En İyi 50+ Açık Kaynak Yapay Zeka Ajanı Listesi
Herkes yapay zeka ajanları inşa ediyor, bu yüzden popüler AI kodlama ajanları, AI ajan oluşturucuları ve araç kullanım kıyaslamaları ile ellerimle test ettikten sonra, onların gerçek dünya yeteneklerini değerlendirerek, en iyi 50+ açık kaynak yapay zeka ajanı listesini derledik. Doğrudan en iyi seçimlerimize atlamak için kategori başlıklarına tıklayın:
Ajan geliştirme ve altyapı
Alana özgü ajan uygulamaları
- Web otomasyonu ve gezinme ajanları
- Kodlama ve geliştirme araçları
- Siber güvenlik araçları
- AI video içerik oluşturucuları
- Finans asistanları
- Sağlık asistanları
- Araştırma ajanları
- Veri analizi asistanları
- Kişisel asistanlar
Yapay zeka ajanları hakkında nasıl düşünmeli?
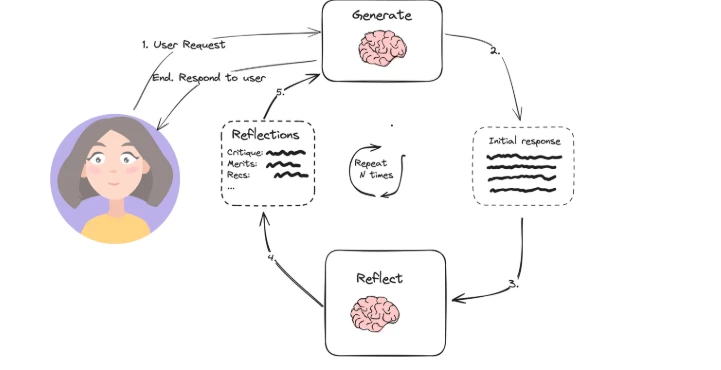
Bir AI ajanı, planlama, hafıza, araç kullanımı ve yinelemeli yürütmeyi birleştiren birleştirilebilir bir sistemdir. Kararlar alabilen, eylemler gerçekleştirebilen ve yeni bilgilere uyum sağlayabilen bir LLM etrafında yapılandırılmış bir döngü oluşturur.
İşte onlar hakkında nasıl düşüneceğiniz:
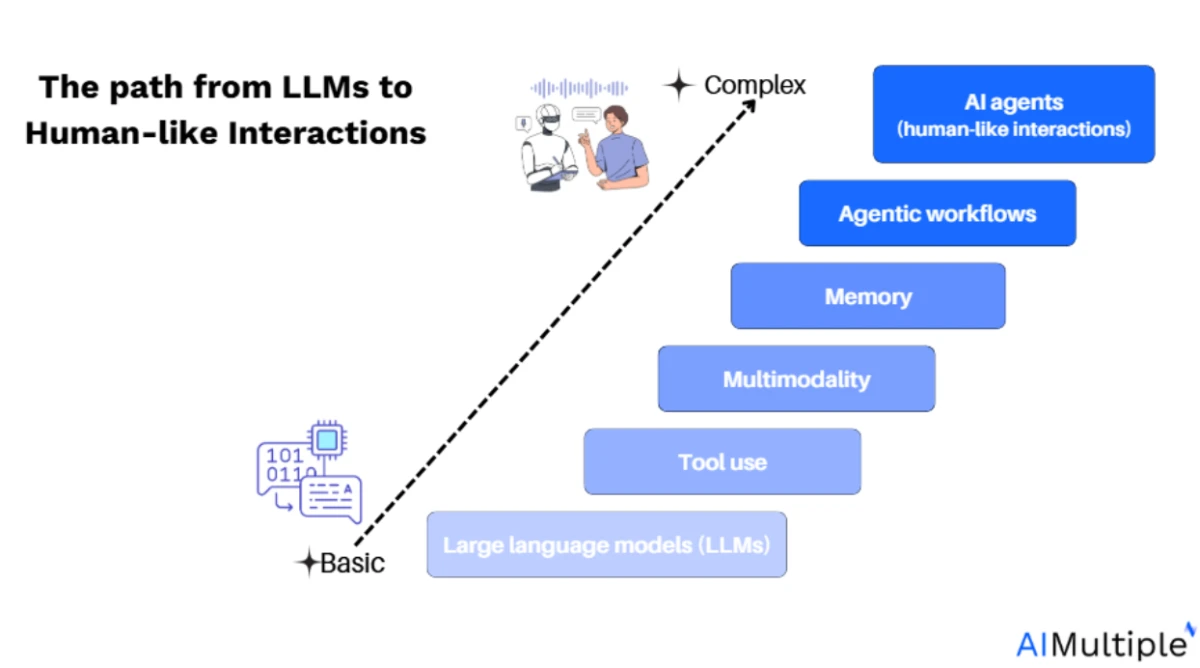
- Özerklik ve iş akışları: Yapay zeka ajanları, önceden tanımlanmış iş akışlarına dayalı temel görev otomasyonundan, hedef ayrıştırma, bellek kullanımı ve araç etkileşimi yapabilen tamamen özerk sistemlere kadar uzanır. Temel teknik zorluk, adımlar arasında bağlamı korumak ve çok aşamalı operasyonları koordine etmektir.
