En İyi 20+ Agentic RAG Çerçevesi
Agentic RAG, LLM performansını artırarak ve daha fazla uzmanlaşma sağlayarak geleneksel RAG'ı geliştirir. Birden çok veritabanı arasında yönlendirme ve sorgu oluşturma konusundaki performansını değerlendirmek için bir kıyaslama gerçekleştirdik.
Agentic RAG çerçevelerini ve kütüphanelerini, standart RAG'tan temel farklarını, avantajlarını ve zorluklarını keşfedin ve tam potansiyellerini ortaya çıkarın.
Agentic RAG kıyaslaması: Çoklu veritabanı yönlendirme ve sorgu oluşturma
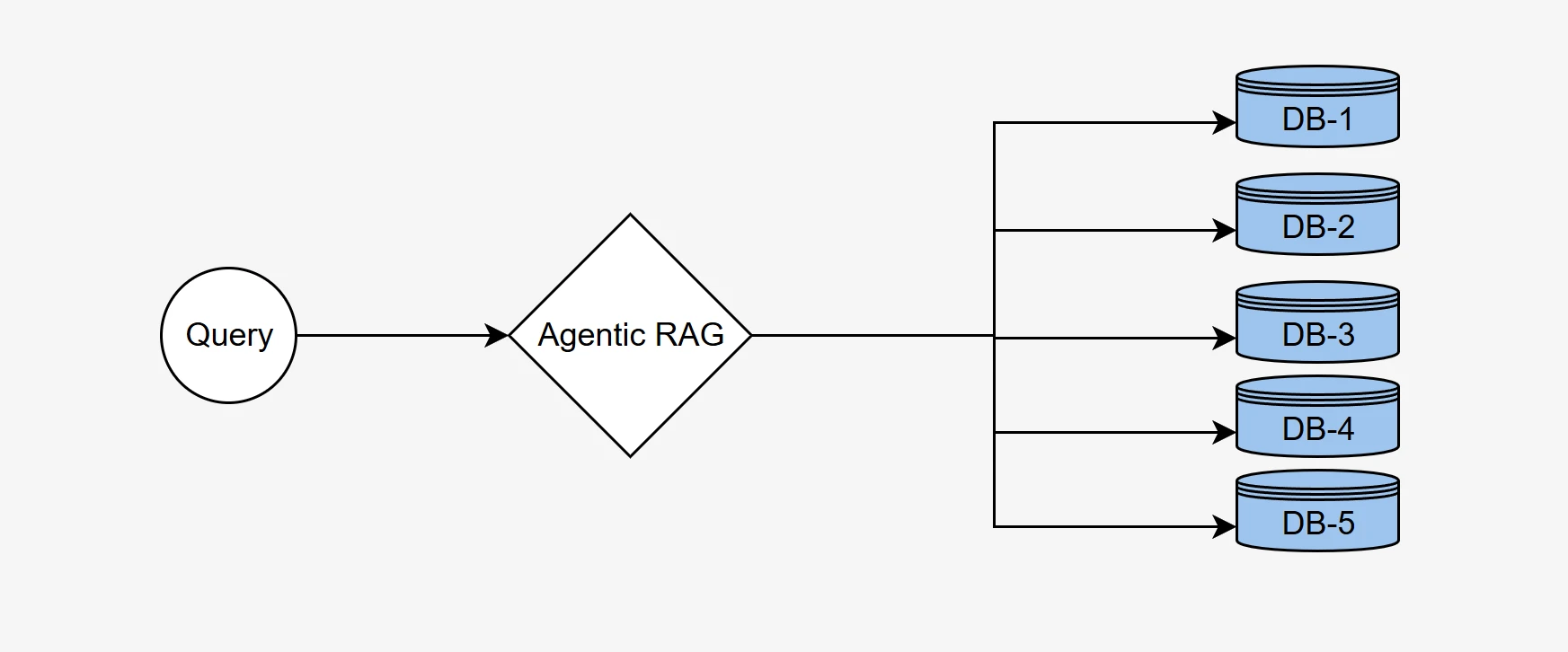
Sistemin, her biri benzersiz bağlamsal bilgilere sahip beş farklı veritabanından oluşan bir kümeden doğru veritabanını seçme ve doğru veriyi almak için anlamsal olarak doğru SQL sorguları oluşturma yeteneğini göstermek için agentic RAG kıyaslama metodolojimizi kullandık.
Agentic RAG kıyaslamasında şunları kullandık:
- Ajan Çerçevesi: Langchain
- Vektör veritabanı: ChromaDB
Gerçek dünyadaki birçok kurumsal senaryoda, veriler genellikle her biri belirli alanlara veya görevlere özgü uzmanlaşmış bilgiler içeren birden çok veritabanına dağılmıştır. Örneğin, bir veritabanı finansal kayıtları saklarken, bir diğeri müşteri verilerini veya envanter ayrıntılarını tutar.
Etkili bir Agentic RAG sistemi, doğru bilgiyi almak için kullanıcı sorgusunu en ilgili veritabanına akıllıca yönlendirmelidir. Bu süreç, sorguyu analiz etmeyi, bağlamı anlamayı ve mevcut veritabanları kümesinden uygun veri kaynağını seçmeyi içerir.
