Évaluation des grands modèles de langage en : plus de 10 indicateurs et méthodes
L’évaluation des grands modèles de langage (LLM eval) est l’évaluation multidimensionnelle des grands modèles de langage (LLM ). Une évaluation efficace est cruciale pour la sélection et l’optimisation des LLM.
Les entreprises disposent d'un large éventail de modèles de base et de leurs variantes, mais le succès reste incertain sans une mesure précise des performances. Pour garantir les meilleurs résultats, il est essentiel d'identifier les méthodes d'évaluation les plus adaptées ainsi que les données pertinentes pour la formation et l'évaluation.
Consultez les indicateurs et méthodes d'évaluation, comment relever les défis posés par les modèles d'évaluation actuels et les solutions pour les atténuer .
Pour des définitions et des références rapides, consultez le glossaire des termes clés .
Meilleurs modèles et indicateurs pour des objectifs spécifiques
Découvrez les ensembles de données et les indicateurs les plus adaptés à vos objectifs spécifiques :
Évaluation | Meilleur ensemble de données de référence | Métrique indispensable |
|---|---|---|
Évaluation humaine Benchmark de codage IA multiple AIMultiple | Exactitude fonctionnelle | |
efficacité énergétique et durabilité | Référence en matière d'efficacité énergétique | consommation d'énergie |
Connaissances de niveau expert | Le dernier examen de l'humanité (HLE) GPQA | Rappel |
Connaissances générales | MMLU-Pro | Précision |
TruthfulQA | Précision | |
Instructions suivant la précision | IFEval | Coherence |
compréhension du langage | BBH/SuperGLUE | Perplexity |
Compréhension du contexte long | NIVEAU | Coherence |
MATHÉMATIQUES | Précision | |
Classement des LLM ouverts | Classements Elo |
5 étapes pour évaluer les LLM
1. Sélection des points de référence
Le meilleur moyen d'évaluer l'efficacité du LLM est de réaliser une tâche concrète en production. Cependant, en raison de contraintes telles que la confidentialité des données, vous n'aurez peut-être pas accès à un large éventail de tâches. Dans ce cas, il est préférable de se fier à des benchmarks.
Il est souvent nécessaire de combiner plusieurs tests de performance pour évaluer de manière exhaustive les résultats d'un modèle de langage. Un ensemble de tâches de référence est sélectionné afin de couvrir un large éventail de défis liés au langage.
Ces tâches peuvent inclure la modélisation du langage, la complétion de texte, l'analyse des sentiments , la réponse aux questions, la synthèse, la traduction automatique, et bien plus encore. Les benchmarks des LLM doivent refléter des scénarios réels et couvrir divers domaines et niveaux de complexité linguistique. Nous disposons d'un classement des LLM présentant les résultats les plus récents pour les logiciels libres et propriétaires.
L'utilisation systématique des mêmes méthodes et jeux de données d'évaluation comparative peut entraîner un surapprentissage. Nous vous conseillons de mettre à jour vos indicateurs d'évaluation afin d'obtenir des résultats généralisables. Voici quelques-uns des jeux de données d'évaluation comparative les plus populaires :
- MMLU-Pro affine l'ensemble de données MMLU en proposant dix choix par question, ce qui exige un raisonnement plus poussé et réduit le bruit grâce à un examen par des experts. 1
- GPQA propose des questions difficiles conçues par des experts du domaine, validées en termes de difficulté et de factualité, et n'est accessible que par des mécanismes de contrôle pour éviter toute contamination. 2
- MuSR consiste en des problèmes complexes générés algorithmiquement, exigeant des modèles qu'ils utilisent le raisonnement et l'analyse contextuelle à longue portée, peu de modèles obtenant de meilleurs résultats que le hasard. 3
- MATH est un recueil de problèmes difficiles de niveau lycée, formatés de manière cohérente, et axé sur les questions les plus ardues. 4
- IFEval teste la capacité des modèles à suivre des instructions et un formatage explicites en utilisant des métriques d'évaluation strictes. 5
- BBH comprend 23 tâches complexes issues de l'ensemble de données BigBench, mesurant des indicateurs objectifs et la compréhension du langage, et présente une bonne corrélation avec les préférences humaines. 6
- HumanEval évalue les performances d'un LLM en matière de génération de code, en se concentrant particulièrement sur sa correction fonctionnelle. 7
- TruthfulQA résout les problèmes d'hallucination en mesurant la capacité d'un LLM à générer des réponses exactes. 8
- Les tests GLUE (General Language Understanding Evaluation) et SuperGLUE évaluent les performances des modèles de traitement automatique du langage naturel (TALN), en particulier pour les tâches de compréhension du langage. 9
Les principaux enseignements de cette recherche soulignent également la nécessité d'améliorer l'analyse comparative, la collaboration et l'innovation afin de repousser les limites des capacités des LLM.
2. Préparation des données
L'utilisation de jeux de données personnalisés ou libres de droits est acceptable. L'important est que le jeu de données soit suffisamment récent pour que les modèles linéaires linéaires n'aient pas encore été utilisés pour l'entraînement.