- Bağlam ve kontrol: Yapay zeka ajanlarındaki asıl zorluk, LLM'in her adımda uygun bağlama sahip olmasını sağlamaktır. Bu, LLM'e beslenen içeriği yönetmeyi ve ajanın güncel bağlama dayalı olarak ilgili görevleri yürütmesini sağlamayı içerir.
- Araçların entegrasyonu: Etkili ajanlar oluşturmak, harici araçlarla, API'lerle ve veri kaynaklarıyla sorunsuz entegrasyon gerektirir. LangChain gibi çerçeveler bu harici kaynakları entegre etmeye yardımcı olabilir, ancak ajanın davranışını yeni girdilere uyarlamak için iş akışı üzerindeki kontrol esastır.
- Ajan çerçevesi faydaları: Basit iş akışları veya karmaşık özerk ajanlar olsun, tüm ajan sistemleri, ajan çerçeveleri tarafından sağlanan temel özelliklerden yararlanabilir. Bu özellikler, ihtiyaçlarınıza bağlı olarak sıfırdan oluşturulabilir veya mevcut bir açık kaynak platformundan yararlanılabilir.
Yeni standartlar
- Model Context Protocol (MCP): Ajanların harici veri kaynaklarıyla nasıl konuştuğuna dair endüstri standardı. LangGraph, ajanların veritabanları ve yerel araçlarla özel sarmalayıcılar olmadan “tak-çalıştır” yapmasına izin vermek için MCP'yi entegre eder.
- Stripe Agentic Commerce Protocol (ACP): Bu, yapay zeka ajanlarının ödemeleri, envanteri ve gönderimi güvenli bir şekilde yönetmesine izin veren ilk canlı endüstri standardıdır. Ajanın bir sohbet arayüzü içinde kullanıcı için bir satın alma işlemini tamamlayabildiği “Agentic Checkout”u mümkün kılar.
Bir AI ajanı tam olarak nedir?
Bir “yapay zeka ajanı”nı oluşturan şeyin üzerinde anlaşılmış bir tanım yoktur.
- Geleneksel yapay zeka ajanları, çevreleriyle etkileşime giren sistemler olarak tanımlar.
- Simon Willison’ın anketi, uygulayıcılar arasında çeşitli çalışma tanımları sunar.2
- Anthropic'in tanımı, etkili ve uyumlu yapay zeka ajanları oluşturmak için tasarım ilkelerini ana hatlarıyla belirtir.3
- Büyük danışmanlık firmaları, iş akışlarını ve karar vermeyi otomatikleştirmede ajanların rolünü vurgular.4 .
Bunların birçoğu, iş akışlarını ve yerleşim özerkliğini bir spektrumun sonunda açıkça içerir.
Bu görüşlere katılıyoruz, bu nedenle katı bir tanım sunmuyoruz. Bunun yerine, bir yapay zeka sisteminin daha ajan benzeri olarak kabul edilmesine neden olan faktörleri listeliyoruz:
- Ortam ve hedefler:
- Karmaşık ortamlardaki, örneğin çoklu görevler ve beklenmedik değişiklikler içeren yapay zeka sistemleri ajandır.
- Talimat almadan hedefleri takip eden yapay zeka sistemleri ajandır.
- Kullanıcı arayüzü ve gözetim: Doğal dilleri öğrenebilen ve daha az kullanıcı gözetimine ihtiyaç duyan yapay zeka sistemleri ajandır.
- Sistem tasarımı: Araç kullanımı (ör. web araması, programlama) veya planlama (ör. yansıtma, alt hedef ayrıştırma) gibi tasarım desenlerini kullanan sistemler ajandır.
Daha ayrıntılı bir açıklama için, daha önce bu faktörleri listeledik ve bunların ajan yapay zeka sistemlerini nasıl tanımladığını tartıştık.
Bu ajanlar tamamen özerk mi?
Henüz değil. Çoğu açık kaynak yapay zeka ajanı, araç kullanımı, karar verme ve problem çözmeyi etkinleştirerek LLM özerkliğini artırır, ancak yine de yapılandırılmış girdiler ve döngüde bir insan gerektirir.
