65 Gerçek Dünya Görevinde Test Edilen Mobil AI Ajanları
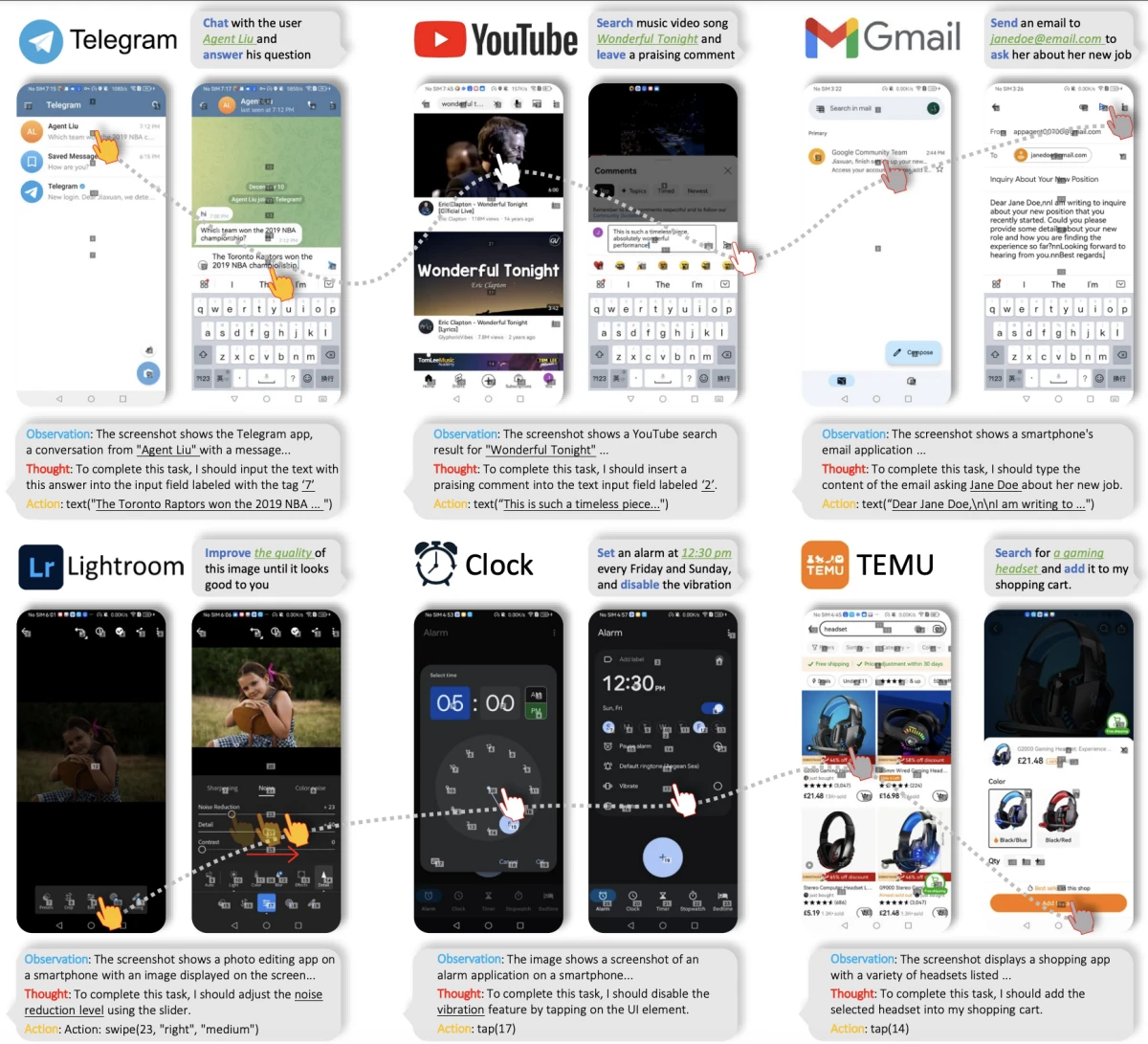
Android emülatörünü takvim yönetimi, kişi oluşturma, fotoğraf çekme, ses kaydı ve dosya işlemleri gibi uygulamalarla kullanarak dört mobil AI ajanını (DroidRun, Mobile-Agent, AutoDroid ve AppAgent) 65 gerçek dünya görevinde 3 gün boyunca kıyasladık.
