RAG Çerçeveleri: LangChain vs LangGraph vs LlamaIndex
Aynı agentic RAG iş akışını standartlaştırılmış bileşenlerle oluşturarak 5 RAG çerçevesini karşılaştırdık: LangChain, LangGraph, LlamaIndex, Haystack ve DSPy: özdeş modeller (GPT-4.1-mini), embedding'ler (BGE-small), alıcı (Qdrant) ve araçlar (Tavily web araması). Bu, her bir çerçevenin gerçek yükünü ve token verimliliğini yalıtır.
RAG çerçeveleri karşılaştırma sonuçları
Karşılaştırma 100 sorgudan oluşuyordu, her bir çerçeve kararlı ortalamalar sağlamak için tam seti 100 kez çalıştırdı.
- Ort. Token: Tüm LLM çağrılarında tüketilen toplam token (yönlendirici, belge değerlendirici, yanıt değerlendirici ve üretici), hem prompt'ları (alınan bağlamla birlikte) hem de tamamlamaları içerir. Daha düşük = daha az API maliyeti.
- Çerçeve Ek Yükü: Saf orkestrasyon süresi (ms), çerçevenin dahili işlemesi (yönlendirme mantığı, durum yönetimi vb.), LLM API ve araç çağrıları hariç. Daha düşük = daha yalın çerçeve.
Tüm uygulamalar test setinde %100 doğruluk elde etti. Aynı modeller, sıcaklık değerleri, alım sağlayıcısı, web arama aracı ve paylaşılan bir bağlam token sınırı kullanıldı.
Temel Bulgular
- Kontrol edilebilir olanı kontrol etmeye odaklanıyoruz: Aynı model ailesi ve sıcaklık değerleri, düğüm düzeyinde max_tokens, alıcı (Qdrant + BGE-small, k=5, normalizasyon açık), web sağlayıcısı (yalnızca Tavily), yönlendirici politikası (sezgisel + model), hesap makinesi erken dönüşü, paylaşılan bağlam token sınırı, özdeş değerlendirme rubriği, birleşik enstrümantasyon. Bu, ölçümlerimizdeki başlıca karıştırıcı faktörleri önemli ölçüde azaltır.
- Çerçeve ek yükü ölçülebilir ancak küçüktür: Orkestrasyon mantığından sorgu başına ~3–14 ms gözlemledik. Bu farklar gerçektir, ancak >1 s gecikme farklarının ana kaynağı değildir; zamanın çoğu harici modeller/araçlarla I/O'ya harcanır.
- Performans token'ları takip eder (bu kısıtlar altında): DSPy en düşük çerçeve ek yükünü gösterir (~3,53 ms). Haystack (~5,9 ms) ve LlamaIndex (~6 ms) onu takip ederken, LangChain (~10 ms) ve LangGraph (~14 ms) daha yüksektir. Token kullanımı en düşük Haystack (~1,57k), ardından LlamaIndex (~1,60k); DSPy ve LangGraph ~2,03k ve LangChain ~2,40k'tir.
- Yönlendirme/araç yolu önemlidir: İlk yönlendirmedeki (alıcı vs. web vs. hesap makinesi) küçük sapmalar ve yedek davranış, prompt'lar ve bütçeler hizalı olsa bile hem token'ları hem de süreyi etkiler.
Farklılıklar neden sürüyor? “Çerçeve DNA'sı”
Standardizasyona rağmen, token sayıları ve gecikmede küçük farklılıklar kalır. Bunlar, her çerçevenin doğal, düşük seviyeli davranışlarına, yani “DNA'sına” atfedilebilir.
- Prompt & mesaj serileştirme: Her çerçeve, aynı mantıksal içeriği LLM'ye göndermeden önce biraz farklı biçimlendirme ile sarar ve küçük ama tutarlı token farkları oluşturur.
- Bağlam birleştirme: Birleştirilmiş bağlam içindeki meta verilerin tam sıralaması ve dahil edilmesi çerçeveye göre biraz farklılık gösterebilir, bu da nihai token sayısını etkiler.
- Yönlendirme eşitlik bozma: Sınırda kalan durumlarda, bir çerçevenin yönlendiricinin JSON çıktısını ayrıştırma biçimindeki ince farklar farklı bir başlangıç aracı seçimine yol açabilir.
Bu kurulumda, token ayak izi, çerçeve yürütme süresinden daha çok birincil itici güç gibi görünmektedir.
