Yapay Zeka Kod İnceleme Araçları Karşılaştırması
Yapay zeka kodlama araçlarının artan kullanımıyla birlikte, kod tabanları güvenlik açıklarına daha yatkın hale geldi ve bu da etkili kod incelemelerine olan ihtiyacı artırdı. Bu sorunu ele almak için, en iyi dört yapay zeka kod inceleme aracını farklı boyutlardaki depolardan alınan 309 pull request üzerinde karşılaştıran ve performanslarını 10 geliştiricinin girdisi ile bir LLM-as-a-judge kullanarak değerlendiren RevEval'i (AI Code Review Eval) tanıtıyoruz.
Karşılaştırma Sonuçları
CodeRabbit, 309 PR'ın %51'inde en başarılı kod inceleme aracı olarak sıralandı:
Sıralamayı ölçmek için LLM-as-a-judge puanlarını kullandık. Her PR'da hangi yapay zeka kod inceleme aracının en yüksek puanı aldığını inceledik (LLM-as-a-judge kullanılarak puanlandı) ve ardından her aracın tüm PR'ların yüzde kaçında birinci olduğunu hesapladık.
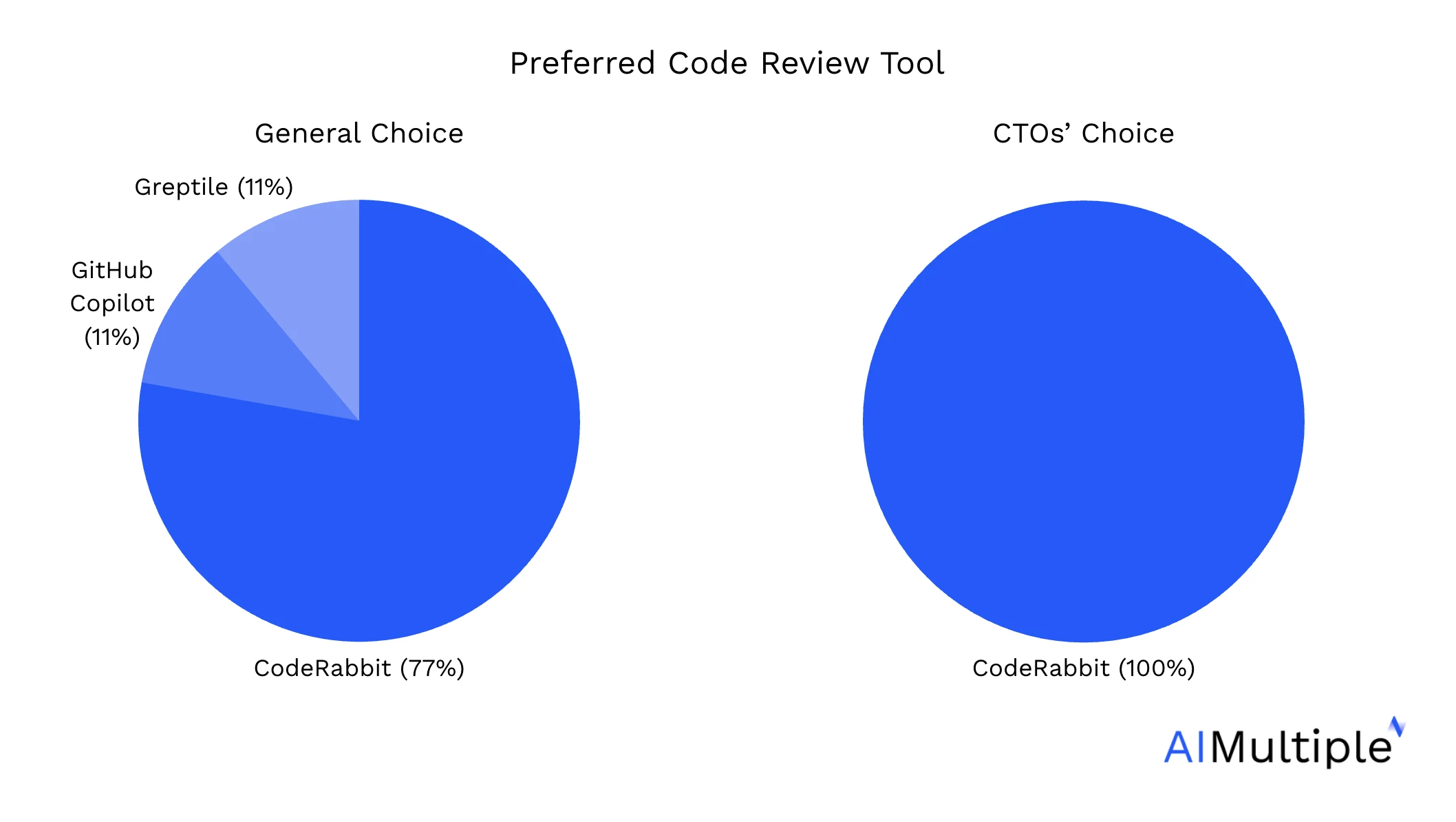
CodeRabbit, hem manuel insan değerlendirmelerinde hem de LLM-as-a-judge değerlendirmelerinde en yüksek puanı aldı, onu Greptile ve GitHub Copilot izledi:
Ortalama puan hesaplanırken, üç değerlendirme kategorisi de eşit ağırlıklandırıldı. Büyük depo puanları ve küçük depo puanları LLM-as-a-judge tarafından değerlendirildi ve geliştirici değerlendirmeleri, LLM-as-a-judge puanlarını iki kez kontrol etmek için manuel olarak tamamlandı.
İnsan değerlendirmeleri
Değerlendirmelere katılan geliştiricilere, iş akışlarına hangi yapay zeka kod inceleme aracını entegre etmeyi tercih edeceklerini sorduk. CTO'lar yazılım geliştirmede kilit karar verme rolü oynadıkları için, yanıtlarını ayrı bir grafikte vurguladık:
