Outils CLI Agents: Codex vs Claude Code
Les outils CLI agents sont des outils de codage IA capables de créer et supprimer des fichiers, d'exécuter des commandes, de planifier et d'exécuter le codage de l'ensemble du projet. Nous avons évalué les principaux outils sur 10 scénarios réels de développement web, effectuant environ 600 vérifications de validation atomiques par agent et plus de 5 000 exécutions de tests automatisés au total, incluant la logique backend, les fonctionnalités frontend et la vérification de la cohérence sur plusieurs exécutions.
Résultats du benchmark CLI Agent
Aperçus de performance des outils CLI Agent
Codex obtient le score global le plus élevé (67,7 %) et les meilleures performances backend (58,5 %). Son score backend devance de plus de 5 points de pourcentage le deuxième meilleur, Junie (54,3 %).
Junie se classe deuxième au total (63,5 %), combinant une solidité backend correcte (54,3 %) avec de solides performances frontend (85,0 %). Son écart backend-frontend (30,7 points de pourcentage) est modéré par rapport aux autres agents, et il a terminé les 10 tâches avec l'infrastructure backend prête sur 9 d'entre elles.
Claude Code obtient le score frontend le plus élevé (95,0 %), mais son score backend (38,6 %) tire vers le bas son résultat global (55,5 %). Cela illustre la dynamique principale du graphique : les performances frontend sont relativement élevées pour plusieurs agents, tandis que la correction backend et la discipline des contrats déterminent la majeure partie de la séparation du classement.
Le plus grand écart UI-backend apparaît dans Claude Code (95,0 % frontend contre 38,6 % backend). En revanche, Codex combine un score frontend élevé (89,2 %) avec le meilleur score backend, c'est pourquoi il mène au total avec un pondération de 0,7 backend / 0,3 frontend.
Les agents moins bien classés échouent pour des raisons différentes. Goose obtient un score proche de zéro à la fois sur le backend (3,1 %) et le frontend (10,0 %), indiquant des problèmes d'exécution et de complétude de base. Forge et Cline affichent des scores frontend modérés (45,8 % et 33,3 %) mais des scores backend faibles (20,1 % et 26,7 %), cohérents avec des problèmes de contrat et de routage backend dominant leurs résultats.
Vitesse vs score & utilisation de tokens vs score
Nous avons évalué l'efficacité d'exécution en utilisant le temps d'exécution moyen (secondes), l'utilisation effective de tokens (entrée + sortie) et le score de précision combiné :
Aider occupe la région la plus équilibrée du graphique. Avec un score combiné de 52,7 %, il termine les tâches en 257 secondes et consomme 126k tokens. C'est le seul agent qui combine une précision moyenne à élevée avec un temps d'exécution relativement faible et une utilisation de tokens modérée.
Codex atteint le score global le plus élevé (67,7 %) mais à un coût plus élevé. Son temps d'exécution moyen est de 426 secondes et l'utilisation de tokens est de 258k. Le compromis d'efficacité semble proportionnel à son gain de précision.
Junie se classe deuxième en précision (63,5 %) avec un temps d'exécution moyen de 483 secondes et 370k tokens effectifs. Par rapport à Codex, il consomme 43 % de tokens en plus pour une diminution de score de 4,2 points de pourcentage. Son ratio tokens/précision est moins favorable que celui d'Aider ou de Codex, mais il surpasse Claude Code à la fois en précision et en efficacité des tokens.
Claude Code est le plus cher parmi les agents les plus performants. Il se classe troisième en précision (55,5 %) mais nécessite 745 secondes et 397k tokens. Par rapport à Aider, Claude consomme plus de 3x de tokens en plus pour une augmentation de score de 2,8 points de pourcentage.
Kiro CLI est l'agent le plus rapide, terminant en 168 secondes et obtenant un score combiné de 58,1 %. Cependant, Kiro n'a pas exposé l'utilisation de tokens. À la place, nous avons mesuré la consommation de crédits (46,1 crédits). Une comparaison complète de l'efficacité est incomplète pour Kiro, mais étant donné son utilisation de crédits, c'est l'un des moins chers.
À l'extrémité inférieure, Goose démontre une mauvaise efficacité. Il consomme 300k tokens et prend 587 secondes tout en obtenant seulement 5,2 %. Une utilisation élevée de tokens ne se traduit pas par une correction dans ce cas.
