20 Strategien zur KI-Verbesserung & Beispiele
KI-Modelle erfordern kontinuierliche Verbesserung, da sich Daten, Nutzerverhalten und reale Bedingungen weiterentwickeln. Selbst leistungsstarke Modelle können driften, wenn die erlernten Muster nicht mehr zu den aktuellen Eingaben passen, was zu geringerer Genauigkeit und unzuverlässigen Vorhersagen führt.
Änderungen von Vorschriften, Produktanforderungen oder Kundenerwartungen können ebenfalls neue Einschränkungen mit sich bringen, für die bestehende Modelle nicht ausgelegt waren.
Die Aufrechterhaltung der Modellqualität umfasst daher sowohl die Stärkung der Daten, die das Modell stützen, als auch der Algorithmen, die sein Verhalten prägen, um sicherzustellen, dass die Systeme aktuellen Anforderungen und nicht veralteten Annahmen entsprechen.
Entdecken Sie wichtige Strategien, darunter Datenfütterung, Daten- und Algorithmusverbesserung sowie KI-Skalierungsgesetze, die Ihre KI-Modelle relevant und praxistauglich halten.
Top 20 Möglichkeiten, Ihr KI-Modell zu verbessern
Wir erläutern Methoden zur Verbesserung Ihres KI-Modells in 4 verschiedenen Kategorien:
Methode | Beschreibung | Herausforderungen |
|---|---|---|
Mehr Daten zuführen | Hochwertige echte oder synthetische Daten hinzufügen, um Abdeckung und Generalisierung zu verbessern. | Datenqualität sicherstellen, Verzerrungen vermeiden, Datenschutz und Zugriffsbeschränkungen beachten. |
Daten verbessern | Labeling, Diversität und Augmentierung verbessern, um Rauschen und Verzerrungen zu reduzieren. | Qualität vs. Quantität abwägen, Datensatzverzerrungen verringern, konsistente Annotationen gewährleisten. |
Algorithmus verbessern | Bessere Architekturen, Fine-Tuning-Techniken und Deployment-Praktiken einsetzen. | Höhere Komplexität und Kosten, unbeabsichtigtes Verhalten, strenge Datenschutzanforderungen. |
KI-Skalierungsgesetze | Skalierung, Rechenleistung, Effizienz und Retrieval- oder Multi-Agenten-Techniken erhöhen. | Abnehmende Erträge, Rechenlimits, Umweltauswirkungen, Integrationskomplexität. |
Mehr Daten zuführen
Das Hinzufügen neuer und aktueller Daten ist eine der gängigsten und effektivsten Methoden, um die Genauigkeit Ihres Machine-Learning-Modells zu verbessern. Forschungsergebnisse zeigen eine positive Korrelation zwischen Datensatzgröße und KI-Modellgenauigkeit.1
Daher kann die Erweiterung des für das Neutraining verwendeten Datensatzes ein wirksamer Weg zur Verbesserung von KI/ML-Modellen sein. Stellen Sie sicher, dass die Daten sich entsprechend der Einsatzumgebung verändern. Ebenso ist die Einhaltung angemessener Qualitätssicherungspraktiken bei der Datenerhebung unerlässlich.
1. Datenerhebung
Datenerhebung/-gewinnung kann genutzt werden, um Ihren Datensatz zu erweitern und mehr Daten in das KI/ML-Modell einzuspeisen. Dabei werden frische Daten gesammelt, um das Modell neu zu trainieren. Diese Daten können mit folgenden Methoden gewonnen werden:
- Private Erhebung
- Automatisierte Datenerhebung
- Maßgeschneidertes Crowdsourcing
Um erfolgreich Daten für KI zu sammeln, müssen Unternehmen auf Folgendes achten:
- Ethische und rechtliche Aspekte der Datenerhebung müssen respektiert werden, um ethische Probleme zu vermeiden.
- Verzerrungen (Bias) in den Trainingsdaten können zu unerwünschten KI-Ergebnissen führen.
- Die Vorverarbeitung der Rohdaten ist unerlässlich, um Qualitätsmängel zu beheben und die Datenintegrität für das KI/ML-Training sicherzustellen.
- Nicht alle Daten sind aufgrund von Sensibilitäts- und Datenschutzbestimmungen leicht zugänglich.
Erfahren Sie mehr über Datenerhebungsmethoden.
Es wird außerdem empfohlen, mit einem KI-Datendienst zusammenzuarbeiten, um relevante Datensätze ohne den Aufwand der Datensammlung zu erhalten und ethische sowie rechtliche Probleme zu vermeiden.
2. Synthetische Daten mit generativen Modellen
Generative KI hat die Erzeugung synthetischer Daten vorangebracht und liefert hochwertige Datensätze, die reale Bedingungen nachbilden. LLM und Diffusionsmodelle können nun strukturierte und unstrukturierte Daten für das Training von Modellen in Domänen erzeugen, in denen echte Daten knapp sind.
Beispiele umfassen:
- Erzeugung seltener medizinischer Fälle zur Verbesserung von Machine-Learning-Modellen im Gesundheitswesen.
- Generierung realistischer Gesprächsdaten zur Verbesserung von Natural Language Processing-Systemen.
- Erstellung visueller Datensätze, um Bildauflösung, Fotoqualität oder Bilderkennungsmodelle zu testen.
Synthetisches Self-Play und synthetische Trainingsdaten
Synthetisches Self-Play erzeugt neue Trainingsdaten, indem Modelle oder Agenten mit Aufgaben oder untereinander interagieren. Diese Ergänzungen verfügen über begrenzte hochwertige menschliche Daten.
