Benchmark de Web Crawler para Alimentar Sitios Web a la IA
Realizamos un benchmark de cuatro APIs de rastreo en tres dominios de dificultad variable a tres niveles de profundidad máxima (5, 10, 20) con un límite de 1.000 páginas, midiendo la cobertura del rastreo, el tiempo de ejecución, el descubrimiento de enlaces, la calidad de los enlaces en markdown y la precisión de la extracción de títulos.
Si tu objetivo es:
- Convertir páginas web en datos estructurados, consulta nuestra guía sobre web scraping.
- Rastrear sitios web completos, sigue leyendo.
Benchmark de web crawlers
Puedes leer nuestra metodología de benchmark.
Páginas promediamente rastreadas vs costo por 1.000 páginas
Páginas rastreadas en dominios por profundidad máxima
Firecrawl consistentemente rastreó alrededor de 100 páginas en theregister.com independientemente de la profundidad máxima, aproximadamente 90 páginas en entrepreneur.com en todos los niveles de profundidad, y solo alrededor de 30 páginas en amazon.com, probablemente debido a la protección agresiva de bots de Amazon. Cabe destacar que aumentar la profundidad máxima no tuvo prácticamente ningún impacto en la cantidad de páginas que Firecrawl pudo rastrear en ningún dominio.
Apify demostró el rendimiento más consistente, alcanzando el límite máximo de rastreo de 1.000 páginas en cada dominio y en cada nivel de profundidad sin ninguna dificultad aparente, incluso en sitios altamente protegidos como Amazon.
Cloudflare mostró un comportamiento inconsistente en las pruebas:
- En theregister.com a profundidad máxima 5, solo rastreó 100 páginas, pero a profundidad máxima 20 alcanzó casi 1.000 páginas.
- Como observamos en pruebas anteriores, Cloudflare ocasionalmente solo rastrea 1 página y luego termina el trabajo por completo. Confirmamos que esto no es un problema de caché (la caché estaba desactivada) y probamos con tiempos de espera entre ejecuciones de hasta 1 minuto, pero el comportamiento persistió. A profundidad máxima 10 en theregister.com, ocurrió exactamente este problema: Cloudflare solo rastreó 1 página antes de detenerse.
- En entrepreneur.com, Cloudflare rastreó 780 páginas a profundidad 5, aumentó a 885 a profundidad 10, pero luego cayó bruscamente a solo 172 páginas a profundidad 20. Esta caída puede estar relacionada con el programador de rastreo de Cloudflare que desprioriza o agota el tiempo de espera de cadenas de enlaces más profundas, o podría reflejar un límite de concurrencia interno que hace que el trabajo termine prematuramente cuando el frente de rastreo crece demasiado en profundidades más altas.
- En amazon.com, Cloudflare rastreó 905 páginas a profundidad 5, pero el número disminuyó constantemente a medida que aumentaba la profundidad máxima, cayendo a 809 a profundidad 10 y 795 a profundidad 20, lo que sugiere que las configuraciones de rastreo más profundas pueden hacer que Cloudflare gaste más tiempo en la sobrecarga de descubrimiento de enlaces en lugar de en la recuperación real de páginas.
Nimble alcanzó o se acercó al límite de 1.000 páginas en theregister.com en todos los niveles de profundidad (1.000 / 1.000 / 999). En entrepreneur.com, rastreó 1.000 páginas a profundidad 5 pero mostró ligeras caídas en profundidades más altas (896 a profundidad 10, 983 a profundidad 20), posiblemente debido a que su tiempo de espera de 7 horas se alcanzó antes de completar el rastreo completo en niveles más profundos; todas las ejecuciones de Nimble terminaron con un estado de tiempo de espera. Amazon resultó ser más desafiante:
- A profundidad 5 solo logró 319 páginas, pero a profundidad 10 saltó a 988 páginas, luego cayó a 906 a profundidad 20
- Esta inconsistencia probablemente refleja la combinación de los mecanismos de protección de bots de Amazon y las limitaciones de tiempo de espera de Nimble, donde los rastreos más profundos tardan más en procesar cada página y pueden encontrar más desafíos anti-bots en el camino
Tiempo de ejecución en dominios por profundidad máxima
Firecrawl fue el proveedor más rápido en todos los dominios, completando los rastreos en menos de 5 minutos, típicamente entre 75-265 segundos. Esta velocidad viene a costa de la cobertura, ya que Firecrawl también rastreó la menor cantidad de páginas. Esencialmente, termina rápidamente porque se detiene temprano.