En général, une consommation de tokens plus élevée ne corrèle pas systématiquement avec une précision plus élevée. Le comportement de réessai architectural et la stratégie de validation semblent influencer l'utilisation de tokens plus que la profondeur brute de résolution de problèmes.
Vous pouvez voir notre méthodologie ci-dessous.
Comment fonctionnent les outils CLI agents
Les outils CLI agents sont des agents autonomes qui opèrent à l'intérieur du terminal. Bien que la plupart des utilisateurs les déploient pour des tâches de codage, ils peuvent exécuter n'importe quel flux de travail qui peut être effectué via des commandes shell.
Ces agents opèrent généralement dans une boucle composée de trois phases :
- Rassembler le contexte
- Agir
- Vérifier les résultats
Après vérification, l'agent rassemble le contexte mis à jour et répète la boucle jusqu'à ce qu'il termine la tâche ou atteigne une condition d'arrêt.
La boucle est influencée par deux sources :
- L'utilisateur humain, qui fournit la tâche initiale et peut interrompre l'exécution
- Le modèle, qui effectue la planification, le raisonnement et la sélection d'actions
Le framework d'agent fournit une structure autour du modèle. Il définit comment le modèle doit planifier, quand il doit exécuter des commandes, comment il doit valider les résultats et quels outils sont disponibles. Ces outils peuvent inclure l'exécution shell, l'accès au système de fichiers, le contrôle du navigateur, l'utilisation d'ordinateur, les intégrations MCP ou des « compétences » réutilisables.
Différentes architectures d'agents imposent différentes stratégies de planification, politiques de réessai et logique de vérification. Certains agents privilégient la précision et un raisonnement plus profond au prix d'une utilisation de tokens plus élevée et de latence. D'autres privilégient la vitesse et un coût réduit avec une robustesse comportementale réduite.
Intelligence du modèle vs architecture d'agent
Les différences de performance entre les outils CLI agents ne proviennent pas d'une seule source. Elles émergent de deux couches : le modèle de base et le framework d'orchestration qui l'entoure.
Le modèle de base détermine à quel point le système comprend les exigences, planifie des tâches multi-étapes et génère du code correct. Si le modèle interprète mal une contrainte ou produit une logique incorrecte, aucune quantité d'orchestration ne peut compenser entièrement cette erreur.
L'architecture de l'agent, cependant, détermine comment ce modèle est utilisé. Elle décide comment le contexte est rassemblé depuis l'espace de travail, quand les commandes shell sont exécutées, comment les sorties sont validées et si le système réessaie après un échec. Ces décisions façonnent le comportement d'exécution, le coût et la fiabilité.
Deux agents alimentés par des modèles également capables peuvent se comporter différemment. L'un peut réessayer agressivement après un échec partiel, consommant plus de tokens mais se rétablissant des erreurs précoces. L'autre peut se terminer rapidement après la première incohérence. L'un peut imposer une validation stricte avant d'avancer, tandis que l'autre peut continuer avec des hypothèses non vérifiées.
Ce benchmark évalue le système complet. Il n'isole pas l'intelligence brute du modèle de la logique d'orchestration. Lorsqu'un agent consomme excessivement de tokens ou échoue à un contrat backend, la cause peut résider dans la qualité de la planification, la politique de réessai, la gestion du contexte ou la rigueur de la validation.
Comprendre cette distinction est essentiel. Une utilisation élevée de tokens n'indique pas nécessairement un raisonnement plus profond, et un score plus bas n'implique pas automatiquement une capacité de modèle sous-jacente plus faible. Dans les environnements autonomes, l'architecture et le raisonnement du modèle interagissent continuellement.
Comportements des agents sur la tâche 6
Nous avons évalué les agents sur 10 tâches. Ci-dessous, nous présentons une ventilation détaillée de la Tâche 6 pour illustrer comment différentes architectures d'agents se comportent sous les mêmes contraintes.