Ajanın düşünce süreci
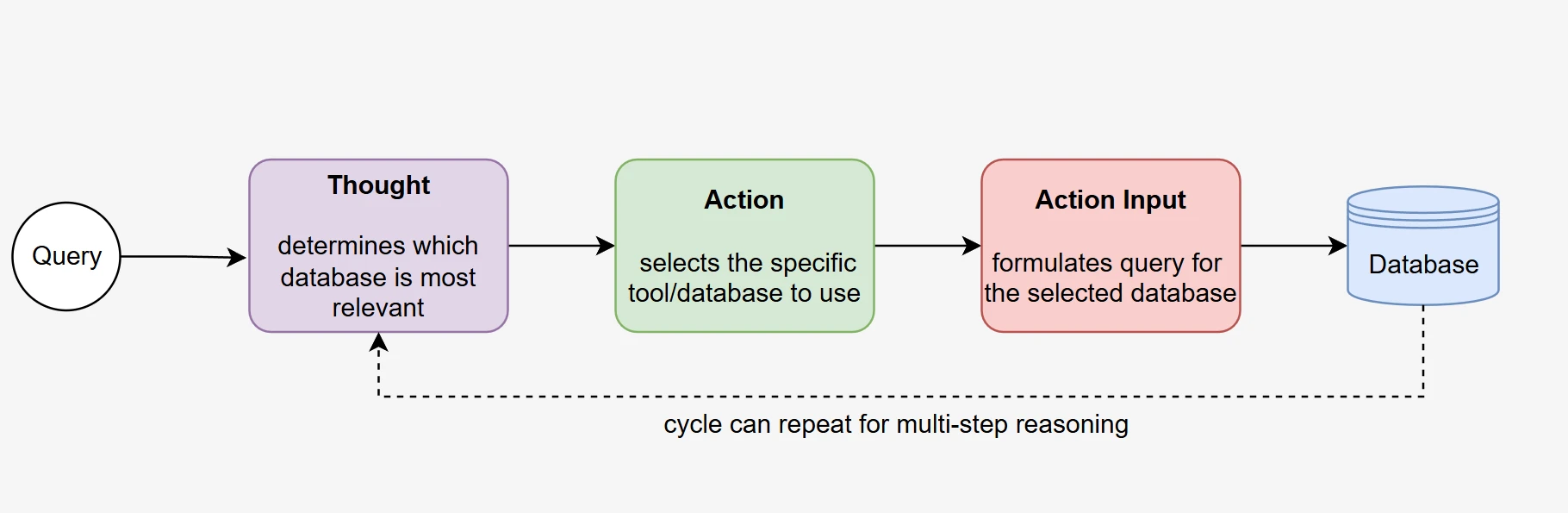
Bir Agentic RAG sisteminin kalbinde, LLM'nin bir hedefe ulaşmak için otonom olarak akıl yürütme ve eylemde bulunma yeteneği yatar. İşlev çağrısı tabanlı yaklaşımımız, modellerin kendi kendine yönlendirilen veritabanı seçimi ve yinelemeli bilgi toplama yoluyla gerçek ajan davranışı sergilemesini sağlar.
Otonom karar verme: Ajan, gelen kullanıcı sorgusunu analiz eder ve sorgu bağlamı ile mevcut işlev açıklamalarına dayanarak hangi veritabanı işlevinin çağrılacağına otonom olarak karar verir. Bu karar verme süreci, önceden belirlenmiş yönlendirme kuralları olmadan gerçekleşir ve gerçek akıl yürütme yeteneklerini gösterir.
Çok adımlı yürütme: Ajan, tipik olarak, önce ilgili veritabanını belirlemek ve erişmek, ardından ayrıntılı şema bilgilerini toplamak ve son olarak SQL sorgusunu oluşturmadan önce anlayışını rafine etmek için sırayla birden çok işlev çağrısı gerçekleştirir. Bu yinelemeli süreç, insan problem çözme yaklaşımlarını yansıtır.
Kendi kendini düzeltme yeteneği: İlk işlev çağrıları yeterli bilgi sağlamadığında, ajan otonom olarak iyileştirilmiş parametrelerle ek çağrılar yapmaya karar verebilir, bu da basit alım sistemlerinin ötesine geçen uyarlanabilir bir davranış sergiler.
Hedef odaklı davranış: Süreç boyunca ajan, doğru bir SQL sorgusu oluşturmaya odaklanır ve sonraki kararlarını ve eylemlerini bilgilendirmek için her işlev çağrısı sonucunu kullanır.
Bu otonom, çok turlu etkileşim deseni, agentic RAG'ı, önceden belirlenmiş yolları ve tek seferlik alım mekanizmalarını izleyen geleneksel RAG sistemlerinden temelden ayırır.
Agentic RAG kıyaslama metodolojisi
Bu kıyaslama, Büyük Dil Modellerinin (LLM'ler) bir Alım Destekli Üretim (RAG) işlem hattı içinde otonom ajanlar olarak işlev görme kapasitesini değerlendirir. Spesifik olarak iki temel yetkinliği ölçer:
- Veritabanı yönlendirme: Ajanın, doğal dilde bir soru verildiğinde birden çok aday arasından en ilgili veritabanını doğru bir şekilde belirleme ve seçme yeteneği.
- SQL oluşturma: Ajanın, seçilen veritabanının şemasını kullanarak doğru bir SQL sorgusu oluşturma yeteneği.
Veri kümesi
Kıyaslama, metin-SQL görevleri için yaygın olarak kabul gören bir akademik benchmark olan BIRD-SQL veri kümesini1 kullanır. BIRD-SQL, doğal dil sorularını temel doğruluk veritabanı tanımlayıcıları ve altın standart SQL sorgularıyla eşleştirir, bu da hem yönlendirme doğruluğunu hem de sorgu üretim kalitesini değerlendirmek için idealdir.