Apify tardó alrededor de 2.200-2.400 segundos (~40 minutos) en theregister.com independientemente de la profundidad. En entrepreneur.com y amazon.com, los tiempos de ejecución fueron significativamente más largos, de 8.300-15.900 segundos (2-4 horas), reflejando las estructuras de sitios más grandes y complejas. A pesar de los tiempos más largos, Apify consistentemente alcanzó el límite de 1.000 páginas, lo que lo convierte en el más confiable en términos de relación cobertura-tiempo.
Cloudflare mostró tiempos que reflejan sus conteos de rastreo inconsistentes:
- En theregister.com a profundidad 10, completó en solo 1 segundo, porque solo rastreó 1 página antes de detenerse.
- En entrepreneur.com a profundidad 20, terminó en 10 segundos después de rastrear solo 172 páginas.
- Cuando Cloudflare completa un rastreo completo, los tiempos oscilan entre 3.500 y 25.200 segundos.
- A medida que aumenta la profundidad máxima, Cloudflare parece priorizar llegar a páginas más profundas sobre la amplitud, rastreando menos páginas pero completando más rápido. En amazon.com, el tiempo de ejecución bajó de 25.200 segundos (tiempo de espera) a profundidad 5 a solo 5.660 segundos a profundidad 20, mientras que las páginas rastreadas también disminuyeron de 905 a 795. Esto sugiere que el crawler de Cloudflare cambia su estrategia en profundidades más altas, gastando menos tiempo en el descubrimiento amplio y más en la traversía profunda.
Nimble alcanzó el tiempo de espera de 7 horas (25.200 segundos) en cada ejecución en todos los dominios y niveles de profundidad. Esto es notable porque en nuestras pruebas rápidas anteriores con profundidad máxima 1, Nimble se completó sin agotar el tiempo de espera. En el benchmark completo con profundidades de 5-20 y un límite de 1.000 páginas, consistentemente se ejecutó hasta alcanzar el tiempo de espera. A pesar de esto, Nimble aún logró rastrear un alto número de páginas en la mayoría de los casos (~900-1.000 en theregister.com y entrepreneur.com), lo que significa que está activamente rastreando durante las 7 horas pero simplemente nunca señala la finalización.
Tasa de llenado de texto de enlace en proveedores por profundidad máxima
Para evaluar la calidad de la salida en markdown, medimos qué porcentaje de enlaces en el markdown de cada proveedor contiene texto de ancla, la parte de texto clicable de un enlace. Un texto de ancla faltante (por ejemplo, [](/about) en lugar de [About Us](/about)) significa que el crawler no pudo extraer la etiqueta del enlace.
- Nimble: 100% en todas las profundidades
- Cloudflare: 91-94%
- Firecrawl: 90%
- Apify: 77-78%, aproximadamente 1 de cada 5 enlaces sin texto de ancla
La profundidad del rastreo tuvo un impacto mínimo en las tasas de llenado para cualquier proveedor, lo que sugiere que esto es una característica del motor de análisis de cada proveedor en lugar de una configuración de rastreo.
Tasa de llenado de texto de enlace en proveedores por dominio
Observar las tasas de llenado en diferentes dominios revela cómo la complejidad del sitio afecta la calidad de extracción de enlaces de cada proveedor.
- Nimble mantuvo el 100% en todos los dominios.
- Apify mostró la mayor variación, 89% en amazon.com pero cayendo al 66% en entrepreneur.com, lo que significa que un tercio de sus enlaces en ese sitio carecían de texto de ancla. Esto sugiere que Apify tiene más dificultades con sitios ricos en contenido que tienen estructuras de navegación complejas.
- Firecrawl tuvo el mejor rendimiento en theregister.com (98%) pero bajó al 81% en entrepreneur.com, siguiendo un patrón similar al de Apify.
- Cloudflare fue el más consistente después de Nimble, manteniéndose entre 89-94% independientemente del dominio.
Entrepreneur.com resultó ser el dominio más desafiante para la extracción de texto de enlace; tanto Apify (66%) como Firecrawl (81%) tuvieron sus puntuaciones más bajas allí, probablemente debido al uso intensivo del sitio de menús de navegación anidados y elementos de contenido dinámico que son más difíciles de convertir limpiamente a markdown.