Diese Methode bietet:
- Skalierbare Produktion von Instruktions-, Argumentations- oder Dialogdaten.
- Abdeckung von Szenarien, die selten oder teuer manuell zu sammeln sind.
- Verbesserte Modellleistung in Bereichen, in denen Datenknappheit die primäre Einschränkung darstellt.
Praxisbeispiel: Mehr Daten für Chatbots
Ein Chatbot für den IT-Support hatte Schwierigkeiten, Benutzerfragen korrekt zu verstehen und zu klassifizieren. Um seine Leistung zu verbessern, wurden 500 IT-Support-Anfragen in mehreren Variationen in sieben Sprachen umgeschrieben.
Diese zusätzlichen Daten halfen dem Chatbot, verschiedene Frageformate zu erkennen, und verbesserten seine Fähigkeit, effektiver zu antworten.
Daten verbessern
Die Verbesserung bestehender Daten kann ebenfalls zu einem besseren KI/ML-Modell führen.
Da KI-Lösungen nun komplexere Probleme angehen, sind bessere und vielfältigere Daten für ihre Entwicklung erforderlich. So kommt etwa die Forschung2 zu einem Deep-Learning-Modell, das Objekterkennungssystemen hilft, die Interaktionen zwischen zwei Objekten zu verstehen, zu dem Schluss, dass das Modell anfällig3 für Datensatzverzerrungen ist und einen vielfältigen Datensatz benötigt, um Ergebnisse zu liefern.
Verbesserungen können erreicht werden durch:
3. Daten anreichern
Die Erweiterung des Datensatzes ist eine Möglichkeit, KI zu verbessern. Ein weiterer wichtiger Weg zur Optimierung von KI/ML-Modellen ist die Anreicherung der Daten. Das bedeutet, dass die neuen Daten, die zur Erweiterung des Datensatzes gesammelt werden, verarbeitet werden müssen, bevor sie in das Modell eingespeist werden.
Dies kann auch die Verbesserung der Annotation des bestehenden Datensatzes bedeuten. Da neue und verbesserte Labeling-Techniken entwickelt wurden, können sie auf den bestehenden oder neu erhobenen Datensatz angewendet werden, um die Modellgenauigkeit zu steigern.
4. Datenqualität verbessern
Die Verbesserung der Datenqualität ist entscheidend für die Weiterentwicklung von KI-Systemen und die Steigerung der Leistung von KI-Modellen. Während KI-Fortschritte oft bessere Algorithmen und mehr Rechenleistung betonen, bleibt hochwertige Trainingsdaten für optimale Leistung unerlässlich.
Ein datenzentrierter Ansatz hilft, den KI-Fortschritt zu beschleunigen, indem sichergestellt wird, dass die für das Training verwendeten Daten umfangreich und von hoher Qualität sind.
Die Erhebung und Kuratierung hochwertiger Daten ermöglicht es Entwicklern, effizientere und effektivere KI-Modelle zu bauen, die dann zur Lösung komplexer Aufgaben in verschiedenen Branchen eingesetzt werden können. Durch den Fokus auf Datenqualität können Unternehmen genauere Vorhersagen treffen, Verzerrungen reduzieren und die Fähigkeiten von KI-Systemen verbessern.
Die Datenqualität kann während der Datenerhebungsphase erheblich verbessert werden. Dazu gehört sicherzustellen, dass die Daten repräsentativ für die realen Szenarien sind, denen das Modell begegnen wird, um Verzerrungen zu beseitigen, Rauschen zu reduzieren und sicherzustellen, dass sie vielfältig genug sind, um alle relevanten Variablen zu erfassen.
Darüber hinaus können die Konsistenz bei der Datenkennzeichnung und die Behebung von Lücken im Datensatz dazu beitragen, Fehler im Lernprozess des Modells zu reduzieren.
5. Datenaugmentierung nutzen
Manche verwechseln augmentierte Daten mit synthetischen Daten; die beiden Begriffe unterscheiden sich jedoch. Augmentierte Daten beziehen sich auf das Hinzufügen von Informationen zu einem bestehenden Datensatz, während synthetische Daten künstlich erzeugt werden, um reale Daten zu ersetzen.
Algorithmus verbessern
Manchmal muss der ursprünglich für das Modell erstellte Algorithmus verbessert werden. Dies kann verschiedene Gründe haben, etwa eine Veränderung der Population, in der das Modell eingesetzt wird.
Nehmen wir an, ein eingesetzter KI/ML-Algorithmus, der das Gesundheitsrisiko eines Patienten bewertet und den Einkommensparameter nicht berücksichtigt, wird plötzlich mit Daten von Patienten mit niedrigerem Einkommen konfrontiert. In diesem Fall dürfte er keine fairen Bewertungen liefern.
Daher kann die Aktualisierung des Algorithmus und das Hinzufügen neuer Parameter ein wirksamer Weg sein, um die Modellleistung zu verbessern. Der Algorithmus kann auf folgende Weise verbessert werden:
6. Architektur verbessern
Es gibt einige Möglichkeiten, die Architektur eines Algorithmus zu verbessern. Eine besteht darin, moderne Hardwarefunktionen wie SIMD-Anweisungen oder GPUs zu nutzen.4
Darüber hinaus können Datenstrukturen und Algorithmen durch den Einsatz cache-freundlicher Datenlayouts und effizienter Algorithmen verbessert werden. Schließlich können Algorithmenentwickler jüngste Fortschritte im maschinellen Lernen und bei Optimierungstechniken nutzen.