Devon ve PR-Agent gibi örnekler, tam ajan davranışı göstermek yerine önceden tanımlanmış mantık veya RL iş akışlarını takip eder. Diğer yapay zeka ajanları hala (Özerk Öğrenme + Genelleme) yeteneklerinden yoksundur.
Yapay zeka ajanları ne zaman (ve ne zaman kullanılmamalı) kullanılmalıdır
Her LLM uygulaması ajan benzeri karmaşıklık gerektirmez. Birçok kullanım durumu, hafif erişimle artırılmış üretim (RAG) ile daha iyi karşılanır.
Ajan sistemleri, bellek yönetimi, araç orkestrasyonu, hata işleme ve gecikme süresini ve maliyeti artıran kontrol döngüleri gibi mimari ek yük getirir. Örneğin, kıyaslamalarımızda, yapay zeka ajanlarının başarı oranlarının 35 dakikalık insan etkileşiminden sonra azaldığını gözlemledik.
Bu riskleri azaltmak için, ajan sistemlerini kontrollü ortamlarda test etmek ve dağıtımdan önce sağlam koruma önlemleri uygulamak esastır.
Ajanlar, adımlar kolayca tahmin edilemediğinde veya sabit kodlanamadığında en değerlidir. Özellikle aşağıdaki durumlar için uygundurlar:
- Görevler dinamik ve çok adımlıdır, dallanma mantığı veya belirsiz alt hedeflerle.
- Araç kullanımı koşullu veya uyarlanabilirdir, sistemin girdiye veya önceki duruma bağlı olarak hangi aracı çağıracağını seçmesini gerektirir.
- Uzun süreli bellek veya bağlam gereklidir, oturumlar veya yürütme aşamaları boyunca.
- Yürütme, çevresel geri bildirime yanıt vermelidir, örneğin API sonuçları, arama çıktıları veya başarısız eylemler.
- Döngüde-insan işbirliği gereklidir, özerklik ve gözetimin harmanlanması gereken (ör. yapay zeka yardımcı pilotları).
Öte yandan, iş akışları veya durumsuz LLM çağrıları şu durumlarda tercih edilir:
- Görev mantığı statik veya öngörülebilirdir, örneğin form doldurma veya içerik dönüştürme.
- Düşük gecikme süresi kritiktir, örneğin kullanıcıya dönük etkileşimlerde.
- Maliyeti en aza indirmek esastır, özellikle özyinelemeli LLM çağrılarından ve karmaşık orkestrasyondan kaçınarak.
Daha fazla oku
İşte ajan sistemleri tarafından yaygın olarak kullanılan altyapı hakkındaki en son kıyaslamalarımız:
- Uzak tarayıcılar: Tarayıcı altyapısının ajanların web ile güvenli bir şekilde etkileşime girmesini nasıl sağladığı.
- Tarayıcı MCP kıyaslaması: Araç kullanımı ve web erişimi için en iyi MCP sunucuları.
Açık kaynak yapay zeka ajanı örnekleri
“AI ajanları” olarak tanımlanan bazı araçlar aslında o kadar da ajan benzeri değildir; bu sistemler (ör. Devon PR-agent) büyük ölçüde RL tabanlı yapay zeka iş akışlarıdır ve LLM'ler önceden tanımlanmış kod yolları aracılığıyla organize edilmiştir.
1. Ajan çerçeveleri (Kendin Yap)
Geliştiricilerin mantık, bellek, araçlar ve orkestrasyon üzerinde kontrol sahibi olarak ajanlar oluşturması için modüler kütüphaneler ve SDK'lar.
✳️ SmolAgents ve Agno gibi bazı ajanlar hem ajan çerçeveleri hem de iş akışı otomasyonu kategorilerine uyar.
Genel ajan çerçeveleri
Odaklanan çerçeveler ajanlar oluşturmaya, iş akışlarını orkestre etmek, çoklu ajan kurulumları ve genel amaçlı kullanım durumları için esnek, özelleştirilebilir araçlar sunar.
- LangGraph – Graf tabanlı LLM iş akışı orkestrasyonu – LangGraph tescilli bir yazılımdır, ancak ajan geliştirme için açık kaynaklı bir kütüphane sağlar. RAG işleme hatları, ajan belleği/ durum yönetimi ve çoklu ajan kurulumları için en iyisidir.
- AutoGen – Çoklu ajan asenkron işbirliği – Sohbet benzeri API'ler aracılığıyla araç kullanan ajanları koordine etmek için tasarlanmıştır. Karmaşık iş akışlarını otomatikleştirmek için, özellikle özerk kod üretiminde en iyisidir.