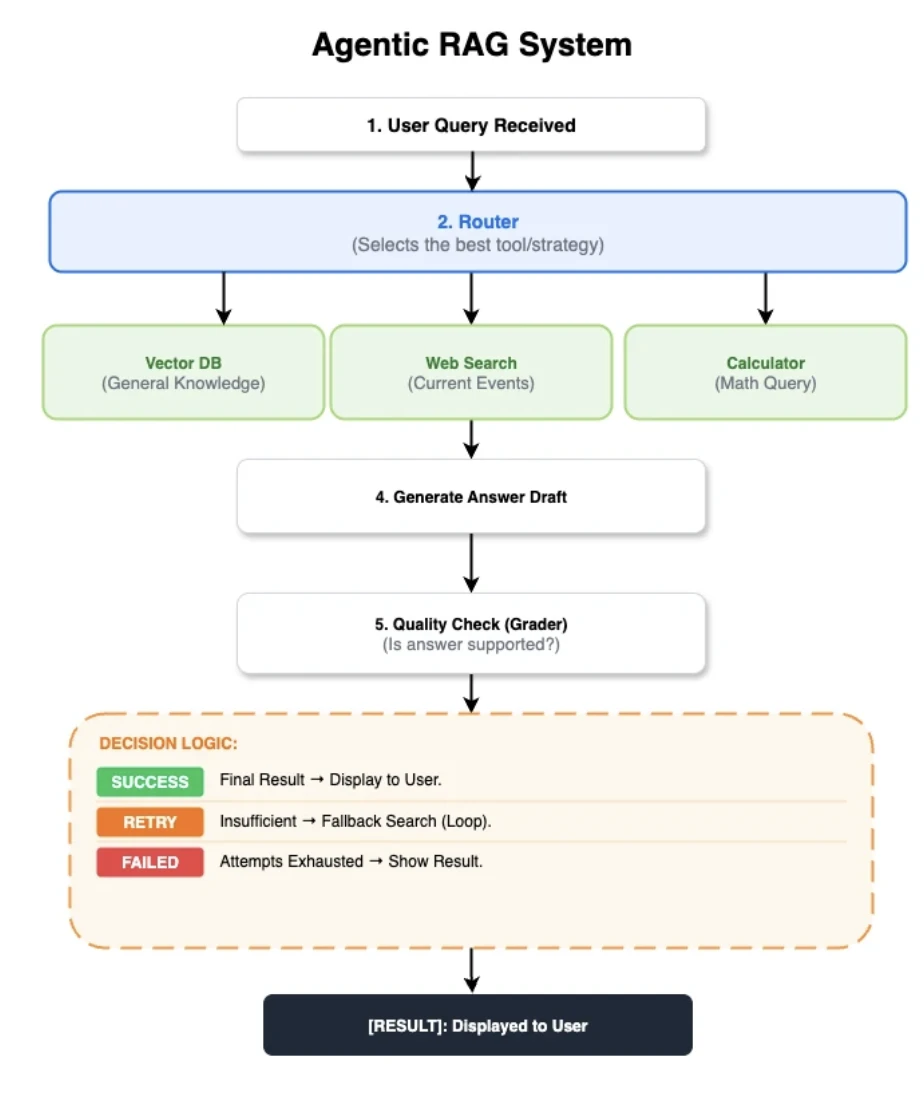
Ortak agentic RAG mimarisi
Adil bir karşılaştırma elde etmek için, beş uygulamanın tümü aynı kontrol akışı üzerine inşa edildi:
- Yönlendirici: Alıcı, web_search veya hesap makinesini seçen hibrit bir model-ve-sezgisel düğüm.
- Belgeleri Al: Normalleştirilmiş BGE-small embedding'leri kullanarak Qdrant'tan en iyi 5 belgeyi getirir.
- Belgeleri Değerlendir: Bir LLM hakemi belge alaka düzeyini değerlendirir. Alakasızsa, bir web araması yedeğini tetikler.
- Yanıt Üret: Paylaşılan bir bağlam token sınırı ile temperature=0.0 LLM kullanarak bir taslak yanıt üretir.
- Yanıtı Değerlendir: İkinci bir LLM hakemi, taslağı dayanaklılık, çelişkiler (halüsinasyonlar) ve bütünlük açısından değerlendirir.
- Yedek & Erken Dönüş: Yanıt notu yetersizse bir web araması tetiklenir. Ancak hesap makinesi sonuçları, üretim ve değerlendirme adımlarını atlayarak doğrudan döndürülür.