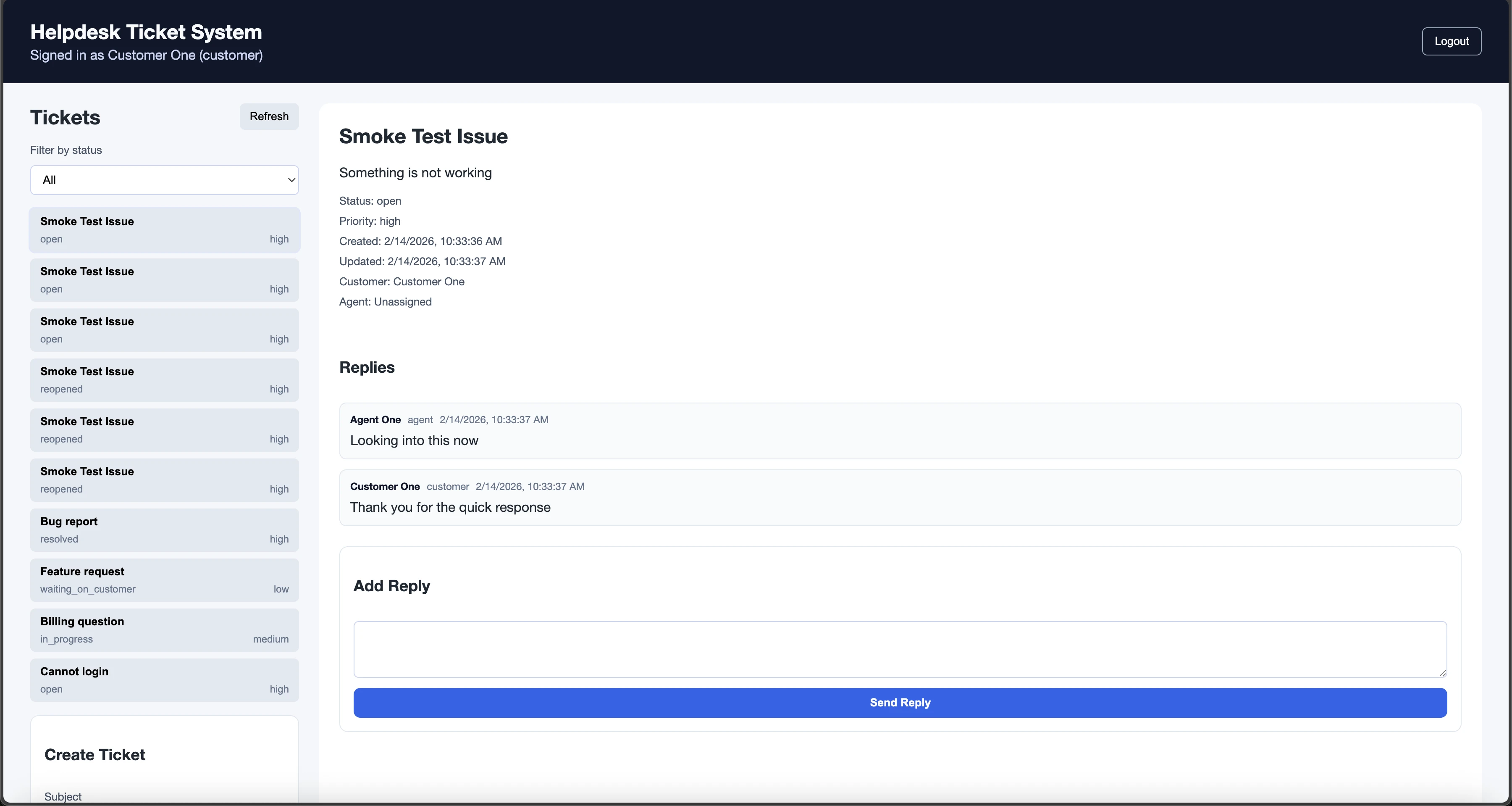
Tâche 6 : Système de tickets de support (Web)
La Tâche 6 nécessitait de construire un système de tickets de support full-stack avec :
- Deux rôles d'utilisateur (client et agent)
- Authentification basée sur JWT
- Transitions de flux de travail de statut strictes
- Isolation des données (404 au lieu de 403 pour l'accès inter-utilisateurs)
- Backend FastAPI
- Frontend React/Vue/Svelte + Vite
- Commandes d'exécution déterministes
Le test de fumée a validé :
- Vérification de santé
- Authentification double rôle
- Opérations CRUD des tickets
- Attribution et réponses
- Transitions de statut
- Application des rôles
- Isolation des données
- Connexion UI et comportement post-connexion
Cette tâche met à l'épreuve la gestion d'état, la correction de l'authentification, la discipline des contrats REST et l'intégration frontend-backend. Visitez GitHub pour voir les détails de la tâche.