Detaylı karşılaştırma
Her kod inceleme aracı tarafından bildirilen tüm hataları/sorunları sayarak ve toplam PR sayısına (309) bölerek PR başına ortalama hata sayısını hesapladık. Kod tabanımızdaki tüm PR'lar hata veya sorun içermez. GitHub Copilot, bir PR'da hata tespit ettiğinde bunu açıkça bildirmez; bu nedenle, bu karşılaştırmanın dışında bırakılmıştır.
Metodolojimizi aşağıda görebilirsiniz.
Özellikler
* CodeRabbit'in "agentic pre-merge checks" özelliği tarafından sağlanır. Pull request'leri birleştirmeden önce kalite standartlarına ve özel kurumsal gereksinimlere göre otomatik olarak doğrular ve doğrudan PR incelemesinde açıklamalarla birlikte geçti/kaldı sonuçları döndürür. Her kontrol, geliştiricileri uyaracak veya birleştirmeleri tamamen engelleyecek şekilde yapılandırılabilir. GitHub Copilot, Cursor BugBot ve Greptile PR inceleme özellikleri sunarken, sistematik doğrulama çerçeveleri yerine geri bildirim ve öneriler sunan danışmanlık sistemleri olarak işlev görürler.
** Cursor ve GitHub Copilot, kod inceleme bileşenlerinin ötesinde daha fazla yetenek sunabilir; karşılaştırmamıza yalnızca Cursor Bugbot ve GitHub Copilot Code Review özellikleri dahil edilmiştir.
Özellikler abonelik planlarına göre değişiklik gösterir, bu nedenle yukarıda kullanılabilir olarak işaretlenen bazı özellikler aboneliğinizde mevcut olmayabilir.
Otomatik kod incelemelerinde, CodeRabbit, GitHub Copilot ve Cursor Bugbot'u yapılandırmak Greptile'a göre daha kolaydı çünkü Greptile'da boş bir depo için otomatik kod incelemeleri etkinleştirilemez.
Özellik derinlemesine inceleme
CodeRabbit
- 40'tan fazla yerleşik linter ve güvenlik tarayıcısı.
