Benchmark de Web Crawler pour alimenter les sites web en IA
Nous avons évalué quatre API de crawl sur trois domaines de difficulté variable à trois niveaux de profondeur maximale (5, 10, 20) avec une limite de 1 000 pages, en mesurant la couverture du crawl, le temps d'exécution, la découverte de liens, la qualité des liens markdown et la précision de l'extraction des titres.
Si votre objectif est de :
- Transformer des pages web en données structurées, consultez notre guide sur le web scraping.
- Crawler des sites web entiers, lisez la suite.
Benchmark des web crawlers
Vous pouvez lire notre méthodologie de benchmark.
Pages moyennes crawlées vs coût par 1 000 pages
Pages crawlées par domaine selon la profondeur maximale
Firecrawl a systématiquement crawlé environ 100 pages sur theregister.com quelle que soit la profondeur maximale, environ 90 pages sur entrepreneur.com à tous les niveaux de profondeur, et seulement environ 30 pages sur amazon.com, probablement en raison de la protection agressive des bots d'Amazon. Il est à noter que l'augmentation de la profondeur maximale n'a eu virtually aucun impact sur le nombre de pages que Firecrawl a pu crawler sur n'importe quel domaine.
Apify a démontré la performance la plus cohérente, atteignant la limite maximale de crawl de 1 000 pages sur chaque domaine à chaque niveau de profondeur sans aucune difficulté apparente, même sur des sites fortement protégés comme Amazon.
Cloudflare a montré un comportement incohérent lors des tests :
- Sur theregister.com à une profondeur maximale de 5, il n'a crawlé que 100 pages, mais à une profondeur maximale de 20, il a atteint près de 1 000 pages.
- Comme nous l'avons observé lors de tests précédents, Cloudflare ne crawl parfois qu'une seule page avant de terminer entièrement le travail. Nous avons confirmé qu'il ne s'agissait pas d'un problème de cache (le cache était désactivé) et avons testé avec des temps d'attente entre les exécutions allant jusqu'à 1 minute, mais le comportement persistait. À une profondeur maximale de 10 sur theregister.com, ce problème exact s'est produit, Cloudflare n'a crawlé qu'une seule page avant de s'arrêter.
- Sur entrepreneur.com, Cloudflare a crawlé 780 pages à une profondeur de 5, est passé à 885 à une profondeur de 10, puis a chuté brutalement à seulement 172 pages à une profondeur de 20. Cette baisse peut être liée au planificateur de crawl de Cloudflare qui dépriorise ou met en timeout les chaînes de liens plus profondes, ou elle pourrait refléter une limite de concurrence interne qui provoque la terminaison prématurée du travail lorsque la frontière de crawl devient trop grande à des profondeurs plus élevées.
- Sur amazon.com, Cloudflare a crawlé 905 pages à une profondeur de 5, mais le nombre a diminué régulièrement à mesure que la profondeur maximale augmentait, tombant à 809 à une profondeur de 10 et 795 à une profondeur de 20, suggérant que des configurations de crawl plus profondes peuvent amener Cloudflare à passer plus de temps sur la surcharge de découverte de liens plutôt que sur la récupération réelle des pages.
Nimble a atteint ou approché la limite de 1 000 pages sur theregister.com à tous les niveaux de profondeur (1 000 / 1 000 / 999). Sur entrepreneur.com, il a crawlé 1 000 pages à une profondeur de 5 mais a montré de légères baisses à des profondeurs plus élevées (896 à une profondeur de 10, 983 à une profondeur de 20), probablement en raison de son timeout de 7 heures atteint avant d'achever le crawl complet à des niveaux plus profonds, toutes les exécutions de Nimble se sont terminées par un statut de timeout. Amazon s'est avéré plus difficile :
- À une profondeur de 5, il n'a géré que 319 pages, mais à une profondeur de 10, il a bondi à 988 pages, puis est tombé à 906 à une profondeur de 20
- Cette incohérence reflète probablement la combinaison des mécanismes de protection des bots d'Amazon et des contraintes de timeout de Nimble, où les crawls plus profonds prennent plus de temps pour traiter chaque page et peuvent rencontrer plus de défis anti-bots en cours de route
Temps d'exécution par domaine selon la profondeur maximale
Firecrawl a été le fournisseur le plus rapide sur tous les domaines, achevant les crawls en moins de 5 minutes, généralement entre 75 et 265 secondes. Cette vitesse se fait au détriment de la couverture, car Firecrawl a également crawlé le moins de pages. Essentiellement, il termine rapidement car il s'arrête tôt.
