Outils d'observabilité RAG - Analyse comparative
Nous avons comparé quatre plateformes d'observabilité RAG sur un pipeline LangGraph à 7 nœuds selon trois dimensions pratiques : la surcharge de latence, l'effort d'intégration et les compromis de la plateforme.
Métriques de surcharge de latence
Explication des indicateurs :
La latence moyenne est calculée sur 150 appels à graph.invoke(). Les évaluations LLM-judge sont exécutées après l'arrêt du chronomètre.
La médiane correspond au 50e percentile de la latence. Les réponses de l'API LLM présentent une longue traîne ; la médiane est donc un meilleur indicateur des performances typiques des requêtes.
P95 correspond au 95e percentile, soit la latence dans le pire des cas pour 95 % des requêtes.
La différence entre la latence moyenne de la plateforme et la latence de référence non surveillée correspond à la différence de latence moyenne entre la plateforme et la ligne de base non surveillée.
Pour comprendre en détail notre évaluation et nos indicateurs, consultez notre méthodologie d'analyse comparative des outils d'observabilité RAG.
effort d'intégration par la plateforme
Principales conclusions
La variance de l'API LLM surpasse largement les frais généraux de surveillance
L'écart type de base était de 2 645 ms. La surcharge maximale était de 169 ms. Il faudrait retirer le LLM du pipeline pour mesurer la surcharge du SDK de manière isolée. Les tests de performance ponctuels des outils de surveillance mesurent la variance de l'API, et non la surcharge du SDK.
LangSmith nécessite le moins de code d'intégration
12 lignes ajoutées par rapport à la configuration de base (2 variables d'environnement). Les outils basés sur les décorateurs (Weave, Laminar, Langfuse) nécessitent 29 à 40 lignes. En résumé : LangSmith capture tout (y compris les appels internes à LangChain dont vous n'avez peut-être pas besoin), tandis que les outils basés sur les décorateurs vous offrent un contrôle précis sur ce qui est tracé.
Seuls Langfuse et Laminar proposent un auto-hébergement gratuit
Ces deux logiciels sont open source (MIT et Apache 2.0). LangSmith et Weave nécessitent des contrats d'entreprise pour les déploiements auto-hébergés.
Weave et LangSmith pilotent l'orchestration de l'évaluation
Les deux outils intègrent des orchestrateurs d'évaluation complets qui gèrent l'itération, la prédiction, le scoring et l'agrégation des données en un seul appel. Langfuse fournit l'infrastructure de scoring ( create_score() ) mais laisse l'orchestration au développeur. Les fonctionnalités d'évaluation de Laminar sont moins abouties : absence d'interface de comparaison des expériences et nombre limité de scoreurs prédéfinis.
Langfuse présente le coût unitaire le plus bas au volume
6 $ pour 100 000 unités à partir de 50 millions d'unités. LangSmith facture par trace (2,50 $ à 5 $ pour 1 000 unités). Weave facture par Mo de données ingérées (0,10 $/Mo supplémentaire).