Gerçek dünya performans karşılaştırması, maliyetler ve çalışma süreleri dahil olmak üzere kıyaslama sonuçlarına bakın:
Mobil AI ajanları performans karşılaştırması
DroidRun
En yüksek başarı oranı (%43) ve başarılı görev başına yüksek maliyet ($0.075, ~3.225 token)
DroidRun, 65 görevde %43'lük bir başarı oranıyla en güçlü performansı sergiledi. Tüm ajanların başarıyla tamamladığı görevleri yalnızca incelediğimizde, DroidRun görev başına ortalama 3.225 token tüketti ve maliyeti $0.075 oldu.
Bu önemli kaynak tüketimi, ajanın detaylı durum takibini sürdürdüğü, açık eylem planları oluşturduğu ve her karar için açıklamalar sağladığı DroidRun'un çok adımlı akıl yürütme mimarisini yansıtmaktadır. Pahalı olsa da, bu kapsamlı yaklaşım kıyaslama en yüksek başarı oranını sunmaktadır.
Mobile-Agent
Güçlü performans (%29) ve maliyet-etkin ($0.025, ~1.130 token)
Mobile-Agent, makul maliyet-etkinliği korurken %29'luk ikinci en yüksek başarı oranına ulaştı. Tüm ajanlarda yaygın olarak başarılı olan görevlerde Mobile-Agent görev başına ortalama $0.025 ve 1.130 token harcadı.
Bu, DroidRun'un görev başına maliyetinin yaklaşık üçte biri iken başarı oranının yaklaşık üçte ikisine ulaşması anlamına gelir ve bu da Mobile-Agent'ı bütçe kısıtlamalarının önemli olduğu dağıtımlar için çekici bir seçenek haline getirir.
Yine de, başarı oranındaki 14 puanlık fark, DroidRun'un ek akıl yürütme yeteneklerinin misyon kritik uygulamalar için anlamlı bir değer sağladığını göstermektedir.
AutoDroid
En iyi maliyet-etkinliği (%14 başarı, $0.017, ~765 token) ancak sınırlı etkililik
AutoDroid, görev başına sadece $0.017 ve 765 token ile yaygın olarak başarılı görevlerde en düşük maliyeti göstererek kıyaslama en ekonomik seçenek oldu.
Yine de, %14'lük başarı oranı, Mobile-Agent'ın performansının yarısından azı ve DroidRun'un yaklaşık üçte biri, bu maliyet avantajının güvenilirlikte önemli fedakarlıklarla geldiğini göstermektedir.
DroidRun'a benzer eylem tabanlı bir yaklaşım kullanmasına rağmen, AutoDroid'in minimal akıl yürütme yükü önemli maliyet tasarrufları sağlarken görev tamamlama yeteneğini sınırlamaktadır.
AppAgent
En zayıf performans (%7 başarı) ve en yüksek maliyet ($0.90, ~2.346 token)
AppAgent, hem %7'lik en düşük başarı oranını hem de görev başına $0.90 ve 2.346 token ile yaygın olarak başarılı görevlerde en yüksek maliyeti kaydetti. DroidRun'dan on iki kat, AutoDroid'den ise elli kat daha pahalı.
Bu zayıf maliyet-performans oranı, AppAgent'ın her etkileşim için multimodal LLM'ler üzerinden etiketlenmiş ekran görüntülerini işleyen görüntü tabanlı yaklaşımından kaynaklanmaktadır. Multimodal LLM'e gönderilen her ekran görüntüsü, görüntü işleme için önemli miktarda giriş token'ı tüketirken, gerçek metin yanıtları (tamamlama token'ları) nispeten mütevazı kalır.
Bu, koordinat hesaplamaları ve mobil arayüzlerdeki UI öğesi tanımlama konusunda ajanın zorluk çektiği için görev tamamlamada karşılık gelen iyileştirmeler olmadan maliyeti baskın hale getiren görüntü işleme yüküyle son derece dengesiz bir token dağılımı yaratır.