Tam BIRD-SQL veri kümesinden, çeşitli alanları kapsayan beş farklı veritabanına dağıtılmış 500 soruluk bir alt küme oluşturduk:
Her sorunun tam olarak bir doğru hedef veritabanı vardır. Her sorunun cevabı belirli bir veritabanında bulunur ve ajanın kesin bir yönlendirme kararı vermesini gerektirir.
Anlamsal belirsizlik zorluğu
Ajanın, yüzeysel anahtar kelime eşleştirmesinin ötesindeki akıl yürütme yeteneklerini değerlendirmek için, soru seçimi sırasında kasıtlı bir karıştırıcı faktör olarak veritabanları arası anlamsal benzerlik ekledik.
Soru seçim süreci:
- Beş veritabanındaki tüm aday sorular, cümle dönüştürücüler (
all-MiniLM-L6-v2) kullanılarak gömüldü. - Veritabanları arası soru çiftleri hesaplandı ve kosinüs benzerliğine göre sıralandı.
- Kosinüs benzerlik puanı 0.70'in üzerinde olan sorular, tamamen farklı veritabanlarına ait anlamsal olarak benzer soruların olduğu senaryolar oluşturmak için bilinçli olarak dahil edilmeye öncelik verildi.
Anlamsal karıştırma örneği:
Soru A (finansal VT): “Kredisi ilk olarak 1993/7/5 tarihinde onaylanan müşteri için, hesap bakiyesindeki artış oranı 1993/3/22'den 1998/12/27'ye kadar nedir?”
Soru B (banka_kartı VT): “2012/8/25 tarihinde 634.8 ödeyen müşteri için 2012 yılından 2013 yılına tüketim azalış oranı neydi?”
Her iki soru da neredeyse aynı anlamsal kalıpları izler: bir işlem olayı aracılığıyla belirli bir müşteriyi tanımlar, ardından bir zaman dilimi boyunca bir oran değişikliği hesaplar. Ancak doğru veritabanları tamamen farklıdır; biri kredi ve hesap verilerini, diğeri ise işlem ve tüketim verilerini gerektirir. Bu, ajanı her iki veritabanıyla da eşleşecek yüzeysel finansal anahtar kelimelere güvenmek yerine, veri alanı hakkında daha derin bağlamsal akıl yürütme yapmaya zorlar.
Veritabanı ortamı
Her veritabanının şeması ve kısa bir doğal dil açıklaması, verimli anlamsal alım için kullanılan bir vektör veritabanı olan ChromaDB'de saklandı. Her veritabanının koleksiyonu şunları içerir:
- Veritabanının alanı ve amacı hakkında üst düzey bir açıklama
- Sütun adları, veri türleri ve değer açıklamaları dahil olmak üzere tablo başına şema belgeleri
Bu kurulum, ajanın bir hedef veritabanı seçtikten sonra anlamsal arama yoluyla ilgili şema bilgilerini almasını sağlar.
Ajan mimarisi
Tüm modeller arasında adil ve standartlaştırılmış bir karşılaştırma sağlamak için işlev çağrısı tabanlı ajan mimarisi kullanıldı. Beş veritabanının her biri, standartlaştırılmış parametrelere sahip ayrı bir çağrılabilir işlev (araç) olarak temsil edildi. Bu tasarım, her modelin yerel işlev çağırma yeteneklerinden yararlanarak modellerin otonom olarak şunları yapmasını sağlar:
- Gelen soruyu analiz etme
- Uygun veritabanı işlevini seçme ve çağırma
- Şema bilgilerini bir işlev yanıtı olarak alma
- İsteğe bağlı olarak iyileştirme için ek işlevler çağırma
- Nihai SQL sorgusunu oluşturma
Bu yaklaşım, geleneksel modeller ve akıl yürütme için optimize edilmiş modeller de dahil olmak üzere farklı model aileleri arasında tutarlı bir değerlendirme metodolojisi sağlar.
Agentic süreç akışı
Sistem, sabit bir işlem hattı yerine gerçek bir çok turlu ajan döngüsü uygular:
- Soru analizi: Ajan, doğal dil sorusunu ve mevcut beş veritabanı işlevinin açıklamalarını alır.
- Veritabanı seçimi (Araç çağrısı): Ajan, en ilgili olduğunu düşündüğü veritabanı işlevini otonom olarak seçer ve çağırır. Bu gerçek bir işlev çağrısıdır; ajan, şemayı aynı konuşma bağlamı içinde yapılandırılmış bir araç yanıtı olarak alır.
- Şema üzerinde akıl yürütme: Ajan, döndürülen şemayı gözlemler ve hangi tabloların ve sütunların soruyla ilgili olduğu konusunda akıl yürütür.
- İsteğe bağlı kurtarma: Ajan, seçilen veritabanının gerekli bilgileri içermediğine karar verirse, harici müdahale olmaksızın kendi kendini düzeltmeyi sağlayarak farklı bir veritabanı işlevi çağırabilir.
- SQL oluşturma: Biriken bağlama (soru + şema gözlemi) dayanarak, ajan nihai SQL sorgusunu üretir.
Bu çok turlu konuşma akışı, kıyaslamayı geleneksel tek seferlik RAG yaklaşımlarından ayırır. Ajan, turlar boyunca tam bağlamı korur, eylemlerinin sonuçlarını gözlemleyebilir ve yaklaşımını yinelemeli olarak rafine edebilir - gerçek ajan davranışının ayırt edici özellikleri.
