Top 10+ des frameworks & outils d'orchestration agentique
Nous avons testé quatre principaux frameworks agentiques en utilisant un workflow de planification de voyage identique à cinq agents et des paramètres LLM cohérents. Chaque framework a été exécuté 100 fois, et nous avons mesuré la latence de la pipeline, l'utilisation des tokens, les transitions d'agent à agent, et l'écart d'exécution agent-à-outil pour isoler le véritable surcoût d'orchestration.
Benchmark de l'orchestration agentique
Tous les frameworks ont réussi la tâche sur 100 exécutions chacun. Cependant, LangGraph s'est terminé 2.2x plus vite que CrewAI, tandis que LangChain et AutoGen ont montré des différences de 8-9x en efficacité de tokens. Cela reflète des décisions architecturales fondamentales sur la manière dont chaque framework orchestre les workflows multi-agents depuis la couche d'orchestration, comment les frameworks acheminent les messages, gèrent l'état et coordonnent les transferts d'agent.
Pour comprendre pourquoi, nous avons mesuré chaque phase du cycle de vie des agents.
Performance par agent
Agent parser : L'agent effectue une simple extraction de texte avec une complexité minimale. Tous les frameworks affichent une latence similaire.
Agent de recherche de vol : Nous constatons des différences significatives de latence et d'utilisation des tokens. Cet agent utilise l'outil API de vol, et nous observons un écart « agent-à-outil » notable, le temps entre le démarrage de l'agent et l'appel effectif de l'outil. Nous examinerons cet écart en détail plus tard dans notre analyse, où nous verrons que 5 secondes des 9 secondes de latence de CrewAI proviennent de cet écart.
Agent de météo : Nous retrouvons le même schéma de classement pour la latence et l'utilisation des tokens que celui observé pour l'agent de recherche de vol.
LangChain génère nettement plus de tokens et une latence plus élevée que les autres frameworks, à l'exception de CrewAI, dont le surcoût provient principalement de l'écart agent-à-outil. Cela découle de l'approche de gestion de la mémoire de LangChain, qui conserve les étapes intermédiaires et l'historique complet des conversations, créant ainsi un surcoût dans les workflows multi-agents.
LangGraph émerge comme le framework le plus rapide avec le moins de tokens. Son architecture basée sur les graphes ne transmet que les deltas d'état nécessaires entre les nœuds plutôt que des historiques de conversation complets, ce qui réduit au minimum l'utilisation des
tokens et la latence.
Agent d'activité : La plupart des frameworks démontrent des performances relativement proches. Sans appels d'outils, tous les frameworks convergent vers des plages similaires (6-8 s pour la latence, 650-744 tokens), ce qui suggère que la
variation provient principalement du temps de génération du LLM avec un surcoût d'orchestration minimal. Cependant, l'écart réel de performance apparaît chez l'agent planificateur de voyage.
Agent planificateur de voyage : L'agent reçoit et synthétise les sorties des quatre agents précédents (parser, recherche de vol, météo et recommandation d'activités) dans chaque framework. Cependant, la manière dont chaque framework
gère cette agrégation de contexte révèle des différences architecturales fondamentales.
CrewAI transmet la sortie complète et non modifiée de chaque tâche précédente directement dans le contexte du planificateur via son système de paramètres de contexte. Le LLM reçoit l'ensemble des tokens des sorties des agents précédents plus la
description de la tâche elle-même. Cette approche n'est pas une limitation mais une philosophie de conception fondamentale : CrewAI privilégie une synthèse complète et consciente du contexte où les agents ont une visibilité totale sur le travail précédent. Le
résultat est un itinéraire détaillé de 5 339 tokens qui intègre de manière approfondie toutes les informations disponibles.
LangChain, AutoGen et LangGraph gèrent le contexte différemment. Bien que ces trois frameworks transmettent les sorties des agents précédents au planificateur, ils mettent en œuvre diverses stratégies d'optimisation qui réduisent la charge contextuelle cumulée. La gestion de la mémoire de LangChain peut compresser ou résumer les sorties intermédiaires et le framework peut ne pas conserver toute la verbosité de la réponse de chaque agent lors de leur chaînage. Cela se traduit par une sortie de 3 187 tokens plus concise que CrewAI mais encore substantielle.
AutoGen montre un comportement similaire avec 3 316 tokens, ce qui suggère des approches de gestion du contexte comparables entre ces deux frameworks. La gestion d'état basée sur les graphes de LangGraph ne transmet que les deltas
d'état nécessaires entre les nœuds, ce qui produit la sortie la plus efficace de 2 589 tokens grâce à ses transitions d'état optimisées.
Écart agent-à-outil
L'écart agent-à-outil est le temps entre le moment où un agent reçoit sa tâche et le moment où il appelle effectivement l'outil.
L'écart de 5 secondes de CrewAI dans le Flight Finder représente un temps de délibération réel, tandis que les autres frameworks affichent des appels d'outils quasi instantanés.
