En İyi 5 Açık Kaynaklı Ajansal Yapay Zeka Çerçevesi
4 popüler açık kaynaklı ajansal çerçeveyi 2,000 çalıştırma (5 görev, çerçeve başına 100 çalıştırma) boyunca kıyasladık; uçtan uca gecikme süresi, token tüketimi ve mimari farklılıkları ölçtük.
Ajansal yapay zeka çerçeveleri kıyaslaması
Çerçevelerin kendilerinin ajan davranışını nasıl etkilediğini ve bunun gecikme süresi ile token tüketimi üzerindeki sonuç etkisini inceledik.
LangGraph, tüm görevlerde en düşük gecikme değerlerine sahip en hızlı çerçevedir; LangChain ise en yüksek gecikme süresi ve token kullanımına sahiptir.
5 görev ve 2,000 çalıştırma boyunca, LangChain en token verimli çerçeve olarak öne çıkarken, AutoGen gecikme süresinde liderdir; LangGraph ve LangChain hemen arkadan takip eder. CrewAI ise en ağır genel profil oluşturur.
Görev 1: Temel toplama
İlk olarak, karmaşık bir akıl yürütme gerçekleştirmeden, tek bir araç çağırıp sonucu döndürürken her çerçevenin ek yükünü ölçtük.
LangChain & LangGraph: Basit görevler için, ajansal olmayan kod kadar hızlı performans gösterirler; her ikisi de 900'den az prompt token ile 5 saniyenin altında tamamlar. LangGraph'ın durum makinesi mimarisi, bu basitlik düzeyinde LangChain'e kıyasla kayda değer bir gecikme yaratmaz; durum yönetiminin ek yükü, görev karmaşıklığı arttıkça kendini gösterir.
AutoGen: Çoklu ajan konuşma döngüsünün taban maliyetini yansıtarak, hem gecikme süresi hem de token kullanımında LangChain ve LangGraph'ın biraz üzerinde yer alır; tek adımlı bir görev için bile iki ajan mesaj alışverişi yapar.
CrewAI: Tek bir araç çağrısı yapması istendiğinde bile, "yönetimsel ek yük" olarak adlandırılabilecek bir davranış sergiler; LangChain'in neredeyse 3 katı token tüketir ve neredeyse 3 kat daha uzun sürer. Planlayıcı ve Analist kişilikleri arasındaki çok adımlı doğrulama süreci, hızdan çok eksiksizliğe öncelik veren kapsamlı ancak kaynak yoğun bir yaklaşım sunar. Bu maliyet yapısaldır: görev karmaşıklığından bağımsız olarak ortaya çıkar.
Görev 2: Karşılaştırmalı gelir analizi (durum yönetimi)
Görev 2'de, çerçevelerin iki farklı filtre grubunu bellekte tutma (Durum Kalıcılığı) ve bunları birleştirme becerisini görmek istedik.
CrewAI
Günlük analizimizde, CrewAI'nin çerçeveler arasında en yüksek düzeyde altyapı şeffaflığı sağladığını, ancak bunun en yüksek kaynak tüketimi pahasına olduğunu gördük.
CrewAI, alınan verileri hemen döndürmek yerine, kendi kendini gözden geçirme mekanizması aracılığıyla kendi süreçlerini tekrar doğrular. Bu keşifsel davranış, yapılandırılmış max_iter=10 sınırına ulaşmasına neden oldu ve bazı çalıştırmaları JSON çıktısı üretmeden sürekli bir düşünme döngüsünde takılı bıraktı.
Bu davranışın temel nedeni, CrewAI'nin sistem prompt'una çok katmanlı talimatlar enjekte ederek her ajana bir rol, hedef ve geçmiş hikayesi ataması ve her adımda ReAct tarzı Düşünce → Eylem → Gözlem döngüsünü zorunlu kılmasıdır. Basit görevler için bile, LLM bu seremoni atlayamaz ve itaatkar bir şekilde ayrıntılı iç monologlar üretir; bu da çoklu ajan senaryolarında daha da bileşik hale gelir.
CrewAI, diğer çerçevelerin neredeyse iki katı token tüketti ve LangChain'den üç kat daha uzun sürdü; bu da onu basit veri alma görevlerinden ziyade karmaşık durum geçişleri ve çok faktörlü karar verme için daha uygun hale getirir.
LangChain
En hızlı ve en maliyet etkin çerçeve. Günlüklerimizde, LangChain'in görevi hiçbir sapma olmadan 5-6 adımda tamamladığını gözlemledik: Yükle → Filtrele → Hesapla → Filtrele → Hesapla → Çıktı. Durum yönetimi çok basit olduğundan, ek yük neredeyse sıfırdır ve gecikme süresi tüm çerçeveler arasında en düşüktür.
AutoGen
Çok dengeli bir performans sergiledi. Görev 2'de, hem token kullanımı hem de gecikme süresinde LangGraph ile neredeyse tam olarak eşleşti; bu da görev zinciri doğrusal kaldığında konuşma döngüsünün ek yükünün önemli ölçüde bileşik hale gelmediğini gösterir.
Ancak, araç çağırma süreci sırasında parametreleri doğrulamak için zaman ekstra bir doğrulama adımı ekler; bu da onu LangChain'den biraz daha yavaş hale getirir. Bir araç çağrısında hata ile karşılaştığında veya veriler beklendiği gibi gelmediğinde, bir sonraki adımda akıl yürütmesini hemen günceller ve doğru JSON'a ulaşır. Araç çıktılarını bir konuşma akışı olarak yönettiği için, mantıksal hatalara karşı en dayanıklı çerçevelerden biridir.
LangGraph
Bu görevde LangGraph, grafik tabanlı mimarisi sayesinde en kararlı çerçevedir. Günlüklerinde, durumun çalıştırma boyunca çok temiz bir şekilde taşındığını gözlemledik. Veri kirliliği veya segmentlerin birbirine müdahale etme riski, bu çerçevede en düşük seviyededir. Tüm 100 çalıştırmada, neredeyse aynı sayıda adımda ve aynı gecikme aralığında sonuçlar üretti.
Görev 3: Eşik ayrıştırma (sayısal disiplin)
Bu görevde, çerçevelerin "1 yıldan az kıdem" ve "aylık ücretlerde 70$'dan fazla" gibi doğal dildeki sayısal koşulları, tenure_max=12 ve charges_min=70.0 gibi kesin araç parametrelerine ne kadar doğru çevirdiğini görmek istedik.
LLM bu dönüşümü nasıl yapacağını bilir; gerçekten test etmek istediğimiz şey, çerçevenin kendi yeniden deneme mekanizmaları, yeniden prompt bağlamı ve durum yönetimi döngüleri boyunca bu parametreleri koruyup koruyamayacağıydı.
LangChain & LangGraph
Her iki çerçeve de parametreleri (tenure_max=12, charges_min=70), LLM'in ürettiği şekilde, hiçbir değişiklik veya yeniden prompt döngüsü olmadan doğrudan araca iletti. Bu verimlilik sayılarda kendini gösterir: her iki çerçeve de Görev 3'ü 1,800'den az prompt token ile 9 saniyenin altında tamamladı; bu görevdeki en düşük değerler.
Sayısal eşiklerin çerçeve müdahalesi olmadan korunup korunmadığını ölçmek istediğimizde, bu ikisi beklentilerimizi karşıladı: hangi parametre üretildiyse, o çalıştırıldı.
AutoGen
AutoGen sayısal doğrulukta tamamen başarılıdır. Bazı çalıştırmalarda, çerçevenin LLM tarafından üretilen parametreyi araca iletmeden önce bir doğrulama adımı eklediği gözlemlendi; bu da çerçevenin parametreyi korurken fazladan bir adım harcadığı anlamına gelir. 2,480 token ve 8 saniyede, ekstra adıma rağmen LangChain'in gecikme süresiyle eşleşti; bu da doğrulama ek yükünün gerçek ancak küçük olduğunu doğrular. Parametre bütünlüğü açısından beklentilerimizi karşıladı; doğrulama adımı anlamlı bir gecikme cezası yerine marjinal bir token maliyeti getirdi.