Des jeux de données soigneusement sélectionnés, comprenant des ensembles d'entraînement , de validation et de test, sont préparés pour chaque tâche de référence. Ces jeux de données doivent être suffisamment volumineux pour prendre en compte les variations d'usage de la langue, les spécificités du domaine et les biais potentiels. Une curation rigoureuse des données est essentielle pour garantir une évaluation objective et de haute qualité.
3. Entraînement et ajustement du modèle
Les modèles entraînés en tant que grands modèles de langage (LLM) font l'objet d'un réglage fin afin d'améliorer leurs performances spécifiques à la tâche. Le processus commence généralement par un pré-entraînement sur de vastes sources textuelles telles que Wikipédia ou Common Crawl, permettant au modèle d'apprendre les structures et les schémas linguistiques, ce qui constitue la base du codage génératif de l'IA et de la génération de textes d'apparence humaine.
Après une phase de pré-entraînement, les modèles linéaires à longue portée (LLM) sont affinés sur des jeux de données de référence spécifiques afin d'améliorer leurs performances dans des tâches telles que la traduction ou la synthèse. Ces modèles, de taille variable, utilisent des architectures basées sur le transformeur. Des méthodes d'entraînement alternatives sont souvent employées pour optimiser leurs capacités.
4. Évaluation du modèle
Les modèles LLM entraînés ou optimisés sont évalués sur les tâches de référence à l'aide des métriques d'évaluation prédéfinies. Leur performance est mesurée en fonction de leur capacité à générer des réponses précises, cohérentes et contextuellement appropriées pour chaque tâche. Les résultats de l'évaluation permettent de mieux comprendre les points forts, les points faibles et la performance relative des modèles LLM.
5. Analyse comparative
Les résultats de l'évaluation sont analysés afin de comparer les performances des différents modèles LLM sur chaque tâche de référence. Les modèles sont classés selon leurs performances globales ou des indicateurs spécifiques à la tâche. L'analyse comparative permet aux chercheurs et aux praticiens d'identifier les modèles les plus performants, de suivre leur évolution et de comprendre les atouts respectifs des différents modèles pour des tâches spécifiques.
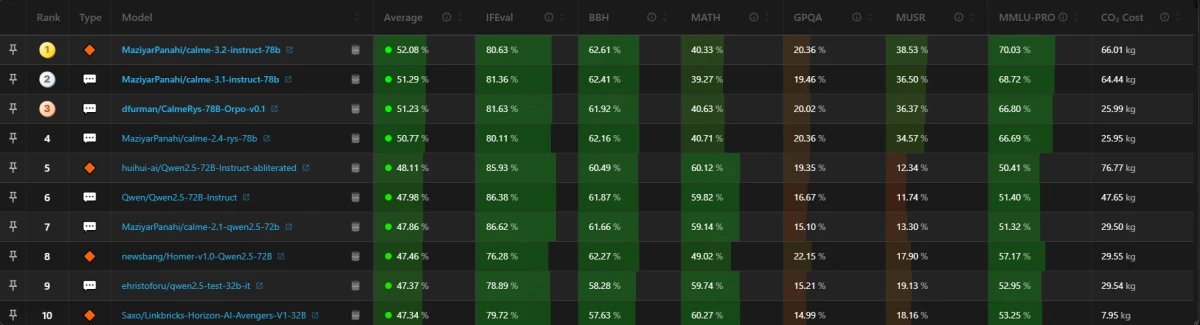
Figure 1 : Classement des 10 meilleurs modèles de langage de grande taille en fonction de leurs indicateurs de performance. 10
Métriques d'évaluation
Le choix d'une méthode d'analyse comparative et de métriques d'évaluation pour définir les critères d'évaluation globaux en fonction de l'utilisation prévue du modèle sont des tâches quasi simultanées. De nombreuses métriques sont utilisées pour l'évaluation.
Ces méthodes de mesure, quantitatives ou qualitatives, évaluent certains aspects de la performance des modèles linéaires. Plus ou moins proches de l'évaluation humaine, elles fournissent des scores numériques ou catégoriels qui peuvent être suivis dans le temps et comparés entre les modèles.
Indicateurs généraux de performance
- La précision correspond au pourcentage de réponses correctes dans les tâches binaires.
- Le rappel correspond au nombre réel de vrais positifs par rapport aux faux positifs dans les réponses LLM.
- Le score F1 combine exactitude et rappel en une seule mesure. Les scores F1 varient de 0 à 1, 1 indiquant un rappel et une précision excellents.
- La latence représente l'efficacité et la vitesse du modèle.
- La toxicité indique l'immunité du modèle aux contenus nuisibles ou offensants dans les résultats.
- Le système de classement Elo des modèles d'IA évalue les modèles de langage en fonction de leurs performances dans des tâches communes, à l'instar du classement des joueurs d'échecs. Les modèles s'affrontent en produisant des résultats pour les mêmes tâches, et les classements sont ajustés à mesure que de nouveaux modèles ou de nouvelles tâches sont introduits.
Indicateurs de performance des agents
Les agents deviendront probablement les cas d'utilisation les plus courants des modèles de langage. Par conséquent, l'évaluation des modèles de langage lorsqu'ils pilotent des agents revêt une importance croissante.