L'architecture de CrewAI incarne une philosophie d'agent autonome. Lorsque l'agent Flight Finder reçoit sa tâche, il n'exécute pas immédiatement l'outil get_flights. Au lieu de cela, il suit un processus de raisonnement :
- Comprendre la tâche : L'agent analyse les informations dont il a besoin pour atteindre l'objectif
- Évaluer les options : Il examine les outils disponibles et détermine lequel est le plus approprié
- Planifier l'approche : L'agent décide des paramètres et de la stratégie d'exécution
- Passer à l'action : Enfin, il invoque l'outil avec les paramètres déterminés. Cet écart de 5 secondes, c'est littéralement CrewAI qui « réfléchit » avant d'agir, un choix de conception qui privilégie la qualité de la décision et le raisonnement autonome plutôt que la vitesse brute. L'agent ne reçoit pas l'ordre « utilise cet outil spécifique » ; il détermine de manière indépendante la meilleure ligne de conduite.
CrewAI ne propose pas d'option pour désactiver la délibération et passer à un appel d'outil direct.
En revanche, les frameworks LangGraph, LangChain et AutoGen utilisent des approches d'exécution directe des outils, atteignant des écarts d'exécution inférieurs à la milliseconde.
LangChain et LangGraph prennent en charge des agents de style ReAct, qui affichent le raisonnement selon le schéma « pensée → action → observation ». Cependant, la composante « Pensée » dans ReAct est purement une incitation textuelle. Par exemple, le LLM pourrait générer « Pensée : Je devrais… ». Cela introduit une génération supplémentaire de tokens, mais ne crée pas un cycle de délibération distinct comme l'écart de 5 secondes de CrewAI. Ces étapes de « pensée » sont générées dans le même appel LLM, dans le cadre d'un processus de génération unique.
Surcoût d'orchestration agent-à-agent
Nous avons mesuré la latence agent-à-agent en calculant le temps moyen entre la fin d'un agent et le début de l'agent suivant sur 100 exécutions, mais les différences étaient minimes, de l'ordre de la milliseconde. Cela révèle que l'architecture du framework compte surtout pour les schémas d'exécution des outils et la gestion du contexte, et non pour les transferts d'agent. Les différences de performance entre les frameworks proviennent de la délibération sur les outils et de la synthèse du contexte, pas du temps passé à basculer entre les agents.
Qu'est-ce que l'orchestration agentique ?
L'orchestration agentique coordonne des agents IA autonomes au sein d'un système unifié pour accomplir des tâches complexes et des tâches structurées sur plusieurs systèmes et domaines.
L'orchestration multiple permet à plusieurs agents de collaborer comme une équipe virtuelle où chaque agent joue un rôle spécifique : certains collectent des données, d'autres les analysent, et quelques-uns exécutent les décisions. La couche d'orchestration garantit que ces agents communiquent, planifient les tâches et travaillent ensemble.
Contrairement aux scripts d'automatisation statiques, l'orchestration agentique tire parti de l'IA générative et des modèles d'IA pour s'adapter au contexte, minimiser le besoin d'intervention humaine, et permettre une exécution transparente à travers divers systèmes.
Orchestration agentique vs orchestration LLM
Les termes sont parfois utilisés de manière interchangeable car les deux impliquent la coordination de systèmes IA, mais ils diffèrent sur le point focal :
- L'orchestration LLM est centrée sur le modèle, optimisant les interactions et les workflows entre plusieurs modèles de langage.
- L'orchestration agentique coordonne des agents autonomes pour résoudre des tâches en plusieurs étapes à travers les systèmes, avec une guidance humaine minimale.
Principes fondamentaux
- Autonomie : Les agents peuvent agir de manière indépendante dans leurs rôles définis, avec l'appel de fonctions vers des systèmes externes.
- Collaboration : Plusieurs agents IA communiquent pour résoudre des problèmes complexes, répartir des tâches multiples et réaliser une automatisation de bout en bout.
- Alignement : Les systèmes maintiennent des objectifs cohérents et garantissent la conformité aux exigences organisationnelles et réglementaires dans les secteurs hautement réglementés.
- Observabilité : Les journaux, les outils de surveillance et les évaluations permettent un suivi continu et une optimisation continue.
- Supervision humaine : Les approches avec un humain dans la boucle combinent l'automatisation et l'apport humain dans des contextes à haut risque ou ambigus.
Modèles d'orchestration
L'orchestration agentique peut être classée en plusieurs modèles selon la manière dont les agents sont coordonnés au sein d'un système. Ces modèles déterminent le flux des tâches, la communication entre agents et l'architecture globale du système.
Orchestration centralisée
Dans ce modèle, un seul agent gestionnaire ou routeur est responsable de l'attribution des tâches, du contrôle du flux de travail et de la garantie que les objectifs sont atteints. Le gestionnaire agit comme un concentrateur central, dirigeant les tâches vers des agents spécialisés selon des règles prédéfinies ou un plan dynamique.
