Comparatif des meilleurs outils de reconnaissance d'images
Nous avons évalué les configurations API par défaut d'Amazon Rekognition, de Google Cloud Vision et de Microsoft Azure IA Vision sur 100 images réparties sur 5 classes d'objets, et comparé leurs tarifs et leur couverture fonctionnelle.
Résultats du benchmark des outils de reconnaissance d'images
Aperçu des performances à IoU=0.5
Les métriques de performance de trois plateformes de reconnaissance d'images ont été évaluées à un seuil d'Intersection over Union (IoU) de 0.5, en comparant les valeurs de mAP, de score F1, de rappel et de précision.
Le mAP est la métrique d'évaluation principale à considérer pour les tâches de détection d'objets, car il fournit une mesure complète de la qualité de détection à travers différents seuils de confiance et classes d'objets.
Vous pouvez en savoir plus sur notre méthodologie de benchmark.
Précision moyenne par classe (AP) à IoU=0.5
Les trois services détectent les personnes de manière fiable mais perdent en précision sur les équipements de protection, les casques affichant la baisse la plus marquée.
Alors qu'Amazon et Google affichent une faible précision dans la détection des gants et des chapeaux, Microsoft Azure IA Vision atteint une précision de 0% pour ces deux catégories. Azure IA Vision ne détecte pas les objets qui sont petits (moins de 5% de l'image) ou disposés de manière rapprochée, ce qui pourrait contribuer à la faible précision observée dans la détection des gants et des chapeaux.1
Aucun des services ne peut détecter avec succès les masques (précision de 0%), ce qui met en évidence une lacune critique dans leurs capacités de reconnaissance d'objets lorsqu'ils sont utilisés avec les paramètres par défaut sans étiquetage personnalisé.
Vous pouvez en savoir plus sur les limites de la reconnaissance d'images.
mAP à différents seuils IoU [0.5:0.05:0.95]
À mesure que les seuils IoU se resserrent de 0.5 à 0.95, le mAP diminue pour les trois services, mais à des rythmes différents. Amazon Rekognition résiste le mieux sur l'ensemble de la plage, ce qui suggère un alignement des boîtes englobantes plus précis que les deux autres services.
Facteurs potentiels influençant les différences de performance
Orientation de l'entraînement des modèles et portée du produit
- Amazon Rekognition inclut des capacités dédiées aux EPI, ce qui se traduit probablement par une meilleure couverture d'entraînement et des représentations de caractéristiques plus riches pour des objets tels que les casques et les gants.
- Google Cloud Vision et Azure IA Vision privilégient les tâches générales de compréhension d'image (par exemple, OCR, monuments, marques, détection Web), reléguant les EPI et objets similaires au second plan dans leurs objectifs d'entraînement.
Configuration API par défaut et compromis précision-rappel
- Tous les services ont été évalués en utilisant les paramètres par défaut, qui privilégient généralement une haute précision pour minimiser les faux positifs.
- Ce choix de conception conduit à des scores de précision élevés chez tous les fournisseurs mais à un rappel significativement plus faible, en particulier pour les objets moins proéminents.
Limitations de la détection des petits objets
- Les objets tels que les gants, les chapeaux et les casques occupent souvent une petite fraction de l'image, ce qui les rend difficiles à détecter de manière fiable.
- Azure IA Vision, qui est documenté comme ayant des performances inférieures sur les objets petits ou rapprochés, montre la dégradation la plus prononcée dans ces catégories.
Taxonomie des étiquettes et correspondance d'évaluation
- Les étiquettes spécifiques à chaque fournisseur ont dû être mappées à une taxonomie de vérité terrain unifiée.
- Les détections valides utilisant des étiquettes non correspondantes ou plus granulaires peuvent avoir été exclues de l'évaluation.
Absence de détection des masques
- Aucun des services évalués n'expose d'étiquettes d'objets liées aux masques dans leurs API par défaut.
- Les trois ont donc retourné une précision de 0% pour les masques.