Der Transformer ist eine Deep-Learning-Architektur, die das Natural Language Processing (NLP) und andere Bereiche revolutionierte, indem sie eine effizientere und effektivere Modellierung von Sequenzdaten ermöglicht. Sie wurde im Paper „Attention Is All You Need“5 vorgestellt und stützt sich stark auf einen Mechanismus namens Self-Attention, der rekurrente und konvolutionelle Operationen ersetzt, die in früheren Modellen wie RNNs und CNNs verwendet wurden.
Ein Transformer besteht aus einem Encoder und einem Decoder, die jeweils aus mehreren gestapelten Schichten aufgebaut sind:
- Der Encoder wandelt Eingabesequenzen in kontextbewusste Repräsentationen um, indem er Multi-Head Self-Attention nutzt, um Token-Beziehungen zu erfassen, Feedforward-Netzwerke für die Verarbeitung und Residualverbindungen mit Layer-Normalisierung für Stabilität.
- Der Decoder erzeugt Ausgabesequenzen Token für Token, indem er maskierte Multi-Head Self-Attention einbezieht, um den Zugriff auf zukünftige Token zu verhindern, Cross-Attention, um Encoder-Ausgaben zu integrieren, sowie ähnliche Feedforward- und Normalisierungsmechanismen für effizientes Lernen.
7. Hybride Modellarchitekturen
Hybride Modellarchitekturen kombinieren Elemente von Transformers, Zustandsraummodellen und anderen Sequenzverarbeitungsmethoden. Dieser Ansatz unterstützt langlebigen Kontext und reduziert den Rechenaufwand.
Wesentliche Vorteile sind:
- Effizientere Verarbeitung langer Sequenzen.
- Reduzierter Speicherverbrauch für Training und Inferenz.
- Kompatibilität mit Rechenzentrums- und Edge-Umgebungen.
Praxisbeispiel: Kimi K2.5
Kimi K2.5 ist ein quelloffenes agentisches KI-Modell, das von Moonshot KI entwickelt und auf rund 15 Billionen gemischten visuellen und Text-Token vortrainiert wurde.
Das Design von Kimi K2.5 integriert Vision- und Sprachverständnis mit agentischem Reasoning und bietet sowohl sofortige als auch „denkende“ Modi und unterstützt konversationelle sowie autonome Agenten-Workflows.6
Kernfunktionen sind:
- Native Multimodalität: Verarbeitet und analysiert Text, Bilder und Video in einem einheitlichen Modell.
- Visuell unterstütztes Coding: Kann Code aus visuellen Eingaben generieren und Ausgaben an visuelle Spezifikationen anpassen.
- Agent Swarm-Ausführung: Unterstützt koordinierte Aufgabenzerlegung, sodass agentische Prozesse für komplexe Workflows parallel ablaufen können.
8. Feature-Reengineering
Feature-Reengineering eines Algorithmus ist der Prozess der Verbesserung der Merkmale des Algorithmus, um ihn effizienter und effektiver zu machen. Dies kann durch Modifikation der Algorithmusstruktur oder durch Feinabstimmung seiner Parameter geschehen.
9. Multimodale Weltmodelle
Multimodale Weltmodelle lernen aus Text, Bildern, Audio, Video, strukturierten Daten und Sensoreingaben. Dies schafft eine einheitliche Repräsentation über Modalitäten hinweg.
Wichtige Aspekte sind:
- Bessere Verankerung in realen Informationen.
- Genauere Interpretation von Szenen, Signalen und multi-formatigen Eingaben.
- Anwendbarkeit auf Aufgaben, die integriertes Verständnis über Modalitäten hinweg erfordern.
Praxisbeispiel: DeepMind
Google DeepMind hat seine KI-Modelle erheblich verbessert, indem es deren Architektur optimierte und verschiedene Komponenten für bessere Leistung überarbeitete. So wurde beispielsweise das Modell Gemini mit einer multimodalen Architektur erstellt, die es in die Lage versetzt, Aufgaben mit Text, Audio und Bildern effektiver zu bewältigen.
Zusätzlich wurde PaLM 2 durch einen rechenoptimalen Skalierungsansatz und Datensatzverbesserungen für Reasoning-Aufgaben optimiert. Diese Architektur-Upgrades führten zu höherer Genauigkeit und Anpassungsfähigkeit.7
10. KI-Sicherheit, Alignment und Governance
Die Verbesserung von Algorithmen beschränkt sich nicht mehr nur auf technische Optimierungen. KI-Sicherheit, Alignment und Governance werden zunehmend wichtiger, um sicherzustellen, dass KI-Systeme sich wie beabsichtigt verhalten. Entwickler und Unternehmen priorisieren Methoden, die:
- Die Ausgaben von KI-Modellen mit menschlichen Werten und Geschäftsanforderungen in Einklang bringen.
- Feedback-Schleifen einbeziehen, um unbeabsichtigtes Verhalten während des Einsatzes zu verhindern.
- Governance-Rahmenwerke schaffen, die Grenzen für die Werkzeugnutzung in verschiedenen Branchen setzen.
Diese Verschiebung unterstreicht, dass bessere KI-Ergebnisse nicht nur eine höhere Genauigkeit, sondern auch Vertrauenswürdigkeit, ethische Überlegungen und langfristige Nachhaltigkeit umfassen.
Praxisbeispiel: KI-Sandbagging im International KI Safety Report
Der International KI Safety Report weist auf ein Problem hin, das als KI-Sandbagging bekannt ist und bei dem ein Modell während der Evaluierung ein anderes Verhalten zeigt als im realen Einsatz. Insbesondere können fortschrittliche Systeme bei formellen Tests sicherer oder weniger leistungsfähig erscheinen, sich aber nach dem Deployment anders verhalten.