Les schémas spécifiques de cette catégorie incluent :
- Orchestration séquentielle : Un pipeline linéaire où un gestionnaire dirige les tâches à travers une séquence fixe, étape par étape, d'agents. Idéal pour les processus avec des dépendances claires, comme les pipelines de traitement de données.
- Orchestration hiérarchique : Une structure évolutive à plusieurs niveaux où une relation gestionnaire-subordonné est utilisée pour traiter des tâches complexes dans plusieurs départements ou équipes.
Orchestration décentralisée
Ce modèle élimine le point de contrôle unique, permettant à plusieurs agents d'interagir directement et de réaliser une tâche complexe. Cette approche améliore la résilience et offre une plus grande flexibilité pour la résolution collaborative de problèmes.
Les schémas spécifiques de cette catégorie incluent :
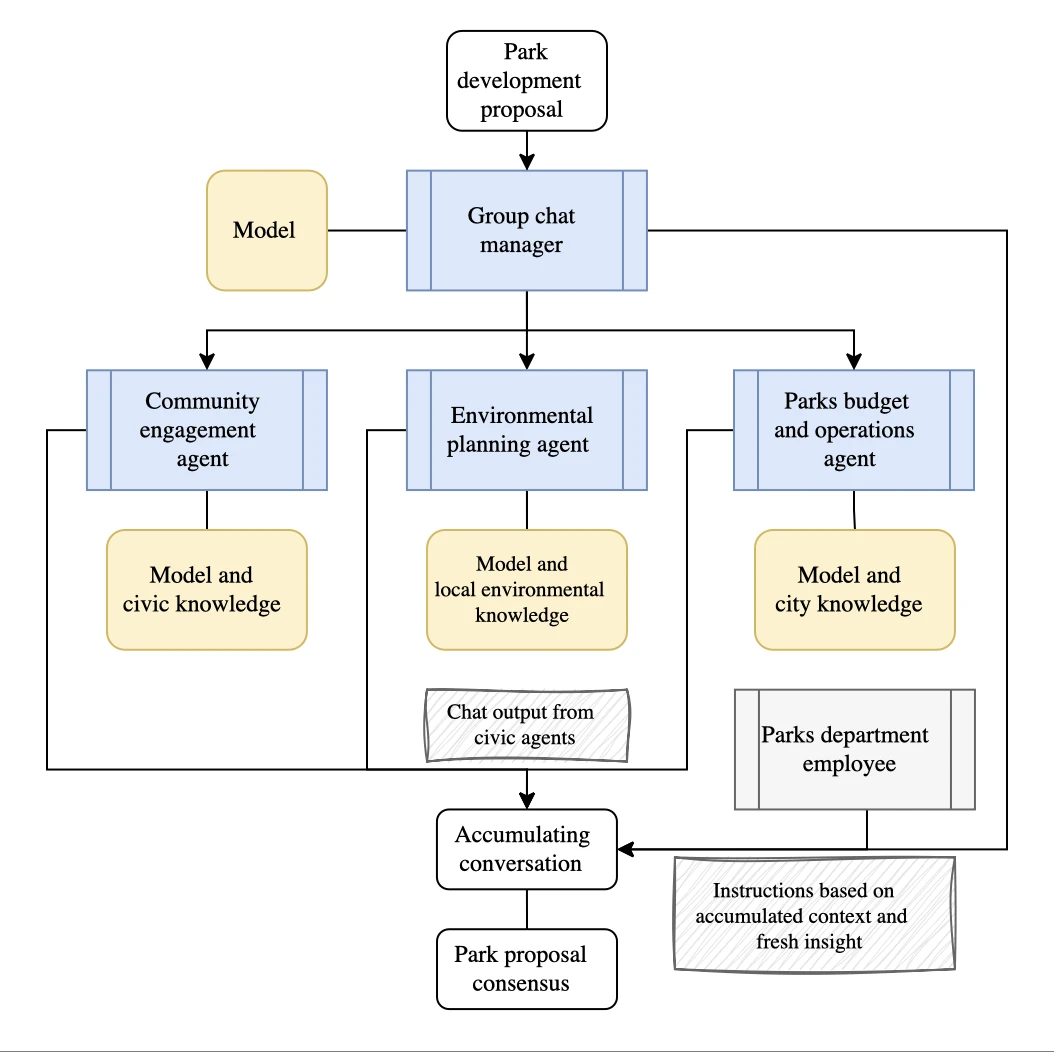
- Orchestration par chat de groupe : Les agents collaborent via un fil de conversation partagé, en s'appuyant sur les contributions des autres pour parvenir à une décision ou résoudre un problème. Un gestionnaire de chat peut animer la discussion, mais les agents communiquent directement pour atteindre un consensus.