Taux de réussite pour les tâches de bout en bout (par exemple, identifier tous les professionnels de la croissance dans les entreprises qui correspondent à notre profil de profil idéal)
Précision d'utilisation des outils : fréquence à laquelle le modèle appelle l'API appropriée avec les paramètres corrects.
Sécurité des agents : Fréquence à laquelle l’agent a entrepris des actions nuisibles telles que la suppression d’un fichier lors de la résolution d’une tâche.
Métriques spécifiques au texte
- Coherence est le score du flux logique et de la cohérence du texte généré.
- Les mesures de diversité évaluent la variété et l'originalité des réponses générées. Elles consistent à analyser des indicateurs tels que la diversité des n-grammes ou à mesurer la similarité sémantique entre les réponses. Des scores de diversité plus élevés indiquent des résultats plus diversifiés et originaux.
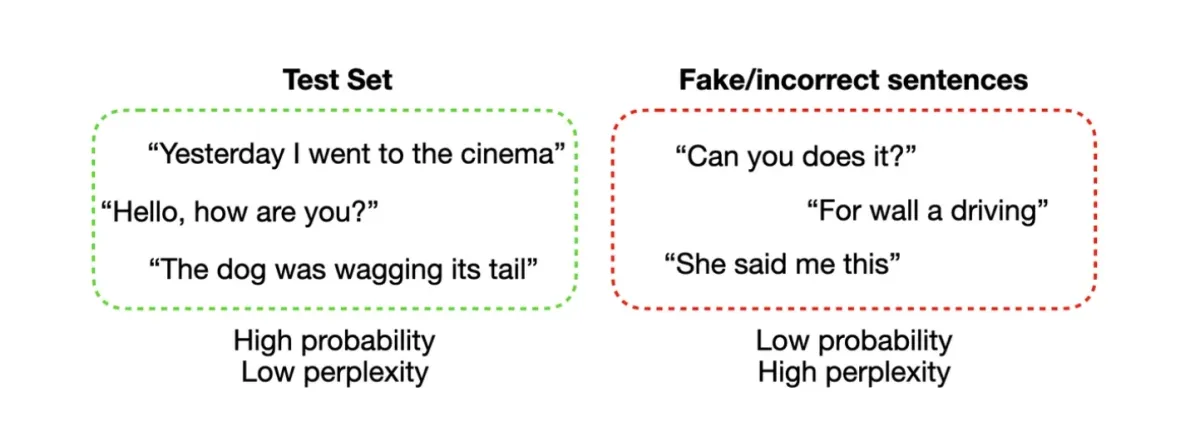
- La perplexité (Perplexity) est une mesure utilisée pour évaluer les performances des modèles de langage. Elle quantifie la capacité du modèle à prédire un échantillon de texte. Plus la valeur de perplexité est faible, meilleures sont les performances.
Figure 2 : Exemples d'évaluation de la perplexité.
- BLEU (Bilingual Evaluation Understudy) est une métrique utilisée en traduction automatique. Elle compare la traduction générée à une ou plusieurs traductions de référence et mesure leur similarité. Les scores BLEU varient de 0 à 1, les scores les plus élevés indiquant une meilleure performance.
- ROUGE (Recall-Oriented Understudy for Gissing Evaluation) est un ensemble de métriques permettant d'évaluer la qualité des résumés. Il compare le résumé généré à un ou plusieurs résumés de référence et calcule la précision, le rappel et le score F1 (Figure 3). Les scores ROUGE renseignent sur les capacités du modèle de langage en matière de génération de résumés.
Figure 3 : Un exemple de processus d’évaluation ROUGE. 11
Les indicateurs d'évaluation peuvent être calculés par un modèle ou par un humain. Chacun présente ses propres avantages et cas d'utilisation :
LLM évaluant les LLM
Le LLM évalue la qualité de ses propres produits lors d'un examen appelé « LLM-en-tant-que-juge ». Cela peut impliquer la comparaison de textes générés par le modèle avec des données de référence ou la mesure des résultats à l'aide de métriques statistiques telles que la précision et le score F1.
LLM-as-a-judge offre aux entreprises une efficacité accrue en évaluant rapidement des millions de documents à un coût bien inférieur à celui d'une évaluation humaine. Cette solution est idéale pour les déploiements à grande échelle où la rapidité et l'optimisation des ressources sont des facteurs clés de succès, car elle permet d'évaluer efficacement le contenu technique même lorsque les évaluateurs qualifiés sont rares, assure un suivi qualité continu des systèmes d'IA et produit des résultats reproductibles et fiables d'un cycle d'évaluation à l'autre.
Évaluation avec intervention humaine
Le processus d'évaluation comprend le recours à des évaluateurs humains qui analysent la qualité des réponses du modèle linguistique. Ces évaluateurs notent les réponses générées selon différents critères : pertinence, fluidité, cohérence et qualité globale. Cette approche offre un retour d'information subjectif sur les performances du modèle.