Sensibilité à l'IoU et qualité de localisation
- Les différences de performance augmentent à des seuils IoU plus élevés, où un alignement plus strict des boîtes englobantes est requis.
- Amazon Rekognition maintient un mAP relativement plus élevé à ces seuils, ce qui suggère une meilleure précision de localisation.
Méthodologie du benchmark des outils de reconnaissance d'images
Nous avons testé les performances prêtes à l'emploi (c'est-à-dire sans étiquetage personnalisé) de ces fournisseurs dans des cas réels.
Nous avons utilisé 100 images. Nous avons redimensionné les images à 512×512 pixels tout en préservant les régions essentielles contenant des instances, car le jeu de données d'origine comprenait des dimensions variables.
Nous souhaitons exécuter ce test à nouveau sans que les fournisseurs n'entraînent leurs solutions sur le jeu de données. Par conséquent, nous ne divulguons pas le jeu de données que nous avons utilisé pour ce benchmark.
Nous avons traité les réponses des API des fournisseurs de services de la manière suivante :
- mappé les étiquettes des fournisseurs de services aux catégories de vérité terrain définies dans le tableau ci-dessus. Les étiquettes des fournisseurs de services qui ne correspondaient pas à ces étiquettes de vérité terrain ont été exclues de l'évaluation.
- normalisé les formats de boîtes englobantes des différents fournisseurs
- calculé l'IoU entre les boîtes prédites et les boîtes de vérité terrain
- apparié les prédictions à la vérité terrain en fonction du seuil IoU
- calculé les métriques : précision, rappel, F1 et AP par catégorie
- calculé le mAP de style COCO en utilisant les seuils 0.5-0.95
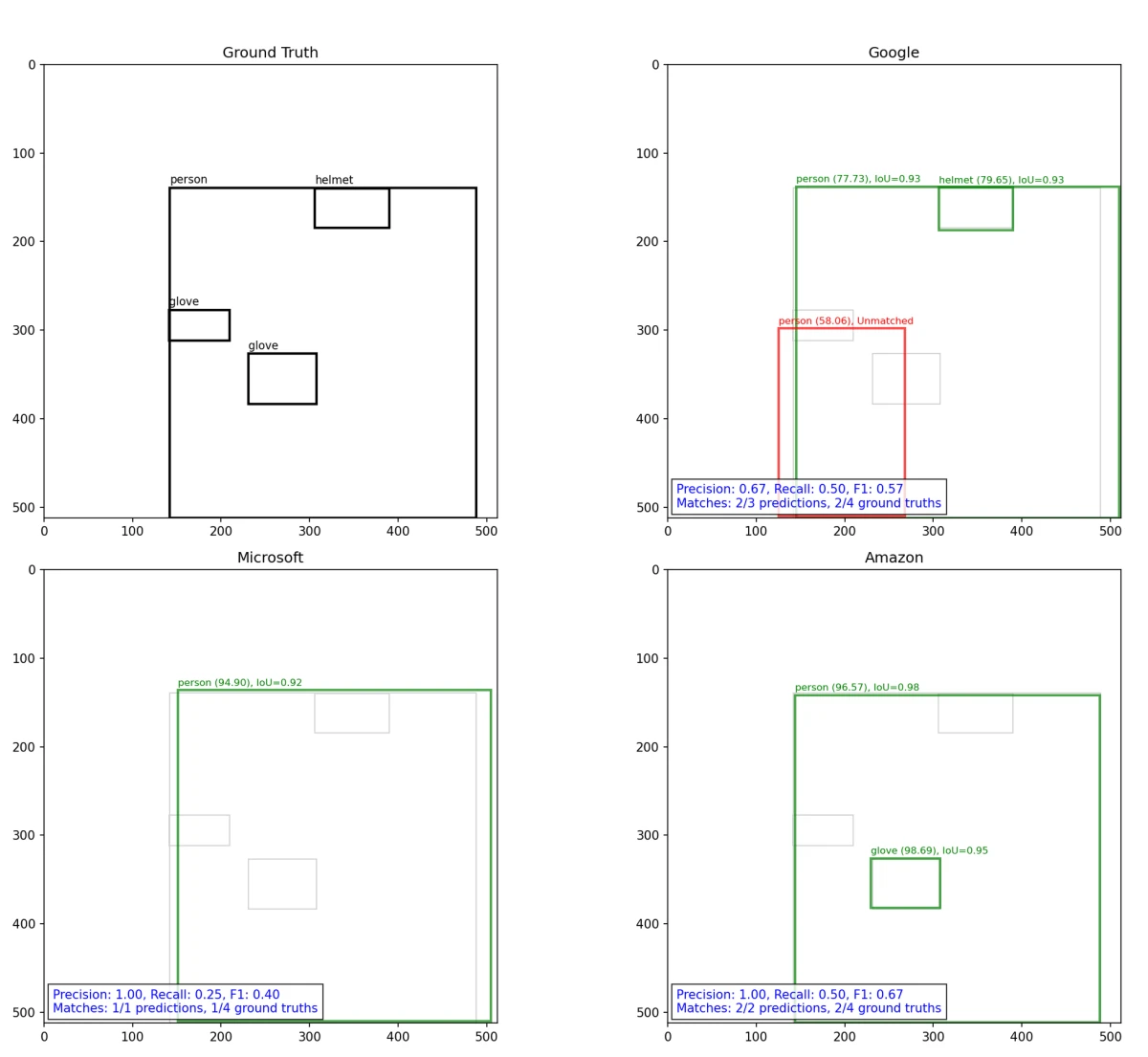
Un exemple de calcul de l'IoU, de la précision, du rappel et du F1 est donné dans la figure ci-dessous :
Métriques du benchmark
Précision
La précision mesure l'exactitude des prédictions positives faites par le modèle. En reconnaissance d'images, pour une classe donnée (par exemple, « personne »), elle répond à la question : « Parmi toutes les images que le modèle a étiquetées comme contenant une personne, combien en contiennent réellement ? ». C'est crucial dans les scénarios où les faux positifs (étiqueter incorrectement une image comme positive) sont coûteux.