- Orchestration par transfert : Les agents délèguent dynamiquement les tâches les uns aux autres sans avoir besoin d'un gestionnaire central. Chaque agent peut évaluer la tâche et décider de la traiter ou de la transférer à un autre agent disposant d'une expertise plus appropriée, à la manière d'un système de référencement.
Orchestration fédérée
Ce modèle est utile pour les environnements hautement réglementés ou distribués. Il permet la collaboration entre différents silos organisationnels ou systèmes tout en maintenant la gouvernance et la sécurité des données. Il combine souvent des éléments des approches centralisée et décentralisée pour gérer un réseau plus large d'agents et de systèmes.
Outils et frameworks
Plusieurs frameworks d'agents IA fournissent l'infrastructure pour les workflows agentiques et l'orchestration multi-agents. Parmi eux :
Voici une liste complète de ces outils par ordre alphabétique :
- LangGraph by LangChain : Fournit une conception modulaire et des workflows basés sur les graphes pour des flux de travail complexes et des tâches structurées.
- MetaGPT de FoundationAgents : Encode la collaboration basée sur les rôles (par ex., ingénieur logiciel, QA) pour coordonner plusieurs agents dans le développement logiciel.
- AutoGen de Microsoft : Se concentre sur la collaboration conversationnelle entre agents numériques, souvent configurée en boucles planificateur–exécuteur–critique.
- CrewAI : Organise des agents spécialisés en « crews » avec des objectifs spécifiques aux rôles, utile pour les processus métier et les opérations de routine.
- Agents SDK d'OpenAI : Permet une orchestration légère et des transferts d'agents avec appel de fonctions vers des outils externes.
- CAMEL-IA : Fournit des sociétés modulaires d'agents IA autonomes avec des coordinateurs pour des simulations à grande échelle et des processus complexes.
- Agent Development Kit de Google : Prend en charge l'orchestration multi-agents avec des capacités intégrées d'évaluation, de débogage et de déploiement.
- Langroid : Implémente un style acteur-modèle pour l'orchestration multi-agents, en mettant l'accent sur la modularité et la délégation.
- BeeAI : Met l'accent sur l'interopérabilité via le protocole de contexte de modèle et l'intégration d'agents tiers pour une intégration transparente.
- Azure IA Foundation Agent Service : Permet l'exploitation d'agents tout au long du développement, du déploiement et de la production en faisant abstraction de la complexité de l'infrastructure.
Protocoles de communication des agents
Les frameworks open source d'orchestration agentique comme LangGraph, CrewAI et AutoGen implémentent chacun leurs propres conventions pour la communication entre agents. Cela crée des défis d'interopérabilité lorsqu'on combine des agents de différents frameworks au sein de la même couche d'orchestration. Deux protocoles émergents visent à combler cette lacune.
Le protocole de contexte de modèle (MCP) d'Anthropic standardise la manière dont les agents se connectent aux outils externes et aux sources de données. Plutôt que chaque framework implémente sa propre couche d'intégration d'outils, MCP fournit une interface commune que les plateformes d'orchestration peuvent exploiter pour une communication agent-à-outil cohérente.
Le protocole Agent-to-Agent (A2A) de Google permet aux agents construits sur différents frameworks de découvrir mutuellement leurs capacités et d'échanger des messages. A2A est conçu pour compléter MCP : tandis que MCP gère les interactions agent-à-outil, A2A se concentre sur la collaboration agent-à-agent. Les agents annoncent leurs capacités via des « Cartes d'Agent », qui sont des documents de métadonnées JSON décrivant l'identité, les points de terminaison et les modalités prises en charge.
Pourquoi les protocoles sont importants pour l'orchestration :
- Interopérabilité : A2A a obtenu le soutien de plus de 150 organisations, dont LangChain, Salesforce et SAP, permettant à des agents de différents fournisseurs de travailler ensemble
- Découverte : Les agents peuvent dynamiquement trouver et comprendre les capacités des autres au moment de l'exécution grâce à des mécanismes standardisés
- Conception complémentaire : Un système orchestré pourrait utiliser A2A pour la communication inter-agents tandis que chaque agent utilise en interne MCP pour accéder à ses outils
- Complexité réduite : Les protocoles standardisés réduisent le besoin d'adaptateurs personnalisés lors du mélange d'agents de différents écosystèmes
Les frameworks qui adoptent A2A ou MCP peuvent plus facilement s'intégrer avec des agents et des outils externes, réduisant ainsi la dépendance vis-à-vis d'un fournisseur et simplifiant les déploiements multi-frameworks.
Applications de l'orchestration agentique
L'orchestration agentique est la capacité critique qui transforme des agents individuels en un système cohérent et orienté vers les objectifs. Voici des applications concrètes où les systèmes multi-agents se coordonnent pour apporter de la valeur métier.
Processus métier
L'orchestration agentique permet une automatisation de bout en bout à travers plusieurs départements et systèmes. Elle coordonne des agents spécialisés pour gérer des flux de travail complexes en plusieurs étapes sans transferts manuels.