L'évaluation humaine demeure essentielle pour les applications d'entreprise critiques, où les erreurs peuvent nuire gravement aux opérations ou à la réputation de l'entreprise. Les examinateurs humains excellent dans l'identification de problèmes subtils, en tenant compte du contexte culturel, des implications éthiques et de l'utilité pratique, autant de points que les systèmes automatisés négligent souvent. Leur intervention répond également aux exigences réglementaires en matière de supervision humaine dans des secteurs sensibles tels que la santé, la finance et les services juridiques.
Outils et cadres d'évaluation des LLM
L'évaluation LLM peut être réalisée de deux manières : vous pouvez la réaliser vous-même en utilisant des frameworks open source ou commerciaux, ou des valeurs précalculées à partir de benchmarks ou de résultats de frameworks open source des modèles de base.
Cadres open source
cadres d'évaluation complets
Les cadres d'évaluation complets sont des systèmes intégrés qui fournissent diverses métriques et techniques d'évaluation dans un environnement de test unifié. Ils offrent généralement des référentiels définis, des suites de tests et des systèmes de reporting pour évaluer les modèles de langage (LLM) selon un large éventail de capacités et de dimensions.
- LEval (Language Model Evaluation) est un cadre d'évaluation des LLM sur la compréhension du contexte long. LEval 12 est un ensemble de tests de performance comprenant 411 questions réparties en huit tâches, avec des contextes allant de 5 000 à 200 000 tokens. Il évalue la performance des modèles en matière de recherche d'informations et de raisonnement sur des documents volumineux. Cet ensemble inclut des tâches telles que la synthèse académique, la génération de documents techniques et la cohérence de dialogues à plusieurs tours de parole, permettant ainsi aux chercheurs de tester les modèles sur des applications concrètes plutôt que sur des tâches linguistiques isolées.
- Prometheus est un framework open-source qui utilise des LLM comme juges avec des stratégies d'incitation systématiques. 13 Il est conçu pour produire des scores d'évaluation qui correspondent aux préférences et au jugement humains.
Approches de test
Les approches de test sont des techniques méthodologiques permettant d'organiser et de réaliser des évaluations qui ne dépendent pas de métriques ou d'instruments particuliers. Elles spécifient des plans expérimentaux, des techniques d'échantillonnage et des philosophies de test qui peuvent être appliqués à différents cadres de référence.
- Les flux de travail d'évaluation DAG (Deep Acyclic Graph) utilisent des graphes acycliques orientés pour représenter les pipelines d'évaluation, bien qu'il ne s'agisse pas d'un outil d'évaluation spécifique.
- Les tests dynamiques d'invites évaluent les modèles en les exposant à des scénarios évolutifs et réalistes qui simulent l'interaction utilisateur. Cette méthode permet d'évaluer la façon dont les modèles réagissent à des requêtes complexes et à plusieurs niveaux, ainsi qu'à des invites ambiguës.
- Le cadre d'évaluation de l'efficacité énergétique et matérielle mesure la consommation d'énergie et l'efficacité de calcul des modèles lors de l'entraînement et de l'inférence. Il se concentre sur des indicateurs de durabilité, tels que les émissions de carbone et la consommation d'énergie.
plateformes d'évaluation commerciale
Les plateformes d'évaluation commerciales sont des solutions proposées par des fournisseurs, dotées de fonctionnalités de conformité, d'une intégration aux pipelines MLOps et d'interfaces conviviales, conçues pour les entreprises. Elles intègrent souvent des capacités de surveillance et offrent un compromis entre la complexité technique et l'accessibilité pour les utilisateurs non techniques.
- DeepEval (Confident AI) est un framework de test destiné aux développeurs, qui permet d'évaluer les applications LLM à l'aide de métriques prédéfinies de précision, de biais et de performance. Il s'interface avec les pipelines CI/CD pour les tests automatisés.
- Azure AI Studio Evaluation (Microsoft) offre des outils d'évaluation intégrés pour comparer différents modèles et invites, avec des capacités de suivi automatique des métriques et de collecte de commentaires humains.
- Prompt Flow (Microsoft) est un outil de développement permettant de créer, d'évaluer et de déployer des applications LLM. Ses fonctionnalités d'évaluation intégrées permettent des tests systématiques sur différents modèles et invites.
- LangSmith (LangChain) est une plateforme de débogage, de test et de surveillance des applications LLM, avec des fonctionnalités permettant de comparer les modèles et de suivre les chemins d'exécution.
- TruLens (TruEra) est une boîte à outils open-source pour évaluer et expliquer les applications LLM, avec des fonctionnalités pour suivre les hallucinations, la pertinence et l'ancrage.
- Vertex AI Studio (Google) fournit des outils pour tester et évaluer les résultats des modèles, avec des métriques automatiques et des capacités d'évaluation humaine au sein de l'écosystème d'IA de Google.
- Amazon Bedrock inclut des fonctionnalités d'évaluation pour les modèles de base, permettant aux développeurs de tester et de comparer différents modèles avant leur déploiement.
- Parea AI est une plateforme d'évaluation et de surveillance des applications LLM, axée spécifiquement sur la qualité des données et les performances du modèle.