Total de enlaces en la salida de markdown en dominios por profundidad máxima
La variación en la cantidad de enlaces entre proveedores fue consistentemente alta (74-97%), lo que indica que los proveedores extraen cantidades muy diferentes de enlaces de las mismas páginas. Para obtener una vista más detallada de esta disparidad, medimos la cantidad total de enlaces en markdown por proveedor.
- Apify devolvió la mayor cantidad de enlaces en general, particularmente en amazon.com con más de 420K enlaces a profundidad 5 (~423 por página). En entrepreneur.com se estabilizó alrededor de 63K independientemente de la profundidad. Su salida incluye rastreadores de anuncios y píxeles de seguimiento junto con enlaces de contenido de página.
- Cloudflare alcanzó un máximo de 303K en entrepreneur.com a profundidad 10 pero bajó a 53K a profundidad 20. En la misma página de inicio de entrepreneur.com, Cloudflare extrajo 434 enlaces en comparación con los 143 de Apify, capturando menús de navegación completos y submenús.
- Firecrawl consistentemente devolvió 5-9K enlaces en todas las configuraciones, limitado por su baja cantidad de páginas.
- Nimble devolvió un total de 3-40K enlaces, promediando 5-28 enlaces por página en comparación con 60-420 para otros proveedores. En la página de inicio de entrepreneur.com, Nimble devolvió 13 enlaces frente a los 434 de Cloudflare, limitado a los titulares principales de los artículos. Su tasa de llenado del 100% refleja que los enlaces que sí incluyó tenían texto de ancla, en lugar de indicar una cobertura integral de enlaces. Nimble no genera enlaces markdown estándar. Su conteo incluye enlaces HTML escapados encontrados dentro de la salida de markdown.
Tasa de presencia de título en proveedores
La similitud de títulos entre proveedores mostró una desviación de menos del 1% en todas las pruebas y dominios, confirmando que cuando los proveedores extraen un título, consistentemente devuelven el mismo resultado. La tasa de presencia de título también se mantuvo entre 98-100% en todos los niveles de profundidad máxima, mostrando que la profundidad del rastreo no tiene un impacto significativo en la extracción de títulos.
Cuando se desglosa por dominio, surgieron algunas diferencias:
En entrepreneur.com y theregister.com, la mayoría de los proveedores lograron tasas de presencia de título del 99-100%. Amazon.com fue el único dominio donde aparecieron diferencias significativas: Firecrawl bajó al 93% y Nimble al 95,9%, mientras que Apify mantuvo el 99,6%. Esto se alinea con la protección de bots más pesada de Amazon, que puede bloquear o distorsionar las respuestas de las páginas, haciendo que algunos proveedores devuelvan páginas sin títulos extraíbles.
¿Qué es un web crawler?
Un web crawler, a veces llamado "araña" o "agente", es un bot que navega por internet para indexar contenido.
Los crawlers han ido más allá de los motores de búsqueda y ahora sirven como la Capa de Datos Agéntica. Actúan como los ojos para agentes de IA autónomos como Claude Code y OpenAI Operator, asistiendo con tareas en tiempo real como investigación competitiva y transacciones de múltiples pasos.
¿Qué hace un web crawler?
El rastreo web se dividió en tres modos, cada uno diseñado para un objetivo de crawler diferente.
- Modo de descubrimiento (tradicional): Los bots de motores de búsqueda como Googlebot rastrean URLs para indexación, ayudando a las personas a encontrar resultados a través de motores de búsqueda.
- Modo de recuperación (RAG): Bots de IA como ChatGPT-User o PerplexityBot obtienen páginas específicas en tiempo real para responder a las solicitudes de los usuarios. Usan markdown en lugar de HTML para ajustarse a los límites de tokens del modelo de IA.
- Modo Agéntico (Orientado a la Acción): Este nuevo tipo de crawler en 2026 hace más que solo leer contenido. Usando el Protocolo de Contexto de Modelo (MCP), estos bots pueden interactuar con sitios web para reservar vuelos o ejecutar comandos de software.
En el pasado, los crawlers usaban selectores como XPath o CSS para extraer datos. Extracción Nativa de IA se ha convertido en la norma.
Herramientas como Firecrawl y Crawl4AI usan instrucciones en lenguaje natural para encontrar datos. En lugar de escribir reglas para cada elemento, los desarrolladores pueden decirle al crawler que "extraiga el precio del producto", y la IA encontrará el valor correcto incluso si el código del sitio web cambia.