Codex
Installation
Installez globalement avec :
- npm install -g @openai/codex
Alternativement, installez globalement avec Homebrew (macOS/Linux)
- brew install –cask codex
Authentification
Après avoir configuré Codex, vous pouvez continuer avec votre compte ChatGPT, ou avec votre OpenAI API Key. Aucune option de fournisseur disponible.
Rapport de tâche
Codex a construit un système fonctionnellement correct mais s'est écarté du contrat REST spécifié. Un choix de méthode a réduit la conformité stricte malgré une logique métier correcte.
Comportement Backend
L'authentification, le CRUD des tickets, les réponses et les transitions de statut ont fonctionné correctement. L'application des rôles et l'isolation des données ont été implémentées correctement.
Le problème principal était un mismatch de méthode HTTP. Codex a implémenté /tickets/{id}/assign et /tickets/{id}/status comme des endpoints PATCH, tandis que le test de fumée exigeait PUT.
Le mode adaptatif a récupéré certaines fonctionnalités en essayant des méthodes alternatives. Le mode strict a échoué toutes les étapes liées à ces endpoints.
Comportement UI
Le frontend a passé toutes les étapes de validation UI. Le flux de connexion et l'état post-connexion se sont comportés correctement.
Junie
Installation
Junie est disponible via JetBrains Toolbox ou en tant que CLI autonome :
- curl -fsSL https://junie.jetbrains.com/install | bash
Authentification
Continuez avec votre compte JetBrains ou générez une JUNIE_API_KEY sur junie.jetbrains.com/cli, ou exportez votre propre API key depuis Anthropic, OpenAI, Google ou d'autres fournisseurs pris en charge. Plusieurs options de fournisseur disponibles.
Rapport de tâche
Junie a produit un système full-stack complet en 327 secondes. L'authentification, le CRUD et l'isolation des données ont fonctionné correctement. Deux choix de conception d'endpoint ont causé six échecs backend. Le frontend a passé toutes les étapes de validation fonctionnelle mais a rendu une interface texte uniquement sans style visuel ni branding.
Comportement Backend
Junie a généré un backend FastAPI avec 8 fichiers et un frontend React + Vite avec Tailwind CSS. Les données de semis comprenaient 2 utilisateurs et 3 tickets de différents statuts.
L'authentification, le CRUD des tickets, les réponses, la vue de détail et l'isolation des données ont fonctionné correctement. Neuf des 16 étapes API ont réussi.
Les six étapes échouées provenaient de deux problèmes. Premièrement, /tickets/{id}/assign a été implémenté comme POST au lieu du PUT attendu, causant l'échec de l'étape d'attribution. Deuxièmement, aucun endpoint dédié /tickets/{id}/status n'existait. Les transitions de statut ont été gérées via un endpoint PUT /tickets/{id} unifié avec un champ de corps. Le test de fumée ciblait directement /tickets/{id}/status, retournant 404.
La logique de transition elle-même a été correctement implémentée. La carte de transition valide a imposé open vers in_progress, in_progress vers waiting_on_customer ou resolved, resolved vers reopened, et reopened vers in_progress. Les restrictions de rôle pour resolve (agent uniquement) et reopen (client uniquement) étaient présentes dans le gestionnaire de mise à jour unifié. L'endpoint d'attribution a également automatiquement transitionné les tickets ouverts vers in_progress.
Comportement UI
Le frontend a passé toutes les 8 étapes de validation. Le formulaire de connexion s'est rendu correctement, l'authentification a persisté et le comportement post-connexion a fonctionné comme prévu. Aucun crash d'exécution ni erreur de console.
Kiro CLI
Installation
Pour macOS/Linux/WSL :
- curl -fsSL https://cli.kiro.dev/install | bash
AppImage Linux alternatif (option portable) :
- Télécharger : https://desktop-release.q.us-east-1.amazonaws.com/latest/kiro-cli.appimage
Ensuite exécutez :
- chmod +x kiro-cli.appimage && ./kiro-cli.appimage
Authentification
Vous pouvez continuer avec votre plan Kiro-Code. Aucune option de fournisseur disponible.
Rapport de tâche
Kiro a produit l'implémentation la plus rapide et la plus compacte. Les transitions de statut, l'application des rôles et l'isolation des données ont été correctement implémentées au niveau logique.
Cependant, le même motif d'endpoint de mise à jour unifié observé dans Aider a causé six échecs de contrat. Un problème de cycle de vie frontend a en outre réduit le score UI. Le système est structurellement sain mais s'écarte de la conception API spécifiée.