Temel mimari özellikler:
- Konuşma süreklidir, ajan kendi önceki akıl yürütmesini ve araç yanıtlarını görür
- Yapay tur sınırı uygulanmaz; ajan yeterli bilgiye sahip olduğuna kendisi karar verir
- Hem veritabanı seçimi hem de SQL oluşturma aynı ajan oturumu içinde gerçekleşir
- Soru başına araç çağrısı sayısı, ajan verimliliğini analiz etmek için ek bir metrik olarak kaydedilir
Değerlendirme süreci
Kıyaslamadaki her soru için:
Adım 1: Veritabanı yönlendirme değerlendirmesi
Ajanın ilk veritabanı işlev çağrısı, yönlendirme kararı olarak kaydedilir. Bu, BIRD-SQL veri kümesinde belirtilen temel doğruluk veritabanı ile karşılaştırılır.
Metrik: Veritabanı yönlendirme doğruluğu (toplam soru sayısı içindeki doğru seçim yüzdesi)
Adım 2: SQL kalite değerlendirmesi
Ajan tarafından oluşturulan SQL sorgusu, LLM Hakem yaklaşımı kullanılarak değerlendirilir. Ayrı bir hakem modeli (Claude 4 Sonnet), ajanın ürettiği SQL ile BIRD-SQL temel doğruluk SQL'ini alır ve 0–5 arası bir anlamsal benzerlik puanı atar:
Önemli tasarım kararı: SQL kalitesi, ajanın doğru veritabanını seçmesi durumunda değerlendirilir. Eğer ajan yanlış veritabanına yönlendirirse, yanlış bir şemaya karşı yapılan bir SQL sorgusu doğası gereği anlamsız olduğu için otomatik olarak 0 puan alır. Bu, SQL kalite metriğinin, yönlendirme hatalarından arınmış olarak yalnızca sorgu oluşturma yeteneğini yansıtmasını sağlar.
Metrikler:
- Ortalama SQL kalite puanı (5.0 üzerinden), doğru yönlendirilen sorular üzerinden hesaplanır
- Mükemmel eşleşme oranı: 5/5 puan alan doğru yönlendirilmiş soruların yüzdesi
Kontrollü değişkenler
Modeller arasında adil karşılaştırma sağlamak için:
- Tüm modeller aynı sistem istemlerini ve araç tanımlarını alır
- Deterministik çıktılar için sıcaklık 0'a ayarlanmıştır
- Hiçbir modele özel prompt'lar mühendisliği veya az sayıda örnek sağlanmaz (sıfır atımlı değerlendirme)
- BIRD-SQL kanıt alanı (alana özgü ipuçları), yardımsız akıl yürütmeyi ölçmek için tüm modellerden gizlenir
- Tüm modeller, aynı şema gömme işlemlerine sahip aynı ChromaDB örneğine erişir
Agentic RAG çerçeveleri ve kütüphaneleri
Agentic RAG çerçeveleri, yapay zeka sistemlerinin bilgi bulmasına, akıl yürütmesine, karar vermesine ve eylemde bulunmasına olanak tanır. Agentic RAG'ı güçlendiren en iyi araçlar ve kütüphaneler:
Bu liste aşağıdaki kriterleri karşılayan araçları içerir:
- GitHub'da 50+ yıldız.
- Agentic RAG projelerinde yaygın kullanım.
Tabloda şuna dikkat edin:
- Araç kullanımı, bir sistemin kendi ortamında araçları yönlendirme ve çağırma doğal yeteneğini ifade eder.
- Araç türü, araçların ana kullanım alanını ifade eder, örneğin:
- Agentic RAG çerçeveleri, Agentic RAG sistemleri oluşturmak, dağıtmak veya yapılandırmak için özel olarak tasarlanmıştır.
- Ajan kütüphaneleri, akıl yürütebilen, karar verebilen ve çok adımlı görevleri yürütebilen akıllı ajanların oluşturulmasını sağlar.
- LLMOps çerçeveleri, LLM'lerin yaşam döngüsünü yönetir ve ajan tabanlı sistemler içinde LLM'lerin dağıtımını ve kullanımını optimize eder.
- LLM'ler, dinamik karar vermeye olanak tanıyan araç çağırma ve yönlendirme için yerleşik yeteneklere sahiptir. Diğer LLM'ler, ajan işlevselliğini etkinleştirmek için harici API'lere veya entegrasyonlara ihtiyaç duyabilir.
- Doğrulama, araç kullanımı ve ajan türleri için kamuya açık kaynaklar aracılığıyla sağlanır.
Agentic RAG nedir?