- AST desen tabanlı özel talimatlar.
- Zamanla geliştirici geri bildirimlerinden uyarlanır.
- Geliştiriciler, takip soruları sormak, düzeltme talep etmek, önerileri sorgulamak için @coderabbitai'yi etiketleyebilir.
- Ek bağlam için özel MCP sunucularını destekler.
GitHub Copilot Code Review
- "Öneriyi uygula" düğmesi işi Copilot kodlama ajanına devreder.
- GitHub ekosistemiyle sıkı entegrasyon.
- copilot-instructions.md aracılığıyla özel talimatlar.
Greptile
- PR yorum geçmişinden ekibin kodlama standartlarını öğrenir.
- Desen depoları ile geliştiriciler, ek bağlam sağlayabilmeleri için greptile.json içinde ilgili depolara başvurabilirler.
- Geliştiriciler, takip soruları veya düzeltme önerileri için @greptileai ile yanıtlayabilir.
- Greptile, beğenme/beğenmeme geri bildirimlerinden öğrenir.
- Tüm PR'lar için otomatik-generated sıra diyagramları.
Cursor BugBot
- BugBot tarafından bir hata tanımlandıktan sonra, geliştiriciler hatayı düzeltmek için Cursor'ü hızla açmak üzere "Cursor'de Düzelt" düğmesini kullanabilirler.
- Geliştiriciler, BUGBOT.md dosyalarında kod inceleme kurallarını özelleştirebilirler.
Ayrıca Graphite'ı da karşılaştırmayı amaçladık; ancak, panolarındaki bir hata nedeniyle, yeni depolar için otomatik kod incelemelerini etkinleştiremedik. Destek ekipleriyle 25 Ekim 2025'te iletişime geçtik, ancak yanıt sorunu çözmedi. Takip e-postalarına ve Slack kanallarındaki bir mesaja rağmen sorun çözülmeden kaldı.
Bileşenler ve entegrasyonlar
* Bu çözümlerin tümü GitHub'ı destekler.
Metodoloji
Özel GitHub organizasyonumuz içinde her araç için ayrı karşılaştırma depoları oluşturduk.
Her araç için atanan deposunda otomatik kod incelemelerini etkinleştirdikten sonra, sırayla pull request'ler açtık, aracın incelemesini tamamlamasını bekledik ve ardından sonuçları kaydetmek için PR'ları kapattık. Hiçbir araç ayarını değiştirmedik veya özelleştirmedik. Her araç, tam olarak kurulduğu gibi varsayılan yapılandırması kullanılarak değerlendirildi.
İş akışımız, kaynak depoyu seçilen bir temel tarihte mevcut olduğu haliyle klonlayarak başlar, ardından orijinal depo yapısını koruyarak bu tarihten sonra gönderilen pull request'leri tek yeniden oynatır.
Tüm ürünlerin Kasım 2025 sürümlerini kullandık. Karşılaştırmamız 2 farklı kaynak depo aralığından oluşuyordu:
1. İyi bilinen, orta-büyük boyutlu depolar
Yapay zeka kod inceleme araçlarının büyük ve karmaşık yapılı depoları ne kadar iyi anladığını görmeyi amaçladık. 7 depoda toplam 289 PR inceledik.
2. Küçük ve yeni depolar
Büyük depolarda bağlam pencereleri yeterli olmadığı için LLM-as-a-judge'ımıza deponun tamamını besleyemeyeceğimizin farkındayız.
Bu nedenle, bunun üstesinden gelmek için, yeni ve küçük depoların ilk 3-5 PR'ını da değerlendirdik. MCP sunucuları ihtiyaçlarımıza mükemmel şekilde uydu. Sonuç olarak, 8 resmi MCP sunucusu seçtik ve üzerlerinde 20 PR inceledik.
Veri setimiz deneyimli geliştiriciler tarafından yazılmış kod içermektedir. Tamamen yapay zeka tarafından oluşturulan kod tabanlarındaki performansı değerlendirmedik.