İş Akışı Örnekleri
Senaryo A — Veritabanından doğrudan isabet:
Senaryo B — Güncel olay web aracını tetikler:
Senaryo C — Hesap makinesi erken dönüş sağlar:
Senaryo D — Vektör VT yetersiz, web aramasına düşer:
RAG çerçeveleri metodolojisi
Beş uygulamanın tümü, 100 sorguluk test setimizde %100 doğruluk elde ederek temel gerçek yanıtlarıyla eşleşti. Bu, performans farklılıklarını ölçmeden önce her çerçevenin aynı agentic RAG iş akışını başarıyla yürütebilmesini sağlayan temel gereklilikti.
1. Temel bileşenler & yapılandırma
Performans değişkenlerini kaynağında ortadan kaldırmak için temel araçlar standartlaştırıldı.
- LLM'ler:
- Model: Tüm düğümler (yönlendirici, üretici, değerlendirici) OpenRouter API'si aracılığıyla openai/gpt-4.1-mini modelini kullandı.
- Determinizm: Yönlendirme, üretim ve değerlendirmede maksimum tutarlılığı sağlamak için tüm LLM çağrıları için temperature 0.0 olarak ayarlandı.
- Token limitleri: Katı max_tokens limitleri uygulandı: yönlendirici ve değerlendiriciler için 256, üretici için 512. Bu, bir çerçevenin aşırı uzun yanıtlar üretmesinden kaynaklanan gecikme farklılıklarını önler.
- Embedding modeli & alım:
- Model: Tüm çerçeveler HuggingFace'ten BAAI/bge-small-en-v1.5 kullandı.
- Normalizasyon: Performans için kritik bir adım olan normalize_embeddings, beş çerçevenin tümünde True olarak ayarlandı. (LangChain/LangGraph encode_kwargs aracılığıyla; LlamaIndex normalize=True aracılığıyla; Haystack normalize_embeddings aracılığıyla; DSPy alıcısı normalleştirildi.)
- Alım: Qdrant vektör deposu, tüm uygulamalarda k=5 (en iyi 5 belge) için sorgulandı.
- Araçlar:
- Web araması: Karşılaştırma yalnızca Tavily ile sınırlandırıldı (max_results=3).
- Hesap makinesi: Beş uygulamanın tümü, matematiksel ifade ayrıştırma ve değerlendirme için sympy kütüphanesini kullanarak özdeş yetenekler sağladı.
2. RAG kontrol akışı & politikası
Ajanın “karar verme” süreci tüm tahtada açıkça aynalandı.
- Yönlendirme mantığı: Model zekasını deterministik kurallarla dengelemek için beş betikte de hibrit bir yönlendirme stratejisi uygulandı:
- Regex tabanlı bir heuristic_route önce bariz hesap makinesi veya web arama desenlerini (örn. matematik sembolleri, “2024” gibi yıllar) kontrol eder.
- Bir LLM router_node daha sonra kendi kararını verir.
- Nihai karar, hesap makineleri için sezgiseli önceliklendirir, aksi takdirde LLM'nin seçimine bırakır.
- Bağlam bütçeleme: Bu en kritik standardizasyonlardan biridir. generate_answer düğümü çağrılmadan önce, alınan tüm belge bağlamı ve web arama sonuçları birleştirilir ve ardından ortak bir truncate_to_token_budget yardımcısı kullanılarak paylaşılan bir 2000-token sınırına kısaltılır. Bu, her çerçevedeki üretici LLM'nin tam olarak aynı boyutta bir girdi almasını sağlar ve herhangi bir çerçevenin alınan bağlamının ayrıntı düzeyiyle avantajlı veya dezavantajlı hale gelmesini önler.
- Yanıt değerlendirme politikası:
- Esnek rubrik: grade_answer düğümü, tüm çerçevelerde özdeş, esnek bir prompt kullanır ve LLM hakemine anlamsal olarak benzer ve makul ölçüde tam yanıtları kabul etmesini söyler.
- Başarısızlık yönetimi: Değerlendiriciden başarısız bir JSON ayrıştırmasını yönetme mantığı standartlaştırıldı. Değerlendiricinin çıktısı geçerli JSON değilse, sistem geçirgen bir nota (grounded=True, complete=True) varsayılan olarak döner; bu, kırılgan bir ayrıştırıcının aksi takdirde iyi bir yanıtı başarısız saymasını istemeyeceğiniz gerçek dünya senaryosunu taklit eder. DSPy yapılandırılmış alan dönüşleri (JSON ayrıştırma yok), bu bir performans avantajı olarak değil, sağlamlık farkı olarak günlüğe kaydedilir.
- Hesap makinesi erken dönüşü: Kodda görüldüğü gibi, calculator_node'a yapılan başarılı bir çağrı doğrudan final_answer'ı ayarlar ve iş akışını erken sonlandırır. Bu, hesap makinesi yolunun generate ve grade_answer LLM'lerini gereksiz yere çağırmasını önleyen, tutarlı bir şekilde uygulanan önemli bir optimizasyondur.