CrewAI
En dikkat çekici davranış, Görev 3'ü bu görevdeki en yüksek değerler olan 30 saniye ve 4,360 token ile tamamlayan CrewAI'de gözlemlendi. Günlük analizinden iki farklı başarısızlık örüntüsü ortaya çıktı.
Bazı çalıştırmalarda, %68,81 olması gereken bir değer 0.6878 (ondalık oran) olarak döndürüldü. Bu, çerçevenin çıktı serileştirmesinin LLM'in çıktısını orijinal bağlamından koparabileceğini gösterir.
Günlükler, LLM'in başlangıçta doğru parametreleri, yani tenure_max=12 ve charges_min=70'i ürettiğini gösteriyor. Ancak CrewAI bir "Ayrıştırılamadı" döngüsüne girdiğinde, çerçeve LLM'i yeniden değerlendirmeye zorladı. Yeniden prompt bağlamında, LLM eşiği tenure_max=14 olarak değiştirdi ve charges_min filtresini tamamen devre dışı bırakarak %46,84'lük bir kayıp oranı üretti; bu aslında kıdemi 14'ten az olan tüm müşterilerin kayıp oranıdır. Bu tam olarak gözlemlemek istediğimiz senaryoydu: çerçevenin yeniden deneme mekanizması, LLM'in doğru yaptığı bir parametreyi bozabilir.
Görev 4: Hata dayanıklılığı ve pivot kapasitesi
Bu görevde, her çerçevenin bozucu senaryoları nasıl ele aldığını görmek ve gecikme süresi ile token tüketimi üzerindeki etkisini gözlemlemek istedik. Araç, art arda 3 farklı hata türü (Ağ, Zaman Aşımı, Hız Limiti) fırlatarak ajanı köşeye sıkıştırır. İlk iki hata ajana yeniden denemesini söyler ve her ikisini de yeniden denedikten sonra, gelen Hız Limiti hatası ajana 10 saniye beklemesini söyler. Ajan bekleyip yeniden denediğinde, araç normal şekilde çalışmaya başlar.
LangGraph & AutoGen
Bu iki çerçeve, bu görevde araç başarısızlıklarıyla karşılaştıklarında özerk bir şekilde alternatif çözümler buldu.
Araç bir hız limiti uyarısı döndürdüğünde, bu ajanlar duraklayıp beklemek yerine, başarısız olan aracı tamamen terk etmeye ve alternatif bir yol bulmaya karar verdi. Yaklaşımları şuydu: "Bu araç çalışmadığına göre, her ödeme yöntemini tek filtreleyeceğim, her biri için kayıp oranını ayrı ayrı hesaplayacağım ve sonra sonuçları kendim birleştireceğim."
Yöntem: Görevi tek bir araç çağrısıyla gerçekleştirmek yerine, filtreleme için bir ve hesaplama için bir olmak üzere iki ayrı araç kullanarak, her PaymentMethod'ı (Electronic check, Mailed check, vb.) ayrı ayrı işleyerek parçalara ayırdılar.
Bu ajanlar, yol bağımlılığından ziyade hedef odaklı akıl yürütme ile çalışır. En kısa yol kullanılamıyorsa, saniyeler içinde alternatif bir yürütme planı oluşturabilirler.
LangGraph, Görev 4'te 15,010 prompt token'a ulaştı; bu, tüm kıyaslama boyunca tek görevdeki en yüksek token sayısıdır, çünkü durum makinesi her manuel araç çağrısının büyüyen geçmişini her adımda bağlama geri biriktirdi. AutoGen, ara sonuçların konuşma temelli işlenmesi nedeniyle biraz daha sınırlı olarak 10,750 token ile takip etti. Buna rağmen, her ikisi de yaklaşık 24-27 saniyede tamamladı; bu da ek token maliyetinin, pivotun kendisi hızlı olduğu için anlamlı bir gecikmeye dönüşmediğini doğrular.
CrewAI
Önceki görevlerde en yüksek token tüketimini göstermesine rağmen, CrewAI bu görevde en düşük token kullanımını) ancak en yüksek gecikme değerlerini sergiledi.
Neden en düşük token?
CrewAI, rakipleri gibi 10-15 adımlı manuel bir geçici çözümden geçmedi. Hatalarla karşılaştığında, tüm geçmişi ve karmaşık ara verileri her adımda tekrar LLM'e pompalamak yerine, daha odaklı, modüler bir akıl yürütme döngüsü oluşturdu. Gereksiz ayrıntıdan kaçınarak, bu görevdeki en maliyet etkin çerçeve haline geldi.
Neden yüksek gecikme?
CrewAI'nin yönetimsel yapısı, bir hata ile karşılaştığında duraklar ve planı yeniden değerlendirir. 10 saniyelik bekleme uyarısı aldığında, "strateji planlama" aşamasında daha fazla zaman harcadı. Ayrıca, filtreleme için başka bir araca pivot yapmak yerine, ısrarla ana aracın toparlanmasını beklemeyi veya kararlı araçla denemeyi seçti; bu da toplam süreyi uzattı.
LangChain
LangChain, bu görevde en önemli dönüşümünü geçirdi ve dayanıklılığın neden doğru yapılandırmaya bağlı olduğunu kanıtladı.
İlk çalıştırmamızda, LangChain her denemede ConnectionError ile çöktü.
LangChain'in varsayılan AgentExecutor'ı, bir araç içinden fırlatılan ham Python istisnalarını ölümcül hatalar olarak değerlendirir ve süreci sonlandırır. Rakiplerinin aksine, varsayılan olarak "hatalar gözlemdir" felsefesini uygulamaz. Ajan hatayı hiç görmediğinden, üzerinde akıl yürütme şansı yoktur.
Araç çağrısını langchain_agent.py içinde bir try-except bloğu ile sardık. Bu, hatayı ajanın işleyebileceği okunabilir bir mesaja dönüştürdü.
Düzeltme sonrası davranış: Düzeltmeyi uyguladıktan sonra, LangChain'in günlüklerinde LangGraph ile tamamen aynı akıl yürütmeyi sergilediğini gözlemledik. Araçtan 3 hata aldı, hemen strateji değiştirdi ve filtreleme için bir, hesaplama için bir olmak üzere iki ayrı araç kullanmaya pivot yaptı, her ödeme yöntemini ayrı ayrı işledi ve sonuçları birleştirdi.
LangChain aslında LangGraph kadar yetenekli ve uyarlanabilirdir, ancak çerçevenin hata işlemesi varsayılan olarak kapalı olduğu için bu yeteneği gösterme fırsatı bulamadı. Doğru şekilde yapılandırıldığında, aynı alternatif yol yaklaşımını kullanarak doğru sonuca ulaştı.
Bu farklılıklar neden oluştu? (çerçeve mimarisi analizi)
Ajan davranışı yalnızca LLM'e (GPT-5.2) bağlı olsaydı, tüm çerçeveler benzer şekilde davranmalıydı. Ancak, bu oranlardaki belirgin farklılıklar, çerçevelerin kendi iç döngü mekanizmalarına dayanmaktadır:
1. LangGraph & AutoGen (90% Pivot):
LangGraph bir Durum Makinesi mimarisinde çalışırken, AutoGen Konuşma tabanlı bir model üzerinde çalışır. Her iki sistemde de hatalar bir geri bildirim döngüsü olarak işlenir. LangGraph'da, hatayı alan durum bir sonraki düğüme geçer; AutoGen'de ise Proxy ajan, hatayı bir sohbet mesajı olarak asistana iletir. Bu sürekli dürtme mekanizması, ajanı çözüm aramaya devam etmeye zorlar. Ajan tekrar "Bir hata aldım, ne yapmalıyım?" sorusuyla karşılaştığı için, alternatif bir manuel yol izlemeye karar verme olasılığı 90%'a yükselir.