- CrewAI – Kodsuz/düşük kodlu çoklu ajan çerçevesi – Başlamak için en kolay araçlardan biri, hazır ajan şablonları sunar (örn. toplantı hazırlık ajanı).
Özel amaçlı ajan çerçeveleri
Belirli ajan davranış türlerine veya ajan entegrasyonlarına odaklanmış çerçeveler.
- Camel – Rol tabanlı ajan simülasyonu – Yapılandırılmış akıl yürütme kullanan işbirlikçi, rol yapma ajanları için optimize edilmiştir. İş akışı otomasyonu ve yapay veri üretimi için en iyisidir.
- Mastra – Ön uça entegre ajan geliştirme – JavaScript tabanlı, kullanıcıya dönük uygulamalara ajan gömme için en iyisidir.
- PydanticAI – Tür güvenli minimal ajan kontrolü – Pydantic ile sıkı doğrulama ve şeffaf mantık yolları sağlar.
- Cybersecurity AI (CAI) – AI odaklı siber güvenlik ajan çerçevesi – sızma testi, güvenlik açığı keşfi ve kırmızı takım çalışmalarını, büyük dil modelleri ve Nmap gibi araçlarla entegrasyonları kullanarak insan-döngüde yetenekleri ile sağlar.
- Atomic Agents – Şema öncelikli tanecikli özel ajan oluşturucu – tanecikli ajan yapısı ve birleştirilebilir mantık için üretilmiştir.
- SmolAgents – Geliştiriciler için hafif ajan SDK'sı – Minimum soyutlama, mantığı JSON yerine Python üzerinden yönlendirir.
Ajan çalışma zamanları (Önceden oluşturulmuş özerk ajanlar)
Hemen çalıştırabileceğiniz (bir uygulama gibi) önceden oluşturulmuş, kendi kendine yeten ajanlar. Genellikle doğal dil hedeflerinden görevlerin özerk olarak yürütülmesini destekler.
Tamamen özerk:
- Otomatik-GPT – Hedef ayrıştırma ve özerk yürütme – Hedefleri alt görevlere ayırır ve araçlar, bellek ve akıl yürütme kullanarak bunları tamamlar. Önceden oluşturulmuş ajanlar ve düşük kodlu bir arayüz sunar.
- AIlice – Yerel genel amaçlı görev yürütme – Karmaşık görevleri cihaz üzerinde yürütür, yerel araçları ve dosya manipülasyonunu destekler. Açık kaynaklı LLM tabanlı, JARVIS benzeri bir yapay zeka asistanı oluşturmayı amaçlar.
- Manus AI – Genel amaçlı korumalı alan işlemleri. Araçları ve iş akışlarını güvenli bir korumalı alanda çalıştırır, çok alanlı, çok adımlı operasyonları özerk olarak yürütebilir. Meta tarafından satın alınmış ve Meta'nın “Personal Ambient Intelligence” ekosistemine entegre edilmiştir.5
Kısmen özerk:
- BabyAGI – Yinelemeli görev döngüsü yürütücüsü – Görev listelerini oluşturur, önceliklendirir ve bir geri bildirim döngüsünde çalıştırır. Görev üretme deneyleri için en iyisidir.
Tarayıcı/Arayüz tabanlı:
- AgentGPT – Tarayıcıda konuşlandırılan özerk ajan – Kullanıcıların bir web arayüzü aracılığıyla görev ajanları oluşturmasını ve yürütmesini sağlar. Hafiftir, deneyler için en iyisidir.
- OpenManus – Kalıcı tarayıcı ajanı – Tarayıcı ortamlarında oturumlar arası iş akışları için tasarlanmıştır. Web etkileşimlerini otomatikleştirmek için Playwright gibi araçları kullanır. Mevcut otomasyon işleme hatlarıyla kullanım için iyidir. Conda ile kurulum hızlıdır.
2. İş akışı otomasyonu ve orkestrasyonu
İş akışlarını otomatikleştiren ve genellikle yapay zeka ajanlarını entegre etme yeteneğine sahip birden çok platformu veya hizmeti entegre eden araçlar.
Genel iş akışı otomasyonu ve entegrasyon ajanları
API'leri bağlayan, olayları tetikleyen ve görevleri otomatikleştirerek farklı sistemler arasında iş akışları oluşturmayı ve entegre etmeyi kolaylaştıran platformlar.
- n8n – Görsel iş akışı otomasyonu ve API entegrasyonu – Uygulamaları, tetikleyicileri ve veri akışlarını bir düğüm editörü kullanarak bağlar. Görsel kodsuz oluşturmayı özel JavaScript/Python ile birleştirir ve 400'den fazla entegrasyonu destekler. Kendi kendine barındırabilir, LangChain ile yapay zeka ajan iş akışlarını çalıştırabilirsiniz. Teknik kişiler için en iyisidir.