Apify a pris environ 2 200-2 400 secondes (~40 minutes) sur theregister.com quelle que soit la profondeur. Sur entrepreneur.com et amazon.com, les temps d'exécution étaient significativement plus longs à 8 300-15 900 secondes (2-4 heures), reflétant des structures de sites plus grandes et plus complexes. Malgré les temps plus longs, Apify a systématiquement atteint la limite de 1 000 pages, ce qui en fait le plus fiable en termes de rapport couverture-temps.
Cloudflare a montré des temps qui reflètent ses comptes de crawl incohérents :
- Sur theregister.com à une profondeur de 10, il s'est terminé en seulement 1 seconde, car il n'a crawlé qu'une seule page avant de s'arrêter.
- Sur entrepreneur.com à une profondeur de 20, il s'est terminé en 10 secondes après avoir crawlé seulement 172 pages.
- Lorsque Cloudflare termine un crawl complet, les temps varient de 3 500 à 25 200 secondes.
- À mesure que la profondeur maximale augmente, Cloudflare semble privilégier l'atteinte de pages plus profondes plutôt que la largeur, crawlant moins de pages mais terminant plus rapidement. Sur amazon.com, le temps d'exécution est passé de 25 200 secondes (timeout) à une profondeur de 5 à seulement 5 660 secondes à une profondeur de 20, tandis que les pages crawlées ont également diminué de 905 à 795. Cela suggère que le crawler de Cloudflare change de stratégie à des profondeurs plus élevées, passant moins de temps à la découverte large et plus à la traversée profonde.
Nimble a atteint le timeout de 7 heures (25 200 secondes) sur chaque exécution sur tous les domaines et niveaux de profondeur. Cela est notable car lors de nos tests rapides précédents avec une profondeur maximale de 1, Nimble s'est terminé sans timeout. Dans le benchmark complet avec des profondeurs de 5 à 20 et une limite de 1 000 pages, il s'est exécuté de manière cohérente jusqu'à ce que le timeout soit atteint. Malgré cela, Nimble a toujours réussi à crawler un grand nombre de pages dans la plupart des cas (~900-1 000 sur theregister.com et entrepreneur.com), ce qui signifie qu'il est activement en train de crawler pendant les 7 heures mais ne signale tout simplement jamais la complétion.
Taux de remplissage du texte des liens par fournisseur selon la profondeur maximale
Pour évaluer la qualité de la sortie markdown, nous avons mesuré le pourcentage de liens dans le markdown de chaque fournisseur contenant un texte d'ancre, la partie cliquable d'un lien. Un texte d'ancre manquant (par exemple [](/about) au lieu de [About Us](/about)) signifie que le crawler n'a pas réussi à extraire l'étiquette du lien.
- Nimble : 100% à toutes les profondeurs
- Cloudflare : 91-94%
- Firecrawl : 90%
- Apify : 77-78%, environ 1 lien sur 5 sans texte d'ancre
La profondeur de crawl a eu un impact minimal sur les taux de remplissage pour tout fournisseur, suggérant qu'il s'agit d'une caractéristique du moteur d'analyse de chaque fournisseur plutôt que d'un paramètre de crawl.
Taux de remplissage du texte des liens par fournisseur selon le domaine
L'examen des taux de remplissage sur différents domaines révèle comment la complexité du site affecte la qualité d'extraction des liens de chaque fournisseur.
- Nimble a maintenu 100% sur tous les domaines.
- Apify a montré la plus grande variation, 89% sur amazon.com mais tombant à 66% sur entrepreneur.com, ce qui signifie qu'un tiers de ses liens sur ce site étaient sans texte d'ancre. Cela suggère que Apify lutte davantage avec des sites riches en contenu qui ont des structures de navigation complexes.
- Firecrawl a été le meilleur sur theregister.com (98%) mais est tombé à 81% sur entrepreneur.com, suivant un modèle similaire à Apify.
- Cloudflare a été le plus cohérent après Nimble, restant entre 89-94% quel que soit le domaine.
Entrepreneur.com s'est avéré le domaine le plus difficile pour l'extraction de texte de lien, à la fois Apify (66%) et Firecrawl (81%) y ont eu leurs scores les plus bas, probablement en raison de l'utilisation intensive de menus de navigation imbriqués et d'éléments de contenu dynamique sur le site qui sont plus difficiles à convertir proprement en markdown.