2. LangChain (65% Pivot / 35% Bekleme):
LangChain, sıralı bir AgentExecutor mimarisinde çalışır. Hata işleme yerinde olsa bile, yürütme döngüsü daha doğrusal bir yapıya sahiptir ve öncelikle bir Nihai Cevap üretmeye odaklanmıştır. Araç 3-4 adım boyunca hata fırlatırsa, LangChain bazen alternatif bir stratejiye pivot yapmak yerine, bir sonraki denemede aracın başarılı olmasını beklemeyi veya mevcut bağlamdan bir sonuç üretmeyi tercih eder. LangChain'in durum kilitlemesi LangGraph'ınkinden daha esnek olduğu için, bekleme/doğrudan çözüm oranı yaklaşık 35% civarındadır.
3. CrewAI (0% Pivot):
CrewAI, bir Yönetimsel Süreç mimarisinde çalışır. Ajanları Rol ve Görev tanımları içine sarılmıştır. Hatalar oluştuğunda, iç mimarisi tipik olarak Kendi Kendini Düzeltme veya Yeniden Deneme mantığını tetikler. Ancak, "tüm planı iptal edip 5 adımda manuel filtreleme yapalım" gibi radikal bir strateji değişikliği, CrewAI'nin yönetimsel plan yapısıyla çelişir. Planını tamamen terk etmektense, "bana verilen aracı düzeltmeli veya en yakın alternatifi kullanmalıyım" disipliniyle çalışır. Bu, hedef merkezli bir yaklaşımın aksine, temelde plan merkezli bir yaklaşımdır.
Görev 5: Yapılandırılmamış veri orkestrasyonu (yapılandırılmamış veri yönlendirme)
Görev 5'te, çerçevelerin bir CSV içindeki JSON ve uzun metin (LongText) sütunlarıyla karşılaştıklarında nasıl davrandıklarını gözlemledik. Ajanların önce bu sütunların veri türünü keşfetmesi, ardından sıralı veya paralel olarak doğru işleme araçlarını seçmesi gerekiyordu.
Gerçek dünyada, yapılandırılmamış veri yönetimi, bir ajanın standart tablo verisinin ötesine geçmesini ve JSON blob'ları, serbest metin paragrafları veya iç içe nesnelerle çalışmasını gerektirir.
Bir çerçevenin bu tür verileri doğru şekilde işlemesi için iki şeyi iyi yapması gerekir:
1- hangi aracın hangi veri türüne uyduğunu anlayan bir keşif zekası
2- birden fazla bağımsız araç çağrısını koordine eden bir orkestrasyon mekanizması.
Görev 5'i özellikle bu iki yeteneği ayrı ayrı ölçmek için tasarladık.
AutoGen
AutoGen bu görevde güçlü bir performans sergiledi; 8,170 prompt token ve 47 saniye medyan gecikme süresi ile Görev 5'teki en hızlı ve en token verimli sonuç.
Mimarisinin merkezindeki konuşma döngüsü, yani AssistantAgent ile UserProxyAgent arasındaki mesajlaşma, tipik olarak ayrıntıya yol açan bir yapı olarak görülür. Ancak Görev 5'te, bu yapı bir avantaja dönüştü.
Konuşma geçmişine bakarak, LLM Metadata ve SupportNotes sütunlarının birbirinden bağımsız olduğunu fark etti. Ardından, aynı anda 4 aracı listeleyen tek bir TOOL CALLS yanıtı gönderdi: inspect_column(Metadata), inspect_column(SupportNotes), parse_json_column(…) ve summarize_text_column(…) hepsi paralel olarak çalıştı. Bu, görevi en az token ve en az adımla 3 LLM turunda tamamlamasını sağladı.
Bu davranışın arkasındaki teknik neden açıktır: AutoGen'in araç yürütme motoru, LLM tarafından döndürülen tool_calls listesini atomik olarak çalıştırır ve sonuçları tek bir konuşma adımında toplar. Çerçevenin "konuşmayı yönet" felsefesi, doğal olarak aynı anda birden fazla paralel kanalın açılmasına izin verir ve token ile gecikme süresi rakamları bunu doğrudan doğrular.
LangGraph
LangGraph, 9,150 prompt token ve 70 saniye medyan ile tamamladı; token bakımından AutoGen'e yakın ancak süre bakımından daha yavaş. Durum Makinesi mimarisi, Görev 5'te hem en büyük gücünü hem de en dikkat çekici zayıflığını aynı anda sergiledi.
Her çalıştırmada, llm düğümü → tools düğümü → llm düğümü döngüsü, önceki tüm araç çıktılarını durumda biriktirir ve bunları LLM'e iletir. Bu yapı, ajanın hiçbir şeyi unutmamasını garanti eder; bu normalde önemli bir avantajdır.
Ancak Görev 5'te bu güç aleyhine çalıştı. LangGraph doğru araçları buluyor ve doğru segmenti oluşturuyordu. Ancak analiz tamamlandıktan sonra bile, biriken durumda belirsizlikler tespit etti, tamamlanmış adımları hala beklemede olarak yorumladı ve tekrar ek araç çağrıları tetikledi. Gerekli verileri almış ve doğru cevabı üretmek üzere olmasına rağmen, durum makinesinin "eksik adım" sinyali devreye girdi ve ajan gereksiz döngülere girdi. Sonuç olarak, çalıştırma başına araç çağrısı sayısı 6 ile 16 arasında değişti. Durumun "hiçbir şeyi unutmama" gücü, bazen tamamlanmış adımların tamamlanmamış olarak görünmesine neden oldu, ajanı gereksiz döngülere geri çekti ve benzer token sayısına rağmen gecikmeyi AutoGen'in 23 saniye üzerine çıkardı.
CrewAI
CrewAI'nin Görev 5 performansı, tüm kıyaslama boyunca en yüksek varyansı üretti. Bazı çalıştırmalarda, 5 araç çağrısı ile kusursuz bir sıra izledi, hiçbir sapma olmadan, bir betik gibi yürütüldü. Bu çalıştırmalarda, CrewAI'nin rol ve görev tanımlı yönetimsel yapısı tam olarak amaçlandığı gibi çalıştı: ajan rolünü net bir şekilde anladığında, öngörülebilir ve disiplinli davrandı.
Ancak diğer çalıştırmalarda (örn. çalıştırma 16: 35 araç çağrısı), tam bir kaos ortaya çıktı. Temel neden, CrewAI'nin her adımda ürettiği iç monologdu (Thought). Doğru filtre ile segmenti doğru şekilde oluşturduktan sonra, ajanın iç monoloğu ek filtrelerin de uygulanıp uygulanmaması gerektiğini sorgulamaya başladı. Sonucu gördükten sonra, mevcut segmentin geçerli mi yoksa öncekinin mi öncelikli olması gerektiğinden şüphe etti. Bu şüphe, verileri sıfırdan yeniden yüklemesine neden oldu. Sonra tekrar filtreledi, başka bir doğrulama döngüsüne girdi, tekrar şüphe etti ve bu sarmalı 8 kez tekrarladı.
CrewAI'de, her Düşünce bağımsız bir değerlendirme üretir ve bu değerlendirmeler zaman önceden doğrulanmış adımları geçersiz kılar. Yönetimsel Sürecin "sürekli doğrulama" refleksi, bazı çalıştırmalarda ajanı kendi doğru kararlarını yeniden sorgulamaya itti.
LangChain
LangChain'in AgentExecutor yapısı doğası gereği sıralıdır ve Görev 5, bu kısıtlamanın en görünür olduğu yerdir. 10,070 prompt token ve 86 saniye medyan ile, en yüksek token sayısına sahip olmamasına rağmen bu görevdeki en yavaş çerçeveydi.
Her adımda tek bir araç çağrısı yapar, sonucu alır, sonra devam eder; bu da 4 bağımsız aracın, 4 ayrı bekleme süresiyle 4 ayrı LLM turu gerektirmesi anlamına gelir. AutoGen'in 47 saniyelik medyanına karşılık LangChain'in 86 saniyesi, sıralıya karşı paralel yürütmenin maliyetinin doğrudan bir ölçümüdür.
