Top 25+ KI-Chip-Hersteller: NVIDIA & seine Wettbewerber
Basierend auf unserer Erfahrung mit dem AIMultiple Cloud-GPU-Benchmark mit 10 verschiedenen GPU-Modellen in 4 verschiedenen Szenarien sind dies die führenden KI-Hardware-Unternehmen für Rechenzentrums-Workloads. Folgen Sie den Links, um unsere Begründung für jede Auswahl zu sehen:
25+ KI-Chip-Hersteller nach Kategorie
*Die ausgewählten Modelle basieren auf den neuesten Ankündigungen.
**ACCEL wurde von chinesischen Wissenschaftlern in Zusammenarbeit mit Alibaba und der China's Semiconductor Manufacturing International Corporation (SMIC) entwickelt1
Sortierung erfolgt nach Kategorie. Anbieter werden innerhalb der Top-3-Kategorien (d. h. führender Hersteller, Public Cloud, Public KI Cloud) nach geschätztem Marktanteil sortiert, da Verkaufszahlen oder Cloud-Nutzung geschätzt werden können. Anbieter der letzten drei Kategorien (d. h. KI-Startup, künftiger Hersteller, sonstige Hersteller) werden alphabetisch sortiert.
5 mobile KI-Chip-Anbieter
*Die beliebtesten & aktuellsten Chips wurden ausgewählt.
5 Edge-KI-Chips
Die Nachfrage nach latenzarmer Verarbeitung hat Innovationen bei Edge-KI-Chips vorangetrieben. Die Prozessoren dieser Chips sind darauf ausgelegt, KI-Berechnungen lokal auf Geräten durchzuführen, anstatt auf cloud-basierte Lösungen angewiesen zu sein:
*Dies sind die maximal von den Anbietern angegebenen Werte. TOPS steht für Tera-Operationen pro Sekunde.
KI-Chip-Architekturen verstehen: GPUs vs. ASICs
Nicht alle KI-Chips sind gleich. Während die oben genannten Anbieter auf demselben Markt konkurrieren, verwenden sie grundlegend unterschiedliche Chip-Architekturen:
- GPUs (Graphics Processing Units) sind universell einsetzbare Prozessoren, die sowohl Training als auch Inferenz für eine breite Palette von KI-Workloads bewältigen können. NVIDIA und AMD dominieren diese Kategorie.
- ASICs (Application-Specific Integrated Circuits) sind speziell für bestimmte Aufgaben entwickelte Chips. Einige unterstützen sowohl Training als auch Inferenz (Google TPU, AWS Trainium), während andere nur für Inferenz ausgelegt sind (Groq LPU, AWS Inferentia).
Wichtige Erkenntnis:
Nicht alle ASICs sind nur für Inferenz. Google TPU, AWS Trainium, Cerebras und SambaNova unterstützen sowohl Training als auch Inferenz, während Groq LPU und AWS Inferentia sich ausschließlich auf Inferenz konzentrieren.
Diese Unterscheidung ist für Käufer wichtig: GPUs bieten Flexibilität bei verschiedenen KI-Workloads, während ASICs eine bessere Leistung pro Watt liefern, aber schwieriger umzuprogrammieren sind, wenn sich Modellarchitekturen ändern.
Laut TrendForce2 wird basierend auf den Wachstumsraten der KI-Server-Auslieferungen erwartet, dass die kundenspezifischen ASIC-Lieferungen von Cloud-Anbietern im Jahr 2026 um 44,6 % wachsen, während die GPU-Lieferungen voraussichtlich um 16,1 % zunehmen werden. Dies signalisiert einen Wandel in der KI-Hardware-Landschaft, da Hyperscaler zunehmend in ihr eigenes Silizium investieren.
Welche sind die führenden KI-Chip-Hersteller?
1. NVIDIA
NVIDIA entwickelt seit den 1990er Jahren Grafikprozessoren (GPUs) für den Gaming-Bereich. NVIDIA ist ein fabless Chip-Hersteller, der den Großteil seiner Chip-Fertigung an TSMC auslagert. Zu den Hauptgeschäftsbereichen gehören:
Desktop-KI-Lösungen
DGX Spark (ehemals Project Digits) ist ein Desktop-KI-Supercomputer für KI-Ingenieure und Datenwissenschaftler mit einem Grace Blackwell Superchip mit einer NVIDIA Blackwell RTX GPU mit 6.144 CUDA-Kernen und Tensor Cores der fünften Generation mit FP4-Präzision, verbunden über die NVIDIA NVLink-C2C Chip-zu-Chip-Verbindung mit einer leistungsstarken 20-Kern NVIDIA Grace CPU, mit bis zu 1 Petaflop KI-Rechenleistung und 128 GB einheitlichem Speicher für geräteinterne Agenten.3 4
NVIDIA und Microsoft arbeiten zusammen, um eine sichere Windows-Plattform für geräteinterne Agenten bereitzustellen, die auf neuen Betriebssystem-Sicherheitsprimitiven basiert.5
Rechenzentrumslösungen
Das Unternehmen stellt KI-Chips nach seinen Ampere-, Hopper- und zuletzt Blackwell-Architekturen her. Dank des generativen KI-Booms erzielte NVIDIA in den vergangenen Jahren hervorragende Ergebnisse, erreichte eine Billionenbewertung und festigte seinen Status als Marktführer im GPU- und KI-Hardware-Markt. Die folgende Grafik zeigt, wie der Umsatz von NVIDIA in diesem Segment im Laufe der Jahre gewachsen ist und wie er zur Haupteinnahmequelle des Unternehmens geworden ist.
Quelle: NVIDIA Corporation Finanzberichte.6
DGX™ A100 und H100 waren erfolgreiche Flaggschiff-KI-Chips von Nvidia, die für KI-Training und Inferenz in Rechenzentren konzipiert wurden.7 NVIDIA setzte diese fort mit
- H200, B300 und GB300 Chips
- HGX-Servern wie HGX H200 und HGX B300, die 8 dieser Chips kombinieren
- NVL-Serie und GB200 SuperPod, die noch mehr Chips zu großen Clustern zusammenfassen.8
Cloud-GPUs
Dank der Stärke seines Rechenzentrumsangebots hat NVIDIA nahezu ein Monopol auf dem Cloud-KI-Markt, wobei die meisten Cloud-Anbieter ausschließlich NVIDIA GPUs als Cloud-GPUs anbieten.
NVIDIA startete zudem sein DGX Cloud-Angebot, das Cloud-GPU-Infrastruktur direkt an Unternehmen bereitstellt und Cloud-Anbieter umgeht.
