Calidad de los datos de IA en: Desafíos y mejores prácticas
La mala calidad de los datos retrasa la implementación exitosa de proyectos de IA y aprendizaje automático. 1 Incluso los algoritmos de IA más avanzados pueden arrojar resultados erróneos si los datos subyacentes son de baja calidad.
Descubra la importancia de la calidad de los datos en la IA, los desafíos a los que se enfrentan las organizaciones y las mejores prácticas para garantizar datos de alta calidad:
¿Qué importancia tiene la calidad de los datos en la IA?
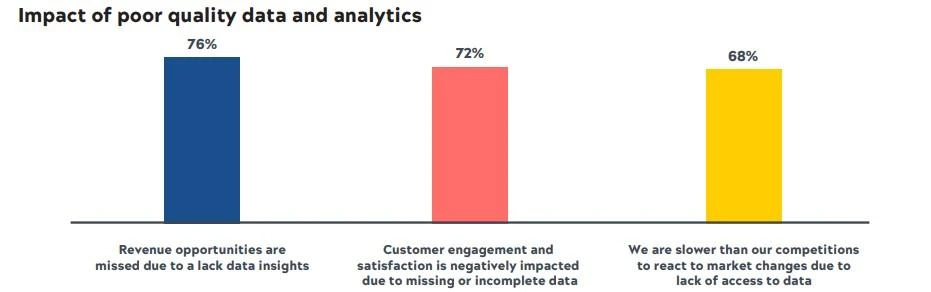
La calidad de los datos es fundamental para la inteligencia artificial , ya que influye directamente en el rendimiento, la precisión y la fiabilidad de los modelos de IA. Los datos de alta calidad permiten a los modelos realizar mejores predicciones y obtener resultados más fiables. El impacto de la mala calidad de los datos en la IA se ilustra en la Figura 1.
Figura 1: Impacto de la mala calidad de los datos y análisis.
Fuente: SnapLogic 2
Abordar los sesgos en los datos es fundamental para garantizar su calidad. Esto evita la perpetuación y amplificación de los sesgos en los resultados generados por la IA, lo que ayuda a minimizar el trato injusto hacia determinados grupos o individuos.
Además, un conjunto de datos diverso y representativo mejora la capacidad de un modelo de IA para generalizar bien en diferentes situaciones y entradas, lo que garantiza su rendimiento y relevancia en diversos contextos y grupos de usuarios.
Como afirma Andrew Ng, profesor de IA en la Universidad de Stanford y fundador de DeepLearning.AI: "Si el 80 por ciento de nuestro trabajo consiste en la preparación de datos, entonces garantizar la calidad de los datos es la tarea más importante para un equipo de aprendizaje automático".
¿Por qué es crucial evitar el problema de "si introduces datos erróneos, obtendrás resultados erróneos" para la calidad de los datos?
El principio «si introduces basura, obtienes basura» (GIGO, por sus siglas en inglés) es sencillo pero eficaz y subraya la importancia de la calidad de los datos de entrada. Esto significa que si los datos de entrada a un sistema, como un modelo o algoritmo de IA, son de mala calidad, inexactos o irrelevantes, la salida del sistema también será de mala calidad, inexacta o irrelevante.
Figura 2: Calidad y estándares de los datos: si se introducen datos erróneos, se obtienen resultados erróneos.
Fuente: Shakoor et al. 3
Este concepto cobra especial relevancia en el contexto de la IA, ya que los modelos de IA, incluidos los de aprendizaje automático y aprendizaje profundo, dependen en gran medida de los datos utilizados para el entrenamiento y la validación. Es probable que el modelo de IA produzca resultados poco fiables o sesgados si los datos de entrenamiento están sesgados, incompletos o contienen errores.
Para evitar el problema GIGO (Garbage In, Garbage Out), es fundamental garantizar que los datos utilizados en los sistemas de IA sean precisos, representativos y de alta calidad. Esto suele implicar la limpieza, el preprocesamiento y el aumento de datos , junto con el uso de métricas de evaluación sólidas para valorar el rendimiento de los modelos de IA.
¿Cuáles son los componentes clave de los datos de calidad en la IA?
Precisión: Los datos precisos son cruciales para los algoritmos de IA, ya que les permiten obtener resultados correctos y fiables. Los errores en la introducción de datos pueden llevar a decisiones incorrectas o conclusiones erróneas, lo que podría perjudicar a organizaciones e individuos.
Consistencia: Garantiza que los datos sigan un formato y una estructura estándar, lo que facilita su procesamiento y análisis eficientes. Los datos inconsistentes pueden generar confusión e interpretaciones erróneas, perjudicando el rendimiento de los sistemas de IA.