Comportement Backend
Kiro a généré une implémentation full-stack compacte en environ 97 secondes. Le backend consistait en un fichier main.py de 324 lignes, et le frontend était une application React single-file de 276 lignes. Seulement 9 fichiers ont été produits au total. Les données de semis comprenaient 4 tickets d'exemple de différents statuts.
L'authentification, le CRUD des tickets, les réponses, la vue de détail et l'isolation des données ont fonctionné correctement. Neuf des 16 étapes API ont réussi.
Les six étapes échouées correspondent à /tickets/{id}/assign et /tickets/{id}/status. Kiro a implémenté un endpoint PATCH /tickets/{id} unifié qui met à jour le statut, la priorité et l'attribution via des champs de corps JSON. La logique métier est correcte, mais la structure de l'endpoint ne correspond pas au contrat attendu, résultant en des réponses 404.
Comportement UI
Le préflight backend a réussi et le frontend a démarré avec succès. Vite a démarré sans crash d'exécution.
Cependant, le formulaire de connexion ne s'est pas rendu. Playwright a expiré après 7 secondes en attendant le champ de saisie email. Les diagnostics de console ont montré une erreur 422 lors du chargement initial de la page, probablement causée par un appel /auth/me exécuté au montage sans token valide. Cela a empêché le composant de connexion de se rendre et a bloqué les étapes UI restantes.
Claude Code
Installation
Pour macOS/Linux/WSL, en considérant votre gestionnaire de paquets préféré, vous pouvez installer Claude Code avec soit :
- curl -fsSL https://claude.ai/install.sh | bash
- brew install –cask codex
Authentification
Après avoir configuré Claude Code, vous pouvez continuer avec votre compte Claude. Aucune option de fournisseur disponible.
Rapport de tâche
Claude Code a produit l'une des bases de code les plus structurées dans cette tâche. Cependant, un problème fondamental de validation JWT a rendu le backend inutilisable.
Cela met en évidence une distinction clé dans l'évaluation des agents : la complétude structurelle ne compense pas la correction de l'authentification.
Il a également consommé le volume de tokens le plus élevé parmi les agents évalués dans la Tâche 6.
Comportement Backend
Les endpoints de connexion ont retourné 200 et ont émis des tokens JWT avec succès. Cependant, toutes les requêtes authentifiées suivantes ont retourné 401 « Could not validate credentials ».
La cause racine semble être un mismatch entre OAuth2PasswordBearer(tokenUrl="auth/login") et le préfixe de route /auth. L'adaptateur de fumée a correctement découvert l'endpoint de connexion, mais les tokens émis n'ont pas été acceptés par le middleware.
En conséquence, 13 des 16 étapes backend ont échoué.
De plus, Claude Code a implémenté un seul endpoint PATCH /tickets/{id} pour les mises à jour au lieu des endpoints dédiés /assign et /status. Cependant, ce choix de conception est devenu sans importance en raison de l'échec d'authentification.
Comportement UI
Le formulaire de connexion s'est rendu correctement. La soumission du formulaire a retourné 200. Cependant, après la connexion, Playwright a détecté un crash de navigation :
« Execution context was destroyed. »
Les journaux du navigateur ont montré des réponses 401 sur les appels API authentifiés, ce qui a causé la rupture de l'état post-connexion.
Aider
Installation
Si vous avez déjà python 3.8-3.13 installé, d'abord, installez aider :
- python -m pip install aider-install
- aider-install
Authentification
Connectez-vous à votre compte OpenRouter et autorisez, ou exportez votre API Key dans votre environnement avec :
- export OPENROUTER_API_KEY="sk-or-v1-…"
Rapport de tâche
Aider a été le constructeur le plus rapide et le plus efficace en tokens. Cependant, sa conception API s'est écartée de la spécification, et l'UI de connexion n'a pas réussi à se rendre correctement.
Comportement Backend
L'authentification, le CRUD des tickets, les réponses, la vue de détail et l'isolation des données ont été implémentés correctement.
Au lieu des endpoints dédiés /assign et /status, Aider a utilisé un endpoint PUT /tickets/{id} unifié pour toutes les mises à jour. Le test de fumée attendait des endpoints séparés, causant des échecs 404 pour les étapes d'attribution et de statut.
Comportement UI
Le frontend a rendu du contenu, mais le formulaire de connexion n'est pas apparu. Playwright a expiré en attendant le champ de saisie email. Les étapes UI suivantes ont été bloquées.