Geliştirici Değerlendirmeleri
Rastgele 35 PR seçtik ve bunları 10 geliştiriciye atadık, her PR geliştiriciler tarafından 5 kez değerlendirildi. Değerlendirmeyi tekrarlamaktaki amacımız geliştirici önyargılarını en aza indirmekti. Geliştiriciler sonuçları satıcıdan bağımsız bir şekilde değerlendirdiler.
Çoğu aynı üst düzey çıkarımlara ulaştı:
- CodeRabbit'in ayrıntılı incelemeleri faydalıdır ve hata tespitinde başarılıdır.
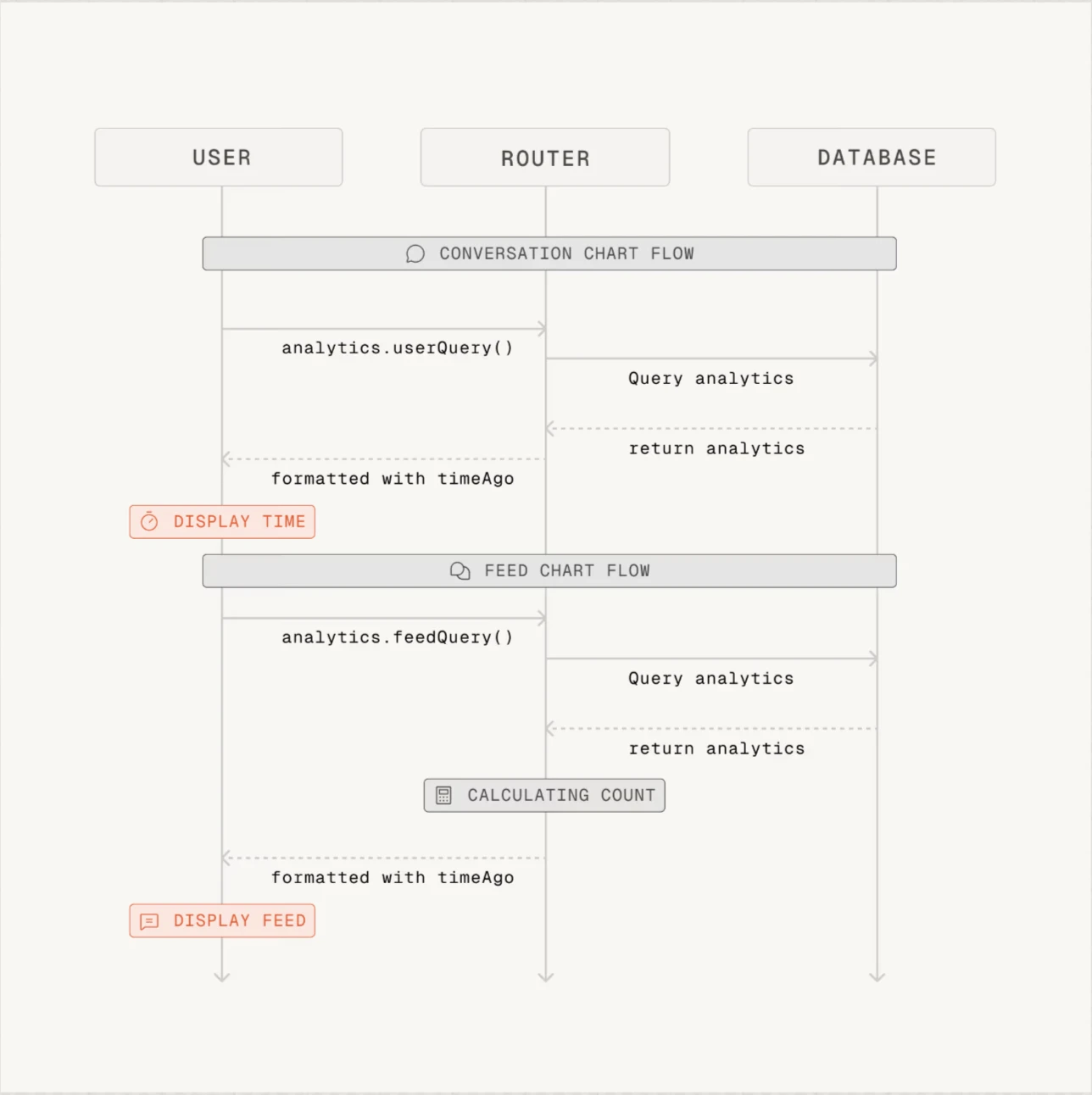
- Greptile başarılı özetler sağladı, ancak oluşturduğu sıra diyagramları bazı PR'lar için gerekli değildir.