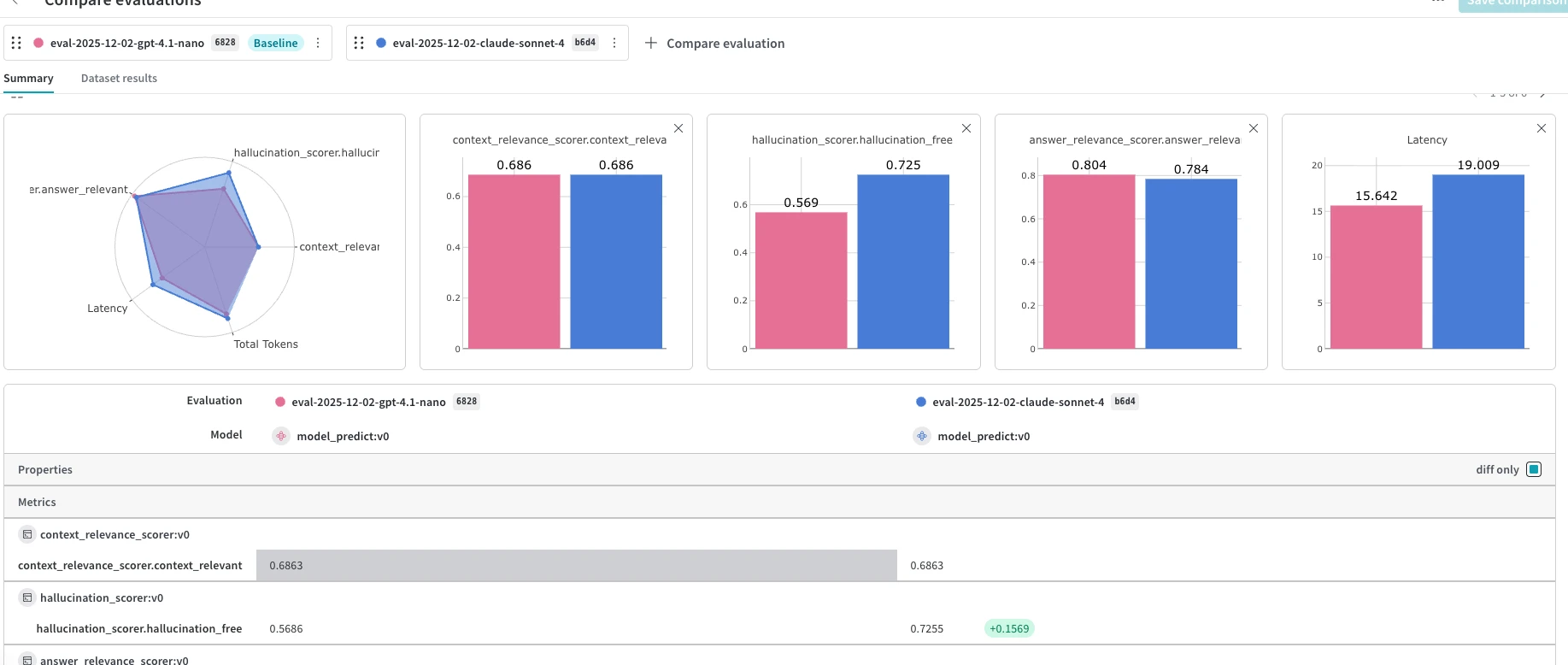
Capacités d'évaluation par plateforme
Poids et biais (Tissage)
- Orchestrateur d'évaluation :
weave.Evaluation.evaluate()gère l'itération, la prédiction, le score et l'agrégation des données en un seul appel. 1 - Évaluateurs personnalisés : sous-classe
Scorerou toute fonction@weave.op() - Évaluateurs préconfigurés : Certains (exactitude, etc.)
- Gestion des jeux de données :
weave.Datasetavec versionnage,publish(),from_pandas() - Comparaison des expériences : onglet Évaluations avec vue Comparer + Classements
- Évaluation en ligne :
EvaluationLogger, garde-fous/moniteurs
LangSmith
- Orchestrateur d'évaluation : fonction
evaluate()2 - Scoreurs personnalisés :
(Run, Example) -> dict - Évaluateurs préconfigurés : Oui (exactitude du contrôle qualité, distance d’intégration, juge LLM basé sur des critères)
- Gestion des jeux de données : API CRUD complète, jeux de données versionnés
- Comparaison des expériences : comparaison côte à côte pour chaque ensemble de données
- Évaluation en ligne : files d’attente d’annotations, règles automatisées sur les traces de production
laminaire
- Orchestrateur d'évaluation :
evaluate()de base est disponible, mais moins fréquemment utilisée. 3 - Évaluateurs personnalisés : fonctions décorées
@observe() - Marqueurs pré-assemblés : Minimal
- Gestion des jeux de données : interface utilisateur + SDK limité
- Comparaison expérimentale : Manuel
- Évaluation en ligne :
@observe()sur les fonctions de production
Langfuse
- Orchestrateur d'évaluation : aucun orchestrateur intégré. Boucle manuelle +
create_score()par trace 4 - Évaluateurs personnalisés : Tout code +
create_score(trace_id, name, value) - Évaluateurs préconfigurés : configurations d’évaluation basées sur un modèle dans l’interface utilisateur
- Gestion des jeux de données : jeux de données d’interface utilisateur et d’API
- Comparaison expérimentale : Manuel (filtrage de session)
- Évaluation en ligne :
create_score()sur des traces en direct, files d’attente d’annotations humaines
Comparaison des prix
Niveau gratuit et conservation des données
Abonnements payants et tarifs d'utilisation
Les prix indiqués sont valables à compter de mars 2026 et peuvent évoluer. Veuillez consulter le site web de chaque fournisseur pour connaître les tarifs les plus récents.