Rappel
Le rappel mesure l'exhaustivité des prédictions positives, répondant à la question : « Parmi toutes les images qui contiennent réellement la classe, combien le modèle a-t-il correctement identifiées ? » C'est vital lorsqu'il est critique de ne pas manquer une instance positive (faux négatif).
Score F1
Le score F1 est la moyenne harmonique de la précision et du rappel, fournissant une mesure équilibrée particulièrement utile lorsqu'il y a une distribution inégale des classes (par exemple, peu d'images de casques par rapport aux images sans casque). C'est une métrique unique qui capture à la fois les faux positifs et les faux négatifs.
mAP
Le mAP, ou mean Average Precision, est une métrique principalement utilisée dans les tâches de détection d'objets en reconnaissance d'images. Il évalue la précision du modèle à travers différentes classes en faisant la moyenne de la précision moyenne (AP) de chaque classe. L'AP elle-même est l'aire sous la courbe précision-rappel, qui est générée en faisant varier le seuil de confiance pour les détections.
Cet outil interactif vous permet de comparer les résultats de détection entre les fournisseurs en utilisant des images d'exemple du jeu de données. Utilisez les boutons du haut pour sélectionner Amazon, Google, Microsoft ou tous les fournisseurs. Affichez la vérité terrain avec la case à cocher. Naviguez entre les images de test en utilisant les boutons numérotés sur la gauche. Des boîtes colorées montrent chaque détection avec les scores de confiance.
Meilleures API de reconnaissance d'images
Amazon Rekognition
Amazon Rekognition inclut des API dédiées à la détection d'EPI aux côtés de la détection générale d'objets et de visages, ce qui lui confère une couverture d'étiquettes plus large sur des classes telles que les casques et les gants que les deux autres services. Cette portée produit est cohérente avec les résultats d'AP par classe dans le benchmark.
Ses API d'image sont divisées en deux groupes :
- Groupe 1 (identification faciale) : CompareFaces, IndexFaces, SearchFaces, utilisés pour la vérification d'identité et la recherche de visages dans des collections d'images.