Total des liens dans la sortie markdown par domaine selon la profondeur maximale
La variance du nombre de liens entre les fournisseurs était constamment élevée (74-97%), indiquant que les fournisseurs extraient des nombres de liens très différents des mêmes pages. Pour obtenir une vue plus détaillée de cette disparité, nous avons mesuré le nombre total de liens markdown par fournisseur.
- Apify a renvoyé le plus de liens au total, en particulier sur amazon.com avec plus de 420K liens à une profondeur de 5 (~423 par page). Sur entrepreneur.com, il s'est stabilisé autour de 63K quelle que soit la profondeur. Sa sortie inclut des trackers publicitaires et des pixels de suivi en plus des liens de contenu de page.
- Cloudflare a culminé à 303K sur entrepreneur.com à une profondeur de 10 mais est tombé à 53K à une profondeur de 20. Sur la même page d'accueil d'entrepreneur.com, Cloudflare a extrait 434 liens contre 143 pour Apify, capturant les menus de navigation complets et les sous-menus.
- Firecrawl a systématiquement renvoyé 5-9K liens sur toutes les configurations, limité par son faible nombre de pages.
- Nimble a renvoyé 3-40K liens au total, en moyenne 5-28 liens par page contre 60-420 pour les autres fournisseurs. Sur la page d'accueil d'entrepreneur.com, Nimble a renvoyé 13 liens contre 434 pour Cloudflare, limité aux titres principaux des articles. Son taux de remplissage de 100% reflète que les liens qu'il a inclus avaient tous un texte d'ancre, plutôt que d'indiquer une couverture complète des liens. Nimble ne renvoie pas de liens markdown standard. Son nombre inclut les liens HTML échappés trouvés dans la sortie markdown.
Taux de présence du titre par fournisseur
La similarité des titres entre les fournisseurs a montré une déviation inférieure à 1% sur tous les tests et domaines, confirmant que lorsque les fournisseurs extraient un titre, ils renvoient systématiquement le même résultat. Le taux de présence du titre est également resté entre 98-100% à tous les niveaux de profondeur maximale, montrant que la profondeur de crawl n'a aucun impact significatif sur l'extraction du titre.
Lorsqu'il est ventilé par domaine, certaines différences sont apparues :
Sur entrepreneur.com et theregister.com, la plupart des fournisseurs ont atteint des taux de présence de titre de 99-100%. Amazon.com était le seul domaine où des différences significatives sont apparues, Firecrawl est tombé à 93% et Nimble à 95,9%, tandis que Apify a maintenu 99,6%. Cela correspond à la protection plus lourde des bots d'Amazon, qui peut bloquer ou déformer les réponses de page, amenant certains fournisseurs à renvoyer des pages sans titres extractibles.
Qu'est-ce qu'un web crawler ?
Un web crawler, parfois appelé « araignée » ou « agent », est un bot qui navigue sur internet pour indexer du contenu.
Les crawlers ont dépassé les moteurs de recherche et servent désormais de couche de données agentic. Ils agissent comme les yeux des agents IA autonomes comme Claude Code et OpenAI Operator, aidant à des tâches en temps réel telles que la recherche concurrentielle et les transactions multi-étapes.
Que fait un web crawler ?
Le web crawling a été divisé en trois modes, chacun conçu pour un objectif de crawler différent.
- Mode découverte (traditionnel) : Les bots de moteur de recherche comme Googlebot crawlent les URL pour l'indexation, aidant les gens à trouver des résultats via les moteurs de recherche.
- Mode récupération (RAG): Les bots IA comme ChatGPT-User ou PerplexityBot récupèrent des pages spécifiques en temps réel pour répondre aux invites utilisateur. Ils utilisent le markdown au lieu du HTML pour s'adapter aux limites de token du modèle IA.
- Mode agentic (orienté action) : Ce nouveau type de crawler en 2026 fait plus que simplement lire du contenu. En utilisant le Model Context Protocol (MCP), ces bots peuvent interagir avec des sites web pour réserver des vols ou exécuter des commandes logicielles.
Par le passé, les crawlers utilisaient des sélecteurs tels que XPath ou CSS pour extraire des données. L'extraction native à l'IA est devenue la norme.
Des outils tels que Firecrawl et Crawl4AI utilisent des instructions en langage naturel pour trouver des données. Au lieu d'écrire des règles pour chaque élément, les développeurs peuvent dire au crawler d'« extraire le prix du produit », et l'IA trouvera la bonne valeur même si le code du site web change.