Görev 5'te, LangChain'in araç sayısı 9 veya 15'te sabitlendi. Bu iki küme, iki tipik stratejiye işaret eder: bazı çalıştırmalarda inceleme adımını atlayıp doğrudan ayrıştırma ve özetlemeye geçti (9 araç), diğerlerinde ise işlemeden önce her sütunu inceledi (15 araç). LangChain'in doğrusal yürütücü kimliği burada netleşti: ne AutoGen'in paralel verimliliğini ne de CrewAI'nin monolog kaosunu sergiledi.
Yapılandırılmamış veri yönetimi ve çerçeve mimarisi
Bu görevin sonuçları, bir çerçevenin yapılandırılmamış verileri (JSON, LongText) ne kadar verimli yönetebileceğinin, iç döngü mekanizmasıyla doğrudan bağlantılı olduğunu ortaya koymaktadır:
Paralel araç çağrıları yapabilen çerçeveler (AutoGen), bağımsız veri sütunlarını tek bir adımda işleyebilir. Büyük JSON nesneleri ve çok sayıda metin sütunu içeren gerçek dünya senaryolarında, bu fark büyük bir maliyet ve hız avantajına dönüşür.
Durum güdümlü döngülere sahip çerçeveler (LangGraph), veri tutarlılığında üstündür ancak geçmişte biriken tamamlanmış adımları yeniden değerlendirme riski taşır.
Monolog tabanlı çerçeveler (CrewAI), verinin türünü ve anlamını derinlemesine anlama yeteneğine sahiptir, ancak bu derinlik bazen aşırı sorgulama ve döngüye dönüşür.
Doğrusal yürütme çerçeveleri (LangChain), yapılandırılmamış verinin farklı dallarını ayrı ayrı işler ve her iki dünyadan orta halli bir sonuç üretir.
Ajansal çerçevelerin GitHub yıldız büyümesi
Ajansal yapay zeka çerçevelerini karşılaştırın
Ajansal yapay zeka çerçeveleri birçok temel boyutta farklılık gösterir ve anlamlı karşılaştırmalar yapmak için bu farklılıkları anlamak esastır.
Çoklu ajan orkestrasyonu
Çoklu ajan orkestrasyonu, tek ajan yeteneklerini aşan karmaşık iş akışlarını ele almak için birden fazla uzmanlaşmış yapay zeka ajanını koordine eder. Tek bir monolitik ajan oluşturmak yerine, orkestrasyon işi farklı roller, araçlar ve uzmanlıklara sahip ajanlar arasında bölüştürür. Her çerçeve, ajan koordinasyonuna farklı yaklaşımlar sunar.
LangGraph
LangGraph nispeten iyi bilinen bir çerçevedir ve ajan sistemleri geliştirenler için önemli bir seçenek olarak öne çıkar.
Açık çoklu ajan koordinasyonu: Birden fazla ajanı, her biri kendi mantığı, belleği ve sistemdeki rolü ile bireysel düğümler veya gruplar olarak modelleyebilirsiniz.
API'ler ve araçlar arasında yapay zeka iş akışları oluşturur. Bu nedenle, RAG ve özel iş hatları için iyi bir uyumdur.
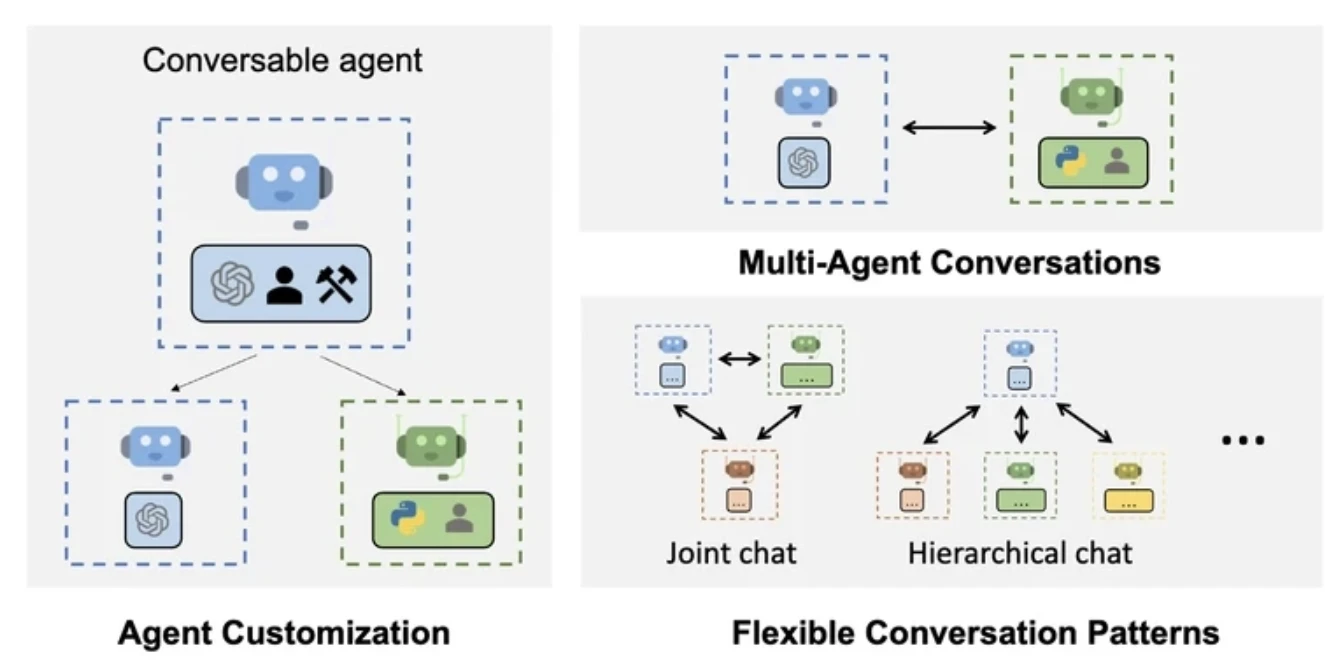
AutoGen
AutoGen, birden fazla ajanın bir döngü içinde mesajlar ileterek iletişim kurmasına izin verir. Her ajan, iç mantığına göre yanıt verebilir, yansıtabilir veya araçları çağırabilir.
Asenkron ajan iş birliğine sahiptir; bu da onu özellikle ajan davranışının deney veya yinelemeli iyileştirme gerektirdiği araştırma ve prototipleme senaryoları için kullanışlı kılar.