Şekil 1: Greptile tarafından sağlanan örnek sıra diyagramı. Greptile, her PR için diyagramları oluşturur.1
- GitHub Copilot, koddaki yazım hatalarını bulmada çok başarılıdır ve yerinde öneriler yapar; analizi CodeRabbit ve Greptile'ınkinden daha kısadır.
- Cursor Bugbot daha az ayrıntılı ve daha az doğru analiz sağlar.
Değerlendirmelerin ardından, geliştiriciler için bir destek aracı olarak bunları kendi depolarında da kullanmaya başlayacaklarını belirttiler.
LLM-as-a-Judge
İncelemeleri değerlendirmek için GPT-5 kullandık. Değerlendirmeden sonra, çıktıyı JSON formatında yapılandırmak için GPT-4o kullandık.
Değerlendirme iş akışımız şunları içerir:
- Büyük depolar için: Orijinal PR gövdesi, diff ve araçlardan gelen yorumlar/incelemeler.
- Küçük depolar için: Tüm kod tabanı, orijinal PR gövdesi, diff ve araçlardan gelen yorumlar/incelemeler.
İşte kullandığımız prompt'un tamamı:
Her aracı şu boyutlarda değerlendirin (ölçek 1-5):
1. Doğruluk
Tespit edilen sorunlar gerçekten kodda gerçek problemler/hatalar/düzeltmeler mi?
– 5 (Mükemmel): Tespit edilen tüm sorunlar gerçek problemlerdir
– 4 (İyi): Çoğu sorun gerçek, küçük yanlış tanımlamalar
– 3 (Kabul edilebilir): Gerçek ve sorgulanabilir sorunların karışımı
– 2 (Zayıf): Tespit edilen sorunların çoğu gerçek problem değil
– 1 (Başarısız): Gerçek sorunları tespit edemiyor, tüm bulgular yanlış
2. Kapsamlılık
Önemli sorunları yakaladı mı? İnceleme ne kadar kapsamlı?
– 5 (Mükemmel): Tüm kritik sorunları ve en önemlilerini yakalar.
– 4 (İyi): Büyük sorunları yakalar, bazı küçükleri kaçırır
– 3 (Kabul edilebilir): Bazı önemli sorunları yakalar ancak belirgin boşlukları vardır
– 2 (Zayıf): Birkaç kritik sorunu kaçırır
– 1 (Başarısız): Tüm veya neredeyse tüm kritik sorunları kaçırır
3. Uygulanabilirlik
Öneriler açık ve uygulanabilir mi? Yama/düzeltme içeriyor mu? Kodda hata yoksa, o PR için tüm araçlara uygulanabilirlik için "null" yazın, hiçbir araca puan vermeyin.
– 5 (Mükemmel): Tüm öneriler açık yamalar/düzeltmeler içerir ve doğrudan uygulanabilir
– 4 (İyi): Çoğu önerinin açık yönlendirmesi var, bazıları yama içerir
– 3 (Kabul edilebilir): Öneriler biraz açık ancak bazı sorunlar için yama eksik
– 2 (Zayıf): Öneriler çoğunlukla belirsiz veya uygulanamaz
– 1 (Başarısız): Net bir öneri veya yönlendirme sağlanmamış
4. Derinlik
Kodun mantığını ve amacını anladığını gösteriyor mu?