- Groupe 2 (analyse de contenu) : DetectLabels (détection générale d'objets), DetectModerationLabels, DetectText, RecognizeCelebrities, DetectPPE.
Il s'intègre avec le reste d'AWS (S3 pour le stockage, Lambda pour le traitement piloté par événements, SageMaker pour l'entraînement de modèles personnalisés).
Google Cloud Vision
Google Cloud Vision a dépassé 89% de précision à IoU=0.5, le même plancher de précision que les deux autres services, mais a produit un rappel plus faible sur les petits objets et les équipements de protection. Sa portée produit penche vers la compréhension d'image à usage général plutôt que la détection industrielle : OCR, reconnaissance de monuments, identification de logos et de marques, et détection Web (mise en correspondance d'une image avec des images indexées publiquement).
Capacités principales :
- Localisation d'objets et détection d'étiquettes
- OCR pour le texte imprimé et manuscrit en plusieurs langues
- Détection de monuments, de logos et de célébrités
- Détection Web pour la recherche d'images inversée
- Entraînement de modèles personnalisés via Vertex IA
Il s'intègre avec Cloud Storage, BigQuery et Google Workspace, et accepte une gamme plus large de formats de fichiers que Rekognition (JPEG, PNG, GIF, BMP, WEBP, RAW, ICO, PDF, TIFF).
Microsoft Azure IA Vision
Microsoft Azure IA Vision fournit l'analyse d'image, l'OCR, le sous-titrage d'image et un service distinct de suppression d'arrière-plan. Sa documentation note que le détecteur d'objets ne gère pas de manière fiable les objets petits ou rapprochés, il se positionne donc davantage vers la compréhension générale d'image et la lecture de texte que la détection fine d'objets.
Les capacités principales sont divisées en deux groupes :
- Groupe 1 (détection d'éléments visuels) : étiquetage, visage, détection d'objets, détection de marques et de monuments, recadrage intelligent, OCR.
- Groupe 2 (sortie sensible au langage) : description d'image, sous-titres denses, lecture complète (OCR de document).
Fonctionnalités différenciantes des fournisseurs de services
Aperçu de la tarification des API
Création de modèles de vision personnalisés
Les API hébergées telles qu'Amazon Rekognition, Google Cloud Vision et Microsoft Azure IA Vision renvoient des prédictions à partir d'un ensemble d'étiquettes fixe défini par le fournisseur. Lorsqu'une classe d'objets requise est absente de cet ensemble, ou lorsque la précision sur un domaine spécifique est trop faible, l'alternative est d'entraîner un modèle personnalisé. Roboflow est un exemple qui couvre ce flux de travail.
Roboflow
Roboflow est une plateforme de vision par ordinateur qui couvre l'annotation de données, l'entraînement de modèles et le déploiement. Elle fonctionne sur un modèle différent des API de détection hébergées ci-dessus : les utilisateurs entraînent des modèles sur leurs propres jeux de données étiquetés et exécutent l'inférence sur leur propre matériel, plutôt que d'appeler un endpoint géré. C'est la voie que les équipes empruntent lorsque les API cloud par défaut n'exposent pas d'étiquettes pour une classe d'objets spécifique, comme les masques qui ont retourné une précision de 0% sur les trois services évalués.
Roboflow comprend trois composants principaux :
- RF-DETR : un modèle en temps réel basé sur transformer pour la détection et la segmentation d'objets, destiné aux entrées de caméra en direct et vidéo.2
- AutoDistill : un outil qui utilise de grands modèles de fondation pour étiqueter automatiquement des jeux de données d'images sans annotation manuelle.3
- Inference : un package de déploiement prenant en charge plusieurs backends (ONNX, TensorRT, PyTorch), avec exécution sur GPU, CPU ou appareils edge tels que NVIDIA Jetson via un service Dockerisé.4
Edge computing dans la reconnaissance d'images
La reconnaissance d'images basée sur le cloud envoie chaque image à un centre de données distant pour analyse. L'edge computing exécute le modèle sur l'appareil qui a capturé l'image, de sorte que le résultat (une étiquette, une alerte, un drapeau) quitte l'appareil.