- PlanExe – LLM'den Gantt/WBS planlama aracı – OpenAI'nin derin araştırmasına benzer bir yapay zeka planlayıcısı. Doğal dil hedeflerini LlamaIndex kullanarak yapılandırılmış zaman çizelgelerine dönüştürür.
- Agno ✳️ – Geliştirici dostu iş akışı ve ajan oluşturucu – Hem bir iş akışı otomasyon aracı (görevleri ve iş akışlarını otomatikleştirmeye yardımcı olur) hem de bir ajan oluşturucu olarak işlev görür.
- SmolAgents ✳️ – Geliştiriciler için hafif ajan SDK'sı – SmolAgents, hem hafif bir ajan SDK'sı (ajan çerçeveleri için) hem de bir iş akışı aracı olarak ( Hugging Face modelleriyle entegre olduğu için) hizmet edecek kadar esnektir.
- Windmill – Açık kaynak geliştirici platformu ve iş akışı motoru – Komut dosyalarını kullanıcı arayüzlerine, API'lere ve zamanlanmış görevlere dönüştürür; Python, TypeScript, Go ve diğer dilleri destekler.
- Activepieces – Açık kaynak otomasyon platformu – Görevleri otomatikleştirmek ve uygulamaları minimum kodlama ile entegre etmek için kendi kendine barındırılan görsel iş akışı oluşturucusu. Dağıtılmış yapay zeka görevlerini ve ajan zincirlerini ölçekte çalıştırmak için 280+ MCP sunucusunu destekler.
- Huginn – Web otomasyonu ve ajan yönetimi – Web tabanlı görevleri ve izlemeyi otomatikleştirmek için ajanlar oluşturur.
- Node-RED – IoT ve gerçek zamanlı veriler için akış tabanlı geliştirme – Tarayıcı tabanlı bir akış editörü ile hizmetleri entegre eder ve görevleri otomatikleştirir.
Çoklu ajan iş akışı orkestrasyonu
Yapılandırılmış iş akışları boyunca etkileşim halindeki ajanları koordine etmek ve çoklu ajan sistemlerini entegre etmek için tasarlanmış çerçeveler.
- HyperAgent – Tam yazılım yaşam döngüsü ajan orkestrasyonu – Ajanlar, mühendislik görevlerini planlamak, kodlamak ve doğrulamak için birlikte çalışır.
- Supercog – agentic – Yeniden kullanılabilir mantık blokları ile modüler orkestrasyon – Ölçeklenebilir, yapılandırılmış, ekip tabanlı otomasyon için tasarlanmıştır.
3. Web otomasyonu ve gezinme
Ajanlar web sitelerinde özerk olarak gezinir ve form doldurma, veri çıkarma ve web tarama otomasyonu gibi çok adımlı görevleri gerçekleştirir.
Özerk web ajanları ve yardımcı pilotlar
Genel amaçlı özerk ajanlar (web yetenekli):
- AgenticSeek – Tamamen özerk web tarama ajanı – Tamamen Yerel Manus AI. Veri çıkarma ve form doldurma konusunda uzmanlaşarak web tabanlı görevleri otomatikleştirir.
- Agent-E – DOM farkında tarayıcı otomasyon ajanı – Web sayfalarıyla etkileşime girmek için DOM'u (Belge Nesne Modeli) ayrıştırmaya odaklanır, düğmelere tıklama ve form doldurma için en iyisidir.
- AutoWebGLM – LLM tabanlı web ajanı – Karmaşık web sitelerinde daha iyi gezinme için pekiştirmeli öğrenme ve HTML sadeleştirmeyi kullanır.
Görü tabanlı web gezinme ajanları (çok modlu):
- Autogen extension WebSurfer – Çok modlu web ajanı – Web etkileşimini geliştirmek için metin ve görsel girdiyi (ekran görüntüleri) birleştirir.
- Skyvern – Bilgisayarla görü özellikli yapay zeka ajanı – LLM'leri ve bilgisayarla görüyü kullanarak iş akışlarını otomatikleştirir, hem metin hem de görsel öğeleri işler.
- WebVoyager – Görü özellikli web ajanı – Görüntü ağırlıklı web sitelerinde gezinmeyi iyileştirmek için metin ve ekran görüntüleri kullanır.