GPUs für Grafik
Die Xbox verwendet einen Chipsatz, der gemeinsam von NVIDIA und Microsoft entwickelt wurde. NVIDIAs GPUs für Endverbraucher umfassen die GeForce-Serie.
Aktuelle Entwicklungen
DGX Cloud Lepton
Angekündigt am 19. Mai 2025 auf der Computex, ist NVIDIAs DGX Cloud Lepton ein Marktplatz, der KI-Entwickler mit NVIDIAs GPU-Cloud-Anbietern verbindet, darunter CoreWeave, Lambda und Crusoe. Es ermöglicht flexiblen Zugang zu GPU-Ressourcen für das Training und die Inferenz von KI-Modellen unter Umgehung traditioneller Cloud-Anbieter-Abhängigkeiten. Dies stärkt NVIDIAs unternehmensorientierte Cloud-Strategie.9
NVIDIA Dynamo
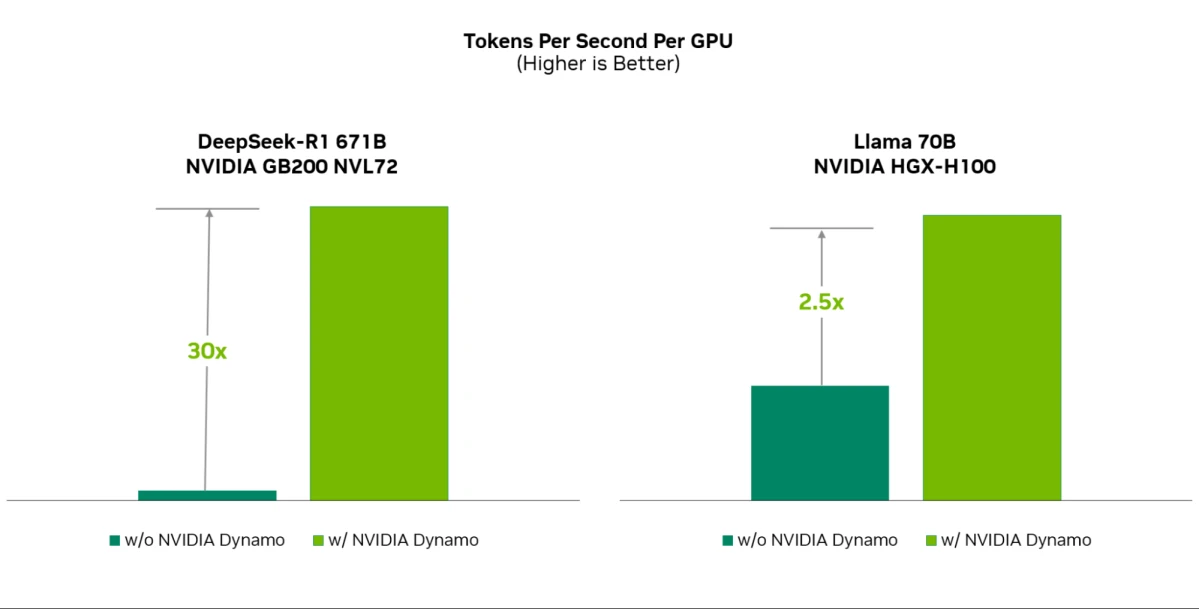
NVIDIA Dynamo, angekündigt auf der GTC 2025, ist ein neues Open-Source-Inferenz-Framework, das für den Einsatz generativer KI-Modelle mit hohem Durchsatz und niedriger Latenz in verteilten Umgebungen entwickelt wurde und die Bereitstellung von Anfragen um bis zu 30x auf NVIDIA Blackwell beschleunigt, wie in der folgenden Abbildung dargestellt. Dieses Framework, kompatibel mit beliebten Tools wie PyTorch und TensorRT-LLM, nutzt Innovationen wie disaggregierte Inferenzstufen und dynamische GPU-Planung, um die Leistung zu optimieren und Kosten zu senken. Verfügbar auf GitHub für Entwickler und enthalten in den NVIDIA NIM-Mikrodiensten für Unternehmenslösungen, ermöglicht Dynamo skalierbare und kosteneffiziente generative KI-Bereitstellung von Einzel- bis zu Multi-GPU-Systemen.10
NVIDIA RTX PRO Server und Enterprise KI Factory
Angekündigt im Mai 2025 auf der Computex, stellte NVIDIA RTX PRO Server vor, die von RTX PRO 6000 Blackwell Server Edition GPUs angetrieben werden und für Enterprise-KI-Fabriken konzipiert sind. Diese Server bieten universelle Beschleunigung für KI-, Design-, Konstruktions- und Geschäftsanwendungen und unterstützen Workloads wie multimodale KI-Inferenz, physische KI und digitale Zwillinge auf der NVIDIA Omniverse-Plattform.
Das NVIDIA Enterprise KI Factory-validierte Design, das RTX PRO Server, NVIDIA Spectrum-X Ethernet, NVIDIA BlueField DPUs und NVIDIA KI Enterprise-Software umfasst, ermöglicht Partnern wie Cadence, Foxconn und Lilly den Aufbau von On-Premises-KI-Infrastruktur. Diese Initiative beschleunigt den billionenschweren IT-Branchenübergang zu GPU-beschleunigten KI-Fabriken. 12
NVIDIA Vera Rubin Plattform
NVIDIAs Plattform der nächsten Generation nach Blackwell Ultra, angekündigt auf der CES 2026 und in Produktion bestätigt auf der Computex 2026, liefert 3,5-fach schnelleres Training und 5-fach schnellere Inferenz gegenüber Blackwell und basiert auf TSMC 3nm mit HBM4.13 14 Das NVL72-Rack bietet 260 TB/s Bandbreite.
DeepSeek
Die Veröffentlichung von DeepSeeks R1 zeigte, dass hochmoderne Modelle mit einer relativ geringen Anzahl von GPUs trainiert werden können. Dies führte zu einem Rückgang des Aktienkurses von NVIDIA. Obwohl dies keine Anlageberatung ist, kann dies positiv für NVIDIA sein, da je mehr Nutzen Rechenleistung bietet, desto breiter sollte sie genutzt werden (d. h. Jevons-Paradoxon15 ).
Angesichts der Tatsache, dass sich die Leistung von GPU-Systemen aufgrund von Fortschritten im Chip-Design und bei Verbindungen jährlich um ein Vielfaches verbessert, wären Käufer jedoch gut beraten, nicht über ihren jährlichen Bedarf hinaus zu kaufen, da dies zum Besitz veralteter Systeme führen kann.