Fonctionnement de l'edge computing
Dans une configuration cloud, les caméras agissent comme des collecteurs de données et diffusent des images brutes en amont ; le modèle réside dans le centre de données. Dans une configuration edge, l'appareil exécute le réseau de neurones localement et transmet la sortie pertinente : « personne détectée », « inventaire bas », « défaut trouvé ».
Pourquoi c'est important pour la reconnaissance d'images
- Latence : l'inférence locale élimine l'aller-retour cloud, ce qui est important pour les véhicules autonomes, les robots de fabrication et tout système qui doit agir sur la prédiction en quelques millisecondes.
- Confidentialité : les images ne quittent pas l'appareil, ce qui est utile lorsque des contraintes de résidence des données ou de RGPD s'appliquent (imagerie médicale, CCTV en magasin).
- Bande passante et coût : les métadonnées sont téléchargées, pas la vidéo complète, ce qui réduit les coûts réseau et d'API cloud pour les déploiements à haut volume.
- Fonctionnement hors ligne : les appareils edge continuent de fonctionner lorsque le réseau tombe en panne, ce qui est requis pour les systèmes de sécurité et les sites industriels distants.
Exemples concrets d'IA edge dans la reconnaissance d'images
SDK embarqué Captur
Le traitement embarqué est la forme la plus courante d'IA edge dans les contextes mobiles. Captur fournit un SDK de vérification d'image embarqué qui exécute des modèles de vision par ordinateur localement sur les appareils mobiles en environ 30ms, même hors ligne.5 Le fournisseur logistique GoBolt a intégré le SDK de Captur dans son application chauffeur pour la vérification de preuve de livraison et a rapporté une baisse de 30% des réclamations de livraison non reçue dès la première semaine.6
Ultralytics YOLO26
YOLO26 d'Ultralytics est un modèle de vision par ordinateur open source conçu pour les appareils edge et à faible consommation. Son architecture entièrement de bout en bout, gratuit de NMS, supprime les étapes de post-traitement telles que la suppression non maximale, réduisant la latence et améliorant l'exportabilité vers le matériel edge tout en prenant en charge la détection d'objets, la segmentation, la classification et l'estimation de pose au sein d'une même famille de modèles.7
Transformers de vision dans la reconnaissance d'images
Les API de reconnaissance d'images évaluées ici utilisent des détecteurs basés sur CNN. Les Vision Transformers (ViTs) sont une architecture alternative qui divise l'image en patchs de taille fixe (typiquement 16×16 pixels) et traite tous les patchs en parallèle, ce qui permet au modèle de relier des régions distantes de l'image dès la première couche plutôt que de construire ce contexte progressivement à travers des convolutions empilées.
Pour la détection d'objets, cela importe lorsque l'identité d'un objet dépend de la scène environnante (un chapeau sur une personne versus un chapeau sur une étagère). Les CNN capturent cela par des convolutions empilées ; les ViTs le capturent par l'attention sur tous les patchs en une seule fois.
Les trois services cloud de ce benchmark exécutent tous des modèles basés sur CNN en production. Des architectures hybrides CNN-Transformer apparaissent dans les nouveaux modèles open source (par exemple, RF-DETR de Roboflow utilise un backbone transformer DINOv2), mais les API cloud de production n'ont pas encore migré.
Modèles de transformers de vision pour la reconnaissance d'images
- ViT de Google : le Vision Transformer original, entraîné sur ImageNet pour la classification d'images. Disponible sur Hugging Face avec des poids pré-entraînés.
- Swin Transformer : utilise un mécanisme de fenêtre décalée pour capturer à la fois les détails globaux et locaux, utilisé pour la détection et la segmentation.
- DINOv2 (Meta) : modèle auto-supervisé entraîné sans étiquettes manuelles, produisant des embeddings d'image à usage général.
- Segment Anything Model (SAM) : segmenteur basé sur ViT qui peut isoler des objets sur lesquels il n'a pas été entraîné.