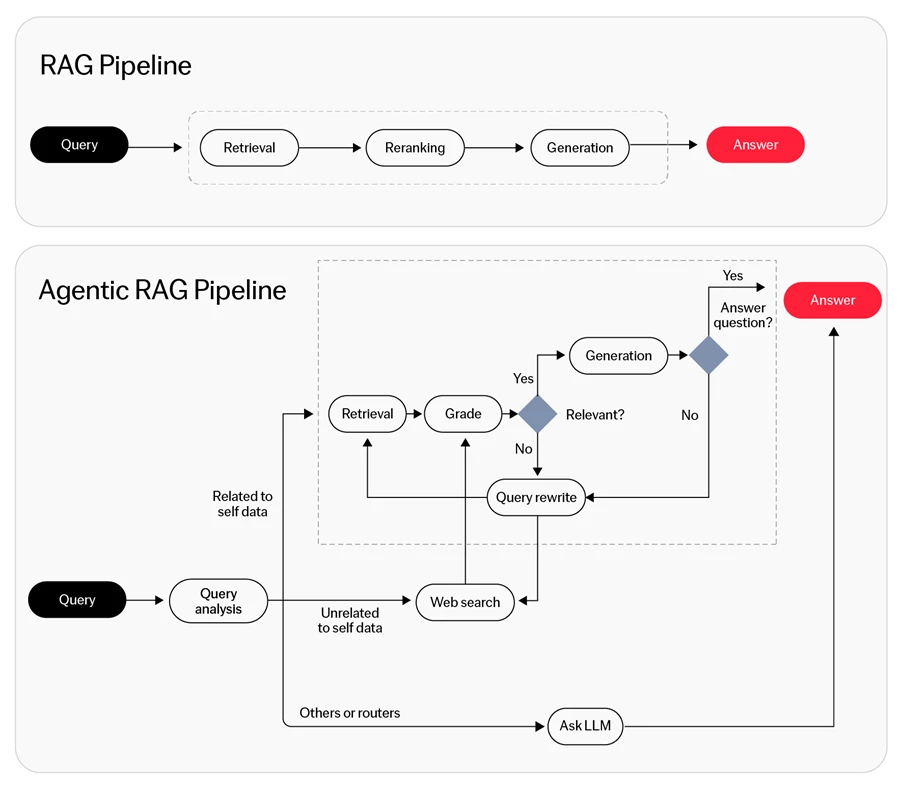
Agentic Alım Destekli Üretim (RAG), dinamik karar verme ve bilgi sentezi sağlamak için alım tekniklerini üretken modellerle birleştiren bir yapay zeka çerçevesidir. Bu yaklaşım, geleneksel RAG'ın doğruluğunu gelişmiş yapay zekanın üretken yetenekleriyle birleştirerek yapay zeka destekli görevlerin verimliliğini ve etkinliğini artırmayı amaçlar.
Geleneksel RAG sistemlerinin kısıtlamaları
Agentic RAG, standart RAG sistemiyle karşılaşılan aşağıdaki gibi kısıtlamaların üstesinden gelmeyi amaçlar:
- Bilgi önceliklendirmede zorluk: RAG sistemleri genellikle büyük veri kümeleri içindeki verileri verimli bir şekilde yönetmekte ve önceliklendirmekte zorlanır, bu da genel performansı düşürebilir.
- Uzman bilgisinin sınırlı entegrasyonu: Bu sistemler, genel bilgileri tercih ederek uzmanlaşmış, yüksek kaliteli içeriğin değerini düşük görebilir.
- Zayıf bağlamsal anlayış: Verileri alabilse de, genellikle bunların ilgililiğini veya belirli sorguyla nasıl uyumlu olduğunu tam olarak kavramakta başarısız olurlar.
Agentic RAG nasıl oluşturulur
1. Araç kullanımı
- Yönlendiricileri kullanın: İlk adım, belgelerin alınıp alınmayacağına, hesaplamalar yapılıp yapılmayacağına veya sorgunun yeniden yazılıp yazılmayacağına karar vermek için yönlendiricileri kullanmayı içerir. Bu yaklaşım, istekleri birden çok araca yönlendirmek için karar verme yetenekleri ekleyerek büyük dil modellerinin (LLM'ler) uygun işlem hatlarını seçmesini sağlar.
- Araç çağırma entegrasyonu: Bu, ajanların seçilen araçlarla bağlantı kurması için bir arayüz oluşturmayı ifade eder. Kullanıcılar, araç çağırma yeteneklerine sahip LLM'leri kullanabilir veya aşağıdakileri yapmak için kendileri oluşturabilir:
- Yürütülecek bir işlev seçme.
- Bu işlev için gerekli argümanları çıkarsama.
- Veritabanı sorguları veya karmaşık akıl yürütme gibi görevleri etkinleştirerek sorgu anlayışını geleneksel RAG işlem hatlarının ötesine taşıma.
2. Ajan uygulaması
- Tek çağrılı ajanlar: Bir sorgu, uygun araca tek bir çağrıyı tetikler ve yanıtı döndürür. Bu, basit görevler için etkilidir, ancak belirsiz veya karmaşık sorgularda zorlanabilir.
- Çoklu çağrılı ajanlar: Bu yaklaşım, görevleri her biri belirli bir alt göreve odaklanan uzman ajanlar arasında bölüştürmeyi içerir. Örneğin:
- Alıcı ajan: Gerçek zamanlı sorgu alımını optimize eder.
- Yönetici ajan: Görev dağıtımı ve orkestrasyonu yönetir.
3. Çok adımlı akıl yürütme
Karmaşık iş akışları için ajanlar, ara adımların belleğini korurken yinelemeli, çok adımlı akıl yürütme gerçekleştirmek için akıl yürütme döngülerini kullanır. Bu döngüler şunları içerir:
- Birden çok aracı çağırma.
- Veri alma ve ilgililiğini doğrulama.
- Gerektiğinde sorguları yeniden yazma.
Çerçeveler, genellikle genel sürecin verimli bir şekilde yürütülmesini sağlamak için belirli alt görevleri yerine getirmek üzere birden çok ajan tanımlar.
4. Hibrit yaklaşımlar: alım ve yürütmeyi birleştirme
Hibrit bir yaklaşım, alım işlem hatlarını dinamik yürütme stratejileriyle birleştirir:
- Belgelere erişim için gömme ve vektör tabanlı alım stratejileri.
- Dinamik sorgu çözümlemesi için araç çağırma yetenekleri.
- Uzmanlaşmış alt görevler için çok ajanlı iş birliği.
RAG ile agentic RAG arasındaki fark nedir?