Zölle & Exportbeschränkungen
NVIDIA darf nun fortschrittliche KI-Prozessoren auf den chinesischen Markt exportieren, was eine Abkehr von den früheren Anforderungen darstellt, nur abgespeckte Versionen zu verkaufen. Diese Exporte stehen jedoch vor neuen logistischen und finanziellen Hürden: In Taiwan hergestellte Chips müssen nun einen Umweg über die Vereinigten Staaten für Tests durch Dritte machen, was einen neu eingeführten 25 % Nationalen Sicherheitszoll auslöst.
Trotz des wiederhergestellten Zugangs zu High-End-Hardware schaffen die zusätzlichen Kosten und die Komplexität der Lieferkette weiterhin Anreize für die chinesische Regierung und Chip-Industrie, wettbewerbsfähige lokale Alternativen zu entwickeln. Während chinesische Chips derzeit hinter der neuesten Technologie von NVIDIA zurückbleiben, stellen diese Handelshemmnisse sicher, dass die heimische Entwicklung eine strategische Priorität bleibt, was möglicherweise die Marktdominanz von NVIDIA in Zukunft herausfordern könnte.16
Wettbewerb im Inferenzmarkt
Während NVIDIA den KI-„Trainingsmarkt“ dominiert, verschärft sich der Wettbewerb in der „Inferenz“, dem Einsatz von KI-Modellen für reale Aufgaben. Unternehmen wie AMD und zahlreiche Startups, darunter Untether KI und Groq, entwickeln Chips, die darauf abzielen, kosteneffizientere Inferenzlösungen mit besonderem Fokus auf geringeren Stromverbrauch zu bieten.
Neue „Reasoning“-KI-Techniken erfordern mehr Rechenleistung. NVIDIA glaubt, dass Reasoning seine Architektur langfristig begünstigen wird, und erwartet, dass der Inferenzmarkt den Trainingsmarkt schließlich an Größe übertreffen wird, auch wenn sein Marktanteil kleiner ist. 17
2. AMD
AMD ist ein fabless Chip-Hersteller mit CPU-, GPU- und KI-Beschleuniger-Produkten.
AMD brachte im Juni 2023 den MI300 für KI-Trainings-Workloads auf den Markt und konkurriert mit NVIDIA um Marktanteile. Es gibt Startups, Forschungsinstitute, Unternehmen und Tech-Giganten, die 2023 AMD-Hardware eingeführt haben, da Nvidia-KI-Hardware aufgrund der rasant steigenden Nachfrage schwer zu beschaffen war, ausgelöst durch den Aufstieg der generativen KI mit der Einführung von ChatGPT.18 19 20
Im Jahr 2025 kündigte AMD die Übernahme eines talentierten Teams von KI-Hardware- und Software-Ingenieuren von Untether KI an, einem Entwickler energieeffizienter KI-Inferenzchips für Edge-Anbieter und Unternehmensrechenzentren. Dieser Schritt verbessert die Fähigkeiten von AMD im Bereich KI-Compiler, Kernel-Entwicklung und Chip-Design und stärkt seine Position auf dem Inferenzmarkt weiter. Darüber hinaus erwarb AMD das Compiler-Startup Brium, um die KI-Leistung auf seinen Instinct-Rechenzentrums-GPUs für Unternehmensanwendungen zu optimieren.21
AMD wird die MI350-Serie herausbringen, um den MI300 zu ersetzen und mit NVIDIAs H200 zu konkurrieren. AMD behauptet, dass der MI325X, ein weiterer aktueller Chip, marktführende Inferenzleistung bietet. Im Februar 2026 kündigte Meta eine langfristige Infrastrukturvereinbarung mit AMD an, um bis zu 6 GW an AMD Instinct GPUs bereitzustellen, einer der größten Nicht-NVIDIA GPU-Beschaffungsverträge der Geschichte und eine bedeutende Bestätigung der KI-Hardware-Roadmap von AMD.22 23
AMD arbeitet auch mit Machine-Learning-Unternehmen wie Hugging Face zusammen, um Datenwissenschaftlern eine effizientere Nutzung ihrer Hardware zu ermöglichen.24
Das Software-Ökosystem ist entscheidend, da die Hardware-Leistung stark von der Software-Optimierung abhängt. Beispielsweise hatten AMD und NVIDIA eine öffentliche Meinungsverschiedenheit über das Benchmarking von H100 und MI300. Im Mittelpunkt der Auseinandersetzung standen das Paket und der im Benchmark zu verwendende Gleitkommatyp. Nach den neuesten Benchmarks scheint der MI300 bei der Inferenz eines 70B LLM besser oder gleichauf mit dem H100 zu sein.25
Software
Während AMD-Hardware zu NVIDIA aufschließt, hinkt die Software in Bezug auf die Benutzerfreundlichkeit hinterher. Während CUDA für die meisten Aufgaben sofort einsatzbereit ist, erfordert AMD-Software erhebliche Konfiguration. 26
Ökosystem
Wie NVIDIA investiert auch AMD selektiv in Nutzer seiner Lösungen, um die Akzeptanz seiner Hardware zu fördern. 27
3. Intel
Intel ist der bedeutendste Akteur im CPU-Markt und verfügt über eine lange Geschichte in der Halbleiterentwicklung. Im Gegensatz zu NVIDIA und AMD nutzt Intel seine eigene Fertigung zur Herstellung seiner Chips.
Gaudi3 ist der neueste KI-Beschleunigerprozessor von Intel. 28 Die Umsatzprognose von Intel für Gaudi3 lag jedoch bei etwa 500 Mio. $ für 2024, was deutlich niedriger ist als die Milliarden, die AMD für 2024 prognostiziert.
Unter dem neuen CEO Lip-Bu Tan (ernannt im März 2025) hat sich die KI-Strategie von Intel auf Rack-Scale-Lösungen ausgerichtet.29 Intel strich seine Falcon Shores GPU, um auf Jaguar Shores umzuschwenken, einen Rack-Scale-KI-Beschleuniger der nächsten Generation, der auf dem Intel 18A-Prozessknoten basiert, und kündigte auf der Computex 2026 neue KI-Hardware an, darunter den Xeon 6+ Prozessor auf dem 18A-Knoten und die Crescent Island Rechenzentrums-GPU.30 31
Welche Public-Cloud-Anbieter produzieren KI-Chips?
4. AWS
AWS produziert Tranium-Chips für das Modelltraining und Inferentia-Chips für die Inferenz. Obwohl AWS Marktführer in der Public Cloud ist, begann das Unternehmen erst nach Google mit der Entwicklung eigener Chips.