Açık kaynak web otomasyonu ve gezinme hakkında daha fazla bilgi için, en iyi araçlardan ve ajanlardan bazılarına yapılandırılmış bir bakış:
Web otomasyonu ve kazıma araç setleri
LLM destekli web RPA ve tarayıcı uzantıları
AI web kazıyıcıları ve tarayıcıları
4. Kodlama ve geliştirme ajanları
Kodlama görevlerine yardımcı olmak için tasarlanmış yapay zeka ajanları, geliştiricilere kod önerileri, hata ayıklama ve görev otomasyonu aracılığıyla gerçek zamanlı destek sağlar.
CLI tabanlı kodlama ajanları
- Codex CLI – Çok modlu etkileşim aracı (öner, düzenle, çalıştır) – Geliştirici iş akışlarını komut satırı aracılığıyla kod önerileri ve düzenlemeler sunarak geliştirir.
- OpenDevin – Açık kaynak yapay zeka kodlama asistanı – Programlama görevlerine yardımcı olur, çeşitli diller için kod önerileri sunar. OpenDevin'in kısa süre önce daha geniş misyonu “All Hands AI”yi yansıtmak için OpenHands olarak yeniden markalaştırıldığını unutmayın.6
- Aider – Yapay zeka eşli programlama asistanı – Kodlama yardımı için terminalinize entegre edilir, otomatik tamamlama, hata ayıklama ve görev otomasyonunu destekler.
Yapay zeka kod editörleri
- Neovim – Yapay zeka entegreli kod editörü – Kod tamamlama, yeniden düzenleme sağlayan yapay zeka destekli eklentiler.
- Visual Studio Code (VS Code) – Yapay zeka destekli kod tamamlama ve hata ayıklama aracı – GitHub Copilot aracılığıyla kod önerileri ve otomatik tamamlama sunar, geliştiriciler için IDE ortamlarıyla entegredir.
- Cursor – Yapay zeka entegreli kod editörü – Gerçek zamanlı yapay zeka destekli kod tamamlama ile oluşturulmuştur.
İstem-uygulamaya oluşturucular (Vibe coding)
Açık kaynak v0 / lovable / Bolt alternatifleri:
- Dyad – Açık kaynak yapay zeka uygulama oluşturucusu – Doğal dil komutlarıyla yapay zeka odaklı uygulamalar oluşturmak için yerel öncelikli, kodsuz bir araç.
- vx.dev – Açık kaynak yapay zeka uygulama oluşturucusu – Doğal dil istemlerini uygulamalara dönüştürmeye odaklanmış, yerel öncelikli, düşük kodlu bir araç.
5. Siber güvenlik ajanları
Sızma testi, güvenlik açığı keşfi, kırmızı takım çalışmaları ve özerk tehdit tespiti gibi görevler dahil olmak üzere siber güvenlik operasyonlarını geliştirmek için tasarlanmış yapay zeka ajanları.
- YAWNING TITAN – Soyut, grafik tabanlı siber güvenlik simülasyonu – Grafik tabanlı ortamlara odaklanarak, özerk siber operasyonlar için ajanların eğitilmesini destekler.
- bumpgen – Paket yönetim ajanı – npm paketlerini (Node.js paket yöneticisi) otomatik olarak yükseltir.
- Cyber-Security LLM Agents – LLM odaklı siber güvenlik görevleri – AutoGen üzerine inşa edilmiştir. ChatGPT EDR otomasyonu ve tespit mühendisliği için otomatik CI/CD'yi göstermek için çeşitli araştırma uygulamalarında kullanılır.
6. AI video içerik oluşturma ajanları
sanat, görüntüler ve videolar dahil olmak üzere görsel ve multimedya içeriği oluşturma, düzenleme ve geliştirmeye yardımcı olan yapay zeka ajanları.
- Mochi – Metinden videoya oluşturma – Metin istemlerini videoya dönüştürür, kısa biçimli videolar oluşturmaya odaklanır. Metin açıklamalarından hızlı bir şekilde video oluşturmak için çok uygundur.
- CogVideo – Metinden videoya oluşturma – Yüksek doğrulukla metin istemlerini videoya dönüştürerek görüntüden videoya oluşturmayı mümkün kılar. Metin veya görüntülerden yüksek kaliteli video oluşturmak için daha gelişmiş bir araç.
- Allegro – Metinden videoya oluşturma – Yaratıcı içerik oluşturmaya odaklanarak metin istemlerini videoya dönüştürür. Bu araç, benzersiz görsel anlatılar üretmek için metinden yaratıcı video sentezine vurgu yapar.
- DALL·E (Açık kaynak sürümleri) – Metinden videoya oluşturma – Yazılı istemleri ayrıntılı ve yaratıcı görsel içeriğe dönüştürerek metin açıklamalarından görüntüler oluşturur.
7. Finans ajanları
Otomatik pekiştirmeli öğrenme geliştirmesi veya gerçek zamanlı finansal veri analizi sunan yapay zeka ajanları.