Integridad: Los conjuntos de datos incompletos pueden provocar que los algoritmos de IA pasen por alto patrones y correlaciones esenciales, lo que conlleva resultados incompletos o sesgados. Garantizar la integridad de los datos es fundamental para entrenar los modelos de IA de forma precisa y exhaustiva.
Actualidad: La actualidad de los datos es fundamental para el rendimiento de la IA. Los datos obsoletos pueden no reflejar el entorno o las tendencias actuales, lo que genera resultados irrelevantes o engañosos.
Relevancia: Los datos relevantes contribuyen directamente a la solución del problema, ayudando a los sistemas de IA a centrarse en las variables y relaciones más importantes. Los datos irrelevantes pueden saturar los modelos y provocar ineficiencias.
¿Cuáles son los retos para garantizar la calidad de los datos en la IA?
1-Recopilación de datos
A medida que los avances en IA benefician a sectores como las finanzas , la sanidad , la industria manufacturera y el entretenimiento, las organizaciones se enfrentan al reto de recopilar datos de diversas fuentes manteniendo la calidad. Muchas recurren a herramientas de extracción web para automatizar el proceso y garantizar que todos los datos cumplan con los mismos estándares.
2-Etiquetado de datos
Los algoritmos de IA se basan en datos etiquetados para su entrenamiento, pero el etiquetado manual consume mucho tiempo y es propenso a errores. Obtener etiquetas precisas que reflejen las condiciones del mundo real suele ser un desafío.
3-Almacenamiento y seguridad de datos
Garantizar la calidad de los datos implica protegerlos del acceso no autorizado y de una posible corrupción. Es fundamental que las organizaciones cuenten con un almacenamiento de datos seguro y fiable, pero esto puede resultar difícil.
4-Gobernanza de datos
Las organizaciones suelen tener dificultades para implementar marcos de gobernanza de datos que aborden eficazmente los problemas de calidad de los datos. La falta de una gobernanza de datos adecuada puede provocar datos aislados, inconsistencias y errores.
5- Envenenamiento de datos
El envenenamiento de datos es un ataque dirigido a sistemas de IA en el que los atacantes introducen información maliciosa o engañosa en el conjunto de datos. Estos datos contaminados pueden distorsionar el entrenamiento del modelo, lo que conlleva resultados poco fiables o incluso perjudiciales. Para mitigar este riesgo, es fundamental mantener la integridad de los datos mediante auditorías periódicas y la detección de anomalías.
6- Bucles de retroalimentación de datos sintéticos
Al retroalimentar los modelos de IA con datos generados por IA, se pueden crear bucles de retroalimentación que degradan su calidad. Por ejemplo, al usar repetidamente datos sintéticos, el modelo podría aprender patrones demasiado artificiales y alejados de las condiciones del mundo real. Esto puede provocar un rendimiento deficiente de los modelos con datos reales, lo que podría amplificar sesgos o errores. Es fundamental equilibrar los datos sintéticos y reales para mantener la robustez del modelo.
Estudios de casos reales
Caso práctico 1: Clínica Mayo – Calidad de los datos de imágenes médicas
La Clínica Mayo procesa millones de imágenes médicas anualmente, y mantener la calidad de los datos es fundamental para obtener diagnósticos precisos. 4
El desafío : Los datos de imágenes médicas presentaban problemas de calidad únicos, incluidos formatos de imagen inconsistentes, estándares de resolución variables entre diferentes escáneres, metadatos incompletos del paciente y la necesidad de mantener el cumplimiento de la HIPAA al tiempo que se garantizaba la utilidad de los datos para el entrenamiento de la IA.
La solución : Mayo Clinic implementó un marco integral de calidad de datos que incluye protocolos automatizados de estandarización de imágenes, sistemas de validación de metadatos que detectan información incompleta o inconsistente del paciente y un enfoque de aprendizaje federado que permite entrenar modelos de IA sin centralizar datos confidenciales del paciente.
Caso práctico 2: JPMorgan Chase – Calidad de los datos de detección de fraude
JPMorgan Chase procesa miles de millones de transacciones al año y depende en gran medida de la IA para la detección de fraudes. La calidad de los datos de las transacciones influye directamente en la eficacia de sus sistemas de prevención de fraudes. 5
El reto : El banco se enfrentaba a dificultades con la calidad de los datos en tiempo real y con el manejo de datos estructurados y no estructurados a través de múltiples canales, incluyendo tarjetas de crédito, transferencias bancarias y banca móvil. Además, necesitaba equilibrar la sensibilidad en la detección de fraudes con la experiencia del cliente, adaptándose a patrones de fraude en constante evolución.