– 5 (Mükemmel): Kod mantığı, mimarisi ve amacı hakkında derin bir anlayış gösterir
– 4 (İyi): Küçük boşluklarla iyi bir anlayış gösterir
– 3 (Kabul edilebilir): Yüzey düzeyinde anlayış, bazı bağlamları kaçırır
– 2 (Zayıf): Kod davranışının sığ veya yanlış açıklamaları
– 1 (Başarısız): Kodun mantığı ve amacı hakkında hiçbir anlayış yok
Çıktı Formatı
Her araç için şunları sağlayın:
1. Detaylı gerekçe: Ne buldu? Önemli sorunları kaçırdı mı? Yamalar dahil mi? Kod tabanının derinlemesine anlaşılması? Spesifik örnekler.
2. Bireysel puanlar (yukarıdaki ölçeklendirmeyi kullanarak her boyut için 1-5)
Örnek Çıktı
Araç A:
Gerekçe: Araç A, 145. satırdaki bağlantı havuzu mantığında gerçek bir bellek sızıntısını tespit ederek ve bir bağlam yöneticisi kullanarak spesifik bir yama sağlayarak mükemmel doğruluk gösterdi. Ayrıca API uç noktasındaki eksik hata yönetimini uygulanabilir kod ile yakaladı. Kapsamlılık puanı, büyük sorunları bulurken, üretim sorunlarına neden olabilecek asenkron işleyicideki yarış durumunu kaçırdığını yansıtmaktadır. 4 yorumun tamamı esasa ilişkin ve doğrudan uygulanabilirdi. Derinlik güçlüydü, kod tabanındaki kaynak yönetimi desenleri ve hata yayılımı hakkında anlayış gösterdi.
Doğruluk: 5
Kapsamlılık: 4
Uygulanabilirlik: 5
Derinlik: 4
Araç B:
Gerekçe: Araç B, 89. satırdaki girdi doğrulama güvenlik açığını doğru bir şekilde tespit etti ve parametre temizleme kullanarak net bir düzeltme sağladı. Ancak, token yeniden kullanımına izin veren kimlik doğrulama akışındaki kritik güvenlik açığını kaçırması nedeniyle kapsamlılık önemli ölçüde zarar gördü. Uygulanabilirlik çoğunlukla iyiydi – öneriler kod parçacıkları içeriyordu. Derinlik kabul edilebilir ancak yüzeyseldi, güvenlik modelini veya veri akışı etkilerini anlamak yerine yüzey düzeyindeki kontrollere odaklanmıştı.
Doğruluk: 4
Kapsamlılık: 1
Uygulanabilirlik: 4
Derinlik: 2
Değerlendirilecek araçlar: CodeRabbit, Cursor Bugbot, Github Copilot, Greptile
Objektif ve kapsamlı olun. Puanlarınızı desteklemek için incelemelerden spesifik örnekler kullanın.
Yapay zeka kod incelemesi nedir?
Yapay zeka kod incelemesi, hataları, verimsizlikleri ve potansiyel güvenlik açıklarını belirlemek için başta büyük dil modelleri (LLM'ler) olmak üzere makine öğrenimi modellerini kullanarak kaynak kodun otomatik analizidir. Bu sistemler, sorunları tespit etmenin yanı sıra bağlam farkında açıklamalar sağlayabilir, somut düzeltmeler önerebilir ve geliştiricilerin hem kod kalitesini hem de sürdürülebilirliğini iyileştirmelerine yardımcı olan yamalar üretebilir. Birçok yapay zeka inceleme aracı, değişiklikleri özetleyerek ve yeni eklenen kod için açıklayıcı yorumlar veya açıklamalar üreterek dokümantasyona da yardımcı olur.
Yapay zeka modelleri kodu hızlı ve ölçeklenebilir bir şekilde değerlendirebildiğinden, inceleme sürecini önemli ölçüde hızlandırır ve büyük veya hızlı ilerleyen projelerde tutarlı kodlama standartlarını korurken sorunları erkenden yakalamayı kolaylaştırır.