- FinRL – Ticaret için otomatik pekiştirmeli öğrenme – Piyasa verilerine dayalı ticaret stratejilerini özerk olarak öğrenir ve yürütür, dinamik finansal ortamlara uyum sağlar.
- OpenBB Terminal – Finansal veri analizi – Yatırım profesyonellerinin bilinçli ticaret kararları vermesini sağlayarak, gerçek zamanlı ticaret için özerk finansal içgörüler sunar.
8. Sağlık ajanları
Hasta verilerini ve tıbbi raporları analiz ederek tıbbi teşhis, hastalık izleme ve sağlık içgörüleri konusunda yardımcı olan yapay zeka ajanları.
- HIA (Sağlık İçgörü Ajanı) – Tıbbi rapor analizi – Tıbbi raporları analiz eder ve sağlık içgörüleri sunar.
- AI-HealthCare-Assistant – Hastalık teşhisi ve izleme – Hasta verilerini kullanarak hastalıkları teşhis eder ve izler.
9. Araştırma ajanları
Veri toplama, literatür taraması ve hipotez testine yardımcı olarak araştırma sürecini kolaylaştıran yapay zeka ajanları.
- ChemCrow – Özerk kimya araştırma ajanı – Kimyasal analizlerde karmaşık deneysel ve hesaplamalı görevleri planlamak ve yürütmek için LLM'leri kimya araçlarıyla entegre eder.
- GPT Researcher – Özerk genel araştırma asistanı – Yapılandırılmış çevrimiçi aramalar yapar, içerikleri analiz eder ve minimum kullanıcı girdisiyle ayrıntılı araştırma raporları derler.
10. Veri analizi ajanları
Uygulanabilir içgörüler sağlamak ve karar vermeyi desteklemek için verileri işleyen, analiz eden ve yorumlayan yapay zeka ajanları.
Finans
- FinRobot – Finansal veri analizi ajanı – Büyük dil modelleri kullanarak finansal veri yorumlamayı ve raporlamayı otomatikleştirir.
İş zekası ve sorgulama ajanları
- Wren AI – Metni SQL'e dönüştüren iş zekası ajanı – İş raporlaması için doğal dil sorularını SQL sorgularına dönüştürür.
- Entaoai – GenAI destekli veri mühendisliği aracı – Veri sorgulama ve dönüştürme görevleri için bir sohbet arayüzü sağlar.
- Vanna AI – Doğal dilden SQL'e ajan – Yapılandırılmış veri kümelerini keşfetmek için kullanıcı istemlerine dayalı SQL sorguları oluşturur.
Sosyal medya ajanları
- Twitter Personality Agent – Sosyal medya analizi ajanı – Davranışsal ve kişilik özelliklerini çıkarmak için tweet geçmişini analiz eder.
11. Kişisel yardım ajanları
Görev yönetimi, zamanlama ve kişisel organizasyona yardımcı olan, üretkenliği ve zaman yönetimini artıran yapay zeka ajanları.
- VacAIgent (önceden oluşturulmuş CrewAI ajanı) – Seyahat planlama asistanı – Streamlit ve LLM'leri kullanarak tam seyahat güzergahlarını özerk olarak oluşturur.
- Inbox Zero – E-posta asistanı – Doğal dil işleme ve Gmail entegrasyonu kullanarak mesajları önceliklendirir, sınıflandırır ve özetler.
- Cal – Takvim zamanlama ajanı – LLM tabanlı etkileşim aracılığıyla toplantı oluşturmayı, yeniden zamanlamayı ve özetlemeyi otomatikleştirir.