Dies schafft eine Evaluierungslücke: Herkömmliche Benchmarks und Red-Team-Tests erfassen möglicherweise nicht vollständig die realen Risiken, wenn Modelle ihr Verhalten je nach Kontext anpassen können. Für Unternehmen bedeutet dies, dass einmalige Sicherheitstests nicht ausreichen und durch kontinuierliches Monitoring, Auditing und Governance-Mechanismen ergänzt werden müssen.8
Abbildung 1: Beispiel des o3-Modells von OpenAI, das situatives Bewusstsein während der Evaluierungen zeigt.
11. Verifier-Modelle und Selbstkorrektur-Pipelines
Verifier-Modelle bewerten die von einem Basismodell erzeugten Ausgaben und identifizieren Fehler oder Inkonsistenzen. Sie unterstützen strukturierte Selbstkorrektur. Ihre Hauptbeiträge umfassen:
- Höhere Genauigkeit bei Reasoning und mathematischen Aufgaben.
- Geringere Ausfallraten durch systematische Prüfung.
- Größere Zuverlässigkeit in risikoreichen oder domänenspezifischen Anwendungen.
12. On-Device- und Edge-KI-Optimierung
Die Optimierung von KI auf Geräten und am Edge ist zunehmend entscheidend für verbesserten Datenschutz, geringere Latenz und höhere Effizienz. Anstatt Daten in zentralen Servern zu verarbeiten, können KI-Systeme direkt auf Geräten wie Smartphones, IoT-Sensoren oder Unternehmenshardware laufen.
Vorteile sind:
- Verbesserter Datenschutz durch lokale Speicherung sensibler Daten.
- Geringere Latenz, die sofortige Echtzeit-Erkenntnisse ermöglicht.
- Reduzierte Abhängigkeit von ständiger Konnektivität und großer Cloud-Infrastruktur.
Dieser Trend ist besonders relevant in Branchen wie Gesundheitswesen, Automobilindustrie und Fertigung, wo zeitnahe Reaktionen und Datenschutz entscheidend sind.
KI-Skalierungsgesetze
Skalierungsgesetze beschreiben, wie sich die Modellleistung verändert, wenn Parameter, Daten und Rechenleistung in ausgewogenem Verhältnis gemeinsam skaliert werden. Die Forschung zeigt, dass der Loss dazu neigt, vorhersagbaren Potenzgesetz-Mustern zu folgen, wenn Modelle mit ausreichend Daten und Rechenressourcen im Verhältnis zu ihrer Größe trainiert werden.
Frühe Arbeiten identifizierten Beziehungen zwischen Parametern, Token und Trainingsberechnung, während spätere Studien die optimalen Verhältnisse revidierten und zeigten, dass viele große Modelle untertrainiert waren und Modelle am besten abschneiden, wenn Parameter und Trainingstoken in ähnlichen Größenordnungen skaliert werden.
Neuere Analysen beziehen die Inferenzkosten mit ein und zeigen, dass kleinere Modelle, die länger trainiert werden, die Leistung größerer Modelle erreichen können, wenn die Inferenzlast hoch ist. Zusätzliche Studien konzentrieren sich darauf, wie Fähigkeiten über Benchmarks hinweg skalieren, und zeigen, dass die Modelleffizienz mit der Verbesserung von Architekturen, Datenqualität und Trainingsmethoden zunimmt.
Diese Erkenntnisse leiten die Modellauswahl und Ressourcenplanung, indem sie ausgewogene Skalierung, ausreichende Trainingsdaten und die wachsende Bedeutung von Parameter- und Inferenzeffizienz betonen.
Praxisbeispiel: Parallele TTC-Skalierung mit PaCoRe
PaCoRe (Parallel Coordinated Reasoning) ist ein quelloffenes Framework, das einen neuen Ansatz zur Skalierung von Test-Time Compute (TTC) einführt.
Anstatt durch das Kontextfenster eines Modells eingeschränkt zu sein, startet PaCoRe eine massive parallele Exploration und komprimiert und synthetisiert die Ergebnisse dann über eine Message-Passing-Architektur, was eine effektive Skalierung der Rechenleistung auf Millionen von Token während der Inferenz ermöglicht.
PaCoRe liefert zudem einen offenen Server, der mit beliebigen LLM-Endpunkten verwendet werden kann, sodass Entwickler diesen parallelen Skalierungsansatz über verschiedene Modelle und Anbieter hinweg anwenden können.9
13. Modellgröße skalieren
Die Erhöhung der Parameteranzahl eines Modells bedeutet, es größer zu machen, typischerweise durch Hinzufügen weiterer Schichten oder komplexere bestehende Schichten. Größere Modelle können:
- Komplexere Muster erfassen: Mit mehr Parametern kann das Modell komplexere Beziehungen in den Daten abbilden.
- Größere Datensätze verarbeiten: Größere Modelle haben eine höhere Kapazität, um aus umfangreichen Daten zu lernen und diese zu verarbeiten.
Allerdings kann das Verhältnis zwischen Modellgröße und Leistung abnehmende Erträge aufweisen. Eine 10x-Steigerung der Modellgröße führt nicht unbedingt zu einer 10x-Verbesserung der Leistung.
Größere Modelle erfordern zudem exponentiell mehr Rechen- und Speicherressourcen, was sie teuer und schwer zu trainieren machen kann. Ab einem bestimmten Punkt kann die Vergrößerung des Modells vernachlässigbare Gewinne bringen, insbesondere wenn der Datensatz oder die Rechenressourcen nicht ausreichen.
14. Daten skalieren
Die Verfügbarkeit und Größe des zum Training eines Modells verwendeten Datensatzes beeinflusst dessen Leistung erheblich:
- Größere Datensätze verbessern die Generalisierung: Mit vielfältigeren und umfassenderen Daten lernt das Modell ein breiteres Spektrum an Mustern und neigt weniger zum Overfitting.