Points de repère pré-évalués
Les benchmarks pré-évalués fournissent des informations précieuses grâce à des indicateurs spécifiques, ce qui les rend particulièrement utiles pour l'analyse axée sur les indicateurs. Notre site web propose des benchmarks pour les principaux modèles, vous aidant ainsi à évaluer efficacement leurs performances. Parmi les benchmarks clés :
- Hallucination – Évalue l'exactitude et la cohérence factuelle du contenu généré.
- Codage IA – Mesure la capacité de codage, l'exactitude et l'exécution.
- Raisonnement IA – Évalue les capacités d'inférence logique et de résolution de problèmes.
De plus, le classement OpenLLM offre un système d'évaluation en temps réel qui compare les modèles sur des jeux de données publics. Il agrège les scores obtenus pour des tâches telles que la traduction automatique, la synthèse et la réponse aux questions, offrant ainsi une comparaison dynamique et actualisée des performances des modèles.
cas d'utilisation d'évaluation
1. Évaluation des performances
Prenons l'exemple d'une entreprise qui doit choisir entre plusieurs modèles pour son système de génération de texte de base. Ces systèmes doivent être évalués afin de déterminer leur capacité à générer du texte et à répondre aux entrées. Les indicateurs de performance peuvent inclure la précision , la fluidité , la cohérence et la pertinence du sujet .
Avec l'avènement des grands modèles multimodaux , les entreprises peuvent également évaluer des modèles qui traitent et génèrent plusieurs types de données, tels que des images , du texte et de l'audio , élargissant ainsi la portée et les capacités de l'IA générative .
2. Comparaison des modèles
Une entreprise peut avoir optimisé un modèle pour améliorer ses performances dans des tâches spécifiques à son secteur d'activité. Un cadre d'évaluation aide les chercheurs et les praticiens à comparer les modèles d'apprentissage et à mesurer les progrès, les aidant ainsi à sélectionner le modèle le plus approprié pour une application donnée. La capacité de l'évaluation des modèles d'apprentissage à identifier les axes d'amélioration et les opportunités de corriger les lacunes peut se traduire par une meilleure expérience utilisateur, une réduction des risques, voire un avantage concurrentiel.
3. Détection et atténuation des biais
Les modèles linéaires logiques (LLM) peuvent présenter des biais dans leurs données d'entraînement, ce qui peut entraîner la diffusion de fausses informations et constitue l'un des risques associés à l'intelligence artificielle générative . Un cadre d'évaluation complet permet d'identifier et de mesurer les biais dans les résultats des LLM, offrant ainsi aux chercheurs la possibilité d'élaborer des stratégies de détection et d'atténuation de ces biais.
4. Satisfaction et confiance des utilisateurs
L'évaluation de la satisfaction et de la confiance des utilisateurs est essentielle pour tester les modèles de langage génératifs. La pertinence, la cohérence et la diversité sont évaluées afin de garantir que les modèles répondent aux attentes des utilisateurs et inspirent confiance. Ce cadre d'évaluation permet de comprendre le niveau de satisfaction et de confiance des utilisateurs vis-à-vis des réponses générées par les modèles.
5. Évaluation des systèmes RAG
L'évaluation LLM permet d'évaluer la qualité des réponses générées par les systèmes de génération augmentée par la recherche (RAG) . Différents ensembles de données peuvent être utilisés pour vérifier l'exactitude des réponses.
Quels sont les défis communs des méthodes d'évaluation des LLM existantes ?
Bien que les méthodes d'évaluation existantes pour les grands modèles de langage (LLM) fournissent des informations précieuses, elles ne sont pas parfaites. Les problèmes courants qui leur sont associés sont les suivants :
Surapprentissage
Scale AI a constaté que certains modèles linéaires à longue portée (LLM) présentent un surapprentissage sur les benchmarks d'IA populaires. Ils ont créé GSM1k, une version allégée du benchmark GSM8k pour les tests mathématiques. Les performances des LLM sur GSM1k étaient inférieures à celles sur GSM8k, ce qui indique un manque de compréhension réelle. Ces résultats suggèrent que les méthodes d'évaluation actuelles de l'IA peuvent être trompeuses en raison du surapprentissage, soulignant ainsi la nécessité de méthodes de test supplémentaires, telles que GSM1k.
Manque de mesures diversifiées
Les techniques d'évaluation utilisées aujourd'hui pour les mémoires de maîtrise en apprentissage (LLM) ne rendent souvent pas compte de toute la diversité et de l'innovation des résultats. L'importance cruciale de produire des réponses diversifiées et créatives est parfois négligée par les indicateurs traditionnels qui privilégient l'exactitude et la pertinence. La recherche sur l'évaluation de la diversité des résultats des LLM est toujours en cours. Bien que la perplexité mesure la capacité d'un modèle à anticiper le texte, elle ignore des éléments essentiels comme la cohérence, la prise en compte du contexte et la pertinence. Par conséquent, se fier uniquement à l'ambiguïté ne permettrait pas d'évaluer pleinement la qualité réelle d'un LLM.