Hunderttausende von Tranium2-Chips werden verwendet, um den Project Rainier-Cluster zu bilden, der die Modelle des LLM-Entwicklers Anthropic antreibt.
5. Google Cloud Platform
Google Cloud TPU ist der speziell entwickelte Machine-Learning-Beschleunigerchip, der Google-Produkte wie Translate, Photos, Search, Assistant und Gmail antreibt. Google kündigte TPUs im Jahr 2016 an.32 Die neueste Trillium TPU ist die 6. Generation.33
Google hat Ironwood eingeführt. Diese neueste Generation ist speziell für komplexe „Denkmodelle“ wie LLMs und MoEs konzipiert und bietet massive parallele Verarbeitung (4.614 TFLOPs pro Chip) und eine Skalierung auf bis zu 42,5 Exaflops in 9.216-Chip-Pods.34
Ironwood bietet bedeutende Fortschritte gegenüber Trillium, darunter die 2-fache Energieeffizienz, die 6-fache High-Bandwidth-Memory-Kapazität (192 GB/Chip), die 4,5-fache HBM-Bandbreite (7,2 TBps/Chip) und die 1,5-fache Inter-Chip-Interconnect-Geschwindigkeit (1,2 Tbps). Es verfügt zudem über einen verbesserten SparseCore für große Embeddings. Google produziert auch die viel kleinere Edge TPU für unterschiedliche Anforderungen, die für den Einsatz auf Edge-Geräten wie Smartphones und IoT-Hardware konzipiert ist.
6. Alibaba
Alibaba produziert Chips wie den Hanguang 800 für die Inferenz. Einige nordamerikanische, europäische und australische Organisationen (z. B. aus der Verteidigungsindustrie) ziehen es jedoch möglicherweise aus geopolitischen Gründen vor, Alibaba Cloud nicht zu nutzen.
7. IBM
IBM kündigte seinen neuesten Deep-Learning-Chip, die Artificial Intelligence Unit (AIU), im Jahr 2022 an.35 . IBM erwägt, diese Chips für die Watsonx-Plattform für generative KI einzusetzen.36
Die IBM AIU baut auf dem IBM Telum Processor auf, der die KI-Verarbeitungsfähigkeiten der IBM Z Mainframe-Server antreibt. Zu den hervorgehobenen Anwendungsfällen der Telum-Prozessoren bei der Markteinführung gehörte die Betrugserkennung.37
IBM demonstrierte auch, dass die Zusammenführung von Rechenleistung und Speicher zu Effizienzsteigerungen führen kann. Dies wurde im North-Pole-Prozessor-Prototyp gezeigt.38
8. Huawei
Huaweis HiSilicon Ascend 910C ist Teil der Ascend 910 Chip-Familie, die 2019 eingeführt wurde.
Aufgrund von Sanktionen können KI-Labore in China nicht die neuesten, leistungsstärksten Chips von US-Unternehmen wie NVIDIA oder AMD kaufen. Daher experimentieren sie mit dem Ascend 910C.
Huaweis Cloud hostet DeepSeek-Modelle, und ein Forscher bei DeepSeek behauptet, dass sie 60 % der Inferenzleistung von NVIDIA H100 erreichen können. 39
Welche Cloud-KI-Anbieter produzieren ihre eigenen Chips?
Diese Anbieter verfügen nicht über Public Clouds mit umfassenden Fähigkeiten wie die Hyperscaler. Sie bieten begrenzte Cloud-Dienste an, die sich typischerweise auf KI-Inferenz konzentrieren. Wir konnten uns für diese Dienste anmelden, ohne mit Vertriebsteams zu sprechen:
9. Groq
Groq wurde von ehemaligen Google-Mitarbeitern gegründet. Das Unternehmen vertritt LPUs, ein neues Modell für KI-Chip-Architektur, das darauf abzielt, Unternehmen die Einführung ihrer Systeme zu erleichtern. Das Startup hat bereits rund 350 Millionen $ gesammelt und seine ersten Produkte wie GroqChip™ Processor, GroqCard™ Accelerator usw. hergestellt.
Das Unternehmen konzentriert sich auf LLM-Inferenz und veröffentlichte Benchmarks für Llama-2 70B.40
Kürzlich sicherte sich Groq eine bedeutende Investitionszusage in Höhe von 1,5 Milliarden $ von Saudi-Arabien, um die Lieferung seiner fortschrittlichen KI-Chips in das Land auszuweiten. Diese Investition wird verwendet, um das bestehende Rechenzentrum von Groq in Dammam, Saudi-Arabien, auszubauen, das in Partnerschaft mit Aramco Digital errichtet wurde.41
Im ersten Quartal 2024 teilte das Unternehmen mit, dass sich 70.000 Entwickler auf seiner Cloud-Plattform registriert und 19.000 neue Anwendungen erstellt haben.42
Am 1. März 2022 erwarb Groq Maxeler, das über High-Performance-Computing (HPC)-Lösungen für Finanzdienstleistungen verfügt.43
10. SambaNova Systems
SambaNova Systems wurde 2017 gegründet, um leistungsstarke, hochpräzise Hardware-Software-Systeme für generative KI-Workloads mit hohem Volumen zu entwickeln. Das Unternehmen hat mehr als 1,5 Milliarden Dollar an Gesamtfinanzierung erhalten, darunter eine Series-E-Runde über 350 Millionen Dollar im Februar 2026.44
Im Februar 2026 stellte SambaNova den SN50-Chip vor, seine neueste Reconfigurable Data Unit (RDU), mit einer maximalen Geschwindigkeit, die 5x schneller als konkurrierende Chips ist und 3x niedrigere Gesamtbetriebskosten im Vergleich zu GPUs für agentenbasierte KI-Workloads bietet. Der SN50 liefert 5x mehr Rechenleistung pro Beschleuniger und 4x mehr Netzwerkbandbreite als die vorherige Generation SN40L und unterstützt eine dreistufige Speicherarchitektur für Modelle mit über 10 Billionen Parametern und Kontextlängen von über 10 Millionen Tokens.45
SoftBank Corp. wird der erste Kunde sein, der SN50 in seinen KI-Rechenzentren der nächsten Generation in Japan einsetzt.
SambaNova kündigte zudem eine geplante mehrjährige strategische Zusammenarbeit mit Intel an, um KI-Inferenzlösungen bereitzustellen, die Systeme von SambaNova mit Intel Xeon-Prozessoren, Intel GPUs und Intel-Netzwerken kombinieren, um eine skalierbare Inferenzinfrastruktur als Alternative zu GPU-zentrierten Lösungen zu schaffen.