İşte RAG ile Agentic RAG'ın farklı yönlere göre güçlü ve zayıf yönleri:
- İstem mühendisliği
- Geleneksel RAG: İstemlerin manuel optimizasyonuna büyük ölçüde bağımlıdır.
- Agentic RAG: Bağlama ve hedeflere göre istemleri dinamik olarak ayarlar, manuel müdahale ihtiyacını azaltır.
- Bağlam farkındalığı
- Geleneksel RAG: Sınırlı bağlamsal farkındalığa sahiptir ve statik alım süreçlerine dayanır.
- Agentic RAG: Konuşma geçmişini dikkate alır ve alım stratejilerini bağlama göre dinamik olarak uyarlar.
- Otonomi
- Geleneksel RAG: Otonom eylemlerden yoksundur ve gelişen durumlara uyum sağlayamaz.
- Agentic RAG: Gerçek zamanlı eylemler gerçekleştirir ve geri bildirime ve gerçek zamanlı gözlemlere göre ayarlamalar yapar.
- Akıl yürütme
- Geleneksel RAG: Çok adımlı akıl yürütme ve araç kullanımı için ek sınıflandırıcılara ve modellere ihtiyaç duyar.
- Agentic RAG: Çok adımlı akıl yürütmeyi dahili olarak ele alır, harici modellere olan ihtiyacı ortadan kaldırır.
- Veri kalitesi
- Geleneksel RAG: Veri kalitesini değerlendirmek veya doğruluğu sağlamak için yerleşik bir mekanizmaya sahip değildir.
- Agentic RAG: Veri kalitesini değerlendirir ve doğru çıktılar sağlamak için üretim sonrası kontroller yapar.
- Esneklik
- Geleneksel RAG: Statik kurallara göre çalışır, uyarlanabilirliği sınırlar.
- Agentic RAG: Dinamik alım stratejileri kullanır ve gerektiğinde yaklaşımını ayarlar.
- Alım verimliliği
- Geleneksel RAG: Alım statiktir ve verimsizlikler nedeniyle genellikle maliyetlidir.
- Agentic RAG: Gereksiz işlemleri en aza indirmek için alımları optimize eder, maliyetleri düşürür ve verimliliği artırır.
- Basitlik
- Geleneksel RAG: Daha az yapılandırma karmaşıklığıyla anlaşılır bir kurulum sunar.
- Agentic RAG: Dinamik ve bağlam duyarlı işlemleri desteklemek için daha karmaşık yapılandırmalar içerir.
- Öngörülebilirlik
- Geleneksel RAG: Tutarlı ve kural tabanlıdır, ancak davranışta katıdır.
- Agentic RAG: Davranış, gerçek zamanlı bağlam ve gözlemlere bağlı olarak dinamik olarak değişebilir.
- Dağıtım maliyeti
- Geleneksel RAG: Temel kurulumlar için daha ucuzdur, ancak uzun vadede daha yüksek operasyonel maliyetlere yol açabilir.
- Agentic RAG: Gelişmiş özellikler ve dinamik yetenekler nedeniyle daha yüksek başlangıç yatırımı gerektirir.
Uzun bağlam modelleri agentic RAG'a karşı: Alım gereksiz hale geldiğinde
2025-2026'nın bağlam penceresi devrimi, RAG mimarisindeki temel bir varsayımı sorguluyor. Modeller artık 1-2 milyon token'ı destekliyor ve temel bir soruyu gündeme getiriyor: doğrudan bağlam işleme, karmaşık alım ajanlarından ne zaman daha iyi performans gösterir?
Değişen bağlam manzarası
Bağlam pencereleri, 2024 başlarında 128k token'dan 2026'da 1M'in üzerine dramatik bir şekilde genişledi. Test verisi olarak tam uzunlukta romanları kullanan son araştırmalar, bu genişlemenin mühendislerin dikkate alması gereken yeni mimari ödünleşimler yarattığını ortaya koymaktadır.4
Büyük bağlamları işlemenin hesaplama maliyeti, alım sistemlerinin mühendislik karmaşıklığı ve potansiyel hata noktalarına karşı tartılmalıdır. 1M token'ı işlemek, parçalara ayırma ve indekslemenin kayıplı sıkıştırmasını ortadan kaldırır, ancak sorgu başına yüksek bir maliyetle.
Alım darboğazı sorunu
Uzun formlu belgeler üzerine yapılan araştırmalar, geleneksel RAG yaklaşımlarında ciddi bir sınırlılık tespit etmektedir. Standart top-k alımı, araştırmacıların “alım darboğazı” dediği şeyi yaratır: ilk getirme işlemi ilgili parçayı kaçırdığında, sistemin bir kurtarma mekanizması yoktur.
Agentic RAG, yinelemeli sorgu iyileştirme yoluyla bunu ele alır. Çalışmalar, ajan sistemlerinin, tek seferlik alımda tamamen başarısız olan sorunların önemli bir kısmını başarıyla çözdüğünü göstermektedir. Otonom döngü, ajanların ilk denemeler yetersiz bilgi döndürdüğünde sorguları yeniden formüle etmesine olanak tanır.5
Ancak, veriler genişletilmiş bağlam pencerelerine sığdığında, doğrudan uzun bağlam işleme, sofistike ajan alım sistemlerinden bile daha iyi performans gösterir. Performans farkı, modelin tüm belge üzerinde aynı anda akıl yürütebilmesi ve parça tabanlı alımın doğasında var olan parçalanmayı önlemesinden kaynaklanır.