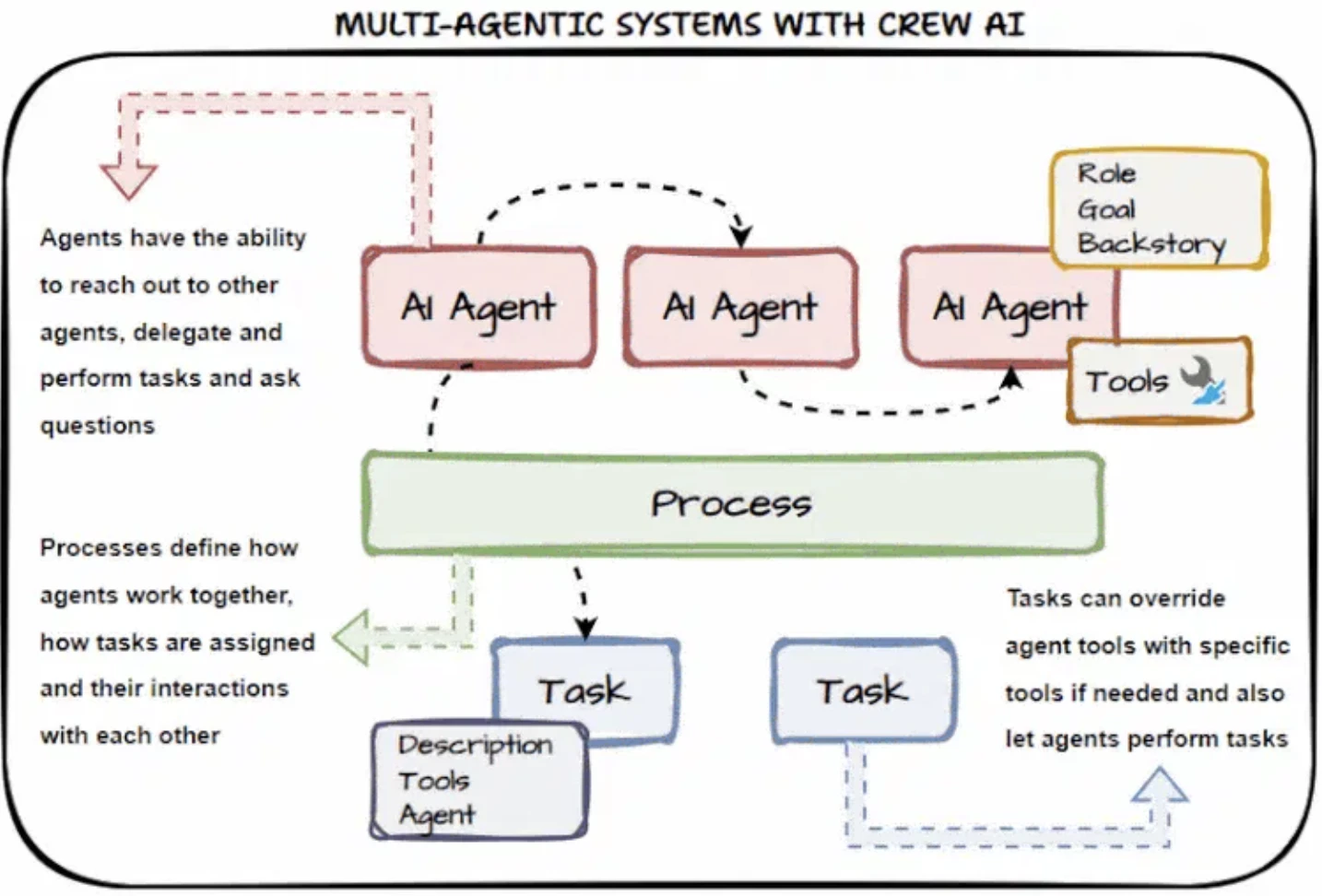
CrewAI
CrewAI, düşük seviyeli mantığın çoğunu sizin için halleder ve çoklu ajan orkestrasyonu sağlar:
- İzleme ve hata ayıklama için izleme araçlarıyla entegre olur
- Koşullu mantık, döngüler ve durum yönetimi ile Akışlar aracılığıyla yerleşik yürütme kontrolü
- Hiyerarşik (yönetici-çalışan) ve yapılandırılmış çoklu ajan koordinasyonunu destekler
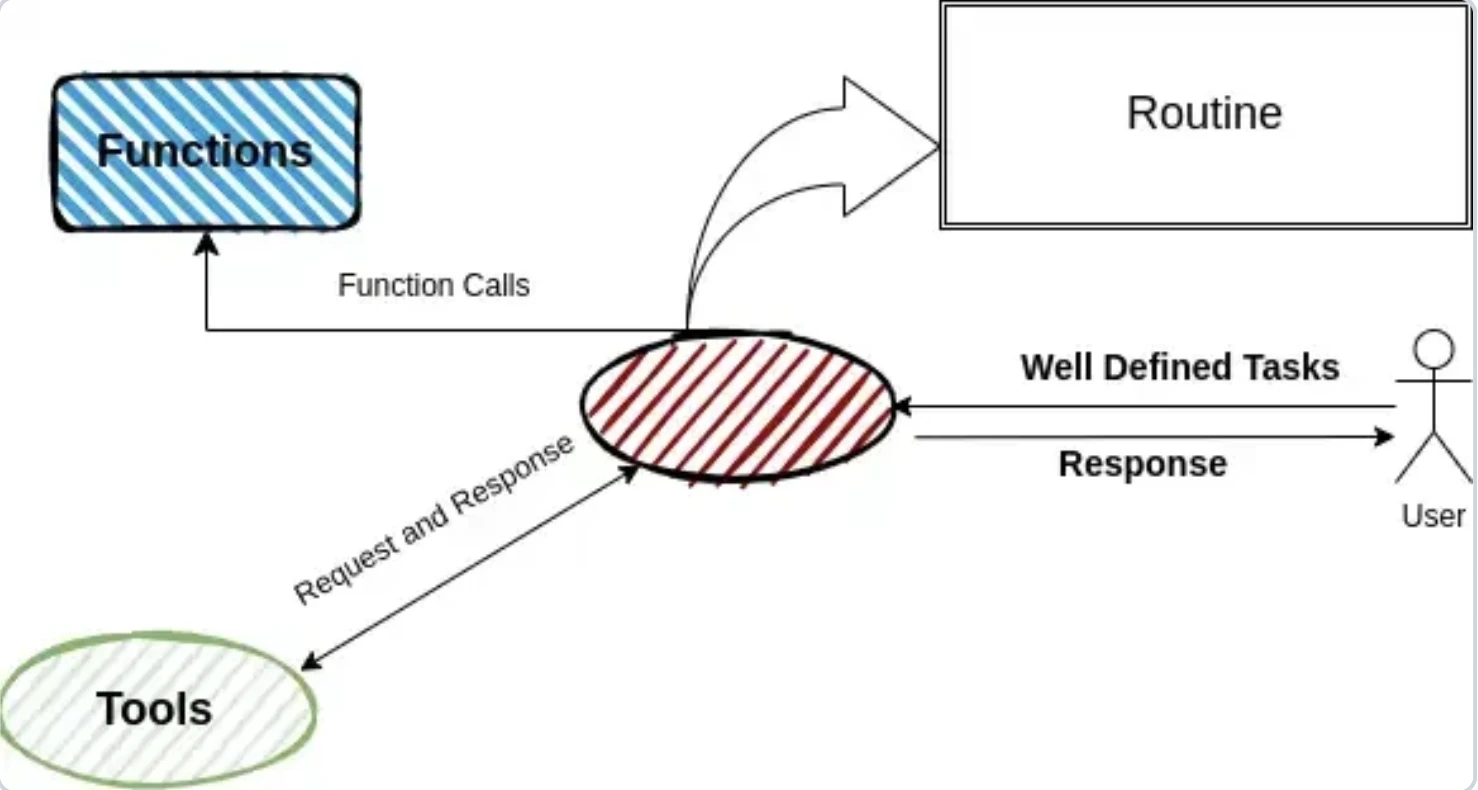
OpenAI Swarm
Swarm, prototipleme için hafif, deneysel bir çoklu ajan çerçevesidir. Ajanlar, paylaşılan bağlamı korurken görevleri aktararak devirler aracılığıyla sıralı olarak çalışır. Esnek iş akışları için doğal dil rutinleri ve Python araçları kullanır.
LangChain
LangChain, RAG araçları ile tek ajanlı LLM uygulamaları oluşturmak için bir çerçevedir. Belge işleme iş akışları için zincirler, araçlar, bellek ve erişim dahil olmak üzere modüler bileşenler sağlar.
LangChain, öncelikle bir ajanın iş akışını yönettiği tek ajanlı yürütme desenleri aracılığıyla çalışır.
Ajan ve fonksiyon tanımı
LangGraph
LangGraph, ajan tasarımına grafik tabanlı bir yaklaşım benimser; burada her ajan, kendi durumunu koruyan bir düğüm olarak temsil edilir. Bu düğümler, koşullu mantık, çoklu ekip koordinasyonu ve hiyerarşik kontrolü mümkün kılan yönlendirilmiş bir grafik aracılığıyla bağlanır. Bu, ölçeklenebilir orkestrasyon için denetleyici düğümleriyle çoklu ajan grafikleri oluşturmanıza ve görselleştirmenize olanak tanır.