SambaNova Systems vermietet seine Plattform über SambaCloud an Unternehmen. Dieser KI-Plattform-as-a-Service-Ansatz erleichtert die Einführung ihrer Systeme und fördert die Wiederverwendung von Hardware für die Kreislaufwirtschaft.46
Welche sind die führenden KI-Chip-Startups?
Wir möchten auch einige Startups in der KI-Chip-Branche vorstellen, deren Namen wir in naher Zukunft möglicherweise häufiger hören werden.
11. Cerebras
Cerebras wurde 2015 gegründet und ist der einzige große Chiphersteller, der sich auf Wafer-Scale-Chips konzentriert. 47 Wafer-Scale-Chips haben Vorteile bei der Parallelverarbeitung im Vergleich zu GPUs dank ihrer höheren Speicherbandbreite. Das Design und die Herstellung solcher Chips sind jedoch eine aufstrebende Technologie.
Zu den Chips von Cerebras gehören:
- WSE-1 mit 1,2 Billionen Transistoren und 400.000 Verarbeitungskernen.
- WSE-2 mit 2,6 Billionen Transistoren und 850.000 Kernen wurde im April 2021 angekündigt. Er nutzte den 7nm-Prozess von TSMC.
- WSE-3 mit 4 Billionen Transistoren und 900.000 KI-Kernen wurde im März 2024 angekündigt. Er nutzt den 5nm-Prozess von TSMC.48
Celebras System arbeitet mit Pharmaunternehmen wie AstraZeneca und GlaxoSmithKline sowie Forschungslaboren zusammen, die für Simulationen darauf angewiesen sind. Es zielt auch auf LLM-Hersteller ab, da seine Chips die Inferenzkosten für Frontier-Modelle senken können.
Cerebras bietet seine Chips auch in seiner Cloud für Unternehmen an.
12. d-Matrix
d-Matrix verfolgt einen neuartigen Ansatz und verzichtet auf die traditionelle Von-Neumann-Architektur zugunsten von In-Memory-Computing. Während dieser Ansatz das Potenzial hat, den Engpass zwischen Speicher und Rechenleistung zu beseitigen, ist er neu und unerprobt. Im November 2025 sammelte d-Matrix 275 Mio. $ in einer Series-C-Runde unter der gemeinsamen Leitung von Bullhound Capital, Triatomic Capital und Temasek ein, wobei Microsofts M12 als Folgeinvestor teilnahm und das Unternehmen mit 2 Milliarden $ bewertet wurde.49 50
Stand Juni 2026 ging d-Matrix mit seiner Corsair-KI-Inferenzplattform in die vollständige Chip-Produktion, die auf einer SRAM-basierten In-Memory-Compute-Chiplet-Architektur basiert, wobei unabhängige Tests eine über 10-fache Geschwindigkeitsverbesserung gegenüber reinen GPU-Alternativen für KI-Inferenz-Workloads zeigten.51
13. Rebellions
Ein in Korea ansässiges Startup sammelte 2024 124 Mio. $ ein und konzentriert sich auf LLM-Inferenz.52
Rebellions fusionierte mit einem anderen koreanischen Halbleiter-Design-Unternehmen, SAPEON, und erreichte 2024 eine Einhorn-Bewertung.53
Im Juli 2025 sicherte sich Rebellions eine Investition des Tech-Giganten Samsung als Teil einer Finanzierungsrunde mit einem Zielvolumen von bis zu 200 Millionen $ im Vorfeld eines geplanten Börsengangs (IPO). Das Unternehmen hat seit seiner Gründung im Jahr 2020 220 Millionen $ eingeworben und arbeitet mit Samsung zusammen, um seinen Chip der zweiten Generation, Rebel-Quad (bestehend aus vier Rebel-KI-Chips), später im Jahr 2025 auf den Markt zu bringen, wobei Samsungs 4-Nanometer-Fertigungsprozess genutzt wird. 54
14. Tenstorrent
Der neueste Blackhole Tensix Processor von Tenstorrent liefert 664 TFLOPS (BLOCKFP8) Leistung, gepaart mit 32 GB GDDR6-Speicher und 512 GB/s Speicherbandbreite.
Die P150a-Karte kostet 1.399 $ und verfügt über vier QSFP-DD 800G-Ports für die Skalierung mehrerer Karten. Das Einstiegsmodell P100a beginnt bei 999 $.55
Tenstorrent bietet einen vollständig quelloffenen Software-Stack. Das Unternehmen sammelte 700 Mio. $ bei einer Bewertung von mehr als 2,6 Milliarden $ von Investoren, darunter Jeff Bezos, im Dezember 2024 ein. 56
15. Positron
Positron wurde 2023 gegründet und konzentriert sich ausschließlich auf Transformer-Modell-Inferenz. Das Unternehmen verfolgt einen ASIC-Ansatz und baut speziell entwickelte Hardware, die spezifisch für Transformer-Architekturen optimiert ist, anstatt auf universelle GPU-Berechnungen zu setzen.
Produkte:
- Atlas (jetzt verfügbar): Ein Transformer-Inferenzserver mit 8x Positron Archer Transformer Accelerators mit 256 GB Gesamt-HBM. Das Unternehmen beansprucht >4x Leistung pro Watt und >3x Leistung pro Dollar im Vergleich zu NVIDIA Hopper-Systemen, benchmarkt mit Llama 3.1 8B mit BF16-Berechnung.57
- Titan (erscheint 2027): Ein System der nächsten Generation mit 8+ TB Speicher, angetrieben von 4x Asimov Custom-Chips, das bis zu 16 Billionen Parameter und 10 Millionen+ Token-Kontextfenster in einem luftgekühlten 4U-Formfaktor unterstützen soll.58
- Asimov (erscheint 2027): Kundenspezifisches Inferenzbeschleuniger-Silizium mit 2+ TB Speicher pro Chip.
Positron sammelte Anfang 2026 eine Series-B-Runde in Höhe von 230 Mio.+ $ mit Investoren wie QIA, Arm Holdings, Arena und Jump Trading ein.59
Atlas wird derzeit von Unternehmen aus den Bereichen Netzwerke, Gaming, Inhaltsmoderation, CDN und Token-as-a-Service genutzt. Positron gibt an, dass sein Atlas-System eine 3x niedrigere Ende-zu-Ende-Latenz für Trading-Inferenz-Workloads im Vergleich zu vergleichbaren H100-Systemen bei einem Drittel des Stromverbrauchs demonstrierte.