Cursor veya Claude Code gibi modern yapay zeka destekli geliştirme ortamlarında, geliştiriciler "vibe coding" yaparken veya büyük ölçüde otomatik-generated önerilere güvenirken kod tabanlarının nasıl evrildiğini istemeden takip edemeyebilirler. Bu, gizli güvenlik açıklarına veya mantıksal tutarsızlıklara yol açabilir. Yapay zeka kod inceleme araçları, yapay zeka tarafından oluşturulan kodu doğrulamak ve iyileştirmek için ek bir yapılandırılmış ve sistematik analiz katmanı sağlayarak bu riskleri azaltmaya yardımcı olur.
Yapay zeka kod incelemesinin faydaları
Verimlilik ve hız
Yapay zeka kod inceleme araçları, kodu gerçek zamanlı olarak analiz edebilir, geliştiriciler çalışırken anında geri bildirim sağlayabilir ve potansiyel sorunları işaretleyebilir. Özellikle büyük veya hızla gelişen kod tabanlarında insan incelemecilerin gözden kaçırabileceği hataları ve güvenlik açıklarını tespit edebilirler. Rutin kontrolleri otomatikleştirerek, bu araçlar geliştiricilerin daha üst düzey akıl yürütme, karmaşık problem çözme ve mimari kararlara odaklanmasını sağlar.
İyileştirilmiş kod kalitesi
Yapay zeka kod inceleme araçları, stilistik tutarsızlıkları ve en iyi uygulamalardan sapmaları belirleyerek ekipler arasında tutarlı kodlama standartlarının korunmasına yardımcı olur. Ayrıca, küçük iyileştirmelerden önemli hatalara kadar çok çeşitli kodlama sorunları hakkında ayrıntılı geri bildirim ve öneriler sunarlar. Zamanla, geliştiriciler bu geri bildirimlerden öğrenebilir, kodlama alışkanlıklarını geliştirebilir ve işlerinin genel kalitesini güçlendiren yeni teknikler benimseyebilirler.
Sınırlamalar ve zorluklar
Yapay zeka araçlarına aşırı güven
Yapay zeka kod incelemesiyle ilgili yaygın bir endişe, otomatik geri bildirime aşırı bağımlılıktır. Yapay zeka değerli bir içgörü kaynağı olabilse de, insan uzmanlığının tam bir ikamesi olarak görülmemelidir. Otomatik incelemeler iş akışlarını hızlandırabilir, ancak insan incelemeciler doğruluğu, bağlam farkındalığını ve proje hedefleriyle uyumu sağlamak için gerekliliğini korur. Karşılaştırmamızda, geliştiriciler sürekli olarak bu araçlara körü körüne güvenmeyeceklerini belirttiler. Onları, insan muhakemesinin yerini almak yerine onu tamamlayan asistanlar olarak gördüler.
Yanlış pozitifleri ve yanlış negatifleri yönetmek
Yanlış pozitifler, araç çalışan kodu yanlışlıkla sorunlu olarak tanımladığında ortaya çıkarken, yanlış negatifler gerçek sorunların gözden kaçırılmasıdır. Değerlendirmemizde, en önemli endişe yanlış negatiflerdi. Araçların, yanlış uyarılar vermekten ziyade önemli sorunları gözden kaçırma olasılığı daha yüksekti. Bu, temeldeki modellerde ve algoritmalarda sürekli iyileştirme ihtiyacını vurgulamaktadır.
Bu zorlukların üstesinden gelmek için, yapay zeka kod inceleme araçları daha iyi eğitim, gelişmiş bağlam yönetimi ve daha doğru akıl yürütme yetenekleri yoluyla gelişmelidir.
Yapay zeka kod incelemelerini kullanmak için en iyi uygulamalar
Uzmanlardan ipuçları
Yapay zeka incelemelerini insan içgörüleriyle eşleştirin: Kodun hem teknik olarak sağlam olduğundan hem de proje hedefleriyle uyumlu olduğundan emin olmak için yapay zeka kod incelemelerini insan incelemeleriyle birlikte kullanın.