Mobil AI ajanları çalışma süresi karşılaştırması
Tüm ajanların başarıyla tamamladığı tek görevde, AutoDroid 57 saniye ile en hızlı oldu, onu 66 saniye ile Mobile-Agent takip etti. DroidRun görevi 78 saniyede tamamladı ve çok adımlı akıl yürütme mimarisinin daha yüksek token tüketimine rağmen verimli çalışmayı hala mümkün kıldığını gösterdi.
AppAgent, her etkileşim için multimodal LLM'ler üzerinden kapsamlı ekran görüntüsü işleme gerektiren görüntü tabanlı yaklaşımı nedeniyle 180 saniyede önemli ölçüde daha yüksek gecikme sergiledi.
Kıyaslama metodolojimizi buradan görebilirsiniz.
Mobil AI ajanlarına genel bakış
GitHub yıldız sayıları hızla değişir ve tabloyu buna göre güncelleyeceğiz.
DroidRun
DroidRun, mobil uygulamaları ve telefonları otonom olarak kontrol edebilen mobil-özel AI ajanları oluşturan açık kaynaklı bir çerçevedir. Kullanıcı arayüzlerini büyük dil modellerinin etkileşime girebileceği yapılandırılmış verilere dönüştüren temel bir çerçevedir ve karmaşık otomasyonları doğrudan mobil cihazlarda mümkün kılar.
DroidRun hızla ilgi gördü: 24 saat içinde 900'den fazla geliştirici kayıt yaptı ve proje GitHub'da 3.8k yıldıza ulaşıp mobil AI ajanları için en hızlı büyüyen çerçevelerden biri haline geldi.
İşte eylemde:
AutoDroid
AutoDroid, manuel kurulum olmaksızın herhangi bir Android uygulamasında keyfi görevleri yerine getirmek üzere tasarlanmış bir mobil görev otomasyon sistemidir. GPT‑4 ve Vicuna gibi büyük dil modellerinin ortak akıl yürütme yeteneklerini, otomatik uygulama özel analizle birleştirir.
AutoDroid, uygulama arayüzlerini LLM'ler ile bağlamak için işlev odaklı bir UI temsilini tanıtıyor, modelin uygulama özel davranışlarını öğretmek için keşif tabanlı bellek enjeksiyonu kullanıyor ve çıkarım maliyetlerini azaltmak için sorgu optimizasyonu içeriyor. 158 görevden oluşan bir kıyaslama üzerinde değerlendirildiğinde, %90.9 eylem doğruluğu ve %71.3 görev başarısı elde etti ve yalnızca GPT‑4 tabanlarını geride bıraktı.1
Mobile-Agent
X-PLUG/MobileAgent GitHub deposu, görsel UI temsillerini algılayarak ve akıl yürüterek mobil uygulamaları otonom olarak kontrol etmek üzere tasarlanmış bir AI ajan çerçevesi olan Mobile-Agent'ın resmi uygulamasıdır.
Bu proje Tsinghua Üniversitesi'ndeki X-PLUG grubundan gelmektedir ve ICLR 2024'te sunulmuştur; çok modlu öğrenmeyi, özellikle görsel algıyı ve talimat izlemeyi kullanarak mobil ajanların sınırlarını zorlamayı amaçlamaktadır. Eylemde görmek için videoyu izleyin.
AppAgent
TencentQQGYLab/AppAgent GitHub deposu, Tencent'in QQG Y-Lab'ından açık kaynaklı bir araştırma projesidir. AppAgent, her bireysel uygulama için insan yazımı kod olmaksızın Android uygulamalarını otonom olarak çalıştırmak ve akıl yürütmek üzere tasarlanmış bir mobil AI ajan çerçevesini tanıtıyor.
Kaynak: AppAgent2
Mobil AI ajanlarının özellikleri
Hedef odaklı komut işleme
Ajan hangi uygulamaları açacağını, hangi eylemleri gerçekleştireceğini ve bunları nasıl sıralayacağını belirler. Örneğin, kullanıcılar bireysel adımları değil, ne yapılmasını istediklerini (örneğin, "Havalimanına bir yolculuk ayarla") belirtir.