Construir vs. comprar web crawlers en la era de la IA
1. Construir tu propio crawler
Ideal para proteger la propiedad intelectual central y permitir una personalización profunda. Construir ahora requiere desarrollar una capa de agente propietaria, no solo escribir scripts básicos de Scrapy.
- Cuándo construir: Selecciona este enfoque si tu crawler proporciona una ventaja competitiva única. Por ejemplo, construye el tuyo propio si estás desarrollando un motor de búsqueda especializado o requieres control total sobre datos sensibles o regulados.
- El conjunto de herramientas: Ya no necesitas empezar desde cero. Los desarrolladores ahora aprovechan el Protocolo de Contexto de Modelo (MCP) para permitir que los agentes de IA internos interactúen con la web.
2. Usar herramientas y APIs de rastreo web
Las herramientas gestionadas han avanzado de scrapers básicos a agentes autónomos.
- Extracción sin mantenimiento: Herramientas modernas como Kadoa y Firecrawl usan IA de auto-reparación. Especificas los datos requeridos, como "Precio del Producto", en lugar de su ubicación en el código. Si el diseño del sitio web cambia, la herramienta se adapta automáticamente.
- Cumplimiento como servicio: Muchos proveedores ofrecen cumplimiento integrado con la Ley de IA de la UE. Gestionan los registros de auditoría requeridos y las verificaciones de opt-out de derechos de autor, que son difíciles de implementar de forma independiente.
- Velocidad hacia el valor: Comprar una plataforma puede mover tu proyecto de concepto a producción en semanas.
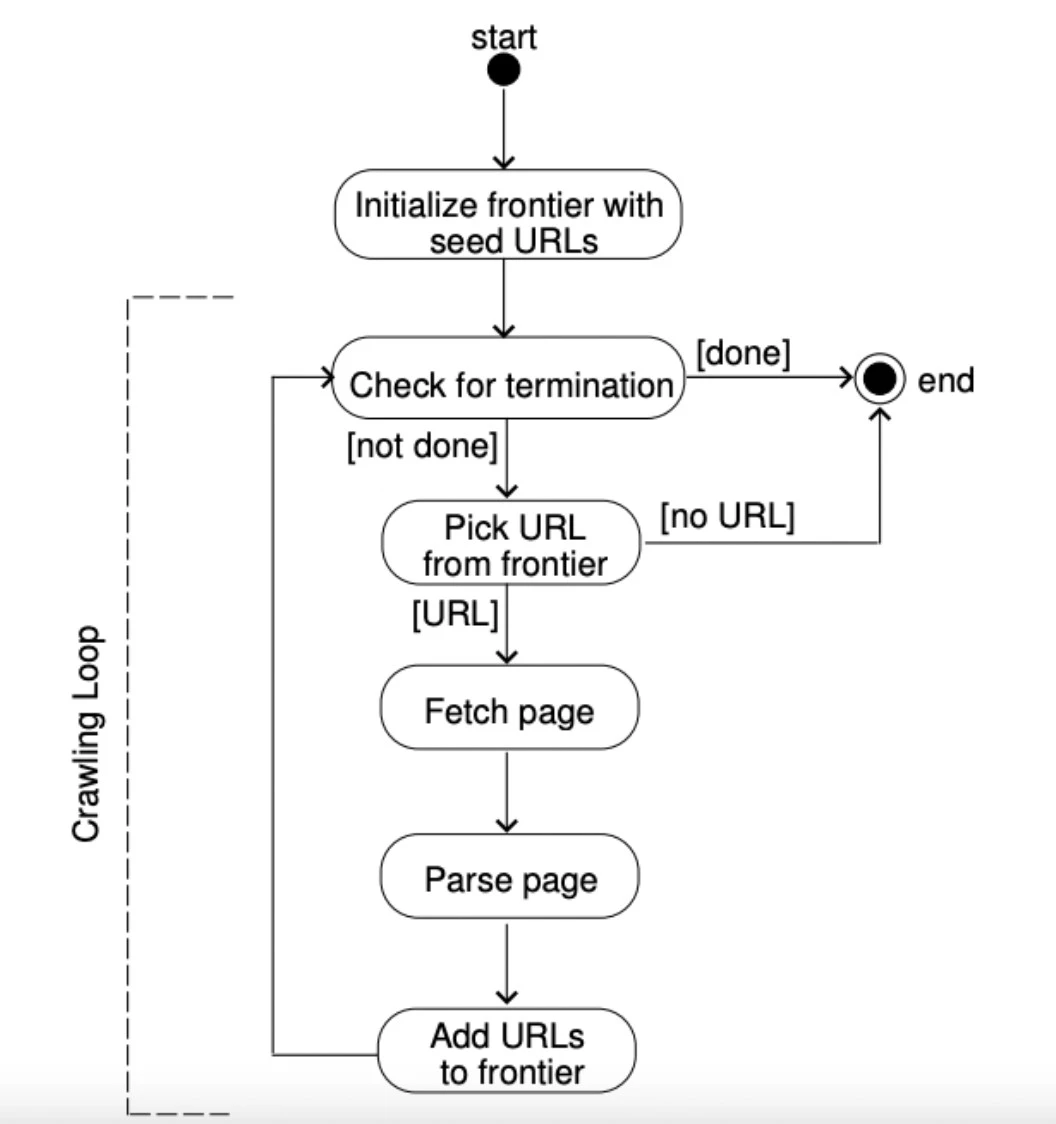
Figura 5: Una explicación de cómo funciona un frente de URL.