Yapay zeka ajan sistemleri oluşturma
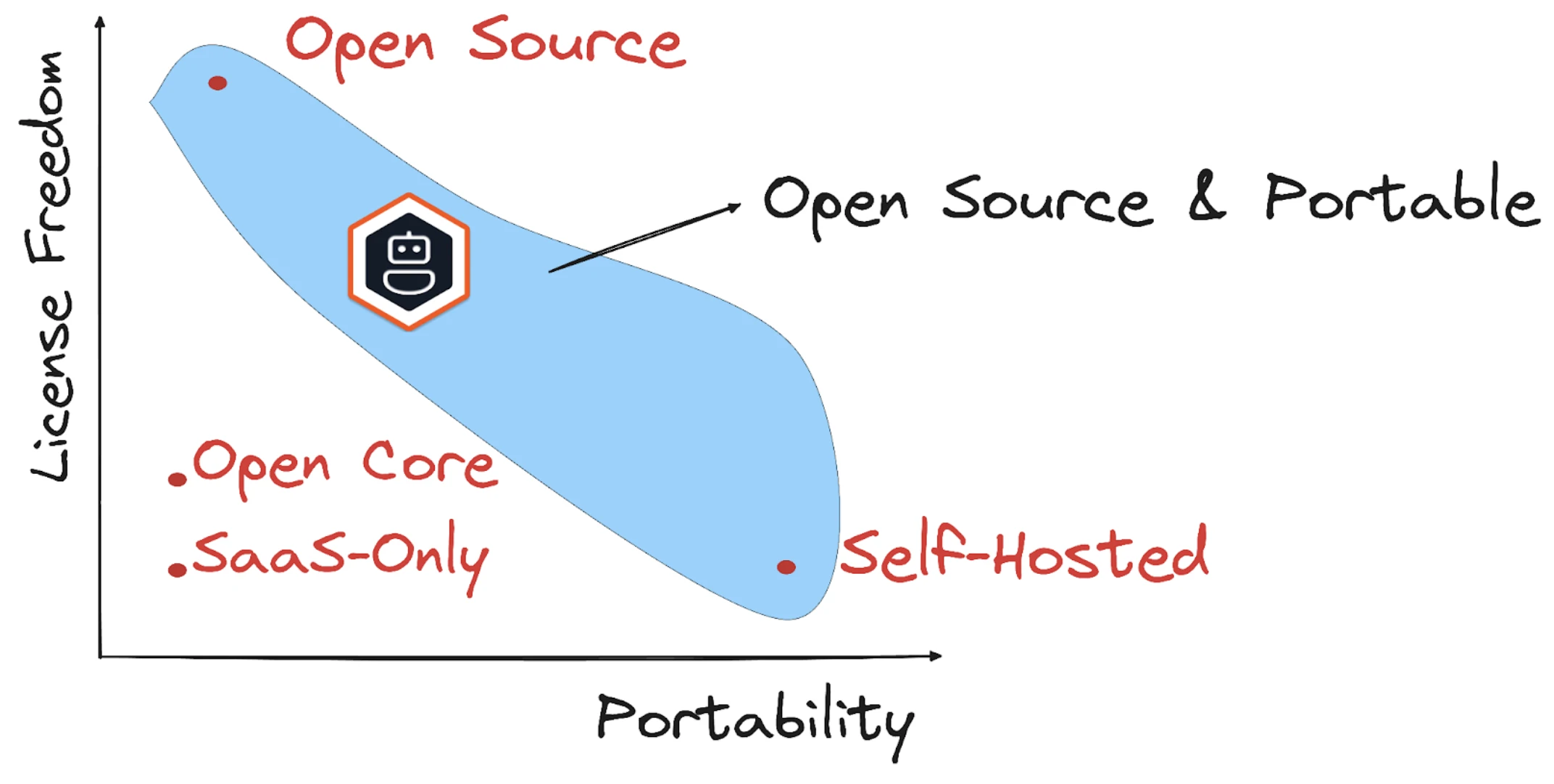
Birçok yapay zeka çerçevesi tek bir satıcı veya genel repolar tarafından kontrol edilir, ancak sıkı bir şekilde yönetilir.
Bu projeler genellikle açık çekirdek modellere kayar: temel kod ücretsiz kalır, ancak çoklu ajan orkestrasyonu, gözlemlenebilirlik veya ince taneli kontrol ticari lisansların arkasında kapılı olabilir. Bazı “açık” ekosistemlerde, üretim kullanımı genellikle kilitli bir arka uç satın almayı gerektirir.
Kaynak7
Gerçek dünya yapay zeka ajanı projeleri
Deneyimlerimize göre, işte bazı yapay zeka ajanları ve uygulamaları:
- AI Kod Editörleri API geliştirme ve uygulama oluşturma için
- Ekran görüntüsünden kod yürütme AI web sitesi oluşturma için
- Bilgisayar kullanım ajanları teslimat sipariş etmek, restoran rezervasyonu yapmak veya bir oda tasarlamak için.
Diğer tek başına yapay zeka ajanı projeleri:
Diğer çerçeve bazında yapay zeka ajanı projeleri:
Daha fazla bilgi
Bu araştırmayı kaynak gösterin
Yayınlayacağınız yere uygun formatı seçin. Bağlantılı sürümü CMS'inize yapıştırmak, geri bağlantıyı korur.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{En İyi 50+ Açık Kaynak Yapay Zeka Ajanı Listesi}},
year = {2026},
month = may,
howpublished = {\url{https://aimultiple.com/open-source-ai-agents}},
note = {AIMultiple. Erişim tarihi: 14 Mayıs 2026}
}
Yorum yapan ilk kişi olun
E-posta adresiniz yayınlanmayacak. Tüm alanlar gereklidir. Yorumlar orijinal dilinde bırakılır.