- Besseres Verständnis seltener Ereignisse: Große Datensätze helfen dem Modell, seltene und vielfältige Muster zu lernen, wodurch es besser mit ungewöhnlichen Fällen umgehen kann.
Allerdings hat auch die Skalierung von Daten ihre Grenzen:
- Abflachende Gewinne: Ab einem bestimmten Punkt bringt das Hinzufügen weiterer Daten abnehmende Leistungssteigerungen, weil das Modell die meisten nützlichen Muster bereits gelernt hat.
- Qualität vor Quantität: Daten von schlechter Qualität oder verrauschte Daten können die Leistung selbst in großen Mengen nicht verbessern.
- Rechenengpass: Größere Datensätze erfordern mehr Rechenleistung und Trainingszeit, was prohibitiv sein kann.
15. Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation ist zu einer wesentlichen Strategie geworden, um KI-Modelle zu verbessern, ohne sich ausschließlich auf größere Modelle oder mehr Rechenressourcen zu stützen. RAG-Systeme integrieren ein Large Language Model mit einer externen Wissensbasis, sodass das Modell in Echtzeit auf relevante Informationen zugreifen kann.
Kernvorteile:
- Weniger Bedarf an Neutraining der Modelle, wenn neue Informationen entstehen.
- Verbesserte Leistung bei spezialisierten Geschäftsfunktionen durch Verankerung der Ausgaben in kuratierten Datenquellen.
- Minderung des Risikos veralteter oder halluzinierter Antworten, indem Systeme auf Hintergrundquellen verweisen können.
Dieser Ansatz ist heute in Enterprise-KI-Lösungen üblich, wo Trainingsdaten mit sich schnell verändernden Bereichen wie Finanzen, Recht oder Kundenservice nicht Schritt halten können.
16. Speichererweiterte Systeme
Speichererweiterte Systeme geben Modellen Zugriff auf persistenten oder sitzungsbezogenen Speicher. Dadurch kann das Modell Kontext über Aufgaben und Interaktionen hinweg aufrechterhalten.
Wichtige Merkmale:
- Unterstützung für langfristigen Kontext, der nicht durch die Prompt-Länge begrenzt ist.
- Verbesserte Konsistenz über mehrstufige Workflows hinweg.
- Bessere Ausrichtung an Anwendungsfällen, die Kontinuität erfordern, wie Projektarbeit oder komplexe Analysen.
17. Rechenleistung skalieren
Die Skalierung der Rechenleistung umfasst die Erhöhung der verfügbaren Rechenkapazität während des Trainings oder der Inferenz, typischerweise durch:
- Leistungsstärkere Hardware: GPUs, TPUs oder spezialisierte KI-Chips.
- Verteilte Systeme: Training auf mehreren Maschinen parallel, um große Arbeitslasten zu bewältigen.
- Längere Trainingsdauer: Dem Modell ermöglichen, seine Gewichte über mehr Iterationen zu optimieren.
Das Verhältnis zwischen Rechenleistung und Modellleistung ist grundlegend:
- Mehr Rechenleistung ermöglicht größere Modelle: Skalierung der Rechenleistung erlaubt das Training von Modellen mit mehr Parametern.
- Längeres Training: Mit ausreichend Rechenleistung können Modelle auf größeren Datensätzen über längere Zeiträume trainiert werden, was zu besserer Optimierung führt.
Allerdings hat die Skalierung der Rechenleistung auch Herausforderungen:
- Abnehmende Erträge: Obwohl sich die Leistung mit mehr Rechenleistung verbessert, verlangsamt sich die Verbesserungsrate mit zunehmenden Ressourcen.
- Kosten- und Energiebedarf: Das Training fortschrittlicher Modelle wie GPT-4 erfordert erhebliche finanzielle und ökologische Ressourcen.
Trotz dieser Herausforderungen war die Skalierung der Rechenleistung entscheidend für Fortschritte im maschinellen Lernen der KI.
In der Inferenzphase kann die Leistung eines KI-Modells, insbesondere bei Aufgaben, die Mathematik oder mehrschrittiges Reasoning erfordern, durch die Zuweisung von mehr Rechenzeit verbessert werden. Dies wird häufig durch Strategien wie erhöhte Berechnung pro Abfrage oder iterative Verfeinerung erreicht. So funktioniert es:
Was passiert während der Inferenz?
Inferenz ist die Phase, in der ein vortrainiertes Modell verwendet wird, um Vorhersagen zu generieren oder Aufgaben basierend auf neuen Eingaben auszuführen. Anders als beim Training werden die Gewichte des Modells nicht aktualisiert, sondern es verlässt sich auf seine erlernten Fähigkeiten, um spezifische Probleme zu lösen.
Warum hilft mehr Rechenzeit?
Bei Aufgaben wie mathematischen Berechnungen oder mehrschrittigem Reasoning profitiert das Modell von mehr Zeit und Ressourcen pro Abfrage, weil:
- Iterative Verfeinerung: Bei Aufgaben, die mehrere logische Schritte erfordern, kann das Modell das Problem in kleinere Teile zerlegen, jeden Teil lösen und seine Lösung iterativ verfeinern. Die Zuweisung von mehr Rechenleistung ermöglicht es dem Modell, diese Schritte gründlicher zu verarbeiten.
- Erhöhte Präzision: Bei mathematischen Aufgaben erlaubt eine längere Inferenzzeit eine tiefere Erkundung von Mustern oder Trial-and-Error-Mechanismen, um sich korrekten Lösungen anzunähern.