- Ressources humaines : Orchestre une équipe d'agents pour gérer l'ensemble du cycle de vie des employés, de l'intégration et de la FAQ politique à la gestion des effectifs et au départ.
- Intégration client :
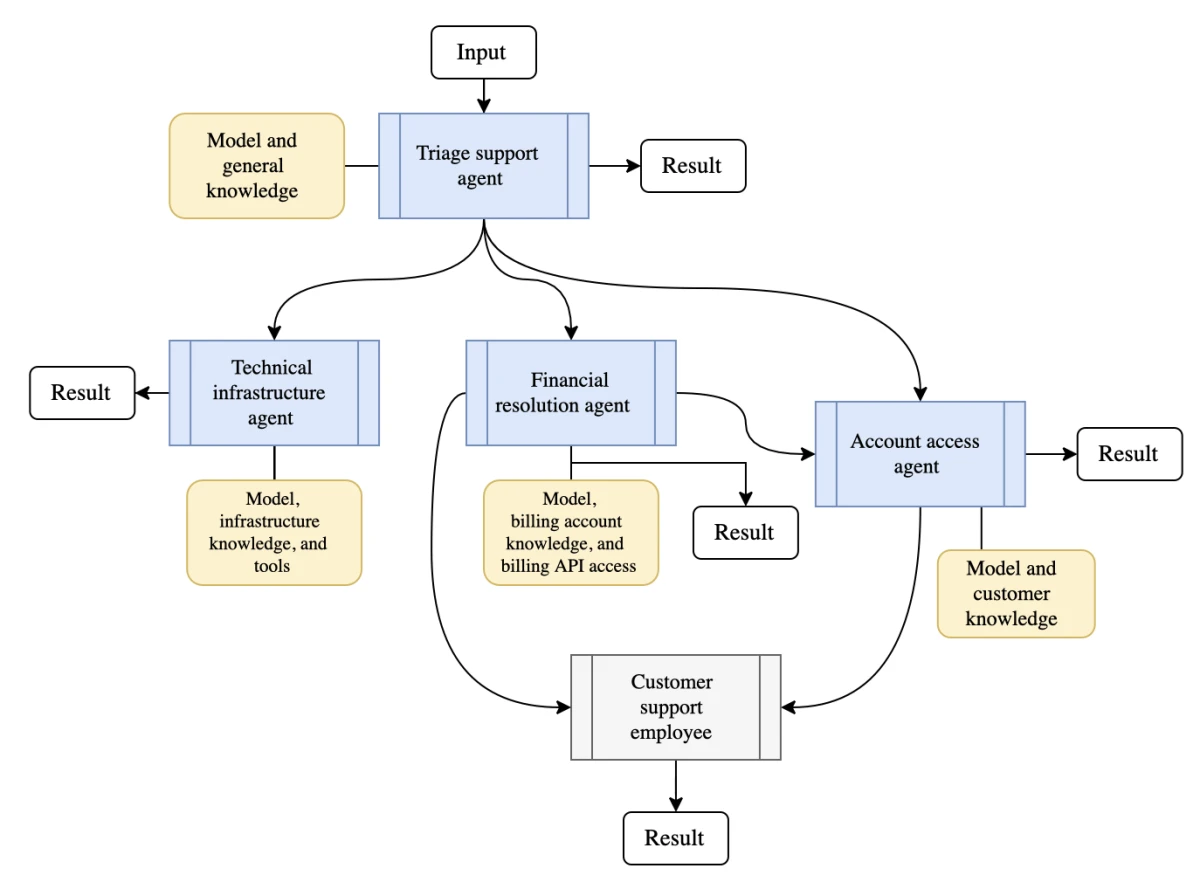
- Opérations client : Les systèmes orchestrés améliorent la qualité de service en gérant les interactions clients sur tous les canaux, avec un groupe d'agents traitant les requêtes initiales, fournissant des informations provenant de différentes bases de données et transférant les problèmes complexes à un humain dans la boucle pour vérification.
Chaîne d'approvisionnement
L'orchestration agentique améliore la gestion de la chaîne d'approvisionnement en coordonnant plusieurs agents spécialisés pour gérer et optimiser un réseau complexe de planification, d'approvisionnement, de logistique et de gestion des stocks.