¿Son legales los web crawlers?
En general, el rastreo web es legal, pero dependiendo de cómo y qué rastrees, podrías encontrarte rápidamente en un problema legal. Cuatro pilares principales determinan si el rastreo (y el scraping que típicamente sigue) es legal:
1. Público vs. privado: Solo rastrea datos que estén abiertamente disponibles para el público sin una cuenta.
2. Información personal: Evita la información de identificación personal (nombres, correos electrónicos y direcciones) a menos que tengas una base legal.
3. Salud del servidor: Usa límites de tasa para evitar ralentizar el servidor; evita "DDOSear" un sitio web.
4. Derechos de autor: Los artículos y las imágenes están protegidos por derechos de autor, pero los hechos (precios, fechas) no lo están.
¿Cuál es la diferencia entre rastreo web y web scraping?
El web scraping es usar web crawlers para escanear y almacenar todo el contenido de una página web objetivo. En otras palabras, el web scraping es un caso de uso específico del rastreo web para crear un conjunto de datos dirigido, como extraer todas las noticias financieras para el análisis de inversiones y buscar nombres de empresas específicos.
Tradicionalmente, una vez que un web crawler ha rastreado e indexado todos los elementos de la página web, un web scraper extraía datos de la página web indexada. Sin embargo, hoy en día los términos scraping y crawling se usan indistintamente con la diferencia de que crawler tiende a referirse más a los crawlers de motores de búsqueda. A medida que las empresas distintas de los motores de búsqueda comenzaron a usar datos web, el término web scraper comenzó a tomar el lugar del término web crawler.
¿Cuáles son los desafíos del rastreo web?
1. Frescura de la base de datos
El contenido de los sitios web se actualiza regularmente. Las páginas web dinámicas, por ejemplo, cambian su contenido basándose en las actividades y comportamientos de los visitantes. Esto significa que el código fuente del sitio web no permanece igual después de que rastreas el sitio web. Para proporcionar la información más actualizada al usuario, el web crawler debe volver a rastrear esas páginas web con más frecuencia.
2. Trampas de crawler
Los sitios web emplean diferentes técnicas, como trampas de crawler, para evitar que los web crawlers accedan y rastreen ciertas páginas web. Una trampa de crawler, o trampa de araña, hace que un web crawler haga un número infinito de solicitudes y quede atrapado en un círculo vicioso de rastreo. Los sitios web también pueden crear trampas de crawler sin intención. En cualquier caso, cuando un crawler encuentra una trampa de crawler, entra en algo así como un bucle infinito que desperdicia los recursos del crawler.
3. Ancho de banda de red
Descargar un gran número de páginas web irrelevantes, utilizar un web crawler distribuido o volver a rastrear muchas páginas web resultan en una alta tasa de consumo de capacidad de red.
4. Páginas duplicadas
Los bots de web crawler principalmente rastrean todo el contenido duplicado en la web; sin embargo, solo una versión de una página se indexa. El contenido duplicado dificulta que los bots de motores de búsqueda determinen qué versión del contenido duplicado indexar y clasificar. Cuando Googlebot descubre un grupo de páginas web idénticas en los resultados de búsqueda, indexa y selecciona solo una de estas páginas para mostrar en respuesta a la consulta de búsqueda de un usuario.
