Meilleurs 12+ Agents de Web Scraping IA (Gratuit & Payant)
Les sélecteurs CSS manuels et les scripts de base ne fonctionnent plus aussi bien. À mesure que les architectures web deviennent plus dynamiques et pilotées par l'IA, les méthodes de scraping traditionnelles deviennent moins efficaces.
Pour maintenir la fiabilité des données, l'industrie se tourne vers des agents IA autonomes, le scraping basé sur la vision (VLM) et les scrapers auto-cicatrisants. Visitez les meilleurs outils de web scraping IA :
Meilleurs outils de web scraping IA
Comment nous avons créé cette liste
Nous avons intentionnellement exclu les outils de scraping de données à usage général et les bibliothèques d'automatisation qui manquent de capacités IA intégrées (comme Scrapy ou Playwright), même s'ils sont couramment utilisés pour le web scraping et peuvent compléter les outils IA dans des flux de travail hybrides.
Nous avons sélectionné cette liste en utilisant les critères suivants :
- Focus sur les capacités pilotées par l'IA : Nous avons inclus des outils qui utilisent l'intelligence artificielle, tels que les LLM et le NLP, pour comprendre la structure de la page sans règles codées en dur ou extraction de données pilotée par prompt.
- Accessibilité pour les utilisateurs : Nous avons catégorisé les outils en fonction du niveau technique, tels que les outils sans code par rapport aux outils pour développeurs.
Qu'est-ce que le web scraping IA ?
Le web scraping IA a évolué vers la liquidation autonome des données. Il ne s'agit plus d'automatiser les clics de navigateur ou d'analyser le HTML ; il implique des Modèles Langage-Vision (VLM) qui « voient » une page web comme un humain et un Raisonnement Agentique capable de naviguer dans des authentifications complexes et du contenu dynamique sans sélecteurs CSS prédéfinis ni mappage DOM.
Types d'outils de web scraping IA
1. Plateformes pilotées par l'IA
Ces solutions utilisent des LLM, la vision par ordinateur ou le NLP pour analyser, extraire ou interpréter le contenu des pages web. Par exemple, le scraping adaptatif de Diffbot s'adapte dynamiquement aux changements de DOM ou aux balises incohérentes entre les pages. De nombreux outils de cette catégorie prennent en charge soit l'extraction basée sur le schéma (structurée), soit basée sur le prompt.
Vous donnez à l'outil une instruction en langage naturel, par exemple, « Extraire tous les titres de poste et les noms d'entreprise de cette URL. »
2. Outils sans code
Les scrapers sans code fournissent des interfaces visuelles qui permettent aux utilisateurs de définir les données à capturer en utilisant une fonctionnalité point-and-click ou des modèles préconstruits. Vous pouvez définir visuellement les règles d'extraction de données.
Cependant, ces outils offrent une utilisation limitée de l'IA par rapport aux plateformes pilotées par l'IA, qui utilisent l'IA pour la détection de motifs ou les suggestions de champs intelligentes.
3. Outils IA open-source
Cette catégorie comprend des bibliothèques ou des frameworks qui utilisent des LLM ou des agents IA pour extraire des données des pages web. Ils offrent un contrôle programmatique ; vous devez définir des schémas d'extraction ou des prompts IA.
Techniques et technologies impliquées dans le web scraping piloté par l'IA
L'approche de web scraping pilotée par l'IA s'adapte automatiquement aux refontes de sites web et extrait les données chargées dynamiquement via JavaScript. Il est important d'employer ces méthodes tout en tenant compte des conditions du site web et des considérations éthiques.
1. Scraping adaptatif
Les méthodes traditionnelles de web scraping reposent sur la structure ou la mise en page spécifique d'une page web. Lorsque les sites web mettent à jour leurs designs et structures, les scrapers traditionnels peuvent facilement se briser. Les méthodes de collecte de données basées sur l'IA, telles que le scraping adaptatif, permettent aux outils de web scraping de s'adapter aux changements sur les sites web, y compris le design et la structure.
Les scrapers adaptatifs utilisent l'apprentissage automatique et l'IA pour ajuster dynamiquement leur comportement en fonction de la structure d'une page web. Ils identifient de manière autonome la structure de la page web cible en analysant le Document Object Model (DOM) ou en suivant des motifs spécifiques. Pour identifier des motifs ou anticiper des changements, l'outil peut être formé à l'aide de données historiques scrapées.
Par exemple, des modèles IA comme les réseaux de neurones convolutifs (CNN) peuvent être utilisés pour reconnaître et analyser les éléments visuels d'une page web tels que les boutons. Typiquement, les techniques de scraping de données traditionnelles reposent sur le code sous-jacent d'une page web, comme les éléments HTML, pour extraire des données.
Extraction visuelle zero-shot :
Le scraping adaptatif traditionnel repose toujours sur l'arbre DOM. Cependant, en 2026, des outils comme Firecrawl et Crawl4AI sont passés à l'extraction « Zero-Shot ». En prenant une capture visuelle (VLM), l'IA identifie les éléments en fonction de l'intention visuelle plutôt que du code. Cela rend les scrapers plus résilients à la randomisation des classes CSS et aux pièges de code « Honey-pot ».