Construire ou acheter des web crawlers à l'ère de l'IA
1. Construire votre propre crawler
Idéal pour protéger la propriété intellectuelle principale et permettre une personnalisation approfondie. Construire maintenant nécessite de développer une couche d'agent propriétaire, pas seulement d'écrire des scripts Scrapy de base.
- Quand construire : Choisissez cette approche si votre crawler offre un avantage concurrentiel unique. Par exemple, construisez le vôtre si vous développez un moteur de recherche spécialisé ou si vous avez besoin d'un contrôle total sur des données sensibles ou réglementées.
- L'ensemble d'outils : Vous n'avez plus besoin de repartir de zéro. Les développeurs exploitent désormais le Model Context Protocol (MCP) pour permettre aux agents IA internes d'interagir avec le web.
2. Utiliser des outils et des API de web crawling
Les outils gérés ont évolué de simples scrapers vers des agents autonomes.
- Extraction sans maintenance : Les outils modernes tels que Kadoa et Firecrawl utilisent une IA auto-cicatrisante. Vous spécifiez les données requises, telles que « Prix du produit », plutôt que son emplacement dans le code. Si la mise en page du site web change, l'outil s'adapte automatiquement.
- Conformité en tant que service : De nombreux fournisseurs offrent une conformité intégrée à la loi européenne sur l'IA. Ils gèrent les journaux d'audit requis et les vérifications d'exclusion des droits d'auteur, qui sont difficiles à mettre en œuvre indépendamment.
- Vitesse vers la valeur : L'achat d'une plateforme peut faire passer votre projet du concept à la production en quelques semaines.
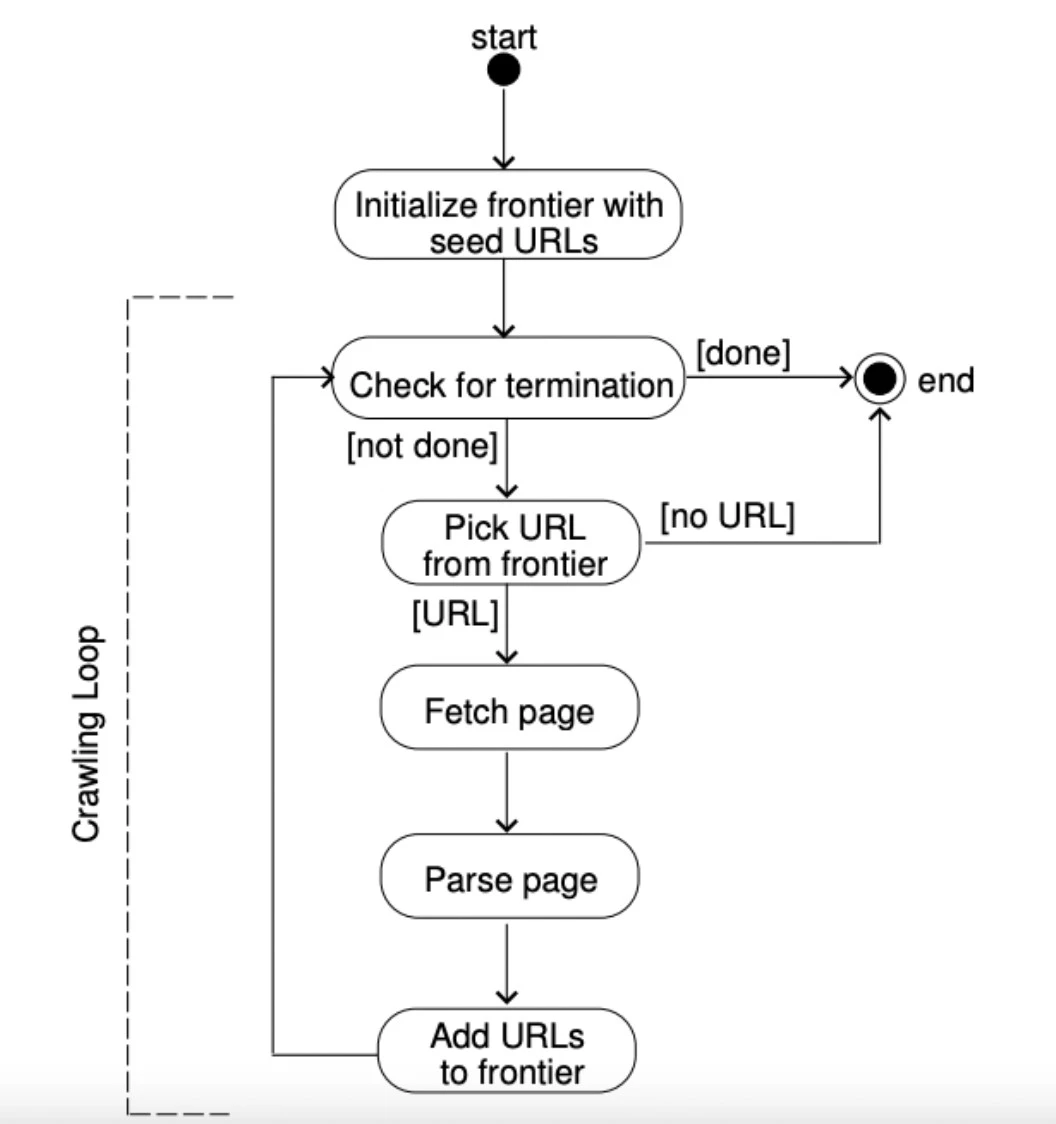
Figure 5 : Une explication du fonctionnement d'une frontière d'URL.
