Benchmark de Reranker: Comparación de los 8 Mejores Modelos
Evaluamos 8 modelos de reranking en ~145k reseñas de Amazon en inglés para medir cuánto mejora una etapa de reranking la recuperación densa. Recuperamos los 100 candidatos principales con multilingual-e5-base, los reordenamos con cada modelo y evaluamos los 10 mejores resultados frente a 300 consultas, cada una haciendo referencia a detalles concretos de su reseña original. El mejor reranker elevó Hit@1 del 62.67 % al 83.00 % (+20.33pp).
Resultados del benchmark de reranker
Métricas explicadas:
ΔHit@1 / ΔHit@10 muestra la mejora sobre la línea base (sin reranker) en puntos porcentuales (pp). Por ejemplo, +20.33pp significa que el reranker mejoró Hit@1 en 20.33 puntos porcentuales en comparación con el 62.67 % de la línea base.
Hit@K mide si aparece alguna reseña con el product_id correcto en los resultados top-K. La verdad fundamental es el product_id de la reseña que generó la consulta. Si una reseña diferente del mismo producto aparece en el top-K, eso cuenta como un acierto. Hit@1 es la prueba más estricta: ¿es el resultado principal del producto correcto? Hit@10 es más indulgente: ¿está el producto correcto en algún lugar de los primeros 10 resultados?
MRR@10 (Mean Reciprocal Rank) promedia 1/rango del primer resultado correcto en todas las consultas. Si el primer product_id coincidente está en el rango 1, la puntuación es 1.0. En el rango 2, es 0.5. En el rango 10, es 0.1. Esto recompensa a los modelos que colocan el producto correcto lo más alto posible.
nDCG@10 (Normalized Discounted Cumulative Gain) evalúa las posiciones de todas las reseñas coincidentes en el top-10, no solo la primera. Si el mismo producto tiene varias reseñas en el conjunto de candidatos y varias aparecen en el top-10, nDCG acredita cada una según su posición. En la práctica, la mayoría de los productos tienen solo 1-2 reseñas en los 100 candidatos principales, por lo que nDCG y MRR siguen una trayectoria muy similar.
Recall@10 mide la fracción de reseñas coincidentes (mismo product_id) en el top-10 de todas las reseñas coincidentes en el conjunto completo de candidatos (top-100). Si un producto tiene 3 reseñas en el top-100 y el reranker pone 2 de ellas en el top-10, Recall@10 es 2/3 para esa consulta. Como la mayoría de los productos tienen pocas reseñas duplicadas en el conjunto de candidatos, Recall@10 y Hit@10 son casi idénticos en este benchmark.
Desglose de latencia
La latencia de reranking mide el tiempo que tarda cada cross-encoder en puntuar 100 documentos candidatos frente a la consulta. El tiempo de búsqueda vectorial (~20ms) se excluye ya que permanece constante en todas las ejecuciones y es independiente del reranker.
Métricas de latencia explicadas:
Rerank es el tiempo que tarda el cross-encoder en puntuar los 100 documentos candidatos frente a la consulta. Aquí es donde los modelos difieren: un solo paso hacia adelante es rápido, mientras que la decodificación autoregresiva es lenta.
P95 es la latencia total en el percentil 95. Algunas consultas tienen textos de reseñas más largos, lo que aumenta el tiempo de tokenización y puntuación. P95 muestra el peor caso que debe esperar para el 95 % de las consultas.
Hallazgos clave
Un modelo de 149M iguala a un modelo de 1.2B
gte-reranker-modernbert-base tiene 149M de parámetros, nemotron-rerank-1b tiene 1.2B. Ambos alcanzaron un Hit@1 del 83.00 % en inglés. La arquitectura ModernBERT es 8 veces más pequeña y ofrece una precisión principal idéntica.
Esto no significa que el tamaño del modelo sea irrelevante. nemotron se lleva una ligera ventaja en MRR@10 (0.8514 vs 0.8483) y Hit@10 (88.33 % vs 88.00 %), lo que significa que clasifica documentos relevantes ligeramente mejor en todo el top-10. Pero para la mayoría de las aplicaciones donde lo que importa es obtener el primer resultado correcto, el modelo de 149M es suficiente.