LLM-destekli akıl yürütme
Büyük dil modelleri (örneğin GPT-4, Claude, Gemini) ile güçlendirilen bu ajanlar şunları yapabilir:
- Kullanıcı niyetini ve ekran içeriğini tanımlama
- Mantıklı, adım adım eylem planları oluşturma
- Farklı uygulama durumlarındaki dinamik UI değişikliklerine uyum sağlama
Yapılandırılmış, yerel uygulama kontrolü
Ekran kazımaya güvenmek yerine:
- Ajanlar yapılandırılmış UI hiyerarşilerini (örneğin, düğmeler ve alanların XML tabanlı ağaçları) çıkarır
- UI öğeleriyle doğrudan etkileşime girer ve bunları birinci sınıf API'ler olarak ele alır.
- Örnek: DroidRun, gerçek UI öğelerini okumak ve üzerinde hareket etmek için Android Erişilebilirlik API'lerini kullanır.
Uygulama-ötesi iş akışı yürütme
Ajanlar birden fazla uygulama ve çok adımlı iş akışları üzerinde çalışır. Bir ara adım başarısız olursa yeniden planlama yapabilirler. Örneğin, "E-postadan bir dosya indir → Google Drive'a yükle → bir onay gönder."
Mobil AI ajanları için bulut ve cihaz içi yürütme
Mobil AI ajanları bulutta, cihaz içinde veya hibrit bir yaklaşım kullanarak çalışabilir.
Bulut tabanlı ajanlar, API çağrıları yoluyla GPT-4, Claude veya Gemini gibi modellere bağlanır. Bu, sofistike akıl yürütme ve çok adımlı görev tamamlamayı mümkün kılar. Ancak, ekran verilerini ve kullanıcı bağlamını harici sunuculara iletme gerektirir, bu da hassas uygulamalar için gizlilik endişelerini gündeme getirir. Performans ayrıca kararlı ağ bağlantısına bağlıdır.
Cihaz içi ajanlar, modelleri doğrudan mobil donanımda çalıştırır ve tüm verileri yerel tutar. Bu, iletim risklerini ortadan kaldırır ve çevrimdışı işlevselliği mümkün kılar. Değiş tokuş, sınırlı model kapasitesidir: mevcut mobil NPUs ve GPU'lar model boyutunu kısıtlar, bu da karmaşık akıl yürütme görevlerinde doğruluğu azaltabilir.
Hibrit mimariler her iki yaklaşımı da birleştirir. Hafif cihaz içi modeller rutin görevleri ve ilk niyet sınıflandırmasını yönetirken, karmaşık işlemler bulut LLM'lerine yönlendirilir. Apple Intelligence ve Gemini Nano bu modeli izler, basit istekleri yerel olarak işler ve gerektiğinde yükseltir. Yerel ve bulut işleme arasındaki optimal denge, kenar AI donanımı iyileştikçe gelişmeye devam etmektedir.
Mobil AI ajanlarında güvenlik ve gizlilik riskleri
Mobil AI ajanları ekran içeriğini okur, uygulamalarda gezinir ve eylemler yürütür, hassas kullanıcı verilerine derin erişim sağlar. Bu birkaç endişe doğurur:
- Ekran içeriği maruziyeti: Ajanlar, işleme için şifreleri, mesajları ve finansal verileri bulut LLM'lerine iletebilir
- Kimlik bilgisi sızıntısı: Otomatik giriş iş akışları, kaydedilmiş şifreleri ve kimlik doğrulama token'larını istemsiz olarak açığa çıkarabilir
- Belirsiz veri saklama: Ajan günlüklerinin ve yakalanan ekran görüntülerinin nasıl saklandığı veya paylaşıldığı genellikle belirsizdir
- Prompt enjeksiyonu riski: Kötü niyetli uygulama içeriği, oluşturulmuş UI metni aracılığıyla ajan davranışını manipüle edebilir
Bu riskleri ele almak çok katmanlı bir yaklaşım gerektirir:
- Cihaz içi işleme: Modelleri yerel olarak çalıştırmak, hassas verilerin harici sunuculara iletilmesi ihtiyacını azaltır
- KİB (Kişisel Bilgi) maskeleme: API çağrılarından önce kişisel bilgileri otomatik olarak tespit etmek ve silmek maruziyeti sınırlar
- İzin sınırları: Ajan erişimini hassas uygulama kategorilerine (bankacılık, sağlık, mesajlaşma) kısıtlamak, istenmeyen veri erişimini önler
- Şeffaf API politikaları: Net veri işleme ve saklama politikalarına sahip sağlayıcıları seçmek uyumu sağlamaya yardımcı olur
Kıyaslama metodolojisi
Gerçek dünya görevlerinde Android işletim sisteminde çalışan AI mobil ajanlarının performansını değerlendirmek için bir kıyaslama değerlendirme gerçekleştirdik. AndroidWorld çerçevesini kullandık ve tüm ajanları aynı standart görevlerde test ettik.