LangGraph, araçları ajanlara bağlayan ek açıklamalı, yapılandırılmış fonksiyonlar kullanır. Düğümler oluşturabilir, bunları çeşitli denetleyicilere bağlayabilir ve farklı ekiplerin nasıl etkileşime girdiğini görselleştirebilirsiniz. Bunu, her ekip üyesine ayrıntılı bir iş tanımı vermek gibi düşünün. Bu, birlikte çalışan ajanları oluşturmayı ve test etmeyi kolaylaştırır.
AutoGen
AutoGen, ajanları esnek yönlendirme ve asenkron iletişim yeteneğine sahip uyarlanabilir birimler olarak tanımlar. Ajanlar, mesaj alışverişi yaparak birbirleriyle (ve isteğe bağlı olarak insanlarla) etkileşime girer; bu da iş birliğine dayalı problem çözmeye olanak tanır. LangGraph gibi ek açıklamalı, yapılandırılmış fonksiyonlar kullanır.
CrewAI
CrewAI, rol tabanlı tasarım yaklaşımını benimser. Her ajana bir rol (ör. Araştırmacı, Geliştirici) ve erişebileceği bir dizi beceri, fonksiyon veya araç atanır. Fonksiyon tanımı yapılandırılmış ek açıklamalar aracılığıyla yapılır.
OpenAI Swarm
OpenAI Swarm, ajanların prompt'lar ve fonksiyon docstring'leri aracılığıyla tanımlandığı rutin tabanlı bir model kullanır. Resmi orkestrasyon veya durum modellerine sahip değildir; bunun yerine manuel olarak yapılandırılmış iş akışlarına dayanır. Fonksiyon davranışı, LLM tarafından docstring'ler aracılığıyla çıkarılır (Swarm, bir fonksiyonun ne yaptığını açıklamasını okuyarak tanımlar); bu da kurulumu esnek ancak daha az kesin kılar.
LangChain
LangChain, tek bir orkestratör ajanın dil modellerine ve çeşitli araçlara yapılan çağrıları yönettiği zincir tabanlı bir mimari kullanır. Fonksiyonları, araç kitleri ve prompt şablonları gibi açık arayüzler aracılığıyla tanımlar.
Öncelikle merkezi iş akışlarına odaklanmış olsa da, LangChain çoklu ajan kurulumları için uzantıları destekler ancak yerleşik ajanlar arası iletişimden yoksundur.
Bellek
Bellek yetenekleri:
- Durumlu: Çerçevenin yürütmeler arasında kalıcı belleği destekleyip desteklemediği.
- Bağlamsal: Mesaj geçmişi veya bağlam iletimi yoluyla kısa vadeli belleği destekleyip desteklemediği.
Bellek özellikleri, bağlamı hatırlamak ve zamanla uyum sağlamak için ajansal sistemler oluşturmanın önemli bir parçasıdır:
- Kısa vadeli bellek: Yakın etkileşimleri takip eder, ajanların çok turlu konuşmaları veya adım adım iş akışlarını yönetmesini sağlar.
- Uzun vadeli bellek: Kullanıcı tercihleri veya görev geçmişi gibi oturumlar arasında kalıcı bilgileri depolar.
- Varlık belleği: Etkileşimler sırasında bahsedilen belirli nesneler, kişiler veya kavramlar hakkındaki bilgileri izler ve günceller (örn. daha önce bahsedilen bir şirket adını veya proje ID'sini hatırlama).
LangGraph
LangGraph iki tür bellek kullanır: tek bir görev veya konuşma sırasında bilgileri depolayan iş parçacığı içi bellek ve verileri oturumlar arasında kaydeden iş parçacıkları arası bellek. Geliştiriciler, bir görevin akışını kaydetmek ve belirli bir thread_id ile ilişkilendirmek için MemorySaver kullanabilir. Uzun vadeli depolama için LangGraph, InMemoryStore veya diğer veritabanları gibi araçları destekler. Bu, belleğin yürütmeler arasında nasıl kapsamlandığı ve korunduğu konusunda esnek kontrol sağlar.
AutoGen
AutoGen bir bağlamsal bellek modeli kullanır. Her ajan, etkileşim geçmişini depolayan bir context_variables nesnesi aracılığıyla kısa vadeli bağlamı korur. Yerleşik kalıcı belleğe sahip değildir.
CrewAI
CrewAI kutudan çıktığı haliyle katmanlı bellek sağlar. Kısa vadeli belleği bir ChromaDB vektör deposunda, son görev sonuçlarını SQLite'da ve uzun vadeli belleği ayrı bir SQLite tablosunda (görev açıklamalarına dayalı olarak) depolar. Ayrıca, vektör embedding'leri kullanarak varlık belleğini destekler. Bu bellek kurulumu, memory=True etkinleştirildiğinde otomatik olarak yapılandırılır,
OpenAI Swarm
Swarm durumsuzdur ve belleği yerel olarak yönetmez. Geliştiriciler, kısa vadeli belleği context_variables aracılığıyla manuel olarak iletebilir ve isteğe bağlı olarak daha uzun vadeli bağlamı depolamak için harici araçları veya üçüncü taraf bellek katmanlarını (örn. mem0) entegre edebilir.
LangChain
LangChain, esnek bileşenler aracılığıyla hem kısa vadeli hem de uzun vadeli belleği destekler. Kısa vadeli bellek, tipik olarak bir oturum içindeki konuşma geçmişini takip eden bellek içi tamponlar aracılığıyla yönetilir. Uzun vadeli bellek için, LangChain embedding'leri ve erişim verilerini kalıcı hale getirmek için harici vektör depoları veya veritabanlarıyla entegre olur.
Geliştiriciler, yerleşik bellek sınıflarını kullanarak bellek kapsamlarını ve stratejilerini özelleştirebilir; bu da etkileşimler arasında bağlamsal ve varlığa özgü belleğin verimli yönetimini sağlar.
Döngüde insan
LangGraph
LangGraph, grafiği duraklatmak ve yürütme ortasında kullanıcı girdisini beklemek için özel kesme noktalarını (interrupt_before) destekler.
AutoGen
AutoGen, UserProxyAgent aracılığıyla insan ajanları yerel olarak destekler; bu da insanların ajan iş birliği sırasında adımları incelemesine, onaylamasına veya değiştirmesine olanak tanır.
CrewAI:
CrewAI, human_input=True ayarlayarak her görevden sonra geri bildirim sağlar; ajan, kullanıcıdan doğal dil girdisi toplamak için duraklar.
OpenAI Swarm
OpenAI Swarm yerleşik HITL sunmaz.
LangChain
LangChain, yürütmeyi duraklatmak ve insan girdisi istemek için zincirler veya ajanlar içine özel kesme noktaları eklemeye izin verir. Bu, iş akışında tanımlanmış noktalarda inceleme, geri bildirim veya manuel müdahaleyi destekler.
Ajansal yapay zeka çerçevelerinde Model Bağlam Protokolü (MCP) entegrasyonu
Yapay zeka ajanlarının veritabanları, API'ler, dosya sistemleri ve iş uygulamaları gibi harici araçlarla etkileşime girmesi gerekir. Bir standart olmadan, her çerçeve her araç için özel entegrasyonlar oluşturmak zorundaydı; bu da parçalı bir ekosistem yarattı. MCP, herhangi bir ajanın tek bir arayüz aracılığıyla herhangi bir araca bağlanmasını sağlayan evrensel bir protokol sağlayarak bu sorunu çözer.
Her çerçeve MCP ile nasıl entegre olur
LangGraph
LangGraph, mevcut araçları otomatik olarak keşfeden ve bunları LangChain uyumlu formata dönüştüren bir adaptör aracılığıyla MCP sunucularına bağlanır. Ajanlar daha sonra bu araçları yerel yeteneklerinin yanı sıra sorunsuz bir şekilde kullanabilir.
AutoGen
AutoGen, uzantı modülü aracılığıyla yerleşik MCP entegrasyonu sağlar. Geliştiriciler, MCP sunucularına bağlanabilir ve sadece birkaç satır kod ile tüm araçlarını AutoGen ajanlarına sunabilir.
