Comparativa de las mejores herramientas de reconocimiento de imágenes
Evaluamos las configuraciones predeterminadas de API de Amazon Rekognition, Google Cloud Vision y Microsoft Azure IA Vision en 100 imágenes de 5 clases de objetos, y comparamos sus precios y cobertura de funciones.
Resultados de la evaluación comparativa de herramientas de reconocimiento de imágenes
Resumen del rendimiento con IoU=0.5
Se evaluaron las métricas de rendimiento de tres plataformas de reconocimiento de imágenes con un umbral de Intersección sobre Unión (IoU) de 0.5, comparando los valores de mAP, puntuación F1, recall y precisión.
El mAP es la métrica de evaluación principal a considerar para tareas de detección de objetos, ya que proporciona una medida integral de la calidad de detección en diferentes umbrales de confianza y clases de objetos.
Puede leer más sobre nuestra metodología de evaluación comparativa.
Precisión media (AP) por clase con IoU=0.5
Los tres servicios detectan personas de manera fiable, pero pierden precisión en equipos de protección, siendo los cascos los que muestran la caída más pronunciada.
Mientras que Amazon y Google muestran baja precisión en la detección de guantes y gorros, Microsoft Azure IA Vision alcanza un 0% de precisión en ambas categorías. Azure IA Vision no detecta objetos pequeños (menos del 5% de la imagen) o que estén muy próximos entre sí, lo que podría contribuir a la baja precisión observada en la detección de guantes y gorros.1
Ninguno de los servicios puede detectar mascarillas con éxito (0% de precisión), lo que pone de relieve una brecha crítica en sus capacidades de reconocimiento de objetos cuando se utilizan en configuraciones predeterminadas sin etiquetado personalizado.
Puede leer más sobre las limitaciones del reconocimiento de imágenes.
mAP en diferentes umbrales de IoU [0.5:0.05:0.95]
A medida que los umbrales de IoU se ajustan de 0.5 a 0.95, el mAP disminuye en los tres servicios, pero a ritmos diferentes. Amazon Rekognition se mantiene mejor en todo el rango, lo que sugiere una alineación de cuadros delimitadores más precisa que los otros dos servicios.
Factores potenciales que afectarían las diferencias de rendimiento
Enfoque del entrenamiento del modelo y alcance del producto
- Amazon Rekognition incluye capacidades específicas relacionadas con EPI, lo que probablemente se traduce en una mejor cobertura de entrenamiento y representaciones de características para objetos como cascos y guantes.
- Google Cloud Vision y Azure IA Vision priorizan tareas generales de comprensión de imágenes (por ejemplo, OCR, puntos de referencia, marcas, detección web), lo que hace que los EPI y objetos similares sean secundarios en sus objetivos de entrenamiento.
Configuración predeterminada de API y compensaciones entre precisión y recall
- Todos los servicios se evaluaron utilizando configuraciones predeterminadas, que normalmente priorizan una alta precisión para minimizar los falsos positivos.
- Esta elección de diseño conduce a puntuaciones de precisión altas en todos los proveedores, pero a un recall significativamente menor, particularmente para objetos menos prominentes.
Limitaciones en la detección de objetos pequeños
- Objetos como guantes, gorros y cascos a menudo ocupan una pequeña fracción de la imagen, lo que dificulta su detección fiable.
- Azure IA Vision, que según la documentación tiene un rendimiento inferior en objetos pequeños o muy próximos, muestra la degradación más pronunciada en estas categorías.
Taxonomía de etiquetas y mapeo de evaluación
- Las etiquetas específicas de cada proveedor tuvieron que mapearse a una taxonomía unificada de referencia.
- Es posible que se hayan excluido de la evaluación detecciones válidas que utilizaban etiquetas no coincidentes o más granulares.
Ausencia de detección de mascarillas
- Ninguno de los servicios evaluados expone etiquetas de objetos relacionadas con mascarillas en sus APIs predeterminadas.
- Por lo tanto, los tres obtuvieron un 0% de precisión para mascarillas.