Sponsorisé
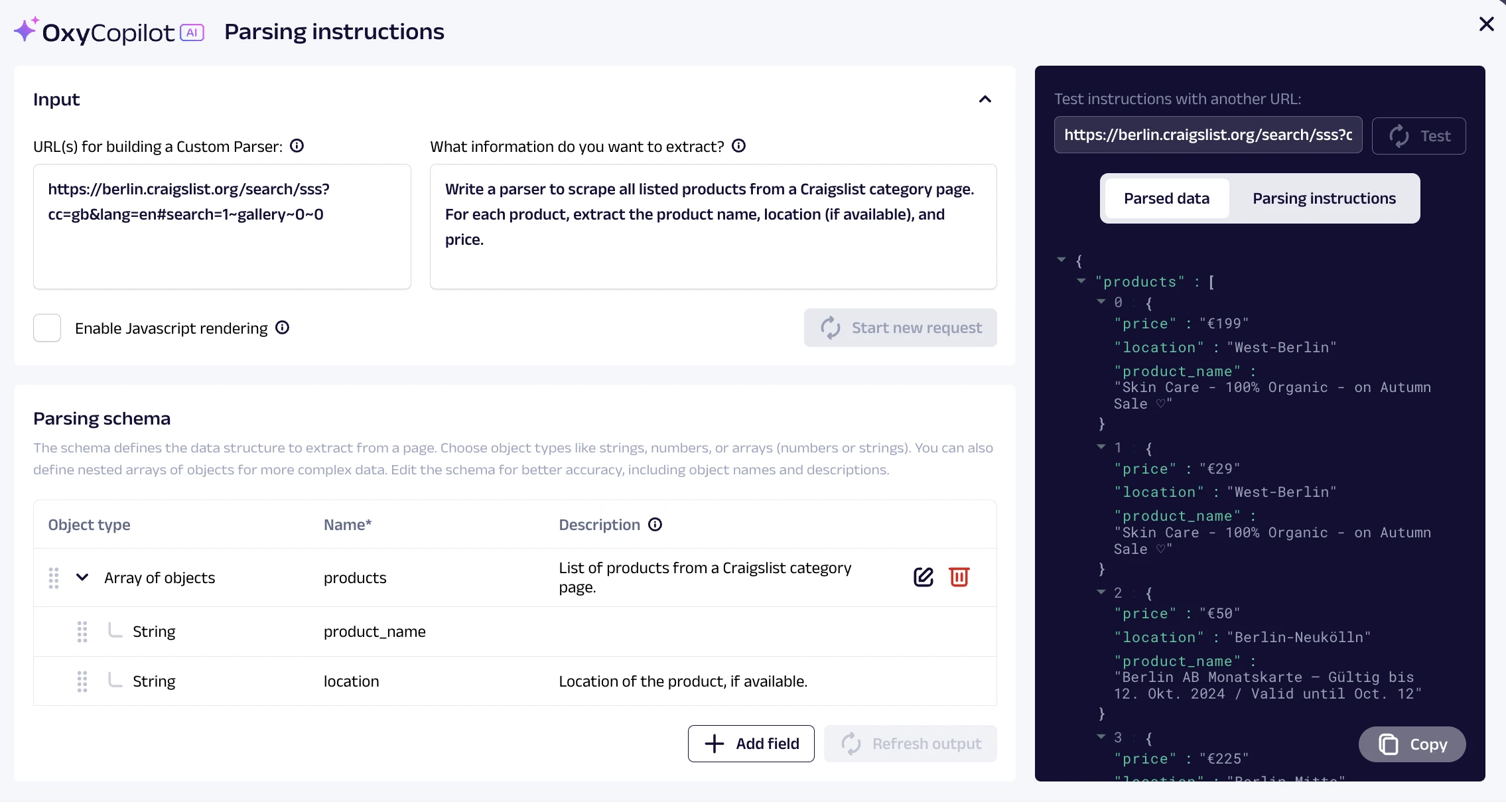
Oxylabs fournit un constructeur de parseur personnalisé basé sur le ML, appelé OxyCopilot, qui améliore l'API Web Scraper d'Oxylab, permettant aux utilisateurs d'affiner et d'organiser les données collectées à l'aide de prompts. Cela simplifie le processus en éliminant le besoin de trier parmi les champs de données non pertinents ou d'effectuer un nettoyage manuel des données.
2. Génération de motifs de navigation semblables à ceux des humains
La plupart des sites web emploient des mesures anti-scraping, comme les CAPTCHAs, pour empêcher les scrapers web d'accéder et de scraper leur contenu. Les outils de web scraping pilotés par l'IA peuvent simuler un comportement semblable à celui des humains comme la vitesse, les mouvements de souris et les motifs de clic.
3. Modèles IA génératifs
En 2025/2026, nous avons cessé de demander à l'IA d'écrire du code BeautifulSoup. Au lieu de cela, nous utilisons des Agents de Scraping (comme Skyvern ou Browser-use).
- Comment cela fonctionne : Vous fournissez un objectif en anglais simple (par exemple, « Trouvez l'ordinateur portable le moins cher sur ce site et exportez vers JSON »).
- Modèle raison-agir (ReAct) : L'agent explore le site, résout le CAPTCHA, gère la pagination et valide la qualité des données en temps réel sans une seule ligne de code manuel.
4. Traitement du langage naturel (NLP)
Le NLP, un sous-ensemble du ML, vous permet d'effectuer des tâches telles que l'analyse de sentiment, le résumé de contenu et la reconnaissance d'entités. Il est nécessaire de tirer des enseignements des données scrapées.
Par exemple, si vous avez extrait une quantité significative de données d'avis de produits, vous devez déterminer le ton émotionnel derrière chaque mot, tel que positif, négatif ou neutre. L'analyse de sentiment vous permet de catégoriser les données extraites comme positives ou négatives. Cela aide les entreprises à répondre aux préoccupations des clients et à améliorer leurs offres.
Citer cette recherche
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{karatas2026,
author = {Karatas, Gulbahar},
title = {{Meilleurs 12+ Agents de Web Scraping IA (Gratuit & Payant)}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/ai-web-scraping}},
note = {AIMultiple. Consulté le 5 Juin 2026}
}
Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.