El modelo más grande no es el mejor
qwen3_reranker_4b tiene 4B de parámetros y tarda más de un segundo por consulta. Alcanza un Hit@1 del 77.67 %, ubicándose en cuarto lugar detrás de nemotron (1.2B), gte_modernbert (149M) y jina (560M). Pagas 4.5 veces la latencia de nemotron por 5.3 puntos porcentuales menos de precisión.
La arquitectura de qwen3 utiliza modelado de lenguaje causal con un enfoque de logit de sí/no. El modelo lee el par consulta-documento y devuelve la probabilidad de "sí, esto es relevante". Esto es conceptualmente limpio, pero la inferencia es costosa debido a la sobrecarga de la decodificación autoregresiva. Los modelos SequenceClassification (gte_modernbert, bge) y el enfoque de plantilla de prompt de nemotron procesan el par en un solo paso hacia adelante, lo que es fundamentalmente más rápido.
Jina ofrece el mejor equilibrio entre velocidad y precisión
jina_reranker_v3 alcanza un Hit@1 del 81.33 % a 188ms. nemotron alcanza un 83.00 % a 243ms. Si necesita una latencia total inferior a 200ms por consulta, Jina es el único modelo de primer nivel que lo ofrece. La brecha de 1.67 puntos porcentuales puede no justificar los 55ms adicionales en un sistema de producción que sirve miles de solicitudes por segundo.
Un reranker empeora los resultados
mxbai_rerank_xsmall (70M de parámetros) obtiene un Hit@1 del 64.67 %. La línea base sin ningún reranker obtiene un 62.67 %. La mejora es de solo 2 puntos porcentuales, lo que está dentro del ruido para 300 consultas. Con 70M de parámetros, el modelo carece de la capacidad para juzgar de manera confiable la relevancia consulta-documento en textos más largos o más matizados.
Un reranker no es automáticamente beneficioso. Pruébalo con tus datos reales antes de implementarlo.
El recuperador establece el límite
Todos los mejores rerankers convergen alrededor del 87-88 % de Hit@10. Este límite proviene del recuperador. Si multilingual-e5-base no coloca el documento correcto en los 100 candidatos principales, ningún reranker puede recuperarlo. El 12 % restante de consultas donde falla cada reranker representa casos donde el recuperador denso simplemente perdió el documento relevante por completo.
Mejorar más allá de este límite requiere un mejor recuperador, un conjunto de candidatos más grande o ambos. Probamos 250 candidatos principales y encontramos casi ninguna mejora sobre los 100 principales, lo que significa que e5_base agota sus candidatos útiles mucho antes del rango 250.
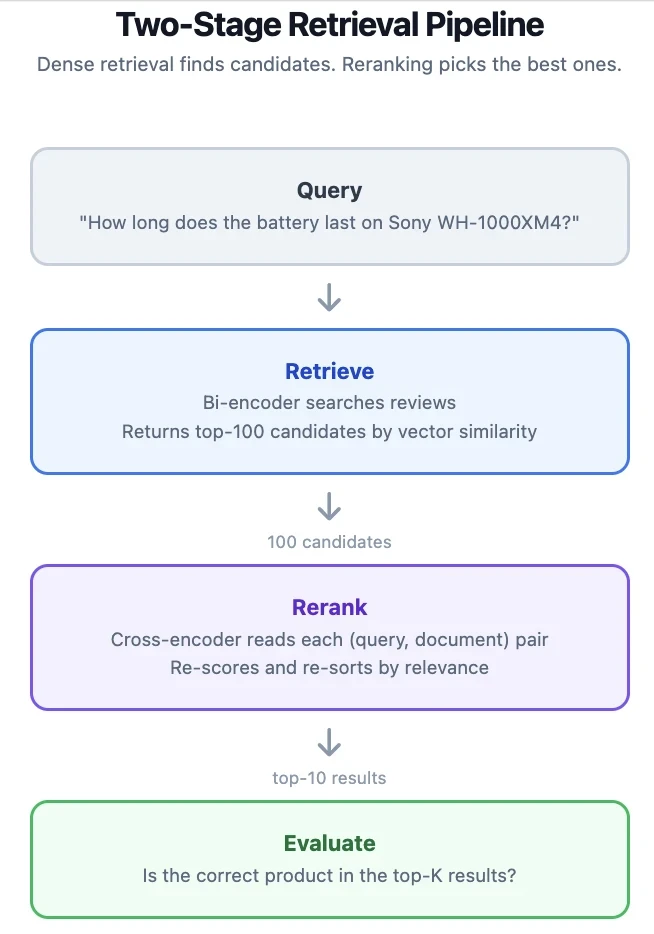
Cómo funcionan los rerankers
Un recuperador denso (bi-encoder) codifica consultas y documentos de forma independiente en vectores. La recuperación es una búsqueda de vecinos más cercanos sobre estos vectores. Esto es rápido porque solo codificas la consulta en el momento de la búsqueda, pero el modelo nunca ve la consulta y el documento juntos, por lo que puede perder señales de relevancia matizadas.