Kuralları projenize uyacak şekilde özelleştirin: Gereksiz uyarıları azaltmak için yapay zeka aracının kurallarını projenizin kodlama standartlarına uyacak şekilde ayarlayın.
Yapay zeka geri bildirimini bir öğrenme aracı olarak kullanın: Yapay zeka önerilerini öğrenmek ve gelişmek için bir yol olarak ele alın, gelecekte benzer sorunlardan kaçınmak için nedenini ve nasılını anlamak üzere ekibinizle tartışın.
Teşekkürler
Manuel değerlendirmeleri gerçekleştirmek için zamanlarını ve uzmanlıklarını sunan geliştiricilere içten teşekkürlerimizi sunarız:
Aziz Durmaz (bir taşımacılık ve lojistik şirketinde CTO)
Berk Kalelioğlu (bir oyun geliştirme stüdyosunda kurucu ortak)
Elif Ece Örnek (bir seyahat web sitesinde yazılım mühendisi)
Haydar Külekçi (arama teknolojileri ve yapay zeka şirketinde danışman)
Mehmet Şirin Can (AIMultiple'da geliştirme başkanı)
Mehmet Korkmaz (e-spor ve video oyunları sektöründe bir medya şirketinde CTO)
Murat Orno (500'den fazla çalışanı olan bölgesel bir ödeme platformunda eski CTO)
Orçun Candan (AIMultiple'da full-stack geliştirici)
Yalçın Börlü (bir sağlık ve zindelik şirketinde kıdemli yazılım mühendisi)
Yiğit Dinç (bir yasal teknoloji şirketinin kurucu ortağı)
Ayrıca, karşılaştırmamıza dahil edilen açık kaynaklı depoların geliştiricilerine ve bakımcılarına çalışmaları ve topluluğa yaptıkları değerli katkılar için teşekkür ederiz.
Orijinal geliştirici kimliklerinin anonimleştirilmesi
Karşılaştırmayı sorumlu bir şekilde yürütmek için, upstream depolardan pull request'leri yeniden oynatırken tüm orijinal geliştirici isimlerini ve e-posta adreslerini anonimleştirdik. Karşılaştırma depoları herkese açık olduğundan, orijinal yazar bilgilerinin korunması istemeden kişisel verileri ifşa edebilir ve yeniden oluşturulan bir pull request her açıldığında veya güncellendiğinde geliştiricilere bildirim gönderilme riski oluşturabilir. GitHub, commit'leri ayrı bir depoda yeniden oynatıldığında yazarlara tipik olarak bildirim göndermese de, istenmeyen bildirimler, atıf sorunları veya gizlilik endişeleri olasılığından kaçınmayı en iyi uygulama olarak değerlendirdik.
Anonimleştirme şunları sağlar:
- Geliştiriciler binlerce otomatik PR olayından rahatsız edilmez.
- Kişisel bilgiler farklı bir herkese açık depoda yeniden yayınlanmaz.
- Karşılaştırmalar tarafsız kalır, araçların veya LLM değerlendiricilerin tanınabilir yazar isimlerinden etkilenmesini engeller.
- Açık kaynak katkılarıyla çalışırken etik ve gizlilik standartları korunur.
Yalnızca kimlik meta verileri değiştirilmiş; karşılaştırmanın gerçekliğini ve tekrarlanabilirliğini korumak için tüm kod, diff'ler, commit sıralaması ve dosya yapıları tam olarak korunmuştur.
Bu benchmarkı kaynak gösterin
Yayınlayacağınız yere uygun formatı seçin. Bağlantılı sürümü CMS'inize yapıştırmak, geri bağlantıyı korur.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Alper, Şevval},
title = {{Yapay Zeka Kod İnceleme Araçları Karşılaştırması}},
year = {2026},
month = mar,
howpublished = {\url{https://aimultiple.com/ai-code-review-tools}},
note = {AIMultiple. Erişim tarihi: 13 Mart 2026}
}
Yorum yapan ilk kişi olun
E-posta adresiniz yayınlanmayacak. Tüm alanlar gereklidir. Yorumlar orijinal dilinde bırakılır.