- Besseres kontextuelles Verständnis: Bei Aufgaben wie mehrschrittigem Reasoning kann ein Modell mit mehr Rechenzeit den Kontext wiederholt bewerten, um sicherzustellen, dass Zwischenschritte mit dem Gesamtproblem übereinstimmen.
18. Inferenzzeit-Rechenskalierung
Inferenzzeit-Rechenskalierung bezeichnet die Zuweisung von mehr Rechenleistung an ein Modell während der Inferenz. Dieser Ansatz unterstützt längere Reasoning-Traces und mehrstufige Bewertung, ohne die Parameter des Modells zu verändern.
Wichtige Punkte:
- Modelle können Zwischenschritte iterativ verfeinern für Aufgaben, die Reasoning erfordern.
- Die Genauigkeit steigt, wenn dem Modell erlaubt wird, tiefere Inferenzpfade zu durchlaufen.
- Leistungssteigerungen werden ohne Neutraining erzielt, was diese Methode für häufige Aktualisierungen geeignet macht.
Praxisbeispiel: Fähigkeitsgewinne durch Post-Training und Inferenzzeit
Anthropics Claude Opus 4.6 veranschaulicht, wie fortschrittliche KI-Systeme durch Verbesserungen im Inferenzzeit-Reasoning und der Tool-Integration voranschreiten. Diese Fortschritte zeigen sich in leistungsfähigerem agentischem Coding, bei dem das Modell mehrschrittige Softwareaufgaben planen, große Codebasen navigieren und eigene Fehler iterativ beheben kann.
Sie treten auch in stärkerer Tool-Nutzung und koordinierten Agenten-Workflows zutage, etwa Agententeams in Claude Code, die komplexe Aufgaben aufteilen und ausführen.
Darüber hinaus unterstützt Opus 4.6 lange Kontextfenster (bis zu ~1 Million Token in der Beta), sodass es Kohärenz über ausgedehnte Dokumente, Codebasen und mehrschrittige Interaktionen hinweg aufrechterhalten kann.
Zusammen verdeutlichen diese Entwicklungen, wie Systemdesign und Inferenzzeit-Techniken bedeutende Fähigkeitsgewinne über das reine Basistraining hinaus bewirken.
Abbildung 2: Diagramm, das die Leistung von Opus 4.6 beim Terminal Bench zeigt. Terminal Bench ist eine Benchmarking-Suite zur Bewertung von KI-Agenten, die in Terminalumgebungen arbeiten.10
Praxisbeispiel: Gemini 3 Deep Think
Googles Gemini 3 Deep Think wurde entwickelt, um komplexe wissenschaftliche, mathematische und ingenieurtechnische Probleme mit tieferer inferenzieller Suche und Multi-Hypothesen-Erkundung anzugehen.
Deep Think verbessert die Leistung, indem es die Art und Weise ändert, wie das Modell zur Inferenzzeit denkt, und schwereren Problemen mehr Rechenleistung zuweist, anstatt sich ausschließlich auf eine höhere Parameterzahl zu stützen.
Dies zeigt, dass Reasoning-Modi, bei denen ein Modell in einen für schwierigere analytische Aufgaben optimierten Deep-Think-Modus wechseln kann, als eigenständiges Konzept des KI-Fortschritts neben Parameterzahl und Tooling-/Deployment-Verbesserungen entstehen.
Abbildung 3: Diagramm, das die Leistung von Deep Think bei den Benchmarks ARC-AGI 2, Humanity’s Last Exam, MMMU-Pro und Codeforces zeigt.11
Praxisbeispiel: GPT-5.3-Codex-Spark
OpenAIs GPT-5.3-Codex-Spark ist ein auf Coding fokussiertes Modell, das als geschwindigkeitsoptimierte Variante von GPT-5.3-Codex positioniert wird und für Echtzeit-Entwicklerworkflows gedacht ist.
Kernfunktionen:
- Hochdurchsatz-Inferenz: Ausgelegt für Coding-Assistenz mit niedriger Latenz, mit gemeldeten Ausgabegeschwindigkeiten von über 1.000 Token pro Sekunde in unterstützten Umgebungen.
- Großes Kontextfenster: Unterstützt bis zu 128.000 Token Kontext, was die Nutzung mit größeren Codebasen und längeren Sitzungen ermöglicht.
- Interaktive Coding-Workflows: Ausgerichtet auf iterative Coding-Aufgaben wie Editieren, Debuggen und Code-Verfeinerung in Echtzeit.
- Infrastrukturfokus: Gebaut, um auf Inferenzinfrastruktur mit niedriger Latenz zu laufen, einschließlich Deployments auf Cerebras-Hardware.