Agentic RAG modellerinin farklı türleri
Büyük Dil Modellerini (LLM'ler) Alım Destekli Üretim (RAG) çerçeveleri içinde kullanan ajanlardan bazıları şunlardır:
- Yönlendirme ajanı: Belirli bir sorgu için en uygun Alım Destekli Üretim (RAG) işlem hattını (ör. özetleme veya soru cevaplama) seçmek üzere ajan akıl yürütmesi için bir Büyük Dil Modeli (LLM) kullanır. Ajan, giriş sorgusunu analiz ederek en iyi uyumu belirler.
- Tek seferlik sorgu planlama ajanı: Karmaşık sorguları daha küçük alt sorgulara ayırır, bunları farklı veri kaynaklarına sahip çeşitli RAG işlem hatlarında yürütür ve sonuçları kapsamlı bir yanıtta birleştirir.
- Araç kullanımı ajanı: Ek bağlam sağlamak için harici veri kaynaklarını (ör. API'ler, veritabanları) dahil ederek standart RAG çerçevelerini geliştirir. Bu, LLM'leri kullanarak sorguların daha zengin bir şekilde işlenmesine olanak tanır.
- ReAct ajanı: Sıralı, çok parçalı sorguları ele almak için akıl yürütme ve eylemi entegre eder. Bellek içi durumu korur ve sorgu tamamen çözülene kadar yinelemeli olarak araçları çağırır, çıktılarını işler ve sonraki adımları belirler.
- Dinamik planlama ve yürütme ajanı: Daha karmaşık sorguları yönetmeyi amaçlayan bu ajan, üst düzey planlamayı yürütmeden ayırır. Sorguyu yanıtlamak için gereken adımların bir hesaplama grafiğini tasarlamak için bir LLM'yi planlayıcı olarak kullanır ve bu adımları verimli bir şekilde gerçekleştirmek için bir yürütücü kullanır. Odak noktası, üretim ortamları için güvenilirlik, gözlemlenebilirlik, paralelleştirme ve optimizasyondur.
Agentic RAG faydaları
Agentic RAG, LLM'leri şu yollarla geliştirir:
- Otonom ve hedef odaklı yaklaşım: Geleneksel RAG'ın aksine, Agentic RAG, tanımlanmış hedeflere ulaşmak ve daha derin, daha anlamlı etkileşimler peşinde koşmak için kararlar veren otonom bir ajan gibi davranır.
- Gelişmiş bağlam farkındalığı ve hassasiyeti: Agentic RAG, ilgili, bilgilendirilmiş yanıtlar ve karar verme sağlamak için konuşma geçmişini, kullanıcı tercihlerini, önceki etkileşimleri ve mevcut bağlamı dinamik olarak dikkate alır.
- Dinamik alım ve gelişmiş akıl yürütme: Sorgulara özel akıllı alım yöntemleri kullanırken, alınan verilerin doğruluğunu ve güvenilirliğini değerlendirir ve doğrular.
- Çok ajanlı orkestrasyon: Birden çok uzman ajanı koordine eder, sorguları yönetilebilir görevlere böler ve doğru sonuçlar sunmak için kusursuz koordinasyon sağlar.
- Üretim sonrası doğrulama ile artan doğruluk: Agentic RAG modelleri, üretilen içerik üzerinde kalite kontrolleri yaparak mümkün olan en iyi yanıtı sağlar ve üstün performans için LLM'leri ajan tabanlı sistemlerle birleştirir.
- Uyarlanabilirlik ve öğrenme: Bu sistemler zaman içinde sürekli olarak öğrenir ve gelişir, problem çözme yeteneklerini, doğruluğu ve verimliliği artırır ve belirli görevler için çeşitli alanlara uyum sağlar.
- Esnek araç kullanımı: Ajanlar, çeşitli uygulamalar için veri toplama, işleme ve özelleştirmeyi geliştirmek üzere arama motorları, veritabanları veya API'ler gibi harici araçlardan yararlanabilir.
Agentic RAG zorlukları
- Veri kalitesi: Güvenilir çıktılar, yüksek kaliteli, özenle seçilmiş veriler gerektirir. Kullanıcı sorgu gereksinimlerini karşılamak için metinsel ve görsel veriler dahil olmak üzere çeşitli veri kümelerini entegre ederken ve işlerken zorluklar ortaya çıkar. Ayrıca, veri alım süreçleri de doğruluk ve tutarlılık sağlamalıdır.
- İpucu: Metinsel ve görsel veri kümeleri arasında tutarlı ve yüksek kaliteli veri entegrasyonu sağlamak için otomatik veri temizleme araçları ve yapay zeka destekli veri doğrulama teknikleri uygulayın.
- Ölçeklenebilirlik: Sistem büyüdükçe sistem kaynaklarının ve alım süreçlerinin verimli yönetimi kritik önem taşır. Kullanıcı sorguları ve veri hacimleri arttıkça, daha fazla veri alımı için hem gerçek zamanlı hem de toplu işlemeyi yönetmek önemli bir zorluk haline gelir.
- İpucu: Artan veri yüklerini verimli bir şekilde yönetmek için ölçeklenebilir bulut tabanlı altyapı ve dağıtılmış hesaplama çerçeveleri kullanın. Gerçek zamanlı sorgu işleme için dinamik yük dengeleme ekleyin.
- Açıklanabilirlik: Karar verme sürecinde şeffaflığın sağlanması güven oluşturur. Özellikle metinsel ve görsel verilerden yararlanırken, kullanıcı sorgularına verilen yanıtların nasıl oluşturulduğuna dair net içgörüler sağlamak süregelen bir zorluk olmaya devam etmektedir.