Cas d'usage des logiciels de reconnaissance d'images
Dans le paysage numérique actuel, les technologies de vision par ordinateur et de traitement d'images ont transformé la façon dont les entreprises exploitent les données visuelles. Les algorithmes avancés de classification d'images permettent des outils de reconnaissance d'images sophistiqués qui redéfinissent les opérations dans tous les secteurs.
Ces technologies de reconnaissance d'images combinent des approches puissantes d'entraînement de modèles avec des interfaces intuitives qui permettent aux utilisateurs d'automatiser des tâches visuelles complexes. Des solutions de vision personnalisée pour des besoins métier spécifiques aux systèmes de reconnaissance faciale pour la sécurité, ces outils peuvent identifier des motifs, des objets et des caractéristiques dans les images.
Inspection visuelle
La reconnaissance d'images permet une inspection visuelle automatisée dans de nombreux secteurs. Ces systèmes identifient des objets, détectent des caractéristiques et vérifient la compatibilité en analysant des données visuelles.
Par exemple, Chamberlain Group a mis en œuvre Amazon Rekognition dans leur application myQ, permettant aux utilisateurs de capturer automatiquement des images de leur ouvre-porte de garage pour vérifier la compatibilité. Cette solution rationalisée a remplacé un processus manuel complexe et a considérablement augmenté les taux de connexion des utilisateurs.8
Traitement de documents
La technologie d'OCR extrait le texte des images et des documents, automatisant la saisie de données dans plusieurs langues. Les systèmes modernes peuvent traiter du texte manuscrit et des mises en page complexes, transformant les flux de travail papier et rendant les documents consultables.
Par exemple, le groupe d'assurance français LSA Courtage utilise l'API Google Cloud Vision pour reconnaître le texte des permis de conduire et des cartes grises. Cette implémentation d'OCR a réduit le temps de traitement des documents de 45% par page et augmenté la productivité des souscripteurs de 20%, leur permettant de traiter 1 500 documents par jour.9
Vous pouvez consulter notre benchmark OCR pour voir la précision des différents outils d'OCR pour différents types de documents.
Surveillance agricole
Les agriculteurs utilisent l'imagerie par drone avec la reconnaissance d'images pour surveiller la santé des cultures, détecter les maladies et optimiser l'irrigation. En identifiant les zones de stress des cultures avant l'apparition de symptômes visibles, les agriculteurs peuvent intervenir tôt et réduire l'utilisation des ressources.
Par exemple, Project FarmBeats de Microsoft (maintenant Azure Data Manager for Agriculture) utilise des capteurs, des drones et l'apprentissage automatique pour permettre une agriculture axée sur les données dans des environnements avec une alimentation électrique et une connectivité Internet limitées. Le système aide à augmenter la productivité agricole et à réduire les coûts en combinant les données visuelles avec les connaissances des agriculteurs sur leurs terres.10
Sécurité et surveillance
Les systèmes de sécurité utilisent la reconnaissance faciale et la détection d'objets pour identifier des activités, contrôler l'accès et localiser des personnes. Ces systèmes surveillent les flux vidéo et alertent le personnel des menaces. Par exemple, Sun Finance utilise Amazon Rekognition pour vérifier l'identité des clients en comparant les selfies avec les documents d'identité, accélérant la vérification et prévenant la fraude tout en élargissant l'inclusion financière.11
Modération de contenu
Les plateformes de médias sociaux utilisent la reconnaissance d'images pour filtrer le contenu inapproprié tel que la nudité, la violence ou les images graphiques des téléchargements des utilisateurs. La génération de sous-titres peut ajouter une deuxième couche en décrivant le contexte de l'image que les classificateurs au niveau des pixels manquent, par exemple en détectant des symboles de haine en arrière-plan d'une photo autrement bénigne. Selon AWS, le filtrage automatique réduit généralement le volume que les modérateurs humains doivent examiner à 1–5% du total.12
Par exemple, CoStar Group utilise Amazon Rekognition pour la modération de contenu et l'analyse vidéo d'environ 150 000 téléchargements quotidiens d'images et de vidéos sur leur plateforme immobilière commerciale. Cette solution de modération de contenu analyse les images, classifie le contenu, détecte le matériel indésirable et exploite la technologie de sous-titrage d'image pour comprendre le contexte, économisant du temps tout en assurant la conformité et des données de haute qualité.13
Vous pouvez en savoir plus sur les applications de la reconnaissance d'images.