Subjectivité et coût élevé des évaluations humaines
L'évaluation humaine est une méthode précieuse pour évaluer les résultats des grands modèles de langage (LLM). Cependant, elle peut être subjective, biaisée et nettement plus coûteuse que les évaluations automatisées. Les opinions des différents évaluateurs humains peuvent diverger et les critères d'évaluation peuvent manquer d'homogénéité. De plus, l'évaluation humaine peut s'avérer longue et onéreuse, notamment pour les évaluations à grande échelle. Les évaluateurs sont souvent en désaccord sur des aspects subjectifs tels que l'utilité ou la créativité, ce qui rend difficile l'établissement d'une vérité de référence fiable pour l'évaluation.
Biais dans les évaluations automatisées
Les évaluations LLM souffrent de biais prévisibles. Nous avons fourni un exemple pour chaque biais, mais les cas inverses sont également possibles (par exemple, certains modèles peuvent favoriser les derniers éléments).
- Biais lié à l'ordre : les premiers éléments sont favorisés.
- L'empathie s'estompe : les noms sont privilégiés par rapport aux codes anonymes.
- Biais d'ego : Les réponses similaires sont privilégiées
- Biais de saillance : les réponses plus longues sont préférées.
- Effet d'entraînement : L'opinion majoritaire est privilégiée
- Biais attentionnel : On préfère partager davantage d'informations non pertinentes.
Données de référence limitées
Certaines méthodes d'évaluation, comme BLEU ou ROUGE, nécessitent des données de référence pour la comparaison. Or, l'obtention de données de référence de haute qualité peut s'avérer complexe, notamment en présence de plusieurs réponses acceptables ou pour des tâches ouvertes. Des données de référence limitées ou biaisées risquent de ne pas couvrir l'ensemble des résultats acceptables du modèle.
Généralisation à des scénarios réels
Les méthodes d'évaluation se concentrent généralement sur des jeux de données ou des tâches de référence spécifiques qui ne reflètent pas pleinement les défis des applications réelles. L'évaluation de jeux de données contrôlés peut ne pas être facilement généralisable aux contextes divers et dynamiques dans lesquels les modèles linguistiques logiques sont déployés.
Attaques adverses
Les modèles linéaires latents (LLM) peuvent être vulnérables aux attaques adverses, telles que la manipulation des prédictions du modèle et l'empoisonnement des données, où des entrées soigneusement conçues peuvent induire le modèle en erreur. Les méthodes d'évaluation existantes ne tiennent souvent pas compte de ces attaques, et l'évaluation de la robustesse demeure un domaine de recherche actif.
Outre ces problèmes, les modèles d'IA génératifs d'entreprise peuvent se heurter à des difficultés juridiques et éthiques , susceptibles d'affecter les LLM au sein de votre entreprise.
Complexité et coût de l'évaluation multidimensionnelle
Les grands modèles de langage (GML) doivent être évalués selon divers critères, tels que l'exactitude factuelle, la toxicité et les biais. Cette évaluation implique souvent des compromis, ce qui rend difficile l'élaboration de systèmes de notation unifiés. Une évaluation approfondie de ces modèles, portant sur de multiples dimensions et ensembles de données, exige des ressources de calcul considérables, ce qui peut en limiter l'accès pour les petites organisations.
Meilleures pratiques pour surmonter les problèmes des méthodes d'évaluation des LLM
Chercheurs et praticiens explorent diverses approches et stratégies pour résoudre les problèmes liés aux méthodes d'évaluation des performances des grands modèles de langage. Bien qu'il puisse s'avérer extrêmement coûteux d'appliquer toutes ces approches à chaque projet, la connaissance de ces bonnes pratiques peut contribuer à la réussite des projets de modélisation de langage.
Données d'entraînement connues
Tirer parti des modèles de base qui partagent leurs données d'entraînement pour éviter toute contamination.
Métriques d'évaluation multiples
Au lieu de se fier uniquement à la perplexité, il est préférable d'intégrer plusieurs indicateurs d'évaluation pour une analyse plus complète des performances des modèles linéaires. Des indicateurs comme ceux-ci permettent de mieux appréhender les différents aspects de la qualité du modèle :
- Aisance
- Coherence
- Pertinence
- Diversité
- Compréhension du contexte
Évaluation humaine améliorée
Des directives claires et des critères standardisés peuvent améliorer la cohérence et l'objectivité de l'évaluation humaine. Le recours à plusieurs évaluateurs et la réalisation de contrôles de fiabilité inter-évaluateurs peuvent contribuer à réduire la subjectivité. De plus, l'évaluation participative peut fournir des perspectives diverses et permettre des évaluations à plus grande échelle.
Données de référence diverses
Créer des données de référence diversifiées et représentatives pour mieux évaluer les résultats des modèles linguistiques. La constitution d'ensembles de données couvrant un large éventail de réponses acceptables, l'encouragement des contributions de sources diverses et la prise en compte de différents contextes peuvent améliorer la qualité et la couverture des données de référence.
Intégration de plusieurs indicateurs
Encouragez la production de réponses diversifiées et évaluez l'originalité du texte généré par des méthodes telles que la diversité des n-grammes ou les mesures de similarité sémantique.