AndroidWorld Çerçevesi
AndroidWorld, mobil ajanları değerlendirmek için özellikle Google Araştırması tarafından geliştirilmiş açık kaynaklı bir kıyaslama platformudur. Bu platform, standartlaştırılmış görevler aracılığıyla gerçek Android uygulamalarında çalışan ajanların performansını ölçmeyi amaçlamaktadır.
AndroidWorld'ün en önemli özelliği, yapay test ortamları yerine gerçek Android uygulamaları kullanması ve ajanların performansını otomatik olarak değerlendirebilmesidir. Bu çalışmada 65 görev kullandık. Bu görevler, takvim yönetimi, kişi ekleme, ses kaydı, fotoğraf çekme ve dosya işlemleri gibi günlük mobil cihaz kullanım senaryolarını kapsamaktadır.
Ortam Kurulumu
Sistem yapılandırması: Kıyaslama ortamını kurmak için öncelikle Windows 11 işletim sistemine Android Studio yükledik ve Google'ın resmi Android Emülatörünü yapılandırdık.
Sanal cihaz kurulumu: Pixel 6 cihazını simüle eden bir sanal cihaz oluşturduk. Bu sanal cihazın özellikleri Android 13 (API Seviyesi 33) işletim sistemi, 1080×2400 çözünürlük, 8GB RAM ve 20GB depolama alanı olarak ayarlandı.
Emülatör yapılandırması: Emülatörü AndroidWorld ile entegre etmek için gRPC bağlantı noktasını 8554 olarak yapılandırdık çünkü AndroidWorld emülatörle bu bağlantı noktası üzerinden iletişim kurar.
Python ortamı kurulumu: Python ortamını hazırlamak için Miniconda kullanarak Python 3.11 ile yeni bir conda ortamı oluşturduk. AndroidWorld deposunu GitHub'dan klonladıktan sonra tüm bağımlılıkları pip kullanarak yükledik. AndroidWorld'ün en kritik adımlarından biri emülatör kurulum işlemidir.
Kurulum komutu yaklaşık 45-60 dakika sürdü. Bu işlem sırasında AndroidWorld, emülatörde test edilecek tüm Android uygulamalarını otomatik olarak yükledi.
İlk durum verisi oluşturma: Her uygulama için ilk durum verisi oluşturdu, örneğin takvim uygulamasına bazı etkinlikler ekledi, kişiler uygulamasına kişiler ekledi ve podcast uygulamasına "muz" adında bir podcast ekledi. Ayrıca her görev için anlık görüntüler kaydetti, böylece her görev temiz bir ilk durumdan başlayabilir.
Ajan entegrasyonları
AutoDroid
AutoDroid Entegrasyonu: AutoDroid'i entegre etmek için öncelikle deposunu GitHub'dan klonladık ve gerekli Python paketlerini yükledik. AutoDroid'in ana özelliği, XML'i ayrıştırarak UI öğelerini tanımlaması ve eylem tabanlı bir yaklaşım ile görevleri tamamlamasıdır.
Ajan, ekrandaki tıklanabilir veya odaklanabilir her öğeye bir indeks numarası atar ve LLM'den "tap(5)" veya "text('hello')" gibi komutlar alır.
AutoDroid wrapper: AndroidWorld ile entegrasyon için autodroid_agent.py adında bir wrapper sınıfı oluşturduk. Bu wrapper, AutoDroid'in başlatma metodunda gerekli yapılandırmaları gerçekleştirir, AndroidWorld'den gelen görev hedefini AutoDroid'in anlayabileceği bir prompt formatına dönüştürür ve AutoDroid tarafından oluşturulan eylemleri AndroidWorld'ün execute_adb_call fonksiyonlarını kullanarak gerçek ADB komutlarına dönüştürür.
Yürütme akışı: AutoDroid'in step metodunda, ajan önce ekranın ekran görüntüsünü ve XML dökümünü alır, UI öğelerini ayrıştırır, bu bilgiyi LLM'e gönderir ve alınan yanıta göre dokunma, kaydırma veya metin girişi eylemleri gerçekleştirir.