Déploiement dans le cloud, auto-hébergé et open source
visibilité de traçage et de débogage
- Weave affiche une arborescence des appels décorés avec
@weave.op(). Cliquer sur un nœud révèle les entrées, les sorties et le temps d'exécution. L'onglet « Évaluations » permet d'accéder aux résultats d'évaluation à partir des traces. - LangSmith capture automatiquement l'intégralité du graphe d'exécution de LangChain, y compris les étapes internes de la chaîne. La vue de trace inclut le nombre de jetons, la répartition de la latence et les estimations de coût par appel LLM.
- Langfuse affiche les traces avec des intervalles. Le suivi de session regroupe les requêtes multiples d'un même utilisateur. Le suivi des coûts est intégré à la vue des traces.
- Laminar affiche une chronologie des étendues similaire à celle des outils de traçage distribué. Les fonctions décorées avec
@observe()apparaissent comme des étendues avec capture des entrées/sorties.
Quel outil pour quel cas d'utilisation ?
- Pipeline LangChain, recherche d'un traçage sans effort : LangSmith. Instrumentation automatique des variables d'environnement, +12 lignes de code.
- Nous utilisons déjà W&B et avons besoin d'une orchestration d'évaluation :
weave.Evaluation+ gestion des versions des jeux de données + classements. - Besoin d'un hébergement indépendant sans contrat d'entreprise ? Langfuse. Logiciel libre (MIT), Docker Compose, zone de données UE.
- Besoin d'une observabilité open source sans orchestrateur eval ? Laminar. Apache 2.0, décorateur
@observe()léger. - Production à grand volume, sensible aux coûts : Langfuse. 6 $/100 000 unités pour un volume de production supérieur à 50 millions d’unités.
- Il nous faut à la fois le traçage et l'évaluation intégrée : Weave ou LangSmith. Des orchestrateurs d'évaluation complets avec gestion des jeux de données.
Méthodologie de référence pour les outils d'observabilité RAG
Configuration matérielle : Apple M4, 16 Go de RAM, macOS 26.3
Pipeline RAG : LangGraph StateGraph avec 7 nœuds (routeur, récupérateur, évaluateur de documents, solution de repli pour la recherche Web, calculateur, constructeur de contexte, générateur)
LLM : openai/gpt-4.1-nano via OpenRouter (température 0.0)
Routeur LLM : google/gemini-2.5-flash via OpenRouter (sortie structurée)
Évaluation LLM : google/gemini-2.5-pro via OpenRouter
Base de données vectorielles : Qdrant 1.12 (Docker local), distance cosinus, 1 204 documents SQuAD
Embeddings : BAAI/bge-small-en-v1.5 (384-dim, inférence CPU)
Recherche de candidats : 5 meilleurs documents par requête
Ensemble de requêtes : 30 requêtes sélectionnées, 20 factuelles (récupération de base de connaissances), 5 multi-sauts (nécessitant la combinaison d'informations), 5 mathématiques (acheminées vers le nœud de calculatrice).
Pipeline : L’échauffement de 3 requêtes a été ignoré. 5 passages complets ont été effectués sur l’ensemble des 30 requêtes par plateforme. Total : 150 exécutions mesurées par plateforme. Chronomètre : time.perf_counter() encapsule uniquement graph.invoke() . Les évaluations LLM-judge sont exécutées après l’arrêt du chronomètre. gc.collect() est utilisé entre les itérations et les plateformes. La ligne de base est utilisée en premier, puis chaque plateforme est traitée séquentiellement.