Un reranker (cross-encoder) toma un par consulta-documento como una sola entrada. El modelo atiende ambos textos conjuntamente, captando relaciones que la codificación independiente pierde. El costo es que debes ejecutar el modelo una vez por candidato, por lo que solo puedes permitirte puntuar un conjunto pequeño.
Arquitecturas en este benchmark
Probamos cuatro arquitecturas de cross-encoder diferentes:
Los modelos SequenceClassification (bge_base, bge_v2_m3, mxbai_xsmall, gte_modernbert) toman un [query, document] par como entrada y devuelven una puntuación de logit única. Este es el enfoque más simple y común.
Nemotron utiliza un formato de plantilla de prompt: "question:{q} passage:{p}". La entrada parece texto plano en lugar de un par estructurado, pero el modelo aún devuelve una única puntuación de relevancia a través de SequenceClassification. El preentrenamiento del LLM (basado en Llama) le otorga una fuerte comprensión del lenguaje.
Los rerankers de Qwen3 utilizan modelado de lenguaje causal. El modelo lee el par y genera un juicio de sí/no. La puntuación es log P(sí) / (P(sí) + P(no)). Esto requiere toda la maquinaria autoregresiva, lo que explica la mayor latencia.
Jina v3 utiliza un API personalizado (model.rerank()) que maneja la tokenización y la puntuación internamente. La arquitectura subyacente utiliza atención cruzada, pero la interfaz abstrae los detalles.
Metodología del benchmark de reranker
- GPU: NVIDIA H100 PCIe 80GB a través de Runpod
- Base de datos vectorial: Qdrant 1.12.0 (binario local), distancia coseno
- Recuperador: multilingual-e5-base (768-dim). Prefijo de consulta:
"query: ", prefijo de documento:"passage: " - Software: transformers 5.2.0, PyTorch 2.8.0, CUDA 12.8.1
- Conjunto de datos: Subconjunto en inglés de Amazon Reviews Multi (Kaggle).1 ~145k reseñas después de filtrar por un mínimo de 100 caracteres. Cada reseña tiene un product_id, texto de reseña y calificación por estrellas.
- Generación de consultas: Claude Sonnet 4.6 a través de OpenRouter. 300 consultas en inglés (5 tipos: fácticas, de opinión, de uso, resolución de problemas, comparación de características). Cada consulta debe hacer referencia a detalles específicos de su reseña original; las preguntas genéricas (puntuación de especificidad < 4/5) se filtran.
- Formato de documento:
"Review Title: {title}\nReview: {body}" - Pipeline: Recuperar los 100 candidatos principales con multilingual-e5-base, reordenar con cross-encoder, devolver los 10 principales. La línea base omite el reranking y devuelve directamente los 10 principales del recuperador.
- Verdad fundamental: solo coincidencia exacta de product_id. Sin respaldo de similitud de coseno. Sin crédito parcial por productos semánticamente similares.
- Variable controlada: Solo el modelo de reranker cambia entre experimentos. Recuperador, recuento de candidatos, conjunto de consultas y criterios de evaluación son idénticos en todas las ejecuciones.