- DSPy uyumu. CoT olmayan temellerle adaleti korumak için DSPy, Yönlendirici ve YanıtÜretici için dspy.Predict (CoT yok) kullanır. İmzalar diğer çerçevelerin düğüm sözleşmelerini yansıtır; mevcut olduğunda, token sayımları model tarafından raporlanan kullanımı kullanır, aksi takdirde tiktoken yedeği kullanılır.
3. Enstrümantasyon ve metrikler
Ölçüm süreci, paylaşılan yardımcı programlar ve ilkeler kullanılarak özdeşti.
- Gecikme: Tüm zamanlamalar için yüksek hassasiyetli time.perf_counter() kullanıldı. Çerçeve Ek Yükü tutarlı bir şekilde Toplam Gecikme – Harici Çağrı Gecikmesi olarak hesaplanır.
- Tokenizasyon: Prompt'lar ve tamamlamalar için tüm token sayımları, tek bir doğruluk kaynağı sağlamak üzere tiktoken, cl100k_base kodlaması kullanılarak hesaplandı. Sonuçlarda raporlanan “Ort. Token” metriği, tek bir sorgu iş akışı içindeki her LLM çağrısı (örn. yönlendirici, değerlendiriciler, üretici) için tüm girdi (prompt) ve çıktı (tamamlama) token'larının kümülatif toplamını temsil eder.
- Durum yönetimi: Uygulama sözdizimi değişse de (LangGraph'ın TypedDict'i, LlamaIndex'in sınıfı, LangChain'in sözlüğü), durum yapısı işlevsel olarak özdeştir. Her çerçeve, düğümler arasında aynı anahtar setini (soru, belgeler, web_sonuçları, vb.) geçirerek kontrol akışı mantığının aynı bilgiler üzerinde çalışmasını sağlar.
Bu sıkı, kod seviyesinde standardizasyonları uygulayarak, bu karşılaştırma yüzeysel karşılaştırmaların ötesine geçmeyi ve sabit bir RAG politikası altında çerçeve performansının tekrarlanabilir bir analizini sunmayı amaçlar.
Sonuçları yorumlama:
- Şu sonuca varabilirsiniz: Bu spesifik, yüksek kontrollü kurulumda, orkestrasyon ek yükü küçük olma eğilimindedir; farklılıklar esas olarak token sayıları ve araç yolları tarafından yönlendirilir.
- Bu spesifik, yüksek kontrollü kurulumda, çerçeve ek yükü ihmal edilebilir düzeydedir.
- Performans farklılıkları token sayısı ve araç yolu varyasyonları tarafından yönlendirildi.
- Genelleme yapamazsınız: Sonuçlar bu mimariye, modellere, prompt'lara, alıcıya ve web sağlayıcısına özgüdür; bunları değiştirmek sıralamaları değiştirebilir.
Geliştirici deneyimi: Nitel bir karşılaştırma
Performans tek faktör değildir; bir çerçeveyle geliştirme yapmanın nasıl hissettirdiği de eşit derecede önemlidir.
- LangGraph: Bildirimsel graf
Graf-öncelikli bir paradigma kullanır. Düğümleri tanımlar ve onları kenarlarla bağlarsınız (add_conditional_edges dahil), böylece kontrol akışı mimarinin bir parçasıdır. Durum, azaltıcı tarzı güncellemelerle (Annotated[…, add]) bir TypedDict aracılığıyla yazılır.- LangGraph'ı şunlar için seçin: birden çok dallı, tekrarlamalı ve döngülü karmaşık iş akışları; yapısı, ajanlar büyüdükçe sağlamlık ve sürdürülebilirlik açısından ölçeklenir.
- LlamaIndex: Emir kipi orkestrasyon
Kontrol akışının standart Python if/else olduğu prosedürel bir betik; “graf” kodunuzda yaşar. Durum özel bir PipelineState sınıfıdır ve çerçeve temiz alım ilkelleri sağlar (VectorStoreIndex → .as_retriever(k=5)).- LlamaIndex'i şunlar için seçin: açık prosedürel mantığa ve kolay hata ayıklamaya değer verdiğiniz okunabilir, tek dosyalı iş akışları.