Évaluation en situation réelle
L'intégration de scénarios et de tâches réels aux méthodes d'évaluation peut améliorer la généralisation des performances des modèles de langage. L'utilisation d'ensembles de données d'évaluation spécifiques à un domaine ou à un secteur d'activité permet une évaluation plus réaliste des capacités du modèle.
Évaluation de la robustesse
L'évaluation de la robustesse des modèles linéaires logiques (LLM) face aux attaques adverses fait l'objet de recherches continues. Le développement de méthodes d'évaluation permettant de tester la résilience du modèle face à diverses entrées et scénarios adverses peut améliorer la sécurité et la fiabilité des LLM.
Tirer parti de LLMOps
LLMOps , une branche spécialisée du MLOps , se consacre au développement et à l'amélioration des LLM. L'utilisation de LLMOps pour tester et personnaliser les LLM au sein de votre entreprise permet non seulement de gagner du temps, mais aussi de minimiser les erreurs.
Exemples pratiques d'évaluation de LLM
Plusieurs organisations ont partagé leurs expériences pratiques en matière d'évaluation des LLM :
Considérations éthiques dans l'évaluation des LLM
Si les indicateurs de performance et l'analyse comparative sont essentiels, les entreprises doivent également prendre en compte les implications éthiques de l'évaluation des LLM. Celles-ci incluent :
- Équité : Les modèles peuvent produire des résultats biaisés qui reflètent des problèmes systémiques dans leurs données d’entraînement. Les cadres d’évaluation doivent mesurer les biais en fonction des caractéristiques démographiques, des contextes et des applications.
- Transparence : La documentation claire des ensembles de données, des critères d'évaluation et des limites du modèle renforce la confiance et la responsabilité.
- Responsabilité : Les entreprises qui déploient des LLM doivent s'assurer que leurs processus d'évaluation sont conformes aux cadres juridiques et réglementaires pertinents, notamment dans les secteurs de la santé , de la finance et du gouvernement .
- Déploiement responsable : les évaluations doivent mesurer non seulement la précision, mais aussi l’impact social, la sécurité et le risque de mésusage. Cela peut inclure des tests d’intrusion et des simulations d’attaques pour identifier les risques.
En intégrant des considérations éthiques dans les cadres d'évaluation, les organisations peuvent atténuer les risques d'atteinte à leur réputation, garantir la conformité et favoriser la confiance des utilisateurs.
Dernières tendances en matière d'évaluation des LLM
La recherche en évaluation des LLM évolue rapidement. Parmi les tendances notables, on peut citer :
- Benchmaxxing : Des modèles comme Llama 4 ont été sur-entraînés aux préférences du public dans des communautés telles que LMArena. Ce sur-entraînement a été obtenu en soumettant plusieurs modèles à la communauté et en sélectionnant le plus populaire. Le modèle s'est avéré inefficace face à des tâches concrètes. 14
- Évaluation multimodale : à mesure que les modèles s’étendent au-delà du texte pour inclure les images, l’audio et la vidéo, les cadres d’évaluation sont étendus pour tester la compréhension et la génération multimodales.
- Création de benchmarks dynamiques : au lieu d’ensembles de données statiques que les modèles peuvent sur-apprendre, les chercheurs développent des benchmarks adaptatifs qui évoluent (par exemple, des suites de tests spécifiques au domaine générées automatiquement).
- LLM-as-a-judge 2.0 : Des stratégies d’incitation améliorées et des évaluations de la chaîne de pensée permettent des évaluations automatisées plus fiables qui correspondent mieux aux jugements humains.
- Évaluation comparative axée sur l'énergie : les évaluations comparatives axées sur la durabilité qui évaluent le coût du carbone et l'efficacité énergétique gagnent du terrain.
- Cadres d'évaluation par équipes rouges : les tests adverses systématiques deviennent une partie intégrante des chaînes d'évaluation, permettant de mesurer la robustesse face à la manipulation et aux comportements dangereux.
Que pensent les chercheurs de premier plan des évaluations ?
La confiance s'érode dans les évaluations qui ne sont plus capables d'évaluer avec précision la performance des modèles :
Glossaire des termes clés
Pour les lecteurs qui découvrent ce domaine, voici un bref récapitulatif des indicateurs d'évaluation essentiels :
- Perplexity: Une mesure de la qualité de prédiction du texte par le modèle ; plus bas est mieux.
- BLEU (Bilingual Evaluation Understudy) : Mesure le chevauchement entre les traductions automatiques et les traductions humaines.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation) : Compare les résumés générés par machine à des références écrites par des humains.
- Précision : Proportion de résultats corrects par rapport à l'ensemble des résultats.
- Rappel : Capacité à extraire les résultats pertinents parmi tous les résultats corrects possibles.
- Score F1 : Moyenne harmonique de l'exactitude et du rappel.
- Coherence : Flux logique et cohérence du texte généré.
- Diversité : Unicité et variabilité des résultats du modèle, souvent mesurées à l'aide de n-grammes ou de similarité sémantique.
- Classement Elo : Un système de classement compétitif adapté des échecs pour comparer les modèles directement entre eux.