OpenCode
Installation
Pour macOS/Linux/WSL :
- curl -fsSL https://opencode.ai/install | bash
Installez globalement avec :
- npm i -g opencode-ai
Pour macOS/Linux, en considérant votre gestionnaire de paquets préféré :
- bun add -g opencode-ai
- brew install anomalyco/tap/opencode
- paru -S opencode
Authentification
Il y a beaucoup d'options de fournisseur, sélectionnez votre fournisseur désiré et authentifiez avec /connect
Rapport de tâche
OpenCode a produit l'implémentation la plus conforme à la spécification avec une seule déviation de cas limite. Il a également consommé le volume de tokens le plus bas parmi tous les agents dans cette tâche.
Comportement Backend
L'authentification, les opérations CRUD, les réponses, l'attribution, les transitions de statut, l'application des rôles et l'isolation des données ont été implémentés correctement.
Les deux endpoints /tickets/{id}/assign et /tickets/{id}/status ont été implémentés comme attendu.
La seule étape échouée s'est produite lorsque l'agent a tenté de définir le statut sur in_progress après attribution. Puisque l'opération d'attribution a déjà transitionné le ticket vers in_progress, la deuxième transition a retourné 400 en raison d'une application stricte de no-op.
Le comportement backend était logiquement correct, mais le test de fumée attendait un succès idempotent pour les transitions répétées.
Comportement UI
Le frontend a passé toutes les 8 étapes de validation. La connexion s'est rendue correctement, l'authentification a persisté et le comportement post-connexion a fonctionné comme prévu.
Forge
Installation
Pour macOS/Linux/WSL :
- curl -fsSL https://opencode.ai/install | bash
Authentification
Configurez vos identifiants de fournisseur de manière interactive par :
- forge provider login
Et choisissez votre fournisseur.
Rapport de tâche
Une seule mauvaise configuration de routage a déclenché des échecs backend en cascade. Le nombre de tokens de sortie relativement faible suggère une profondeur d'implémentation limitée.
Comportement Backend
La connexion a réussi et les tokens ont été émis.
La création de ticket a retourné des redirections 307 au lieu de 200/201. Parce que la création de ticket a échoué, les étapes suivantes faisant référence à $created_ticket.id ont échoué avec des erreurs 422.
Les réponses 307 proviennent probablement du comportement de redirection de barre oblique traînante dans FastAPI.
Les endpoints /assign et /status ont retourné 404.
Comportement UI
Le frontend a servi du contenu, mais les composants de connexion n'ont pas réussi à se rendre correctement en raison d'erreurs d'exécution dans AuthContext.tsx. Les étapes UI suivantes ont été bloquées.
Gemini CLI
Installation
Exécutez instantanément avec :
- npx @google/gemini-cli
Installez globalement avec :
- npm install -g @google/gemini-cli
Installez globalement avec Homebrew (macOS/Linux) :
- brew install gemini-cli
Installez globalement avec MacPorts (macOS) :
- sudo port install gemini-cli
Installez avec Anaconda (pour environnements restreints) :
- conda create -y -n gemini_env -c conda-forge nodejs
- conda activate gemini_env
Authentification
Option 1 : Connectez-vous avec Google (connexion OAuth utilisant votre compte Google) :
Démarrez gemini et écrivez :
- export GOOGLE_CLOUD_PROJECT="YOUR_PROJECT_ID"
Ensuite, démarrez Gemini.
Option 2 : Gemini API Key
Démarrez gemini et écrivez :
- export GEMINI_API_KEY="YOUR_API_KEY"
Ensuite, démarrez Gemini.
Option 3 : Vertex AI
Démarrez gemini et écrivez :
- export GOOGLE_API_KEY="YOUR_API_KEY"
- export GOOGLE_GENAI_USE_VERTEXAI=true
Rapport de tâche
Gemini CLI a produit un backend solide mais a échoué en raison d'une incompatibilité d'outillage frontend. Il a également consommé le volume de tokens le plus élevé parmi les implémentations backend réussies.
Comportement Backend
L'authentification, le CRUD, les réponses, l'attribution, l'application des rôles et l'isolation des données ont été implémentés correctement.
Cependant, l'endpoint /tickets/{id}/status manquait entièrement, causant à toutes les étapes de transition de statut de retourner 404.