- LangChain: Bildirimsel bileşenlerle emir kipi
Orkestrasyon bir Python betiği olarak kalır, ancak bireysel görevler | operatörünü kullanan küçük, birleştirilebilir zincirlerdir (örn. prompt | llm | parser). Durum esnek, yazısız bir Python sözlüğüdür.- LangChain'i şunlar için seçin: Hızlı prototipleme veya halihazırda LangChain ekosisteminde olan ve daha büyük bir emir kipi sürücü içinde küçük bildirimsel birimler oluşturmayı tercih eden takımlar.
- Haystack: Bileşen tabanlı, manuel orkestrasyon Açık I/O'lu yazılı, yeniden kullanılabilir bileşenler (@component), kontrol akışı ise düz Python (if/else) olarak kalır. LLM/alıcı/web arka uçlarını değiştirmek kolaydır, ayrıca birinci sınıf adım başına enstrümantasyon (harici vs. çerçeve süresi).
- Haystack'i şunlar için seçin: net sözleşmelere ve ince taneli kontrole sahip üretime hazır, test edilebilir pipeline'lar.
- DSPy: İmza-öncelikli programlar (daha az kod satırı)
Bir görevi bir imza (girdiler/çıktılar + niyet) aracılığıyla tanımlayın, ardından prompt'lama ve LLM çağrılarını kapsülleyen Modüller ile uygulayın. Prompt/kullanım yönetimini merkezileştirir ve yapıştırıcı kodu kaldırır; dahili parçaları değiştirmek (örn. Predict ↔ CoT) sözleşmeyi değiştirmez.- DSPy'yi şunlar için seçin: minimal taslak kod, okunabilir tek dosyalı akışlar, sözleşme odaklı geliştirme (isteğe bağlı optimize edicilerle).
Karşılaştırılabilirlik için optimal performanstan ödün verme
- LangGraph, paralel yürütme, durum önbellekleme ve karmaşık dallanma mantığı için koşullu kenar sistemini kullanmasına izin verildiğinde doğal graf optimizasyonlarıyla öne çıkabilir.
- DSPy, yanıt kalitesini önemli ölçüde artırabilen imza optimize edicilerini (MIPROv2 gibi) ve Chain-of-Thought prompt'lamayı kullanırken çarpıcı biçimde farklı sonuçlar gösterebilir.
- Haystack, adillik için devre dışı bıraktığımız üretime hazır önbellekleme, yığın işleme özelliklerinden ve bileşen düzeyinde optimizasyonlardan yararlanabilir.
- LlamaIndex, bu karşılaştırmada kullanılmayan gelişmiş indeksleme stratejilerinden, sorgu motorlarından ve çok modlu yeteneklerden faydalanabilir.
- LangChain, standartlaştırılmış araç setimize kısıtlanmadığında kapsamlı araç ekosistemi ve LCEL (LangChain Expression Language) optimizasyonlarıyla parlayabilir.
“En iyi” çerçeve, şunlardan hangisini optimize ettiğinize bağlıdır: geliştirme hızı, sürdürülebilirlik, performans veya belirli mimari desenler.
Sonuç
Sıkı eşleştirilmiş bir agentic RAG pipeline'ında, orkestrasyon ek yükü genellikle küçük bir dilimdir. Önemli olan, kaç token işlediğiniz ve hangi araçları çağırdığınızdır; her ikisi de prompt'lar, alım ve yönlendirme tarafından şekillendirilir. “Doğru” çerçeve nihayetinde takımınızın tercih ettiği orkestrasyon stiline bağlıdır: bildirimsel graflar (LangGraph), emir kipi betikler (LlamaIndex), birleştirilebilir zincirler (LangChain), modüler bileşenler (Haystack) veya taslak kodu en aza indiren imza-öncelikli programlar (DSPy).
Daha fazla bilgi
Aşağıdakiler gibi diğer RAG karşılaştırmalarını keşfedin:
- Embedding Modelleri: OpenAI vs Gemini vs Cohere
- RAG için En İyi Vektör Veritabanı: Qdrant vs Weaviate vs Pinecone
- Agentic RAG karşılaştırması: çoklu veritabanı yönlendirme ve sorgu üretimi
- Hibrit RAG: RAG Doğruluğunu Artırma
Bu benchmarkı kaynak gösterin
Yayınlayacağınız yere uygun formatı seçin. Bağlantılı sürümü CMS'inize yapıştırmak, geri bağlantıyı korur.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Sarı, Ekrem},
title = {{RAG Çerçeveleri: LangChain vs LangGraph vs LlamaIndex}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/rag-frameworks}},
note = {AIMultiple. Erişim tarihi: 3 Haziran 2026}
}
Yorum yapan ilk kişi olun
E-posta adresiniz yayınlanmayacak. Tüm alanlar gereklidir. Yorumlar orijinal dilinde bırakılır.