Sensibilidad al IoU y calidad de localización
- Las diferencias de rendimiento aumentan en umbrales de IoU más altos, donde se requiere una alineación más estricta de los cuadros delimitadores.
- Amazon Rekognition mantiene un mAP relativamente más alto en estos umbrales, lo que sugiere una mayor precisión de localización.
Metodología de evaluación comparativa de herramientas de reconocimiento de imágenes
Probamos el rendimiento de estos proveedores en su versión estándar (es decir, sin etiquetado personalizado) en casos reales.
Utilizamos 100 imágenes. Escalamos las imágenes a 512×512 píxeles preservando las regiones esenciales que contienen instancias, ya que el conjunto de datos original comprendía dimensiones variables.
Queremos ejecutar esta prueba nuevamente sin que los proveedores entrenen sus soluciones en el conjunto de datos. Por lo tanto, no revelamos el conjunto de datos que utilizamos para esta evaluación comparativa.
Procesamos las respuestas de las APIs de los proveedores de servicios de la siguiente manera:
- mapeamos las etiquetas de los proveedores de servicios a las categorías de referencia definidas en la tabla anterior. Las etiquetas de los proveedores de servicios que no coincidían con estas etiquetas de referencia se excluyeron de la evaluación.
- normalizamos los formatos de cuadros delimitadores de los diferentes proveedores
- calculamos el IoU entre los cuadros predichos y los de referencia
- emparejamos las predicciones con la referencia basándonos en el umbral de IoU
- calculamos las métricas: precisión, recall, F1 y AP por categoría
- calculamos el mAP al estilo COCO utilizando umbrales de 0.5-0.95
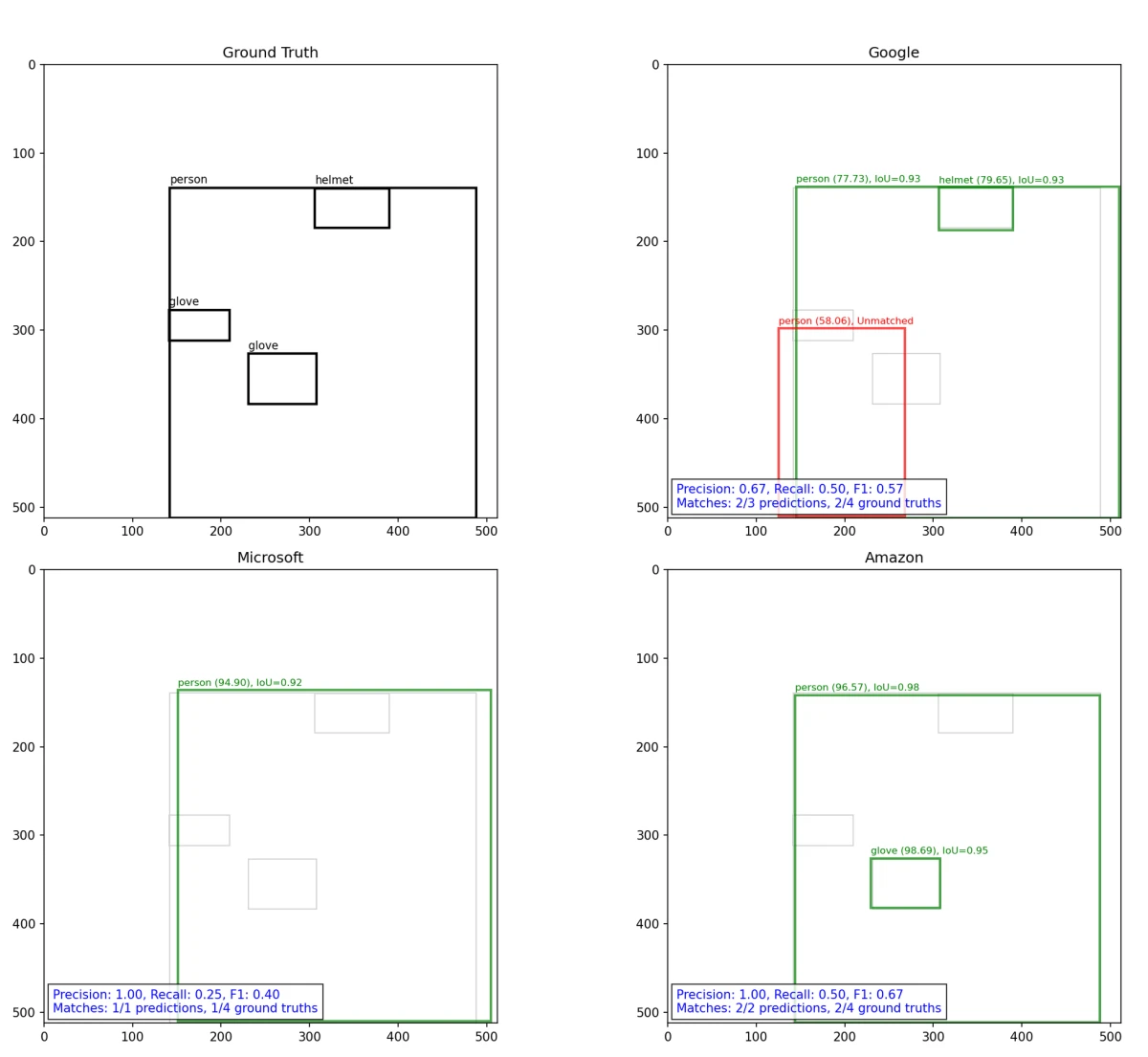
A continuación se muestra un ejemplo de cálculo de IoU, precisión, recall y F1 en la siguiente figura:
Métricas de evaluación comparativa
Precisión
La precisión mide la exactitud de las predicciones positivas realizadas por el modelo. En el reconocimiento de imágenes, para una clase dada (por ejemplo, «persona»), responde a la pregunta: «De todas las imágenes que el modelo etiquetó como que contenían una persona, ¿cuántas realmente la contenían?». Esto es crucial en escenarios donde los falsos positivos (etiquetar incorrectamente una imagen como positiva) son costosos.