Les web crawlers sont-ils légaux ?
En général, le web crawling est légal, mais selon la manière et ce que vous crawl, vous pourriez rapidement vous retrouver dans une impasse juridique. Quatre piliers majeurs déterminent si le crawl (et le scraping qui suit généralement) est légal :
1. Public vs privé : Ne crawl que les données qui sont ouvertement disponibles au public sans compte.
2. Informations personnelles : Évitez les informations personnellement identifiables (noms, e-mails et adresses) sauf si vous avez une base légale.
3. Santé du serveur : Utilisez des limites de débit pour éviter de ralentir le serveur ; évitez de « DDOSer » un site web.
4. Droit d'auteur : Les articles et les images sont protégés par le droit d'auteur, mais les faits (prix, dates) ne le sont pas.
Quelle est la différence entre le web crawling et le web scraping ?
Le web scraping consiste à utiliser des web crawlers pour scanner et stocker tout le contenu d'une page web ciblée. En d'autres termes, le web scraping est un cas d'utilisation spécifique du web crawling pour créer un ensemble de données ciblé, comme extraire toutes les actualités financières pour l'analyse d'investissement et rechercher des noms d'entreprises spécifiques.
Traditionnellement, une fois qu'un web crawler a crawlé et indexé tous les éléments de la page web, un web scraper extrayait des données de la page web indexée. Cependant, de nos jours, les termes scraping et crawling sont utilisés de manière interchangeable avec la différence que crawler tend à se référer davantage aux crawlers de moteur de recherche. Comme des entreprises autres que les moteurs de recherche ont commencé à utiliser des données web, le terme web scraper a commencé à prendre le dessus sur le terme web crawler.
Quels sont les défis du web crawling ?
1. Fraîcheur de la base de données
Le contenu des sites web est mis à jour régulièrement. Les pages web dynamiques, par exemple, changent leur contenu en fonction des activités et des comportements des visiteurs. Cela signifie que le code source du site web ne reste pas le même après avoir crawlé le site web. Pour fournir les informations les plus à jour à l'utilisateur, le web crawler doit re-crawler ces pages web plus fréquemment.
2. Pièges de crawler
Les sites web emploient différentes techniques, telles que des pièges de crawler, pour empêcher les web crawlers d'accéder et de crawler certaines pages web. Un piège de crawler, ou piège d'araignée, amène un web crawler à faire un nombre infini de requêtes et à rester piégé dans un cercle vicieux de crawl. Les sites web peuvent également créer involontairement des pièges de crawler. Dans tous les cas, lorsqu'un crawler rencontre un piège de crawler, il entre dans quelque chose comme une boucle infinie qui gaspille les ressources du crawler.
3. Bande passante réseau
Télécharger un grand nombre de pages web non pertinentes, utiliser un web crawler distribué ou recrawler de nombreuses pages web entraînent tous un taux élevé de consommation de capacité réseau.
4. Pages en double
Les bots web crawlers crawlent principalement tout le contenu en double sur le web ; cependant, seule une version d'une page est indexée. Le contenu en double rend difficile pour les bots de moteur de recherche de déterminer quelle version du contenu en double indexer et classer. Lorsque Googlebot découvre un groupe de pages web identiques dans les résultats de recherche, il indexe et sélectionne uniquement l'une de ces pages pour afficher en réponse à la requête de recherche d'un utilisateur.