Top 3 mejores prácticas de rastreo web
1. Cortesía/Tasa de rastreo
Los sitios web establecen una tasa de rastreo para limitar la cantidad de solicitudes realizadas por bots de web crawler. La tasa de rastreo indica cuántas solicitudes puede hacer un web crawler a tu sitio web en un intervalo de tiempo dado (por ejemplo, 100 solicitudes por hora). Permite a los propietarios de sitios web proteger el ancho de banda de sus servidores web y reducir la sobrecarga del servidor. Un web crawler debe adherirse al límite de rastreo del sitio web objetivo.
2. Cumplimiento de robots.txt
Un archivo robots.txt es un archivo de texto colocado en la raíz de un sitio web que indica a los crawlers qué páginas tienen permitido o no permitido acceder. Es un estándar voluntario, lo que significa que los bots compatibles lo respetan, pero técnicamente no previene el acceso. Seguir el robots.txt de un sitio web se considera una buena práctica, y en muchas jurisdicciones, ignorarlo puede exponerte a riesgos legales o reputacionales.
3. Rotación de IP
Los sitios web emplean diferentes técnicas anti-scraping como CAPTCHAs para gestionar el tráfico de crawlers y reducir las actividades de web scraping. Por ejemplo, huella digital del navegador es una técnica de seguimiento utilizada por sitios web para recopilar información sobre los visitantes, como la duración de la sesión o las vistas de página.
Este método permite a los propietarios de sitios web detectar "tráfico no humano" y bloquear la dirección IP del bot. Para evitar la detección, puedes integrar proxies rotativos, como residenciales proxies, en tu web crawler.
Metodología de benchmark de web crawlers
Probamos cuatro APIs de rastreo (Apify, Nimble, Cloudflare, Firecrawl) en tres dominios de dificultad variable: amazon.com (protección pesada de bots), entrepreneur.com (sitio de contenido complejo) y theregister.com (sitio de noticias).
Configuración compartida
Todos los proveedores recibieron configuraciones centrales idénticas para garantizar una comparación justa:
- Sitemap: Desactivado, los proveedores deben descubrir páginas solo a través de enlaces HTML
- Enlaces externos: Desactivados, los crawlers se mantienen dentro del dominio objetivo
- Subdominios: Activados, se siguen las páginas de subdominio (por ejemplo, india.entrepreneur.com)
- Renderizado de JavaScript: Activado, todos los proveedores usan un navegador sin cabeza
- Caché: Desactivada
- Límite de páginas: 1.000 páginas por ejecución
- Tiempo de espera: 7 horas (25.200 segundos)
- Manejo de límite de tasa: Espera de 20 segundos con hasta 3 reintentos en HTTP 429
Cada proveedor fue probado en tres niveles de profundidad máxima (5, 10, 20) en los tres dominios, totalizando 36 ejecuciones de rastreo. Los proveedores fueron probados secuencialmente (no en paralelo), cada combinación se ejecutó una vez y el estado del rastreo se consultó cada 1 segundo.
Apify se configuró con el actor website-content-crawler usando Playwright/Firefox como su navegador sin cabeza. El acceso a subdominios se controló mediante patrones glob, y el proxy integrado de Apify se usó para todas las solicitudes.
Nimble, Cloudflare y Firecrawl se configuraron usando sus respectivas APIs REST con la configuración compartida descrita anteriormente. No se aplicaron configuraciones adicionales específicas del proveedor más allá de los parámetros estandarizados.
Para Cloudflare, usamos el plan Workers Paid. El costo reportado refleja lo que gastamos para rastrear 1.000 páginas bajo este plan. Cloudflare cobra según el tiempo de renderizado del navegador en lugar de la cantidad de páginas.
Para Firecrawl, usamos el plan Hobby. El costo reportado es la cantidad prorrateada por 1.000 créditos de los créditos proporcionados en este plan. El costo efectivo por página varía según el nivel del plan y si se compran paquetes de créditos adicionales.
Cita esta investigación
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Şipi, Nazlı},
title = {{Benchmark de Web Crawler para Alimentar Sitios Web a la IA}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/web-crawler}},
note = {AIMultiple. Recuperado el 2 de Julio de 2026}
}
Comentarios 1
Comparte tus ideas
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.
Hi Cem, I think there is a misunderstanding regarding the robots.txt role in the crawling context. The web bots can crawl any website when indexing is allowed without having the robots.txt somewhere on their top domain, subdomains and ports and so on. The role of a robots.txt is to keep control of the traffic from web bots so the website is not overloaded by requests.