- Sin fine-tuning: Todos los modelos evaluados zero-shot con los pesos predeterminados de HuggingFace.
- Latencia: Reranking (puntuación de cross-encoder de 100 candidatos). Medido por consulta en GPU.
Modelos probados
Limitaciones
Este benchmark utiliza un solo recuperador (multilingual-e5-base). Un recuperador diferente produciría conjuntos de candidatos diferentes y podría cambiar las clasificaciones de los rerankers. Los resultados reflejan qué tan bien funciona cada reranker con este recuperador específico, no la calidad del reranker de forma aislada.
Probamos en reseñas de productos en inglés de Amazon. El rendimiento en otros dominios (artículos científicos, documentos legales, código) u otros idiomas será diferente.
El recuento de candidatos está fijo en 100. Algunos rerankers podrían clasificar de manera diferente con 20 o 200 candidatos. Probamos 250 candidatos y encontramos una mejora insignificante, lo que sugiere que 100 es suficiente para e5_base, pero otros recuperadores pueden comportarse de manera diferente.
300 consultas es un tamaño de muestra moderado. Los tres mejores modelos (nemotron, gte_modernbert, jina) están separados por menos de 2 puntos porcentuales. Con un conjunto de consultas más grande, estas clasificaciones podrían cambiar. La brecha entre el primer nivel y el último nivel (20+ puntos porcentuales) es robusta.
Conclusión
Los rerankers funcionan. El mejor modelo en este benchmark eleva Hit@1 del 62.67 % al 83.00 % (+20.33pp), lo que significa que 20 de cada 100 consultas que anteriormente devolvían el documento incorrecto primero ahora devuelven el correcto. Eso es una ganancia significativa para un componente que agrega menos de 250ms de latencia.
El hallazgo más útil es que el tamaño del modelo no determina la calidad del reranker. gte-reranker-modernbert-base con 149M de parámetros iguala a nemotron-rerank-1b con 1.2B en Hit@1. El modelo Qwen3 de 4B de parámetros termina en cuarto lugar. Si estás eligiendo un reranker para un sistema de producción, comienza con los modelos más pequeños. Es posible que nunca necesites los más grandes.
Para aplicaciones sensibles a la latencia, jina-reranker-v3 es la opción más sólida por debajo de 200ms. Para la máxima precisión sin restricción de latencia, nemotron-rerank-1b y gte-reranker-modernbert-base comparten el primer lugar. Para equipos con un presupuesto de GPU, gte-modernbert es el claro ganador: la misma precisión que el modelo de 1.2B a una fracción de la huella de memoria.
Un patrón se mantuvo en todos los experimentos: el recuperador establece el límite. Ningún reranker empujó Hit@10 por encima del 88 %, porque el 12 % restante de documentos correctos nunca apareció en los 100 candidatos principales. Invertir en un mejor recuperador probablemente arrojará mayores ganancias que cambiar entre los tres mejores rerankers.
Lectura adicional
Explora otros benchmarks de RAG, como:
- Modelos de Embedding: OpenAI vs Gemini vs Cohere
- Top 16 Modelos de Embedding de Código Abierto para RAG
- Mejor Base de Datos Vectorial para RAG: Qdrant vs Weaviate vs Pinecone
- Benchmark de RAG Agéntico: Enrutamiento de múltiples bases de datos y generación de consultas
- Modelos de Embedding Multimodal: Apple vs Meta vs OpenAI
- RAG Híbrido: Aumentando la precisión de RAG
- Top 10 Modelos de Embedding Multilingüe para RAG
Cita este benchmark
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{sari2026,
author = {Sarı, Ekrem},
title = {{Benchmark de Reranker: Comparación de los 8 Mejores Modelos}},
year = {2026},
month = feb,
howpublished = {\url{https://aimultiple.com/rerankers}},
note = {AIMultiple. Recuperado el 26 de Febrero de 2026}
}Resultados y marcas de tiempo de 9 puntos de datos. Descargue los datos utilizados en este artículo como un archivo ZIP que contiene un archivo CSV y un README.

Sé el primero en comentar
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.