DroidRun
DroidRun entegrasyonu: DroidRun için benzer bir entegrasyon sürecini izledik. DroidRun deposunu GitHub'dan klonladıktan sonra requirements.txt'deki bağımlılıkları yükledik.
DroidRun'un mimari yapısı, çok adımlı akıl yürütme ve durum takip sistemine sahip olduğu için daha karmaşıktır. DroidRun, her adımda ne yapacağını değil, neden yapacağını da açıklayabilir ve önceki adımların sonuçlarını sonraki adımda kullanabilir.
DroidRun wrapper: AndroidWorld entegrasyonu için droidrun_agent.py wrapper'ını oluşturduk. Bu wrapper'daki en önemli kısım, DroidRun'un kendi CodeActAgent sınıfını AndroidWorld'ün temel ajan arayüzü ile uyumlu hale getirmekti.
Yürütme süreci: DroidRun'un execute_task metodunu çağırdığımızda, ajan bir görev planlama aşamasından geçer, ardından her adımı yürütür ve sonuçları değerlendirir. Bu süreci AndroidWorld'ün adım adım yürütme modeline uyarladık. Ayrıca DroidRun'un kullandığı araçları (tap_by_index, start_app, list_packages vb.) AndroidWorld'ün ADB komutları ile uyguladık.
AppAgent
AppAgent entegrasyonu: AppAgent'in entegrasyonu, görüntü tabanlı bir yaklaşım kullandığı için diğerlerinden farklıydı. AppAgent deposunu klonladıktan sonra scripts klasöründeki Python dosyalarını AndroidWorld'e entegre ettik.
Görüntü tabanlı yaklaşım: AppAgent'in çalışma prensibi şöyledir: önce ekranın ekran görüntüsünü alır, ardından UI öğelerinin sınırlayıcı kutularını hesaplar, bu kutuları ekran görüntüsüne çizer, her birine bir numara atar ve bu etiketlenmiş ekran görüntüsünü çok modlu bir LLM'e gönderir. LLM görsel olarak hangi öğenin tıklanması gerektiğini belirler.
Wrapper yapılandırması: AppAgent'i entegre etmedeki en önemli adım, AppAgent'in and_controller.py modülü kullanarak Android cihazıyla iletişim kurduğu kısmı AndroidWorld'ün emülatörüne yönlendirmekti. appagent_agent.py wrapper'ında, AndroidWorld'ün API'leri ile çalışması için AppAgent'in get_screenshot ve get_xml metodlarını yeniden uyguladık. Ayrıca OpenAI API formatını kullanan AppAgent'in model.py dosyasını OpenRouter API ile uyumlu hale getirdik.
Mobile-Agent (M3A)
Mobile-Agent (M3A) entegrasyonu: M3A'nın entegrasyonu, tamamen görüntü tabanlı çalıştığı ve çok detaylı bir UI analiz sistemine sahip olduğu için en kapsamlı süreçti. M3A deposunu klonladıktan sonra, M3A bu çerçeveye bağımlı olduğu için Mobile-Env Android etkileşim çerçevesini de yükledik.
Çok adımlı analiz: M3A'nın çalışma prensibi, ekranı ızgaralara ayırmaya, her ızgarayı ayrı ayrı analiz etmeye ve çok adımlı planlama yapmaya dayanır. m3a_agent.py wrapper'ını oluştururken, M3A'nın kendi ortam sistemini AndroidWorld'ün ortamı ile entegre etmemiz gerekiyordu. M3A normalde kendi Mobile-Env'sini kullanır, ancak bunu AndroidWorld'ün env'ine yönlendirdik.
Çoklu LLM çağrıları: M3A'nın her adımda (planlama, eylem seçimi, doğrulama gibi) birden fazla LLM çağrısı yaptığını gözlemledik ve bunları AndroidWorld'ün adım sınırları ile uyumlu hale getirdik.
Test prosedürü ve veri toplama
Test akışı: Her ajan için test prosedürü şu şekilde işledi: Öncelikle temiz bir anlık görüntü ile emülatörü başlattık. Emülatör tamamen açıldıktan sonra AndroidWorld'ün run.py dosyasını çalıştırdık. Her ajan için 65 görevi sırayla çalıştırdık ve tüm ajanlar için Claude 4.5 Sonnet kullandık.