Recall
El recall mide la exhaustividad de las predicciones positivas, respondiendo a: «De todas las imágenes que realmente contienen la clase, ¿cuántas identificó correctamente el modelo?». Esto es vital cuando pasar por alto una instancia positiva (falso negativo) es crítico.
Puntuación F1
La puntuación F1 es la media armónica de precisión y recall, proporcionando una medida equilibrada que es especialmente útil cuando hay una distribución desigual de clases (por ejemplo, pocas imágenes de cascos en comparación con imágenes sin cascos). Es una métrica única que captura tanto los falsos positivos como los falsos negativos.
mAP
El mAP, o Precisión Media Promedio (mean Average Precision), es una métrica utilizada principalmente en tareas de detección de objetos dentro del reconocimiento de imágenes. Evalúa la precisión del modelo en diferentes clases promediando la Precisión Media (AP) de cada clase. La AP en sí misma es el área bajo la curva de precisión-recall, que se genera variando el umbral de confianza para las detecciones.
Esta herramienta interactiva le permite comparar los resultados de detección entre proveedores utilizando imágenes de ejemplo del conjunto de datos. Utilice los botones superiores para seleccionar Amazon, Google, Microsoft o todos los proveedores. Active la referencia con la casilla de verificación. Navegue entre las imágenes de prueba utilizando los botones numerados de la izquierda. Los cuadros codificados por colores muestran cada detección con puntuaciones de confianza.
Las mejores APIs de reconocimiento de imágenes
Amazon Rekognition
Amazon Rekognition incluye APIs dedicadas a la detección de EPI junto con la detección general de objetos y rostros, lo que le proporciona una cobertura de etiquetas más amplia en clases como cascos y guantes que los otros dos servicios. Este alcance de producto es coherente con los resultados de AP por clase en la evaluación comparativa.
Sus APIs de imagen se dividen en dos grupos:
- Grupo 1 (identificación facial): CompareFaces, IndexFaces, SearchFaces, utilizados para verificación de identidad y búsqueda facial en colecciones de imágenes.