CrewAI
CrewAI ajanları, basit URL'ler veya yapılandırılmış ayarlar kullanarak yapılandırmalarında MCP sunucularına doğrudan referans verebilir. Çerçeve, bağlantı yaşam döngüsünü ve hata yönetimini otomatik olarak ele alır.
OpenAI Swarm
Swarm, OpenAI'in ekosistemi genelindeki yerel MCP desteğinden yararlanır. OpenAI, MCP'yi ChatGPT ve Agents SDK'sına entegre ettiğinden, Swarm bu altyapıdan doğrudan yararlanabilir.
LangChain
LangChain, Python fonksiyonlarının MCP sunucularına köprü görevi gördüğü MCP araç çağırma yetenekleri sunar. Bu, çeşitli kaynaklardan araçların çekilmesini ve özel sarmalayıcılar olmadan zincirlere, ajanlara ve diğer LangChain bileşenlerine entegre edilmesini sağlar.
Ajansal yapay zeka çerçeveleri aslında ne yapar?
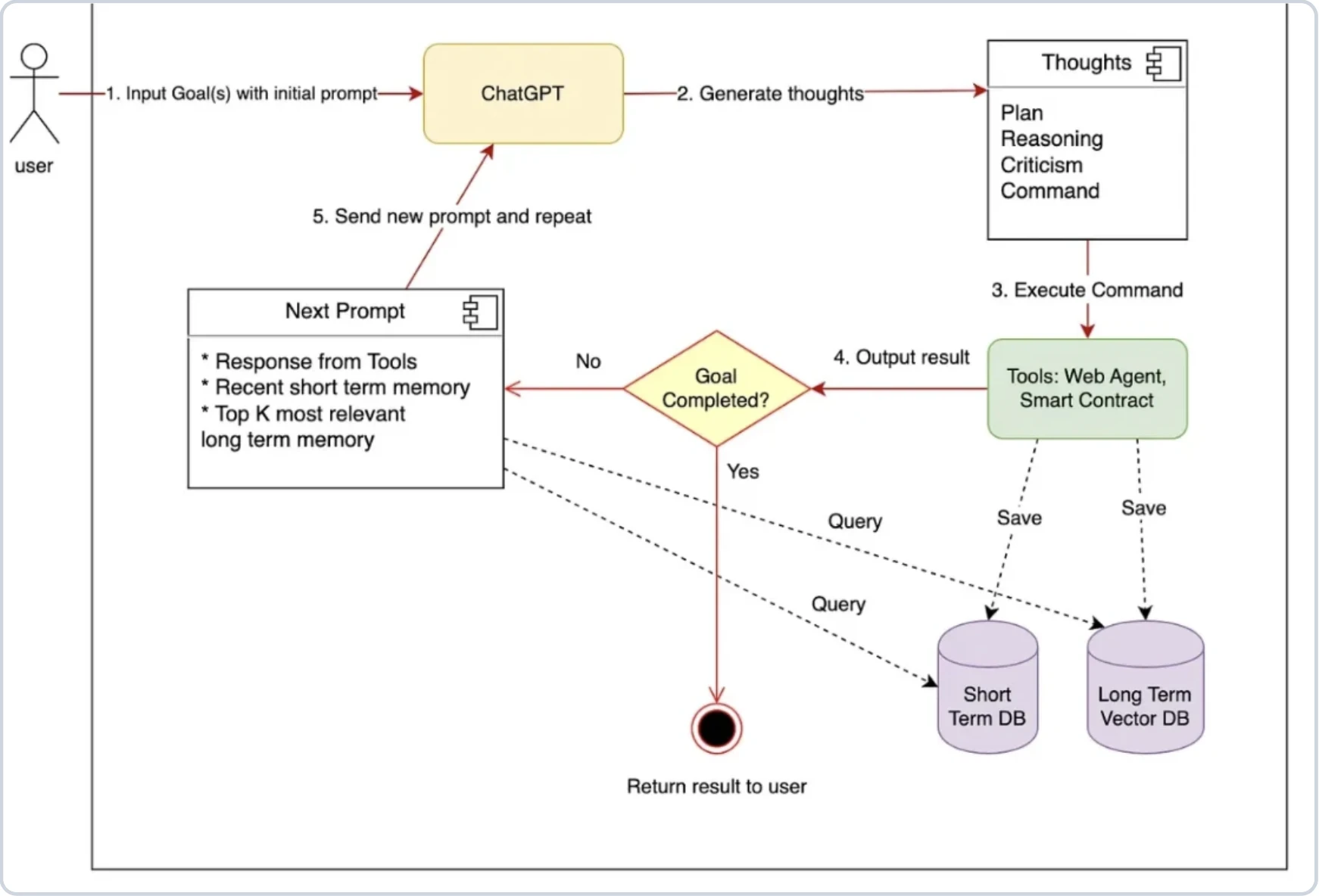
Ajansal yapay zeka çerçeveleri, prompt mühendisliğine ve verilerin LLM'lere nasıl aktığına ve geri döndüğüne yardımcı olur. Temel düzeyde, LLM'in öngörülebilir bir formatta yanıt vermesi ve yanıtları doğru araca, API'ye veya belgeye yönlendirmesi için prompt'ları yapılandırmaya yardımcı olurlar.
Sıfırdan oluşturuyor olsaydınız, prompt'u manuel olarak tanımlamanız, LLM'in kullanmak istediği aracı çıkarmanız ve ilgili API çağrısını tetiklemeniz gerekirdi. Çerçeveler bunu şu yollarla kolaylaştırır:
- Prompt orkestrasyonu: Karmaşık prompt'ları oluşturma, yönetme ve LLM'lere yönlendirme
- Araç entegrasyonu: Ajanların harici API'leri, veritabanlarını, kod fonksiyonlarını vb. çağırmasına izin verme
- Bellek: Turlar veya oturumlar arasında durumu koruma (kısa ve uzun vadeli)
- RAG entegrasyonu: Harici kaynaklardan bilgi alımını sağlama
- Çoklu ajan koordinasyonu: Ajanların nasıl iş birliği yapacağını veya görevleri nasıl devredeceğini yapılandırma
Ajansal yapay zeka çerçeveleri: Gerçek hayat kullanım örnekleri
LangGraph – Çoklu ajan seyahat planlayıcı
LangGraph ile oluşturulmuş bir üretim projesi, uçuş ve otel verilerini (Google Flights & Hotels API'lerini kullanarak) çeken ve seyahat önerileri oluşturan durumlu, çoklu ajan bir seyahat asistanı gösterir.4
CrewAI – Ajansal içerik oluşturucu
CrewAI'nin resmi örnekler deposu, role özgü ajanların (örn. "Araştırmacı", "Yazar") görevler üzerinde iş birliği yaptığı seyahat planlama, pazarlama stratejisi, hisse senedi analizi ve işe alım asistanları gibi akışları içerir.5
CrewAI, Groq kullanarak üst düzey bir içerik özetini eksiksiz bir makaleye dönüştürür.
Ajansal yapay zeka çerçevelerinin temel özellikleri
Model desteği:
- Çoğu model bağımsızdır ve birden fazla LLM sağlayıcısını destekler (örn. OpenAI, Anthropic, açık kaynaklı modeller).
- Ancak, sistem prompt yapıları çerçeveye göre değişir ve bazı modellerle diğerlerinden daha iyi performans gösterebilir.
- Sistem prompt'larına erişim ve özelleştirme, optimal sonuçlar için genellikle esastır.
Araçlama:
- Tüm çerçeveler, ajan eylemlerini etkinleştirmenin temel bir parçası olan araç kullanımını destekler.
- Özel araçları tanımlamak için basit soyutlamalar sunar.
- Çoğu, yerel olarak veya topluluk uzantıları aracılığıyla Model-Bağlam-Protokolü (MCP)'nü destekler.
Bellek / Durum:
- Adımlar veya LLM çağrıları arasında kısa vadeli belleği korumak için durum takibi kullanır.
- Bazıları, ajanların bir oturum içinde önceki etkileşimleri veya bağlamı tutmasına yardımcı olur.