Positrons Chips werden in den Vereinigten Staaten entworfen, gefertigt und montiert.
16. _etched
Ihr Ansatz opfert Flexibilität zugunsten von Effizienz, indem die Transformer-Architektur direkt in ihre Chips eingebrannt wird.
Das Team behauptet:
- Sohu hat den weltweit ersten Transformer-ASIC gebaut.
- 8 Sohu-Chips können >500.000 Tokens/Sekunde generieren. Dies ist eine Größenordnung mehr als das, was 8 NVIDIA B200s erreichen können.
Derzeit basieren diese Angaben auf internen Messungen des Teams. Die Teams von AIMultiple sind bisher auf keine Benchmarks oder Kundenreferenzen gestoßen. Wir sind neugierig auf:
- Was passiert, wenn das Modell veraltet ist? Müssen Benutzer einen neuen Chip kaufen, oder kann der alte Chip mit dem nächsten Modell neu konfiguriert werden?
- Wie haben sie ihren Benchmark durchgeführt? Welche Quantisierung und welches Modell wurden verwendet?
Wir werden dies aktualisieren, sobald das _etched-Team weitere Details veröffentlicht. Es wird interessant sein zu sehen, ob das Einbrennen von Modellen in Chips nachhaltig sein wird, angesichts der Veröffentlichung neuer Modelle alle paar Monate.
17. Taalas
Taalas wurde Anfang 2023 gegründet und verfolgt den extremsten Ansatz zur KI-Chip-Spezialisierung: das direkte Einbrennen einzelner Modelle in kundenspezifisches Silizium, wodurch sogenannte „Hardcore Models“ entstehen.60 Das Unternehmen behauptet, jedes zuvor ungesehene KI-Modell innerhalb von zwei Monaten in kundenspezifisches Silizium verwandeln zu können.
Die Architektur von Taalas vereint Speicher und Rechenleistung auf einem einzigen Chip mit DRAM-ähnlicher Dichte und eliminiert die Notwendigkeit von HBM, fortschrittlichem Packaging, 3D-Stacking, Flüssigkühlung oder Hochgeschwindigkeits-I/O. Das Unternehmen beschreibt dies als eine radikale Vereinfachung des Hardware-Stacks.
Produkte:
- HC1 (jetzt verfügbar): Ein Technologiedemonstrator, fest verdrahtet mit Llama 3.1 8B, gebaut auf TSMC 6nm mit 53 Milliarden Transistoren. Taalas gibt 17.000 Tokens pro Sekunde pro Benutzer an, was nach eigenen Angaben fast 10x schneller als der aktuelle Stand der Technik ist, bei 20x geringeren Baukosten und 10x weniger Stromverbrauch in einem luftgekühlten 2,5-kW-Server. Das Modell verwendet jedoch aggressive kundenspezifische 3-Bit- und 6-Bit-Quantisierung, was zu Qualitätseinbußen im Vergleich zu GPU-Baselines führt.61
- HC2 (geplant): Eine Plattform der zweiten Generation mit höherer Dichte, schnellerer Ausführung und standardmäßigen 4-Bit-Gleitkommaformaten, um die Quantisierungseinschränkungen des HC1 zu beheben.
Taalas hat mehr als 200 Millionen Dollar eingeworben, gibt aber an, nur 30 Millionen Dollar ausgegeben zu haben, um sein erstes Produkt mit einem Team von 24 Personen auf den Markt zu bringen.
18. Extropic
Extropic sammelte Ende 2023 eine Series-A-Runde in Höhe von 14 Mio. $ ein, um Thermodynamik für die Berechnung zu nutzen. Das Unternehmen hat noch keinen Chip veröffentlicht.
19. Vaire
Vaire ist ein in Großbritannien ansässiges Startup, das Pionierarbeit im Bereich reversibles Computing leistet, einem innovativen Ansatz zur Entwicklung von Chips mit nahezu null Energieverbrauch. Im Gegensatz zum traditionellen Computing, bei dem Energie als Wärme verloren geht, recycelt reversibles Computing einen erheblichen Teil der Energie für nachfolgende Berechnungen.
Vaire hat einen Testchip demonstriert, der 50 % seiner Energie zurückgewinnen kann und zeigt damit das Potenzial der Technologie, den Energieverbrauch von KI-Workloads zu senken und die physikalischen Grenzen, die sogenannte thermische Wand, zu umgehen, die moderne Halbleiterfertigung herausfordern. 62
20. Fractile
Fractile ist ein in Großbritannien ansässiges KI-Inferenzchip-Startup, das im Juli 2024 mit einer 15 Millionen $-Finanzierung aus dem Stealth-Modus hervortrat, um NVIDIA bei der Frontier-Modell-Inferenz herauszufordern.63
Das Unternehmen baut Prozessoren, die Speicher und Rechenleistung physisch auf demselben Chip verschränken, was nach eigenen Angaben die gleichzeitige Anforderung nach niedriger Latenz und hohem Durchsatz löst, die GPUs für Frontier-Modell-Inferenz nicht erfüllen können. Fractile behauptet, dass sein Design Frontier-Modelle bis zu 25x schneller und zu 1/10 der Kosten bestehender Lösungen ausführen kann, mit dem Ziel, Tausende von Tokens pro Sekunde an Tausende gleichzeitiger Benutzer zu liefern.
Fractile hat seinen Hauptsitz in London mit Hardware-Entwicklung in Bristol und wurde im März 2025 von der Financial Times als Teil einer Welle von inferenzorientierten Startups porträtiert, die Dominanz von NVIDIA herausfordern.64
Welche sind die kommenden KI-Hardware-Hersteller?
Obwohl es sich um vielversprechende KI-Hardware-Lösungen handelt, gibt es derzeit nur begrenzte Benchmarks zu ihrer Effektivität, da sie neu auf dem Markt sind.
21. Apple
Apples Project ACDC konzentriert sich Berichten zufolge auf die Entwicklung von Chips für KI-Inferenz in Rechenzentren, wobei die Massenproduktion für das zweite Halbjahr 2026 erwartet wird.65 Apple ist bereits ein bedeutender Chip-Designer mit seinen intern entwickelten Halbleitern, die in iPhones, iPads und MacBooks verwendet werden. Apple stärkt seine On-Device-KI-Strategie mit dem Core KI-Framework, das Modelle vollständig auf Apple-Silizium ohne Server-Abhängigkeiten ausführt, unterstützt durch ein quelloffenes Core KI-Modelle-Repository auf GitHub.66 67
22. Meta
Der Meta Training and Inference Accelerator (MTIA) ist eine Familie von Prozessoren für KI-Workloads wie das Training der LLaMa-Modelle von Meta.