Conclusion
L'évaluation des grands modèles de langage est cruciale tout au long de leur cycle de vie, depuis la sélection et l'ajustement fin jusqu'au déploiement sécurisé et fiable. À mesure que les capacités des grands modèles de langage augmentent, il devient insuffisant de se fier uniquement à une seule métrique (comme la perplexité) ou à un seul benchmark. Par conséquent, une stratégie multidimensionnelle intégrant des scores automatisés (par exemple, BLEU/ROUGE, vérifications de la cohérence factuelle), des évaluations humaines structurées (avec des directives spécifiques et une concordance inter-évaluateurs) et des tests personnalisés de biais, d'équité et de toxicité est essentielle pour évaluer à la fois les performances quantitatives et les risques qualitatifs.
Des défis importants subsistent néanmoins. Les benchmarks publics peuvent induire un surapprentissage sur des jeux de données largement exploités, tandis que les évaluations avec intervention humaine sont chronophages et complexes à mettre en œuvre à grande échelle. Les entrées adverses révèlent des failles de robustesse, et les modèles énergivores soulèvent des questions de durabilité. Pour y remédier, il est nécessaire de constituer des suites de tests diversifiées et spécifiques au domaine ; d’intégrer des tests de résistance (red team et tests adverses) ; de déployer des pipelines LLM-as-juge pour une évaluation rapide et économique ; et de suivre les coûts énergétiques et d’inférence parallèlement aux indicateurs de précision.
En intégrant ces bonnes pratiques à un cadre LLMOps, les organisations peuvent maintenir une vision fiable et continue du comportement des modèles en production. Cette stratégie d'évaluation holistique atténue les risques tels que les biais, les hallucinations et les failles de sécurité, et garantit que les modèles logiques logiques (LLM) produisent des résultats fiables et à fort impact tout au long de leur évolution.
FAQ
Les organisations utilisent généralement une combinaison de métriques d'évaluation prédéterminées couvrant un large éventail de compétences pour évaluer les modèles de langage. L'évaluation quantitative des performances du modèle est assurée par des mesures automatisées telles que la précision sur des bases de données de référence standardisées (par exemple, Massive Multitask Language Understanding, Stanford Question Answering Dataset). Les cadres d'évaluation complets incluent également une évaluation humaine afin d'apprécier des facteurs qualitatifs comme l'utilité et les considérations éthiques. L'approche la plus fiable combine le jugement humain et les métriques automatisées, en évaluant les situations d'évaluation contextuelles, la génération augmentée par la recherche et la capacité du modèle à respecter les modèles de requêtes tout en restant fidèle à la réalité.
Dans le processus d'évaluation des modèles de langage (LLM), les jeux de données d'évaluation ont une fonction fondamentalement différente de celle des données d'entraînement. Les jeux de données d'évaluation évaluent la compréhension globale et les capacités de généralisation du modèle, tandis que les données d'entraînement servent à son fonctionnement. Une grande variété de cas d'utilisation, incluant des situations typiques et des cas limites susceptibles de mettre l'architecture du modèle à l'épreuve, doit être représentée dans des jeux de données d'évaluation efficaces. Contrairement aux données d'entraînement, les jeux de données d'évaluation doivent être soigneusement sélectionnés afin d'éviter toute contamination (chevauchement avec les données d'entraînement) et doivent contenir une variété d'instances permettant d'évaluer le modèle sous différents aspects, tels que la logique, la factualité et le comportement moral. La principale différence réside dans le fait que les jeux de données d'évaluation offrent des critères impartiaux permettant de comparer méthodiquement différents LLM.
L'évaluation la plus complète des performances d'un modèle de langage (LLM) est obtenue par une combinaison de tests hors ligne (expériences contrôlées) et d'évaluation en ligne (évaluation en temps réel avec de véritables utilisateurs). Les tests en ligne révèlent des problèmes qui pourraient passer inaperçus dans un environnement contrôlé, en montrant comment le modèle se comporte dans des scénarios réels et imprévisibles. Parallèlement, les tests hors ligne, réalisés avec des bancs d'essai établis, permettent des comparaisons fiables entre les modèles et leurs versions. Ensemble, ces deux approches produisent une évaluation synthétique qui englobe l'utilité pratique du modèle ainsi que ses capacités techniques. Cette double approche est particulièrement cruciale pour l'évaluation des grands modèles de langage destinés aux systèmes d'intelligence artificielle, où les performances doivent être fiables dans un large éventail de circonstances et où les questions d'éthique imposent des tests approfondis avant toute diffusion publique.
Pour en savoir plus
Pour en savoir plus sur les LLM, consultez ChatGPT et lisez :
- Transformation par l'IA : 6 stratégies concrètes pour réussir
- Cas d'utilisation, avantages et défis de ChatGPT dans le domaine de l'éducation
- Comment utiliser ChatGPT en entreprise : les 40 meilleures applications
- GPT-5: Guide détaillé
Citer cette recherche
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Évaluation des grands modèles de langage en : plus de 10 indicateurs et méthodes}},
year = {2026},
month = may,
howpublished = {\url{https://aimultiple.com/large-language-model-evaluation}},
note = {AIMultiple. Retrieved Mai 22, 2026}
}

Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.