Comportement UI
Le frontend n'a pas réussi à démarrer. Vite 7.3.1 a été installé, ce qui nécessite Node.js 20.19+, tandis que l'environnement de test exécute Node.js 18.18.0. L'API crypto.hash requise par Vite n'était pas disponible.
En conséquence, l'UI n'a jamais démarré et a obtenu 0/8.
Cline
Installation
Installez globalement avec :
- npm install -g cline
Authentification
En écrivant `cline auth` vous pouvez sélectionner votre compte Cline ou continuer avec votre fournisseur désiré.
Rapport de tâche
Le mécanisme de limitation d'erreur de Cline a terminé la construction avant achèvement. La structure backend montre une intention architecturale correcte, mais des problèmes d'enregistrement de route et une implémentation incomplète ont empêché la validation fonctionnelle.
L'absence de frontend et les échecs backend en cascade placent ce résultat parmi les plus faibles de la Tâche 6.
Comportement Backend
Cline a généré un backend avec cinq fichiers : main.py, models.py, schemas.py, auth.py et database.py, ainsi qu'un requirements.txt. La structure comprenait des modèles appropriés, un squelette d'authentification JWT et des stubs d'endpoint.
Cependant, l'agent a atteint sa limite de huit erreurs pendant le développement backend et s'est terminé avant d'achever le système.
Seuls les endpoints de connexion ont fonctionné correctement. Trois des 16 étapes API ont réussi.
La création de ticket a retourné des redirections 307 au lieu de 200 ou 201, probablement en raison de mismatches de route de barre oblique traînante. Parce que la création de ticket a échoué, $created_ticket.id n'a jamais été capturé. Toutes les étapes suivantes faisant référence à l'ID de ticket ont passé la valeur littérale de chaîne, conduisant à des erreurs 422.
Les endpoints /tickets/{id}/assign et /tickets/{id}/status n'ont pas été implémentés, résultant en des réponses 404.
Cela a produit un motif d'échec en cascade similaire à Forge, où un problème de routage précoce a invalidé les étapes en aval.
Comportement UI
Le backend a démarré avec succès. Cependant, le répertoire frontend/ était vide et aucun fichier package.json n'existait.
Seule l'étape de préflight backend a réussi. Toutes les étapes UI restantes ont été bloquées.
Goose
Installation
Pour macOS/Linux/WSL :
- curl -fsSL https://github.com/block/goose/releases/download/stable/download_cli.sh | bash
Modèle : Gemini 3 Pro Preview (via OpenRouter)
Temps : 1 297s
Tokens : 17k entrée / 752 sortie
API Score : 60%
Score UI : 0%
Goose a démontré une auto-correction limitée mais n'a pas réussi à achever l'exigence full-stack. Des problèmes de fiabilité lors des ré-exécutions soulèvent des préoccupations de stabilité.
Comportement Backend
L'authentification, le CRUD des tickets, les réponses, la vue de détail et l'isolation des données ont fonctionné.
Cependant, les endpoints /assign et /status n'ont pas été implémentés, causant des réponses 404 pour toutes les étapes associées.
Dans une construction antérieure, Goose a rencontré des erreurs de compatibilité bcrypt, s'est auto-corrigé en verrouillant la version de la dépendance et a finalement lancé le backend.
Une ré-exécution ultérieure s'est écrasée avec une erreur de décodage de flux après une génération minimale de fichiers.
Comportement UI
Aucun frontend n'a été créé. Le répertoire frontend était vide et aucun package.json n'existait. Le test UI a échoué immédiatement.
Outils de codage IA
Les outils de codage IA peuvent être regroupés en trois catégories :
- CLI Agent : Outils pour les flux de travail de développement basés sur terminal, génèrent, modifient et refactorisent du code via des prompts et des interactions en ligne de commande.
- Exemples : Aider, Junie, Opencode, Claude Code, Codex
- Éditeurs de code IA : Également connus sous le nom d'IDE agents, ces outils fournissent une GUI similaire à VS Code (la plupart sont construits sur VS Code).
- Exemples : Antigravity, Cursor, Kiro Code, Windsurf
- Constructeurs prompt-to-app : Plateformes low-code/no-code pour construire des applications en utilisant des prompts en langage naturel et des flux de travail visuels.
- Exemples : Bolt, Lovable, v0.dev, Firebase Studio, Dazl
Outils de revue de code IA
À mesure que le code généré par IA devient plus courant, les outils de revue de code sont essentiels pour attraper les bugs et les vulnérabilités. Nous avons évalué les meilleurs outils sur 309 PRs dans notre benchmark RevEval.