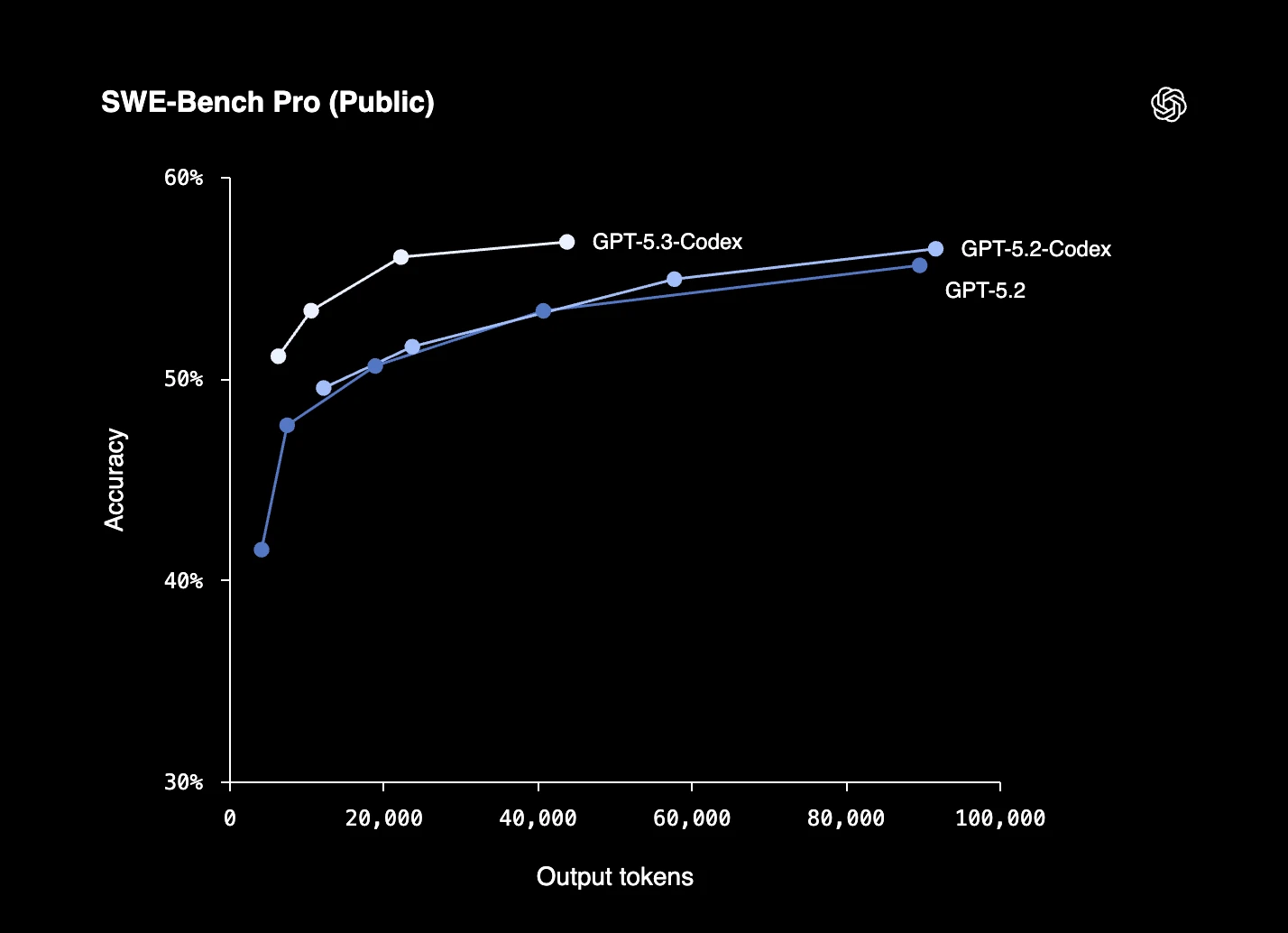
Abbildung 4: Benchmark-Leistung von OpenAIs GPT-5.3-Codex-Spark im SWE-Bench Pro.12
19. Agentische KI
Anstatt sich auf ein einzelnes größeres Modell zu verlassen, nutzen agentische Systeme verschiedene Modelle mit definierten Rollen, etwa Planung, Reasoning und Ausführung.
Vorteile:
- Skalierung der Reasoning-Fähigkeiten ohne endlose Erhöhung der Parameterzahl.
- Größere Flexibilität bei der Werkzeugnutzung durch Zuweisung von Aufgaben an das jeweils leistungsfähigste Modell.
- Einfachere Einbeziehung von Feedback von Nutzern und Stakeholdern in verschiedenen Phasen eines Prozesses.
Ein Beispiel ist ein Multi-Agenten-System, bei dem ein Modell Projektmanagement-Aufgaben übernimmt, ein anderes natürliche Spracheingaben interpretiert und ein drittes die Datenabfrage und -integration steuert. Zusammen liefern diese Modelle bessere Ergebnisse als ein einzelnes Modell allein.
20. Modelleffizienztechniken
Als Reaktion auf die Kosten und die Umweltauswirkungen des Trainings größerer Modelle sind Effizienztechniken in letzter Zeit in den Fokus gerückt. Diese Methoden ermöglichen es Entwicklern, die Leistung mit weniger Ressourcen zu verbessern:
- Quantisierung reduziert den Speicherbedarf, indem die Präzision der Modellparameter verringert wird, ohne die Vorhersagequalität zu beeinträchtigen.
- Knowledge Distillation überträgt Fähigkeiten von einem großen Modell auf ein kleineres und ermöglicht so schnellere Inferenz.
- Pruning entfernt überflüssige Parameter, um die Komplexität zu reduzieren und gleichzeitig die Genauigkeit zu erhalten.
- Low-Rank Adaptation (LoRA) ermöglicht effizientes Fine-Tuning großer Modelle für domänenspezifische Aufgaben mit begrenzten Ressourcen.
Diese Techniken machen KI-Systeme skalierbarer über verschiedene Modelle und Geschäftskontexte hinweg und ermöglichen bessere Ergebnisse zu geringeren Kosten.
Empfehlungen für die Herangehensweise an die Verbesserung von KI/ML-Modellen
Die Verbesserung eines KI/ML-Modells erfordert einen strategischen Ansatz, um Bereiche zu identifizieren, in denen wirksame Lösungen implementiert werden können. Durch die Kombination von Leistungsüberwachung mit hypothesengesteuerter Entscheidungsfindung können KI/ML-Modelle verfeinert und für bessere Ergebnisse optimiert werden:
Leistung überwachen
Man kann etwas nur verbessern, wenn man seine Verbesserungsbereiche kennt. Dies kann durch die Überwachung der Merkmale des KI/ML-Modells geschehen. Falls jedoch nicht alle Modellmerkmale überwacht werden können, kann eine ausgewählte Anzahl von Schlüsselmerkmalen beobachtet werden, um Variationen in deren Ausgabe zu untersuchen, die Modellleistung beeinflussen können.
