu'a un framework lors du développement est tout aussi importante.
- LangGraph : Le graphe déclaratif
Utilise un paradigme orienté graphe. Vous définissez des nœuds et les reliez par des arêtes (y compris add_conditional_edges), de sorte que le flux de contrôle fait partie de l'architecture. L'état est typé via un TypedDict avec des mises à jour de style réducteur (Annotated[…, add]).- Choisissez LangGraph pour : les workflows complexes avec de multiples branches, reprises et cycles ; sa structure gagne en robustesse et en maintenabilité à mesure que les agents se complexifient.
- LlamaIndex : Orchestration impérative
Un script procédural où le flux de contrôle est du Python standard if/else ; le « graphe » réside dans votre code. L'état est une classe PipelineState dédiée, et le framework fournit des primitives de récupération propres (VectorStoreIndex → .as_retriever(k=5)).- Choisissez LlamaIndex pour : des workflows lisibles en fichier unique où vous appréciez une logique procédurale claire et un débogage facile.
- LangChain : Impératif avec composants déclaratifs
L'orchestration reste un script Python, mais les tâches individuelles sont de petites chaînes utilisant l'opérateur | (par exemple, prompt | llm | parser). L'état est un dict Python flexible et non typé.- Choisissez LangChain pour : Le prototypage rapide ou les équipes déjà dans l'écosystème LangChain qui préfèrent composer de petites unités déclaratives au sein d'un pilote impératif plus large.
- Haystack : Basé sur des composants, orchestration manuelle Composants typés et réutilisables (@component) avec E/S explicites, tandis que le flux de contrôle reste en Python standard (if/else). Facile à permuter les backends LLM/retriever/web, avec une instrumentation de première classe par étape (temps externe vs framework).
- Choisissez Haystack pour : des pipelines prêts pour la production, testables, avec des contrats clairs et un contrôle fin.
- DSPy : Programmes orientés signatures (moins de lignes de code)
Définissez une tâche via une signature (entrées/sorties + intention), puis implémentez-la avec des Modules qui encapsulent le prompting et les appels LLM. Centralise la gestion des prompts/de la consommation et supprime le code de liaison ; permuter les éléments internes (par exemple, Predict ↔ CoT) ne change pas le contrat.- Choisissez DSPy pour : un minimum de code boilerplate, des flux lisibles en fichier unique, un développement piloté par contrat (avec des optimiseurs optionnels).
Compromis entre performance optimale et comparabilité
- LangGraph pourrait exceller avec ses optimisations natives de graphe lorsqu'il est autorisé à utiliser l'exécution parallèle, la mise en cache d'état et son système d'arêtes conditionnelles pour une logique de branchement complexe.
- DSPy pourrait montrer des résultats radicalement différents en utilisant ses optimiseurs de signature (comme MIPROv2) et le prompting Chain-of-Thought, qui peuvent améliorer significativement la qualité des réponses.
- Haystack pourrait tirer parti de ses fonctionnalités de mise en cache prêtes pour la production, de traitement par lots et d'optimisations au niveau des composants que nous avons désactivées par souci d'équité.
- LlamaIndex pourrait bénéficier de ses stratégies d'indexation avancées, de ses moteurs de requête et de ses capacités multi-modales qui n'ont pas été exercées dans ce benchmark.
- LangChain pourrait briller avec son vaste écosystème d'outils et les optimisations LCEL (LangChain Expression Language) lorsqu'il n'est pas contraint à notre ensemble d'outils standardisé.
Le « meilleur » framework dépend de ce que vous optimisez : vitesse de développement, maintenabilité, performance ou motifs architecturaux spécifiques.
Conclusion
Dans un pipeline RAG agentique étroitement apparié, la surcharge d'orchestration est généralement une petite partie. Ce qui fait la différence, c'est le nombre de tokens que vous traitez et les outils que vous invoquez, tous deux façonnés par les prompts, la récupération et le routage. Le « bon » framework dépend en fin de compte du style d'orchestration préféré de votre équipe : graphes déclaratifs (LangGraph), scripts impératifs (LlamaIndex), chaînes composables (LangChain), composants modulaires (Haystack) ou programmes orientés signatures (DSPy) qui minimisent le code boilerplate.
Pour aller plus loin
Explorez d'autres benchmarks RAG, tels que :
- Modèles d'embedding : OpenAI vs Gemini vs Cohere
- Meilleure base de données vectorielle pour RAG : Qdrant vs Weaviate vs Pinecone
- Benchmark RAG agentique : routage multi-base de données et génération de requêtes
- RAG hybride : améliorer la précision du RAG
Citez ce benchmark
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sarı, Ekrem},
title = {{RAG Frameworks: LangChain vs LangGraph vs LlamaIndex}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/rag-frameworks}},
note = {AIMultiple. Consulté le 3 Juin 2026}
}
Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.