- Grupo 2 (análisis de contenido): DetectLabels (detección general de objetos), DetectModerationLabels, DetectText, RecognizeCelebrities, DetectPPE.
Se integra con el resto de AWS (S3 para almacenamiento, Lambda para procesamiento basado en eventos, SageMaker para entrenamiento de modelos personalizados).
Google Cloud Vision
Google Cloud Vision superó el 89% de precisión con IoU=0.5, el mismo nivel mínimo de precisión que los otros dos servicios, pero produjo un recall más bajo en objetos pequeños y equipos de protección. Su alcance de producto se inclina hacia la comprensión general de imágenes en lugar de la detección industrial: OCR, reconocimiento de puntos de referencia, identificación de logotipos y marcas, y Detección Web (comparación de una imagen con imágenes indexadas públicamente).
Capacidades principales:
- Localización de objetos y detección de etiquetas
- OCR para texto impreso y manuscrito en varios idiomas
- Detección de puntos de referencia, logotipos y celebridades
- Detección Web para búsqueda inversa de imágenes
- Entrenamiento de modelos personalizados a través de Vertex IA
Se integra con Cloud Storage, BigQuery y Google Workspace, y acepta una gama más amplia de formatos de archivo que Rekognition (JPEG, PNG, GIF, BMP, WEBP, RAW, ICO, PDF, TIFF).
Microsoft Azure IA Vision
Microsoft Azure IA Vision proporciona análisis de imágenes, OCR, subtitulado de imágenes y un servicio independiente de eliminación de fondo. Su documentación señala que el detector de objetos no maneja de manera fiable objetos pequeños o muy próximos, por lo que se posiciona más hacia la comprensión general de imágenes y la lectura de texto que hacia la detección detallada de objetos.
Las capacidades principales se dividen en dos grupos:
- Grupo 1 (detección de elementos visuales): etiquetado, rostros, detección de objetos, detección de marcas y puntos de referencia, recorte inteligente, OCR.
- Grupo 2 (salida consciente del lenguaje): descripción de imágenes, subtítulos densos, lectura completa (OCR de documentos).
Características diferenciadoras de los proveedores de servicios
Resumen de precios de API
Creación de modelos de visión personalizados
Las APIs alojadas como Amazon Rekognition, Google Cloud Vision y Microsoft Azure IA Vision devuelven predicciones de un conjunto fijo de etiquetas definido por el proveedor. Cuando una clase de objeto requerida no está en ese conjunto, o cuando la precisión en un dominio específico es demasiado baja, la alternativa es entrenar un modelo personalizado. Roboflow es un ejemplo que cubre este flujo de trabajo.
Roboflow
Roboflow es una plataforma de visión artificial que abarca la anotación de datos, el entrenamiento de modelos y el despliegue. Funciona con un modelo diferente al de las APIs de detección alojadas mencionadas anteriormente: los usuarios entrenan modelos con sus propios conjuntos de datos etiquetados y ejecutan la inferencia en su propio hardware, en lugar de llamar a un endpoint gestionado. Este es el camino que toman los equipos cuando las APIs predeterminadas en la nube no exponen etiquetas para una clase de objeto específica, como las mascarillas que obtuvieron un 0% de precisión en los tres servicios evaluados.
Roboflow incluye tres componentes principales:
- RF-DETR: un modelo basado en transformador en tiempo real para detección y segmentación de objetos, diseñado para entradas de cámara y vídeo en vivo.2
- AutoDistill: una herramienta que utiliza grandes modelos fundacionales para etiquetar automáticamente conjuntos de datos de imágenes sin anotación manual.3
- Inference: un paquete de despliegue compatible con múltiples backends (ONNX, TensorRT, PyTorch), con ejecución en GPUs, CPUs o dispositivos edge como NVIDIA Jetson a través de un servicio Dockerizado.4
Computación edge en el reconocimiento de imágenes
El reconocimiento de imágenes basado en la nube envía cada fotograma a un centro de datos remoto para su análisis. La computación edge ejecuta el modelo en el dispositivo que capturó el fotograma, de modo que el resultado (una etiqueta, una alerta, una señal) sale del dispositivo.