Das neueste MTIA-Modell, Next Gen MTIA, basiert auf TSMC 5nm-Technologie und soll die 3-fache Leistung des MTIA v1 bieten. MTIA wird in Racks mit bis zu 72 Beschleunigern untergebracht sein.68
MTIA ist derzeit für die interne Nutzung von Meta bestimmt. Sollte Meta jedoch in Zukunft ein LLaMa-basiertes Enterprise Generative KI-Angebot auf den Markt bringen, könnten diese Chips ein solches Angebot betreiben.
23. Microsoft Azure
Auf der Hot Chips 2024 stellte Microsoft Maia 100 vor, seinen ersten kundenspezifischen KI-Beschleuniger, der für die Optimierung großer KI-Workloads in Azure durch Hardware- und Software-Co-Optimierung entwickelt wurde. Aufgebaut auf dem N5-Prozess von TSMC mit fortschrittlicher Speicher- und Interconnect-Technologie, zielt Maia 100 auf hohen Durchsatz und vielfältige Datenformate ab und bietet Entwicklern Flexibilität über sein SDK für die schnelle Bereitstellung von PyTorch- und Triton-Modellen. Microsoft brachte Maia 200 (Codename Braga) am 26. Januar 2026 als inferenzorientierten KI-Beschleuniger für Azure auf den Markt, der die KI-Token-Kosten senken und eine 30 % bessere Leistung pro Dollar gegenüber bestehenden Systemen bieten soll.69
24. OpenAI
OpenAI stellt das Design seines ersten KI-Chips mit Broadcom und TSMC unter Verwendung der 3-Nanometer-Technologie von TSMC fertig. Die Leitung des Chip-Teams von OpenAI verfügt über Erfahrung im Design von TPUs bei Google, und sie streben an, ihren Chip 2026 in Massenproduktion zu bringen. Der Project Titan Chip von OpenAI, der gemeinsam mit Broadcom entwickelt und auf dem 3nm-Prozess von TSMC gefertigt wird, ist auf dem Weg zur Massenproduktion im zweiten Halbjahr 2026.70 71
Samsung hat eine Vereinbarung zur Lieferung von HBM4-Speicher für den Titan-Chip getroffen und Berichten zufolge über 50 % seiner Pyeongtaek-Foundry-Kapazität für HBM4-Base-Dies für diesen Zweck zugewiesen.72 OpenAI und Broadcom haben den Jalapeño-Inferenzchip angekündigt, eine strategische Zusammenarbeit im Wert von rund 10 Milliarden $ mit dem Ziel, 10 GW an bereitgestellter KI-Rechenleistung bis 2029 zu erreichen, um die Abhängigkeit von OpenAI von NVIDIA zu verringern.73
Welche sonstigen KI-Chip-Hersteller gibt es?
25. Graphcore
Graphcore ist ein britisches Unternehmen, das 2016 gegründet wurde. Das Unternehmen kündigte seinen Flaggschiff-KI-Chip als IPU-POD256 an. Graphcore wurde bereits mit rund 700 Millionen $ finanziert.
Das Unternehmen unterhält strategische Partnerschaften mit Datenspeicherunternehmen wie DDN, Pure Storage und Vast Data. Die KI-Chips von Graphcore bedienen Forschungsinstitute wie das Oxford-Man Institute of Quantitative Finance, die University of Bristol und die Berkeley University of California.
Die langfristige Überlebensfähigkeit des Unternehmens war gefährdet, da es jährlich rund 200 Mio. $ verlor.74 Graphcore wurde im Oktober 2024 von SoftBank für über 600 Millionen $ übernommen.75
26. Mythic
Mythic wurde 2012 gegründet und konzentriert sich auf Edge-KI. Mythic verfolgt einen unkonventionellen Weg, eine analoge Rechenarchitektur, die darauf abzielt, energieeffiziente Edge-KI-Berechnungen zu liefern.
Das Unternehmen hat Produkte wie M1076 AMP und MM1076 Key Card entwickelt und bereits rund 165 Millionen $ an Finanzierung eingeworben.76
Mythic entließ den Großteil seiner Belegschaft und restrukturierte sein Geschäft mit einer Finanzierungsrunde im März 2023.77
27. Speedata
Speedata wurde 2019 in Tel Aviv gegründet und entwickelt eine Analytics Processing Unit (APU), die darauf ausgelegt ist, Big-Data-Analysen und KI-Workloads zu beschleunigen. Es handelt sich um eine APU, die auf Apache Spark-Workloads abzielt, mit Plänen zur Unterstützung anderer wichtiger Datenanalyse-Plattformen.
Speedata sammelte 44 Mio. $ in einer Series-B-Runde im Juni 2025 ein, angeführt von Walden Catalyst Ventures, 83North und anderen, womit sich die Gesamtfinanzierung auf 114 Mio. $ erhöht. Das Unternehmen behauptet, dass seine APU universelle Prozessoren und GPUs übertrifft, indem sie Server-Racks durch einen einzigen Chip ersetzt und überlegene Leistung und Energieeffizienz für die Datenverarbeitung bietet.78
28. Axelera KI
Axelera KI wurde im Juli 2021 in Eindhoven, Niederlande, gegründet und ist auf KI-Hardware-Beschleunigungstechnologie für Computer Vision und generative KI spezialisiert. Das Unternehmen entwickelt Titania, ein KI-Inferenz-Chiplet auf Basis seiner Digital In-Memory Computing (D-IMC)-Architektur, das zur Beschleunigung von KI-Workloads vom Edge bis zur Cloud konzipiert ist.
Axelera KI sicherte sich im März 2025 im Rahmen des DARE-Projekts bis zu 61,6 Millionen € an Finanzierung vom Gemeinsamen Unternehmen EuroHPC (JU) und den Mitgliedstaaten, nach einer vorherigen Series-B-Finanzierungsrunde in Höhe von 68 Millionen $. Damit beläuft sich die Gesamtfinanzierung in drei Jahren auf über 200 Millionen $. Axelera KI strebt an, Titania bis 2028 einzusetzen, um der wachsenden Nachfrage nach leistungsstarken, kosteneffizienten und nachhaltigen KI-Lösungen gerecht zu werden, und betont die Fähigkeit, Durchsatz und Effizienz im Vergleich zu herkömmlichen Cloud-Lösungen zu verbessern.79
Gießereipartner und die Rolle von TSMC
Als weltweit führende reine Gießerei fertigt TSMC Halbleiter auf der Grundlage von Kundendesigns, anstatt eigene Chips zu entwickeln, was es von Unternehmen wie NVIDIA und AMD unterscheidet. Während Samsung Foundry und Intel Foundry Services in diesem Bereich konkurrieren, behält TSMC einen technologischen Vorsprung.