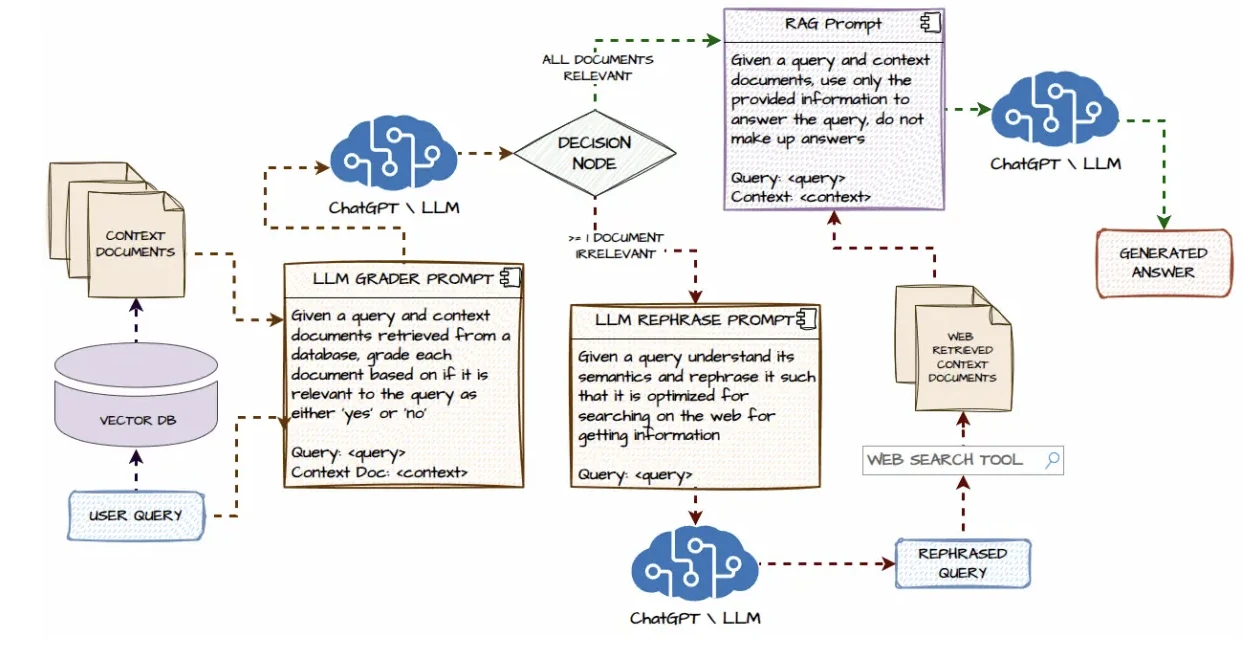
RAG (Erişim-Destekli Üretim):
- Çoğu, vektör veritabanlarını veya belge depolarını entegre eden RAG için kolay kurulum seçenekleri içerir.
- Bu, ajanların yürütme sırasında harici bilgiye başvurmasına olanak tanır.
Diğer ortak özellikler
- Asenkron yürütme desteği, eş zamanlı ajan veya araç çağrılarını mümkün kılar.
- Yapılandırılmış çıktılar için yerleşik işleme (örn. JSON).
- Modelin sonuçları kademeli olarak ürettiği akış çıktıları desteği.
- Ajan çalıştırmalarını izleme ve hata ayıklama için temel gözlemlenebilirlik özellikleri.
Kıyaslama metodolojisi
1. Görev Yapısı
Görev 1: Tek bir araç çağrısının doğru parametre ile yapılıp yapılamayacağını ölçer. Çerçevenin temel altyapı ek yükü en net şekilde bu basit senaryoda ortaya çıkar.
Görev 2: İki ayrı filtre grubunun sonuçlarını bellekte tutmayı ve bunları tek bir çıktıda birleştirmeyi gerektirir. Durum yönetimi ve çok segmentli koordinasyon test edilir.
Görev 3: Doğal dildeki sayısal koşulların bozulma olmadan araç parametrelerine çevrilip çevrilmediğini ölçer. Asıl test, çerçevenin yeniden deneme ve yeniden prompt mekanizmalarının bu parametreleri koruyup koruyamayacağıdır.
Görev 4: Bir araç art arda Network, Timeout ve RateLimit hataları fırlatır. Bu hatalar karşısında çerçevenin strateji değiştirip değiştirmediği ölçülür.
Görev 5: Ajan önce JSON ve LongText sütunlarını keşfetmeli, ardından doğru araçları doğru kapsam parametreleriyle çağırmalıdır. Çerçevenin bağımsız araçları paralel mi yoksa sıralı mı yürüttüğü gözlemlenir.
Bir görev aslında neye benzer
Kurulumu somutlaştırmak için, işte ajansal yapay zeka çerçeveleri kıyaslamasındaki en karmaşık görev olan Görev 5. Her çerçeve aynı prompt'u ve aynı araç setini aldı; yalnızca LLM'i sarmalayan çerçeve değişti.
Ajana verilen prompt:
MonthlyCharges'ta 100'den fazla ödeyen kaybedilmiş müşterileri (Churn='Yes') analiz et.
- Veri setini Churn='Yes' olarak filtrele.
- Veri türlerini keşfetmek için 'Metadata' ve 'SupportNotes' sütunlarını incele.
- JSON 'Metadata' sütunundan 'device_type' dağılımını çıkar.
- Serbest metin 'SupportNotes' sütunundaki şikayet anahtar kelimelerini say.
Sonucu yalnızca JSON olarak döndür.
Gerekli JSON çıktısı:
Bu görevin çerçeveler arasında neden ayrım yaptığı: ajan, dört araç çağrısı zincirini planlamalı, filtrelenmiş segmenti her çağrıda durumda tutmalı ve bir sütunun JSON iken diğerinin serbest metin olduğunu tanımalıdır. Bağımsız sütunları paralel olarak çalıştıran bir çerçeve (AutoGen), bunları sıralı olarak çalıştırandan (LangChain) çok daha hızlı tamamlar ve tamamlanmış adımları yeniden değerlendiren bir çerçeve (LangGraph, CrewAI) gereksiz yere döngüye girer. Katı JSON şeması, doğruluğu otomatik olarak puanlamamızı sağlar.
2. Yapılandırma
Tüm çerçeveler aynı LLM modelini (openai/gpt-5.2) ve aynı sıcaklık değerini (0.1) kullandı. Tüm görevler için, her ajana aynı araçlar ve aynı prompt'lar verildi. Her çerçeve kendi yerel yapısında kuruldu: AgentExecutor ile LangChain, StateGraph ile LangGraph, AssistantAgent + UserProxyAgent ile AutoGen ve Agent + Task + Crew ile CrewAI.
IBM Telco Müşteri Kaybı veri seti (7,032 müşteri) kullanıldı. Her çalıştırmadan önce araç durumu sıfırlandı. Her çerçeve ve görev kombinasyonu için 100 bağımsız çalıştırma gerçekleştirildi.
Maksimum yineleme sınırları görev karmaşıklığına göre belirlendi: Görev 1, 2 ve 3 için 10; güvenilmez araç döngüsü nedeniyle Görev 4 için 20; ve 4 adımlı keşif zinciri nedeniyle Görev 5 için 20.
Bu benchmarkı kaynak gösterin
Yayınlayacağınız yere uygun formatı seçin. Bağlantılı sürümü CMS'inize yapıştırmak, geri bağlantıyı korur.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Şipi, Nazlı},
title = {{En İyi 5 Açık Kaynaklı Ajansal Yapay Zeka Çerçevesi}},
year = {2026},
month = jul,
howpublished = {\url{https://aimultiple.com/agentic-frameworks}},
note = {AIMultiple. Erişim tarihi: 6 Temmuz 2026}
}
Yorumlar 1
Düşüncelerinizi Paylaşın
E-posta adresiniz yayınlanmayacak. Tüm alanlar gereklidir. Yorumlar orijinal dilinde bırakılır.
Thank you for this informative and detailed article! It helped me get a reading on these frameworks.