Cómo funciona la computación edge
En una configuración en la nube, las cámaras actúan como recolectoras de datos y transmiten fotogramas sin procesar hacia el servidor; el modelo reside en el centro de datos. En una configuración edge, el dispositivo ejecuta la red neuronal localmente y transmite la salida relevante: «persona detectada», «inventario bajo», «defecto encontrado».
Por qué es importante para el reconocimiento de imágenes
- Latencia: la inferencia local elimina el viaje de ida y vuelta a la nube, lo cual es importante para vehículos autónomos, robots de fabricación y cualquier sistema que deba actuar sobre la predicción en milisegundos.
- Privacidad: las imágenes no salen del dispositivo, lo cual es útil donde se aplican restricciones de residencia de datos o GDPR (imágenes médicas, CCTV en tiendas).
- Ancho de banda y coste: se cargan los metadatos, no el vídeo completo, lo que reduce los costes de red y de API en la nube para despliegues de gran volumen.
- Funcionamiento sin conexión: los dispositivos edge siguen funcionando cuando la red falla, lo cual es necesario para sistemas de seguridad y sitios industriales remotos.
Ejemplos reales de IA edge en el reconocimiento de imágenes
SDK en dispositivo Captur
El procesamiento en el dispositivo es la forma más común de IA edge en contextos móviles. Captur proporciona un SDK de verificación de imágenes en el dispositivo que ejecuta modelos de visión artificial localmente en dispositivos móviles en ~30ms, incluso sin conexión.5 El proveedor logístico GoBolt integró el SDK de Captur en su aplicación de conductor para la verificación de comprobante de entrega e informó de una reducción del 30% en reclamaciones de entrega no recibida en la primera semana.6
Ultralytics YOLO26
YOLO26 de Ultralytics es un modelo de visión artificial de código abierto diseñado para dispositivos edge y de bajo consumo. Su arquitectura completamente end-to-end y gratis de NMS elimina pasos de postprocesamiento como la supresión no máxima, reduciendo la latencia y mejorando la exportabilidad a hardware edge, a la vez que admite detección de objetos, segmentación, clasificación y estimación de pose dentro de una única familia de modelos.7
Transformadores de visión en el reconocimiento de imágenes
Las APIs de reconocimiento de imágenes evaluadas aquí utilizan detectores basados en CNN. Los Transformadores de Visión (ViTs) son una arquitectura alternativa que divide la imagen en parches de tamaño fijo (típicamente 16×16 píxeles) y procesa todos los parches en paralelo, lo que permite al modelo relacionar regiones distantes de la imagen desde la primera capa en lugar de construir ese contexto gradualmente a través de convoluciones apiladas.
Para la detección de objetos, esto es importante cuando la identidad de un objeto depende de la escena circundante (un gorro en una persona frente a un gorro en un estante). Las CNN capturan esto a través de convoluciones apiladas; los ViTs lo capturan a través de la atención en todos los parches a la vez.
Los tres servicios en la nube de esta evaluación comparativa ejecutan modelos basados en CNN en producción. Las arquitecturas híbridas CNN-Transformer están apareciendo en modelos de código abierto más recientes (por ejemplo, RF-DETR de Roboflow utiliza un backbone transformer DINOv2), pero las APIs de nube en producción aún no han migrado.
Modelos de transformador de visión para el reconocimiento de imágenes
- Google ViT: el Transformador de Visión original, entrenado en ImageNet para clasificación de imágenes. Disponible en Hugging Face con pesos pre-entrenados.
- Swin Transformer: utiliza un mecanismo de ventana desplazada para capturar tanto el detalle global como el local, utilizado para detección y segmentación.
- DINOv2 (Meta): modelo auto-supervisado entrenado sin etiquetas manuales, que produce embeddings de imagen de propósito general.