Seine fortschrittlichen Prozesstechnologien, insbesondere die bahnbrechenden 5nm- und 3nm-Knoten, bieten die wesentliche Kombination aus Leistung und Energieeffizienz, die für modernste KI-Anwendungen erforderlich ist, wie die Fertigungspartnerschaften mit den unten aufgeführten KI-Chip-Designern zeigen:
Expansionspläne
TSMC bemüht sich, dass Nvidia, AMD, Broadcom und Qualcomm in ein Joint Venture investieren, um die Gießerei-Sparte von Intel zu betreiben, wobei TSMC die operative Kontrolle behält, aber weniger als 50 % der Eigentumsanteile hält. Diese von der Trump-Administration unterstützte Initiative erfolgt, nachdem TSMC Pläne für eine bedeutende US-Investition angekündigt hat, und zielt darauf ab, Intel wiederzubeleben und die US-Chip-Fertigung zu stärken. Die Vereinbarung steht aufgrund von Prozessunterschieden vor Herausforderungen, baut jedoch auf den Stärken von TSMC als führender Gießerei auf.80 81
Welche sind die KI-Chip-Hersteller in China?
Aufgrund von US-Sanktionen, die viele chinesische Unternehmen daran hindern, die fortschrittlichsten KI-Chips von AMD und NVIDIA zu erwerben, haben chinesische Käufer ihre Einkäufe bei lokalen Herstellern erhöht.
Neben den oben behandelten Huawei und Alibaba sind dies die führenden KI-Chip-Hersteller in China:
- Cambricon konzentriert sich auf KI-Hardware und erwartet im letzten Geschäftsjahr einen Umsatz von rund 150 Mio. $. 82
- Baidu verwendet Kunlun-Chips in seiner Cloud und entwirft den Chip der 3. Generation. Kunlun 2 war mit NVIDIA A100 vergleichbar.
- Biren, gegründet von NVIDIA-Alumni, produziert BR106 & BR110 GPU-Chips.
- Moore Threads produziert MTT S2000 GPUs.
FAQs
Chips und die Geräte, die sie herstellen, sind die komplexesten Maschinen, die jemals von Menschen gebaut wurden. Obwohl es viele Unternehmen im Halbleiter-Ökosystem gibt, haben wir uns in diesem Artikel auf Chip-Designer wie NVIDIA konzentriert.
Die meisten Chip-Designer lagern die Chip-Fertigung an Gießereien wie TSMC aus. Gießereien verwenden Lithographiegeräte von Unternehmen wie ASML, um diese Chips herzustellen. Das Ökosystem wird von Anbietern wie Arm und Synopsys unterstützt, die IP und Design-Tools bereitstellen.
Wie oben zu sehen, führten eine zunehmende Anzahl von Parametern, Dataset-Größe und Rechenleistung dazu, dass generative KI-Modelle genauer wurden. Um bessere Deep-Learning-Modelle zu entwickeln und generative KI-Anwendungen zu betreiben, benötigen Unternehmen mehr Rechenleistung und Speicherbandbreite.
Leistungsstarke Allzweckchips (wie CPUs) können hochgradig parallelisierte Deep-Learning-Modelle nicht unterstützen. Daher sind KI-Chips (z. B. GPUs), die parallele Rechenkapazitäten ermöglichen, zunehmend gefragt.
Hyperscaler reagieren darauf, indem sie ihre eigenen Chips entwerfen, ein Prozess, der Jahre dauert. Der Rest muss einen der folgenden Wege gehen, um eigene KI-Modelle zu entwickeln: Kapazität von Cloud-GPU-Anbietern mieten oder Hardware von den führenden KI-Chip-Anbietern kaufen, die in diesem Artikel aufgeführt sind.
KI-Hardware wird auch als Neural Processing Units (NPUs), KI-Beschleuniger oder Deep-Learning-Prozessoren (DLPs) bezeichnet.
Weiterführende Literatur
Für praktische Leistungsvergleiche der in diesem Artikel behandelten Chips verweisen wir auf unsere Benchmarks:
- Multi-GPU-Benchmark: Wie NVIDIAs B200, H200, H100 und AMDs MI300X über 1, 2, 4 und 8-GPU-Konfigurationen für LLM-Inferenz skalieren, mit Analyse von Durchsatz, Latenz und Kosten pro Token.
- GPU-Parallelitäts-Benchmark: Wie NVIDIAs B200, H200, H100 und AMDs MI300X 1 bis 512 gleichzeitige Anfragen bewältigen, einschließlich Systemdurchsatz, Geschwindigkeit pro Abfrage, Ende-zu-Ende-Latenz und Tokens pro Dollar auf jeder Parallelitätsebene.
Referenzen
Diese Forschung zitieren
Wählen Sie das Format, das zu Ihrem Veröffentlichungsort passt. Wenn Sie die Link-Version in Ihr CMS einfügen, bleibt der Backlink erhalten.
@misc{dilmegani2026,
author = {Dilmegani, Cem},
title = {{Top 25+ KI-Chip-Hersteller: NVIDIA & seine Wettbewerber}},
year = {2026},
month = jun,
howpublished = {\url{https://aimultiple.com/ai-chip-makers}},
note = {AIMultiple. Abgerufen am 25. Juni 2026}
}
Kommentare 2
Teilen Sie Ihre Gedanken
Ihre E-Mail-Adresse wird nicht veröffentlicht. Alle Felder sind erforderlich. Kommentare werden in ihrer Originalsprache belassen.
You forgot to include Tesla with their DOJO supercomputer. From the ground-up, the supercomputer was specifically designed for machine learning and image recognition - which means that every component was designed for it including, but not limited to, PCI board design, CPU, RAM, cooling, power, scalable hardware design and software. If I'm not mistaken, the AI is also the second most widely tested and used in the "wild", just below that of Google due to Google using it in their Search.
Thank you for your feedback, Dave! Here we are only covering companies that sell the chips that they produce. Therefore, companies like Tesla that build supercomputers for their own use or companies that embed chips in their products are out of our scope.
surprised that brainchip (akida) missing in this report. any reasons?
All included companies here raised $100+M. Last time we collected the data, that wasn't the case for akida. Why don't you reach out to us at info@aimultiple.com and let's discuss why it should be included. Thank you!