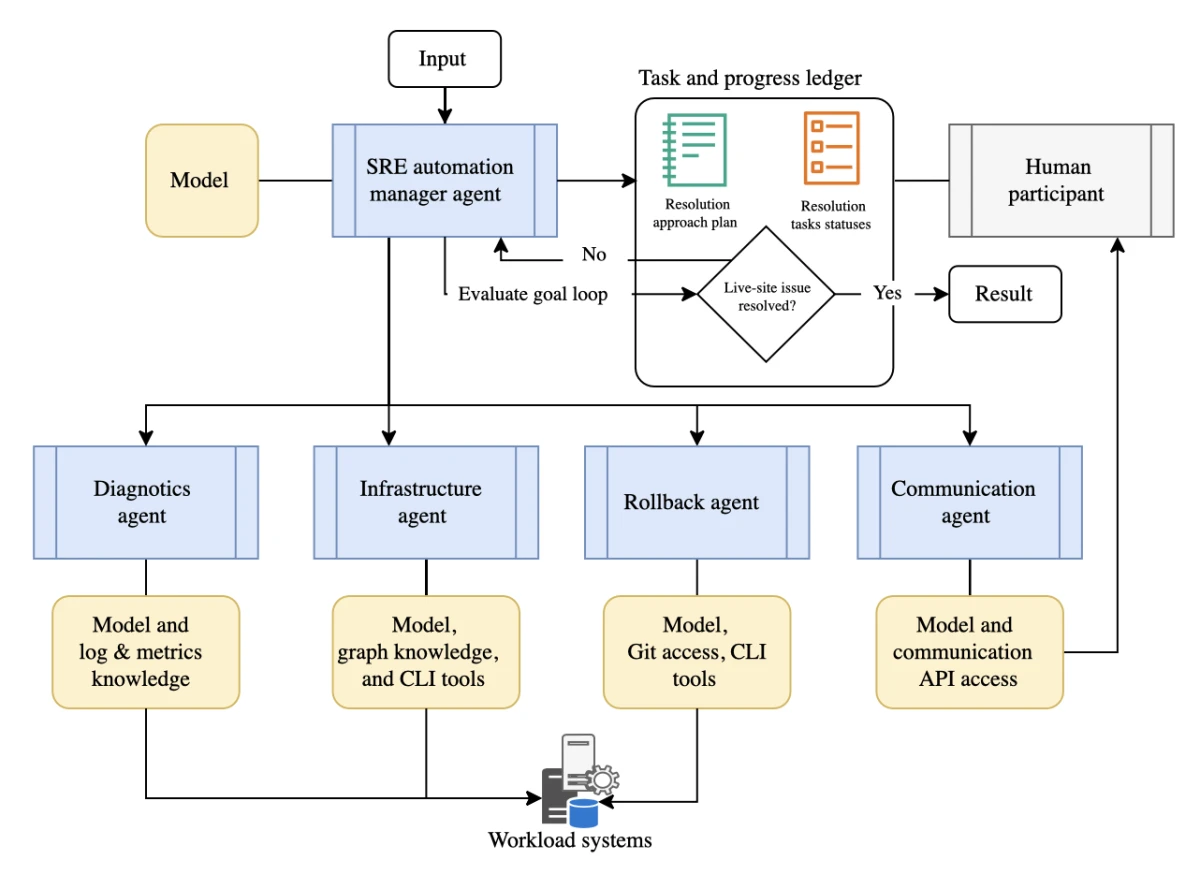
- Maintenance prédictive : Une plateforme d'orchestration coordonne des agents pour analyser les données d'équipement en temps réel, prédire les défaillances potentielles et déclencher automatiquement un agent de maintenance pour planifier une réparation ou commander de nouvelles pièces.
- Gestion des stocks : Les agents sont orchestrés pour suivre les niveaux de stock, réapprovisionner automatiquement lorsqu'un seuil est atteint et communiquer avec les agents logistiques pour gérer les perturbations en temps réel comme les retards d'expédition.
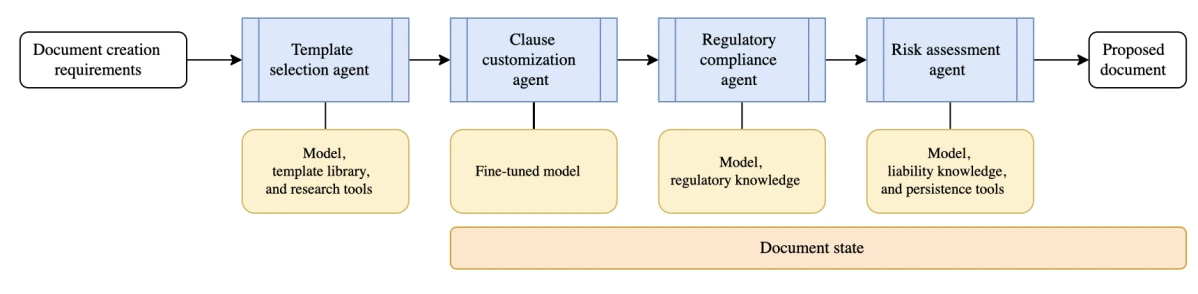
- Intégration des fournisseurs : Un système coordonné d'agents numériques gère l'ensemble du processus, de l'exécution des contrôles de conformité et de la génération des contrats à l'intégration de nouveaux fournisseurs dans les flux de travail existants de l'entreprise.
Systèmes d'entreprise
L'orchestration agentique fournit la logique de base pour les processus pilotés par l'IA qui nécessitent une collaboration transparente entre différentes plateformes d'entreprise, telles que l'ERP, le CRM et la RPA.