Variable contrôlée : Toutes les plateformes partagent le même code de pipeline, les mêmes instances LLM, la même configuration de récupération et le même ensemble de requêtes. La seule variable est la couche d’observabilité.
Tests statistiques : IC à 95 % via la distribution t, U de Mann-Whitney (non paramétrique, bilatéral) pour la signification, d de Cohen pour la taille de l’effet, méthode IQR pour la détection des valeurs aberrantes.
Outils testés
Comment fonctionne l'observabilité RAG
Chaque outil regroupe les appels de fonctions instrumentés sous forme de « trace » (un arbre de « spans ») et les envoie à un serveur. La surcharge provient de trois opérations sur chaque appel : (1) la création du span à l’entrée, (2) la sérialisation de la charge utile au retour et (3) la transmission en arrière-plan. La plupart des outils transmettent de manière asynchrone, mais la création et la sérialisation des spans sont effectuées en temps réel.
Variables d'environnement vs décorateurs vs instrumentation du SDK
Instrumentation par variables d'environnement (LangSmith). Définir LANGCHAIN_TRACING_V2=true active les points d'entrée de traçage intégrés à LangChain et LangGraph. Chaque appel LLM, invocation de récupérateur et nœud de graphe est capturé automatiquement. Aucune modification du code du pipeline n'est requise.
(Weave, Laminar, Langfuse). Le développeur décore chaque fonction ( @weave.op() , @observe() ). Les fonctions non décorées ne sont pas suivies.
Limites
Charge de travail de requêtes séquentielles monothread. Les requêtes simultanées en production peuvent modifier le profil de surcharge en raison des conflits de vidage asynchrones.
Les API LLM externes (OpenRouter) représentent la majeure partie de la latence totale, réduisant ainsi la surcharge relative de surveillance. L'inférence locale (par exemple, Ollama) augmenterait proportionnellement cette surcharge.
Serveurs backend cloud uniquement. Les déploiements auto-hébergés de Langfuse et Laminar peuvent présenter une surcharge différente car ils évitent la transmission réseau vers un service de traçage externe.
La phase de préchauffage élimine les coûts de démarrage à froid. Les déploiements sans serveur subiraient une surcharge plus importante lors de la première requête en raison de l'initialisation du SDK.
LangSmith capture tous les appels internes de LangChain, et pas seulement ceux des 7 nœuds du pipeline. D'autres plateformes ne tracent que les fonctions décorées. La comparaison porte donc sur des périmètres d'instrumentation différents, et non sur des charges de travail équivalentes.
Données tarifaires extraites en mars 2026. Veuillez vérifier les tarifs actuels sur le site web de chaque fournisseur.
Conclusion
La latence n'est pas un critère pertinent pour choisir entre ces outils. Les quatre ont ajouté moins de 170 ms à un pipeline où les appels à l'API LLM prennent entre 1 000 et 3 000 ms, et aucune différence n'était statistiquement significative.
LangSmith est la solution la plus rapide à intégrer si vous utilisez LangChain 12 lignes et que le traçage est complet. Weave et LangSmith proposent tous deux une orchestration d'évaluation, contrairement à Langfuse et Laminar. Langfuse et Laminar sont les seules options si vous devez héberger vous-même votre solution sans contrat d'entreprise.
Pour en savoir plus
Explorez d'autres indicateurs RAG, tels que :
- Modèles d'intégration : OpenAI vs Gemini vs Cohere
- Les 16 meilleurs modèles d'embeddings open source pour RAG
- Meilleure base de données vectorielles pour RAG : Qdrant vs Weaviate vs Pinecone
- Analyse comparative des modèles de reclassement : Comparaison des 8 meilleurs modèles
- Modèles d'intégration multimodaux : Apple vs Meta vs OpenAI
- Comparaison des performances graphiques et vectorielles
- Les 10 meilleurs modèles d'intégration multilingues pour RAG
Citer cette recherche
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{sar2026,
author = {Sarı, Ekrem},
title = {{Outils d'observabilité RAG - Analyse comparative}},
year = {2026},
month = mar,
howpublished = {\url{https://aimultiple.com/rag-monitoring}},
note = {AIMultiple. Retrieved Mars 23, 2026}
}
Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.