Mejores 12+ Agentes de Web Scraping con IA (Gratis y de Pago)
Los selectores CSS manuales y los scripts básicos ya no funcionan bien. A medida que las arquitecturas web se vuelven más dinámicas e impulsadas por la IA, los métodos de scraping tradicionales se vuelven menos efectivos.
Para mantener los datos confiables, la industria se está volviendo hacia agentes de IA autónomos, scraping basado en visión (VLM) y scrapers de auto-reparación. Visita las principales herramientas de web scraping con IA:
Mejores herramientas de web scraping con IA
Cómo creamos esta lista
Excluimos intencionalmente las herramientas de extracción de datos de propósito general y las bibliotecas de automatización que carecen de capacidades de IA integradas (como Scrapy o Playwright), incluso si se usan comúnmente para web scraping y pueden complementar las herramientas de IA en flujos de trabajo híbridos.
Curamos esta lista utilizando los siguientes criterios:
- Enfoque en capacidades impulsadas por IA: Incluimos herramientas que utilizan inteligencia artificial, como LLMs y NLP, para entender la estructura de la página sin reglas codificadas o extracción de datos impulsada por prompts.
- Accesibilidad para usuarios: Clasificamos las herramientas según el nivel técnico, como herramientas sin código vs. herramientas para desarrolladores.
¿Qué es el web scraping con IA?
El web scraping con IA ha evolucionado hacia la Liquidación Autónoma de Datos. Ya no se trata de automatizar clics en el navegador o analizar HTML; implica Modelos de Lenguaje y Visión (VLMs) que 'ven' una página web como un humano y Razonamiento Agente que puede navegar por autenticaciones complejas y contenido dinámico sin selectores CSS predefinidos o mapeo de DOM.
Tipos de herramientas de web scraping con IA
1. Plataformas impulsadas por IA
Estas soluciones utilizan LLMs, visión por computadora o NLP para analizar, extraer o interpretar contenido de páginas web. Por ejemplo, el scraping adaptativo de Diffbot se adapta dinámicamente a los cambios de DOM o al marcado inconsistente entre páginas. Muchas herramientas en esta categoría soportan extracción basada en esquemas (estructurada) o basada en prompts.
Le das a la herramienta una instrucción en lenguaje natural, por ejemplo, "Extrae todos los títulos de trabajo y nombres de empresas de esta URL."
2. Herramientas sin código
Los scrapers sin código proporcionan interfaces visuales que permiten a los usuarios definir los datos a capturar usando funcionalidad de punto y clic o plantillas predefinidas. Puedes definir reglas de extracción de datos visualmente.
Sin embargo, estas herramientas ofrecen un uso limitado de IA en comparación con las plataformas impulsadas por IA, que utilizan IA para la detección de patrones o sugerencias inteligentes de campos.
3. Herramientas de IA de código abierto
Esta categoría incluye bibliotecas o frameworks que utilizan LLMs o agentes de IA para extraer datos de páginas web. Proporcionan control programático; necesitas definir esquemas de extracción o prompts de IA.
Técnicas y tecnologías involucradas en el web scraping impulsado por IA
El enfoque de web scraping impulsado por IA se adapta automáticamente a los rediseños de sitios web y extrae datos cargados dinámicamente a través de JavaScript. Es importante emplear estos métodos considerando los términos del sitio web y las consideraciones éticas.
1. Scraping adaptativo
Los métodos tradicionales de web scraping dependen de la estructura o diseño específico de una página web. Cuando los sitios web actualizan sus diseños y estructuras, los scrapers tradicionales pueden romperse fácilmente. Los métodos de recolección de datos basados en IA, como el scraping adaptativo, permiten a las herramientas de web scraping adaptarse a los cambios en los sitios web, incluido el diseño y la estructura.
Los scrapers adaptativos utilizan aprendizaje automático e IA para ajustar dinámicamente su comportamiento según la estructura de una página web. Identifican autónomamente la estructura de la página web objetivo analizando el Modelo de Objeto de Documento (DOM) o siguiendo patrones específicos. Para identificar patrones o anticipar cambios, la herramienta puede entrenarse usando datos históricos extraídos.
Por ejemplo, los modelos de IA como las redes neuronales convolucionales (CNNs) pueden usarse para reconocer y analizar elementos visuales de una página web, como botones. Típicamente, las técnicas de extracción de datos tradicional dependen del código subyacente de una página web, como elementos HTML, para extraer datos.
Extracción de visión zero-shot:
El scraping adaptativo tradicional aún depende del árbol DOM. Sin embargo, en 2026, herramientas como Firecrawl y Crawl4AI han pasado a la extracción 'Zero-Shot'. Tomando una instantánea visual (VLM), la IA identifica elementos basándose en la intención visual en lugar del código. Esto hace que los scrapers sean más resistentes a la aleatorización de clases CSS y las trampas de código 'Honey-pot'.