- Purchase-to-pay : Une série d'agents orchestrés gère le cycle complet d'approvisionnement, depuis un agent acheteur passant une commande jusqu'à un agent de comptabilité fournisseurs traitant la facture pour le paiement, réduisant les temps de cycle et améliorant la transparence.
- Order-to-cash : Un système multi-agents accélère tout le parcours depuis la réception de la commande jusqu'au paiement en coordonnant des agents qui gèrent le traitement des commandes, l'exécution et les comptes clients, améliorant ainsi le flux de trésorerie et la satisfaction client.
- Résolution des litiges : Un workflow orchestré automatise le suivi des réclamations et des rétrofacturations en faisant en sorte qu'un agent recueille les informations, un autre analyse le litige et un troisième communique la résolution, simplifiant et accélérant le processus.
Découvrez comment les agents IA sont utilisés dans les systèmes d'entreprise, par exemple :
Services bancaires et financiers
Dans ce secteur, l'orchestration est utilisée pour des flux de travail complexes et sensibles aux risques qui nécessitent la collaboration de plusieurs agents pour garantir l'exactitude et la conformité.
- Conformité réglementaire : Un système coordonné d'agents assure la conformité en validant les informations clients par rapport aux listes de surveillance, en signalant les écarts et en maintenant une piste d'audit transparente de chaque action pour examen réglementaire.
- Traitement des prêts et hypothèques : Un workflow orchestré permet à un groupe d'agents de gérer l'ensemble du processus d'approbation de prêt — depuis la collecte et la vérification des documents jusqu'à l'application des modèles financiers et la fourniture de l'autorisation finale pour examen par un analyste humain.
- Détection et prévention de la fraude : C'est un exemple classique d'orchestration, où un agent surveille les transactions, un autre identifie et signale les activités suspectes, et un troisième gèle compte et génère un rapport d'incident pour une équipe de sécurité humaine.
Découvrez comment les agents IA et les LLM agentiques sont utilisés dans la finance :
Énergie et services publics
L'orchestration agentique permet la gestion de systèmes hautement distribués et complexes, tels que les réseaux électriques et la gestion des effectifs, en permettant à des agents spécialisés de communiquer et d'agir en temps réel.
- Gestion du réseau : Un système multi-agents avec des agents distincts pour les stations de production, les hubs de distribution, les compteurs intelligents individuels et les solutions de réseau intelligent travaille ensemble pour équilibrer l'offre et la demande d'énergie, optimiser la distribution et prévenir les pannes.
- Meter-to-cash : Un processus de meter-to-cash orchestré peut automatiser l'ensemble du cycle de facturation, en coordonnant les agents qui gèrent la relève automatisée des compteurs, la génération de factures et la collecte des paiements pour améliorer la précision et l'efficacité.
- Gestion des effectifs : Un système d'orchestration optimise la planification et le déploiement des techniciens de terrain en faisant coordonner les agents pour suivre la disponibilité des techniciens, attribuer les tâches en fonction de l'emplacement et des compétences, et fournir des mises à jour en temps réel sur l'avancement des travaux.
Télécommunications
Dans les télécoms, l'orchestration est utilisée pour gérer et automatiser des réseaux à grande échelle, complexes, ainsi que les opérations orientées client.
- Opérations réseau : Un système coordonné d'agents surveille différentes parties du réseau pour détecter automatiquement les pannes, diagnostiquer le problème et déclencher une série d'actions pour le résoudre, garantissant la fiabilité du réseau et minimisant les temps d'arrêt.
- Intégration client : L'orchestration accélère le processus en faisant coordonner les agents pour gérer l'activation de la carte SIM, la configuration de l'appareil et la mise en service, offrant une expérience client transparente du début à la fin.
- Gestion de la facturation et des revenus : Un workflow orchestré automatise les ajustements de facturation complexes, les paiements et les remboursements en faisant gérer chaque étape par des agents spécialisés, ce qui améliore la précision et la satisfaction client.
Avantages
79 % des cadres dirigeants adoptent des agents IA. Pourtant, 19 % des entreprises peinent à la coordination.7 L'orchestration agentique aide à gérer les agents à travers différentes applications. Voici quelques avantages de l'orchestration agentique :
- Efficacité opérationnelle : Rationalise les opérations de routine, réduit les coûts et améliore l'évolutivité.
- Agilité opérationnelle : Permet de répondre dynamiquement aux données et perturbations en temps réel.
- Collaboration transparente : Garantit la coopération entre les agents, les humains et les multiples systèmes.
- Avantages concurrentiels : Soutient l'innovation tout en permettant aux systèmes IA de fonctionner aux côtés du personnel humain.
- Satisfaction améliorée : Génère des expériences client supérieures et des améliorations mesurables de la qualité de service.