Görev yürütme: AndroidWorld, her görev için otomatik olarak aşağıdaki adımları gerçekleştirdi: görevin ilk durumunu yükle, ajanı başlat, görev hedefini ajana gönder, ajanın adımlarını izle, maksimum adım sayısına ulaşıldığında veya ajan "görev tamamlandı" dediğinde durdur ve görevin başarılı olup olmadığını kontrol et.
Başarı kriterleri: AndroidWorld'ün görev değerlendirme sistemi önceden tanımlanmış başarı kriterlerini içerir. Örneğin, "John Doe adında kişi ekle" görevi için AndroidWorld, kişinin eklendiğini doğrulamak için kişiler veritabanını sorgular.
Takvim görevleri için, etkinin doğru tarih, saat, başlık ve açıklama ile oluşturulup oluşturulmadığını veritabanından kontrol eder. Her görev yürütmesinin sonunda AndroidWorld bize yürütme süresi ve başarı durumu (True/False) sağladı. Bu veri otomatik olarak kaydedildi ve analiz için kullanıldı.
Veri toplama: Tüm kıyaslamayı tamamladıktan sonra, tüm ajanların başarıyla tamamladığı görevi belirledik. Bu görevlerin her biri daha sonra her ajan tarafından 10 kez yürütüldü ve daha güvenilir performans metrikleri için ortalama yürütme süresi, maliyet ve token tüketimi hesaplandı.
Mobil AI ajanlarındaki performans farklılıklarının arkasındaki olası nedenler
Gözlemlenen farklılıklar büyük ölçüde mimari seçimlerden ve etkileşim yöntemlerinden kaynaklanmaktadır.
DroidRun, çok adımlı akıl yürütme, açık planlama ve durum takibi yoluyla güvenilirliği önceliklendirir. Bu, görev başarısını artırır ancak token kullanımını ve maliyeti artırır.
Mobile-Agent, performans ve verimliliği dengeler. Daha hafif akıl yürütme ve görsel anlayış, orta düzey başarı oranlarını korurken maliyeti düşürür ve bu da onu bütçe duyarlı kullanım durumları için uygun hale getirir.
AutoDroid, minimal akıl yürütme yüküyle eylem tabanlı yürütmeye odaklanır. Bu, en düşük maliyet ve en hızlı yürütme sürelerini sonuçlandırır, ancak karmaşık veya belirsiz görevleri işleme yeteneğini de sınırlar.
AppAgent, çok modlu LLM'ler kullanarak görüntü tabanlı etkileşime büyük ölçüde güvenir. Sık ekran görüntüsü işleme gecikmeyi ve maliyeti artırırken, UI koordinat zorlukları görev başarısını azaltır.
SSS'ler
Mobil AI ajanları, kullanıcılar adına görevleri tamamlamak için doğal dil girdilerini ve hedef odaklı akıl yürütmeyi kullanarak kullanıcılarla ve mobil uygulamalarla otonom olarak etkileşime giren yazılım sistemleridir. Geleneksel otomasyon araçlarından veya erken kişisel asistanlardan farklı olarak, bu ajanlar AI tarafından güçlendirilir. Bazı kullanım alanları şunlardır:
Test betikleri olmadan mobil QA otomasyonu
ID belgelerini yüklemek veya profil ayarlarını değiştirmek gibi mobil iş akışlarını otomatikleştirme
Görme engelliler, yaşlılar veya başka herkes için uygulamaları çalıştıran AI asistanları
Takvimde etkinlik oluşturmak veya hatta Duolingo derslerini tamamlamak gibi günlük genel görevler.
Bu araştırmayı kaynak gösterin
Yayınlayacağınız yere uygun formatı seçin. Bağlantılı sürümü CMS'inize yapıştırmak, geri bağlantıyı korur.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{65 Gerçek Dünya Görevinde Test Edilen Mobil AI Ajanları}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/mobile-ai-agent}},
note = {AIMultiple. Erişim tarihi: 9 Haziran 2026}
}
Yorum yapan ilk kişi olun
E-posta adresiniz yayınlanmayacak. Tüm alanlar gereklidir. Yorumlar orijinal dilinde bırakılır.