Patrocinado
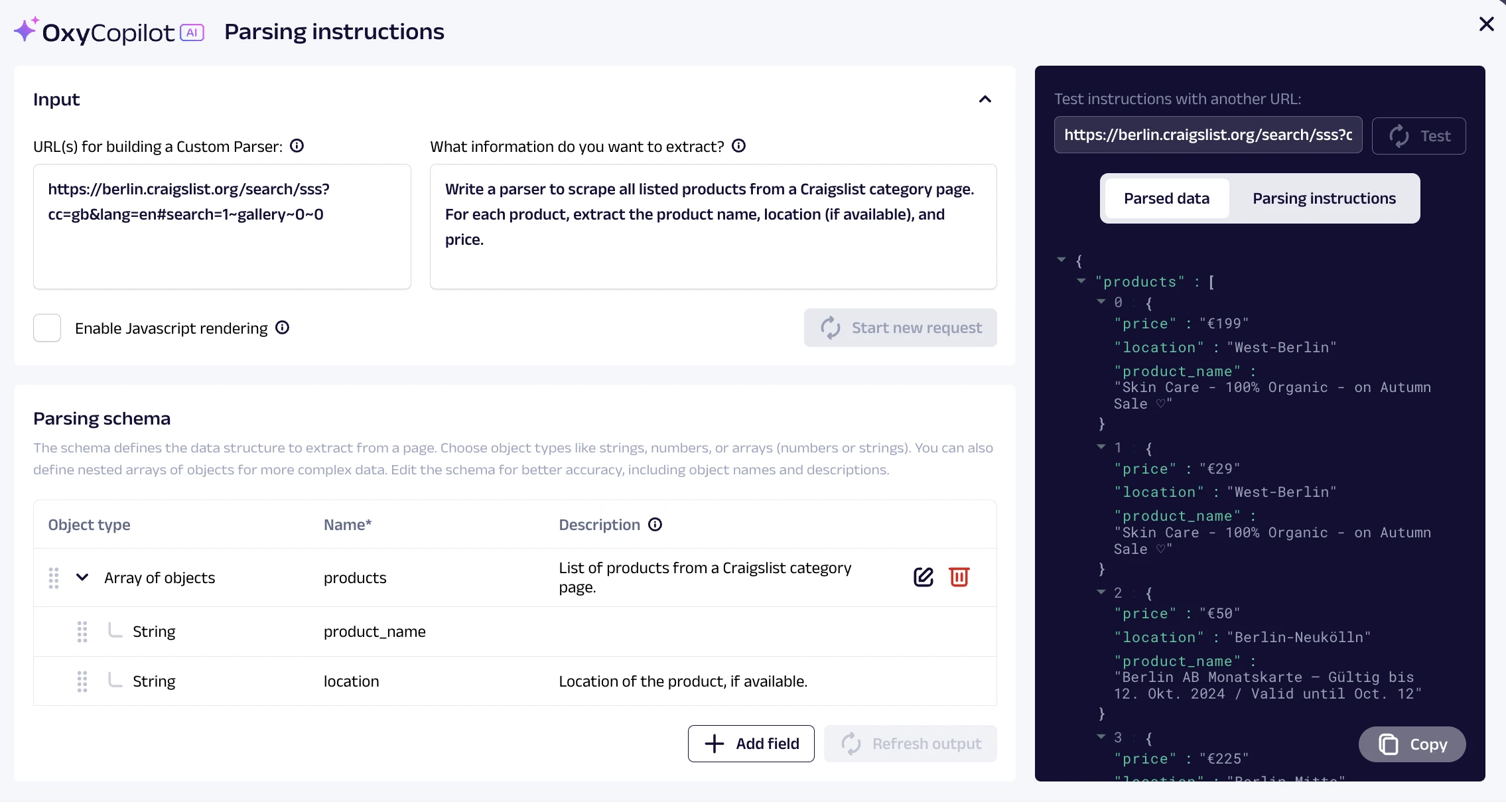
Oxylabs proporciona un constructor de analizadores personalizados basado en ML, llamado OxyCopilot, que mejora la API de Web Scraper de Oxylab, permitiendo a los usuarios refinar y organizar los datos recopilados usando prompts. Esto agiliza el proceso al eliminar la necesidad de clasificar campos de datos irrelevantes o realizar limpieza manual de datos.
2. Generación de patrones de navegación similares a los humanos
La mayoría de los sitios web emplean medidas anti-scraping, como CAPTCHAs, para evitar que los scrapers web accedan y extraigan su contenido. Las herramientas de web scraping impulsadas por IA pueden simular comportamientos similares a los humanos como velocidad, movimientos del mouse y patrones de clics.
3. Modelos de IA generativa
En 2025/2026, dejamos de pedirle a la IA que escriba código BeautifulSoup. En su lugar, usamos Agentes de Scraping (como Skyvern o Browser-use).
- Cómo funciona: Proporcionas un objetivo en inglés sencillo (por ejemplo, 'Encuentra la computadora portátil más barata en este sitio y exporta a JSON').
- Patrón razonar-actuar (ReAct): El agente explora el sitio, resuelve CAPTCHA, maneja la paginación y valida la calidad de los datos en tiempo real sin una sola línea de código manual.
4. Procesamiento de lenguaje natural (NLP)
El NLP, un subconjunto de ML, te permite realizar tareas como análisis de sentimientos, resumen de contenido y reconocimiento de entidades. Es necesario derivar insights de los datos extraídos.
Por ejemplo, si has extraído una cantidad significativa de datos de reseñas de productos, necesitas determinar el tono emocional detrás de cada palabra, como positivo, negativo o neutral. El análisis de sentimientos te permite categorizar los datos extraídos como positivos o negativos. Esto ayuda a las empresas a abordar las preocupaciones de los clientes y mejorar sus ofertas.
Cita esta investigación
Elige el formato que se ajuste al lugar donde vas a publicar. Pegar la versión con enlace en tu CMS conserva el enlace de retroceso.
@misc{karatas2026,
author = {Karatas, Gulbahar},
title = {{Mejores 12+ Agentes de Web Scraping con IA (Gratis y de Pago)}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/ai-web-scraping}},
note = {AIMultiple. Recuperado el 5 de Junio de 2026}
}
Sé el primero en comentar
Tu dirección de correo electrónico no será publicada. Todos los campos son obligatorios. Los comentarios se dejan en su idioma original.