Top 3 des meilleures pratiques de web crawling
1. Politesse/Taux de crawl
Les sites web définissent un taux de crawl pour limiter le nombre de requêtes effectuées par les bots web crawlers. Le taux de crawl indique combien de requêtes un web crawler peut faire à votre site web dans un intervalle de temps donné (par exemple, 100 requêtes par heure). Cela permet aux propriétaires de sites web de protéger la bande passante de leurs serveurs web et de réduire la surcharge du serveur. Un web crawler doit respecter la limite de crawl du site web cible.
2. Conformité robots.txt
Un fichier robots.txt est un fichier texte placé à la racine d'un site web qui indique aux crawlers quelles pages ils ont le droit d'accéder ou non. C'est une norme volontaire, ce qui signifie que les bots conformes la respectent mais qu'elle n'empêche pas techniquement l'accès. Suivre le robots.txt d'un site web est considéré comme une meilleure pratique, et dans de nombreuses juridictions, l'ignorer peut vous exposer à un risque juridique ou réputationnel.
3. Rotation d'IP
Les sites web emploient différentes techniques anti-scraping telles que les CAPTCHAs pour gérer le trafic de crawler et réduire les activités de web scraping. Par exemple, l'empreinte digitale du navigateur est une technique de suivi utilisée par les sites web pour collecter des informations sur les visiteurs, telles que la durée de la session ou les vues de page.
Cette méthode permet aux propriétaires de sites web de détecter le « trafic non humain » et de bloquer l'adresse IP du bot. Pour éviter la détection, vous pouvez intégrer des proxies rotatifs, tels que des proxies résidentiels, dans votre web crawler.
Méthodologie de benchmark des web crawlers
Nous avons testé quatre API de crawl (Apify, Nimble, Cloudflare, Firecrawl) sur trois domaines de difficulté variable : amazon.com (protection lourde des bots), entrepreneur.com (site de contenu complexe) et theregister.com (site d'actualités).
Configuration partagée
Tous les fournisseurs ont reçu des paramètres de base identiques pour assurer une comparaison équitable :
- Sitemap : Désactivé, les fournisseurs doivent découvrir les pages uniquement via les liens HTML
- Liens externes : Désactivés, les crawlers restent dans le domaine cible
- Sous-domaines : Activés, les pages de sous-domaines sont suivies (par exemple, india.entrepreneur.com)
- rendu JavaScript : Activé, tous les fournisseurs utilisent un navigateur sans tête
- Cache : Désactivé
- Limite de page : 1 000 pages par exécution
- Timeout : 7 heures (25 200 secondes)
- Gestion de la limite de débit : attente de 20 secondes avec jusqu'à 3 tentatives sur HTTP 429
Chaque fournisseur a été testé à trois niveaux de profondeur maximale (5, 10, 20) sur les trois domaines, soit un total de 36 exécutions de crawl. Les fournisseurs ont été testés séquentiellement (pas en parallèle), chaque combinaison a été exécutée une fois, et le statut de crawl a été interrogé toutes les 1 seconde.
Apify a été configuré avec l'acteur website-content-crawler utilisant Playwright/Firefox comme navigateur sans tête. L'accès aux sous-domaines était contrôlé via des motifs glob, et le proxy intégré de Apify a été utilisé pour toutes les requêtes.
Nimble, Cloudflare et Firecrawl ont été configurés en utilisant leurs API REST respectives avec les paramètres partagés décrits ci-dessus. Aucune configuration spécifique au fournisseur supplémentaire n'a été appliquée au-delà des paramètres standardisés.
Pour Cloudflare, nous avons utilisé le plan Workers Paid. Le coût signalé reflète ce que nous avons dépensé pour crawler 1 000 pages sous ce plan. Cloudflare facture en fonction du temps de rendu du navigateur plutôt que du nombre de pages.
Pour Firecrawl, nous avons utilisé le plan Hobby. Le coût signalé est le montant proratisé pour 1 000 crédits sur les crédits fournis dans ce plan. Le coût effectif par page varie en fonction du niveau de plan et de l'achat de packs de crédits supplémentaires.
Citer cette recherche
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Şipi, Nazlı},
title = {{Benchmark de Web Crawler pour alimenter les sites web en IA}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/web-crawler}},
note = {AIMultiple. Consulté le 2 Juillet 2026}
}
Commentaires 1
Partagez vos idées
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.
Hi Cem, I think there is a misunderstanding regarding the robots.txt role in the crawling context. The web bots can crawl any website when indexing is allowed without having the robots.txt somewhere on their top domain, subdomains and ports and so on. The role of a robots.txt is to keep control of the traffic from web bots so the website is not overloaded by requests.