La solución : JPMorgan desarrolló un enfoque de calidad de datos de múltiples capas que incluye la validación de datos en tiempo real, que comprueba los datos de las transacciones según las reglas de calidad en cuestión de milisegundos; sistemas de detección de anomalías que identifican los problemas de calidad de los datos antes de que afecten a los modelos de fraude; y una monitorización continua del modelo que rastrea la desviación de datos y conceptos en los patrones de fraude.
Caso práctico 3: Walmart – Calidad de los datos del motor de recomendaciones
Walmart opera una de las plataformas de comercio electrónico más grandes del mundo. La calidad de los datos sobre el comportamiento del cliente, los catálogos de productos y los sistemas de inventario es fundamental para ofrecer recomendaciones pertinentes. 6
El reto : Walmart necesitaba integrar datos de más de 4700 tiendas físicas con el comportamiento de los clientes en línea, gestionar los datos del catálogo de productos con millones de referencias que cambian con frecuencia, manejar las variaciones estacionales y las rápidas fluctuaciones de inventario, y fusionar datos de empresas adquiridas como Jet.com con diferentes estándares de datos.
La solución : El gigante minorista implementó un marco unificado de calidad de datos con limpieza automatizada del catálogo de productos para estandarizar los atributos, descripciones y categorizaciones de los productos. Implementaron la validación de datos de inventario en tiempo real para garantizar que las recomendaciones reflejen la disponibilidad real de los productos y crearon sistemas de deduplicación de datos de clientes para generar perfiles de clientes unificados en todos los canales.
Buenas prácticas para garantizar la calidad de los datos en IA
1-Implementar políticas de gobernanza de datos
Un marco de gobernanza de datos debe definir estándares, procesos y roles relacionados con la calidad de los datos. Esto contribuirá a crear una cultura de calidad de datos y garantizará que las prácticas de gestión de datos se alineen con los objetivos de la organización.
Ejemplo de la vida real: Airbnb
Airbnb lanzó “Data University” para mejorar la alfabetización digital de sus empleados, ofreciendo cursos personalizados que integran los datos y las herramientas específicas de Airbnb. Desde su creación en el tercer trimestre de 2016, Data University ha incrementado la interacción con las herramientas internas de ciencia de datos de Airbnb, elevando los usuarios activos semanales del 30 % al 45 %.
Con la participación de más de 500 empleados, esta iniciativa subraya la importancia de alinear los esfuerzos de gobernanza de datos con los objetivos organizacionales, promoviendo una cultura de calidad de datos y toma de decisiones informada en toda la empresa. El programa demuestra cómo los marcos de gobernanza de datos personalizados pueden impulsar la competencia en el manejo de datos y fomentar la alineación con los objetivos de negocio.
2-Utilizar herramientas de calidad de datos
Las herramientas de calidad de datos pueden automatizar los procesos de limpieza, validación y monitorización de datos, garantizando que los modelos de IA tengan acceso constante a datos de alta calidad.
Ejemplo de la vida real: General Electric
Un ejemplo real y relevante del uso de herramientas de calidad de datos es la implementación por parte de General Electric (GE) de su estrategia de gobernanza y gestión de la calidad de datos, en particular dentro de su plataforma Predix para el análisis de datos industriales. Para respaldar su transformación digital e iniciativas de IA, GE invirtió en un conjunto robusto de herramientas de calidad de datos para mantener altos estándares de datos en todo su ecosistema de IoT industrial.
GE implementó herramientas automatizadas para la limpieza, validación y monitorización continua de datos, con el fin de gestionar los enormes volúmenes de datos generados por sus equipos industriales, como turbinas y motores a reacción. Estas herramientas permitieron a GE garantizar que los datos que alimentaban sus modelos de IA fueran precisos, consistentes y fiables, reduciendo la necesidad de intervención manual y facilitando la obtención de información en tiempo real basada en datos.
Ejemplos de soluciones para la calidad de los datos
Pandada AI , lanzada a principios de 2026, es una plataforma basada en inteligencia artificial para la limpieza y el análisis automatizados de datos. Puede procesar archivos de datos (CSV, hojas de cálculo de Excel, PDF e incluso imágenes) y generar informes y presentaciones analíticas estructuradas y compartibles. 7 La plataforma incluye funciones inteligentes de limpieza de datos (eliminación de duplicados, estandarización de formato, detección de valores faltantes) que corrigen automáticamente los problemas de datos, reduciendo el trabajo manual de preparación de datos. 8
Sieve es una plataforma de limpieza de datos de una startup de Y Combinator de la primavera de 2025 que combina el procesamiento impulsado por IA con la revisión humana opcional. 9 Proporciona una API y un complemento de Excel para la limpieza automatizada de datos, que dirige automáticamente cualquier problema señalado a operadores humanos para su validación. 10
3-Desarrollar un equipo de calidad de datos
La creación de un equipo especializado responsable de la calidad de los datos garantizará la supervisión y mejora continua de los procesos relacionados con los datos. Este equipo también podrá capacitar a otros empleados sobre la importancia de la calidad de los datos.