- İpucu: Model tahminlerini yorumlanabilir kılmak için SHAP veya LIME gibi yapay zeka açıklanabilirlik araçlarından yararlanın ve yanıtların arkasındaki mantığı netleştirmek için görselleştirme panoları entegre edin.
- Gizlilik ve güvenlik: Güçlü veri koruması ve güvenli iletişim protokolleri esastır. Hassas veya gizli verileri yönetmek, depolama, daha fazla veri alımı ve işleme sırasında sağlam şifreleme ve uyumluluk mekanizmaları gerektirir.
- İpucu: Uçtan uca şifreleme ve erişim yönetimi çözümleri kullanın ve GDPR veya CCPA gibi veri koruma düzenlemelerine uyum sağlayın. Daha fazla veri alımı için güvenli API ağ geçitleri kullanın.
- Etik kaygılar: Önyargı, adalet ve kötüye kullanımın ele alınması, sorumlu yapay zeka dağıtımı için çok önemlidir. Çeşitli kullanıcı sorgularına karşı tarafsız yanıtlar sağlamak, etik yapay zeka tasarımında önemli bir husus olmaya devam etmektedir.
- İpucu: sorumlu yapay zeka platformları ve yapay zeka yönetişim araçları dağıtarak yapay zeka önyargısıyla başa çıkın ve yapay zekanın dört yol gösterici ilkesine uyun.
Gelecek beklentileri
Agentic RAG üzerine en son araştırmalar aşağıdaki gibi iyileştirme alanlarını içermektedir:
- Bilgi grafiği entegrasyonu: Karmaşık veri ilişkilerinden yararlanarak akıl yürütmeyi geliştirir.
- Gelişmekte olan teknolojiler: Sistem yeteneklerini ilerletmek için ontolojiler ve anlamsal web gibi araçları dahil etme.
- Uzmanlaşmış ajan iş birliği: Farklı alanlarda (ör. satış, pazarlama, finans) uzmanlığa sahip ajanlar, karmaşık görevleri ele almak için koordineli bir iş akışında birlikte çalışır.
- Kalite optimizasyonu: Çok ajanlı sistemlerin güvenilirliğini ve hassasiyetini artırmak için tutarsız çıktıların ele alınması.
Daha fazla okuma
Aşağıdakiler gibi diğer RAG kıyaslamalarını keşfedin:
- RAG için En İyi 10 Çok Dilli Gömme Modeli
- Gömme Modelleri: OpenAI vs Gemini vs Cohere
- RAG için En İyi 16 Açık Kaynak Gömme Modeli
- RAG için En İyi Vektör Veritabanı: Qdrant vs Weaviate vs Pinecone
- Yeniden Sıralayıcı Kıyaslaması: En İyi 8 Model Karşılaştırması
- Çok Modlu Gömme Modelleri: Apple vs Meta vs OpenAI
SSS'ler
Alım Destekli Üretim (RAG), bilgi alımını ve yanıt üretimini geliştirmek için alım tabanlı yöntemleri üretken modellerle birleştiren bir tekniktir.
Alım-destekli üretim tekniği ve yaygın modeller hakkında daha fazlasını keşfedin.
Bir ajan, belirli hedeflere doğrudan insan müdahalesi olmadan ulaşmak için çevresini gözlemlemek, kararlar almak ve eylemleri otonom olarak yürütmek üzere tasarlanmış bir bilgisayar programıdır.
Yapay Zeka Sistemlerinde Kullanımı
Ajanlar, görevleri otomatikleştirmek, süreçleri optimize etmek ve dinamik ortamlarda akıllı kararlar almak için kullanılır. Karmaşıklıklarına bağlı olarak, ajanlar basit kural tabanlı sistemlerden öğrenme tekniklerini kullanan gelişmiş modellere kadar çeşitlilik gösterebilir.
Ajan Türleri
Tepkisel Ajanlar: Geçmiş deneyimleri kullanmadan, ortamın mevcut durumuna göre çalışır ve önceden tanımlanmış kuralları izler.
Bilişsel Ajanlar: Geçmiş deneyimleri saklar ve bunları kalıpları analiz etmek ve kararlar almak için kullanır, böylece önceki etkileşimlerden öğrenmeyi sağlar.
İşbirlikçi Ajanlar: Ortak hedeflere ulaşmak için diğer ajanlar veya sistemlerle etkileşime girer; genellikle koordinasyon ve bilgi paylaşımının kilit olduğu çok ajanlı sistemler içinde yer alır.
Agentic RAG, daha dinamik, bağlam duyarlı karar verme ve yinelemeli etkileşimler gerektiren görevler için daha iyi olabilir, ancak etkinliği spesifik kullanım durumuna ve uygulama ihtiyaçlarına bağlıdır.
Vanilya RAG, statik bir sorgu-cevap modeline dayalı olarak pasif bir şekilde alım yapar ve cevaplar üretirken, agentic RAG yanıtları iyileştirmek veya karmaşık görevleri ele almak için yinelemeli süreçler, karar verme ve dinamik etkileşimler içerir.
Bu benchmarkı kaynak gösterin
Yayınlayacağınız yere uygun formatı seçin. Bağlantılı sürümü CMS'inize yapıştırmak, geri bağlantıyı korur.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sarı, Ekrem},
title = {{En İyi 20+ Agentic RAG Çerçevesi}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/agentic-rag}},
note = {AIMultiple. Erişim tarihi: 17 Temmuz 2026}
}




Yorum yapan ilk kişi olun
E-posta adresiniz yayınlanmayacak. Tüm alanlar gereklidir. Yorumlar orijinal dilinde bırakılır.