- Segment Anything Model (SAM): segmentador basado en ViT que puede aislar objetos para los que no ha sido entrenado.
Casos de uso del software de reconocimiento de imágenes
En el panorama digital actual, las tecnologías de visión artificial y procesamiento de imágenes han transformado la manera en que las empresas aprovechan los datos visuales. Los algoritmos avanzados de clasificación de imágenes permiten herramientas sofisticadas de reconocimiento de imágenes que están remodelando las operaciones en todas las industrias.
Estas tecnologías de reconocimiento de imágenes combinan potentes enfoques de entrenamiento de modelos con interfaces intuitivas que permiten a los usuarios automatizar tareas visuales complejas. Desde soluciones de visión personalizadas para necesidades empresariales específicas hasta sistemas de reconocimiento facial para seguridad, estas herramientas pueden identificar patrones, objetos y características dentro de las imágenes.
Inspección visual
El reconocimiento de imágenes permite la inspección visual automatizada en múltiples industrias. Estos sistemas identifican objetos, detectan características y verifican la compatibilidad analizando datos visuales.
Por ejemplo, Chamberlain Group implementó Amazon Rekognition en su aplicación myQ, permitiendo a los usuarios capturar automáticamente imágenes del abre-puertas de su garaje para comprobar la compatibilidad. Esta solución simplificada reemplazó un proceso manual complejo y aumentó significativamente las tasas de conexión de usuarios.8
Procesamiento de documentos
La tecnología de OCR extrae texto de imágenes y documentos, automatizando la entrada de datos en múltiples idiomas. Los sistemas modernos pueden procesar texto manuscrito y diseños complejos, transformando flujos de trabajo basados en papel y haciendo que los documentos sean buscables.
Por ejemplo, el grupo asegurador francés LSA Courtage utiliza Google Cloud Vision API para reconocer texto de permisos de conducir y documentos de registro. Esta implementación de OCR redujo el tiempo de procesamiento de documentos en un 45% por página y aumentó la productividad de los suscriptores en un 20%, permitiéndoles procesar 1,500 documentos diarios.9
Puede consultar nuestra evaluación comparativa de OCR para ver la precisión de las diversas herramientas de OCR para diferentes tipos de documentos.
Monitorización agrícola
Los agricultores utilizan imágenes de drones con reconocimiento de imágenes para monitorizar la salud de los cultivos, detectar enfermedades y optimizar el riego. Al identificar áreas de estrés en los cultivos antes de que aparezcan síntomas visibles, los agricultores pueden intervenir temprano y reducir el uso de recursos.
Por ejemplo, Project FarmBeats de Microsoft (ahora Azure Data Manager for Agriculture) utiliza sensores, drones y aprendizaje automático para permitir la agricultura basada en datos en entornos con limitaciones de energía y conectividad a internet. El sistema ayuda a aumentar la productividad agrícola y reducir costes combinando datos visuales con el conocimiento de los agricultores sobre sus tierras.10
Seguridad y vigilancia
Los sistemas de seguridad utilizan reconocimiento facial y detección de objetos para identificar actividades, controlar el acceso y localizar personas. Estos sistemas monitorizan transmisiones de vídeo y alertan al personal sobre amenazas. Por ejemplo, Sun Finance utiliza Amazon Rekognition para verificar la identidad de los clientes comparando selfies con documentos de identidad, agilizando la verificación y previniendo el fraude mientras expande la inclusión financiera.11
Moderación de contenido
Las plataformas de redes sociales utilizan el reconocimiento de imágenes para filtrar contenido inapropiado como desnudos, violencia o imágenes gráficas de las subidas de los usuarios. La generación de subtítulos puede añadir una segunda capa al describir el contexto de la imagen que los clasificadores a nivel de píxel pasan por alto, por ejemplo, detectando símbolos de odio en el fondo de una foto por lo demás benigna. Según AWS, el filtrado automático reduce típicamente el volumen que los moderadores humanos necesitan revisar al 1–5% del total.12
Por ejemplo, CoStar Group utiliza Amazon Rekognition para la moderación de contenido y el análisis de vídeo de aproximadamente 150,000 subidas diarias de imágenes y vídeos a su plataforma de bienes raíces comerciales. Esta solución de moderación de contenido analiza las imágenes, clasifica el contenido, detecta material no deseado y aprovecha la tecnología de subtitulado de imágenes para comprender el contexto, ahorrando tiempo y garantizando el cumplimiento normativo y datos de alta calidad.13
Puede leer más sobre las aplicaciones del reconocimiento de imágenes.