4. Colaborar con los proveedores de datos.
Establecer relaciones sólidas con los proveedores de datos y garantizar su compromiso con la calidad de los datos puede minimizar el riesgo de recibir datos de baja calidad.
5- Supervisar continuamente las métricas de calidad de los datos.
Medir y supervisar periódicamente las métricas de calidad de los datos puede ayudar a las organizaciones a identificar y abordar posibles problemas antes de que afecten al rendimiento de la IA.
¿Qué son los datos de IA?
Los datos de IA se refieren, en términos generales, a cualquier dato utilizado en el desarrollo o funcionamiento de sistemas de inteligencia artificial. Por consiguiente, esto incluye, entre otros, conjuntos de datos utilizados para entrenar modelos, datos de entrada en tiempo real para predicciones y datos sintéticos generados para complementar ejemplos del mundo real. Si bien no es un término técnico formal, "datos de IA" se usa comúnmente para describir la información que impulsa los sistemas de aprendizaje automático y aprendizaje profundo.
Preguntas frecuentes
Según un estudio de Gartner, la mala calidad de los datos le cuesta a las organizaciones un promedio de 12,9 millones de dólares anuales. Sin embargo, el verdadero costo va más allá del impacto financiero directo. La mala calidad de los datos lleva al fracaso de los proyectos de IA; informes del sector sugieren que hasta el 85 % de los proyectos de IA y aprendizaje automático no cumplen con sus expectativas iniciales, a menudo debido a problemas de calidad de los datos. Otros costos incluyen la pérdida de tiempo, ya que los científicos de datos dedican entre el 60 % y el 80 % de su tiempo a la limpieza de datos en lugar del desarrollo de modelos; la pérdida de oportunidades de ingresos por predicciones inexactas y malas experiencias de cliente; y los riesgos de cumplimiento normativo, especialmente en sectores regulados donde las fallas en la calidad de los datos pueden resultar en multas significativas.
Según investigaciones de fuentes del sector, entre el 70 % y el 85 % de los fracasos en proyectos de IA se deben a problemas relacionados con los datos, siendo la calidad de los mismos la principal causa. Un análisis de VentureBeat sobre implementaciones de IA reveló que el 87 % de los proyectos de ciencia de datos nunca llegan a producción, siendo la insuficiencia o la mala calidad de los datos la causa principal. Una encuesta de Dimensional Research reveló que el 96 % de las organizaciones se enfrentan a problemas de calidad de datos al entrenar modelos de IA. Estos fracasos se manifiestan de diversas maneras, como modelos que funcionan bien en las pruebas pero fallan en producción debido a la deriva de datos, resultados sesgados derivados de datos de entrenamiento no representativos y la incapacidad de escalar porque las canalizaciones de datos no pueden mantener la calidad a volúmenes de producción.
Aunque están estrechamente relacionadas, la calidad de los datos y la gobernanza de datos cumplen funciones distintas. La calidad de los datos se refiere a las características de los datos en sí, centrándose en si son precisos, completos, coherentes, oportunos y relevantes. Se trata del estado y la utilidad de los datos para el propósito previsto. La calidad de los datos se suele medir mediante métricas como las tasas de error, los porcentajes de completitud y el número de duplicados.
Por otro lado, la gobernanza de datos es el marco de políticas, procedimientos, roles y responsabilidades que garantizan una gestión adecuada de los datos en toda la organización. La gobernanza define quién es el propietario de los datos, quién puede acceder a ellos, cómo deben utilizarse, qué estándares deben cumplir y cómo se debe mantener su calidad.
La gobernanza de datos se define como la estructura organizativa y el conjunto de normas, mientras que la calidad de los datos es el resultado que se busca alcanzar. Una buena gobernanza permite una buena calidad, pero ambas son necesarias para el éxito de las iniciativas de IA. La gobernanza proporciona la estructura sostenible que garantiza que la calidad de los datos no sea una tarea puntual, sino una práctica continua.
Cita esta investigación
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Calidad de los datos de IA en: Desafíos y mejores prácticas}},
year = {2026},
month = mar,
howpublished = {\url{https://aimultiple.com/data-quality-ai}},
note = {AIMultiple. Retrieved Marzo 27, 2026}
}

Sé el primero en comentar
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.