Limites de la technologie de reconnaissance d'images
Réduction des détails dans les petits objets
Lorsque les objets apparaissent petits dans les images, ils contiennent moins de pixels, ce qui entraîne des données visuelles limitées. De plus, les CNN ont tendance à perdre des détails fins importants pendant le traitement à travers les couches de sous-échantillonnage, ce qui entrave considérablement les capacités de détection.
Détections manquées
Les systèmes de reconnaissance d'images favorisent généralement les objets plus grands pendant les phases d'entraînement et d'analyse, ce qui entraîne des fréquences plus élevées de petits objets manqués ou de faux négatifs.
Interférence de l'arrière-plan
Les objets plus petits sont plus vulnérables au masquage par le bruit visuel, l'encombrement de l'arrière-plan ou les éléments qui se chevauchent, ce qui les rend plus difficiles à identifier avec précision. Même une occlusion partielle peut affecter de manière disproportionnée les petits objets, car ils ont une surface moins distinguishable au départ.
Variabilité d'échelle
Les objets apparaissant à différentes distances ou échelles posent des difficultés aux modèles qui ne sont pas spécifiquement conçus pour détecter les détails fins à travers des tailles d'objets variables.
Exigences computationnelles
Les techniques visant à améliorer la détection des petits objets, comme l'extraction de caractéristiques multi-échelles ou les entrées à plus haute résolution, nécessitent plus de puissance de traitement, limitant l'applicabilité en temps réel.
Biais d'entraînement
Les jeux de données sous-représentent souvent les petits objets ou manquent d'annotations suffisantes pour eux, réduisant la généralisation du modèle à de tels cas dans les scénarios réels.
FAQ
Un logiciel de reconnaissance d'images est un type de technologie de vision par ordinateur qui utilise des algorithmes d'apprentissage automatique pour analyser des données non structurées comme les images numériques et les données vidéo. Il va au-delà de l'identification d'objets spécifiques ; les systèmes avancés visent la compréhension de scène, interprétant le contexte et les relations au sein d'une image pour fournir une analyse plus complète. Cela permet aux ordinateurs de voir et de classifier efficacement les informations visuelles.
Aucun logiciel de reconnaissance d'images ou logiciel de vision par ordinateur n'est universellement le meilleur. Le choix idéal parmi les technologies de reconnaissance d'images dépend de vos besoins spécifiques. Tenez compte de facteurs tels que la précision requise, le type de tâches que vous devez effectuer (comme la détection d'objets ou l'OCR, et même si vous devez intégrer le traitement du langage naturel pour des tâches qui combinent la compréhension d'image avec l'analyse de texte), la facilité d'utilisation, l'évolutivité, le budget, les options de personnalisation et l'expertise technique de votre équipe. Essayer différentes options est le meilleur moyen de trouver les technologies de reconnaissance d'images qui offrent le mieux les capacités de vision par ordinateur dont vous avez besoin pour votre application.
Bien que la reconnaissance d'images se soit considérablement améliorée, la précision n'est pas garantie. Les facteurs impactant les performances incluent la qualité de l'image (éclairage, résolution), la complexité de la scène, les variations d'apparence des objets et la qualité des données d'entraînement utilisées pour les algorithmes de deep learning. Atteindre une compréhension de scène robuste et détecter avec précision des objets spécifiques peut être difficile dans des données visuelles complexes ou bruyantes.
Citez ce benchmark
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Comparatif des meilleurs outils de reconnaissance d'images}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/image-recognition-software}},
note = {AIMultiple. Consulté le 17 Juin 2026}
}
Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.