Limitaciones de la tecnología de reconocimiento de imágenes
Reducción de detalle en objetos pequeños
Cuando los objetos aparecen pequeños en las imágenes, contienen menos píxeles, lo que resulta en datos visuales limitados. Además, las CNN tienden a perder detalles finos importantes durante el procesamiento a través de capas de reducción de muestreo, lo que dificulta significativamente las capacidades de detección.
Detecciones omitidas
Los sistemas de reconocimiento de imágenes suelen favorecer los objetos más grandes tanto durante las fases de entrenamiento como de análisis, lo que resulta en una mayor frecuencia de objetos pequeños no detectados o falsos negativos.
Interferencia del fondo
Los objetos más pequeños son más vulnerables a ser oscurecidos por el ruido visual, el desorden del fondo o elementos superpuestos, lo que dificulta su identificación precisa. Incluso la oclusión parcial puede afectar desproporcionadamente a los objetos pequeños, ya que tienen menos área distinguible de partida.
Variabilidad de escala
Los objetos que aparecen a diferentes distancias o escalas plantean dificultades para los modelos no diseñados específicamente para detectar detalles finos en tamaños de objeto variables.
Demandas computacionales
Las técnicas para mejorar la detección de objetos pequeños, como la extracción de características a múltiples escalas o las entradas de mayor resolución, requieren más potencia de procesamiento, lo que limita su aplicabilidad en tiempo real.
Sesgo de entrenamiento
Los conjuntos de datos a menudo subrepresentan los objetos pequeños o carecen de anotaciones suficientes para ellos, lo que reduce la generalización del modelo a tales casos en escenarios del mundo real.
Preguntas frecuentes
El software de reconocimiento de imágenes es un tipo de tecnología de visión artificial que utiliza algoritmos de aprendizaje automático para analizar datos no estructurados como imágenes digitales y datos de vídeo. Va más allá de identificar objetos específicos; los sistemas avanzados apuntan a la comprensión de la escena, interpretando el contexto y las relaciones dentro de una imagen para proporcionar un análisis más completo. Esto permite a las computadoras ver y clasificar la información visual de manera efectiva.
Ningún software de reconocimiento de imágenes o software de visión artificial es universalmente el mejor. La elección ideal entre las tecnologías de reconocimiento de imágenes depende de sus necesidades específicas. Considere factores como la precisión requerida, el tipo de tareas que necesita realizar (como detección de objetos o OCR, e incluso considerar si necesita integrarse con procesamiento de lenguaje natural para tareas que combinan la comprensión de imágenes con el análisis de texto), la facilidad de uso, la escalabilidad, el presupuesto, las opciones de personalización y la experiencia técnica de su equipo. Probar diferentes opciones es la mejor manera de encontrar las tecnologías de reconocimiento de imágenes que mejor proporcionen las capacidades de visión artificial que necesita para su aplicación.
Aunque el reconocimiento de imágenes ha mejorado significativamente, la precisión no está garantizada. Los factores que afectan al rendimiento incluyen la calidad de la imagen (iluminación, resolución), la complejidad de la escena, las variaciones en la apariencia de los objetos y la calidad de los datos de entrenamiento utilizados para los algoritmos de aprendizaje profundo. Lograr una comprensión robusta de la escena y detectar con precisión objetos específicos puede ser un desafío en datos visuales complejos o con ruido.
Cita este benchmark
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Comparativa de las mejores herramientas de reconocimiento de imágenes}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/image-recognition-software}},
note = {AIMultiple. Recuperado el 17 de Junio de 2026}
}
Sé el primero en comentar
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.