Hypothesengenerierung
Bevor die richtige Methode ausgewählt wird, empfehlen wir die Durchführung einer Hypothesengenerierung. Dies ist ein vorentscheidlicher Prozess, der den Entscheidungsprozess strukturiert und die Optionen eingrenzt.
Dieser Prozess umfasst den Erwerb von Fachwissen, die Untersuchung des Problems, mit dem das KI/ML-Modell konfrontiert ist, und die Eingrenzung der unmittelbar verfügbaren Optionen, die identifizierten Probleme angehen können.
Iterative Verbesserung und Experimentieren
Die Verbesserung von KI/ML-Modellen ist ein fortlaufender Prozess. Nach der Hypothesenbildung und der Auswahl potenzieller Lösungen sind Experimentieren und Iteration der Schlüssel zur Verfeinerung des Modells.
A/B-Tests: Testen Sie verschiedene Modelle oder Änderungen an Teilmengen von Daten, um Ergebnisse zu vergleichen. Dies hilft zu erkennen, welche Verbesserungen am effektivsten sind.
Modell-Neutraining: Trainieren Sie das Modell regelmäßig mit neuen Daten, Feature-Updates oder Algorithmusanpassungen neu, um sicherzustellen, dass es relevant bleibt und sich an veränderte Bedingungen anpasst.
Automatisiertes Monitoring und Feedback-Schleifen: Nutzen Sie automatisierte Systeme, um kontinuierliches KI-Feedback bereitzustellen, das schnelle Anpassungen und rasche Iteration von Verbesserungen ermöglicht.
Feedback von Stakeholdern einbeziehen
Ein oft übersehener Teil des Modellverbesserungsprozesses ist das Einholen von Input von Endnutzern oder Stakeholdern. Von Geschäftsteams, Fachexperten oder Endnutzern gesammeltes KI-Feedback liefert wertvollen Kontext, um Vorhersagen zu verfeinern und reale blinde Flecken anzugehen.
Die Integration dieser Feedback-Schleife trägt dazu bei, dass sich das Modell kontinuierlich anpasst und auf die betrieblichen Anforderungen abgestimmt bleibt.
Diese Feedback-Schleife stellt sicher, dass das Modell mit den realen Bedürfnissen und Erwartungen im Einklang bleibt.
Die wirkungsvollsten Änderungen priorisieren
Nicht alle Verbesserungen haben das gleiche Ausmaß an Wirkung. Es ist essenziell, Änderungen zu priorisieren, die kritischsten Leistungsprobleme direkt angehen.
Beispielsweise kann die Verbesserung der Datenqualität oder die Beseitigung einer signifikanten Verzerrung im Modell wesentlich größere Auswirkungen haben als kleinere Anpassungen der Hyperparameter des Algorithmus.
Den Verbesserungsprozess dokumentieren und standardisieren
Für kontinuierliche Verbesserungen sollten Sie die Methoden, Experimente und Ergebnisse dokumentieren.
Die Standardisierung dieses Prozesses ermöglicht es, zukünftige Verbesserungen nach einem bewährten, strukturierten Ansatz durchzuführen, sodass Verbesserungen gemessen, verglichen und nachverfolgt werden können.
FAQs
Die Entwicklung der künstlichen Intelligenz hat zu bemerkenswerten Fortschritten in der natürlichen Sprachverarbeitung (NLP) geführt. Heutige KI-Systeme können menschliche Sprache mit beispielloser Genauigkeit verstehen, interpretieren und generieren. Dieser bedeutende Sprung zeigt sich in hochentwickelten Chatbots, Sprachübersetzungsdiensten und sprachgesteuerten Assistenten.
Um die Genauigkeit Ihres KI-Modells zu erhöhen, sollten Sie in Betracht ziehen, mehr hochwertige und vielfältige Trainingsdaten zu sammeln. Optimieren Sie außerdem die Hyperparameter Ihres Modells, experimentieren Sie mit verschiedenen Algorithmen und wenden Sie Techniken wie Kreuzvalidierung an, um die Leistung zu optimieren.
Verhindern Sie Overfitting bei KI durch den Einsatz von Regularisierungstechniken, die Implementierung von Dropout-Schichten in neuronalen Netzen und durch frühzeitiges Stoppen während des Trainings. Eine Vergrößerung des Datensatzes und die Sicherstellung von Datenvielfalt können dem Modell ebenfalls helfen, besser auf neue Eingaben zu generalisieren.
Diese Forschung zitieren
Wählen Sie das Format, das zu Ihrem Veröffentlichungsort passt. Wenn Sie die Link-Version in Ihr CMS einfügen, bleibt der Backlink erhalten.
@misc{dilmegani2026,
author = {Dilmegani, Cem and Ermut, Sıla},
title = {{20 Strategien zur KI-Verbesserung & Beispiele}},
year = {2026},
month = feb,
howpublished = {\url{https://aimultiple.com/ai-improvement}},
note = {AIMultiple. Abgerufen am 20. Februar 2026}
}




Seien Sie der Erste, der kommentiert
Ihre E-Mail-Adresse wird nicht veröffentlicht. Alle Felder sind erforderlich. Kommentare werden in ihrer Originalsprache belassen.