Que peuvent faire les outils CLI agents ?
À travers des outils comme Codex, Junie, Kiro et Claude Code, les capacités communes incluent :
- Travail de code de bout en bout : Créer et modifier des fichiers, corriger des bugs, refactoriser du code et exécuter des tests ou des linters directement depuis le terminal.
- Flux de travail agents : Effectuer des tâches multi-étapes telles que le chaînage de tâches, le dépannage, la recherche et le débogage itératif.
- Git & gestion de projet : Examiner l'historique, résoudre les fusions, gérer les branches et créer des commits ou des pull requests.
- Exécution de Command & automatisation : Exécuter des commandes shell, automatiser des analyses et traduire le langage naturel en opérations CLI complexes.
- Gestion de contexte profond : Opérer sur des dépôts complets avec une conscience des dépendances et de la structure du projet.
- Flexibilité du modèle : Prendre en charge plusieurs modèles cloud et, dans certains cas, locaux ; certains outils permettent d'utiliser votre propre API key ou de choisir entre des plans.
- Accès isolé ou contrôlé : Offrir des modes allant du seul lecture à l'automatisation complète, souvent avec des environnements isolés pour la sécurité.
Méthodologie
Nous avons évalué les agents dans une configuration d'exécution one-shot pour mesurer leurs capacités autonomes sans intervention humaine. Les agents ont ensuite été évalués en utilisant nos tests de fumée backend et frontend pour mesurer la préparation de l'infrastructure et la correction comportementale.
Les scores reflètent la fiabilité avec laquelle chaque agent a produit des systèmes exécutables et combien d'exigences fonctionnelles ont passé la validation.
Configuration du modèle
Nous avons visé d'utiliser Google's gemini-3-pro-preview en raison de sa haute fenêtre de contexte, qui convient à l'orchestration multi-fichiers et aux prompts de tâches longs. Cependant, certains CLIs agents sont étroitement couplés à des fournisseurs spécifiques :
- Claude Code a été évalué en utilisant claude-opus-4-5-20251101 via l'API officielle de Anthropic.
- Codex a été évalué en utilisant gpt-5.2-codex-medium via la configuration native de OpenAI.
Pour ces agents, les fournisseurs de modèles alternatifs ne sont pas pris en charge dans leur architecture CLI actuelle. Chaque agent a été évalué en utilisant sa configuration par défaut. Nous n'avons pas ajusté la température, les politiques de réessai ou les paramètres de raisonnement.
Notre objectif d'évaluation était de séparer et de mesurer :
- Capacité de construction (l'agent peut-il produire du code exécutable ?)
- Correction du comportement backend
- Correction du comportement frontend
- Fiabilité de l'orchestration autonome
Versions CLI (Mi-février 2026)
- Opencode : v1.2.10
- Cline : v3.41
- Aider : v0.86.0
- Gemini CLI : v0.29.0
- Forge : v1.28.0
- Codex : 0.104.0
- Goose : v1.25.0
- Claude Code : v2.1.62
- Junie : 888.212
- Kiro CLI : 1.26.0
Pour la méthodologie d'évaluation, visitez : Méthodologie du benchmark de codage IA
Lire plus
Pour ceux qui explorent l'écosystème plus large des outils de développement agents, voici nos derniers benchmarks :
- Benchmark MCP : Une comparaison des meilleurs serveurs MCP pour l'accès web.
- Navigateurs distants : Comment l'infrastructure navigateur émergente permet aux agents IA d'interagir avec le web de manière sécurisée.
Citez ce benchmark
Choisissez le format qui correspond à votre lieu de publication. Coller la version avec lien dans votre CMS préserve le lien retour.
@misc{kaleliolu2026,
author = {Kalelioğlu, Berk and Dilmegani, Cem},
title = {{Outils CLI Agents: Codex vs Claude Code}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/agentic-cli}},
note = {AIMultiple. Retrieved Juin 18, 2026}
}Résultats et horodatages de 110 points de données. Téléchargez les données utilisées dans cet article sous forme de fichier ZIP contenant un fichier CSV et un README.




Soyez le premier à commenter
Votre adresse courriel ne sera pas publiée. Tous les champs sont obligatoires. Les commentaires sont laissés dans leur langue d'origine.