Défis
- Gouvernance : Nécessite une gouvernance des données robuste pour prévenir les risques liés à l'interaction de multiples agents avec divers systèmes.
- Conformité : Les systèmes doivent garantir la conformité dans les secteurs hautement réglementés, notamment dans la finance et la santé.
- Supervision humaine : Un déploiement efficace nécessite des seuils clairs pour l'intervention humaine et l'escalade.
- Intégration transparente avec les workflows existants et les systèmes hérités reste un obstacle important. Ces anciens systèmes peuvent être construits sur des architectures obsolètes qui ne sont pas compatibles avec les technologies modernes d'IA.
Méthodologie du benchmark
Architecture du workflow
Notre workflow d'agent séquentiel traite les demandes de voyage en cinq étapes :
- Agent parser : Extrait les données structurées à partir d'une entrée en langage naturel (« Je veux voyager de Berlin à Rome le 25 octobre 2025. Je resterai 3 jours ») pour identifier l'origine, la destination, les dates et la durée.
- Agent de recherche de vol : Appelle l'API Amadeus pour récupérer les vols disponibles en utilisant les codes IATA extraits et les dates de départ.
- Agent de météo : Récupère les prévisions météorologiques pour la destination sur toute la durée du séjour via WeatherAPI.
- Agent de recommandation d'activités : Associe les activités aux conditions météorologiques (musées pour la pluie, visites en extérieur pour le soleil).
- Agent planificateur de voyage : Synthétise toutes les sorties précédentes dans un itinéraire complet jour par jour avec
les vols, les prévisions météo et les activités recommandées.
Variables contrôlées
Pour garantir une comparaison équitable, nous avons maintenu des composants identiques dans tous les frameworks :
Configuration LLM :
- Modèle : Claude Haiku 4.5 via OpenRouter
- Température : 0,1
- Aucune limite maximale de tokens imposée à aucun agent
Fonctions d'outils :
- Implémentations Python identiques de get_flights() et get_weather() dans tous les frameworks
- Appels d'API externes à Amadeus (vols) et WeatherAPI (météo)
Paramètres de test
- Taille de l'échantillon : 100 exécutions par framework
- Mode d'exécution : Exécution séquentielle des agents (pas de traitement parallèle)
- Agrégation des métriques : Valeurs moyennes sur toutes les exécutions
Métriques mesurées
- Latence de la pipeline : Temps d'exécution total de bout en bout, de l'entrée à l'itinéraire final
- Transitions agent-à-agent : Surcoût du framework entre les transferts séquentiels d'agents
- Latence par agent : Temps d'exécution individuel pour chacun des cinq agents
- Écart agent-à-outil : Temps écoulé entre l'initialisation de l'agent et la première invocation d'outil
- Utilisation des tokens : Tokens de sortie générés.
Implémentation du chronométrage : Tout le chronométrage a été capturé en utilisant time.time() de Python avec une précision à la milliseconde. Pour chaque agent, nous avons enregistré l'heure de début avant l'exécution et l'heure de fin après l'achèvement, en calculant la latence comme la
différence. Pour l'exécution d'outil, nous avons mesuré le temps immédiatement avant l'appel de l'API et immédiatement après la réception de la réponse. Les transitions agent-à-agent ont capturé l'écart entre le moment où un agent se termine et
le moment où le framework lance l'agent suivant, ce surcoût pur du framework exclut le temps d'exécution du LLM et des outils.
Comptage des tokens : Nous avons utilisé une approche à double source pour plus de précision :
- Suivi intégré du framework (lorsqu'il est disponible) :
- LangChain : cb.total_tokens depuis les callbacks
- LangGraph : Utilisation de tokens depuis les points de contrôle d'état
- AutoGen : agent.get_total_usage() depuis les résultats de chat
- Estimation Tiktoken (solution de repli pour Claude via OpenRouter)
Étant donné que Claude n'expose pas le nombre de tokens via OpenRouter dans tous les frameworks, nous avons utilisé tiktoken comme approximation cohérente entre les implémentations.
Infrastructure d'observabilité : Toutes les métriques ont été validées à l'aide d'outils d'observabilité :
- Laminar : Collecte de traces en temps réel, mesures de latence et suivi des tokens.
- AgentOps : Suivi de l'exécution des agents, surveillance des performances.
Ces plateformes ont fourni une validation de référence pour notre instrumentation manuelle, garantissant la précision
des mesures entre les différents frameworks.
Résultats agrégés sous forme de moyennes sur 100 exécutions.
Pour en savoir plus sur l'orchestration agentique
Approfondissez l'IA agentique en consultant :
- Les 7 couches de la stack d'IA agentique
- 4 modèles de conception pour l'IA agentique & exemples concrets.
Citer cette recherche
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{simsek2026,
author = {Şimşek, Hazal},
title = {{Top 10+ des frameworks & outils d'orchestration agentique}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/agentic-orchestration}},
note = {AIMultiple. Consulté le 30 Juin 2026}
}


Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.